- spaCy 教程
- spaCy - 首页
- spaCy - 简介
- spaCy - 入门
- spaCy - 模型和语言
- spaCy - 架构
- spaCy - 命令行助手
- spaCy - 顶级函数
- spaCy - 可视化函数
- spaCy - 实用函数
- spaCy - 兼容性函数
- spaCy - 容器
- Doc 类上下文管理器和属性
- spaCy - 容器 Token 类
- spaCy - Token 属性
- spaCy - 容器 Span 类
- spaCy - Span 类属性
- spaCy - 容器 Lexeme 类
- 训练神经网络模型
- 更新神经网络模型
- spaCy 有用资源
- spaCy - 快速指南
- spaCy - 有用资源
- spaCy - 讨论
spaCy - 训练神经网络模型
在本章中,让我们学习如何在 spaCy 中训练神经网络模型。
在这里,我们将了解如何更新 spaCy 的统计模型以根据我们的用例对其进行定制。例如,预测在线评论中的新实体类型。要进行自定义,我们首先需要训练自己的模型。
训练步骤
让我们了解在 spaCy 中训练神经网络模型的步骤。
步骤 1 - **初始化** - 如果您不使用预训练模型,那么首先,我们需要使用 **nlp.begin_training** 随机初始化模型权重。
步骤 2 - **预测** - 接下来,我们需要使用当前权重预测一些示例。可以通过调用 **nlp.updates** 来完成。
步骤 3 - **比较** - 现在,模型将检查预测结果与真实标签是否一致。
步骤 4 - **计算** - 比较之后,在这里,我们将决定如何更改权重以便下次进行更好的预测。
步骤 5 - **更新** - 最后,对当前权重进行微小更改,并选择下一批示例。继续对您获取的每一批示例调用 **nlp.updates**。
现在让我们借助下图了解这些步骤 -
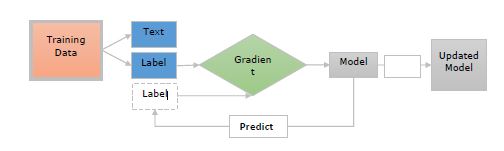
这里 -
**训练数据** - 训练数据是示例及其注释。这些是我们想要更新模型的示例。
**文本** - 它表示模型应该预测其标签的输入文本。它可以是句子、段落或更长的文档。
**标签** - 标签实际上是我们希望模型预测的内容。例如,它可以是文本类别。
**梯度** - 梯度是指我们应该如何更改权重以减少误差。在将预测标签与真实标签进行比较后,将计算梯度。
训练实体识别器
首先,实体识别器将获取文档并预测短语及其标签。
这意味着训练数据需要包含以下内容 -
文本。
它们包含的实体。
实体标签。
每个标记只能是某个实体的一部分。因此,实体不能重叠。
我们还应该在实体及其周围上下文中对其进行训练,因为实体识别器会在上下文中预测实体。
这可以通过向模型显示文本和字符偏移列表来完成。
例如,在下面给出的代码中,phone 是一个从字符 0 开始到字符 8 结束的小工具。
("Phone is coming", {"entities": [(0, 8, "GADGET")]})
在这里,模型还应该学习除实体之外的其他单词。
考虑另一个训练实体识别器的示例,如下所示 -
("I need a new phone! Any suggestions?", {"entities": []})
主要目标应该是教会我们的实体识别器模型,即使在训练数据中不存在,也能在类似上下文中识别新的实体。
spaCy 的训练循环
一些库为我们提供了负责模型训练的方法,但另一方面,spaCy 为我们提供了对训练循环的完全控制。
训练循环可以定义为一系列步骤,这些步骤用于更新和训练模型。
训练循环步骤
让我们看看训练循环的步骤,如下所示 -
**步骤 1** - **循环** - 第一步是循环,我们通常需要执行多次,以便模型从中学习。例如,如果您想训练模型 20 次迭代,则需要循环 20 次。
**步骤 2** - **随机洗牌** - 第二步是随机洗牌训练数据。我们需要对每次迭代的数据进行随机洗牌。这有助于防止模型陷入次优解。
**步骤 3** - **划分** – 然后将数据分成批次。在这里,我们将训练数据分成小批次。这有助于提高梯度估计的可读性。
**步骤 4** - **更新** - 下一步是更新每个步骤的模型。现在,我们需要更新模型并重新开始循环,直到达到最后一次迭代。
**步骤 5** - **保存** - 最后,我们可以保存此训练后的模型并在 spaCy 中使用它。
示例
以下是 spaCy 的训练循环示例 -
DATA = [
("How to order the Phone X", {"entities": [(20, 28, "GADGET")]})
]
# Step1: Loop for 10 iterations
for i in range(10):
# Step2: Shuffling the training data
random.shuffle(DATA)
# Step3: Creating batches and iterating over them
for batch in spacy.util.minibatch(DATA):
# Step4: Splitting the batch in texts and annotations
texts = [text for text, annotation in batch]
annotations = [annotation for text, annotation in batch]
# Step5: Updating the model
nlp.update(texts, annotations)
# Step6: Saving the model
nlp.to_disk(path_to_model)