- Splunk 教程
- Splunk - 首页
- Splunk - 概述
- Splunk - 环境
- Splunk - 接口
- Splunk - 数据摄取
- Splunk - 数据源类型
- Splunk - 基础搜索
- Splunk - 字段搜索
- Splunk - 时间范围搜索
- Splunk - 分享和导出
- Splunk - 搜索语言
- Splunk - 搜索优化
- Splunk - 数据转换命令
- Splunk - 报表
- Splunk - 仪表盘
- Splunk - 数据透视和数据集
- Splunk - 查找
- Splunk - 定时任务和告警
- Splunk - 知识管理
- Splunk - 子搜索
- Splunk - 搜索宏
- Splunk - 事件类型
- Splunk - 基础图表
- Splunk - 叠加图表
- Splunk - 小型图表
- Splunk - 管理索引
- Splunk - 计算字段
- Splunk - 标签
- Splunk - 应用
- Splunk - 删除数据
- Splunk - 自定义图表
- Splunk - 监控文件
- Splunk - 排序命令
- Splunk - top 命令
- Splunk - stats 命令
- Splunk 有用资源
- Splunk 快速指南
- Splunk - 有用资源
- Splunk - 讨论
Splunk 快速指南
Splunk - 概述
Splunk 是一款软件,它可以处理机器数据和其他形式的大数据并从中提取洞察。这些机器数据是由运行 Web 服务器的 CPU、物联网设备、移动应用程序日志等生成的。这些数据无需提供给最终用户,也没有任何业务意义。但是,它们对于理解、监控和优化机器性能至关重要。
Splunk 可以读取非结构化、半结构化或少量结构化数据。读取数据后,它允许搜索、标记、创建这些数据的报表和仪表盘。随着大数据时代的到来,Splunk 现在能够从各种来源(可能是也可能不是机器数据)摄取大数据,并在其上运行分析。
因此,从一个简单的日志分析工具开始,Splunk 已经发展成为一个通用的非结构化机器数据和各种形式的大数据分析工具。
产品类别
Splunk 提供以下三种不同的产品类别:
Splunk Enterprise - 它被拥有大型 IT 基础设施和 IT 驱动型业务的公司使用。它有助于收集和分析来自网站、应用程序、设备和传感器等的数据。
Splunk Cloud - 它是云托管平台,具有与企业版相同的特性。它可以从 Splunk 本身或通过 AWS 云平台获得。
