
 数据结构
数据结构 网络
网络 RDBMS
RDBMS 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C语言编程
C语言编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP机器学习中的无监督反向传播
人工智能的机器学习分支赋予计算机从数据中学习并做出判断的能力。在监督学习中,使用标记数据集来训练模型,而在无监督学习中,使用未标记数据集。无监督反向传播是一种无监督学习,它使用神经网络来发现未标记数据集中的模式。本文将概述无监督反向传播,然后继续介绍 Python 代码实践。
什么是无监督反向传播?
反向传播是一种监督学习方法,它修改神经网络的权重以减少预测结果与观察结果之间的差异。另一方面,无监督反向传播使用未标记的输入来训练网络,以找到隐藏的结构和模式。在这种方法中,自动编码器神经网络将输入数据压缩成更小的表示形式(称为潜在空间),然后解码器网络使用潜在空间重建原始输入。无监督反向传播的目标是最小化输入数据和解码器网络输出之间的重建误差。
自动编码器神经网络
自动编码器是最流行的反向传播无监督学习神经网络架构。自动编码器是一种神经网络,由两个神经网络组成:编码器网络,将输入数据转换为低维表示;解码器网络,将低维表示转换回原始输入空间。
生成对抗网络
GAN 是一种机器学习模型,由两个神经网络组成,一个用于生成,一个用于判别。生成器试图生成逼真的合成数据,而判别器试图区分真实数据和虚假数据。GAN 可用于无监督反向传播的背景下,以创建没有标签的新数据样本。然后,神经网络可以从这些生成的样本中学习,以发现数据中隐藏的模式和结构。对于标签数据稀缺或不可用的问题,使用 GAN 的无监督学习策略可能很有用。
使用 Python 进行无监督反向传播
首先,我们将创建一个包含两个数据点簇的虚构数据集。然后,使用 Keras 创建一个自动编码器神经网络,其中编码器网络包含两个密集层,解码器网络包含两个密集层。使用无监督反向传播来训练自动编码器数据集。使用散点图可视化数据集的潜在空间表示。最后,显示自动编码器的重建输出并将其与输入数据进行比较,使用散点图。结果表明,自动编码器已学习到数据集的良好模型。
创建数据集
为了在无监督反向传播研究中使用,让我们创建一个特定数据集。我们将使用 scikit-learn 工具创建具有两个数据点簇的二维数据集。
from sklearn.datasets import make_blobs X, y = make_blobs(n_samples=1000, centers=2, n_features=2, random_state=42)
上面显示的代码创建了一个包含 1000 个数据点和两个属性的数据集。数据集中的两个簇的中心分别为 (-5, 0) 和 (5, 0)。
可视化数据集
让我们使用散点图来可视化数据集,以识别两个数据点分组。
import matplotlib.pyplot as plt
plt.scatter(X[:, 0], X[:, 1])
plt.title('Dataset')
plt.show()
输出
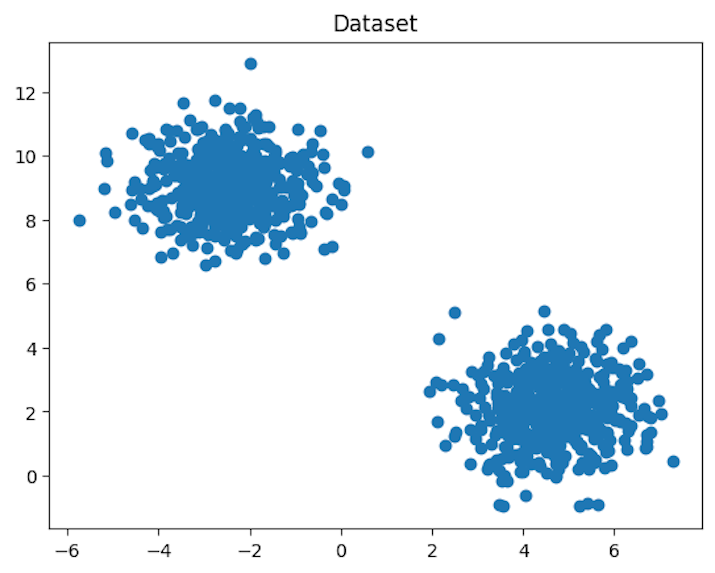
散点图显示数据集包含两个数据点簇。
定义自动编码器模型
使用 Keras 库,让我们定义自动编码器神经网络。自动编码器由解码器网络和编码器网络组成。编码器网络由两个具有 ReLU 激活函数的密集层组成,而解码器网络由两个具有 sigmoid 激活函数的密集层组成。
