- spaCy 教程
- spaCy - 首页
- spaCy - 简介
- spaCy - 入门
- spaCy - 模型和语言
- spaCy - 架构
- spaCy - 命令行助手
- spaCy - 顶级函数
- spaCy - 可视化函数
- spaCy - 实用函数
- spaCy - 兼容性函数
- spaCy - 容器
- Doc 类上下文管理器和属性
- spaCy - 容器 Token 类
- spaCy - Token 属性
- spaCy - 容器 Span 类
- spaCy - Span 类属性
- spaCy - 容器 Lexeme 类
- 训练神经网络模型
- 更新神经网络模型
- spaCy 有用资源
- spaCy 快速指南
- spaCy - 有用资源
- spaCy - 讨论
spaCy 快速指南
spaCy - 简介
在本章中,我们将了解 spaCy 的功能、扩展和可视化工具。此外,还提供了功能比较,帮助读者分析 spaCy 提供的功能与自然语言工具包 (NLTK) 和 coreNLP 的对比。这里,NLP 指的是自然语言处理。
什么是 spaCy?
spaCy 由软件开发者Matthew Honnibal 和Ines Montani 开发,是一个用于高级 NLP 的开源软件库。它使用Python 和Cython(Python 的 C 扩展,主要旨在为 Python 语言程序提供类似 C 的性能)编写。
spaCy 是一个相对较新的框架,但也是最强大和最先进的库之一,用于实现 NLP。
特性
下面解释了 spaCy 一些使其流行的特性:
快速 - spaCy 特别设计为尽可能快。
准确 - spaCy 实现的标记依存句法分析器使其成为同类中最准确的框架之一(在最佳可用范围内的 1% 之内)。
内置功能 - spaCy 内置的功能如下:
索引保留分词。
“Alpha 分词”支持 50 多种语言。
词性标注。
预训练词向量。
内置简单美观的命名实体和句法可视化工具。
文本分类。
可扩展 - 可以轻松地将 spaCy 与其他现有工具(如 TensorFlow、Gensim、scikit-Learn 等)一起使用。
深度学习集成 - 它拥有 Thinc——一个为 NLP 任务设计的深度学习框架。
扩展和可视化工具
下面列出了一些 spaCy 附带的易于使用的扩展和可视化工具,它们是免费的开源库:
Thinc - 它是一个针对中央处理器 (CPU) 使用优化的机器学习 (ML) 库。它也专为深度学习、文本输入和 NLP 任务而设计。
sense2vec - 此库用于计算词语相似度。它基于 Word2vec。
displaCy - 它是一个开源的依存句法树可视化工具。它使用 JavaScript、CSS(层叠样式表)和 SVG(可缩放矢量图形)构建。
displaCy ENT - 它是 spaCy 附带的内置命名实体可视化工具。它使用 JavaScript 和 CSS 构建。它允许用户在浏览器中检查其模型的预测。
功能比较
下表显示了 spaCy、NLTK 和 CoreNLP 提供的功能的比较:
| 特性 | spaCy | NLTK | CoreNLP |
|---|---|---|---|
| Python API | 是 | 是 | 否 |
| 易于安装 | 是 | 是 | 是 |
| 多语言支持 | 是 | 是 | 是 |
| 集成词向量 | 是 | 否 | 否 |
| 分词 | 是 | 是 | 是 |
| 词性标注 | 是 | 是 | 是 |
| 句子分割 | 是 | 是 | 是 |
| 依存句法分析 | 是 | 否 | 是 |
| 实体识别 | 是 | 是 | 是 |
| 实体链接 | 是 | 否 | 否 |
| 共指消解 | 否 | 否 | 是 |
基准测试
spaCy 拥有世界上最快的句法分析器,并且具有最高的准确性(在最佳可用范围内的 1% 之内)。
下表显示了 spaCy 的基准测试:
| 系统 | 年份 | 语言 | 准确性 |
|---|---|---|---|
| spaCy v2.x | 2017 | Python 和 Cython | 92.6 |
| spaCy v1.x | 2015 | Python 和 Cython | 91.8 |
| ClearNLP | 2015 | Java | 91.7 |
| CoreNLP | 2015 | Java | 89.6 |
| MATE | 2015 | Java | 92.5 |
| Turbo | 2015 | C++ | 92.4 |
spaCy - 入门
本章将帮助读者了解 spaCy 的最新版本。此外,读者还可以了解该版本的新功能和改进、其兼容性以及如何安装 spaCy。
最新版本
spaCy v3.0 是最新的版本,可作为夜间发布版本获得。这是通过名为spacy-nightly 的单独渠道发布的 spaCy 的实验性和 alpha 版本。它反映了“未来的 spaCy”,不能用于生产环境。
为了防止潜在的冲突,请尝试使用一个新的虚拟环境。
可以使用以下给出的 pip 命令安装它:
pip install spacy-nightly --pre
新功能和改进
下面解释了 spaCy 最新版本中的新功能和改进:
基于 Transformer 的管道
它具有全新的基于 Transformer 的管道,并支持多任务学习。这些新的基于 Transformer 的管道使其成为最准确的框架之一(在最佳可用范围内的 1% 之内)。
可以访问数千个预训练模型以用于管道,因为 spaCy 的 Transformer 支持与其他框架(如 PyTorch 和 HuggingFace transformers)互操作。
新的训练工作流程和配置系统
spaCy v3.0 提供了训练运行的单个配置文件。
没有隐藏的默认值,因此可以轻松地重现实验并跟踪更改。
使用任何 ML 框架的自定义模型
spaCy v3.0 的新配置系统使我们能够轻松地自定义神经网络 (NN) 模型并通过 ML 库Thinc 实现我们自己的架构。
管理端到端工作流程和项目
spaCy 项目允许我们管理和共享各种用例和领域的端到端工作流程。
它还允许我们组织训练、打包和服务我们的自定义管道。
另一方面,我们还可以与其他数据科学和 ML 工具(如DVC(数据版本控制)、Prodigy、Streamlit、FastAPI、Ray 等)集成。
使用 Ray 进行并行训练和分布式计算
为了加快训练过程,我们可以使用 Ray(一个快速简单的构建和运行分布式应用程序的框架)在一个或多个远程机器上训练 spaCy。
新的内置管道组件
这是 spaCy 的新版本,包含以下可训练和基于规则的组件,可以添加到管道中。
这些组件如下:
SentenceRecognizer
Morphologizer
Lemmatizer
AttributeRuler
Transformer
TrainablePipe
新的管道组件 API
此 SpaCy v3.0 为我们提供了新的和改进的管道组件 API 和装饰器,这使得定义、配置、重用、训练和分析更加轻松和便捷。
依存匹配
SpaCy v3.0 为我们提供了新的DependencyMatcher,它允许我们在依存句法分析器中匹配模式。它使用Semgrex 运算符。
新的和更新的文档
它具有新的和更新的文档,包括:
关于嵌入、转换器和迁移学习的新使用指南。
关于训练管道和模型的指南。
有关新的 spaCy 项目的详细信息以及关于自定义管道组件的更新使用文档。
新的插图和新的 API 参考页面,记录了 spaCy 的 ML 模型架构和预计的数据格式。
兼容性
spaCy 可以在所有主要操作系统(如 Windows、macOS/OS X 和 Unix/Linux)上运行。它与 64 位 CPython 2.7/3.5+ 版本兼容。
安装 spaCy
下面解释了安装 spaCy 的不同选项:
使用包管理器
spaCy 的最新发布版本可在两种包管理器pip 和conda 上获得。让我们看看如何使用它们来安装 spaCy:
pip - 要使用 pip 安装 Spacy,可以使用以下命令:
pip install -U spacy
为了避免修改系统状态,建议在虚拟环境中安装 spacy 包,如下所示:
python -m venv .env source .env/bin/activate pip install spacy
conda - 要通过 conda-forge 安装 spaCy,可以使用以下命令:
conda install -c conda-forge spacy
从源代码安装
还可以通过从GitHub 存储库克隆 spaCy 并从源代码构建它来安装 spaCy。这是对代码库进行更改的最常见方法。
但是,为此,需要一个 Python 发行版,其中包括以下内容:
头文件
编译器
pip
virtualenv
git
使用以下命令:
首先,更新 pip,如下所示:
python -m pip install -U pip
现在,克隆 spaCy,使用以下命令
git clone https://github.com/explosion/spaCy
现在,需要导航到目录,使用以下命令:
cd spaCy
接下来,需要在 .env 中创建环境,如下所示:
python -m venv .env
现在,激活上面创建的虚拟环境。
source .env/bin/activate
接下来,需要将 Python 路径设置为 spaCy 目录,如下所示:
export PYTHONPATH=`pwd`
现在,安装所有需求,如下所示:
pip install -r requirements.txt
最后,编译 spaCy:
python setup.py build_ext --inplace
Ubuntu
使用以下命令在 Ubuntu 操作系统 (OS) 中安装系统级依赖项:
sudo apt-get install build-essential python-dev git
macOS/OS X
实际上,macOS 和 OS X 预装了 Python 和 git。因此,只需要安装最新版本的 XCode,包括 CLT(命令行工具)。
Windows
在下表中,给出了用于 Python 解释器官方发行版的 Visual C++ Build Tools 或 Visual Studio Express 版本。根据需要选择一个并安装:
| 发行版 | 版本 |
|---|---|
| Python 2.7 | Visual Studio 2008 |
| Python 3.4 | Visual Studio 2010 |
| Python 3.5+ | Visual Studio 2015 |
升级 spaCy
升级 spaCy 时应牢记以下几点:
从干净的虚拟环境开始。
要将 spaCy 升级到新的主要版本,必须安装最新的兼容模型。
虚拟环境中不应存在旧的快捷方式链接或不兼容的模型包。
如果您训练了自己的模型,则训练和运行时输入必须匹配,即也必须使用较新版本重新训练模型。
spaCy v2.0 及更高版本提供了一个validate 命令,允许用户验证所有已安装的模型是否与已安装的 spaCy 版本兼容。
如果存在任何不兼容的模型,validate 命令将打印提示和安装说明。此命令还可以检测在各种虚拟环境中创建的模型链接是否不同步。
可以使用以下命令运行 validate 命令:
pip install -U spacy python -m spacy validate
在上述命令中,python -m 用于确保正在执行正确的 spaCy 版本。
使用 GPU 运行 spaCy
spaCy v2.0 及更高版本附带可以在Thinc 中实现的神经网络 (NN) 模型。如果要使用图形处理单元 (GPU) 支持运行 spaCy,请使用 Chainer 的 CuPy 模块的工作。此模块为 GPU 数组提供了一个与 numpy 兼容的接口。
