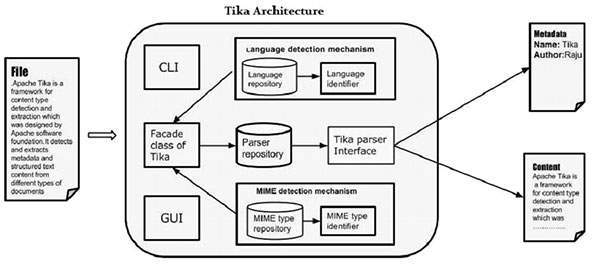
TIKA 架构
Tika 的应用级架构
应用程序程序员可以轻松地将其应用程序集成到 Tika 中。Tika 提供命令行界面和图形用户界面,使其更易于使用。
本章将讨论构成 Tika 架构的四个重要模块。下图显示了 Tika 的架构及其四个模块:
- 语言检测机制。
- MIME 检测机制。
- 解析器接口。
- Tika Facade 类。
语言检测机制
每当将文本文档传递给 Tika 时,它都会检测文档的书写语言。它接受没有语言注释的文档,并通过检测语言在文档的元数据中添加该信息。
为了支持语言识别,Tika 在包 **org.apache.tika.language** 中有一个名为 **Language Identifier** 的类,以及一个内部包含用于从给定文本检测语言的算法的语言识别库。Tika 内部使用 N-gram 算法进行语言检测。
MIME 检测机制
Tika 可以根据 MIME 标准检测文档类型。Tika 中的默认 MIME 类型检测是使用 org.apache.tika.mime.mimeTypes 完成的。它对大多数内容类型检测使用 org.apache.tika.detect.Detector 接口。
Tika 内部使用多种技术,例如文件通配符、内容类型提示、魔数字节、字符编码以及其他多种技术。
解析器接口
org.apache.tika.parser 的解析器接口是 Tika 中解析文档的关键接口。此接口从文档中提取文本和元数据,并将其总结给想要编写解析器插件的外部用户。
使用针对单个文档类型而不同的具体解析器类,Tika 支持许多文档格式。这些特定于格式的类通过直接实现解析器逻辑或使用外部解析器库来提供对不同文档格式的支持。
Tika Facade 类
使用 Tika facade 类是从 Java 调用 Tika 的最简单直接的方法,它遵循外观设计模式。您可以在 Tika API 的 org.apache.tika 包中找到 Tika facade 类。
通过实现基本用例,Tika 充当景观的代理。它抽象了 Tika 库的底层复杂性,例如 MIME 检测机制、解析器接口和语言检测机制,并为用户提供了一个简单的接口。
Tika 的特性
**统一的解析器接口** - Tika 将所有第三方解析器库封装在一个单一的解析器接口中。由于此特性,用户无需承担选择合适的解析器库并根据遇到的文件类型使用它的负担。
**低内存使用** - Tika 消耗的内存资源较少,因此易于与 Java 应用程序嵌入。我们还可以在运行在资源较少平台(如移动 PDA)上的应用程序中使用 Tika。
**快速处理** - 可以预期从应用程序快速检测和提取内容。
**灵活的元数据** - Tika 理解用于描述文件的各种元数据模型。
**解析器集成** - Tika 可以在单个应用程序中使用各种针对每种文档类型的解析器库。
**MIME 类型检测** - Tika 可以检测并提取 MIME 标准中包含的所有媒体类型的内容。
**语言检测** - Tika 包含语言识别功能,因此可以用于多语言网站中基于语言类型的文档。
Tika 的功能
Tika 支持各种功能:
- 文档类型检测
- 内容提取
- 元数据提取
- 语言检测
文档类型检测
Tika 使用各种检测技术来检测给定文档的类型。

内容提取
Tika 有一个解析器库,可以解析各种文档格式的内容并提取它们。检测到文档类型后,它会从解析器库中选择合适的解析器并传递文档。Tika 的不同类具有解析不同文档格式的方法。

元数据提取
除了内容之外,Tika 还使用与内容提取相同的过程提取文档的元数据。对于某些文档类型,Tika 有类可以提取元数据。

语言检测
在内部,Tika 使用 **n-gram** 等算法来检测给定文档中内容的语言。Tika 依赖于 **Languageidentifier** 和 **Profiler** 等类进行语言识别。