- Sqoop 教程
- Sqoop - 首页
- Sqoop - 简介
- Sqoop - 安装
- Sqoop - 导入
- Sqoop - 导入所有表
- Sqoop - 导出
- Sqoop - Sqoop 作业
- Sqoop - 代码生成
- Sqoop - Eval
- Sqoop - 列出数据库
- Sqoop - 列出表
- Sqoop 有用资源
- Sqoop - 常见问题解答
- Sqoop 快速指南
- Sqoop - 有用资源
- Sqoop - 讨论
Sqoop 快速指南
Sqoop - 简介
传统的应用程序管理系统,即应用程序与使用 RDBMS 的关系数据库的交互,是大数据产生的来源之一。这种由 RDBMS 生成的大数据存储在关系数据库结构中的关系数据库服务器中。
当 Hadoop 生态系统中的 MapReduce、Hive、HBase、Cassandra、Pig 等大数据存储和分析工具出现时,它们需要一个工具来与关系数据库服务器交互,以导入和导出驻留在其中的大数据。在这里,Sqoop 在 Hadoop 生态系统中占据一席之地,以提供关系数据库服务器和 Hadoop 的 HDFS 之间的可行交互。
Sqoop - “SQL 到 Hadoop 和 Hadoop 到 SQL”
Sqoop 是一种旨在在 Hadoop 和关系数据库服务器之间传输数据的工具。它用于将数据从关系数据库(如 MySQL、Oracle)导入到 Hadoop HDFS,以及将数据从 Hadoop 文件系统导出到关系数据库。它由 Apache 软件基金会提供。
Sqoop 如何工作?
下图描述了 Sqoop 的工作流程。
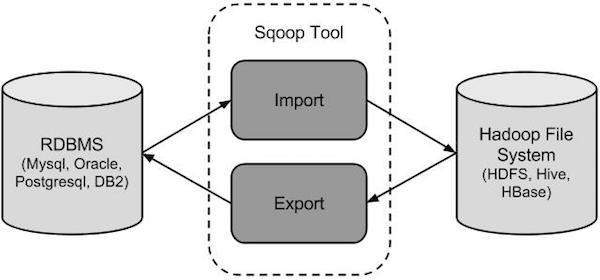
Sqoop 导入
导入工具将 RDBMS 中的单个表导入到 HDFS。表中的每一行都被视为 HDFS 中的一条记录。所有记录都以文本文件的形式存储为文本数据,或以 Avro 和 Sequence 文件的形式存储为二进制数据。
Sqoop 导出
导出工具将 HDFS 中的一组文件导出回 RDBMS。作为 Sqoop 输入的文件包含记录,这些记录称为表中的行。它们被读取并解析成一组记录,并以用户指定的定界符分隔。
Sqoop - 安装
由于 Sqoop 是 Hadoop 的一个子项目,因此它只能在 Linux 操作系统上运行。请按照以下步骤在您的系统上安装 Sqoop。
步骤 1:验证 JAVA 安装
在安装 Sqoop 之前,您需要在系统上安装 Java。让我们使用以下命令验证 Java 安装 -
$ java –version
如果 Java 已安装在您的系统上,您将看到以下响应 -
java version "1.7.0_71" Java(TM) SE Runtime Environment (build 1.7.0_71-b13) Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)
如果 Java 未安装在您的系统上,请按照以下步骤操作。
安装 Java
按照以下简单步骤在您的系统上安装 Java。
步骤 1
通过访问以下链接下载 Java(JDK <最新版本> - X64.tar.gz)。
然后 jdk-7u71-linux-x64.tar.gz 将下载到您的系统上。
步骤 2
通常,您可以在“下载”文件夹中找到下载的 Java 文件。验证它并使用以下命令解压缩 jdk-7u71-linux-x64.gz 文件。
$ cd Downloads/ $ ls jdk-7u71-linux-x64.gz $ tar zxf jdk-7u71-linux-x64.gz $ ls jdk1.7.0_71 jdk-7u71-linux-x64.gz
步骤 3
要使 Java 对所有用户可用,您必须将其移动到“/usr/local/”位置。打开 root,并键入以下命令。
$ su password: # mv jdk1.7.0_71 /usr/local/java # exitStep IV:
步骤 4
要设置 PATH 和 JAVA_HOME 变量,请将以下命令添加到 ~/.bashrc 文件中。
export JAVA_HOME=/usr/local/java export PATH=$PATH:$JAVA_HOME/bin
现在将所有更改应用到当前正在运行的系统中。
$ source ~/.bashrc
步骤 5
使用以下命令配置 Java 备选方案 -
# alternatives --install /usr/bin/java java usr/local/java/bin/java 2 # alternatives --install /usr/bin/javac javac usr/local/java/bin/javac 2 # alternatives --install /usr/bin/jar jar usr/local/java/bin/jar 2 # alternatives --set java usr/local/java/bin/java # alternatives --set javac usr/local/java/bin/javac # alternatives --set jar usr/local/java/bin/jar
现在使用终端中的命令java -version验证安装,如上所述。
步骤 2:验证 Hadoop 安装
在安装 Sqoop 之前,必须在您的系统上安装 Hadoop。让我们使用以下命令验证 Hadoop 安装 -
$ hadoop version
如果 Hadoop 已安装在您的系统上,那么您将获得以下响应 -
Hadoop 2.4.1 -- Subversion https://svn.apache.org/repos/asf/hadoop/common -r 1529768 Compiled by hortonmu on 2013-10-07T06:28Z Compiled with protoc 2.5.0 From source with checksum 79e53ce7994d1628b240f09af91e1af4
