- 软件工程教程
- 软件工程主页
- 软件工程概述
- 软件开发生命周期
- 软件项目管理
- 软件需求
- 软件设计基础
- 分析与设计工具
- 软件设计策略
- 软件用户界面设计
- 软件设计复杂性
- 软件实现
- 软件测试概述
- 软件维护
- CASE工具概述
- 软件考试题及答案
- 软件工程考试题及答案
- 软件工程资源
- 软件工程面试题
- 软件工程实用资源
- 软件工程快速指南
- 软件工程Android应用
软件设计复杂性
复杂性是指事件或事物状态,具有多个相互关联的链接和高度复杂的结构。在软件编程中,随着软件设计的实现,元素数量及其相互连接的数量逐渐变得巨大,以至于难以一次理解。
如果不使用复杂性度量和衡量方法,软件设计复杂性很难评估。让我们看看三个重要的软件复杂性度量。
霍尔斯特德复杂性度量
1977年,Maurice Howard Halstead先生引入了度量软件复杂性的指标。霍尔斯特德度量取决于程序的实际实现及其度量,这些度量是静态地直接从源代码中的运算符和操作数计算出来的。它允许评估C/C++/Java源代码的测试时间、词汇量、大小、难度、错误和工作量。
根据霍尔斯特德,“计算机程序是算法的实现,被认为是可分类为运算符或操作数的标记的集合”。霍尔斯特德度量将程序视为运算符及其相关操作数的序列。
他定义了各种指标来检查模块的复杂性。
| 参数 | 含义 |
|---|---|
| n1 | 唯一运算符的数量 |
| n2 | 唯一操作数的数量 |
| N1 | 运算符的总出现次数 |
| N2 | 操作数的总出现次数 |
当我们选择源文件以查看其在度量查看器中的复杂性详细信息时,在度量报告中可以看到以下结果
| 度量 | 含义 | 数学表示 |
|---|---|---|
| n | 词汇量 | n1 + n2 |
| N | 大小 | N1 + N2 |
| V | 体积 | 长度 * Log2(词汇量) |
| D | 难度 | (n1/2) * (N2/n2) |
| E | 工作量 | 难度 * 体积 |
| B | 错误 | 体积 / 3000 |
| T | 测试时间 | 时间 = 工作量 / S,其中 S = 18 秒。 |
圈复杂度度量
每个程序都包含按顺序执行以执行某些任务的语句以及决定需要执行哪些语句的决策语句。这些决策结构改变了程序的流程。
如果我们比较两个相同大小的程序,则具有更多决策语句的程序将更加复杂,因为程序的控制会频繁跳转。
McCabe于1976年提出了圈复杂度度量来量化给定软件的复杂性。这是一个基于程序决策结构(例如if-else、do-while、repeat-until、switch-case和goto语句)的图形驱动模型。
制作流程控制图的过程
- 将程序分解成更小的块,由决策结构分隔。
- 创建表示这些节点的节点。
- 按如下方式连接节点
如果控制可以从块i分支到块j
绘制一条弧
从出口节点到入口节点
绘制一条弧。
为了计算程序模块的圈复杂度,我们使用以下公式:
V(G) = e – n + 2 Where e is total number of edges n is total number of nodes
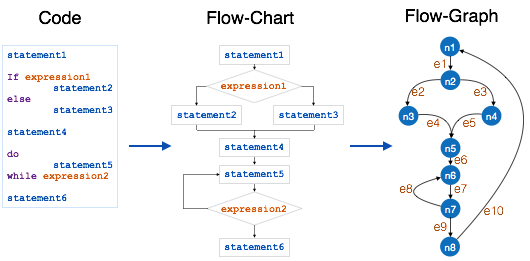
上述模块的圈复杂度为
e = 10
n = 8
Cyclomatic Complexity = 10 - 8 + 2
= 4