Splunk Light - 它允许在一个位置实时搜索、报告和告警所有日志数据。与其他两个版本相比,它的功能和特性有限。
Splunk 特性
在本节中,我们将讨论企业版的关键特性:
数据摄取
Splunk 可以摄取各种数据格式,例如 JSON、XML 和非结构化机器数据(如 Web 和应用程序日志)。非结构化数据可以根据用户的需要建模成数据结构。
数据索引
Splunk 对摄取的数据进行索引,以便更快地根据不同的条件进行搜索和查询。
数据搜索
Splunk 中的搜索涉及使用索引数据来创建指标、预测未来趋势和识别数据中的模式。
使用告警
Splunk 告警可用于在分析的数据中发现特定条件时触发电子邮件或 RSS 提要。
仪表盘
Splunk 仪表盘可以以图表、报表和数据透视表等形式显示搜索结果。
数据模型
索引数据可以建模为一个或多个数据集,这些数据集基于专业的领域知识。这使得最终用户更容易浏览业务案例,而无需学习 Splunk 使用的搜索处理语言的技术细节。
Splunk - 环境
在本教程中,我们将安装企业版。此版本提供 60 天的免费试用,所有功能均已启用。您可以使用以下链接下载安装程序,该链接适用于 Windows 和 Linux 平台。
https://www.splunk.com/en_us/download/splunk-enterprise.html.
Linux 版本
Linux 版本可从上述下载链接下载。我们选择 .deb 包类型,因为安装将在 Ubuntu 平台上进行。
我们将逐步学习这个过程:
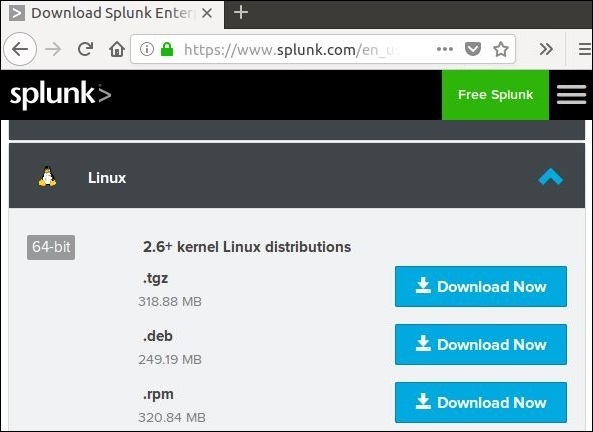
步骤 1
下载 .deb 包,如下图所示:
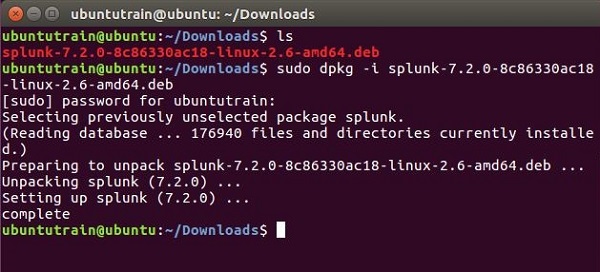
步骤 2
转到下载目录,并使用上面下载的包安装 Splunk。
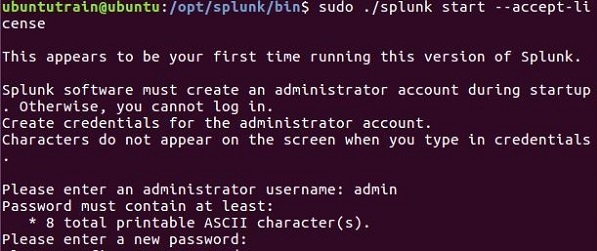
步骤 3
接下来,您可以使用带有接受许可证参数的以下命令启动 Splunk。它会要求您提供管理员用户名和密码,您应该提供并记住它们。
步骤 4
Splunk 服务器启动并显示可以访问 Splunk 接口的 URL。
步骤 5
现在,您可以访问 Splunk URL 并输入在步骤 3 中创建的管理员用户 ID 和密码。
Windows 版本
Windows 版本以 msi 安装程序的形式提供,如下图所示:
双击 msi 安装程序即可直接安装 Windows 版本。为确保成功安装,必须在以下两个重要步骤中做出正确的选择。
步骤 1
由于我们将其安装在本地系统上,请选择以下所示的本地系统选项:
步骤 2
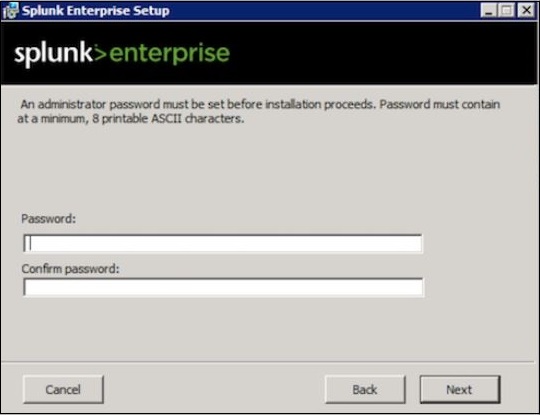
输入管理员密码并记住它,因为它将在未来的配置中使用。
步骤 3
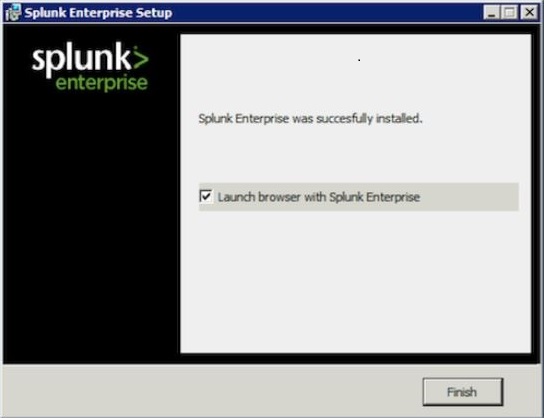
在最后一步,我们看到 Splunk 已成功安装,并且可以从 Web 浏览器启动。
步骤 4
接下来,打开浏览器并输入提供的 url,https://:8000,并使用管理员用户 ID 和密码登录 Splunk。
Splunk - 接口
Splunk Web 接口包含搜索、报告和分析已摄取数据所需的所有工具。相同的 Web 接口提供管理用户及其角色的功能。它还提供数据摄取和 Splunk 中提供的内置应用程序的链接。
下图显示了使用管理员凭据登录 Splunk 后出现的初始屏幕。
管理员链接
管理员下拉菜单提供设置和编辑管理员详细信息的选项。我们可以使用以下屏幕重置管理员电子邮件 ID 和密码:
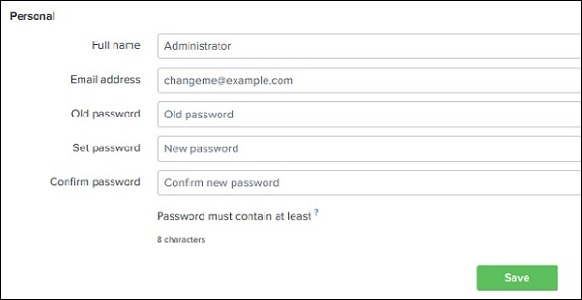
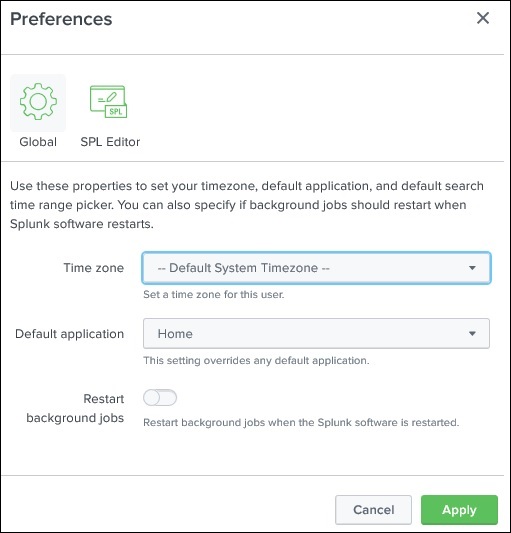
此外,从管理员链接,我们还可以导航到首选项选项,在这里我们可以设置时区和登录后将打开目标页面的主应用程序。目前,它打开的是如下所示的主页:
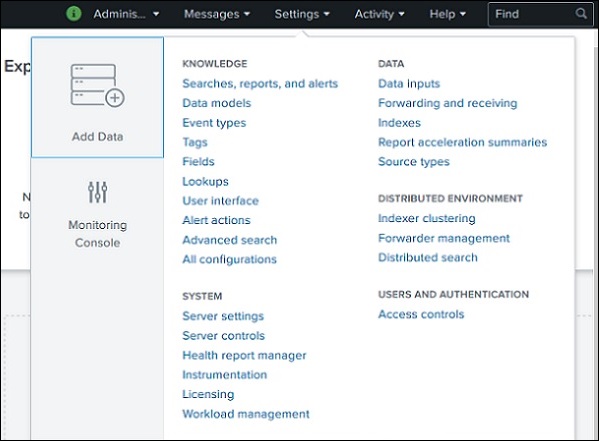
设置链接
这是一个链接,显示 Splunk 中可用的所有核心功能。例如,您可以通过选择查找链接来添加查找文件和查找定义。
我们将在后续章节中讨论这些链接的重要设置。
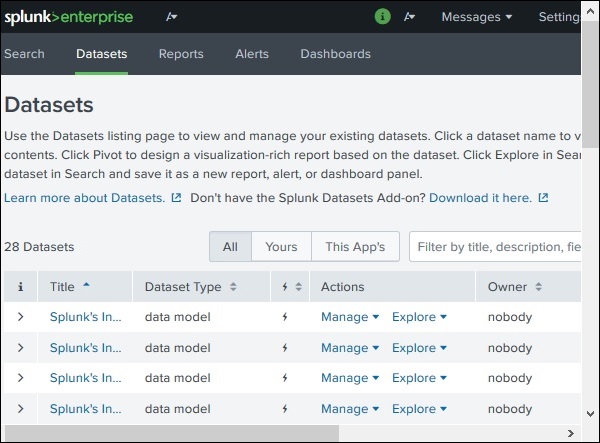
搜索和报表链接
搜索和报表链接将我们带到可以找到可用于搜索报表和为这些搜索创建的告警的数据集的功能。这在下图中清晰地显示:
Splunk - 数据摄取
Splunk 中的数据摄取是通过添加数据功能进行的,该功能是搜索和报表应用程序的一部分。登录后,Splunk 接口主屏幕显示添加数据图标,如下所示。
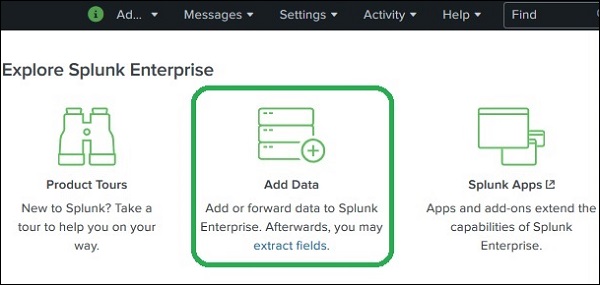
单击此按钮后,我们将看到一个屏幕,用于选择计划推送到 Splunk 进行分析的数据的源和格式。
收集数据
