Spring Cloud - 快速指南
Spring Cloud - 简介
在深入了解 Spring Cloud 之前,让我们先简要概述一下微服务架构以及 Spring Boot 在创建微服务中的作用。
微服务架构
微服务架构是一种应用程序开发风格,其中应用程序被分解成小的服务,并且这些服务之间具有松耦合关系。以下是使用微服务架构的主要优势:
易于维护 - 微服务规模小,并且应该只处理单个业务任务。因此,它们易于开发和维护。
独立扩展和部署 - 微服务具有其独立的部署模式和节奏。因此,每个服务可以根据其需要处理的负载进行扩展。每个服务都可以根据其计划进行部署。
独立的技术使用 - 微服务的代码库与其部署环境隔离,因此可以根据用例决定微服务需要使用的语言和技术。无需在所有微服务中使用通用技术栈。
有关微服务架构的更多详细信息,请参阅 微服务架构
Spring Boot
Spring Boot 是一个基于 Java 的框架,用于创建微服务架构中使用的微服务。它进一步缩短了开发 Spring 应用程序所需的时间。以下是它提供的主要好处:
易于理解和开发 Spring 应用程序
提高生产力
缩短开发时间
有关 Spring Boot 的更多信息,请参阅 - Spring Boot
Spring Cloud
Spring Cloud 提供了一系列组件,这些组件在构建云中的分布式应用程序方面非常有用。我们可以自己开发这些组件,但这会浪费时间来开发和维护这些样板代码。
这就是 Spring Cloud 发挥作用的地方。它为分布式环境中常见的难题提供了现成的云模式。它试图解决的一些模式包括:
分布式消息
负载均衡
断路器
路由
分布式日志
服务注册
分布式锁
集中式配置
因此,它成为开发需要高可扩展性、性能和可用性的应用程序的非常有用的框架。
在本教程中,我们将介绍上面列出的 Spring Cloud 组件。
使用 Spring Cloud 的好处
开发人员专注于业务逻辑 - Spring Cloud 提供了所有样板代码来实现云的常见设计模式。因此,开发人员可以专注于业务逻辑,而无需开发和维护这些样板代码。
快速开发时间 - 由于开发人员可以免费获得样板代码,因此他们可以在保持代码质量的同时快速交付所需的项目。
易于使用 - Spring Cloud 项目可以轻松地与现有的 Spring 项目集成。
活跃的项目 - Spring Cloud 由 Pivotal(Spring 背后的公司)积极维护。因此,我们只需升级 Spring Cloud 版本即可免费获得所有新功能和错误修复。
微服务架构具有多种优势;但是,它最关键的缺点之一是在分布式环境中的部署。并且对于分布式系统,我们有一些常见的问题经常出现,例如:
服务 A 如何知道在哪里联系服务 B,即服务 B 的地址?
多个服务如何相互通信,即使用什么协议?
我们如何监控环境中的各种服务?
我们如何将服务的配置与服务实例一起分发?
我们如何链接跨服务的调用以进行调试?
等等…
这些是 Spring Cloud 试图解决并提供通用解决方案的一系列问题。
虽然Spring Boot 用于快速应用程序开发,但将其与 Spring Cloud 一起使用可以减少我们在开发和部署到分布式环境中的微服务集成时间。
Spring Cloud 组件
现在让我们看一下 Spring Cloud 提供的各种组件以及这些组件解决的问题
| 问题 | 组件 |
|---|---|
| 分布式云配置 | Spring Cloud Config,Spring Cloud Zookeeper,Spring Consul Config |
| 分布式消息 | Spring Stream 与 Kafka,Spring Stream 与 RabbitMQ |
| 服务发现 | Spring Cloud Eureka,Spring Cloud Consul,Spring Cloud Zookeeper |
| 日志记录 | Spring Cloud Zipkin,Spring Cloud Sleuth |
| Spring 服务通信 | Spring Hystrix,Spring Ribbon,Spring Feign,Spring Zuul |
我们将在接下来的章节中介绍其中一些组件。
Spring Cloud 和 Spring Boot 之间的区别
这是在开始使用 Spring Cloud 时经常出现的一个非常常见的问题。实际上,这里没有可比性。Spring Cloud 和 Spring Boot 用于实现不同的目标。
Spring Boot 是一个用于更快应用程序开发的 Java 框架,特别是在微服务架构中使用。
Spring Cloud 用于集成这些微服务,以便它们能够在分布式环境中轻松协同工作并相互通信
实际上,为了获得最大的好处,例如更短的开发时间,建议将 Spring Boot 与 Spring Cloud 一起使用。
Spring Cloud - 依赖管理
在本章中,我们将使用 Spring Cloud 构建我们的第一个应用程序。让我们回顾一下 Spring Cloud 应用程序的项目结构和依赖项设置,同时使用 Spring Boot 作为基础框架。
核心依赖项
Spring Cloud 组列出了多个作为依赖项的包。在本教程中,我们将使用 Spring Cloud 组中的多个包。为了避免这些包之间的任何兼容性问题,让我们使用下面给出的 Spring Cloud 依赖项管理 POM:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Hoxton.SR8</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
Gradle 用户可以通过使用以下方式实现相同的功能:
buildscript {
dependencies {
classpath "io.spring.gradle:dependency-management-plugin:1.0.10.RELEASE"
}
}
apply plugin: "io.spring.dependency-management"
dependencyManagement {
imports {
mavenBom "org.springframework.cloud:spring-cloud-dependencies:
'Hoxton.SR8')"
}
}
项目架构和结构
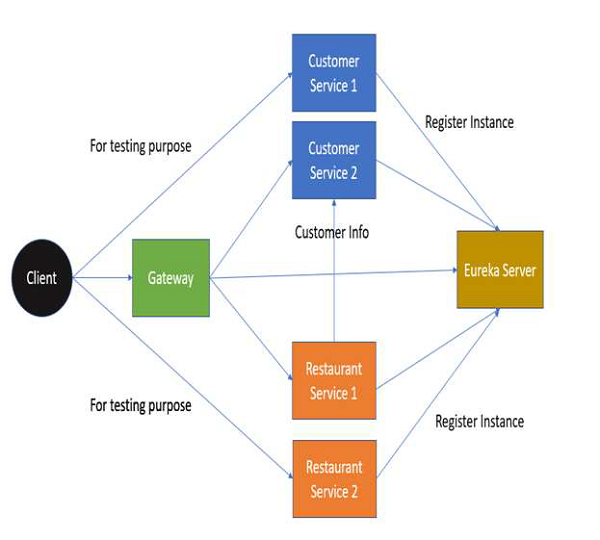
在本教程中,我们将使用餐厅的案例:
餐厅服务发现 - 用于注册服务地址。
餐厅客户服务 - 向客户端和其他服务提供客户信息。
餐厅服务 - 向客户端提供餐厅信息。使用客户服务获取客户的城市信息。
餐厅网关 - 应用程序的入口点。但是,为了简单起见,我们只在本教程中使用一次。
在高层次上,以下是项目架构:
我们将拥有以下项目结构。请注意,我们将在接下来的章节中查看这些文件。
项目 POM
为了简单起见,我们将使用基于 Maven 的构建。以下是我们将在此教程中使用的基本 POM 文件。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.tutorials.point</groupId>
<artifactId>spring-cloud-eureka-client</artifactId>
<version>1.0</version>
<packaging>jar</packaging>
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>2020.0.1</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>2.4.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<executions>
<execution>
<goals>
<goal>repackage</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
需要注意的事项 -
POM 依赖项管理部分几乎包含了我们所需的所有项目。我们将在需要时添加依赖项部分。
我们将使用 Spring Boot 作为应用程序开发的基础框架,这就是为什么您看到它被列为依赖项的原因。
Spring Cloud - 使用 Eureka 进行服务发现
简介
当应用程序作为微服务部署到云中时,服务发现是其中最关键的部分之一。这是因为对于任何使用操作,微服务架构中的应用程序可能都需要访问多个服务,以及它们之间的通信。
服务发现有助于跟踪服务地址以及可以联系服务实例的端口。这里有三个组件在起作用:
服务实例 - 负责处理传入的服务请求并响应这些请求。
服务注册中心 - 跟踪服务实例的地址。服务实例应该向服务注册中心注册其地址。
服务客户端 - 想要访问或想要发出请求并从服务实例获取响应的客户端。服务客户端联系服务注册中心以获取实例的地址。
Apache Zookeeper、Eureka 和 Consul 是几个用于服务发现的知名组件。在本教程中,我们将使用 Eureka
设置 Eureka 服务器/注册中心
要设置 Eureka 服务器,我们需要更新 POM 文件以包含以下依赖项:
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies>
然后,使用正确的注解,即 @EnableEurekaServer,注释我们的 Spring 应用程序类。
package com.tutorialspoint;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.eureka.server.EnableEurekaServer;
@SpringBootApplication
@EnableEurekaServer
public class RestaurantServiceRegistry{
public static void main(String[] args) {
SpringApplication.run(RestaurantServiceRegistry.class, args);
}
}
如果我们想要配置注册中心并更改其默认值,我们还需要一个属性文件。以下是我们将进行的更改:
将端口更新为 8900 而不是默认的 8080
在生产环境中,为了实现高可用性,注册中心将有多个节点。这就是我们需要注册中心之间进行点对点通信的地方。由于我们是在独立模式下执行此操作,因此我们可以简单地将客户端属性设置为false 以避免任何错误。
因此,我们的application.yml 文件如下所示:
server:
port: 8900
eureka:
client:
register-with-eureka: false
fetch-registry: false
就是这样,现在让我们编译项目并使用以下命令运行程序:
java -jar .\target\spring-cloud-eureka-server-1.0.jar
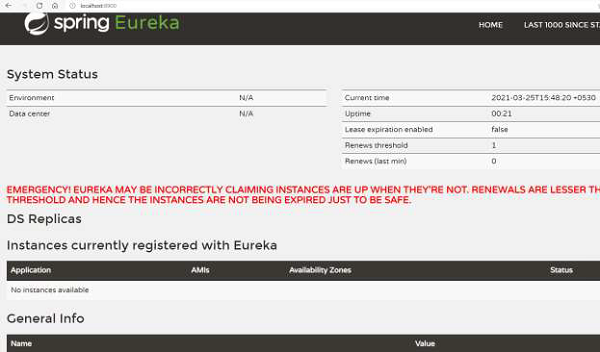
现在我们可以在控制台中看到日志:
... 2021-03-07 13:33:10.156 INFO 17660 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat initialized with port(s): 8900 (http) 2021-03-07 13:33:10.172 INFO 17660 --- [ main] o.apache.catalina.core.StandardService : Starting service [Tomcat] ... 2021-03-07 13:33:16.483 INFO 17660 --- [ main] DiscoveryClientOptionalArgsConfiguration : Eureka HTTP Client uses Jersey ... 2021-03-07 13:33:16.632 INFO 17660 --- [ main] o.s.c.n.eureka.InstanceInfoFactory : Setting initial instance status as: STARTING 2021-03-07 13:33:16.675 INFO 17660 --- [ main] com.netflix.discovery.DiscoveryClient : Initializing Eureka in region useast- 1 2021-03-07 13:33:16.675 INFO 17660 --- [ main] com.netflix.discovery.DiscoveryClient : Client configured to neither register nor query for data. 2021-03-07 13:33:16.686 INFO 17660 --- [ main] com.netflix.discovery.DiscoveryClient : Discovery Client initialized at timestamp 1615104196685 with initial instances count: 0 ... 2021-03-07 13:33:16.873 INFO 17660 --- [ Thread-10] e.s.EurekaServerInitializerConfiguration : Started Eureka Server 2021-03-07 13:33:18.609 INFO 17660 --- [ main] c.t.RestaurantServiceRegistry : Started RestaurantServiceRegistry in 15.219 seconds (JVM running for 16.068)
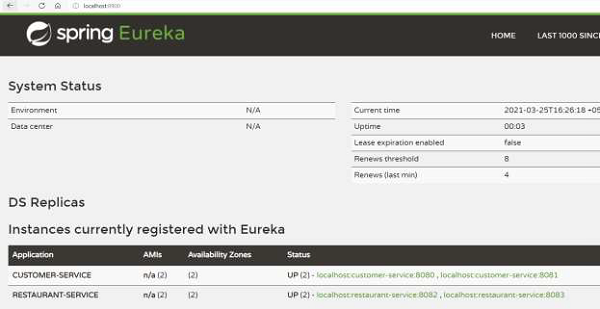
从上面的日志中可以看到,Eureka 注册中心已经设置好了。我们还获得了 Eureka 的仪表盘(参见下图),它托管在服务器 URL 上。
为实例设置 Eureka 客户端
现在,我们将设置服务实例,这些实例将注册到 Eureka 服务器。要设置 Eureka 客户端,我们将使用一个单独的 Maven 项目,并更新 POM 文件以包含以下依赖项:
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies>
然后,使用正确的注解,即 @EnableDiscoveryClient,注释我们的 Spring 应用程序类。
package com.tutorialspoint;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
@SpringBootApplication
@EnableDiscoveryClient
public class RestaurantCustomerService{
public static void main(String[] args) {
SpringApplication.run(RestaurantCustomerService.class, args);
}
}
如果我们想要配置客户端并更改其默认值,我们还需要一个属性文件。以下是我们将进行的更改:
我们将在运行时提供 jar 执行时的端口。
我们将指定 Eureka 服务器正在运行的 URL。
因此,我们的 application.yml 文件如下所示
spring:
application:
name: customer-service
server:
port: ${app_port}
eureka:
client:
serviceURL:
defaultZone: https://:8900/eureka
为了执行,我们将有两个服务实例运行。为此,让我们打开两个 shell,然后在一个 shell 上执行以下命令:
java -Dapp_port=8081 -jar .\target\spring-cloud-eureka-client-1.0.jar
并在另一个 shell 上执行以下命令:
java -Dapp_port=8082 -jar .\target\spring-cloud-eureka-client-1.0.jar
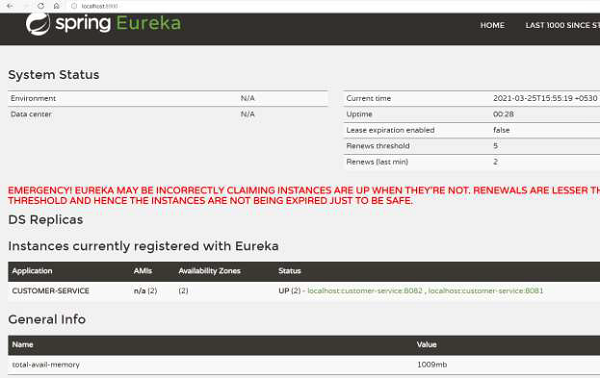
现在我们可以在控制台中看到日志:
... 2021-03-07 15:22:22.474 INFO 16920 --- [ main] com.netflix.discovery.DiscoveryClient : Starting heartbeat executor: renew interval is: 30 2021-03-07 15:22:22.482 INFO 16920 --- [ main] c.n.discovery.InstanceInfoReplicator : InstanceInfoReplicator onDemand update allowed rate per min is 4 2021-03-07 15:22:22.490 INFO 16920 --- [ main] com.netflix.discovery.DiscoveryClient : Discovery Client initialized at timestamp 1615110742488 with initial instances count: 0 2021-03-07 15:22:22.492 INFO 16920 --- [ main] o.s.c.n.e.s.EurekaServiceRegistry : Registering application CUSTOMERSERVICE with eureka with status UP 2021-03-07 15:22:22.494 INFO 16920 --- [ main] com.netflix.discovery.DiscoveryClient : Saw local status change event StatusChangeEvent [timestamp=1615110742494, current=UP, previous=STARTING] 2021-03-07 15:22:22.500 INFO 16920 --- [nfoReplicator-0] com.netflix.discovery.DiscoveryClient : DiscoveryClient_CUSTOMERSERVICE/ localhost:customer-service:8081: registering service... 2021-03-07 15:22:22.588 INFO 16920 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port(s): 8081 (http) with context path '' 2021-03-07 15:22:22.591 INFO 16920 --- [ main] .s.c.n.e.s.EurekaAutoServiceRegistration : Updating port to 8081 2021-03-07 15:22:22.705 INFO 16920 --- [nfoReplicator-0] com.netflix.discovery.DiscoveryClient : DiscoveryClient_CUSTOMERSERVICE/ localhost:customer-service:8081 - registration status: 204 ...
从上面的日志可以看出,客户端实例已经设置好了。我们还可以查看之前看到的 Eureka Server 仪表盘。可以看到,Eureka 服务器知道有两个“CUSTOMER-SERVICE”实例正在运行。
Eureka 客户端消费者示例
我们的 Eureka 服务器已经获得了“Customer-Service”的注册客户端实例。现在,我们可以设置消费者,它可以向 Eureka 服务器请求“Customer-Service”节点的地址。
为此,让我们添加一个控制器,它可以从 Eureka 注册表获取信息。此控制器将添加到我们之前的 Eureka 客户端本身,即“Customer Service”。让我们为客户端创建以下控制器。
package com.tutorialspoint;
import java.util.List;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.cloud.client.ServiceInstance;
import org.springframework.cloud.client.discovery.DiscoveryClient;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
class RestaurantCustomerInstancesController {
@Autowired
private DiscoveryClient eurekaConsumer;
@RequestMapping("/customer_service_instances")
请注意注释 @DiscoveryClient,它是 Spring 框架提供的与注册表通信的方式。
现在让我们重新编译我们的 Eureka 客户端。为了执行,我们将运行两个服务实例。为此,让我们打开两个 shell,然后在一个 shell 上执行以下命令:
java -Dapp_port=8081 -jar .\target\spring-cloud-eureka-client-1.0.jar
并在另一个 shell 上执行以下命令:
java -Dapp_port=8082 -jar .\target\spring-cloud-eureka-client-1.0.jar
一旦两个 shell 上的客户端都启动,我们就可以访问我们在控制器中创建的 https://:8081/customer_service_instances。此 URL 显示了有关这两个实例的完整信息。
[
{
"scheme": "http",
"host": "localhost",
"port": 8081,
"metadata": {
"management.port": "8081"
},
"secure": false,
"instanceInfo": {
"instanceId": "localhost:customer-service:8081",
"app": "CUSTOMER-SERVICE",
"appGroupName": null,
"ipAddr": "10.0.75.1",
"sid": "na",
"homePageUrl": "https://:8081/",
"statusPageUrl": "https://:8081/actuator/info",
"healthCheckUrl": "https://:8081/actuator/health",
"secureHealthCheckUrl": null,
"vipAddress": "customer-service",
"secureVipAddress": "customer-service",
"countryId": 1,
"dataCenterInfo": {
"@class": "com.netflix.appinfo.InstanceInfo$DefaultDataCenterInfo",
"name": "MyOwn"
},
"hostName": "localhost",
"status": "UP",
"overriddenStatus": "UNKNOWN",
"leaseInfo": {
"renewalIntervalInSecs": 30,
"durationInSecs": 90,
"registrationTimestamp": 1616667914313,
"lastRenewalTimestamp": 1616667914313,
"evictionTimestamp": 0,
"serviceUpTimestamp": 1616667914313
},
"isCoordinatingDiscoveryServer": false,
"metadata": {
"management.port": "8081"
},
"lastUpdatedTimestamp": 1616667914313,
"lastDirtyTimestamp": 1616667914162,
"actionType": "ADDED",
"asgName": null
},
"instanceId": "localhost:customer-service:8081",
"serviceId": "CUSTOMER-SERVICE",
"uri": "https://:8081"
},
{
"scheme": "http",
"host": "localhost",
"port": 8082,
"metadata": {
"management.port": "8082"
},
"secure": false,
"instanceInfo": {
"instanceId": "localhost:customer-service:8082",
"app": "CUSTOMER-SERVICE",
"appGroupName": null,
"ipAddr": "10.0.75.1",
"sid": "na",
"homePageUrl": "https://:8082/",
"statusPageUrl": "https://:8082/actuator/info",
"healthCheckUrl": "https://:8082/actuator/health",
"secureHealthCheckUrl": null,
"vipAddress": "customer-service",
"secureVipAddress": "customer-service",
"countryId": 1,
"dataCenterInfo": {
"@class": "com.netflix.appinfo.InstanceInfo$DefaultDataCenterInfo",
"name": "MyOwn"
},
"hostName": "localhost",
"status": "UP",
"overriddenStatus": "UNKNOWN",
"leaseInfo": {
"renewalIntervalInSecs": 30,
"durationInSecs": 90,
"registrationTimestamp": 1616667913690,
"lastRenewalTimestamp": 1616667913690,
"evictionTimestamp": 0,
"serviceUpTimestamp": 1616667913690
},
"isCoordinatingDiscoveryServer": false,
"metadata": {
"management.port": "8082"
},
"lastUpdatedTimestamp": 1616667913690,
"lastDirtyTimestamp": 1616667913505,
"actionType": "ADDED",
"asgName": null
},
"instanceId": "localhost:customer-service:8082",
"serviceId": "CUSTOMER-SERVICE",
"uri": "https://:8082"
}
]
Eureka 服务器 API
Eureka 服务器为客户端实例或服务提供了各种 API 来进行通信。许多这些 API 都是抽象的,可以直接使用我们之前定义和使用的 @DiscoveryClient。需要注意的是,它们的 HTTP 对应项也存在,对于非 Spring 框架使用 Eureka 很有用。
事实上,我们之前使用的 API,即获取有关运行“Customer_Service”的客户端的信息,也可以通过浏览器使用 https://:8900/eureka/apps/customer-service 调用,如下所示:
<application slick-uniqueid="3">
<div>
<a id="slick_uniqueid"/>
</div>
<name>CUSTOMER-SERVICE</name>
<instance>
<instanceId>localhost:customer-service:8082</instanceId>
<hostName>localhost</hostName>
<app>CUSTOMER-SERVICE</app>
<ipAddr>10.0.75.1</ipAddr>
<status>UP</status>
<overriddenstatus>UNKNOWN</overriddenstatus>
<port enabled="true">8082</port>
<securePort enabled="false">443</securePort>
<countryId>1</countryId>
<dataCenterInfo
class="com.netflix.appinfo.InstanceInfo$DefaultDataCenterInfo">
<name>MyOwn</name>
</dataCenterInfo>
<leaseInfo>
<renewalIntervalInSecs>30</renewalIntervalInSecs>
<durationInSecs>90</durationInSecs>
<registrationTimestamp>1616667913690</registrationTimestamp>
<lastRenewalTimestamp>1616668273546</lastRenewalTimestamp>
<evictionTimestamp>0</evictionTimestamp>
<serviceUpTimestamp>1616667913690</serviceUpTimestamp>
</leaseInfo>
<metadata>
<management.port>8082</management.port>
</metadata>
<homePageUrl>https://:8082/</homePageUrl>
<statusPageUrl>https://:8082/actuator/info</statusPageUrl>
<healthCheckUrl>https://:8082/actuator/health</healthCheckUrl>
<vipAddress>customer-service</vipAddress>
<secureVipAddress>customer-service</secureVipAddress>
<isCoordinatingDiscoveryServer>false</isCoordinatingDiscoveryServer>
<lastUpdatedTimestamp>1616667913690</lastUpdatedTimestamp>
<lastDirtyTimestamp>1616667913505</lastDirtyTimestamp>
<actionType>ADDED</actionType>
</instance>
<instance>
<instanceId>localhost:customer-service:8081</instanceId>
<hostName>localhost</hostName>
<app>CUSTOMER-SERVICE</app>
<ipAddr>10.0.75.1</ipAddr>
<status>UP</status>
<overriddenstatus>UNKNOWN</overriddenstatus>
<port enabled="true">8081</port>
<securePort enabled="false">443</securePort>
<countryId>1</countryId>
<dataCenterInfo
class="com.netflix.appinfo.InstanceInfo$DefaultDataCenterInfo">
<name>MyOwn</name>
</dataCenterInfo>
<leaseInfo>
<renewalIntervalInSecs>30</renewalIntervalInSecs>
<durationInSecs>90</durationInSecs>
<registrationTimestamp>1616667914313</registrationTimestamp>
<lastRenewalTimestamp>1616668274227</lastRenewalTimestamp>
<evictionTimestamp>0</evictionTimestamp>
<serviceUpTimestamp>1616667914313</serviceUpTimestamp>
</leaseInfo>
<metadata>
<management.port>8081</management.port>
</metadata>
<homePageUrl>https://:8081/</homePageUrl>
<statusPageUrl>https://:8081/actuator/info</statusPageUrl>
<healthCheckUrl>https://:8081/actuator/health</healthCheckUrl>
<vipAddress>customer-service</vipAddress>
<secureVipAddress>customer-service</secureVipAddress>
<isCoordinatingDiscoveryServer>false</isCoordinatingDiscoveryServer>
<lastUpdatedTimestamp>1616667914313</lastUpdatedTimestamp>
<lastDirtyTimestamp>1616667914162</lastDirtyTimestamp>