如果 Hadoop 未安装在您的系统上,请继续执行以下步骤 -
下载 Hadoop
使用以下命令从 Apache 软件基金会下载并解压缩 Hadoop 2.4.1。
$ su password: # cd /usr/local # wget http://apache.claz.org/hadoop/common/hadoop-2.4.1/ hadoop-2.4.1.tar.gz # tar xzf hadoop-2.4.1.tar.gz # mv hadoop-2.4.1/* to hadoop/ # exit
以伪分布式模式安装 Hadoop
按照以下步骤以伪分布式模式安装 Hadoop 2.4.1。
步骤 1:设置 Hadoop
您可以通过将以下命令附加到 ~/.bashrc 文件来设置 Hadoop 环境变量。
export HADOOP_HOME=/usr/local/hadoop export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
现在,将所有更改应用到当前正在运行的系统中。
$ source ~/.bashrc
步骤 2:Hadoop 配置
您可以在“$HADOOP_HOME/etc/hadoop”位置找到所有 Hadoop 配置文件。您需要根据您的 Hadoop 基础架构对这些配置文件进行适当的更改。
$ cd $HADOOP_HOME/etc/hadoop
为了使用 java 开发 Hadoop 程序,您必须通过将 JAVA_HOME 值替换为系统中 java 的位置来重置hadoop-env.sh文件中的 java 环境变量。
export JAVA_HOME=/usr/local/java
以下是您需要编辑以配置 Hadoop 的文件列表。
core-site.xml
core-site.xml 文件包含诸如 Hadoop 实例使用的端口号、分配给文件系统的内存、存储数据的内存限制以及读/写缓冲区的大小等信息。
打开 core-site.xml 并将以下属性添加到<configuration>和</configuration>标签之间。
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://:9000 </value>
</property>
</configuration>
hdfs-site.xml
hdfs-site.xml 文件包含诸如复制数据的值、namenode 路径和本地文件系统的 datanode 路径等信息。这意味着您要存储 Hadoop 基础架构的位置。
让我们假设以下数据。
dfs.replication (data replication value) = 1 (In the following path /hadoop/ is the user name. hadoopinfra/hdfs/namenode is the directory created by hdfs file system.) namenode path = //home/hadoop/hadoopinfra/hdfs/namenode (hadoopinfra/hdfs/datanode is the directory created by hdfs file system.) datanode path = //home/hadoop/hadoopinfra/hdfs/datanode
打开此文件并在<configuration>、</configuration>标签之间添加以下属性。
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode </value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode </value>
</property>
</configuration>
注意 - 在上述文件中,所有属性值都是用户定义的,您可以根据您的 Hadoop 基础架构进行更改。
yarn-site.xml
此文件用于将 yarn 配置到 Hadoop 中。打开 yarn-site.xml 文件并在<configuration>、</configuration>标签之间添加以下属性。
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
mapred-site.xml
此文件用于指定我们正在使用哪个 MapReduce 框架。默认情况下,Hadoop 包含 yarn-site.xml 的模板。首先,您需要使用以下命令将文件从 mapred-site.xml.template 复制到 mapred-site.xml 文件。
$ cp mapred-site.xml.template mapred-site.xml
打开 mapred-site.xml 文件并在<configuration>、</configuration>标签之间添加以下属性。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
验证 Hadoop 安装
以下步骤用于验证 Hadoop 安装。
步骤 1:Name Node 设置
使用命令“hdfs namenode -format”设置 namenode,如下所示。
$ cd ~ $ hdfs namenode -format
预期结果如下。