我们可以从 Splunk 官方网站获取分析数据。保存此文件并将其解压缩到您的本地驱动器中。打开文件夹后,您可以找到三个具有不同格式的文件。它们是由某些 Web 应用程序生成的日志数据。我们还可以收集 Splunk 提供的另一组数据,这些数据可从 Splunk 官方网页获得。
我们将使用这两组数据来了解 Splunk 各个功能的工作原理。
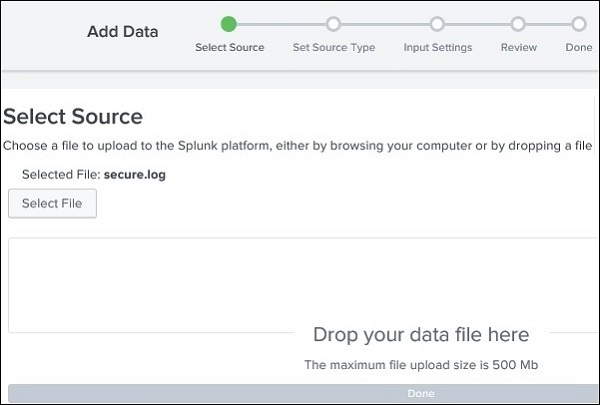
上传数据
接下来,我们从我们在上一段中提到的本地系统中保存的mailsv文件夹中选择secure.log文件。选择文件后,我们使用右上角的绿色“下一步”按钮进入下一步。
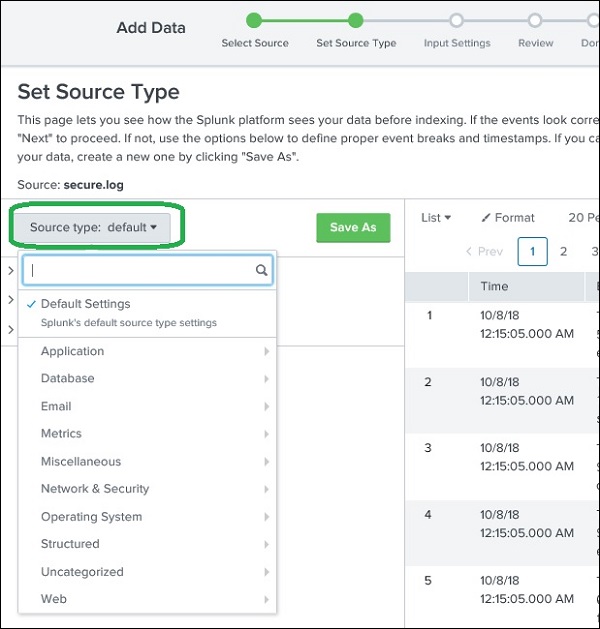
选择数据源类型
Splunk 具有一个内置功能,可以检测正在摄取的数据类型。它还允许用户选择与 Splunk 选择的数据类型不同的数据类型。单击数据源类型下拉菜单,我们可以看到 Splunk 可以摄取并启用搜索的各种数据类型。
在下面给出的当前示例中,我们选择默认数据源类型。
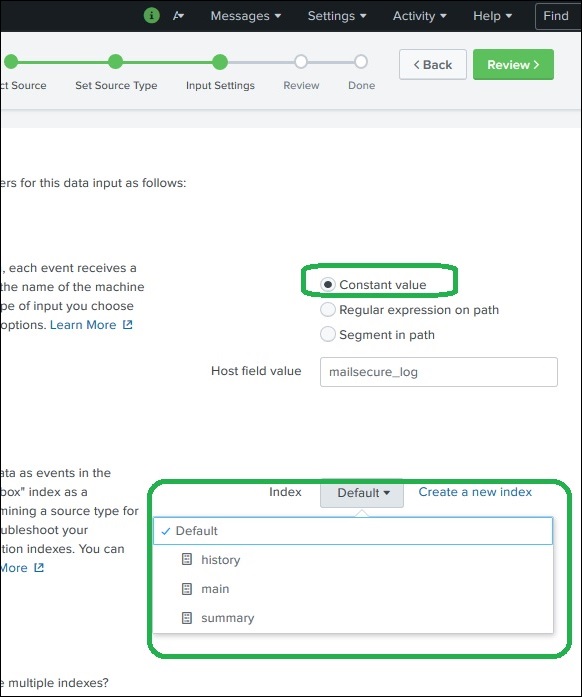
输入设置
在此数据摄取步骤中,我们配置正在摄取数据的宿主名称。以下是宿主名称的选择项:
常量值
它是源数据所在的完整宿主名称。
路径上的正则表达式
当您想要使用正则表达式提取宿主名称时。然后在“正则表达式”字段中输入要提取的宿主名称的正则表达式。
路径中的段
当您想要从数据源路径中的段提取宿主名称时,在“段号”字段中输入段号。例如,如果源的路径为 /var/log/,并且您希望第三个段(宿主服务器名称)作为宿主值,请输入“3”。
接下来,我们选择要为输入数据创建的索引类型以进行搜索。我们选择默认索引策略。摘要索引仅通过聚合创建数据的摘要并在其上创建索引,而历史索引用于存储搜索历史记录。这在下图中清楚地显示:
查看设置
单击“下一步”按钮后,我们会看到我们选择的设置摘要。我们对其进行审查,然后选择“下一步”以完成数据的上传。
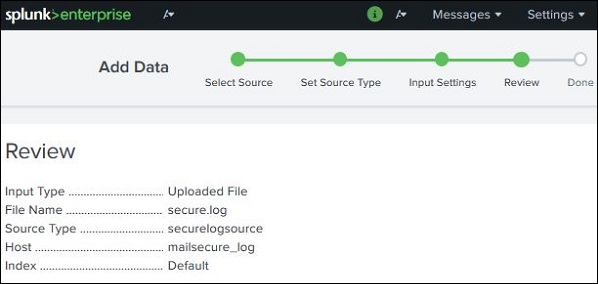
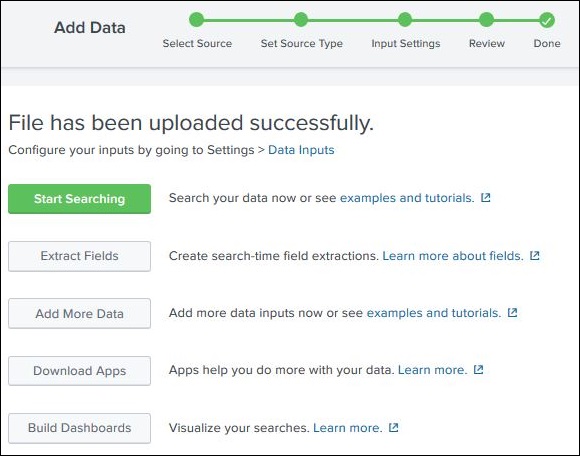
加载完成后,将出现以下屏幕,显示数据已成功摄取以及我们可以对数据执行的其他操作。
Splunk - 数据源类型
所有传入 Splunk 的数据首先由其内置的数据处理单元进行判断,并分类为某些数据类型和类别。例如,如果它是来自 Apache Web 服务器的日志,Splunk 能够识别它并从读取的数据中创建相应的字段。
