- Spring Batch 教程
- Spring Batch - 首页
- Spring Batch - 概述
- Spring Batch - 环境
- Spring Batch - 架构
- Spring Batch - 应用
- Spring Batch - 配置
- 读取器、写入器和处理器
- Spring Batch - 基础应用
- Spring Batch - XML 到 MySQL
- Spring Batch - CSV 到 XML
- Spring Batch - MySQL 到 XML
- Spring Batch - MySQL 到平面文件
- Spring Batch 有用资源
- Spring Batch - 快速指南
- Spring Batch - 有用资源
- Spring Batch - 讨论
Spring Batch - 架构
以下是 Spring Batch 架构的图示。如图所示,该架构包含三个主要组件,即 **应用程序、批处理核心** 和 **批处理基础设施**。
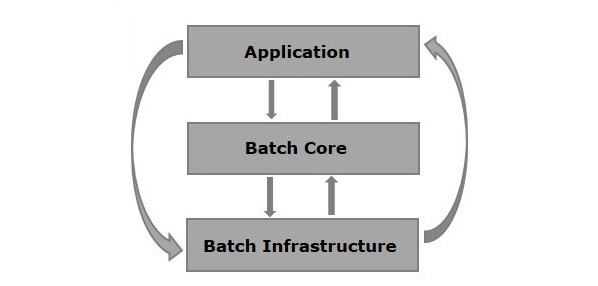
**应用程序** - 此组件包含所有作业以及我们使用 Spring Batch 框架编写的代码。
**批处理核心** - 此组件包含控制和启动批处理作业所需的所有 API 类。
**批处理基础设施** - 此组件包含应用程序和批处理核心组件使用的读取器、写入器和服务。
Spring Batch 的组件
下图显示了 Spring Batch 的不同组件以及它们是如何相互连接的。
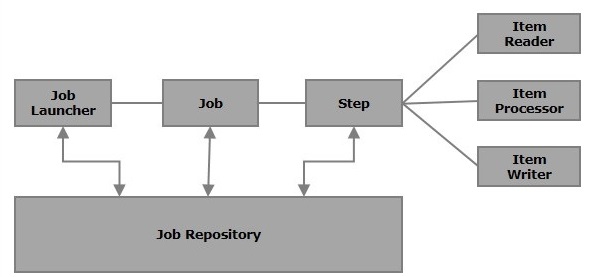
作业
在 Spring Batch 应用程序中,作业是要执行的批处理过程。它从头到尾运行,不会中断。此作业进一步细分为步骤(或作业包含步骤)。
我们将在 Spring Batch 中使用 XML 文件或 Java 类配置作业。以下是 Spring Batch 中作业的 XML 配置。
<job id = "jobid"> <step id = "step1" next = "step2"/> <step id = "step2" next = "step3"/> <step id = "step3"/> </job>
批处理作业在 <job></job> 标签内配置。它有一个名为 **id** 的属性。在这些标签内,我们定义步骤的定义和顺序。
**可重启** - 通常,当作业正在运行并且我们尝试再次启动它时,这被视为 **重启**,它将再次启动。为了避免这种情况,您需要将 **restartable** 值设置为 **false**,如下所示。
<job id = "jobid" restartable = "false" > </job>
步骤
**步骤** 是作业的独立部分,其中包含定义和执行作业(其部分)的必要信息。
如图表所示,每个步骤都由 ItemReader、ItemProcessor(可选)和 ItemWriter 组成。**作业可以包含一个或多个步骤**。
读取器、写入器和处理器
**项读取器** 从特定来源读取数据到 Spring Batch 应用程序,而 **项写入器** 将数据从 Spring Batch 应用程序写入特定目标。
**项处理器** 是一个包含处理代码的类,该代码处理读取到 Spring Batch 中的数据。如果应用程序读取 **“n”** 条记录,则处理器中的代码将在每条记录上执行。
当没有给出读取器和写入器时,**任务** 充当 SpringBatch 的处理器。它只处理单个任务。例如,如果我们正在编写一个包含简单步骤的作业,其中我们从 MySQL 数据库读取数据并对其进行处理并将其写入文件(平面),则我们的步骤使用 -
一个 **读取器**,它从 MySQL 数据库读取数据。
一个 **写入器**,它写入平面文件。
一个 **自定义处理器**,它根据我们的意愿处理数据。
<job id = "helloWorldJob">
<step id = "step1">
<tasklet>
<chunk reader = "mysqlReader" writer = "fileWriter"
processor = "CustomitemProcessor" ></chunk>
</tasklet>
</step>
</ job>
Spring Batch 提供了很长的 **读取器** 和 **写入器** 列表。使用这些预定义类,我们可以为它们定义 Bean。我们将在后面的章节中更详细地讨论 **读取器** 和 **写入器**。
JobRepository
Spring Batch 中的 Job 存储库为 JobLauncher、Job 和 Step 实现提供创建、检索、更新和删除 (CRUD) 操作。我们将在 XML 文件中定义作业存储库,如下所示。
<job-repository id = "jobRepository"/>
除了 **id** 之外,还有一些其他(可选)选项可用。以下是具有所有选项及其默认值的作业存储库配置。
<job-repository id = "jobRepository" data-source = "dataSource" transaction-manager = "transactionManager" isolation-level-for-create = "SERIALIZABLE" table-prefix = "BATCH_" max-varchar-length = "1000"/>
**内存存储库** - 如果您不想在数据库中持久化 Spring Batch 的域对象,您可以配置作业存储库的内存版本,如下所示。
<bean id = "jobRepository" class = "org.springframework.batch.core.repository.support.MapJobRepositoryFactoryBean "> <property name = "transactionManager" ref = "transactionManager"/> </bean>
JobLauncher
JobLauncher 是一个接口,它使用 **给定的参数集** 启动 Spring Batch 作业。**SampleJoblauncher** 是实现 **JobLauncher** 接口的类。以下是 JobLauncher 的配置。
<bean id = "jobLauncher" class = "org.springframework.batch.core.launch.support.SimpleJobLauncher"> <property name = "jobRepository" ref = "jobRepository" /> </bean>
JobInstance
**JobInstance** 表示作业的逻辑运行;当我们运行作业时,它会被创建。每个作业实例都通过作业的名称和运行时传递给它的参数来区分。
如果 JobInstance 执行失败,则可以再次执行相同的 JobInstance。因此,每个 JobInstance 可以有多个作业执行。
JobExecution 和 StepExecution
JobExecution 和 StepExecution 是作业/步骤执行的表示。它们包含作业/步骤的运行信息,例如开始时间(作业/步骤)、结束时间(作业/步骤)。