可以通过指定以下内容在 GPU 上安装 spaCy:
spaCy[cuda]
spaCy[cuda90]
spaCy[cuda91]
spaCy[cuda92]
spaCy[cuda100]
spaCy[cuda101]
spaCy[cuda102]
另一方面,如果知道cuda 版本,则显式说明符允许安装cupy。这将节省编译时间。
使用以下命令进行安装:
pip install -U spacy[cuda92]
在启用 GPU 的安装后,可以通过调用 **spacy.prefer_gpu** 或 **spacy.require_gpu** 来激活它,如下所示:
import spacy
spacy.prefer_gpu()
nlp_model = spacy.load("en_core_web_sm")
spaCy - 模型和语言
让我们了解一下 spaCy 支持的语言及其统计模型。
语言支持
目前,spaCy 支持以下语言:
| 语言 | 代码 |
|---|---|
| 中文 | zh |
| 丹麦语 | da |
| 荷兰语 | nl |
| 英语 | en |
| 法语 | fr |
| 德语 | de |
| 希腊语 | el |
| 意大利语 | it |
| 日语 | ja |
| 立陶宛语 | lt |
| 多语言 | xx |
| 挪威语(书面挪威语) | nb |
| 波兰语 | pl |
| 葡萄牙语 | pt |
| 罗马尼亚语 | ro |
| 西班牙语 | es |
| 南非荷兰语 | af |
| 阿尔巴尼亚语 | sq |
| 阿拉伯语 | ar |
| 亚美尼亚语 | hy |
| 巴斯克语 | eu |
| 孟加拉语 | bn |
| 保加利亚语 | bg |
| 加泰罗尼亚语 | ca |
| 克罗地亚语 | hr |
| 捷克语 | cs |
| 爱沙尼亚语 | et |
| 芬兰语 | fi |
| 古吉拉特语 | gu |
| 希伯来语 | he |
| 印地语 | hi |
| 匈牙利语 | hu |
| 冰岛语 | is |
| 印尼语 | id |
| 爱尔兰语 | ga |
| 卡纳达语 | kn |
| 韩语 | ko |
| 拉脱维亚语 | lv |
| 利古里亚语 | lij |
| 卢森堡语 | lb |
| 马其顿语 | mk |
| 马拉雅拉姆语 | ml |
| 马拉地语 | mr |
| 尼泊尔语 | ne |
| 波斯语 | fa |
| 俄语 | ru |
| 塞尔维亚语 | sr |
| 僧伽罗语 | si |
| 斯洛伐克语 | sk |
| 斯洛文尼亚语 | sl |
| 瑞典语 | sv |
| 塔加拉语 | tl |
| 泰米尔语 | ta |
| 鞑靼语 | tt |
| 泰卢固语 | te |
| 泰语 | th |
| 土耳其语 | tr |
| 乌克兰语 | uk |
| 乌尔都语 | ur |
| 越南语 | vi |
| 约鲁巴语 | yo |
spaCy 的统计模型
众所周知,spaCy 的模型可以作为 Python 包安装,这意味着就像任何其他模块一样,它们是应用程序的一部分。这些模块可以进行版本控制,并在 **requirement.txt** 文件中定义。
安装 spaCy 的统计模型
以下是 spaCy 统计模型的安装说明:
使用下载命令
使用 spaCy 的 **download** 命令是下载模型最简单的方法之一,因为它会自动查找与 spaCy 版本兼容的最佳匹配模型。
您可以通过以下方式使用 **download** 命令:
以下命令将下载与您的 spaCy 版本最匹配的特定模型版本:
python -m spacy download en_core_web_sm
以下命令将下载最匹配的默认模型,并创建一个快捷链接:
python -m spacy download en
以下命令将下载精确的模型版本,并且不会创建任何快捷链接:
python -m spacy download en_core_web_sm-2.2.0 --direct
通过 pip
我们还可以通过 pip 直接下载和安装模型。为此,您需要使用 **pip install** 以及存档文件的 URL 或本地路径。如果您没有模型的直接链接,请访问模型版本,然后从那里复制。
例如:
使用 pip 和外部 URL 安装模型的命令如下:
pip install https://github.com/explosion/spacy-models/releases/download/en_core_web_sm-2.2.0/en_core_web_sm-2.2.0.tar.gz
使用 pip 和本地文件安装模型的命令如下:
pip install /Users/you/en_core_web_sm-2.2.0.tar.gz
以上命令会将特定模型安装到您的 site-packages 目录中。完成后,我们可以使用 **spacy.load()** 通过其包名称加载它。
手动
您还可以手动下载数据并将其放置在您选择的自定义目录中。
使用以下任何一种方法手动下载数据:
通过浏览器从最新版本下载模型。
您可以使用存档文件的 URL(统一资源定位符)配置自己的下载脚本。
下载完成后,我们可以将模型包目录放置在本地文件系统的任何位置。现在,要将其与 spaCy 一起使用,我们可以为数据目录创建一个快捷链接。
在 spaCy 中使用模型
这里解释了如何在 spaCy 中使用模型。
使用自定义快捷链接
我们可以手动下载所有 spaCy 模型(如上所述),并将它们放入我们的本地目录中。现在,每当 spaCy 项目需要任何模型时,我们都可以创建一个快捷链接,以便 spaCy 可以从那里加载模型。这样,您就不会遇到重复数据的问题。
为此,spaCy 为我们提供了 link 命令,可以使用如下方式:
python -m spacy link [package name or path] [shortcut] [--force]
在以上命令中,第一个参数是包名称或本地路径。如果您已通过 pip 安装模型,则可以在此处使用包名称。或者,您有一个指向模型包的本地路径。
第二个参数是内部名称。这是您要为模型使用的名称。以上命令中的 –-**force** 标志将覆盖任何现有链接。
以下给出了这两种情况的示例。
示例
以下是设置快捷链接以将已安装的包加载为“**default_model**”的示例:
python -m spacy link en_core_web_md en_default
以下是设置快捷链接以将本地模型加载为“**my_default_model**”的示例:
python -m spacy link /Users/Leekha/model my_default_en
作为模块导入
我们还可以**导入**已安装的模型,该模型可以调用其 **load()** 方法,不带任何参数,如下所示:
import spaCy
import en_core_web_sm
nlp_example = en_core_web_sm.load()
my_doc = nlp_example("This is my first example.")
my_doc
输出
This is my first example.
使用自己的模型
您还可以使用您训练的模型。为此,您需要使用 **Language.to_disk()** 方法保存训练模型的状态。为了便于部署,您还可以将其包装为 Python 包。
命名约定
通常,**[lang_[name]]** 的命名约定是 spaCy 期望所有模型包遵循的一种约定。
spaCy 模型的名称可以进一步细分为以下三个组成部分:
**类型** - 它反映了模型的功能。例如,**core** 用于具有词汇、语法、实体的通用模型。类似地,**depent** 用于仅包含词汇、语法和实体。
**类型** - 它显示了模型训练的文本类型。例如,**web** 或 **news**。
**大小** - 顾名思义,它是模型大小的指示器。例如,**sm**(小型),**md**(中型)或 **lg**(大型)。
模型版本控制
模型版本控制反映以下内容:
与 spaCy 的兼容性。
主要和次要模型版本。
例如,模型版本 r.s.t 转换为以下内容:
**r** - **spaCy 主版本。**例如,spaCy v1.x 为 1。
**s** - **模型主版本。**它限制用户使用相同的代码加载不同的主版本。
**t** - **模型次要版本。**它显示相同的模型结构,但参数值不同。例如,在不同数据上训练了不同迭代次数。
spaCy - 架构
本章介绍了 spaCy 中的数据结构,并解释了对象及其作用。
数据结构
spaCy 中的核心数据结构如下:
**Doc** - 这是 spaCy 架构中最重要的对象之一,它拥有标记序列及其所有注释。
**Vocab** - spaCy 核心数据结构的另一个重要对象是 Vocab。它拥有一个查找表集,使文档之间可以共享常用信息。
spaCy 的数据结构有助于集中字符串、词向量和词法属性,通过避免存储数据的多个副本来节省内存。
对象及其作用
以下是 spaCy 中的对象及其作用和示例:
Span
它是 **Doc** 对象的切片,我们上面已经讨论过。我们可以使用以下命令从切片创建 Span 对象:
doc[start : end]
示例
以下是 Span 的示例:
import spacy
import en_core_web_sm
nlp_example = en_core_web_sm.load()
my_doc = nlp_example("This is my first example.")
span = my_doc[1:6]
span
输出
is my first example.
Token
顾名思义,它表示单个标记,例如单词、标点符号、空格、符号等。
示例
以下是 Token 的示例:
import spacy
import en_core_web_sm
nlp_example = en_core_web_sm.load()
my_doc = nlp_example("This is my first example.")
token = my_doc[4]
token
输出
example
Tokenizer
顾名思义,Tokenizer 类将文本分割成单词、标点符号等。
示例
此示例将创建一个仅包含英语词汇表的空 Tokenizer:
from spacy.tokenizer import Tokenizer from spacy.lang.en import English nlp_lang = English() blank_tokenizer = Tokenizer(nlp_lang.vocab) blank_tokenizer
输出
<spacy.tokenizer.Tokenizer at 0x26506efc480>
语言
这是一个文本处理管道,我们需要在每个进程中加载一次,并在应用程序中传递实例。当我们调用 **spacy.load()** 方法时,将创建此类。
它包含以下内容:
共享词汇表
语言数据
从模型包加载的可选模型数据
包含诸如标记器或解析器等组件的处理管道。
示例
此语言示例将初始化英语 Language 对象
from spacy.vocab import Vocab from spacy.language import Language nlp_lang = Language(Vocab()) from spacy.lang.en import English nlp_lang = English() nlp_lang
输出
运行代码时,您将看到以下输出:
<spacy.lang.en.English at 0x26503773cf8>
spaCy - 命令行助手
本章提供了有关 spaCy 中使用的命令行帮助程序的信息。
为什么使用命令行界面?