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = localhost/192.168.1.11 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.4.1 ... ... 10/24/14 21:30:56 INFO common.Storage: Storage directory /home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted. 10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0 10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11 ************************************************************/
步骤 2:验证 Hadoop dfs
以下命令用于启动 dfs。执行此命令将启动您的 Hadoop 文件系统。
$ start-dfs.sh
预期输出如下 -
10/24/14 21:37:56 Starting namenodes on [localhost] localhost: starting namenode, logging to /home/hadoop/hadoop- 2.4.1/logs/hadoop-hadoop-namenode-localhost.out localhost: starting datanode, logging to /home/hadoop/hadoop- 2.4.1/logs/hadoop-hadoop-datanode-localhost.out Starting secondary namenodes [0.0.0.0]
步骤 3:验证 Yarn 脚本
以下命令用于启动 yarn 脚本。执行此命令将启动您的 yarn 守护进程。
$ start-yarn.sh
预期输出如下 -
starting yarn daemons starting resourcemanager, logging to /home/hadoop/hadoop- 2.4.1/logs/yarn-hadoop-resourcemanager-localhost.out localhost: starting node manager, logging to /home/hadoop/hadoop- 2.4.1/logs/yarn-hadoop-nodemanager-localhost.out
步骤 4:在浏览器中访问 Hadoop
访问 Hadoop 的默认端口号为 50070。使用以下 URL 在浏览器中获取 Hadoop 服务。
https://:50070/
下图显示了一个 Hadoop 浏览器。
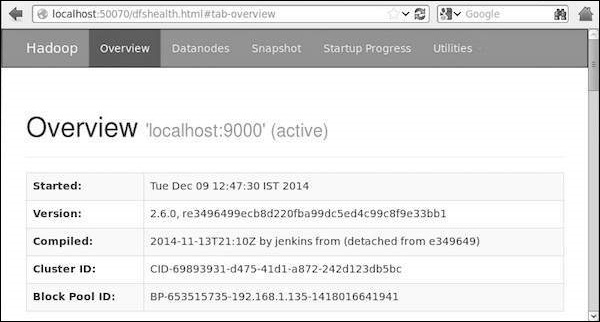
步骤 5:验证集群的所有应用程序
访问集群所有应用程序的默认端口号为 8088。使用以下 url 访问此服务。
https://:8088/
下图显示了 Hadoop 集群浏览器。
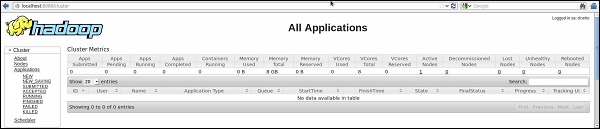
步骤 3:下载 Sqoop
我们可以从以下链接下载最新版本的 Sqoop。在本教程中,我们使用版本 1.4.5,即sqoop-1.4.5.bin__hadoop-2.0.4-alpha.tar.gz。
步骤 4:安装 Sqoop
以下命令用于解压缩 Sqoop tar 包并将其移动到“/usr/lib/sqoop”目录。
$tar -xvf sqoop-1.4.4.bin__hadoop-2.0.4-alpha.tar.gz $ su password: # mv sqoop-1.4.4.bin__hadoop-2.0.4-alpha /usr/lib/sqoop #exit
步骤 5:配置 bashrc
您必须通过将以下行附加到 ~/.bashrc文件来设置 Sqoop 环境 -
#Sqoop export SQOOP_HOME=/usr/lib/sqoop export PATH=$PATH:$SQOOP_HOME/bin
以下命令用于执行 ~/.bashrc文件。
$ source ~/.bashrc
步骤 6:配置 Sqoop
要将 Sqoop 与 Hadoop 配合使用,您需要编辑sqoop-env.sh文件,该文件位于$SQOOP_HOME/conf目录中。首先,重定向到 Sqoop 配置目录并使用以下命令复制模板文件 -
$ cd $SQOOP_HOME/conf $ mv sqoop-env-template.sh sqoop-env.sh
打开sqoop-env.sh并编辑以下行 -
export HADOOP_COMMON_HOME=/usr/local/hadoop export HADOOP_MAPRED_HOME=/usr/local/hadoop
步骤 7:下载并配置 mysql-connector-java
我们可以从以下链接下载mysql-connector-java-5.1.30.tar.gz文件。
以下命令用于解压缩 mysql-connector-java tar 包并将mysql-connector-java-5.1.30-bin.jar移动到 /usr/lib/sqoop/lib 目录。
$ tar -zxf mysql-connector-java-5.1.30.tar.gz $ su password: # cd mysql-connector-java-5.1.30 # mv mysql-connector-java-5.1.30-bin.jar /usr/lib/sqoop/lib
步骤 8:验证 Sqoop
以下命令用于验证 Sqoop 版本。
$ cd $SQOOP_HOME/bin $ sqoop-version
预期输出 -
14/12/17 14:52:32 INFO sqoop.Sqoop: Running Sqoop version: 1.4.5 Sqoop 1.4.5 git commit id 5b34accaca7de251fc91161733f906af2eddbe83 Compiled by abe on Fri Aug 1 11:19:26 PDT 2014
Sqoop 安装已完成。
Sqoop - 导入