<actionType>ADDED</actionType>
</instance>
</application>
其他一些有用的 API 是:
| 操作 | API |
|---|---|
| 注册新服务 | POST /eureka/apps/{appIdentifier} |
| 注销服务 | DELTE /eureka/apps/{appIdentifier} |
| 有关服务的信息 | GET /eureka/apps/{appIdentifier} |
| 有关服务实例的信息 | GET /eureka/apps/{appIdentifier}/ {instanceId} |
有关程序化 API 的更多详细信息,请访问 https://javadoc.io/doc/com.netflix.eureka/eureka-client/latest/index.html
Eureka – 高可用性
我们一直在以独立模式使用 Eureka 服务器。但是,在生产环境中,我们应该理想地运行多个 Eureka 服务器实例。这样可以确保即使一台机器出现故障,另一台具有 Eureka 服务器的机器也能继续运行。
让我们尝试在高可用性模式下设置 Eureka 服务器。在我们的示例中,我们将使用两个实例。为此,我们将使用以下application-ha.yml启动 Eureka 服务器。
需要注意的事项 -
我们已经将端口参数化,以便我们可以使用相同的配置文件启动多个实例。
我们添加了地址,同样是参数化的,以传递 Eureka 服务器地址。
我们将应用程序命名为“Eureka-Server”。
spring:
application:
name: eureka-server
server:
port: ${app_port}
eureka:
client:
serviceURL:
defaultZone: ${eureka_other_server_url}
现在让我们重新编译我们的 Eureka 服务器项目。为了执行,我们将运行两个服务实例。为此,让我们打开两个 shell,然后在一个 shell 上执行以下命令:
java -Dapp_port=8900 '-Deureka_other_server_url=https://:8901/eureka' - jar .\target\spring-cloud-eureka-server-1.0.jar -- spring.config.location=classpath:application-ha.yml
并在另一个 shell 上执行以下命令:
java -Dapp_port=8901 '-Deureka_other_server_url=https://:8900/eureka' - jar .\target\spring-cloud-eureka-server-1.0.jar -- spring.config.location=classpath:application-ha.yml
我们可以通过查看仪表盘来验证服务器是否已在高可用性模式下启动并运行。例如,这是 Eureka 服务器 1 上的仪表盘:
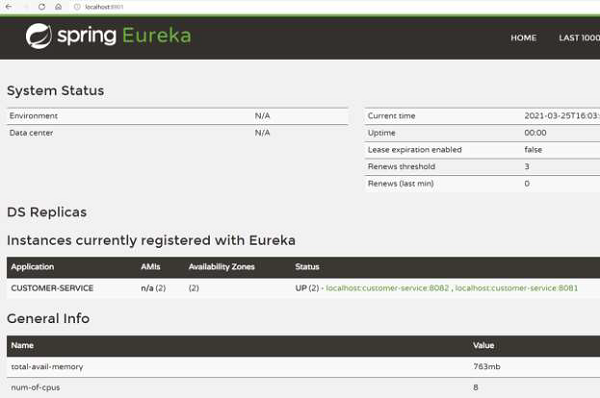
这是 Eureka 服务器 2 的仪表盘:
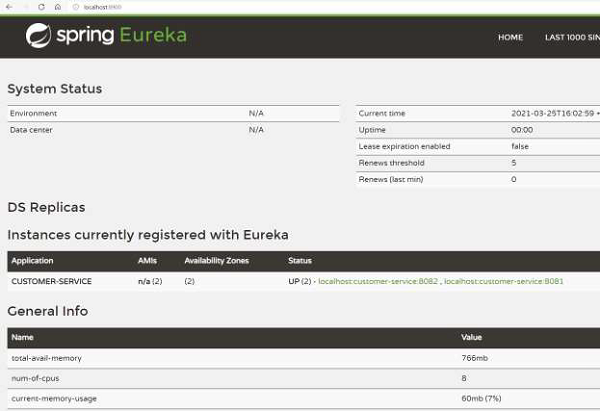
因此,正如我们所看到的,我们有两个 Eureka 服务器正在运行并且保持同步。即使一台服务器宕机,另一台服务器也将继续运行。
我们还可以更新服务实例应用程序,使其具有两个 Eureka 服务器的地址,方法是使用逗号分隔的服务器地址。
spring:
application:
name: customer-service
server:
port: ${app_port}
eureka:
client:
serviceURL:
defaultZone: https://:8900/eureka,
https://:8901/eureka
Eureka – 区域感知
Eureka 还支持区域感知的概念。区域感知作为一种概念,当我们在不同地理位置拥有集群时非常有用。例如,我们收到一个服务的传入请求,我们需要选择应该为该请求提供服务的服务器。与其将该请求发送到并处理到远处的服务器上,不如选择同一区域中的服务器更有益。这是因为网络瓶颈在分布式应用程序中非常常见,因此我们应该避免它。
现在让我们尝试设置 Eureka 客户端并使其具有区域感知能力。为此,让我们添加application-za.yml
spring:
application:
name: customer-service
server:
port: ${app_port}
eureka:
instance:
metadataMap:
zone: ${zoneName}
client:
serviceURL:
defaultZone: https://:8900/eureka
现在让我们重新编译我们的 Eureka 客户端项目。为了执行,我们将运行两个服务实例。为此,让我们打开两个 shell,然后在一个 shell 上执行以下命令:
java -Dapp_port=8080 -Dzone_name=USA -jar .\target\spring-cloud-eureka-client- 1.0.jar --spring.config.location=classpath:application-za.yml
并在另一个 shell 上执行以下命令:
java -Dapp_port=8081 -Dzone_name=EU -jar .\target\spring-cloud-eureka-client- 1.0.jar --spring.config.location=classpath:application-za.yml
我们可以返回到仪表盘以验证 Eureka 服务器是否注册了服务的区域。如以下图像所示,我们有两个可用区,而不是我们一直看到的 1 个。
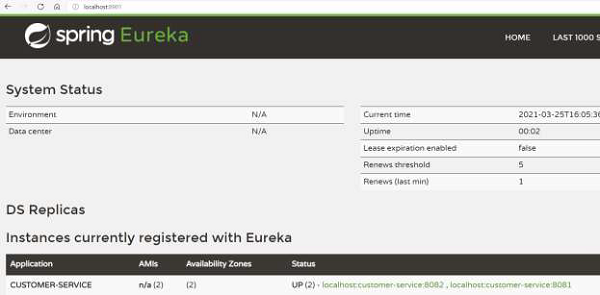
现在,任何客户端都可以查看它所在的区域。例如,如果客户端位于美国,它将优先选择美国的服务器实例。它可以从 Eureka 服务器获取区域信息。
Spring Cloud - 使用 Feign 进行同步通信
简介
在分布式环境中,服务需要相互通信。通信可以同步或异步进行。在本节中,我们将了解服务如何通过同步 API 调用进行通信。
虽然这听起来很简单,但作为进行 API 调用的一部分,我们需要注意以下几点:
查找被调用方的地址 - 调用方服务需要知道它要调用的服务的地址。
负载均衡 - 调用方服务可以进行一些智能负载均衡,以将负载分散到被调用方服务中。
区域感知 - 调用方服务最好调用同一区域中的服务以获得快速响应。
Netflix Feign 和Spring RestTemplate(以及Ribbon)是用于进行同步 API 调用的两个众所周知的 HTTP 客户端。在本教程中,我们将使用Feign Client。
Feign – 依赖项设置
让我们使用我们在前面章节中使用过的Restaurant案例。让我们开发一个 Restaurant 服务,其中包含有关餐厅的所有信息。
首先,让我们使用以下依赖项更新服务的pom.xml:
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies>
然后,使用正确的注释,即 @EnableDiscoveryClient 和 @EnableFeignCLient,对我们的 Spring 应用程序类进行注释
package com.tutorialspoint;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
import org.springframework.cloud.openfeign.EnableFeignClients;
@SpringBootApplication
@EnableFeignClients
@EnableDiscoveryClient
public class RestaurantService{
public static void main(String[] args) {
SpringApplication.run(RestaurantService.class, args);
}
}
以上代码需要注意的几点:
@ EnableDiscoveryClient - 这是我们用于读取/写入 Eureka 服务器的相同注释。
@EnableFeignCLient - 此注释扫描我们代码包中启用的 feign 客户端,并相应地初始化它。
完成后,现在让我们简要了解一下需要定义 Feign 客户端的 Feign 接口。
使用 Feign 接口进行 API 调用
Feign 客户端可以通过在接口中定义 API 调用来简单地设置,该接口可以在 Feign 中用于构建调用 API 所需的样板代码。例如,假设我们有两个服务:
服务 A - 使用 Feign 客户端的调用方服务。
服务 B - 上述 Feign 客户端将调用的服务的 API。
调用方服务,即本例中的服务 A,需要为其打算调用的 API(即服务 B)创建一个接口。
package com.tutorialspoint;
import org.springframework.cloud.openfeign.FeignClient;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
@FeignClient(name = "service-B")
public interface ServiceBInterface {
@RequestMapping("/objects/{id}", method=GET)
public ObjectOfServiceB getObjectById(@PathVariable("id") Long id);
@RequestMapping("/objects/", method=POST)
public void postInfo(ObjectOfServiceB b);
@RequestMapping("/objects/{id}", method=PUT)
public void postInfo((@PathVariable("id") Long id, ObjectOfBServiceB b);
}
需要注意的事项 -
@FeignClient 注释将由 Spring Feign 初始化的接口,并且可以被代码的其余部分使用。
请注意,FeignClient 注释需要包含服务的名称,这用于从 Eureka 或其他发现平台发现服务 B 的地址。
然后,我们可以定义我们计划从服务 A 调用的所有 API 函数名称。这可以是使用 GET、POST、PUT 等动词的一般 HTTP 调用。
完成此操作后,服务 A 可以简单地使用以下代码来调用服务 B 的 API:
@Autowired ServiceBInterface serviceB . . . ObjectOfServiceB object = serviceB. getObjectById(5);
让我们看一个示例,以了解其工作原理。
示例 – 带有 Eureka 的 Feign 客户端
假设我们想找到与客户所在城市相同的餐厅。我们将使用以下服务:
客户服务 - 拥有所有客户信息。我们在前面的 Eureka 客户端部分中定义了它。
Eureka 发现服务器 - 拥有上述服务的信息。我们在前面的 Eureka 服务器部分中定义了它。
餐厅服务 - 我们将定义的新服务,其中包含所有餐厅信息。
让我们首先向客户服务添加一个基本的控制器:
@RestController
class RestaurantCustomerInstancesController {
static HashMap<Long, Customer> mockCustomerData = new HashMap();
static{
mockCustomerData.put(1L, new Customer(1, "Jane", "DC"));
mockCustomerData.put(2L, new Customer(2, "John", "SFO"));
mockCustomerData.put(3L, new Customer(3, "Kate", "NY"));
}
@RequestMapping("/customer/{id}")
public Customer getCustomerInfo(@PathVariable("id") Long id) {
return mockCustomerData.get(id);
}
}
我们还将为上述控制器定义一个Customer.java POJO。
package com.tutorialspoint;
public class Customer {
private long id;
private String name;
private String city;
public Customer() {}
public Customer(long id, String name, String city) {
super();
this.id = id;
this.name = name;
this.city = city;
}
public long getId() {
return id;
}
public void setId(long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getCity() {
return city;
}
public void setCity(String city) {
this.city = city;
}
}
因此,添加完成后,让我们重新编译我们的项目并执行以下查询以启动:
java -Dapp_port=8081 -jar .\target\spring-cloud-eureka-client-1.0.jar
注意 - 启动 Eureka 服务器和此服务后,我们应该能够在 Eureka 中看到此服务的实例已注册。
要查看我们的 API 是否有效,让我们访问 https://:8081/customer/1
我们将获得以下输出:
{
"id": 1,
"name": "Jane",
"city": "DC"
}
这证明我们的服务运行良好。
现在让我们继续定义餐厅服务将用于获取客户城市的 Feign 客户端。
package com.tutorialspoint;
import org.springframework.cloud.openfeign.FeignClient;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
@FeignClient(name = "customer-service")
public interface CustomerService {
@RequestMapping("/customer/{id}")
public Customer getCustomerById(@PathVariable("id") Long id);
}
Feign 客户端包含服务的名称以及我们计划在餐厅服务中使用的 API 调用。
最后,让我们在餐厅服务中定义一个控制器,它将使用上述接口。
package com.tutorialspoint;
import java.util.HashMap;
import java.util.List;
import java.util.stream.Collectors;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
class RestaurantController {
@Autowired
CustomerService customerService;
static HashMap<Long, Restaurant> mockRestaurantData = new HashMap();
static{
mockRestaurantData.put(1L, new Restaurant(1, "Pandas", "DC"));
mockRestaurantData.put(2L, new Restaurant(2, "Indies", "SFO"));
mockRestaurantData.put(3L, new Restaurant(3, "Little Italy", "DC"));
}
@RequestMapping("/restaurant/customer/{id}")
public List<Restaurant> getRestaurantForCustomer(@PathVariable("id") Long
id) {
String customerCity = customerService.getCustomerById(id).getCity();
return mockRestaurantData.entrySet().stream().filter(
entry -> entry.getValue().getCity().equals(customerCity))
.map(entry -> entry.getValue())
.collect(Collectors.toList());