spaCy v1.7.0 及更高版本带有新的命令行帮助程序。它用于下载和链接模型。您还可以使用它来显示有用的调试信息。简而言之,命令行帮助程序用于下载、训练、打包模型以及调试 spaCy。
检查可用命令
您可以使用 **spacy - -help** 命令检查可用命令。
以下是检查 spaCy 中可用命令的示例:
示例
C:\Users\Leekha>python -m spacy --help
输出
输出显示可用命令。
Available commands download, link, info, train, pretrain, debug-data, evaluate, convert, package, init-model, profile, validate
可用命令
以下是 spaCy 中可用的命令及其说明。
| 序号 | 命令及说明 |
|---|---|
| 1 | Download 下载 spaCy 模型。 |
| 2 | Link 创建模型的快捷链接。 |
| 3 | Info 打印信息。 |
| 4 | Validate 检查已安装模型的兼容性。 |
| 5 | Convert 将文件转换为 spaCy 的 JSON 格式。 |
| 6 | Pretrain 预训练管道组件的“标记到向量(tok2vec)”层。 |
| 7 | Init-model 从原始数据创建新的模型目录。 |
| 8 | Evaluate 评估模型的准确性和速度。 |
| 9 | Package 从现有的模型数据目录生成模型 Python 包。 |
| 10 | Debug-data 分析、调试和验证训练和开发数据。 |
| 11 | Train 训练模型。 |
spaCy - 顶级函数
这里,我们将讨论 spaCy 中使用的一些顶级函数。以下是这些函数及其说明:
| 序号 | 命令及说明 |
|---|---|
| 1 | spacy.load() 加载模型。 |
| 2 | spacy.blank() 创建空白模型。 |
| 3 | spacy.info() 提供有关 spaCy 中的安装、模型和本地设置的信息。 |
| 4 | spacy.explain() 给出描述。 |
| 5 | spacy.prefer_gpu() 分配数据并在 GPU 上执行操作。 |
| 6 | spacy.require_gpu() 分配数据并在 GPU 上执行操作。 |
spacy.load()
顾名思义,此 spacy 函数将通过以下方式加载模型:
其快捷链接。
已安装模型包的名称。
Unicode路径。
路径类对象。
spaCy将尝试按照以下顺序解析加载参数:
如果从快捷链接或包名称加载模型,spaCy将假设它是一个Python包,并调用模型自己的load()方法。
另一方面,如果从路径加载模型,spacy将假设它是一个数据目录,因此会初始化Language类。
使用此函数后,数据将通过Language.from_disk加载。
参数
下表解释了它的参数:
| 名称 | 类型 | 描述 |
|---|---|---|
| name | unicode / Path | 它是要加载的模型的快捷链接、包名称或路径。 |
| disable | 列表 | 它表示要禁用的管道组件的名称。 |
示例
在以下示例中,spacy.load()函数使用快捷链接、包、Unicode路径和pathlib路径加载模型:
以下是使用快捷链接加载模型的spacy.load()函数的命令:
nlp_model = spacy.load("en")
以下是使用包加载模型的spacy.load()函数的命令:
nlp_model = spacy.load("en_core_web_sm")
以下是使用Unicode路径加载模型的spacy.load()函数的命令:
nlp_model = spacy.load("/path/to/en")
以下是使用pathlib路径加载模型的spacy.load()函数的命令:
nlp_model = spacy.load(Path("/path/to/en"))
以下是使用所有参数加载模型的spacy.load()函数的命令:
nlp_model = spacy.load("en_core_web_sm", disable=["parser", "tagger"])
spacy.blank()
它是spacy.blank()函数的孪生兄弟,创建一个给定语言类的空白模型。
参数
下表解释了它的参数:
| 名称 | 类型 | 描述 |
|---|---|---|
| name | unicode | 它表示要加载的语言类的ISO代码。 |
| disable | list | 此参数表示要禁用的管道组件的名称。 |
示例
在以下示例中,spacy.blank()函数用于创建“en”语言类的空白模型。
nlp_model_en = spacy.blank("en")
spacy.info()
与info命令类似,spacy.info()函数提供了有关spaCy内部安装、模型和本地设置的信息。
如果要将模型元数据作为字典获取,可以使用已加载模型的nlp对象上的meta属性。例如,nlp.meta。
参数
下表解释了它的参数:
| 名称 | 类型 | 描述 |
|---|---|---|
| model | unicode | 它是模型的快捷链接、包名称或路径。 |
| markdown | 布尔值 | 此参数将信息打印为Markdown格式。 |
示例
下面给出一个示例:
spacy.info()
spacy.info("en")
spacy.info("de", markdown=True)
spacy.explain()
此函数将为以下内容提供描述:
词性标签
依存关系标签
实体类型
参数
下表解释了它的参数:
| 名称 | 类型 | 描述 |
|---|---|---|
| term | unicode | 它是我们想要解释的术语。 |
示例
下面给出了spacy.explain()函数用法的示例:
import spacy
import en_core_web_sm
nlp= en_core_web_sm.load()
spacy.explain("NORP")
doc = nlp("Hello TutorialsPoint")
for word in doc:
print(word.text, word.tag_, spacy.explain(word.tag_))
输出
Hello UH interjection TutorialsPoint NNP noun, proper singular
spacy.prefer_gpu()
如果您有GPU,此函数将分配数据并在GPU上执行操作。但是,如果数据和操作已在CPU上可用,则不会将其移动到GPU。它将返回一个布尔输出,指示GPU是否被激活。
示例
下面给出了spacy.prefer_gpu()用法的示例:
import spacy
activated = spacy.prefer_gpu()
nlp = spacy.load("en_core_web_sm")
spacy.require_gpu()
此函数在2.0.14版本中引入,它也将分配数据并在GPU上执行操作。如果不存在GPU,它将引发错误。如果数据和操作已在CPU上可用,则不会将其移动到GPU。
建议在导入spacy之后以及加载任何模型之前立即调用此函数。它也将返回布尔类型输出。
示例
以下是spacy.require_gpu()函数用法的示例:
import spacy
spacy.require_gpu()
nlp = spacy.load("en_core_web_sm")
spaCy - 可视化函数
可视化函数主要用于在浏览器或笔记本中可视化依存关系以及命名实体。从spacy 2.0版本开始,有两个流行的可视化工具,即displaCy和displaCyENT。
它们都是spacy内置可视化套件的一部分。通过使用此可视化套件(即displaCy),我们可以可视化文本中的依存关系解析器或命名实体。
displaCy()
在这里,我们将学习有关displayCy依存关系可视化工具和displayCy实体可视化工具的信息。
可视化依存关系解析
displaCy依存关系可视化工具(dep)将显示词性(POS)标签和句法依存关系。
示例
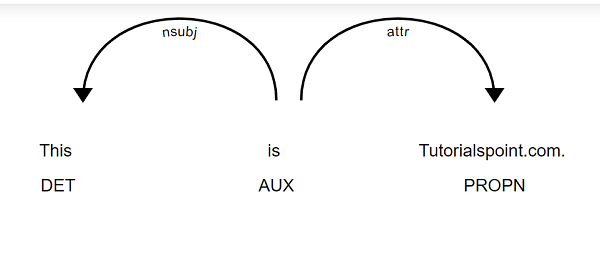
下面给出了使用displaCy()依存关系可视化工具可视化依存关系解析的示例:
import spacy
from spacy import displacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("This is Tutorialspoint.com.")
displacy.serve(doc, style="dep")
输出
这将产生以下输出:
我们还可以指定一个设置字典来自定义布局。它将在参数option下(我们稍后将详细讨论)。
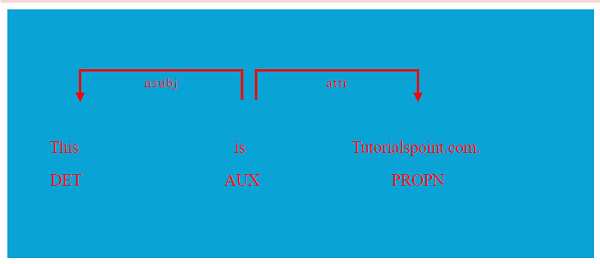
带有选项的示例如下所示:
import spacy
from spacy import displacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("This is Tutorialspoint.com.")
options = {"compact": True, "bg": "#09a3d5",
"color": "red", "font": "Source Sans Pro"}
displacy.serve(doc, style="dep", options=options)
输出
以下是输出:
可视化命名实体
displaCy实体可视化工具(ent)将突出显示文本中的命名实体及其标签。
示例
下面给出了使用displaCy实体可视化工具可视化命名实体的示例:
import spacy
from spacy import displacy
text = "When Sebastian Thrun started working on self-driving cars at Google in
2007, few people outside of the company took him seriously. But Google is
starting from behind. The company made a late push into hardware, and Apple's
Siri has clear leads in consumer adoption."
nlp = spacy.load("en_core_web_sm")
doc = nlp(text)
displacy.serve(doc, style="ent")
输出
以下是输出:

我们还可以指定一个设置字典来自定义布局。它将在参数option下(我们稍后将详细讨论)。
带有选项的示例如下所示:
import spacy
from spacy import displacy
text = "When Sebastian Thrun started working on self-driving cars at Google in
2007, few people outside of the company took him seriously. But Google is
starting from behind. The company made a late push into hardware, and Apple's
Siri has clear leads in consumer adoption."