根据P. Jorgensen的说法,模块的圈复杂度不应超过10。
功能点
它被广泛用于衡量软件的大小。功能点关注系统提供的功能。系统的特性和功能用于衡量软件的复杂性。
功能点计数基于五个参数,分别命名为外部输入、外部输出、逻辑内部文件、外部接口文件和外部查询。为了考虑软件的复杂性,每个参数进一步分为简单、平均或复杂。
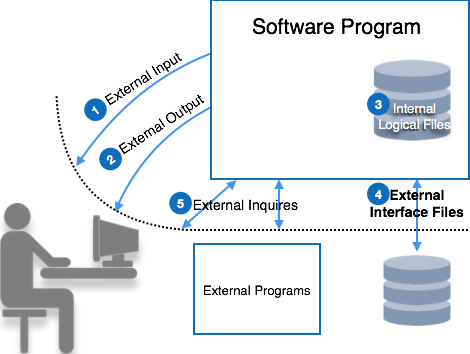
让我们看看功能点的参数
外部输入
来自外部的每个唯一输入都被视为外部输入。输入的唯一性是衡量的,因为没有两个输入应该具有相同的格式。这些输入可以是数据或控制参数。
**简单** - 如果输入计数低且影响的内部文件较少
**复杂** - 如果输入计数高且影响的内部文件较多
**平均** - 简单和复杂之间。
外部输出
系统提供的所有输出类型都计入此类别。如果输出格式和/或处理是唯一的,则输出被认为是唯一的。
**简单** - 如果输出计数低
**复杂** - 如果输出计数高
**平均** - 简单和复杂之间。
逻辑内部文件
每个软件系统都维护内部文件以维护其功能信息并正常运行。这些文件保存系统的逻辑数据。这些逻辑数据可能包含功能数据和控制数据。
**简单** - 如果记录类型数量较少
**复杂** - 如果记录类型数量较多
**平均** - 简单和复杂之间。
外部接口文件
软件系统可能需要与其一些外部软件共享其文件,或者可能需要将文件传递进行处理或作为参数传递给某些函数。所有这些文件都被计为外部接口文件。
**简单** - 如果共享文件中记录类型的数量较少
**复杂** - 如果共享文件中记录类型的数量较多
**平均** - 简单和复杂之间。
外部查询
查询是输入和输出的组合,用户发送一些数据作为输入进行查询,系统使用处理的查询输出响应用户。查询的复杂性高于外部输入和外部输出。如果查询的输入和输出在格式和数据方面是唯一的,则该查询被认为是唯一的。
**简单** - 如果查询需要较低的处理量并产生少量输出数据
**复杂** - 如果查询需要高处理量并产生大量输出数据
**平均** - 简单和复杂之间。
系统中的每个参数都根据其类别和复杂性赋予权重。下表提到了赋予每个参数的权重
| 参数 | 简单 | 平均 | 复杂 |
|---|---|---|---|
| 输入 | 3 | 4 | 6 |
| 输出 | 4 | 5 | 7 |
| 查询 | 3 | 4 | 6 |
| 文件 | 7 | 10 | 15 |
| 接口 | 5 | 7 | 10 |
上表产生原始功能点。这些功能点根据环境复杂性进行调整。系统使用十四种不同的特征进行描述
- 数据通信
- 分布式处理
- 性能目标
- 操作配置负载
- 事务速率
- 在线数据输入
- 最终用户效率
- 在线更新
- 复杂的处理逻辑
- 可重用性
- 安装简易性
- 操作简易性
- 多个站点
- 促进更改的愿望
然后,这些特征因素的等级从 0 到 5,如下所示
- 无影响
- 偶然的
- 适中的
- 平均
- 重要的
- 必要的
所有等级然后相加为N。N的值范围为0到70(14种特征类型x 5种等级类型)。它用于使用以下公式计算复杂性调整因子(CAF)
CAF = 0.65 + 0.01N
然后,
Delivered Function Points (FP)= CAF x Raw FP
此FP然后可用于各种指标,例如
**成本** = $/FP
**质量** = 错误/FP
**生产力** = FP/人月