本章介绍如何将数据从 MySQL 数据库导入到 Hadoop HDFS。“导入工具”将 RDBMS 中的单个表导入到 HDFS。表中的每一行都被视为 HDFS 中的一条记录。所有记录都以文本文件的形式存储为文本数据,或以 Avro 和 Sequence 文件的形式存储为二进制数据。
语法
以下语法用于将数据导入 HDFS。
$ sqoop import (generic-args) (import-args) $ sqoop-import (generic-args) (import-args)
示例
让我们以三个名为emp、emp_add和emp_contact的表为例,它们位于 MySQL 数据库服务器中名为 userdb 的数据库中。
三个表及其数据如下所示。
emp
| id | name | deg | salary | dept |
|---|---|---|---|---|
| 1201 | gopal | manager | 50,000 | TP |
| 1202 | manisha | Proof reader | 50,000 | TP |
| 1203 | khalil | php dev | 30,000 | AC |
| 1204 | prasanth | php dev | 30,000 | AC |
| 1204 | kranthi | admin | 20,000 | TP |
emp_add
| id | hno | street | city |
|---|---|---|---|
| 1201 | 288A | vgiri | jublee |
| 1202 | 108I | aoc | sec-bad |
| 1203 | 144Z | pgutta | hyd |
| 1204 | 78B | old city | sec-bad |
| 1205 | 720X | hitec | sec-bad |
emp_contact
| id | phno | |
|---|---|---|
| 1201 | 2356742 | gopal@tp.com |
| 1202 | 1661663 | manisha@tp.com |
| 1203 | 8887776 | khalil@ac.com |
| 1204 | 9988774 | prasanth@ac.com |
| 1205 | 1231231 | kranthi@tp.com |
导入表
Sqoop 工具“导入”用于将表数据从表导入到 Hadoop 文件系统作为文本文件或二进制文件。
以下命令用于将emp表从 MySQL 数据库服务器导入到 HDFS。
$ sqoop import \ --connect jdbc:mysql:///userdb \ --username root \ --table emp --m 1
如果成功执行,则您将获得以下输出。
14/12/22 15:24:54 INFO sqoop.Sqoop: Running Sqoop version: 1.4.5 14/12/22 15:24:56 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset. 14/12/22 15:24:56 INFO tool.CodeGenTool: Beginning code generation 14/12/22 15:24:58 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `emp` AS t LIMIT 1 14/12/22 15:24:58 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `emp` AS t LIMIT 1 14/12/22 15:24:58 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /usr/local/hadoop 14/12/22 15:25:11 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-hadoop/compile/cebe706d23ebb1fd99c1f063ad51ebd7/emp.jar ----------------------------------------------------- ----------------------------------------------------- 14/12/22 15:25:40 INFO mapreduce.Job: The url to track the job: https://:8088/proxy/application_1419242001831_0001/ 14/12/22 15:26:45 INFO mapreduce.Job: Job job_1419242001831_0001 running in uber mode : false 14/12/22 15:26:45 INFO mapreduce.Job: map 0% reduce 0% 14/12/22 15:28:08 INFO mapreduce.Job: map 100% reduce 0% 14/12/22 15:28:16 INFO mapreduce.Job: Job job_1419242001831_0001 completed successfully ----------------------------------------------------- ----------------------------------------------------- 14/12/22 15:28:17 INFO mapreduce.ImportJobBase: Transferred 145 bytes in 177.5849 seconds (0.8165 bytes/sec) 14/12/22 15:28:17 INFO mapreduce.ImportJobBase: Retrieved 5 records.
