- Sqoop 教程
- Sqoop - 主页
- Sqoop - 简介
- Sqoop - 安装
- Sqoop - 导入
- Sqoop - Import-All-Tables
- Sqoop - 导出
- Sqoop - Sqoop 作业
- Sqoop - Codegen
- Sqoop - Eval
- Sqoop - 列出数据库
- Sqoop - 列出表格
- Sqoop 有用资源
- Sqoop - 问答
- Sqoop - 快速指南
- Sqoop - 有用资源
- Sqoop - 讨论
Sqoop - 简介
传统的应用程序管理系统,也就是使用 RDBMS 的应用程序与关系数据库之间的交互,是生成大数据的一个来源。由 RDBMS 生成的此类大数据存储在关系数据库结构中的关系数据库服务器 中。
当 Hadoop 生态系统中的大数据存储和分析器(例如 MapReduce、Hive、HBase、Cassandra、Pig 等)出现时,它们需要一个工具来与关系数据库服务器交互,以导入和导出驻留在其中的大数据。在这里,Sqoop 在 Hadoop 生态系统中占有一席之地,提供关系数据库服务器与 Hadoop 的 HDFS 之间的可行交互。
Sqoop − “SQL 到 Hadoop 以及 Hadoop 到 SQL”
Sqoop 是一款设计用来在 Hadoop 和关系数据库服务器之间传输数据。它用于将数据从关系数据库中(例如 MySQL、Oracle)导入 Hadoop HDFS 中,并从 Hadoop 文件系统导出到关系数据库中。它由 Apache 软件基金会提供。
Sqoop 如何工作?
下图描述了 Sqoop 的工作流程。
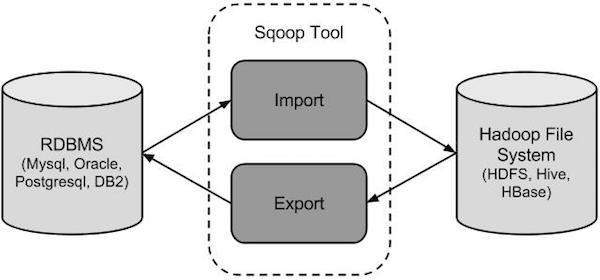
Sqoop 导入
导入工具将各个表格从 RDBMS 导入到 HDFS 中。表格中的每一行都作为 HDFS 中的一条记录进行处理。所有记录都作为文本文件中的文本数据或作为 Avro 和 Sequence 文件中的二进制数据进行存储。
Sqoop 导出
导出工具将一组文件从 HDFS 导出回 RDBMS 中。作为 Sqoop 输入的文件包含被称为表格中行的记录。对这些记录进行读入并解析成一组记录,并使用用户指定的定界符分隔。
广告