}
}
这里最重要的行是:
customerService.getCustomerById(id)
这是我们之前定义的 Feign 客户端进行 API 调用的魔力发生的地方。
让我们也定义Restaurant POJO:
package com.tutorialspoint;
public class Restaurant {
private long id;
private String name;
private String city;
public Restaurant(long id, String name, String city) {
super();
this.id = id;
this.name = name;
this.city = city;
}
public long getId() {
return id;
}
public void setId(long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getCity() {
return city;
}
public void setCity(String city) {
this.city = city;
}
}
定义完成后,让我们使用以下application.properties文件创建一个简单的 JAR 文件:
spring:
application:
name: restaurant-service
server:
port: ${app_port}
eureka:
client:
serviceURL:
defaultZone: https://:8900/eureka
现在让我们编译我们的项目并使用以下命令执行它:
java -Dapp_port=8083 -jar .\target\spring-cloud-feign-client-1.0.jar
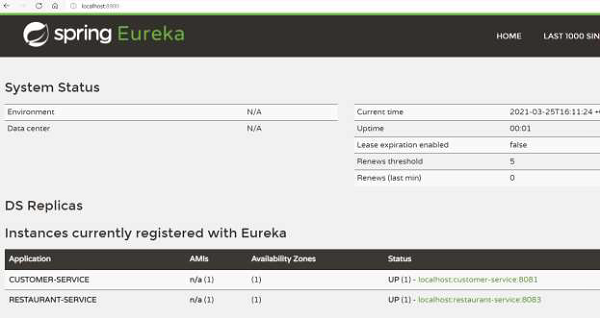
总共有以下项目正在运行:
独立的 Eureka 服务器
客户服务
餐厅服务
我们可以从 https://:8900/ 上的仪表盘确认以上项目正在运行。
现在,让我们尝试查找所有可以为位于 DC 的 Jane 提供服务的餐厅。
为此,首先让我们访问客户服务:https://:8080/customer/1
{
"id": 1,
"name": "Jane",
"city": "DC"
}
然后,调用餐厅服务:https://:8082/restaurant/customer/1
[
{
"id": 1,
"name": "Pandas",
"city": "DC"
},
{
"id": 3,
"name": "Little Italy",
"city": "DC"
}
]
正如我们所看到的,Jane 可以由 DC 区域的 2 家餐厅提供服务。
此外,从客户服务的日志中,我们可以看到:
2021-03-11 11:52:45.745 INFO 7644 --- [nio-8080-exec-1] o.s.web.servlet.DispatcherServlet : Completed initialization in 1 ms Querying customer for id with: 1
总之,正如我们所看到的,无需编写任何样板代码,甚至无需指定服务的地址,我们就可以对服务进行 HTTP 调用。
Feign 客户端 – 区域感知
Feign 客户端也支持区域感知。例如,我们收到一个服务的传入请求,我们需要选择应该为该请求提供服务的服务器。与其将该请求发送到并处理到远处的服务器上,不如选择同一区域中的服务器更有益。
现在让我们尝试设置一个区域感知的 Feign 客户端。为此,我们将使用与前面示例相同的案例。我们将有以下内容:
一个独立的 Eureka 服务器
两个区域感知的客户服务实例(代码与上面相同,我们只需要使用“Eureka 区域感知”中提到的属性文件)
两个区域感知的餐厅服务实例。
现在,让我们首先启动区域感知的客户服务。概括地说,这是application property文件。
spring:
application:
name: customer-service
server:
port: ${app_port}
eureka:
instance:
metadataMap:
zone: ${zoneName}
client:
serviceURL:
defaultZone: https://:8900/eureka
为了执行,我们将运行两个服务实例。为此,让我们打开两个 shell,然后在一个 shell 上执行以下命令:
java -Dapp_port=8080 -Dzone_name=USA -jar .\target\spring-cloud-eureka-client- 1.0.jar --spring.config.location=classpath:application-za.yml
并在另一个 shell 上执行以下命令:
java -Dapp_port=8081 -Dzone_name=EU -jar .\target\spring-cloud-eureka-client- 1.0.jar --spring.config.location=classpath:application-za.yml
现在让我们创建区域感知的餐厅服务。为此,我们将使用以下application-za.yml文件。
spring:
application:
name: restaurant-service
server:
port: ${app_port}
eureka:
instance:
metadataMap:
zone: ${zoneName}
client:
serviceURL:
defaultZone: https://:8900/eureka
为了执行,我们将有两个服务实例运行。为此,让我们打开两个shell,然后在一个shell上执行以下命令
java -Dapp_port=8082 -Dzone_name=USA -jar .\target\spring-cloud-feign-client- 1.0.jar --spring.config.location=classpath:application-za.yml
并在另一个shell上执行以下命令:
java -Dapp_port=8083 -Dzone_name=EU -jar .\target\spring-cloud-feign-client- 1.0.jar --spring.config.location=classpath:application-za.yml
现在,我们已在区域感知模式下设置了餐厅和客户服务的两个实例。
现在,让我们通过访问https://:8082/restaurant/customer/1来测试它,其中我们访问的是美国区域。
[
{
"id": 1,
"name": "Pandas",
"city": "DC"
},
{
"id": 3,
"name": "Little Italy",
"city": "DC"
}
]
但这里更重要的一点需要注意的是,请求是由位于美国区域的客户服务处理的,而不是位于欧盟区域的服务。例如,如果我们访问相同的API 5次,我们会看到位于美国区域的客户服务在日志语句中会有以下内容:
2021-03-11 12:25:19.036 INFO 6500 --- [trap-executor-0] c.n.d.s.r.aws.ConfigClusterResolver : Resolving eureka endpoints via configuration Got request for customer with id: 1 Got request for customer with id: 1 Got request for customer with id: 1 Got request for customer with id: 1 Got request for customer with id: 1
而欧盟区域的客户服务没有处理任何请求。
Spring Cloud - 负载均衡
简介
在分布式环境中,服务需要相互通信。通信可以是同步的,也可以是异步的。现在,当服务同步通信时,最好让这些服务在工作程序之间负载均衡请求,以避免单个工作程序过载。有两种方法可以负载均衡请求
服务器端负载均衡 - 工作程序由一个软件作为前端,该软件将传入请求分发到工作程序。
客户端负载均衡 - 调用服务本身将请求分发到工作程序。客户端负载均衡的优点是我们不需要以负载均衡器的形式拥有一个单独的组件。我们不需要拥有负载均衡器的高可用性等。此外,我们避免了从客户端到负载均衡器到工作程序的额外跳跃来完成请求。因此,我们节省了延迟、基础设施和维护成本。
Spring Cloud负载均衡器(SLB)和Netflix Ribbon是两种众所周知的客户端负载均衡器,用于处理这种情况。在本教程中,我们将使用Spring Cloud负载均衡器。
负载均衡器依赖项设置
让我们使用我们在前面章节中一直在使用的餐厅案例。让我们重用Restaurant Service,其中包含有关餐厅的所有信息。请注意,我们将与我们的负载均衡器一起使用Feign Client。
首先,让我们使用以下依赖项更新服务的pom.xml:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-loadbalancer</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
我们的负载均衡器将使用Eureka作为发现客户端来获取有关工作程序实例的信息。为此,我们将必须使用@EnableDiscoveryClient注解。
package com.tutorialspoint;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
import org.springframework.cloud.openfeign.EnableFeignClients;
@SpringBootApplication
@EnableFeignClients
@EnableDiscoveryClient
public class RestaurantService{
public static void main(String[] args) {
SpringApplication.run(RestaurantService.class, args);
}
}
使用Spring Load Balancer与Feign
我们之前在Feign中使用的@FeignClient注解实际上包含了负载均衡器客户端的默认设置,该设置将我们的请求轮询。让我们测试一下。这是我们之前Feign部分中相同的Feign客户端。
package com.tutorialspoint;
import org.springframework.cloud.openfeign.FeignClient;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
@FeignClient(name = "customer-service")
public interface CustomerService {
@RequestMapping("/customer/{id}")
public Customer getCustomerById(@PathVariable("id") Long id);
}
这是我们将要使用的控制器。同样,它没有发生变化。
package com.tutorialspoint;
import java.util.HashMap;
import java.util.List;
import java.util.stream.Collectors;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
class RestaurantController {
@Autowired
CustomerService customerService;
static HashMap<Long, Restaurant> mockRestaurantData = new HashMap();
static{
mockRestaurantData.put(1L, new Restaurant(1, "Pandas", "DC"));
mockRestaurantData.put(2L, new Restaurant(2, "Indies", "SFO"));
mockRestaurantData.put(3L, new Restaurant(3, "Little Italy", "DC"));
mockRestaurantData.put(4L, new Restaurant(4, "Pizeeria", "NY"));
}
@RequestMapping("/restaurant/customer/{id}")
public List<Restaurant> getRestaurantForCustomer(@PathVariable("id") Long
id) {
System.out.println("Got request for customer with id: " + id);
String customerCity = customerService.getCustomerById(id).getCity();
return mockRestaurantData.entrySet().stream().filter(
entry -> entry.getValue().getCity().equals(customerCity))
.map(entry -> entry.getValue())
.collect(Collectors.toList());
}
}
现在我们完成了设置,让我们尝试一下。这里稍微介绍一下背景,我们将执行以下操作:
启动Eureka Server。
启动两个Customer Service实例。
启动一个Restaurant Service,它内部调用Customer Service并使用Spring Cloud负载均衡器
对Restaurant Service进行四次API调用。理想情况下,每个客户服务将处理两个请求。
假设我们已经启动了Eureka服务器和Customer Service实例,现在让我们编译Restaurant Service代码并使用以下命令执行:
java -Dapp_port=8082 -jar .\target\spring-cloud-feign-client-1.0.jar
现在,让我们找到位于华盛顿特区的Jane的餐厅,方法是访问以下API https://:8082/restaurant/customer/1,然后再次访问相同的API三次。您会从Customer Service的日志中注意到,两个实例都处理了2个请求。每个Customer Service shell都会打印以下内容:
Querying customer for id with: 1 Querying customer for id with: 1
这有效地意味着请求被轮询了。
配置Spring负载均衡器
我们可以配置负载均衡器以更改算法类型,或者我们可以提供自定义算法。让我们看看如何调整我们的负载均衡器以优先考虑请求的相同客户端。
为此,让我们更新我们的Feign Client以包含负载均衡器定义。
package com.tutorialspoint;
import org.springframework.cloud.loadbalancer.annotation.LoadBalancerClient;
import org.springframework.cloud.openfeign.FeignClient;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
@FeignClient(name = "customer-service")
@LoadBalancerClient(name = "customer-service",
configuration=LoadBalancerConfiguration.class)
public interface CustomerService {
@RequestMapping("/customer/{id}")
public Customer getCustomerById(@PathVariable("id") Long id);
}
如果您注意到了,我们添加了@LoadBalancerClient注解,它指定了将用于此Feign客户端的负载均衡器类型。我们可以为负载均衡器创建一个配置类,并将该类传递给注解本身。现在让我们定义LoadBalancerConfiguratio.java
package com.tutorialspoint;
import org.springframework.cloud.loadbalancer.core.ServiceInstanceListSupplier;
import org.springframework.context.ConfigurableApplicationContext;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class LoadBalancerConfiguration {