要验证 HDFS 中导入的数据,请使用以下命令。
$ $HADOOP_HOME/bin/hadoop fs -cat /emp/part-m-*
它向您显示emp表数据,字段以逗号 (,) 分隔。
1201, gopal, manager, 50000, TP 1202, manisha, preader, 50000, TP 1203, kalil, php dev, 30000, AC 1204, prasanth, php dev, 30000, AC 1205, kranthi, admin, 20000, TP
导入到目标目录
在将表数据导入到 HDFS 时,我们可以使用 Sqoop 导入工具指定目标目录。
以下是将目标目录作为选项指定给 Sqoop 导入命令的语法。
--target-dir <new or exist directory in HDFS>
以下命令用于将emp_add表数据导入到‘/queryresult’目录。
$ sqoop import \ --connect jdbc:mysql:///userdb \ --username root \ --table emp_add \ --m 1 \ --target-dir /queryresult
以下命令用于验证从emp_add表导入到/queryresult目录的数据。
$ $HADOOP_HOME/bin/hadoop fs -cat /queryresult/part-m-*
它将显示emp_add表数据,字段之间以逗号(,)分隔。
1201, 288A, vgiri, jublee 1202, 108I, aoc, sec-bad 1203, 144Z, pgutta, hyd 1204, 78B, oldcity, sec-bad 1205, 720C, hitech, sec-bad
导入表的子集数据
我们可以使用Sqoop导入工具中的‘where’子句导入表的子集。它在相应的数据库服务器上执行对应的SQL查询,并将结果存储到HDFS的目标目录中。
where子句的语法如下所示。
--where <condition>
以下命令用于导入emp_add表数据的子集。子集查询用于检索居住在Secunderabad市的员工的员工ID和地址。
$ sqoop import \ --connect jdbc:mysql:///userdb \ --username root \ --table emp_add \ --m 1 \ --where “city =’sec-bad’” \ --target-dir /wherequery
以下命令用于验证从emp_add表导入到/wherequery目录的数据。
$ $HADOOP_HOME/bin/hadoop fs -cat /wherequery/part-m-*
它将显示emp_add表数据,字段之间以逗号(,)分隔。
1202, 108I, aoc, sec-bad 1204, 78B, oldcity, sec-bad 1205, 720C, hitech, sec-bad
增量导入
增量导入是一种仅导入表中新添加行的技术。需要添加‘incremental’、‘check-column’和‘last-value’选项来执行增量导入。
以下语法用于Sqoop导入命令中的增量选项。
--incremental <mode> --check-column <column name> --last value <last check column value>
假设新添加到emp表中的数据如下所示:
1206, satish p, grp des, 20000, GR
以下命令用于执行emp表的增量导入。
$ sqoop import \ --connect jdbc:mysql:///userdb \ --username root \ --table emp \ --m 1 \ --incremental append \ --check-column id \ -last value 1205
以下命令用于验证从emp表导入到HDFS emp/目录的数据。
$ $HADOOP_HOME/bin/hadoop fs -cat /emp/part-m-*
它将显示emp表数据,字段之间以逗号(,)分隔。
1201, gopal, manager, 50000, TP 1202, manisha, preader, 50000, TP 1203, kalil, php dev, 30000, AC 1204, prasanth, php dev, 30000, AC 1205, kranthi, admin, 20000, TP 1206, satish p, grp des, 20000, GR
以下命令用于查看emp表中修改或新添加的行。
$ $HADOOP_HOME/bin/hadoop fs -cat /emp/part-m-*1
它将显示新添加到emp表中的行,字段之间以逗号(,)分隔。
1206, satish p, grp des, 20000, GR
Sqoop - 导入所有表
本章介绍如何将RDBMS数据库服务器中的所有表导入到HDFS。每个表的数据都存储在单独的目录中,并且目录名称与表名称相同。
语法
以下语法用于导入所有表。
$ sqoop import-all-tables (generic-args) (import-args) $ sqoop-import-all-tables (generic-args) (import-args)
示例
让我们以从userdb数据库导入所有表为例。数据库userdb包含的表列表如下所示。
+--------------------+ | Tables | +--------------------+ | emp | | emp_add | | emp_contact | +--------------------+
