
 数据结构
数据结构 网络
网络 关系数据库管理系统 (RDBMS)
关系数据库管理系统 (RDBMS) 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C语言编程
C语言编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP数据科学家应该了解的7大聚类算法?
聚类算法是一种机器学习算法,可用于在数据集中查找相似数据点的分组。这些算法可用于各种应用,例如数据压缩、异常检测和主题建模。在某些情况下,聚类算法可用于查找数据集中可能并不立即明显的隐藏模式或关系。通过将相似的数据点分组在一起,聚类算法可以帮助简化和理解大型和复杂的数据集。在这篇文章中,我们将仔细研究聚类算法以及数据科学家应该熟悉的七大算法。
什么是聚类算法?
聚类算法是一种无监督的机器学习方法,用于在数据集中查找相似数据点的分组。这些算法不需要标记数据,而是寻找数据本身的模式和相关性。数据压缩、异常检测和主题建模只是使用聚类算法的一些应用。
常见的聚类算法包括 k 均值聚类、层次聚类和基于密度的聚类。这些算法根据每个集群内数据点的相似性将数据集划分为组或集群。聚类算法的目的是找到最相关和最有价值的数据组,这有助于简化和理解大型和复杂的数据集。
数据科学家应该了解的7大聚类算法
数据科学家可以使用多种聚类方法,而使用哪种方法取决于手头的特定问题。最流行的聚类算法包括:
1. K均值聚类
K均值聚类是一种流行的聚类方法,它试图将一组数据点划分为预定的组数。它通过反复将每个数据点分配到均值最近的集群,然后根据分配给它的点更改每个集群的均值来做到这一点。重复此过程,直到集群收敛,然后算法返回最终集群。

K均值聚类的一个主要优点是它的简单性和易于实现,这使其成为数据科学家中的流行选择。它在计算上也很高效,使其适用于大型数据集。但是,K均值聚类的一个缺点是它假设集群具有球形,这在现实世界的数据中并非总是如此。
2. 层次聚类
层次聚类是一种聚类分析方法,它试图创建一个组的层次结构。在层次聚类中,集群是按照从上到下的特定顺序构建的。这意味着层次结构中较高层次的集群更广泛和包容,而较低层次的集群更专业和排他。

层次聚类的基本原理是将相关的数据点分组到集群中,然后分组到更大、更通用的集群中,直到所有数据点都被集群到层次结构顶部的单个集群中。此方法使聚类算法能够捕获数据的底层结构,并发现从原始数据中可能看不出的模式和相关性。
3. 基于密度的聚类
基于密度的聚类是一种聚类分析方法,它识别数据集中密度高的集群。基于密度的聚类中的过程从选择数据集中的一组点开始,这些点被大量其他点包围。
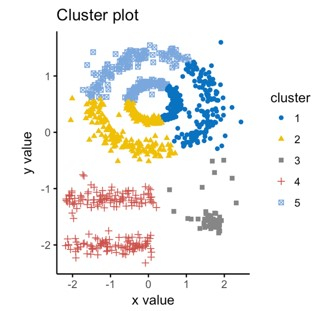
这些点被认为是密集区域的一部分,然后算法将尝试扩展此区域以包含集群的所有点。此方法使算法能够找到任何形状的集群,这使其非常适合没有明显和可识别结构的数据集。DBSCAN 和 HDBSCAN 是基于密度的聚类算法的两个例子。
4. 模糊聚类
模糊聚类,也称为软聚类,是一种聚类分析技术,它允许数据点属于多个集群。在模糊聚类中,每个数据点都被分配一个成员资格值,该值反映了它属于每个集群的程度。这意味着数据点可以部分分配给多个集群,而不是像在传统的(硬)聚类方法中那样完全分配给一个集群。
当数据点不明显属于其中一个集群或集群本身没有明确定义时,这很有用。模糊 C 均值 (FCM) 和 Gustafson-Kessel (GK) 算法是模糊聚类算法的两个例子。
5. 基于模型的聚类
基于模型的聚类是一种聚类分析技术,它涉及将统计模型拟合到数据以发现集群。基于模型的聚类中的过程首先指定数据的概率模型,例如高斯分布的混合。
然后,算法使用优化技术来选择最适合数据的模型参数集。此方法使算法能够捕获数据的底层结构,并发现从原始数据中可能看不出的集群。期望最大化 (EM) 算法和贝叶斯高斯混合模型是基于模型的聚类算法的两个例子。
6. EM 聚类
期望最大化 (EM) 算法,通常称为 EM 聚类,是一种聚类分析方法,它使用概率方法来发现数据集中存在的集群。EM 算法是一种迭代方法,它首先猜测表示数据的统计模型的参数。然后使用这些参数来计算每个数据点属于每个集群的概率。这被称为期望步骤。
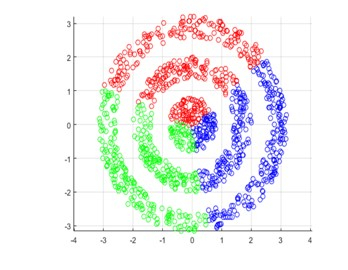
然后,算法使用这些概率来更新模型参数,这是一个称为最大化的过程。重复此过程,直到模型参数收敛到稳定的解决方案。EM 聚类特别适用于具有复杂底层结构的数据集,对于这些数据集,传统的聚类方法可能无法很好地工作。
7. DBSCAN
DBSCAN(基于密度的应用空间聚类噪声)是一种流行的基于密度的聚类技术。它是一种聚类方法,它识别数据集中密度高的集群。DBSCAN 通过查找数据集中被大量其他点包围的点来工作。
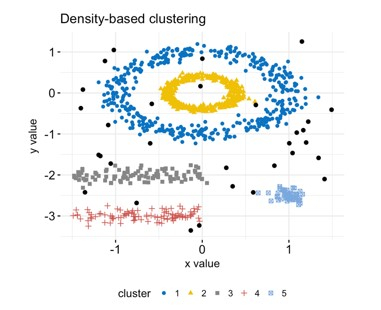
这些点被认为是密集区域的一部分,然后算法将尝试扩展此区域以包含集群的所有点。此方法使算法能够找到任何形状的集群,这使其非常适合没有明确定义结构的数据集。DBSCAN 算法由于其可扩展性和效率而在许多不同的应用中使用。
结论
总而言之,聚类算法是数据科学家查找数据集中模式和关系的有效工具。这些方法适用于各种数据和聚类应用,并使用各种策略将可比数据点分组到集群中。最佳聚类方法的选择将取决于数据集的个体特征和研究的目标。有几种类型的聚类算法,每种算法都有其独特的优势和局限性。作为数据科学家,全面了解各种聚类算法及其功能对于选择适合您研究的最佳聚类方法至关重要。

212 次浏览