nlp = spacy.load("en_core_web_sm")
doc = nlp(text)
colors = {"ORG": "linear-gradient(90deg, #aa9cfc, #fc9ce7)"}
options = {"ents": ["ORG"], "colors": colors}
displacy.serve(doc, style="ent", options=options)
输出
以下是输出:

displaCy()方法
从2.0版本开始,displaCy()函数有两个方法,即serve和render。让我们详细讨论它们。下表列出了这些方法及其相应的描述。
| 序号 | 方法和描述 |
|---|---|
| 1 | displayCy.serve 它将提供依存关系解析树。 |
| 2 | displayCy.render 它将呈现依存关系解析树。 |
displaCy.serve
此方法将提供依存关系解析树/命名实体可视化,以便在Web浏览器中查看。它将运行一个简单的Web浏览器。
参数
下表解释了它的参数:
| 名称 | 类型 | 描述 | 默认值 |
|---|---|---|---|
| 文档 | 列表、doc、Span | 它表示要可视化的文档。 | |
| 样式 | Unicode | 我们有两个可视化样式,即'dep'或'ent'。 | 默认值为'dep'。 |
| 页面 | 布尔值 | 它将标记呈现为完整的HTML页面。 | 默认值为true。 |
| minify | 布尔值 | 此参数将缩小HTML标记。 | 默认值为false。 |
| options | 字典 | 它表示可视化工具特定的选项。例如,颜色。 | {} |
| manual | 布尔值 | 此参数不会解析Doc,而是期望一个字典或字典列表。 | 默认值为false。 |
| 端口 | 整数 | 它是提供可视化的端口号。 | 5000 |
| 主机 | unicode | 它是提供可视化的主机号。 | '0.0.0.0' |
示例
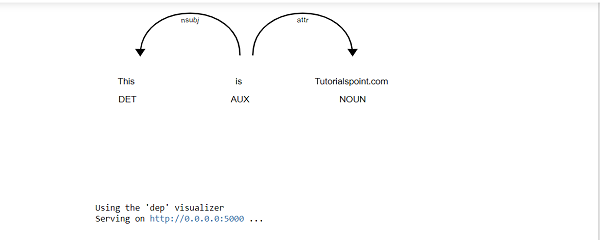
以下是displayCy.serve方法的示例:
import spacy
from spacy import displacy
nlp = spacy.load("en_core_web_sm")
doc1 = nlp("This is Tutorialspoint.com")
displacy.serve(doc1, style="dep")
输出
这将产生以下输出:
displaCy.render
此displaCy方法将呈现依存关系解析树或命名实体可视化。
参数
下表解释了它的参数:
| 名称 | 类型 | 描述 | 默认值 |
|---|---|---|---|
| 文档 | 列表、doc、Span | 它表示要可视化的文档。 | |
| 样式 | Unicode | 我们有两个可视化样式,即'dep'或'ent'。 | 默认值为'dep'。 |
| 页面 | 布尔值 | 它将标记呈现为完整的HTML页面。 | 默认值为false。 |
| minify | 布尔值 | 此参数将缩小HTML标记。 | 默认值为false。 |
| options | 字典 | 它表示可视化工具特定的选项。例如,颜色。 | {} |
| manual | 布尔值 | 此参数不会解析Doc,而是期望一个字典或字典列表。 | 默认值为false。 |
| jupyter | 布尔值 | 要返回准备好在笔记本中呈现的标记,此参数将显式启用或禁用Jupyter模式。如果我们不提供此参数,它将自动检测。 | 无 |
示例
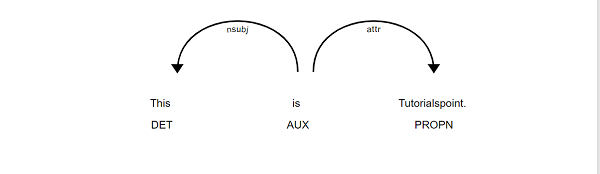
以下是displaCy.render方法的示例:
import spacy
from spacy import displacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("This is Tutorialspoint.")
html = displacy.render(doc, style="dep")
输出
可视化工具选项
dispaCy()函数的option参数允许我们为每个可视化工具(依存关系和命名实体可视化工具)指定其他设置。
依存关系可视化工具选项
下表解释了依存关系可视化工具选项:
| 名称 | 类型 | 描述 | 默认值 |
|---|---|---|---|
| fine_grained | 布尔值 | 如果要使用细粒度的词性标签(Token.tag_),而不是粗粒度的标签(Token.pos_),请将此参数的值设置为True。 | 默认值为False。 |
| add_lemma | 布尔值 | 在2.2.4版本中引入,此参数在标记文本下方单独一行打印词形。 | 默认值为False。 |
| collapse_punct | 布尔值 | 它将标点符号附加到标记上。 | 默认值为True。 |
| collapse_phrases | 布尔值 | 此参数将名词短语合并为一个标记。 | 默认值为False。 |
| compact | 布尔值 | 如果将此参数设置为true,则将获得使用占用空间较小的方括号箭头的“紧凑模式”。 | 默认值为False。 |
| color | unicode | 顾名思义,此参数用于文本颜色(十六进制、RGB或颜色名称)。 | '#000000' |
| bg | unicode | 顾名思义,此参数用于背景颜色(十六进制、RGB或颜色名称)。 | '#ffffff' |
| font | unicode | 它用于字体名称。 | 默认值为'Arial'。 |
| offset_x | 整数 | 此参数用于调整SVG左侧的间距(以像素为单位)。 | 此参数的默认值为50。 |
| arrow_stroke | 整数 | 此参数用于调整箭头路径的宽度(以像素为单位)。 | 此参数的默认值为2。 |
| arrow_width | 整数 | 此参数用于调整箭头头的宽度(以像素为单位)。 | 此参数的默认值为10/8(紧凑)。 |
| arrow_spacing | 整数 | 此参数用于调整箭头之间的间距(以像素为单位),以避免重叠。 | 此参数的默认值为20/12(紧凑)。 |
| word_spacing | 整数 | 此参数用于调整单词和弧线之间的垂直间距(以像素为单位)。 | 此参数的默认值为45。 |
| distance | 整数 | 此参数用于调整单词之间的距离(以像素为单位)。 | 此参数的默认值为175/150(紧凑)。 |
命名实体可视化工具选项
下表解释了命名实体可视化工具选项:
| 名称 | 类型 | 描述 | 默认值 |
|---|---|---|---|
| ents | list | 它表示要突出显示的实体类型。对于所有类型,请设置为None。 | 默认值为None。 |
| colors | 字典 | 顾名思义,它用于颜色覆盖。大写实体类型必须映射到颜色名称。 | {} |
spaCy - 实用函数
我们可以在spacy/util.py中找到一些spaCy的实用程序函数的小集合。让我们了解这些函数及其用法。
下表列出了实用程序函数及其描述。
| 序号 | 实用程序函数和描述 |
|---|---|
| 1 | Util.get_data_path 获取数据目录的路径。 |
| 2 | Util.set_data_path 设置数据目录的自定义路径。 |
| 3 | Util.get_lang_class 导入并加载Language类。 |
| 4 | Util.set_lang_class 设置自定义Language类。 |
| 5 | Util.lang_class_is_loaded 查找Language类是否已加载。 |
| 6 | Util.load_model 此函数将加载模型。 |
| 7 | Util.load_model_from_path 此函数将从数据目录路径加载模型。 |
| 8 | Util.load_model_from_init_py 这是一个辅助函数,用于模型包的load()方法中。 |
| 9 | Util.get_model_meta 从目录路径获取模型的meta.json。 |
| 10 | Util.update_exc 此函数将更新、验证和覆盖分词器期望。 |
| 11 | Util.is_in_jupyter 检查我们是否从Jupyter笔记本中运行spacy。 |
| 12 | Util.get_package_path 获取已安装的spacy包的路径。 |
| 13 | Util.is_package 验证模型包。 |
| 14 | Util.compile_prefix_regex 此函数将一系列前缀规则编译成正则表达式对象。 |
| 15 | Util.compile_suffix_regex 此函数将一系列后缀规则编译成正则表达式对象。 |
| 16 | Util.compile_infix_regex 此函数将一系列中缀规则编译成正则表达式对象。 |
| 17 | Util.compounding 此函数将生成一个无限的复合值序列。 |
| 18 | Util.decaying 此函数将生成一个无限的线性衰减值序列。 |
| 19 | Util.itershuffle 随机排列迭代器。 |
| 20 | Util.filter_spans 过滤一系列span对象并删除重复项。 |
spaCy - 兼容性函数
众所周知,所有Python代码都编写在Python 2和Python 3的交集中,这在Python中可能不是很好。但在Cython中,这很容易。
以下列出了spaCy中的兼容性函数及其描述:
| 兼容性函数 | 描述 |
|---|---|
| Spacy.compat() | 处理Python或平台兼容性。 |
| compat.is_config() | 检查Python版本和操作系统(OS)的特定配置是否与用户的设置匹配。 |
Spacy.compat()
此函数包含所有处理Python或平台兼容性的逻辑。它与其他内置函数的区别在于以下划线结尾。例如,unicode_。
以下表格中给出了一些示例:
| 名称 | PYTHON 2 | PYTHON 3 |
|---|---|---|
| compat.bytes_ | str | bytes |
| compat.unicode_ | unicode | str |
| compat.basestring_ | basestring | str |
| compat.input_ | raw_input | input |
| compat.path2str | str(path) with .decode('utf8') | str(path) |
示例
以下是spacy.compat()函数的示例:
import spacy
from spacy.compat import unicode_
compat_unicode = unicode_("This is Tutorialspoint")
compat_unicode
输出
执行后,您将收到以下输出 -
'This is Tutorialspoint'
compat.is_config()
它是一个函数,用于检查 Python 版本和操作系统 (OS) 的特定配置是否与用户的设置匹配。此函数主要用于显示目标错误消息。
参数
下表解释了它的参数:
| 名称 | 类型 | 描述 |
|---|---|---|
| python2 | 布尔值 | spaCy 是否使用 Python 2.x 执行。 |
| python3 | 布尔值 | spaCy 是否使用 Python 3.x 执行。 |
| windows | 布尔值 | spaCy 是否在 Windows 上执行。 |
| linux | 布尔值 | spaCy 是否在 Linux 上执行。 |
| OS X | 布尔值 | spaCy 是否在 OS X 上执行。 |
示例
compat.is_config() 函数的示例如下 -
import spacy
from spacy.compat import is_config
if is_config(python3=True, windows=True):
print("Spacy is executing on Python 3 on Windows.")