Splunk 中此功能称为数据源类型检测,它使用其称为“预训练”数据源类型的内置数据源类型来实现此目的。
这简化了分析过程,因为用户无需手动对数据进行分类并为传入数据的字段分配任何数据类型。
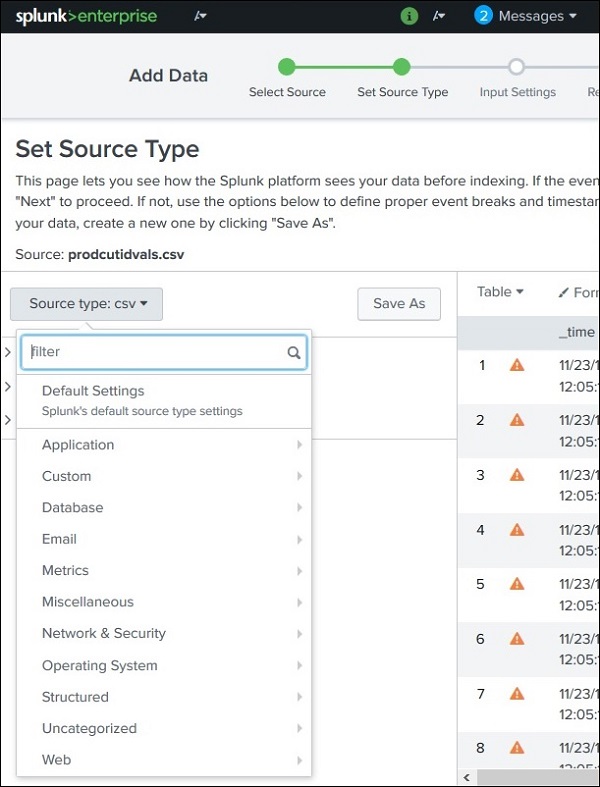
支持的数据源类型
Splunk 支持的源类型可以通过添加数据功能上传文件,然后选择源类型下拉菜单查看。在下图中,我们上传了一个 CSV 文件,然后检查了所有可用的选项。
源类型子类别
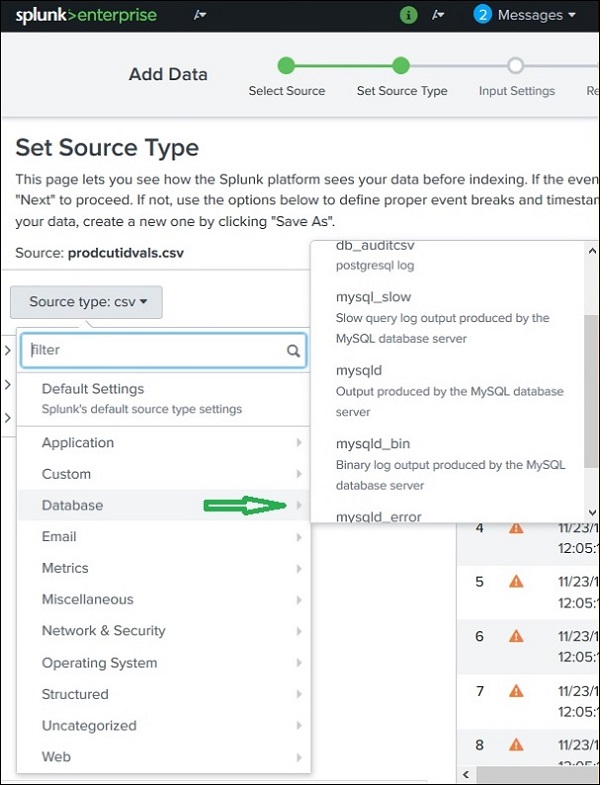
即使在这些类别中,我们也可以进一步点击查看所有支持的子类别。因此,当您选择数据库类别时,您可以找到不同类型的数据库及其Splunk可以识别的支持文件。
预训练源类型
下表列出了一些 Splunk 识别的重要预训练源类型:
| 源类型名称 | 性质 |
|---|---|
| access_combined | NCSA 组合格式 http web 服务器日志(可由 Apache 或其他 web 服务器生成) |
| access_combined_wcookie | NCSA 组合格式 http web 服务器日志(可由 Apache 或其他 web 服务器生成),在末尾添加了 cookie 字段 |
| apache_error | 标准 Apache web 服务器错误日志 |
| linux_messages_syslog | 标准 Linux syslog(大多数平台上的 /var/log/messages) |
| log4j | 任何使用 log4j 的 J2EE 服务器生成的 Log4j 标准输出 |
| mysqld_error | 标准 MySQL 错误日志 |
Splunk - 基本搜索
Splunk 具有强大的搜索功能,使您可以搜索所有已摄取的数据集。此功能可通过名为搜索和报告的应用程序访问,登录 web 界面后可在左侧边栏中看到。
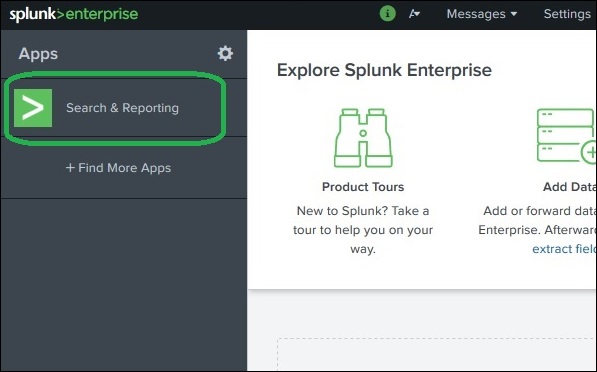
点击搜索和报告应用程序后,会出现一个搜索框,我们可以在其中开始搜索之前章节中上传的日志数据。
我们按照如下所示的格式键入主机名,然后单击最右角的搜索图标。这将给出突出显示搜索词的结果。
组合搜索词
我们可以将用于搜索的词语组合起来,方法是将它们一个接一个地写出来,但将用户搜索字符串放在双引号中。
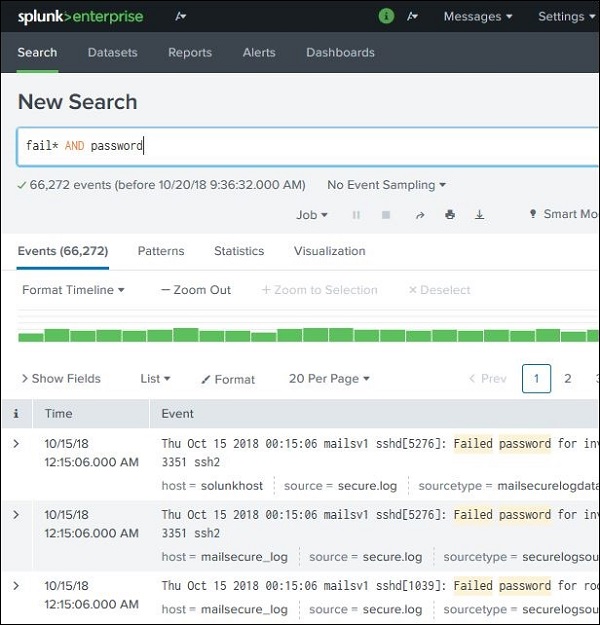
使用通配符
