- TIKA 教程
- TIKA - 主页
- TIKA - 概述
- TIKA - 体系架构
- TIKA - 环境
- TIKA - 被引用的 API
- TIKA - 文件格式
- TIKA - 文档类型检测
- TIKA - 内容提取
- TIKA - 元数据提取
- TIKA - 语言检测
- TIKA - GUI
- TIKA 的有用资源
- TIKA - 快速指南
- TIKA - 有用资源
- TIKA - 讨论
.class 文件提取 TIKA
下面是用于从 .class 文件中提取内容和元数据的程序。
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.asm.ClassParser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class JavaClassParse {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("Example.class"));
ParseContext pcontext = new ParseContext();
//Html parser
ClassParser ClassParser = new ClassParser();
ClassParser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + " : " + metadata.get(name));
}
}
}
将以上代码保存为 JavaClassParse.java,并使用以下命令从命令提示符对其进行编译 −
javac JavaClassParse.java java JavaClassParse
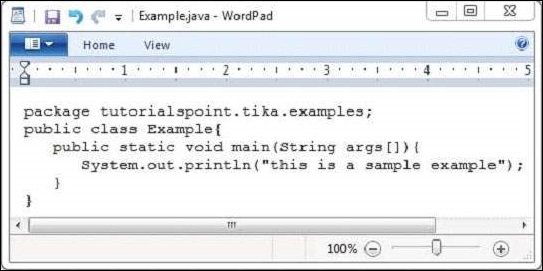
以下为 Example.java 的快照,编译后将生成 Example.class。
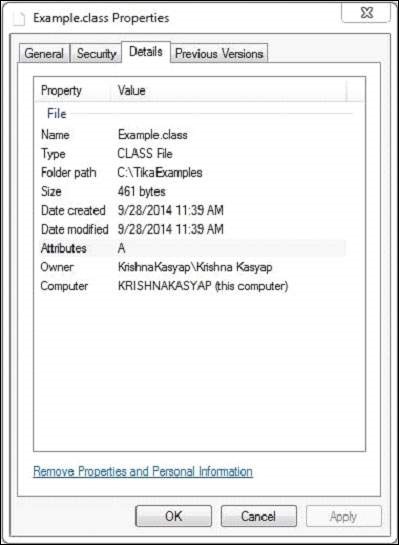
Example.class 文件具有以下属性 −
执行以上程序后,你将获得以下输出。
输出 −
Contents of the document:
package tutorialspoint.tika.examples;
public synchronized class Example {
public void Example();
public static void main(String[]);
}
Metadata of the document:
title: Example
resourceName: Example.class
dc:title: Example
广告