@Bean
public ServiceInstanceListSupplier
discoveryClientServiceInstanceListSupplier(
ConfigurableApplicationContext context) {
System.out.println("Configuring Load balancer to prefer same instance");
return ServiceInstanceListSupplier.builder()
.withBlockingDiscoveryClient()
.withSameInstancePreference()
.build(context);
}
}
现在,正如您所看到的,我们已经设置了我们的客户端负载均衡以每次都优先考虑相同的实例。现在我们完成了设置,让我们尝试一下。这里稍微介绍一下背景,我们将执行以下操作:
启动Eureka Server。
启动两个Customer Service实例。
启动一个Restaurant Service,它内部调用Customer Service并使用Spring Cloud负载均衡器
对Restaurant Service进行4次API调用。理想情况下,所有四个请求都将由同一个客户服务处理。
假设我们已经启动了Eureka服务器和Customer Service实例,现在让我们编译Restaurant Service代码,然后使用以下命令执行:
java -Dapp_port=8082 -jar .\target\spring-cloud-feign-client-1.0.jar
现在,让我们找到位于华盛顿特区的Jane的餐厅,方法是访问以下API https://:8082/restaurant/customer/1,然后再次访问相同的API三次。您会从Customer Service的日志中注意到,一个实例处理了所有4个请求:
Querying customer for id with: 1 Querying customer for id with: 1 Querying customer for id with: 1 Querying customer for id with: 1
这有效地意味着请求优先选择了同一个客户服务代理。
类似地,我们可以使用各种其他负载均衡算法来使用粘性会话、基于提示的负载均衡、区域优先负载均衡等。
Spring Cloud - 使用Hystrix的断路器
简介
在分布式环境中,服务需要相互通信。通信可以是同步的,也可以是异步的。当服务同步通信时,可能有多种原因会导致问题。例如:
被调用服务不可用 - 被调用的服务由于某种原因而停止运行,例如:bug、部署等。
被调用服务响应时间过长 - 被调用的服务可能由于高负载或资源消耗而变慢,或者它正在初始化服务。
在这两种情况下,对于调用方来说,等待被调用方响应都是浪费时间和网络资源。更有意义的做法是让服务退避,并在一段时间后再次调用被调用服务,或共享默认响应。
Netflix Hystrix、Resilince4j是两种众所周知的断路器,用于处理此类情况。在本教程中,我们将使用Hystrix。
Hystrix – 依赖项设置
让我们使用我们之前一直在使用的餐厅案例。让我们将hystrix依赖项添加到我们的Restaurant Services中,该服务调用Customer Service。首先,让我们使用以下依赖项更新服务的pom.xml:
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-hystrix</artifactId> <version>2.7.0.RELEASE</version> </dependency>
然后,使用正确的注解,即@EnableHystrix,注解我们的Spring应用程序类。
package com.tutorialspoint;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.circuitbreaker.EnableCircuitBreaker;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
import org.springframework.cloud.netflix.hystrix.EnableHystrix;
import org.springframework.cloud.openfeign.EnableFeignClients;
@SpringBootApplication
@EnableFeignClients
@EnableDiscoveryClient
@EnableHystrix
public class RestaurantService{
public static void main(String[] args) {
SpringApplication.run(RestaurantService.class, args);
}
}
注意事项
@ EnableDiscoveryClient 和 @EnableFeignCLient - 我们已经在上一章中介绍了这些注解。
@EnableHystrix - 此注解扫描我们的包,并查找使用@HystrixCommand注解的方法。
Hystrix命令注解
完成后,我们将重用之前为Restaurant服务中的customer service类定义的Feign客户端,这里没有更改:
package com.tutorialspoint;
import org.springframework.cloud.openfeign.FeignClient;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
@FeignClient(name = "customer-service")
public interface CustomerService {
@RequestMapping("/customer/{id}")
public Customer getCustomerById(@PathVariable("id") Long id);
}
现在,让我们在此处定义服务实现类,它将使用Feign客户端。这将是Feign客户端的简单包装器。
package com.tutorialspoint;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import com.netflix.hystrix.contrib.javanica.annotation.HystrixCommand;
@Service
public class CustomerServiceImpl implements CustomerService {
@Autowired
CustomerService customerService;
@HystrixCommand(fallbackMethod="defaultCustomerWithNYCity")
public Customer getCustomerById(Long id) {
return customerService.getCustomerById(id);
}
// assume customer resides in NY city
public Customer defaultCustomerWithNYCity(Long id) {
return new Customer(id, null, "NY");
}
}
现在,让我们了解上面代码中的几个要点:
HystrixCommand注解 - 它负责包装函数调用getCustomerById并在其周围提供一个代理。然后,代理提供了各种挂钩,通过这些挂钩我们可以控制对客户服务的调用。例如,请求超时、请求池化、提供回退方法等。
回退方法 - 当Hystrix确定被调用方出现问题时,我们可以指定要调用的方法。此方法需要与使用注解的方法具有相同的签名。在我们的例子中,我们决定将数据提供回我们的控制器以获取纽约市的数据。
此注解提供的一些有用选项:
错误阈值百分比 - 在断路器跳闸之前允许请求失败的百分比,即调用回退方法。这可以通过使用cicutiBreaker.errorThresholdPercentage来控制。
在超时后放弃网络请求 - 如果被调用服务(在我们的例子中是Customer Service)速度缓慢,我们可以设置超时时间,在此之后我们将放弃请求并转到回退方法。这可以通过设置execution.isolation.thread.timeoutInMilliseconds来控制。
最后,这是我们调用CustomerServiceImpl的控制器
package com.tutorialspoint;
import java.util.HashMap;
import java.util.List;
import java.util.stream.Collectors;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
class RestaurantController {
@Autowired
CustomerServiceImpl customerService;
static HashMap<Long, Restaurant> mockRestaurantData = new HashMap();
static{
mockRestaurantData.put(1L, new Restaurant(1, "Pandas", "DC"));
mockRestaurantData.put(2L, new Restaurant(2, "Indies", "SFO"));
mockRestaurantData.put(3L, new Restaurant(3, "Little Italy", "DC"));
mockRestaurantData.put(3L, new Restaurant(4, "Pizeeria", "NY"));
}
@RequestMapping("/restaurant/customer/{id}")
public List<Restaurant> getRestaurantForCustomer(@PathVariable("id") Long
id)
{
System.out.println("Got request for customer with id: " + id);
String customerCity = customerService.getCustomerById(id).getCity();
return mockRestaurantData.entrySet().stream().filter(
entry -> entry.getValue().getCity().equals(customerCity))
.map(entry -> entry.getValue())
.collect(Collectors.toList());
}
}
断路器跳闸/打开
现在我们完成了设置,让我们尝试一下。这里稍微介绍一下背景,我们将执行以下操作:
启动Eureka Server
启动Customer Service
启动Restaurant Service,它将在内部调用Customer Service。
对Restaurant Service进行API调用
关闭Customer Service
对Restaurant Service进行API调用。鉴于Customer Service已关闭,它将导致失败,最终将调用回退方法。
现在让我们编译Restaurant Service代码并使用以下命令执行:
java -Dapp_port=8082 -jar .\target\spring-cloud-feign-client-1.0.jar
此外,启动Customer Service和Eureka服务器。请注意,这些服务没有任何更改,它们与前面章节中看到的一样。
现在,让我们尝试查找位于华盛顿特区的Jane的餐厅。
{
"id": 1,
"name": "Jane",
"city": "DC"
}
为此,我们将访问以下URL:https://:8082/restaurant/customer/1
[
{
"id": 1,
"name": "Pandas",
"city": "DC"
},
{
"id": 3,
"name": "Little Italy",
"city": "DC"
}
]
所以,这里没有什么新内容,我们得到了位于华盛顿特区的餐厅。现在,让我们进入有趣的部分,即关闭Customer Service。您可以通过按下Ctrl+C或简单地杀死shell来执行此操作。
现在让我们再次访问相同的URL:https://:8082/restaurant/customer/1
{
"id": 4,
"name": "Pizzeria",
"city": "NY"
}
从输出中可以看出,我们得到了来自纽约的餐厅,尽管我们的客户来自华盛顿特区。这是因为我们的回退方法返回了一个位于纽约的虚拟客户。虽然没有用,但以上示例显示了按预期调用了回退。
将缓存与Hystrix集成
为了使上述方法更有用,我们可以在使用Hystrix时集成缓存。当底层服务不可用时,这可能是一种提供更好答案的有用模式。
首先,让我们创建一个服务的缓存版本。
package com.tutorialspoint;
import java.util.HashMap;
import java.util.Map;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import com.netflix.hystrix.contrib.javanica.annotation.HystrixCommand;
@Service
public class CustomerServiceCachedFallback implements CustomerService {
Map<Long, Customer> cachedCustomer = new HashMap<>();
@Autowired
CustomerService customerService;
@HystrixCommand(fallbackMethod="defaultToCachedData")
public Customer getCustomerById(Long id) {
Customer customer = customerService.getCustomerById(id);
// cache value for future reference
cachedCustomer.put(customer.getId(), customer);
return customer;
}
// get customer data from local cache
public Customer defaultToCachedData(Long id) {
return cachedCustomer.get(id);
}
}
我们使用 HashMap 作为存储来缓存数据。这是为了开发目的。在生产环境中,我们可能希望使用更好的缓存解决方案,例如 Redis、Hazelcast 等。
现在,我们只需要更新控制器中的一行代码来使用上述服务。
@RestController
class RestaurantController {
@Autowired
CustomerServiceCachedFallback customerService;
static HashMap<Long, Restaurant> mockRestaurantData = new HashMap();
…
}
我们将遵循与上述相同的步骤。
启动Eureka Server。
启动客户服务。
启动餐厅服务,该服务在内部调用客户服务。
对餐厅服务进行 API 调用。
关闭客户服务。
对餐厅服务进行 API 调用。鉴于客户服务已关闭但数据已缓存,我们将获得一组有效的数据。
现在,让我们按照相同的流程执行到步骤 3。
现在访问 URL:https://:8082/restaurant/customer/1
[
{
"id": 1,
"name": "Pandas",
"city": "DC"
},
{
"id": 3,
"name": "Little Italy",
"city": "DC"
}
]
所以,这里没有什么新东西,我们得到了位于 DC 的餐厅。现在,让我们进入有趣的环节,即关闭客户服务。您可以通过按下 Ctrl+C 或简单地终止 shell 来实现。
现在让我们再次访问相同的URL:https://:8082/restaurant/customer/1
[
{
"id": 1,
"name": "Pandas",
"city": "DC"
},
{
"id": 3,
"name": "Little Italy",
"city": "DC"
}
]
从输出中可以看出,我们得到了来自 DC 的餐厅,这正是我们期望的,因为我们的客户来自 DC。这是因为我们的回退方法返回了缓存的客户数据。
将 Feign 与 Hystrix 集成