以下命令用于从userdb数据库导入所有表。
$ sqoop import-all-tables \ --connect jdbc:mysql:///userdb \ --username root
注意 - 如果您使用import-all-tables,则该数据库中的每个表都必须具有主键字段。
以下命令用于验证所有表数据到HDFS中的userdb数据库。
$ $HADOOP_HOME/bin/hadoop fs -ls
它将显示userdb数据库中表名作为目录的列表。
输出
drwxr-xr-x - hadoop supergroup 0 2014-12-22 22:50 _sqoop drwxr-xr-x - hadoop supergroup 0 2014-12-23 01:46 emp drwxr-xr-x - hadoop supergroup 0 2014-12-23 01:50 emp_add drwxr-xr-x - hadoop supergroup 0 2014-12-23 01:52 emp_contact
Sqoop - 导出
本章介绍如何将数据从HDFS导出回RDBMS数据库。目标表必须存在于目标数据库中。作为Sqoop输入的文件包含记录,在表中称为行。这些记录被读取并解析成一组记录,并以用户指定的定界符分隔。
默认操作是使用INSERT语句将输入文件中的所有记录插入到数据库表中。在更新模式下,Sqoop会生成UPDATE语句,该语句会将现有记录替换到数据库中。
语法
以下是导出命令的语法。
$ sqoop export (generic-args) (export-args) $ sqoop-export (generic-args) (export-args)
示例
让我们以HDFS中文件中的员工数据为例。员工数据位于HDFS中‘emp/’目录下的emp_data文件中。emp_data内容如下所示。
1201, gopal, manager, 50000, TP 1202, manisha, preader, 50000, TP 1203, kalil, php dev, 30000, AC 1204, prasanth, php dev, 30000, AC 1205, kranthi, admin, 20000, TP 1206, satish p, grp des, 20000, GR
必须手动创建要导出的表,并且该表存在于要从中导出数据的数据库中。
以下查询用于在mysql命令行中创建表‘employee’。
$ mysql mysql> USE db; mysql> CREATE TABLE employee ( id INT NOT NULL PRIMARY KEY, name VARCHAR(20), deg VARCHAR(20), salary INT, dept VARCHAR(10));
以下命令用于将表数据(位于HDFS上的emp_data文件)导出到Mysql数据库服务器的db数据库中的employee表。
$ sqoop export \ --connect jdbc:mysql:///db \ --username root \ --table employee \ --export-dir /emp/emp_data
以下命令用于在mysql命令行中验证表。
mysql>select * from employee;
如果给定数据成功存储,则您可以在以下表中找到给定员工数据。
+------+--------------+-------------+-------------------+--------+ | Id | Name | Designation | Salary | Dept | +------+--------------+-------------+-------------------+--------+ | 1201 | gopal | manager | 50000 | TP | | 1202 | manisha | preader | 50000 | TP | | 1203 | kalil | php dev | 30000 | AC | | 1204 | prasanth | php dev | 30000 | AC | | 1205 | kranthi | admin | 20000 | TP | | 1206 | satish p | grp des | 20000 | GR | +------+--------------+-------------+-------------------+--------+
Sqoop - 作业
本章介绍如何创建和维护Sqoop作业。Sqoop作业创建并保存导入和导出命令。它指定参数来识别和调用已保存的作业。此重新调用或重新执行用于增量导入,该导入可以将更新的行从RDBMS表导入到HDFS。
语法
以下是创建Sqoop作业的语法。
$ sqoop job (generic-args) (job-args) [-- [subtool-name] (subtool-args)] $ sqoop-job (generic-args) (job-args) [-- [subtool-name] (subtool-args)]
创建作业(--create)
在这里,我们使用名称myjob创建一个作业,该作业可以将表数据从RDBMS表导入到HDFS。以下命令用于创建一个作业,该作业将db数据库中的employee表中的数据导入到HDFS文件。
$ sqoop job --create myjob \ -- import \ --connect jdbc:mysql:///db \ --username root \ --table employee --m 1