输出
执行后,您将收到以下输出 -
Spacy is executing on Python 3 on Windows.
spaCy - 容器
在本章中,我们将学习 spaCy 的容器。让我们首先了解包含 spaCy 容器的类。
类
我们有四个类包含 spaCy 的容器 -
Doc
Doc 是用于访问语言注释的容器,它是 token 对象的序列。借助 Doc 类,我们可以访问句子以及命名实体。
我们还可以将注释导出到 numpy 数组并序列化为压缩二进制字符串。Doc 对象保存一个 TokenC 结构体数组,而 Token 和 Span 对象只能查看此数组,不能保存任何数据。
Token
顾名思义,它表示单个标记,例如单词、标点符号、空格、符号等。
Span
它是我们上面讨论过的 Doc 对象的一个切片。
Lexeme
它可以定义为词汇表中的一个条目。与单词 token 相反,Lexeme 没有字符串上下文。它是一个词性,因此它没有任何词性 (Part-of-Speech) 标签、依赖关系解析或词形。
现在,让我们详细讨论所有四个类 -
Doc 类
下面解释了 Doc 类中使用的参数、序列化字段和方法 -
参数
下表解释了它的参数:
| 名称 | 类型 | 描述 |
|---|---|---|
| text | unicode | 此属性表示文档文本(Unicode)。 |
| mem | Pool | 顾名思义,此属性用于文档的本地内存堆,用于它拥有的所有 C 数据。 |
| vocab | Vocab | 它存储所有词汇类型。 |
| tensor | ndarray | 在 2.0 版中引入,它是密集向量表示的容器。 |
| cats | 字典 | 在 2.0 版中引入,此属性将标签映射到应用于文档的类别的分数。请注意,标签是字符串,分数应该是浮点值。 |
| user_data | - | 它表示一个通用存储区域,主要用于用户自定义数据。 |
| lang | 整数 | 在 2.1 版中引入,它表示文档词汇表的语言。 |
| lang_ | unicode | 在 2.1 版中引入,它表示文档词汇表的语言。 |
| is_tagged | 布尔值 | 它是一个标志,指示文档是否已被词性标注。如果 Doc 为空,它将返回 True。 |
| is_parsed | 布尔值 | 它是一个标志,指示文档是否已被句法分析。如果 Doc 为空,它将返回 True。 |
| is_sentenced | 布尔值 | 它是一个标志,指示句子边界是否已应用于文档。如果 Doc 为空,它将返回 True。 |
| is_nered | 布尔值 | 此属性在 2.1 版中引入。它是一个标志,指示命名实体是否已设置。如果 Doc 为空,它将返回 True。如果任何 token 设置了实体标签,它也将返回 True。 |
| sentiment | float | 它将以浮点数返回文档的积极/消极分数(如果可用)。 |
| user_hooks | 字典 | 此属性是一个字典,允许自定义 Doc 的属性。 |
| user_token_hooks | 字典 | 此属性是一个字典,允许自定义 Token 子元素的属性。 |
| user_span_hooks | 字典 | 此属性是一个字典,允许自定义 Span 子元素的属性。 |
| _ | Underscore | 它表示用户空间,用于添加自定义属性扩展。 |
序列化字段
在序列化过程中,为了恢复对象的各个方面,spacy 将导出多个数据字段。我们还可以通过传递 exclude 参数来排除序列化中的数据字段。
下表解释了序列化字段 -
| 序号 | 名称和描述 |
|---|---|
| 1 | Text 它表示 Doc.text 属性的值。 |
| 2 | Sentiment 它表示 Doc.sentiment 属性的值。 |
| 3 | Tensor 它表示 Doc.tensor 属性的值。 |
| 4 | user_data 它表示 Doc.user_data 字典的值。 |
| 5 | user_data_keys 它表示 Doc.user_data 字典的键。 |
| 6 | user_data_values 它表示 Doc.user_data 字典的值。 |
方法
以下是 Doc 类中使用的方法 -
| 序号 | 方法和描述 |
|---|---|
| 1 | Doc._ _init_ _ 构造 Doc 对象。 |
| 2 | Doc._ _getitem_ _ 获取特定位置的 token 对象。 |
| 3 | Doc._ _iter_ _ 迭代可以轻松访问注释的 token 对象。 |
| 4 | Doc._ _len_ _ 获取文档中的 token 数量。 |
类方法
以下是 Doc 类中使用的类方法 -
| 序号 | 类方法和描述 |
|---|---|
| 1 | Doc.set_extension 它在 Doc 上定义一个自定义属性。 |
| 2 | Doc.get_extension 它将按名称查找先前扩展。 |
| 3 | Doc.has_extension 它将检查 Doc 类上是否已注册扩展。 |
| 4 | Doc.remove_extension 它将删除 Doc 类上先前注册的扩展。 |
Doc 类上下文管理器和属性
在本章中,让我们学习 spaCy 中的上下文管理器和 Doc 类的属性。
上下文管理器
它是一个上下文管理器,用于处理 Doc 类的重新标记。现在让我们详细了解一下。
Doc.retokenize
当您使用此上下文管理器时,它将首先修改 Doc 的标记化,将其存储起来,然后在上下文管理器退出时一次性完成所有操作。
此上下文管理器的优点是它更高效且错误更少。
示例 1
请参考下面给出的 Doc.retokenize 上下文管理器示例 -
import spacy
nlp_model = spacy.load("en_core_web_sm")
from spacy.tokens import Doc
doc = nlp_model("This is Tutorialspoint.com.")
with doc.retokenize() as retokenizer:
retokenizer.merge(doc[0:0])
doc
输出
您将看到以下输出 -
is Tutorialspoint.com.
示例 2
这是 Doc.retokenize 上下文管理器的另一个示例 -
import spacy
nlp_model = spacy.load("en_core_web_sm")
from spacy.tokens import Doc
doc = nlp_model("This is Tutorialspoint.com.")
with doc.retokenize() as retokenizer:
retokenizer.merge(doc[0:2])
doc
输出
您将看到以下输出 -
This is Tutorialspoint.com.
重新标记方法
下面是表格,简要提供了有关重新标记方法的信息。下表详细解释了两种重新标记方法。
| 序号 | 方法和描述 |
|---|---|
| 1 | Retokenizer.merge 它将标记一个要合并的跨度。 |
| 2 | Retokenizer.split 它将标记一个要拆分为指定 orths 的 token。 |
属性
下面解释了 spaCy 中 Doc 类的属性 -
| 序号 | Doc 属性和描述 |
|---|---|
| 1 | Doc.ents 用于文档中的命名实体。 |
| 2 | Doc.noun_chunks 用于迭代特定文档中的基本名词短语。 |
| 3 | Doc.sents 用于迭代特定文档中的句子。 |
| 4 | Doc.has_vector 表示一个布尔值,指示是否与对象关联了词向量。 |
| 5 | Doc.vector 表示一个实值含义。 |
| 6 | Doc.vector_norm 表示文档向量表示的 L2 范数。 |
spaCy - 容器 Token 类
本章将帮助读者了解 spaCy 中的 Token 类。
Token 类
如前所述,Token 类表示单个 token,例如单词、标点符号、空格、符号等。
属性
下表解释了其属性 -
| 名称 | 类型 | 描述 |
|---|---|---|
| Doc | Doc | 它表示父文档。 |
| sent | Span | 在 2.0.12 版中引入,表示此 token 所属的句子跨度。 |
| Text | unicode | 它是 Unicode 原文文本内容。 |
| text_with_ws | unicode | 它表示文本内容,以及尾随空格字符(如果存在)。 |
| whitespace_ | unicode | 顾名思义,它是尾随空格字符(如果存在)。 |
| Orth | 整数 | 它是 Unicode 原文文本内容的 ID。 |
| orth_ | unicode | 它是与 Token.text 相同的 Unicode 原文文本内容。此文本内容主要用于与其他属性保持一致。 |
| Vocab | Vocab | 此属性表示父 Doc 的 vocab 对象。 |
| tensor | ndarray | 在 2.1.7 版中引入,表示 token 在父 Doc 的张量中的切片。 |
| Head | Token | 它是此 token 的句法父元素。 |
| left_edge | Token | 顾名思义,它是此 token 的句法后代中最左边的 token。 |
| right_edge | Token | 顾名思义,它是此 token 的句法后代中最右边的 token。 |
| I | Int | 表示 token 在父文档中的索引的整数类型属性。 |
| ent_type | 整数 | 它是命名实体类型。 |
| ent_type_ | unicode | 它是命名实体类型。 |
| ent_iob | 整数 | 它是命名实体标签的 IOB 代码。这里,3 = token 开始一个实体,2 = 它在实体之外,1 = 它在实体内部,0 = 未设置实体标签。 |
| ent_iob_ | unicode | 它是命名实体标签的 IOB 代码。“B”= token 开始一个实体,“I”= 它在实体内部,“O”= 它在实体外部,"" = 未设置实体标签。 |
| ent_kb_id | 整数 | 在 2.2 版中引入,表示引用此 token 所属的命名实体的知识库 ID。 |
| ent_kb_id_ | unicode | 在 2.2 版中引入,表示引用此 token 所属的命名实体的知识库 ID。 |
| ent_id | 整数 | 它是 token 是其实例的实体的 ID(如果有)。此属性当前未使用,但可能用于共指消解。 |
| ent_id_ | unicode | 它是 token 是其实例的实体的 ID(如果有)。此属性当前未使用,但可能用于共指消解。 |
| Lemma | 整数 | Lemma 是 token 的基本形式,没有屈折后缀。 |
| lemma_ | unicode | 它是 token 的基本形式,没有屈折后缀。 |
| Norm | 整数 | 此属性表示 token 的规范。 |
| norm_ | unicode | 此属性表示 token 的规范。 |
| Lower | 整数 | 顾名思义,它是 token 的小写形式。 |
| lower_ | unicode | 它也是 token 文本的小写形式,等效于 Token.text.lower()。 |
| Shape | 整数 | 为了显示正字法特征,此属性用于转换 token 的字符串。 |
| shape_ | unicode | 为了显示正字法特征,此属性用于转换 token 的字符串。 |
| Prefix | 整数 | 它是从 token 开始的长度为 N 的子字符串的哈希值。默认值为 N=1。 |
| prefix_ | unicode | 它是从 token 开始的长度为 N 的子字符串。默认值为 N=1。 |
| Suffix | 整数 | 它是从 token 结尾的长度为 N 的子字符串的哈希值。默认值为 N=3。 |
| suffix_ | unicode | 它是从 token 结尾的长度为 N 的子字符串。默认值为 N=3。 |
| is_alpha | 布尔值 | 此属性表示 token 是否由字母字符组成?它等效于 token.text.isalpha()。 |
| is_ascii | 布尔值 | 此属性表示 token 是否由 ASCII 字符组成?它等效于 all(ord(c) < 128 for c in token.text)。 |
| is_digit | 布尔值 | 此属性表示 token 是否由数字组成?它等效于 token.text.isdigit()。 |
| is_lower | 布尔值 | 此属性表示 token 是否为小写?它等效于 token.text.islower()。 |
| is_upper | 布尔值 | 此属性表示标记是否为大写?它等价于 token.text.isupper()。 |
| is_title | 布尔值 | 此属性表示标记是否为标题大小写?它等价于 token.text.istitle()。 |
| is_punct | 布尔值 | 此属性表示标记是否为标点符号? |
| is_left_punct | 布尔值 | 此属性表示标记是否为左括号标点符号,例如 '('? |
| is_right_punct | 布尔值 | 此属性表示标记是否为右括号标点符号,例如 ')'? |
| is_space | 布尔值 | 此属性表示标记是否仅由空格字符组成?它等价于 token.text.isspace()。 |
| is_bracket | 布尔值 | 此属性表示标记是否为括号? |
| is_quote | 布尔值 | 此属性表示标记是否为引号? |
| is_currency | 布尔值 | 在 2.0.8 版本中引入,此属性表示标记是否为货币符号? |
| like_url | 布尔值 | 此属性表示标记是否类似于 URL? |
| like_num | 布尔值 | 此属性表示标记是否代表一个数字? |
| like_email | 布尔值 | 此属性表示标记是否类似于电子邮件地址? |
| is_oov | 布尔值 | 此属性表示标记是否有词向量? |
| is_stop | 布尔值 | 此属性表示标记是否属于“停用词列表”? |
| Pos | 整数 | 它表示来自通用词性标记集的粗粒度词性。 |
| pos_ | unicode | 它表示来自通用词性标记集的粗粒度词性。 |
| Tag | 整数 | 它表示细粒度的词性。 |
| tag_ | unicode | 它表示细粒度的词性。 |
| Dep | 整数 | 此属性表示句法依存关系。 |