我们看到了如何使用 @HystrixCommand 注解来触发断路器并提供回退。但是我们还必须额外定义一个服务类来包装我们的 Hystrix 客户端。但是,我们也可以通过简单地将正确的参数传递给 Feign 客户端来实现相同的功能。让我们尝试这样做。为此,首先通过添加一个**回退类**来更新我们用于 CustomerService 的 Feign 客户端。
package com.tutorialspoint;
import org.springframework.cloud.openfeign.FeignClient;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
@FeignClient(name = "customer-service", fallback = FallBackHystrix.class)
public interface CustomerService {
@RequestMapping("/customer/{id}")
public Customer getCustomerById(@PathVariable("id") Long id);
}
现在,让我们为 Feign 客户端添加回退类,当 Hystrix 断路器触发时将调用该类。
package com.tutorialspoint;
import org.springframework.stereotype.Component;
@Component
public class FallBackHystrix implements CustomerService{
@Override
public Customer getCustomerById(Long id) {
System.out.println("Fallback called....");
return new Customer(0, "Temp", "NY");
}
}
最后,我们还需要创建**application-circuit.yml**来启用 Hystrix。
spring:
application:
name: restaurant-service
server:
port: ${app_port}
eureka:
client:
serviceURL:
defaultZone: https://:8900/eureka
feign:
circuitbreaker:
enabled: true
现在,我们已经准备好了设置,让我们测试一下。我们将遵循以下步骤。
启动Eureka Server。
我们不启动客户服务。
启动Restaurant Service,它将在内部调用Customer Service。
对餐厅服务进行 API 调用。鉴于客户服务已关闭,我们将注意到回退。
假设步骤 1 已经完成,让我们转到步骤 3。让我们编译代码并执行以下命令。
java -Dapp_port=8082 -jar .\target\spring-cloud-feign-client-1.0.jar -- spring.config.location=classpath:application-circuit.yml
现在让我们尝试访问:https://:8082/restaurant/customer/1
由于我们没有启动客户服务,因此将调用回退,并且回退将发送 NY 作为城市,这就是为什么我们在以下输出中看到 NY 餐厅的原因。
{
"id": 4,
"name": "Pizzeria",
"city": "NY"
}
此外,为了确认,在日志中,我们将看到。
…. 2021-03-13 16:27:02.887 WARN 21228 --- [reakerFactory-1] .s.c.o.l.FeignBlockingLoadBalancerClient : Load balancer does not contain an instance for the service customer-service Fallback called.... 2021-03-13 16:27:03.802 INFO 21228 --- [ main] o.s.cloud.commons.util.InetUtils : Cannot determine local hostname …..
Spring Cloud - 网关
简介
在分布式环境中,服务需要相互通信。但是,这是服务间通信。我们还有用例,其中我们域外部的客户端希望访问我们的服务以获取 API。因此,我们可以公开所有可以被客户端调用的微服务的地址,或者我们可以创建一个服务网关,该网关将请求路由到各种微服务并响应客户端。
在这里,创建网关是更好的方法。它有两个主要优点。
不需要维护每个单独服务的安全性。
并且,横切关注点(例如,添加元信息)可以在一个地方处理。
**Netflix Zuul** 和 **Spring Cloud Gateway** 是两种众所周知的云网关,用于处理此类情况。在本教程中,我们将使用 Spring Cloud Gateway。
Spring Cloud Gateway – 依赖项设置
让我们使用我们一直在使用的餐厅案例。让我们在两个服务(即餐厅服务和客户服务)前面添加一个新的服务(网关)。首先,让我们使用以下依赖项更新服务的**pom.xml**。
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
</dependencies>
然后,使用正确的注解(即 @EnableDiscoveryClient)注释我们的 Spring 应用程序类。
package com.tutorialspoint;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
@SpringBootApplication
@EnableDiscoveryClient
public class RestaurantGatewayService{
public static void main(String[] args) {
SpringApplication.run(RestaurantGatewayService.class, args);
}
}
我们使用 @EnableDiscoveryClient 进行注释,因为我们希望使用 Eureka 服务发现来获取正在为特定用例提供服务的宿主机列表。
使用网关进行动态路由
Spring Cloud Gateway 包含三个重要的部分。它们是。
**路由** – 这些是网关的构建块,包含要将请求转发到的 URL 以及应用于传入请求的断言和过滤器。
**断言** – 这些是传入请求应匹配的一组条件,以便将其转发到内部微服务。例如,路径断言仅在传入 URL 包含该路径时才转发请求。
**过滤器** – 这些充当可以在将请求发送到内部微服务之前或在向客户端响应之前修改传入请求的位置。
让我们为我们的餐厅和客户服务编写一个简单的网关配置。
spring:
application:
name: restaurant-gateway-service
cloud:
gateway:
discovery:
locator:
enabled: true
routes:
- id: customers
uri: lb://customer-service
predicates:
- Path=/customer/**
- id: restaurants
uri: lb://restaurant-service
predicates:
- Path=/restaurant/**
server:
port: ${app_port}
eureka:
client:
serviceURL:
defaultZone: https://:8900/eureka
关于上述配置需要注意的几点。
我们启用了**discovery.locator**以确保网关可以从 Eureka 服务器读取。
我们在这里使用了 Path 断言来路由请求。这意味着任何以 /**customer** 开头的请求都将路由到客户服务,对于 /**restaurant**,我们将转发该请求到餐厅服务。
现在让我们在网关服务之前设置其他服务。
启动Eureka Server
启动Customer Service
启动餐厅服务
现在,让我们编译并执行网关项目。我们将使用以下命令执行此操作。
java -Dapp_port=8084 -jar .\target\spring-cloud-gateway-1.0.jar
完成后,我们的网关准备好在端口 8084 上进行测试。首先让我们访问 https://:8084/customer/1,我们可以看到请求已正确路由到客户服务,并且我们得到了以下输出。
{
"id": 1,
"name": "Jane",
"city": "DC"
}
现在,访问我们的餐厅 API,即 https://:8084/restaurant/customer/1,我们得到以下输出。
[
{
"id": 1,
"name": "Pandas",
"city": "DC"
},
{
"id": 3,
"name": "Little Italy",
"city": "DC"
}
]
这意味着这两个调用都已正确路由到各自的服务。
断言和过滤器请求
我们在上面的示例中使用了 Path 断言。以下是一些其他重要的断言。
| 断言 | 描述 |
|---|---|
| Cookie 断言(输入:名称和正则表达式) | 将 Cookie 与“名称”与“正则表达式”进行比较 |
| 标头断言(输入:名称和正则表达式) | 将标头与“名称”与“正则表达式”进行比较 |
| 主机断言(输入:名称和正则表达式) | 将传入的“名称”与“正则表达式”进行比较 |
| 权重断言(输入:组名称和权重) | 权重断言(输入:组名称和权重) |
**过滤器**用于在将数据发送到下游服务之前或在将响应发送回客户端之前从请求中添加/删除数据。
以下是一些用于添加元数据的重要过滤器。
| 过滤器 | 描述 |
|---|---|
| 添加请求标头过滤器(输入:标头和值) | 在下游转发请求之前添加“标头”和“值”。 |
| 添加响应标头过滤器(输入:标头和值) | 在将请求转发到上游(即客户端)之前添加“标头”和“值”。 |
| 重定向过滤器(输入:状态和 URL) | 在传递到下游主机之前添加重定向标头以及 URL。 |
| ReWritePath(输入:正则表达式和替换) | 负责通过将匹配的“正则表达式”字符串替换为输入替换来重写路径。 |
过滤器和断言的详尽列表位于 https://cloud.spring.io/spring-cloudgateway/reference/html/#the-rewritepath-gatewayfilter-factory
监控
为了监控网关或访问各种路由、断言等,我们可以在项目中启用执行器。为此,让我们首先更新 pom.xml 以包含执行器作为依赖项。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
为了进行监控,我们将使用一个单独的应用程序属性文件,其中将包含启用执行器的标志。因此,它将如下所示。
spring:
application:
name: restaurant-gateway-service
cloud:
gateway:
discovery:
locator:
enabled: true
routes:
- id: customers
uri: lb://customer-service
predicates:
- Path=/customer/**
- id: restaurants
uri: lb://restaurant-service
predicates:
- Path=/restaurant/**
server:
port: ${app_port}
eureka:
client:
serviceURL:
defaultZone: https://:8900/eureka
management:
endpoint:
gateway:
enabled: true
endpoints:
web:
exposure:
include: gateway
现在,要列出所有路由,我们可以访问:https://:8084/actuator/gateway/routes
[
{
"predicate": "Paths: [/customer/**], match trailing slash: true",
"route_id": "customers",
"filters": [],
"uri": "lb://customer-service",
"order": 0
},
{
"predicate": "Paths: [/restaurant/**], match trailing slash: true",
"route_id": "restaurants",
"filters": [],
"uri": "lb://restaurant-service",
"order": 0
}
]
其他重要的监控 API。
| API | 描述 |
|---|---|
| GET /actuator/gateway/routes/{id} | 获取有关特定路由的信息 |
| POST /gateway/routes/{id_to_be assigned} | 向网关添加新路由 |
| DELETE /gateway/routes/{id} | 从网关删除路由 |
| POST /gateway/refresh | 删除所有缓存条目 |
Spring Cloud - 使用 Apache Kafka 的流
简介
在分布式环境中,服务需要相互通信。通信可以同步或异步进行。在本节中,我们将了解服务如何通过使用**消息代理**异步通信。
执行异步通信的两个主要好处。
**生产者和消费者的速度可以不同** – 如果数据的消费者速度慢或快,则不会影响生产者的处理,反之亦然。两者都可以以自己的速度工作,而不会相互影响。
**生产者无需处理来自各种消费者的请求** – 可能有多个消费者希望从生产者读取相同的数据集。在中间使用消息代理,生产者无需关心这些消费者产生的负载。此外,生产者级别的任何中断都不会阻止消费者读取旧的生产者数据,因为此数据将存在于消息代理中。
**Apache Kafka** 和 **RabbitMQ** 是两种众所周知的用于进行异步通信的消息代理。在本教程中,我们将使用 Apache Kafka。
Kafka – 依赖项设置
让我们使用我们之前一直在使用的餐厅案例。因此,假设我们的客户服务和餐厅服务通过异步通信进行通信。为此,我们将使用 Apache Kafka。我们将在两个服务中使用它,即客户服务和餐厅服务。
要使用 Apache Kafka,我们将更新这两个服务的 POM 并添加以下依赖项。
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-kafka</artifactId>
</dependency>
我们还需要运行 Kafka 实例。有多种方法可以做到这一点,但我们更倾向于使用 Docker 容器启动 Kafka。以下是一些我们可以考虑使用的镜像。
无论我们使用哪个镜像,这里需要注意的重要一点是,一旦镜像启动并运行,请确保可以在**localhost:9092**访问 Kafka 集群。
现在我们已经让 Kafka 集群在我们的镜像上运行,让我们进入核心示例。
绑定和绑定器
在 Spring Cloud 流方面,有三个重要的概念。
**外部消息系统** – 这是外部管理的组件,负责存储应用程序产生的事件/消息,其订阅者/消费者可以读取这些消息。请注意,这不是在应用程序/Spring 中管理的。一些示例包括 Apache Kafka、RabbitMQ。
**绑定器** – 这是提供与消息系统集成的组件,例如,包含消息系统的 IP 地址、身份验证等。
**绑定** – 此组件使用绑定器将消息发送到消息系统或从特定主题/队列中使用消息。
所有上述属性都在**应用程序属性文件**中定义。
示例
让我们使用我们之前一直在使用的餐厅案例。因此,假设每当向客户服务添加新的服务时,我们都希望通知附近的餐厅有关他/她的客户信息。
为此,让我们首先更新我们的客户服务以包含并使用 Kafka。请注意,我们将使用客户服务作为数据的生产者。也就是说,每当我们通过 API 添加客户时,它也将添加到 Kafka 中。
spring:
application:
name: customer-service
cloud:
stream:
source: customerBinding-out-0
kafka:
binder:
brokers: localhost:9092
replicationFactor: 1
bindings:
customerBinding-out-0:
destination: customer
producer:
partitionCount: 3
server:
port: ${app_port}
eureka:
client:
serviceURL:
defaultZone: https://:8900/eureka
需要注意的事项 -
我们使用我们本地 Kafka 实例的地址定义了一个绑定器。
我们还定义了绑定“customerBinding-out-0”,它使用“customer”主题输出消息。
我们还在stream.source中提到了我们的绑定,以便我们可以在代码中使用它。