我们可以在搜索选项中使用通配符,并结合使用AND/OR运算符。在下述搜索中,我们得到的结果是日志文件中包含包含 fail、failed、failure 等词语,以及同一行中包含 password 词语的结果。
细化搜索结果
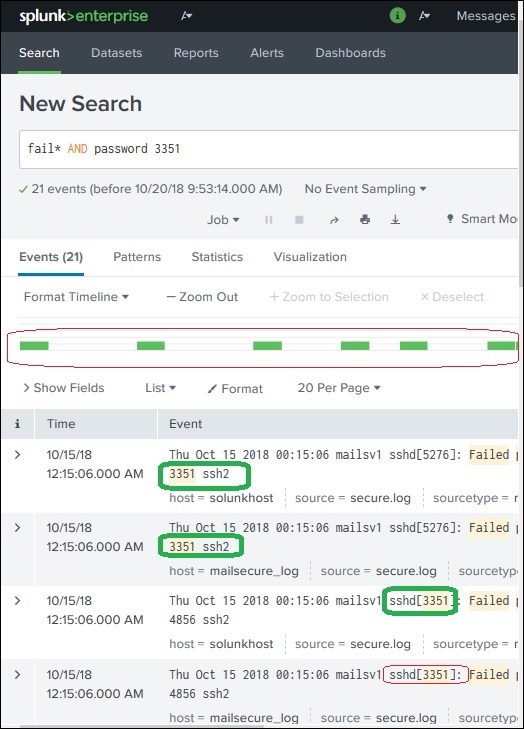
我们可以通过选择一个字符串并将其添加到搜索中来进一步细化搜索结果。在下面的示例中,我们单击字符串3351并选择添加到搜索选项。
将3351添加到搜索词后,我们将得到以下结果,其中仅显示日志中包含 3351 的那些行。还要注意搜索结果的时间线是如何随着我们细化搜索而变化的。
Splunk - 字段搜索
当 Splunk 读取上传的机器数据时,它会解释数据并将其划分为许多字段,这些字段表示关于整个数据记录的单个逻辑事实。
例如,单个信息记录可能包含服务器名称、事件时间戳、正在记录的事件类型(登录尝试或 http 响应等)。即使对于非结构化数据,Splunk 也会尝试将字段划分为键值对,或根据它们的数据类型(数字和字符串等)进行分离。
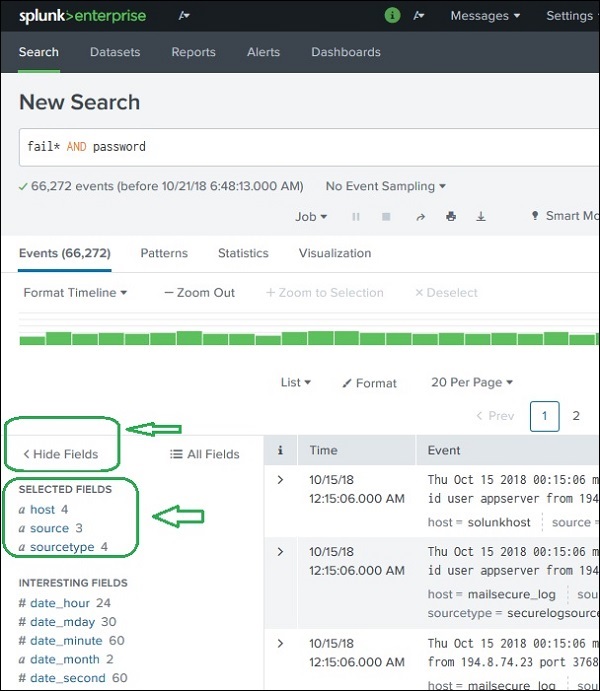
继续使用上一章中上传的数据,我们可以通过单击显示字段链接查看secure.log文件的字段,这将打开以下屏幕。我们可以注意到 Splunk 从此日志文件中生成的字段。
选择字段
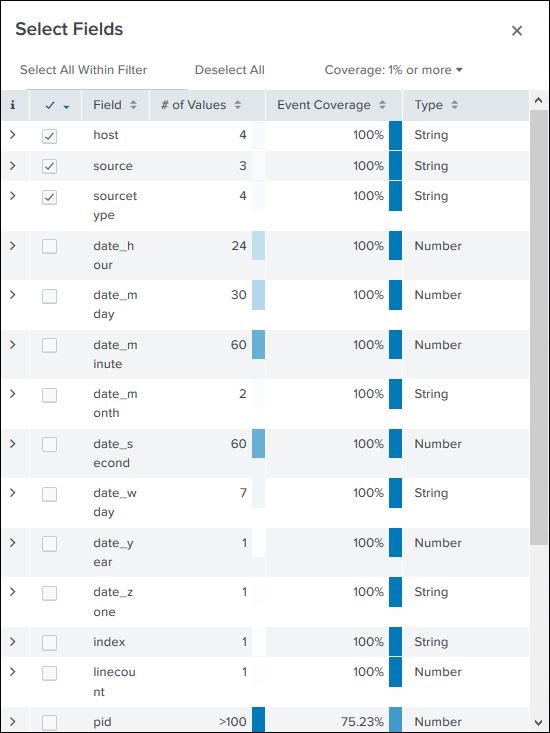
我们可以通过从所有字段列表中选择或取消选择字段来选择要显示的字段。单击所有字段将打开一个窗口,显示所有字段的列表。其中一些字段带有复选标记,表明它们已被选中。我们可以使用复选框来选择要显示的字段。
除了字段名称外,它还显示字段的不同值的个数、其数据类型以及此字段出现在多少百分比的事件中。
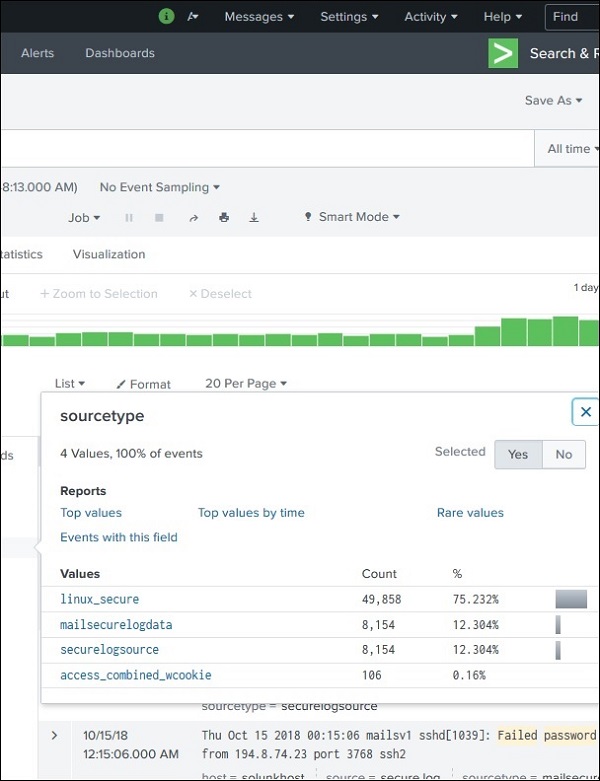
字段摘要
通过单击字段名称,可以获得每个选中字段的非常详细的统计信息。它显示字段的所有不同值、其计数和百分比。
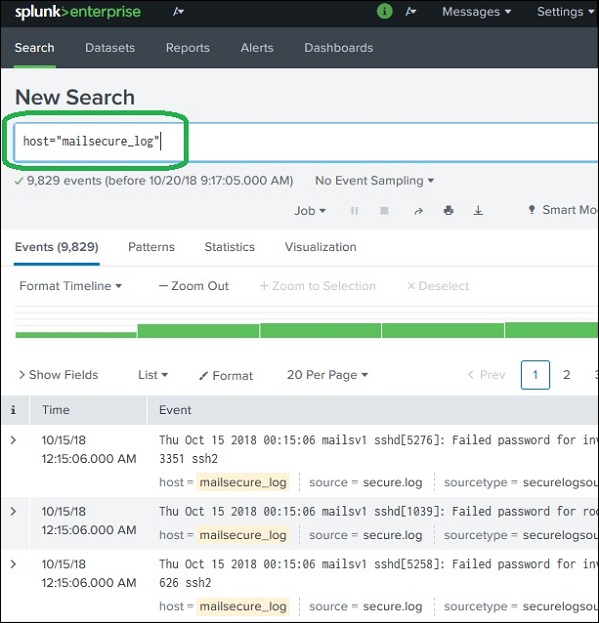
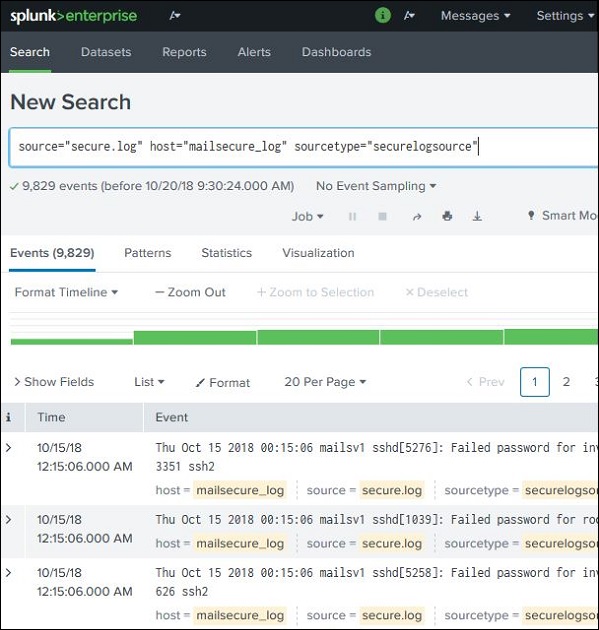
在搜索中使用字段
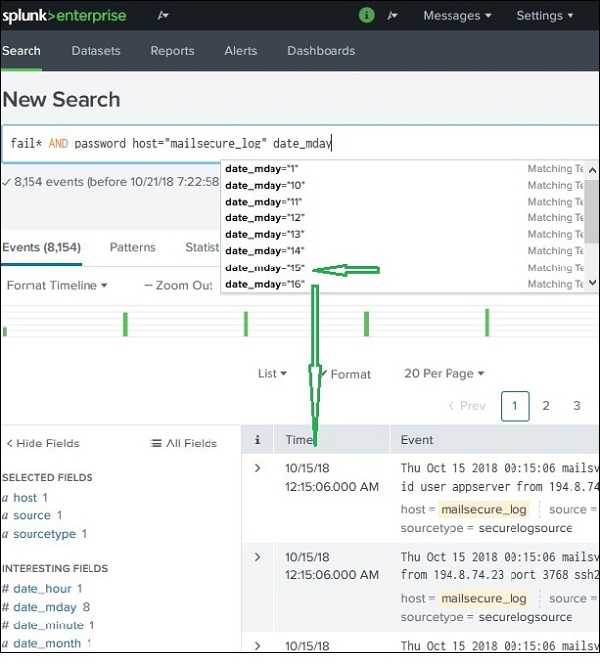
字段名称也可以与搜索的特定值一起插入搜索框中。在下面的示例中,我们的目标是查找主机名为mailsecure_log的 10 月 15 日的所有记录。我们将获得此特定日期的结果。
Splunk - 时间范围搜索