| dep_ | unicode | 此属性表示句法依存关系。 |
| Lang | Int | 此属性表示父文档词汇的语言。 |
| lang_ | unicode | 此属性表示父文档词汇的语言。 |
| Prob | float | 它是标记词类型的平滑对数概率估计。 |
| Idx | 整数 | 它是标记在父文档中的字符偏移量。 |
| Sentiment | float | 它表示一个标量值,指示标记的正面或负面情绪。 |
| lex_id | 整数 | 它表示标记词法类型的顺序 ID,用于索引到表格中。 |
| Rank | 整数 | 它表示标记词法类型的顺序 ID,用于索引到表格中。 |
| Cluster | 整数 | 它是布朗聚类 ID。 |
| _ | Underscore | 它表示用户空间,用于添加自定义属性扩展。 |
方法
以下是 Token 类中使用的方法 -
| 序号 | 方法和描述 |
|---|---|
| 1 | Token._ _init_ _ 它用于构造一个 Token 对象。 |
| 2 | Token.similarity 它用于计算语义相似度估计。 |
| 3 | Token.check_flag 它用于检查布尔标志的值。 |
| 4 | Token._ _len_ _ 它用于计算标记中 Unicode 字符的数量。 |
类方法
以下是 Token 类中使用的类方法 -
| 序号 | 类方法和描述 |
|---|---|
| 1 | Token.set_extension 它在 Token 上定义一个自定义属性。 |
| 2 | Token.get_extension 它将按名称查找先前扩展。 |
| 3 | Token.has_extension 它将检查是否在 Token 类上注册了扩展。 |
| 4 | Token.remove_extension 它将删除之前在 Token 类上注册的扩展。 |
spaCy - Token 属性
在本章中,我们将学习有关 spaCy 中 Token 类的属性。
属性
标记属性及其描述如下所示。
| 序号 | Token 属性和描述 |
|---|---|
| 1 | Token.ancestors 用于此标记的句法后代的最右侧标记。 |
| 2 | Token.conjuncts 用于返回一个协调标记的元组。 |
| 3 | Token.children 用于返回标记的直接句法子节点的序列。 |
| 4 | Token.lefts 用于单词的左侧直接子节点。 |
| 5 | Token.rights 用于单词的右侧直接子节点。 |
| 6 | Token.n_rights 用于单词的右侧直接子节点的数量。 |
| 7 | Token.n_lefts 用于单词的左侧直接子节点的数量。 |
| 8 | Token.subtree 这会生成一个包含标记和所有标记的句法后代的序列。 |
| 9 | Token.vector 它表示一个实值含义。 |
| 10 | Token.vector_norm 它表示标记向量表示的 L2 范数。 |
Token.ancestors
此标记属性用于此标记的句法后代的最右侧标记。
示例
下面给出了 Token.ancestors 属性的一个示例 -
import spacy
nlp_model = spacy.load("en_core_web_sm")
from spacy.tokens import Token
doc = nlp_model("Give it back! He pleaded.")
it_ancestors = doc[1].ancestors
[t.text for t in it_ancestors]
输出
['Give']
Token.conjuncts
此标记属性用于返回一个协调标记的元组。此处,不会包含标记本身。
示例
Token.conjuncts 属性的示例如下 -
import spacy
nlp_model = spacy.load("en_core_web_sm")
from spacy.tokens import Token
doc = nlp_model("I like cars and bikes")
cars_conjuncts = doc[2].conjuncts
[t.text for t in cars_conjuncts]
输出
以下是输出:
['bikes']
Token.children
此标记属性用于返回标记的直接句法子节点的序列。
示例
Token.children 属性的示例如下 -
import spacy
nlp_model = spacy.load("en_core_web_sm")
from spacy.tokens import Token
doc = nlp_model("This is Tutorialspoint.com.")
give_child = doc[1].children
[t.text for t in give_child]
输出
['This', 'Tutorialspoint.com', '.']
Token.lefts
此标记属性用于单词的左侧直接子节点。它将在句法依存分析中。
示例
Token.lefts 属性的示例如下 -
import spacy
nlp_model = spacy.load("en_core_web_sm")
from spacy.tokens import Token
doc = nlp_model("This is Tutorialspoint.com.")
left_child = [t.text for t in doc[1].lefts]
left_child
输出
您将获得以下输出 -
['This']
Token.rights
此标记属性用于单词的右侧直接子节点。它将在句法依存分析中。
示例
下面给出了 Token.rights 属性的一个示例 -
import spacy
nlp_model = spacy.load("en_core_web_sm")
from spacy.tokens import Token
doc = nlp_model("This is Tutorialspoint.com.")
right_child = [t.text for t in doc[1].rights]
right_child
输出
['Tutorialspoint.com', '.']
Token.n_rights
此标记属性用于单词的右侧直接子节点的数量。它将在句法依存分析中。
示例
下面给出了 Token.n_rights 属性的一个示例 -
import spacy
nlp_model = spacy.load("en_core_web_sm")
from spacy.tokens import Token
doc = nlp_model("This is Tutorialspoint.com.")
doc[1].n_rights
输出
2
Token.n_lefts
此标记属性用于单词的左侧直接子节点的数量。它将在句法依存分析中。
示例
Token.n_lefts 属性的示例如下 -
import spacy
nlp_model = spacy.load("en_core_web_sm")
from spacy.tokens import Token
doc = nlp_model("This is Tutorialspoint.com.")
doc[1].n_lefts
输出
以下是输出:
1
Token.subtree
此标记属性会生成一个包含标记和所有标记的句法后代的序列。
示例
Token.subtree 属性的示例如下 -
import spacy
nlp_model = spacy.load("en_core_web_sm")
from spacy.tokens import Token
doc = nlp_model("This is Tutorialspoint.com.")
subtree_doc = doc[1].subtree
[t.text for t in subtree_doc]
输出
['This', 'is', 'Tutorialspoint.com', '.']
Token.vector
此标记属性表示一个实值含义。它将返回一个表示标记语义的一维数组。
示例 1
Token.vector 属性的示例如下 -
import spacy
nlp_model = spacy.load("en_core_web_sm")
doc = nlp_model("The website is Tutorialspoint.com.")
doc.vector.dtype
输出
以下是输出:
dtype('float32')
示例 2
下面给出了 Token.vector 属性的另一个示例 -
doc.vector.shape
输出
以下是输出:
(96,)
Token.vector_norm
此标记属性表示标记向量表示的 L2 范数。
示例
下面给出了 Token.vector_norm 属性的一个示例 -
import spacy
nlp_model = spacy.load("en_core_web_sm")
doc1 = nlp_model("The website is Tutorialspoint.com.")
doc2 = nlp_model("It is having best technical tutorials.")
doc1[2].vector_norm !=doc2[2].vector_norm
输出
True
spaCy - 容器 Span 类
本章将帮助您了解 spaCy 中的 Span 类。
Span 类
它是从 Doc 对象切片,我们在上面讨论过。
属性
下表解释了它的参数:
| 名称 | 类型 | 描述 |
|---|---|---|
| doc | Doc | 它表示父文档。 |
| tensor V2.1.7 | Ndarray | 在 2.1.7 版本中引入,表示 span 对父 Doc 张量的切片。 |
| sent | Span | 它实际上是此 span 所属的句子 span。 |
| start | Int | 此属性是 span 起始处的标记偏移量。 |
| end | Int | 此属性是 span 结束处的标记偏移量。 |
| start_char | Int | 整数类型属性,表示 span 起始处的字符偏移量。 |
| end_char | Int | 整数类型属性,表示 span 结束处的字符偏移量。 |
| text | Unicode | 它是一个 Unicode,表示 span 文本。 |
| text_with_ws | Unicode | 它表示 span 的文本内容,如果最后一个标记有一个,则带有一个尾随空格字符。 |
| orth | Int | 此属性是逐字文本内容的 ID。 |
| orth_ | Unicode | 它是 Unicode 逐字文本内容,与 Token.text 相同。此文本内容主要出于与其他属性保持一致的目的而存在。 |
| label | Int | 此整数属性是 span 标签的哈希值。 |
| label_ | Unicode | 它是 span 的标签。 |
| lemma_ | Unicode | 它是 span 的词形。 |
| kb_id | Int | 它表示知识库 ID 的哈希值,span 引用它。 |
| kb_id_ | Unicode | 它表示知识库 ID,span 引用它。 |
| ent_id | Int | 此属性表示标记是其实例的命名实体的哈希值。 |
| ent_id_ | Unicode | 此属性表示标记是其实例的命名实体的字符串 ID。 |
| sentiment | Float | 一个浮点类型的标量值,指示 span 的正面或负面情绪。 |
| _ | Underscore | 它表示用于添加自定义属性扩展的用户空间。 |
方法
以下是 Span 类中使用的方法 -
| 序号 | 方法和描述 |
|---|---|
| 1 | Span._ _init_ _ 从切片 doc[start : end] 构造 Span 对象。 |
| 2 | Span._ _getitem_ _ 获取特定位置(例如 n)处的标记对象,其中 n 是一个整数。 |
| 3 | Span._ _iter_ _ 迭代可以轻松访问注释的 token 对象。 |
| 4 | Span._ _len_ _ 获取 span 中标记的数量。 |
| 5 | Span.similarity 进行语义相似度估计。 |
| 6 | Span.merge 以将 span 合并为单个标记的方式重新标记文档。 |
类方法
以下是 Span 类中使用的类方法 -
| 序号 | 类方法和描述 |
|---|---|
| 1 | Span.set_extension 它在 Span 上定义一个自定义属性。 |
| 2 | Span.get_extension 按名称查找之前注册的扩展。 |
| 3 | Span.has_extension 检查是否在 Span 类上注册了扩展。 |
| 4 | Span.remove_extension 删除之前在 Span 类上注册的扩展。 |
spaCy - Span 类属性
在本章中,让我们学习 spaCy 中的 Span 属性。
属性
以下是关于 spaCy 中 Span 类的属性。
| 序号 | Span 属性和描述 |
|---|---|
| 1 | Span.ents 用于 span 中的命名实体。 |
| 2 | Span.as_doc 用于创建对应于 Span 的新 Doc 对象。它也将拥有数据的副本。 |
| 3 | Span.root 提供具有到句子根的最短路径的标记。 |
| 4 | Span.lefts 用于位于 span 左侧且其头部在 span 内的标记。 |
| 5 | Span.rights 用于位于 span 右侧且其头部在 span 内的标记。 |
| 6 | Span.n_rights 用于位于 span 右侧且其头部在 span 内的标记。 |
| 7 | Span.n_lefts 用于位于 span 左侧且其头部在 span 内的标记。 |
| 8 | Span.subtree 生成 span 内的标记以及从它们派生的标记。 |
| 9 | Span.vector 表示一个实值含义。 |
| 10 | Span.vector_norm 表示文档向量表示的 L2 范数。 |
Span.ents
此 Span 属性用于 span 中的命名实体。如果已应用实体识别器,则此属性将返回一个命名实体 span 对象的元组。
示例 1
Span.ents 属性的示例如下 -
import spacy
nlp_model = spacy.load("en_core_web_sm")
doc = nlp_model("This is Tutorialspoint.com.")