验证作业(--list)
‘--list’参数用于验证已保存的作业。以下命令用于验证已保存的Sqoop作业列表。
$ sqoop job --list
它显示已保存作业的列表。
Available jobs: myjob
检查作业(--show)
‘--show’参数用于检查或验证特定作业及其详细信息。以下命令和示例输出用于验证名为myjob的作业。
$ sqoop job --show myjob
它显示了在myjob中使用的工具及其选项。
Job: myjob Tool: import Options: ---------------------------- direct.import = true codegen.input.delimiters.record = 0 hdfs.append.dir = false db.table = employee ... incremental.last.value = 1206 ...
执行作业(--exec)
‘--exec’选项用于执行已保存的作业。以下命令用于执行名为myjob的已保存作业。
$ sqoop job --exec myjob
它将显示以下输出。
10/08/19 13:08:45 INFO tool.CodeGenTool: Beginning code generation ...
Sqoop - 代码生成
本章介绍了‘codegen’工具的重要性。从面向对象应用程序的角度来看,每个数据库表都具有一个DAO类,该类包含‘getter’和‘setter’方法来初始化对象。此工具(-codegen)会自动生成DAO类。
它根据表模式结构生成Java中的DAO类。Java定义在导入过程中实例化。此工具的主要用途是检查Java是否丢失了Java代码。如果是,它将使用字段之间的默认分隔符创建Java的新版本。
语法
以下是Sqoop codegen命令的语法。
$ sqoop codegen (generic-args) (codegen-args) $ sqoop-codegen (generic-args) (codegen-args)
示例
让我们以生成userdb数据库中emp表的Java代码为例。
以下命令用于执行给定的示例。
$ sqoop codegen \ --connect jdbc:mysql:///userdb \ --username root \ --table emp
如果命令执行成功,则它将在终端上生成以下输出。
14/12/23 02:34:40 INFO sqoop.Sqoop: Running Sqoop version: 1.4.5 14/12/23 02:34:41 INFO tool.CodeGenTool: Beginning code generation ………………. 14/12/23 02:34:42 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /usr/local/hadoop Note: /tmp/sqoop-hadoop/compile/9a300a1f94899df4a9b10f9935ed9f91/emp.java uses or overrides a deprecated API. Note: Recompile with -Xlint:deprecation for details. 14/12/23 02:34:47 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-hadoop/compile/9a300a1f94899df4a9b10f9935ed9f91/emp.jar
验证
让我们看一下输出。以粗体显示的路径是生成并存储emp表Java代码的位置。让我们使用以下命令验证该位置中的文件。
$ cd /tmp/sqoop-hadoop/compile/9a300a1f94899df4a9b10f9935ed9f91/ $ ls emp.class emp.jar emp.java
如果要深入验证,请比较userdb数据库中的emp表和以下目录中的emp.java
/tmp/sqoop-hadoop/compile/9a300a1f94899df4a9b10f9935ed9f91/。
Sqoop - Eval
本章介绍如何使用Sqoop的‘eval’工具。它允许用户对相应的数据库服务器执行用户定义的查询,并在控制台中预览结果。因此,用户可以预期要导入的结果表数据。使用eval,我们可以评估任何类型的SQL查询,该查询可以是DDL或DML语句。
语法
以下是Sqoop eval命令的语法。
$ sqoop eval (generic-args) (eval-args) $ sqoop-eval (generic-args) (eval-args)
选择查询评估
使用eval工具,我们可以评估任何类型的SQL查询。让我们以在db数据库的employee表中选择有限行为例。以下命令用于使用SQL查询评估给定的示例。
$ sqoop eval \ --connect jdbc:mysql:///db \ --username root \ --query “SELECT * FROM employee LIMIT 3”
如果命令执行成功,则它将在终端上生成以下输出。
+------+--------------+-------------+-------------------+--------+ | Id | Name | Designation | Salary | Dept | +------+--------------+-------------+-------------------+--------+ | 1201 | gopal | manager | 50000 | TP | | 1202 | manisha | preader | 50000 | TP | | 1203 | khalil | php dev | 30000 | AC | +------+--------------+-------------+-------------------+--------+