完成后,我们现在通过添加一个新的方法“addCustomer”来更新我们的控制器,该方法负责处理POST请求。然后,从post请求中,我们将数据发送到Kafka Broker。
package com.tutorialspoint;
import java.util.HashMap;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.cloud.stream.function.StreamBridge;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.RestController;
@RestController
class RestaurantCustomerInstancesController {
@Autowired
private StreamBridge streamBridge;
static HashMap<Long, Customer> mockCustomerData = new HashMap();
static{
mockCustomerData.put(1L, new Customer(1, "Jane", "DC"));
mockCustomerData.put(2L, new Customer(2, "John", "SFO"));
mockCustomerData.put(3L, new Customer(3, "Kate", "NY"));
}
@RequestMapping("/customer/{id}")
public Customer getCustomerInfo(@PathVariable("id") Long id) {
System.out.println("Querying customer for id with: " + id);
return mockCustomerData.get(id);
}
@RequestMapping(path = "/customer/{id}", method = RequestMethod.POST)
public Customer addCustomer(@PathVariable("id") Long id) {
// add default name
Customer defaultCustomer = new Customer(id, "Dwayne", "NY");
streamBridge.send("customerBinding-out-0", defaultCustomer);
return defaultCustomer;
}
}
需要注意的要点
我们正在自动装配StreamBridge,我们将使用它来发送消息。
我们在“send”方法中使用的参数也指定了我们想要用于发送数据的绑定。
现在让我们更新我们的Restaurant Service以包含并订阅“customer”主题。请注意,我们将使用Restaurant Service作为数据的消费者。也就是说,每当我们通过API添加Customer时,Restaurant Service都会通过Kafka了解到它。
首先,让我们更新application properties文件。
spring:
application:
name: restaurant-service
cloud:
function:
definition: customerBinding
stream:
kafka:
binder:
brokers: localhost:9092
replicationFactor: 1
bindings:
customerBinding-in-0:
destination: customer
server:
port: ${app_port}
eureka:
client:
serviceURL:
defaultZone: https://:8900/eureka
完成后,我们现在通过添加一个新的方法“customerBinding”来更新我们的控制器,该方法负责获取请求并提供一个函数,该函数将打印请求及其元数据详细信息。
package com.tutorialspoint;
import java.util.HashMap;
import java.util.List;
import java.util.function.Consumer;
import java.util.function.Supplier;
import java.util.stream.Collectors;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.cloud.stream.annotation.StreamListener;
import org.springframework.cloud.stream.function.StreamBridge;
import org.springframework.context.annotation.Bean;
import org.springframework.kafka.support.Acknowledgment;
import org.springframework.kafka.support.KafkaHeaders;
import org.springframework.messaging.Message;
import org.springframework.messaging.support.MessageBuilder;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
class RestaurantController {
@Autowired
CustomerService customerService;
@Autowired
private StreamBridge streamBridge;
static HashMap<Long, Restaurant> mockRestaurantData = new HashMap();
static{
mockRestaurantData.put(1L, new Restaurant(1, "Pandas", "DC"));
mockRestaurantData.put(2L, new Restaurant(2, "Indies", "SFO"));
mockRestaurantData.put(3L, new Restaurant(3, "Little Italy", "DC"));
mockRestaurantData.put(4L, new Restaurant(4, "Pizeeria", "NY"));
}
@RequestMapping("/restaurant/customer/{id}")
public List<Restaurant> getRestaurantForCustomer(@PathVariable("id") Long id) {
System.out.println("Got request for customer with id: " + id);
String customerCity = customerService.getCustomerById(id).getCity();
return mockRestaurantData.entrySet().stream().filter(
entry -> entry.getValue().getCity().equals(customerCity))
.map(entry -> entry.getValue())
.collect(Collectors.toList());
}
@RequestMapping("/restaurant/cust/{id}")
public void getRestaurantForCust(@PathVariable("id") Long id) {
streamBridge.send("ordersBinding-out-0", id);
}
@Bean
public Consumer<Message<Customer>> customerBinding() {
return msg -> {
System.out.println(msg);
};
}
}
需要注意的事项 -
我们使用“customerBinding”,它应该传递当此绑定收到消息时将调用的函数。
我们在创建绑定并指定主题时,YAML文件中也需要使用此函数/bean的名称。
现在,让我们像往常一样执行上述代码,启动Eureka Server。请注意,这不是硬性要求,这里是为了完整性而存在。
然后,让我们编译并开始使用以下命令更新Customer Service:
mvn clean install ; java -Dapp_port=8083 -jar .\target\spring-cloud-eurekaclient- 1.0.jar --spring.config.location=classpath:application-kafka.yml
然后,让我们编译并开始使用以下命令更新Restaurant Service:
mvn clean install; java -Dapp_port=8082 -jar .\target\spring-cloud-feign-client- 1.0.jar --spring.config.location=classpath:application-kafka.yml
我们准备好了,现在让我们通过访问API来测试我们的代码片段:
curl -X POST https://:8083/customer/1
这是我们将为此API获得的输出:
{
"id": 1,
"name": "Dwayne",
"city": "NY"
}
现在,让我们检查Restaurant Service的日志:
GenericMessage [payload=Customer [id=1, name=Dwayne, city=NY],
headers={kafka_offset=1,...
因此,实际上,您可以看到,使用Kafka Broker,Restaurant Service已收到关于新添加的Customer的通知。
分区和消费者组
分区和消费者组是使用Spring Cloud Streams时应该了解的两个重要概念。
分区 - 它们用于对数据进行分区,以便我们可以在多个消费者之间分配工作。
让我们看看如何在Spring Cloud中对数据进行分区。假设,我们希望根据CustomerID对数据进行分区。因此,让我们更新我们的Customer Service以实现相同的功能。为此,我们需要告诉
让我们更新Customer Service应用程序属性以指定数据的键。
spring:
application:
name: customer-service
cloud:
function:
definition: ordersBinding
stream:
source: customerBinding-out-0
kafka:
binder:
brokers: localhost:9092
replicationFactor: 1
bindings:
customerBinding-out-0:
destination: customer
producer:
partitionKeyExpression: 'getPayload().getId()'
partitionCount: 3
server:
port: ${app_port}
eureka:
client:
serviceURL:
defaultZone: https://:8900/eureka
为了指定键,即“partitionKeyExpression”,我们提供了Spring表达式语言。该表达式假定类型为GenericMessage<Customer>,因为我们正在消息中发送Customer数据。请注意,GenericMessage是Spring框架中用于将有效负载和标头封装在单个对象中的类。因此,我们从此消息中获取有效负载,该有效负载的类型为Customer,然后我们在customer上调用getId()方法。
现在,让我们也更新我们的消费者,即Restaurant Service,以便在使用请求时记录更多信息。
现在,让我们像往常一样执行上述代码,启动Eureka Server。请注意,这不是硬性要求,这里是为了完整性而存在。
然后,让我们编译并开始使用以下命令更新Customer Service:
mvn clean install ; java -Dapp_port=8083 -jar .\target\spring-cloud-eurekaclient- 1.0.jar --spring.config.location=classpath:application-kafka.yml
然后,让我们编译并开始使用以下命令更新Restaurant Service:
mvn clean install; java -Dapp_port=8082 -jar .\target\spring-cloud-feign-client- 1.0.jar --spring.config.location=classpath:application-kafka.yml
我们准备好了,现在让我们测试我们的代码片段。作为测试的一部分,我们将执行以下操作:
插入ID为1的客户:curl -X POST https://:8083/customer/1
插入ID为1的客户:curl -X POST https://:8083/customer/1
插入ID为5的客户:curl -X POST https://:8083/customer/5
插入ID为3的客户:curl -X POST https://:8083/customer/3
插入ID为1的客户:curl -X POST https://:8083/customer/1
我们不太关心API的输出。相反,我们更关心数据发送到的分区。由于我们使用CustomerID作为键,因此我们期望具有相同ID的客户最终会进入同一分区。
现在,让我们检查Restaurant Service的日志:
Consumer: org.apache.kafka.clients.consumer.KafkaConsumer@7d6d8400 Consumer Group: anonymous.9108d02a-b1ee-4a7a-8707-7760581fa323 Partition Id: 1 Customer: Customer [id=1, name=Dwayne, city=NY] Consumer: org.apache.kafka.clients.consumer.KafkaConsumer@7d6d8400 Consumer Group: anonymous.9108d02a-b1ee-4a7a-8707-7760581fa323 Partition Id: 1 Customer: Customer [id=1, name=Dwayne, city=NY] Consumer: org.apache.kafka.clients.consumer.KafkaConsumer@7d6d8400 Consumer Group: anonymous.9108d02a-b1ee-4a7a-8707-7760581fa323 Partition Id: 2 Customer: Customer [id=5, name=Dwayne, city=NY] Consumer: org.apache.kafka.clients.consumer.KafkaConsumer@7d6d8400 Consumer Group: anonymous.9108d02a-b1ee-4a7a-8707-7760581fa323 Partition Id: 0 Customer: Customer [id=3, name=Dwayne, city=NY] Consumer Group: anonymous.9108d02a-b1ee-4a7a-8707-7760581fa323 Partition Id: 1 Customer: Customer [id=1, name=Dwayne, city=NY]
因此,正如我们所看到的,ID为1的客户每次都最终进入同一分区,即分区1。
消费者组 - 消费者组是读取同一主题以实现相同目的的消费者的逻辑分组。主题中的数据在消费者组中的消费者之间进行分区,以便给定消费者组中的只有一个消费者可以读取主题的分区。
要定义消费者组,我们只需在使用Kafka主题名称的绑定中定义一个组即可。例如,让我们在应用程序文件中为我们的控制器定义消费者组名称。
spring:
application:
name: restaurant-service
cloud:
function:
definition: customerBinding
stream:
kafka:
binder:
brokers: localhost:9092
replicationFactor: 1
bindings:
customerBinding-in-0:
destination: customer
group: restController
server:
port: ${app_port}
eureka:
client:
serviceURL:
defaultZone: https://:8900/eureka