span = doc[0:5]
ents = list(span.ents)
ents[0].label
输出
您将收到以下输出 -
383
示例 2
Span.ents 属性的另一个示例如下 -
ents[0].label_
输出
您将收到以下输出 -
‘ORG’
示例 3
下面给出了 Span.ents 属性的另一个示例 -
ents[0].text
输出
您将收到以下输出 -
'Tutorialspoint.com'
Span.as_doc
顾名思义,此 Span 属性将创建对应于 Span 的新 Doc 对象。它也将拥有数据的副本。
示例
下面给出了 Span.as_doc 属性的一个示例 -
import spacy
nlp_model = spacy.load("en_core_web_sm")
doc = nlp_model("I like India.")
span = doc[2:4]
doc2 = span.as_doc()
doc2.text
输出
您将收到以下输出 -
India
Span.root
此 Span 属性将提供具有到句子根的最短路径的标记。如果树中有多个标记在相同的高度,它将获取第一个标记。
示例 1
Span.root 属性的示例如下 -
import spacy
nlp_model = spacy.load("en_core_web_sm")
doc = nlp_model("I like New York in Autumn.")
i, like, new, york, in_, autumn, dot = range(len(doc))
doc[new].head.text
输出
您将收到以下输出 -
'York'
示例 2
Span.root 属性的另一个示例如下 -
doc[york].head.text
输出
您将收到以下输出 -
'like'
示例 3
下面给出了 Span.root 属性的一个示例 -
new_york = doc[new:york+1] new_york.root.text
输出
您将收到以下输出 -
'York'
Span.lefts
此 Span 属性用于位于 span 左侧且其头部在 span 内的标记。
示例
下面是一个 Span.lefts 属性的示例:
import spacy
nlp_model = spacy.load("en_core_web_sm")
doc = nlp_model("This is Tutorialspoint.com.")
lefts = [t.text for t in doc[1:4].lefts]
lefts
输出
您将收到以下输出 -
['This']
Span.rights
此 Span 属性用于 span 右侧的标记,其头部位于 span 内。
示例
下面给出了 Span.rights 属性的一个示例:
import spacy
nlp_model = spacy.load("en_core_web_sm")
doc = nlp_model("This is Tutorialspoint.com.")
rights = [t.text for t in doc[1:2].rights]
rights
输出
您将收到以下输出 -
['Tutorialspoint.com', '.']
Span.n_rights
此 Span 属性用于 span 右侧的标记,其头部位于 span 内。
示例
Span.n_rights 属性的一个示例如下:
import spacy
nlp_model = spacy.load("en_core_web_sm")
doc = nlp_model("This is Tutorialspoint.com.")
doc[1:2].n_rights
输出
您将收到以下输出 -
2
Span.n_lefts
此 Span 属性用于 span 左侧的标记,其头部位于 span 内。
示例
Span.n_lefts 属性的一个示例如下:
import spacy
nlp_model = spacy.load("en_core_web_sm")
doc = nlp_model("This is Tutorialspoint.com.")
doc[1:2].n_lefts
输出
您将收到以下输出 -
1
Span.subtree
此 Span 属性会生成 span 内的标记以及从它们派生的标记。
示例
Span.subtree 属性的一个示例如下:
import spacy
nlp_model = spacy.load("en_core_web_sm")
doc = nlp_model("This is Tutorialspoint.com.")
subtree = [t.text for t in doc[:1].subtree]
subtree
输出
您将收到以下输出 -
['This']
Span.vector
此 Span 属性表示一个实数值含义。默认值为标记向量的平均值。
示例 1
Span.vector 属性的一个示例如下:
import spacy
nlp_model = spacy.load("en_core_web_sm")
doc = nlp_model("The website is Tutorialspoint.com.")
doc[1:].vector.dtype
输出
您将收到以下输出 -
dtype('float32')
示例 2
Span.vector 属性的另一个示例如下:
输出
您将收到以下输出 -
(96,)
Span.vector_norm
此 doc 属性表示文档向量表示的 L2 范数。
示例
Span.vector_norm 属性的一个示例如下:
import spacy
nlp_model = spacy.load("en_core_web_sm")
doc = nlp_model("The website is Tutorialspoint.com.")
doc[1:].vector_norm
doc[2:].vector_norm
doc[1:].vector_norm != doc[2:].vector_norm
输出
您将收到以下输出 -
True
spaCy - 容器 Lexeme 类
本章详细解释了 spaCy 中的词元类 (Lexeme Class)。
词元类 (Lexeme Class)
词元类是词汇表中的一个条目。它没有字符串上下文。与单词标记相反,它是一个单词类型。这就是它没有 POS(词性)标记、依存关系分析或词形的原因。
属性
下表解释了它的参数:
| 名称 | 类型 | 描述 |
|---|---|---|
| vocab | Vocab | 它表示词元的词汇表。 |
| text | unicode | 一个 Unicode 属性,表示逐字文本内容。 |
| orth | 整数 | 它是一个整数类型属性,表示逐字文本内容的 ID。 |
| orth_ | unicode | 它是与 Lexeme.text 相同的 Unicode 逐字文本内容。此文本内容主要用于与其他属性保持一致。 |
| 等级 (rank) | 整数 | 它表示词元词法类型的顺序 ID,用于索引到表格中。 |
| 标志 (flags) | 整数 | 它表示词元二进制标志的容器。 |
| 范数 (norm) | 整数 | 此属性表示词元的范数。 |
| norm_ | unicode | 此属性表示词元的范数。 |
| 小写 (lower) | 整数 | 顾名思义,它是单词的小写形式。 |
| lower_ | unicode | 它也是单词的小写形式。 |
| 形状 (shape) | 整数 | 为了显示正字法特征,此属性用于转换单词的字符串。 |
| shape_ | unicode | 为了显示正字法特征,此属性用于转换单词的字符串。 |
| 前缀 (prefix) | 整数 | 它是单词开头长度为 N 的子字符串的哈希值。默认值为 N=1。 |
| prefix_ | unicode | 它是单词开头长度为 N 的子字符串。默认值为 N=1。 |
| 后缀 (suffix) | 整数 | 它是单词结尾长度为 N 的子字符串的哈希值。默认值为 N=3。 |
| suffix_ | unicode | 它是单词结尾长度为 N 的子字符串。默认值为 N=3。 |
| is_alpha | 布尔值 | 此属性表示词元是否包含字母字符?它等效于 lexeme.text.isalpha()。 |
| is_ascii | 布尔值 | 此属性表示词元是否包含 ASCII 字符?它等效于 all(ord(c) < 128 for c in lexeme.text)。 |
| is_digit | 布尔值 | 此属性表示词元是否包含数字?它等效于 lexeme.text.isdigit()。 |
| is_lower | 布尔值 | 此属性表示词元是否为小写?它等效于 lexeme.text.islower()。 |
| is_upper | 布尔值 | 此属性表示词元是否为大写?它等效于 lexeme.text.isupper()。 |
| is_title | 布尔值 | 此属性表示词元是否为标题大小写?它等效于 lexeme.text.istitle()。 |
| is_punct | 布尔值 | 此属性表示词元是否为标点符号? |
| is_left_punct | 布尔值 | 此属性表示词元是否为左标点符号,例如 '('? |
| is_right_punct | 布尔值 | 此属性表示词元是否为右标点符号,例如 ')'? |
| is_space | 布尔值 | 此属性表示词元是否包含空格字符?它等效于 lexeme.text.isspace()。 |
| is_bracket | 布尔值 | 此属性表示词元是否为括号? |
| is_quote | 布尔值 | 此属性表示词元是否为引号? |
| is_currency | 布尔值 | 在 2.0.8 版中引入,此属性表示词元是否为货币符号? |
| like_url | 布尔值 | 此属性表示词元是否类似于 URL? |
| like_num | 布尔值 | 此属性表示词元是否表示数字? |
| like_email | 布尔值 | 此属性表示词元是否类似于电子邮件地址? |
| is_oov | 布尔值 | 此属性表示词元是否具有词向量? |
| is_stop | 布尔值 | 此属性表示词元是否属于“停用词列表”的一部分? |
| Lang | Int | 此属性表示父文档词汇的语言。 |
| lang_ | unicode | 此属性表示父文档词汇的语言。 |
| Prob | float | 它是词元词类型的平滑对数概率估计。 |
| 聚类 (cluster) | 整数 | 它表示布朗聚类 ID。 |
| Sentiment | float | 它表示一个标量值,指示词元的积极性或消极性。 |
方法
以下是词元类中使用的方法:
| 序号 | 方法及描述 |
|---|---|
| 1 | Lexeme._ _init_ _ 构造 Lexeme 对象。 |
| 2 | Lexeme.set_flag 更改布尔标志的值。 |
| 3 | Lexeme.check_flag 检查布尔标志的值。 |
| 4 | Lexeme.similarity 计算语义相似度估计。 |
Lexeme._ _init_ _
这是词元类中最有用的方法之一。顾名思义,它用于构造一个**词元**对象。
参数
下表解释了它的参数:
| 名称 | 类型 | 描述 |
|---|---|---|
| Vocab | Vocab | 此参数表示父词汇表。 |
| Orth | 整数 | 它是词元的正字法 ID。 |
示例
下面给出了 Lexeme._ _init_ _ 方法的一个示例:
import spacy
nlp_model = spacy.load("en_core_web_sm")
doc = nlp_model("The website is Tutorialspoint.com.")