插入查询评估
Sqoop eval工具既适用于建模也适用于定义SQL语句。这意味着,我们也可以将eval用于insert语句。以下命令用于在db数据库的employee表中插入新行。
$ sqoop eval \ --connect jdbc:mysql:///db \ --username root \ -e “INSERT INTO employee VALUES(1207,‘Raju’,‘UI dev’,15000,‘TP’)”
如果命令执行成功,则它将在控制台中显示更新行的状态。
或者,您可以在MySQL控制台中验证employee表。以下命令用于使用select’查询验证db数据库的employee表的行。
mysql> mysql> use db; mysql> SELECT * FROM employee; +------+--------------+-------------+-------------------+--------+ | Id | Name | Designation | Salary | Dept | +------+--------------+-------------+-------------------+--------+ | 1201 | gopal | manager | 50000 | TP | | 1202 | manisha | preader | 50000 | TP | | 1203 | khalil | php dev | 30000 | AC | | 1204 | prasanth | php dev | 30000 | AC | | 1205 | kranthi | admin | 20000 | TP | | 1206 | satish p | grp des | 20000 | GR | | 1207 | Raju | UI dev | 15000 | TP | +------+--------------+-------------+-------------------+--------+
Sqoop - 列出数据库
本章介绍如何使用Sqoop列出数据库。Sqoop list-databases工具解析并对数据库服务器执行‘SHOW DATABASES’查询。然后,它列出服务器上的现有数据库。
语法
以下是Sqoop list-databases命令的语法。
$ sqoop list-databases (generic-args) (list-databases-args) $ sqoop-list-databases (generic-args) (list-databases-args)
示例查询
以下命令用于列出MySQL数据库服务器中的所有数据库。
$ sqoop list-databases \ --connect jdbc:mysql:/// \ --username root
如果命令执行成功,则它将显示MySQL数据库服务器中的数据库列表,如下所示。
... 13/05/31 16:45:58 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset. mysql test userdb db
本章介绍如何使用Sqoop列出MySQL数据库服务器中特定数据库的表。Sqoop list-tables工具解析并对特定数据库执行‘SHOW TABLES’查询。然后,它列出数据库中的现有表。
语法
以下是Sqoop list-tables命令的语法。
$ sqoop list-tables (generic-args) (list-tables-args) $ sqoop-list-tables (generic-args) (list-tables-args)
示例查询
以下命令用于列出MySQL数据库服务器的userdb数据库中的所有表。
$ sqoop list-tables \ --connect jdbc:mysql:///userdb \ --username root
如果命令执行成功,则它将显示userdb数据库中的表列表,如下所示。
... 13/05/31 16:45:58 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset. emp emp_add emp_contact
Sqoop - 列出表
本章介绍如何使用Sqoop列出MySQL数据库服务器中特定数据库的表。Sqoop list-tables工具解析并对特定数据库执行‘SHOW TABLES’查询。然后,它列出数据库中的现有表。
语法
以下是Sqoop list-tables命令的语法。
$ sqoop list-tables (generic-args) (list-tables-args) $ sqoop-list-tables (generic-args) (list-tables-args)
示例查询
以下命令用于列出MySQL数据库服务器的userdb数据库中的所有表。
$ sqoop list-tables \ --connect jdbc:mysql:///userdb \ --username root
如果命令执行成功,则它将显示userdb数据库中的表列表,如下所示。
... 13/05/31 16:45:58 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset. emp emp_add emp_contact