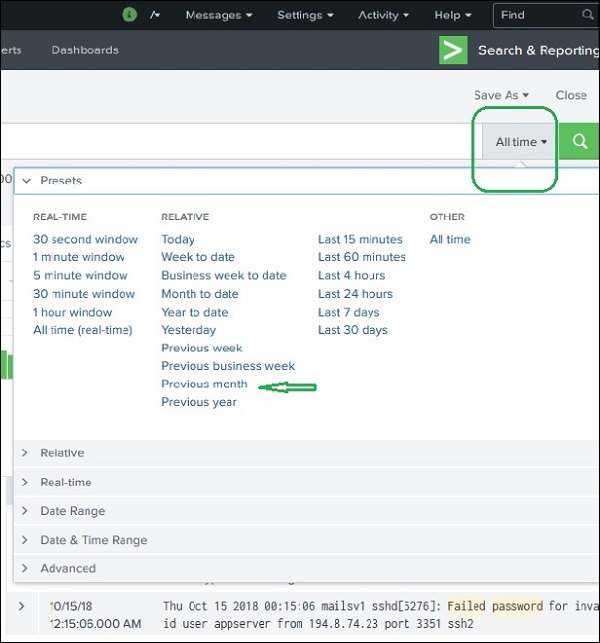
Splunk web 界面显示时间线,指示事件在一段时间内的分布。您可以从中选择特定时间范围的预设时间间隔,也可以根据您的需要自定义时间范围。
下图显示了各种预设时间线选项。选择任何这些选项只会获取特定时间段的数据,您还可以使用可用的自定义时间线选项进一步分析这些数据。
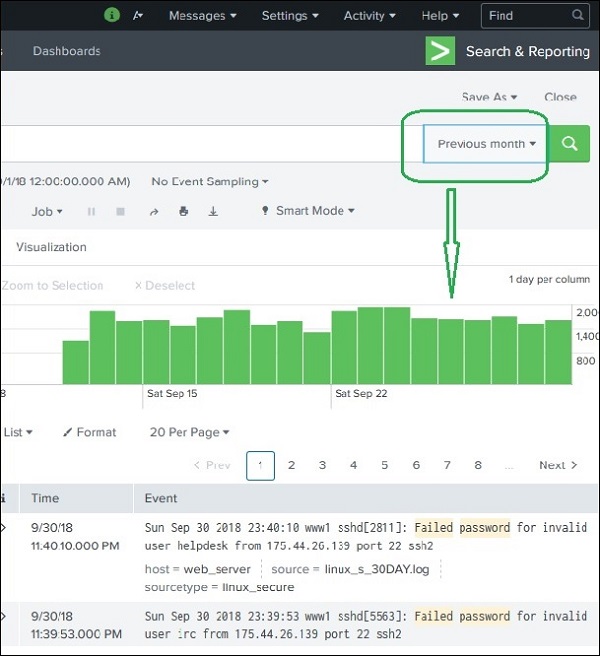
例如,选择上个月选项只会给我们上个月的结果,如下面的时间线图表所示。
选择时间子集
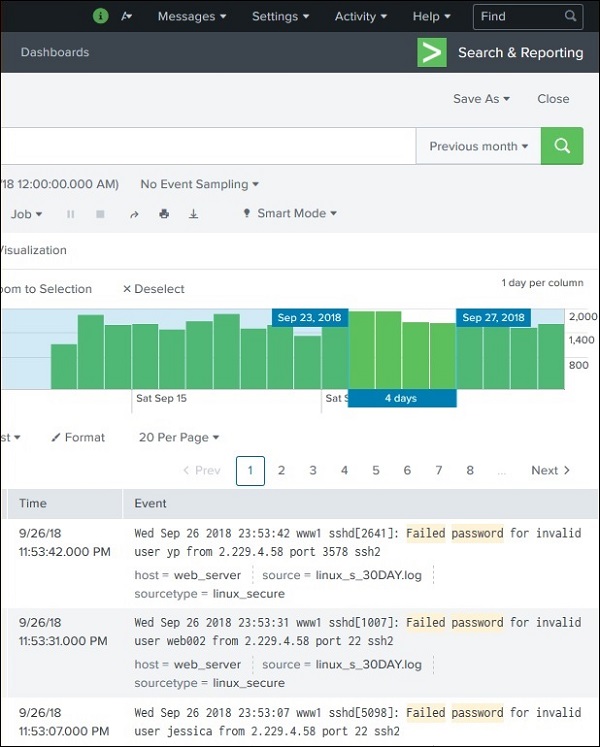
通过单击并拖动时间线上的条形图,我们可以选择已存在结果的子集。这不会导致查询重新执行。它只会从现有结果集中过滤掉记录。
下图显示了从结果集中选择子集:
最早和最晚
earliest 和 latest 这两个命令可以在搜索栏中使用,以指示您从中过滤结果的时间范围。这类似于选择时间子集,但它是通过命令而不是单击特定时间线条的选项来实现的。因此,它提供了对您可以选择用于分析的数据范围的更精细的控制。
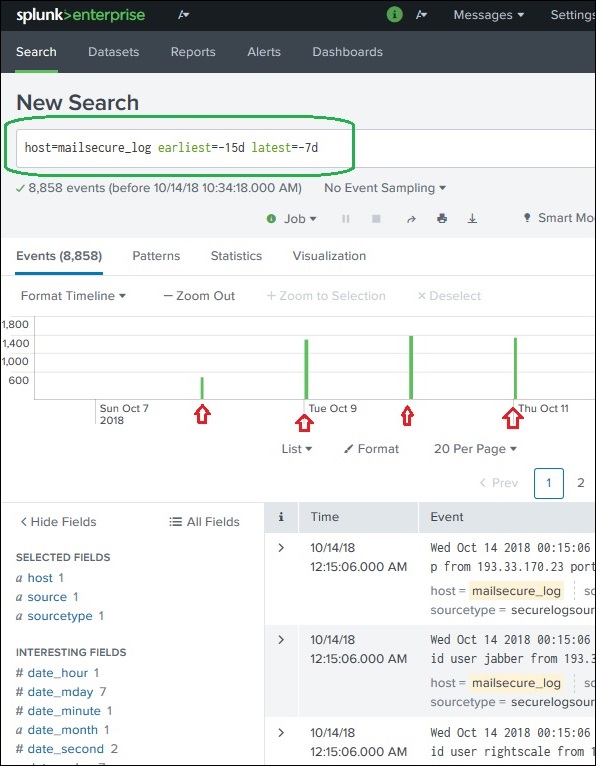
在上图中,我们给出了从过去 7 天到过去 15 天的时间范围。因此,将显示这两天之间的数据。
附近事件
我们还可以通过提及我们希望过滤事件的接近程度来查找特定时间的附近事件。我们可以选择间隔的比例,例如秒、分钟、天和周等。
Splunk - 共享导出
运行搜索查询时,结果将作为作业存储在 Splunk 服务器中。虽然此作业是由一个特定用户创建的,但它可以与其他用户共享,以便他们可以使用此结果集,而无需再次构建查询。结果还可以导出并保存为文件,这些文件可以与不使用 Splunk 的用户共享。
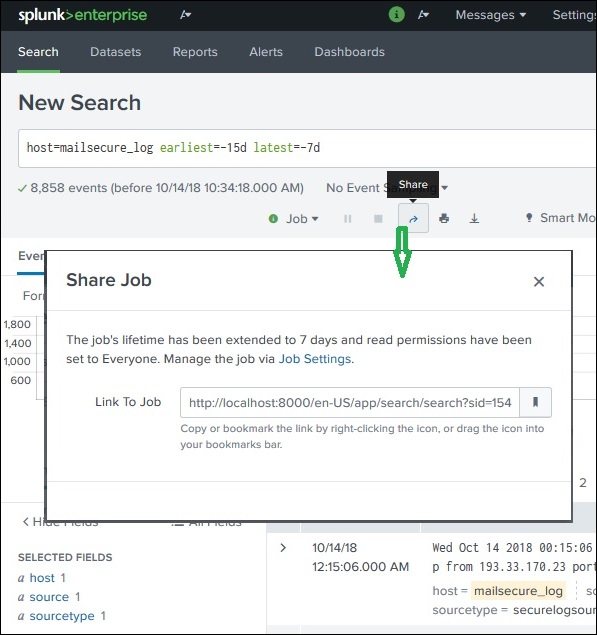
共享搜索结果
查询成功运行后,我们可以在网页的中间右侧看到一个小的向上箭头。单击此图标将提供一个 URL,可以通过该 URL 访问查询和结果。需要向将使用此链接的用户授予权限。权限是通过 Splunk 管理界面授予的。
查找保存的结果
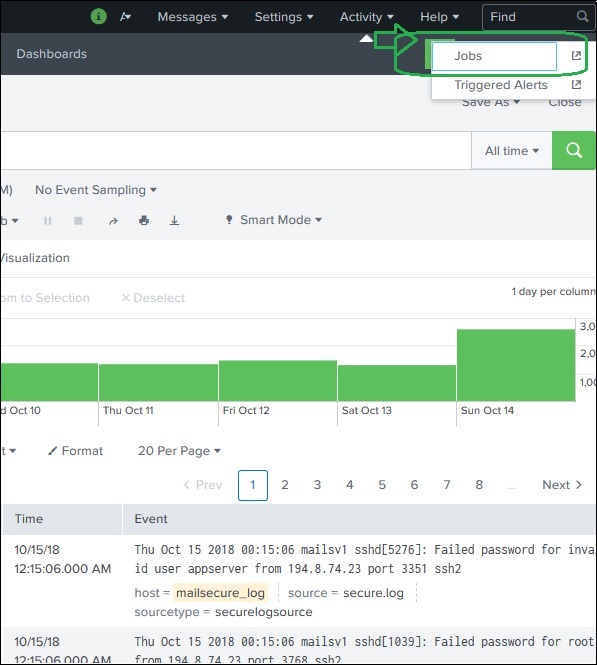
保存供所有具有相应权限的用户使用的作业可以通过查看 Splunk 界面右上角活动菜单下的作业链接来找到。在下图中,我们单击名为作业的突出显示链接以查找保存的作业。
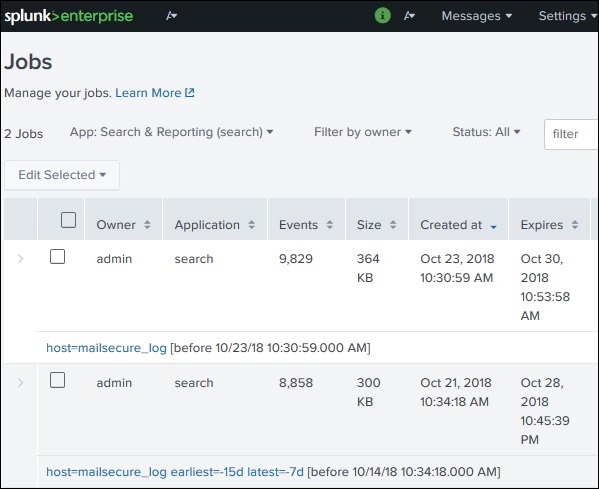