lexeme = doc[3]
lexeme.text
输出
运行代码时,您将看到以下输出:
'Tutorialspoint.com'
Lexeme.set_flag
此方法用于更改布尔标志的值。
参数
下表解释了它的参数:
| 名称 | 类型 | 描述 |
|---|---|---|
| 标志 ID (flag_id) | Int | 它表示要设置的标志的属性 ID。 |
| 值 (value) | 布尔值 | 它是标志的新值。 |
示例
下面给出了 Lexeme.set_flag 方法的一个示例:
import spacy
nlp_model = spacy.load("en_core_web_sm")
New_FLAG = nlp_model.vocab.add_flag(lambda text: False)
nlp_model.vocab["Tutorialspoint.com"].set_flag(New_FLAG, True)
New_FLAG
输出
运行代码时,您将看到以下输出:
25
Lexeme.check_flag
此方法用于检查布尔标志的值。
参数
下表解释了其参数:
| 名称 | 类型 | 描述 |
|---|---|---|
| 标志 ID (flag_id) | Int | 它表示要检查的标志的属性 ID。 |
示例 1
下面给出了 Lexeme.check_flag 方法的一个示例:
import spacy
nlp_model = spacy.load("en_core_web_sm")
library = lambda text: text in ["Website", "Tutorialspoint.com"]
my_library = nlp_model.vocab.add_flag(library)
nlp_model.vocab["Tutorialspoint.com"].check_flag(my_library)
输出
运行代码时,您将看到以下输出:
True
示例 2
下面是 Lexeme.check_flag 方法的另一个示例:
nlp_model.vocab["Hello"].check_flag(my_library)
输出
运行代码时,您将看到以下输出:
False
Lexeme.similarity
此方法用于计算语义相似度估计。默认情况下,它是向量的余弦相似度。
参数
下表解释了其参数:
| 名称 | 类型 | 描述 |
|---|---|---|
| 其他 | - | 它是将要进行比较的对象。默认情况下,它将接受 Doc、Span、Token 和 Lexeme 对象。 |
示例
Lexeme.similarity 方法的一个示例如下:
import spacy
nlp_model = spacy.load("en_core_web_sm")
apple = nlp.vocab["apple"]
orange = nlp.vocab["orange"]
apple_orange = apple.similarity(orange)
orange_apple = orange.similarity(apple)
apple_orange == orange_apple
输出
运行代码时,您将看到以下输出:
True
属性
以下是词元类的属性。
| 序号 | 属性及描述 |
|---|---|
| 1 | Lexeme.vector 它将返回一个表示词元语义的一维数组。 |
| 2 | Lexeme.vector_norm 它表示词元向量表示的 L2 范数。 |
Lexeme.vector
此词元属性表示一个实数值含义。它将返回一个表示词元语义的一维数组。
示例
下面给出了 Lexeme.vector 属性的一个示例:
import spacy
nlp_model = spacy.load("en_core_web_sm")
apple = nlp_model.vocab["apple"]
apple.vector.dtype
输出
您将看到以下输出 -
dtype('float32')
Lexeme.vector_norm
此标记属性表示词元向量表示的 L2 范数。
示例
下面给出了 Lexeme.vector_norm 属性的一个示例:
import spacy
nlp_model = spacy.load("en_core_web_sm")
apple = nlp.vocab["apple"]
pasta = nlp.vocab["pasta"]
apple.vector_norm != pasta.vector_norm
输出
您将看到以下输出 -
True
spaCy - 训练神经网络模型
在本章中,让我们学习如何在 spaCy 中训练神经网络模型。
在这里,我们将了解如何更新 spaCy 的统计模型以将其自定义以用于我们的用例。例如,预测在线评论中的新实体类型。要进行自定义,我们首先需要训练自己的模型。
训练步骤
让我们了解在 spaCy 中训练神经网络模型的步骤。
步骤 1 - **初始化** - 如果您没有使用预训练模型,那么首先,我们需要使用 **nlp.begin_training** 将模型权重随机初始化。
步骤 2 - **预测** - 接下来,我们需要使用当前权重预测一些示例。可以通过调用 **nlp.updates** 来完成。
步骤 3 - **比较** - 现在,模型将根据真实标签检查预测结果。
步骤 4 - **计算** - 比较后,在这里,我们将决定如何更改权重以在下一次预测中获得更好的结果。
步骤 5 - **更新** - 最后,对当前权重进行微小更改并选择下一批示例。继续对您获取的每一批示例调用 **nlp.updates**。
现在让我们借助下图了解这些步骤:
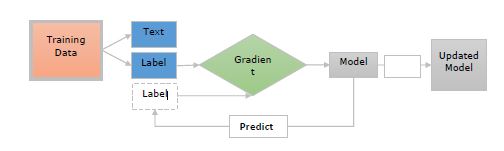
这里:
**训练数据** - 训练数据是示例及其注释。这些是我们希望更新模型的示例。
**文本** - 它表示模型应该预测标签的输入文本。它应该是一个句子、段落或更长的文档。
**标签** - 标签实际上是我们希望模型预测的内容。例如,它可以是文本类别。
**梯度** - 梯度是我们应该如何更改权重以减少误差。它将在将预测标签与真实标签进行比较后计算。
训练实体识别器
首先,实体识别器将获取一个文档并预测短语及其标签。
这意味着训练数据需要包含以下内容:
文本。
它们包含的实体。
实体标签。
每个标记只能是单个实体的一部分。因此,实体不能重叠。
我们还应该根据实体及其周围的上下文对其进行训练,因为实体识别器会在上下文中预测实体。
可以通过向模型显示文本和字符偏移列表来完成。
例如,在下面给出的代码中,phone 是一个从字符 0 开始到字符 8 结束的小工具。
("Phone is coming", {"entities": [(0, 8, "GADGET")]})
在这里,模型还应该学习除实体之外的其他单词。
考虑另一个训练实体识别器的示例,如下所示:
("I need a new phone! Any suggestions?", {"entities": []})
主要目标应该是教会我们的实体识别器模型,即使在训练数据中不存在,也能在类似的上下文中识别新的实体。
spaCy 的训练循环
一些库为我们提供了负责模型训练的方法,但另一方面,spaCy 为我们提供了对训练循环的完全控制。
训练循环可以定义为一系列用于更新和训练模型的步骤。
训练循环步骤
让我们看看训练循环的步骤,如下所示:
**步骤 1** - **循环** - 第一步是循环,我们通常需要执行多次,以便模型从中学习。例如,如果您想训练模型 20 次迭代,则需要循环 20 次。
**步骤 2** - **随机化** - 第二步是随机化训练数据。我们需要为每次迭代随机打乱数据。这有助于防止模型陷入次优解。
**步骤 3** - **划分** – 稍后将数据划分为批次。在这里,我们将训练数据划分为小批量。这有助于提高梯度估计的可读性。
**步骤 4** - **更新** - 下一步是为每个步骤更新模型。现在,我们需要更新模型并重新开始循环,直到我们到达最后一次迭代。
**步骤 5** - **保存** - 最后,我们可以保存此训练后的模型并在 spaCy 中使用它。
示例
以下是 spaCy 训练循环的一个示例:
DATA = [
("How to order the Phone X", {"entities": [(20, 28, "GADGET")]})
]
# Step1: Loop for 10 iterations
for i in range(10):
# Step2: Shuffling the training data
random.shuffle(DATA)
# Step3: Creating batches and iterating over them
for batch in spacy.util.minibatch(DATA):
# Step4: Splitting the batch in texts and annotations
texts = [text for text, annotation in batch]
annotations = [annotation for text, annotation in batch]
# Step5: Updating the model
nlp.update(texts, annotations)
# Step6: Saving the model
nlp.to_disk(path_to_model)
spaCy - 更新神经网络模型
在本章中,我们将学习如何在 spaCy 中更新神经网络模型。
更新原因
以下是更新现有模型的原因:
更新后的模型将在您的特定领域提供更好的结果。
在更新现有模型时,您可以为您的问题学习分类方案。
更新现有模型对于文本分类至关重要。
它对于命名实体识别尤其有用。
对于词性标注和依存关系分析,它不太重要。
更新现有模型
借助 spaCy,我们可以使用更多数据更新现有的预训练模型。例如,我们可以更新模型以提高其对不同文本的预测精度。
更新现有的预训练模型非常有用,如果你想改进模型已经掌握的类别。例如,“人”或“组织”。我们还可以更新现有的预训练模型以添加新的类别。
建议始终使用新类别的示例以及模型之前正确预测的其他类别的示例来更新现有的预训练模型。如果不这样做,改进新类别可能会损害其他类别。
设置新的管道
从下面给出的示例中,让我们了解如何从头开始设置一个新的管道来更新现有模型:
首先,我们将使用spacy.blank方法从空白的英语模型开始。它仅包含语言数据和分词规则,不包含任何管道组件。
之后,我们将创建一个空白实体识别器并将其添加到管道中。接下来,我们将使用add_label将新的字符串标签添加到模型中。
现在,我们可以通过调用nlp.begin_training来使用随机权重初始化模型。
接下来,我们需要在每次迭代中随机打乱数据。这样做是为了获得更好的准确率。
打乱后,使用spaCy的minibatch函数将示例划分为批次。最后,使用文本和注释更新模型,然后继续循环。
示例
下面是一个使用spacy.blank从空白英语模型开始的示例:
nlp = spacy.blank("en")
下面是一个创建空白实体识别器并将其添加到管道中的示例:
ner = nlp.create_pipe("ner")
nlp.add_pipe(ner)
这是一个使用add_label添加新标签的示例:
ner.add_label("GADGET")
一个使用nlp.begin_training开始训练的示例如下:
nlp.begin_training()
这是一个迭代训练并在每次迭代中打乱数据的示例。
for itn in range(10): random.shuffle(examples)
这是一个使用minibatch实用程序函数将示例划分为批次(例如,在spacy.util.minibatch(examples, size=2)中)的示例。
texts = [text for text, annotation in batch] annotations = [annotation for text, annotation in batch]
下面是一个使用文本和注释更新模型的示例:
nlp.update(texts, annotations)