from keras.layers import Input, Dense from keras.models import Model input_layer = Input(shape=(2,)) encoded = Dense(32, activation='relu')(input_layer) encoded = Dense(16, activation='relu')(encoded) decoded = Dense(32, activation='relu')(encoded) decoded = Dense(2, activation='sigmoid')(decoded) autoencoder = Model(inputs=input_layer, outputs=decoded) autoencoder.compile(optimizer='adam', loss='mse')
在上面的代码中,我们创建了一个输入层,其维度与我们的数据集相对应。接下来,我们定义编码器网络,它包含两个具有 ReLU 激活函数的密集层。编码器网络的输出是潜在空间表示。解码器网络被认为包含两个具有 sigmoid 激活函数的密集层。解码器网络产生与输入维度相同的重建输出。
训练自动编码器模型
定义完自动编码器神经网络后,让我们使用无监督反向传播来训练它在我们的数据集上。我们将使用 fit() 方法训练模型。
auto encoder.fit(X, X, epochs=50, batch_size=32)
在上面的代码中,我们使用 fit() 方法训练自动编码器模型。由于目标是重建输入数据,因此我们将原始数据作为输入和目标输出。我们还定义了批大小和训练模型的时期数。
可视化潜在空间
一旦自动编码器训练完成,我们就可以使用编码器网络检索我们数据集的潜在空间表示。然后,我们可以使用散点图来可视化潜在空间。
encoder = Model(inputs=input_layer, outputs=encoded)
latent_space = encoder.predict(X)
plt.scatter(latent_space[:, 0], latent_space[:, 1])
plt.title('Latent Space')
plt.show()
在上面的代码中,我们引入了一个名为编码器的新模型,它将输入层作为输入,并输出编码器网络第二密集层的潜在空间表示。然后,我们使用编码器模型获得我们数据集的潜在空间表示。使用散点图来绘制潜在空间。
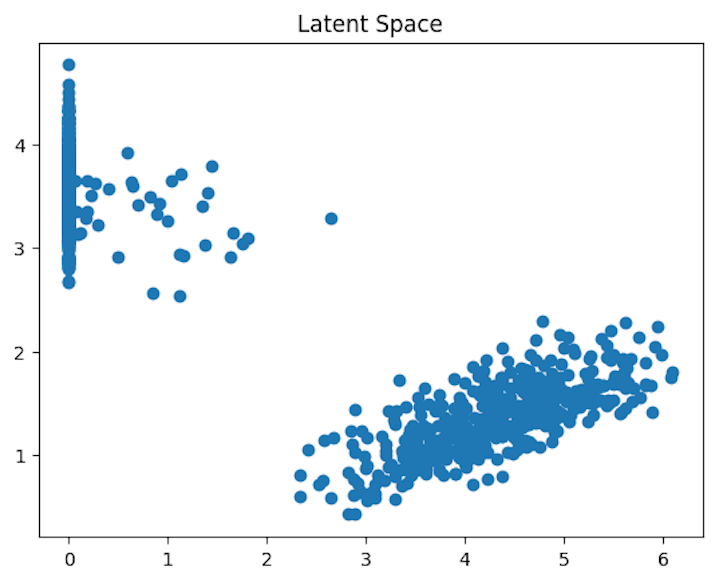
散点图表明,我们数据集的潜在空间表示清楚地分隔了两个数据点组,这表明自动编码器已学习到数据集的有用表示。
可视化重建输出
最后,让我们通过自动编码器传递输入数据,并将输出与原始输入数据进行比较,以查看输出是如何重建的。
reconstructed = autoencoder.predict(X)
fig, axes = plt.subplots(1, 2, figsize=(10, 5))
axes[0].scatter(X[:, 0], X[:, 1])
axes[0].set_title('Original Data')
axes[1].scatter(reconstructed[:, 0], reconstructed[:, 1])
axes[1].set_title('Reconstructed Data')
plt.show()
在上面的代码中,输入数据通过自动编码器处理以产生重建输出,然后使用散点图与原始数据一起可视化。

散点图显示,自动编码器的重建输出与原始输入数据非常匹配,这表明它已学习到数据集的可靠表示。
结论
最后,无监督反向传播是一种强大的神经网络方法,用于无监督学习。它包括训练神经网络来表示传入数据,而无需使用标记训练数据。这种方法可用于解决各种无监督学习问题,例如聚类、异常检测和降维。自动编码器是无监督学习中常用的神经网络类型,因为它们能够学习高维数据的有用表示,而无需标记训练数据。通过掌握这些方法,机器学习从业人员可以将无监督反向传播和自动编码器应用于他们自己的数据集,并从数据中获得有见地的知识。

368 次查看