单击上述链接后,我们将获得所有保存作业的列表,如下所示。需要注意的是,有一个过期日期,在此日期之后,保存的作业将自动从 Splunk 中删除。您可以通过选择作业并单击“编辑所选”,然后选择“延长过期时间”来调整此日期。
导出搜索结果
我们还可以将搜索结果导出到文件中。可用于导出的三种不同格式是:CSV、XML 和 JSON。选择格式后单击“导出”按钮将从本地浏览器下载文件到本地系统。这在下图中进行了说明:
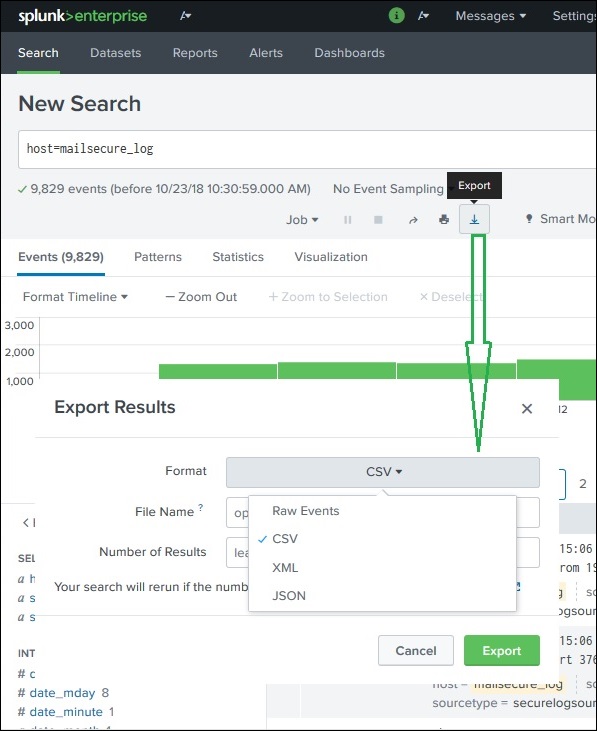
Splunk - 搜索语言
Splunk 搜索处理语言 (SPL) 是一种包含许多命令、函数、参数等的语言,用于从数据集中获取所需结果。例如,当您获得搜索词的结果集时,您可能希望进一步从结果集中过滤一些更具体的词语。为此,需要将一些附加命令添加到现有命令中。这可以通过学习 SPL 的用法来实现。
SPL 的组件
SPL 具有以下组件。
搜索词 - 这些是您要查找的关键字或短语。
命令 - 您要对结果集执行的操作,例如格式化结果或计数结果。
函数 - 您将对结果应用哪些计算。例如 Sum、Average 等。
子句 - 如何对结果集中的字段进行分组或重命名。
让我们在下节中借助图像讨论所有组件:
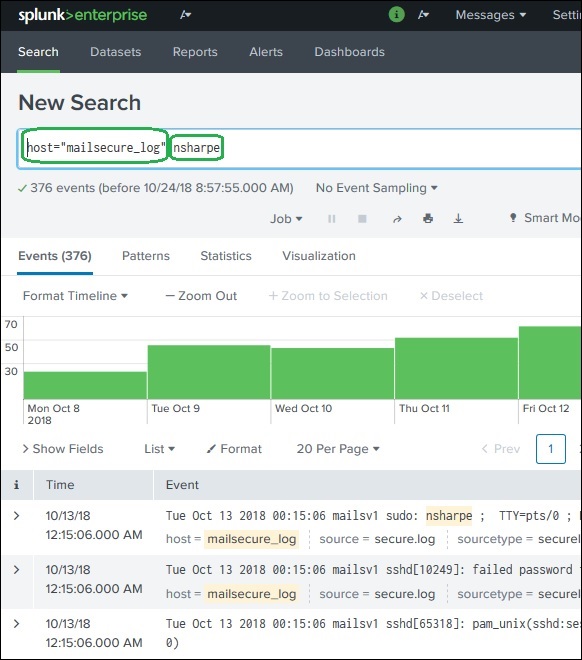
搜索词
这些是您在搜索栏中提到的词语,用于从满足搜索条件的数据集中获取特定记录。在下面的示例中,我们正在搜索包含两个突出显示的词语的记录。
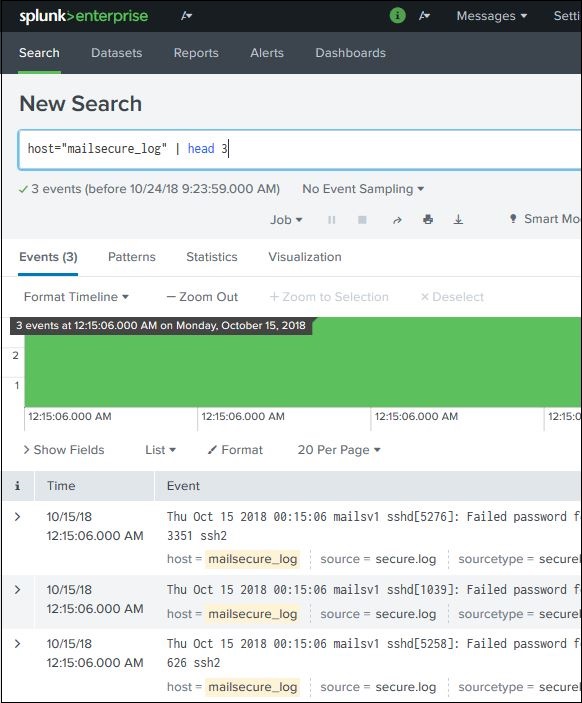
命令
您可以使用 SPL 提供的许多内置命令来简化分析结果集中数据的过程。在下面的示例中,我们使用 head 命令从搜索操作中过滤掉前 3 个结果。
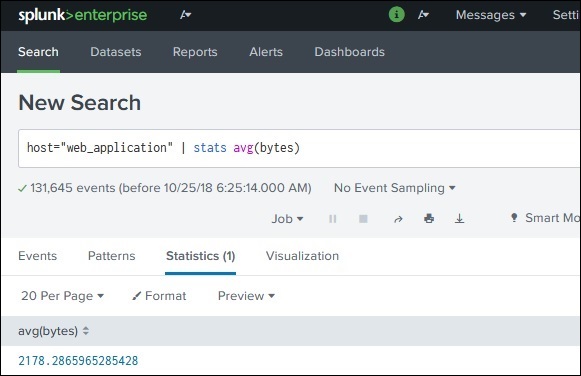
函数
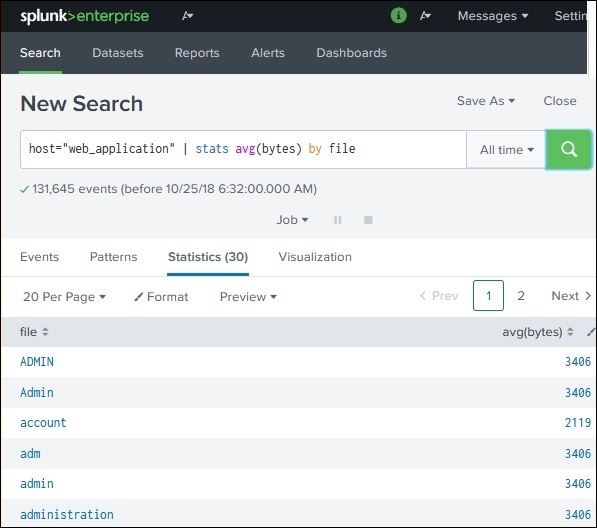
除了命令之外,Splunk 还提供许多内置函数,这些函数可以从正在分析的字段中获取输入,并在对该字段应用计算后给出输出。在下面的示例中,我们使用Stats avg()函数计算作为输入的数字字段的平均值。
子句
当我们想要按某些特定字段对结果进行分组,或者想要重命名输出中的字段时,我们分别使用group by子句和 as 子句。在下面的示例中,我们获取web_application日志中每个文件平均字节大小。如您所见,结果显示每个文件的名称以及每个文件的平均字节数。