让我们重新编译并启动Restaurant Service。现在,让我们通过访问Customer Service上的POST API来生成事件:
插入ID为1的客户:curl -X POST https://:8083/customer/1
现在,如果我们检查Restaurant Service的日志,我们将看到以下内容:
Consumer: org.apache.kafka.clients.consumer.KafkaConsumer@7d6d8400 Consumer Group: restContoller Partition Id: 1 Customer: Customer [id=1, name=Dwayne, city=NY]
因此,正如我们从输出中看到的,我们创建了一个名为“rest-contoller”的消费者组,其消费者负责读取主题。在上述情况下,我们只有一个服务实例正在运行,因此“customer”主题的所有分区都被分配给了同一个实例。但是,如果我们有多个分区,我们将有多个分区分布在工作程序之间。
使用 ELK 和 Sleuth 实现分布式日志
简介
在分布式环境或单体环境中,应用程序日志对于调试任何错误都至关重要。在本节中,我们将了解如何有效地记录和改进可跟踪性,以便我们可以轻松地查看日志。
日志模式变得至关重要的两个主要原因:
服务间调用 - 在微服务架构中,我们在服务之间进行异步和同步调用。将这些请求链接起来非常关键,因为单个请求可能有多个嵌套级别。
服务内调用 - 单个服务接收多个请求,并且它们的日志很容易混合在一起。因此,为请求关联一些ID对于筛选请求的所有日志变得很重要。
Sleuth是用于应用程序日志记录的知名工具,而ELK用于跨系统进行更简单的观察。
依赖项设置
让我们以我们在每一章中一直在使用的Restaurant为例。因此,假设我们有我们的Customer服务和Restaurant服务通过API进行通信,即同步通信。我们希望使用Sleuth来跟踪请求,并使用ELK堆栈进行集中可视化。
为此,首先设置ELK堆栈。为此,首先,我们将设置ELK堆栈。我们将使用Docker容器启动ELK堆栈。以下是我们可以考虑的镜像:
完成ELK设置后,请确保它按预期工作,方法是访问以下API:
Elasticsearch - localhost:9200
Kibana - localhost:5601
我们将在本节末尾查看Logstash配置文件。
然后,让我们将以下依赖项添加到我们的Customer Service和Restaurant Service中:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
现在我们已经设置了依赖项并运行了ELK,让我们转到核心示例。
服务内部的请求跟踪
在最基本的层面上,以下是Sleuth添加的元数据:
服务名称 - 当前正在处理请求的服务。
跟踪ID - 一个元数据ID被添加到日志中,该日志在服务之间发送以处理输入请求。这对于服务间通信很有用,可以对处理一个输入请求的所有内部请求进行分组。
跨度ID - 一个元数据ID被添加到日志中,该日志在服务为处理请求而记录的所有日志语句中都是相同的。它对于服务内日志很有用。请注意,对于父服务,跨度ID = 跟踪ID。
让我们看看它是如何工作的。为此,让我们更新我们的Customer Service代码以包含日志行。这是我们将使用的控制器代码。
package com.tutorialspoint;
import java.util.HashMap;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.messaging.Message;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.RestController;
@RestController
class RestaurantCustomerInstancesController {
Logger logger =
LoggerFactory.getLogger(RestaurantCustomerInstancesController.class);
static HashMap<Long, Customer> mockCustomerData = new HashMap();
static{
mockCustomerData.put(1L, new Customer(1, "Jane", "DC"));
mockCustomerData.put(2L, new Customer(2, "John", "SFO"));
mockCustomerData.put(3L, new Customer(3, "Kate", "NY"));
}
@RequestMapping("/customer/{id}")
public Customer getCustomerInfo(@PathVariable("id") Long id) {
logger.info("Querying customer with id: " + id);
Customer customer = mockCustomerData.get(id);
if(customer != null) {
logger.info("Found Customer: " + customer);
}
return customer;
}
}
现在让我们像往常一样执行代码,启动Eureka Server。请注意,这不是硬性要求,这里是为了完整性而存在。
然后,让我们编译并开始使用以下命令更新Customer Service:
mvn clean install ; java -Dapp_port=8083 -jar .\target\spring-cloud-eurekaclient- 1.0.jar
我们准备好了,现在让我们通过访问API来测试我们的代码片段:
curl -X GET https://:8083/customer/1
这是我们将为此API获得的输出:
{
"id": 1,
"name": "Jane",
"city": "DC"
}
现在让我们检查Customer Service的日志:
2021-03-23 13:46:59.604 INFO [customerservice, b63d4d0c733cc675,b63d4d0c733cc675] 11860 --- [nio-8083-exec-7] .t.RestaurantCustomerInstancesController : Querying customer with id: 1 2021-03-23 13:46:59.605 INFO [customerservice, b63d4d0c733cc675,b63d4d0c733cc675] 11860 --- [nio-8083-exec-7] .t.RestaurantCustomerInstancesController : Found Customer: Customer [id=1, name=Jane, city=DC] …..
因此,实际上,正如我们所看到的,我们在日志语句中添加了服务名称、跟踪ID和跨度ID。
跨服务的请求跟踪
让我们看看如何在服务之间进行日志记录和跟踪。例如,我们将执行的操作是使用Restaurant Service,它在内部调用Customer Service。
为此,让我们更新我们的Restaurant Service代码以包含日志行。这是我们将使用的控制器代码。
package com.tutorialspoint;
import java.util.HashMap;
import java.util.List;
import java.util.function.Consumer;
import java.util.function.Supplier;
import java.util.stream.Collectors;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
class RestaurantController {
@Autowired
CustomerService customerService;
Logger logger = LoggerFactory.getLogger(RestaurantController.class);
static HashMap<Long, Restaurant> mockRestaurantData = new HashMap();
static{
mockRestaurantData.put(1L, new Restaurant(1, "Pandas", "DC"));
mockRestaurantData.put(2L, new Restaurant(2, "Indies", "SFO"));
mockRestaurantData.put(3L, new Restaurant(3, "Little Italy", "DC"));
mockRestaurantData.put(4L, new Restaurant(4, "Pizeeria", "NY"));
}
@RequestMapping("/restaurant/customer/{id}")
public List<Restaurant> getRestaurantForCustomer(@PathVariable("id") Long id) {
logger.info("Get Customer from Customer Service with customer id: " + id);
Customer customer = customerService.getCustomerById(id);
logger.info("Found following customer: " + customer);
String customerCity = customer.getCity();
return mockRestaurantData.entrySet().stream().filter(
entry -> entry.getValue().getCity().equals(customerCity))
.map(entry -> entry.getValue())
.collect(Collectors.toList());
}
}
让我们编译并开始使用以下命令更新Restaurant Service:
mvn clean install; java -Dapp_port=8082 -jar .\target\spring-cloud-feign-client-1.0.jar
确保我们已运行Eureka服务器和Customer服务。我们准备好了,现在让我们通过访问API来测试我们的代码片段:
curl -X GET https://:8082/restaurant/customer/2
这是我们将为此API获得的输出:
[
{
"id": 2,
"name": "Indies",
"city": "SFO"
}
]
现在让我们检查Restaurant Service的日志:
2021-03-23 14:44:29.381 INFO [restaurantservice, 6e0c5b2a4fc533f8,6e0c5b2a4fc533f8] 19600 --- [nio-8082-exec-6] com.tutorialspoint.RestaurantController : Get Customer from Customer Service with customer id: 2 2021-03-23 14:44:29.400 INFO [restaurantservice, 6e0c5b2a4fc533f8,6e0c5b2a4fc533f8] 19600 --- [nio-8082-exec-6] com.tutorialspoint.RestaurantController : Found following customer: Customer [id=2, name=John, city=SFO]
然后,让我们检查Customer Service的日志:
2021-03-23 14:44:29.392 INFO [customerservice, 6e0c5b2a4fc533f8,f2806826ac76d816] 11860 --- [io-8083-exec-10] .t.RestaurantCustomerInstancesController : Querying customer with id: 2 2021-03-23 14:44:29.392 INFO [customerservice, 6e0c5b2a4fc533f8,f2806826ac76d816] 11860 --- [io-8083-exec-10] .t.RestaurantCustomerInstancesController : Found Customer: Customer [id=2, name=John, city=SFO]…..
因此,实际上,正如我们所看到的,我们在日志语句中添加了服务名称、跟踪ID和跨度ID。此外,我们看到跟踪ID,即6e0c5b2a4fc533f8在Customer Service和Restaurant Service中重复出现。
使用ELK进行集中式日志记录
到目前为止,我们已经看到了一种通过Sleuth改进日志记录和跟踪功能的方法。但是,在微服务架构中,我们有多个服务正在运行,并且每个服务有多个实例正在运行。查看每个实例的日志以识别请求流是不切实际的。这就是ELK对我们有帮助的地方。
让我们使用与我们在Sleuth中相同的服务间通信案例。让我们更新我们的Restaurant和Customer以添加logback appender用于ELK堆栈。
在继续之前,请确保已设置ELK堆栈并且Kibana可在localhost:5601访问。此外,使用以下设置配置Lostash配置:
input {
tcp {
port => 8089
codec => json
}
}
output {
elasticsearch {
index => "restaurant"
hosts => ["https://:9200"]
}
}
完成后,我们需要执行两个步骤才能在我们的Spring应用程序中使用Logstash。我们将对我们的两个服务执行以下步骤。首先,添加logback的依赖项以使用Logstash的appender。
<dependency> <groupId>net.logstash.logback</groupId> <artifactId>logstash-logback-encoder</artifactId> <version>6.6</version> </dependency>
其次,为logback添加一个appender,以便logback可以使用此appender将数据发送到Logstash
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<appender name="logStash"
class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<destination>10.24.220.239:8089</destination>
<encoder class="net.logstash.logback.encoder.LogstashEncoder" />
</appender>
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} -
%msg%n</pattern>
</encoder>
</appender>
<root level="INFO">
<appender-ref ref="logStash" />
<appender-ref ref="console" />
</root>
</configuration>
上述appender将记录到控制台,并将日志发送到Logstash。现在,完成此操作后,我们就可以测试它了。
现在,让我们像往常一样执行上述代码,启动Eureka Server。
然后,让我们编译并开始使用以下命令更新Customer Service:
mvn clean install ; java -Dapp_port=8083 -jar .\target\spring-cloud-eurekaclient- 1.0.jar
然后,让我们编译并开始使用以下命令更新Restaurant Service:
mvn clean install; java -Dapp_port=8082 -jar .\target\spring-cloud-feign-client- 1.0.jar
我们准备好了,现在让我们通过访问API来测试我们的代码片段:
curl -X GET https://:8082/restaurant/customer/2
这是我们将为此API获得的输出:
[
{
"id": 2,
"name": "Indies",
"city": "SFO"
}
]
但更重要的是,日志语句也将在Kibana上可用。
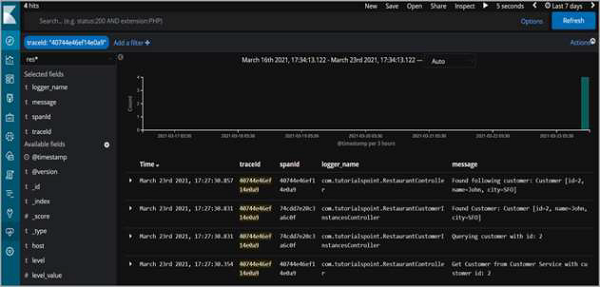
因此,正如我们所看到的,我们可以筛选traceId并查看跨服务的所有日志语句,这些语句已记录以满足请求。