
 数据结构
数据结构 网络
网络 关系数据库管理系统(RDBMS)
关系数据库管理系统(RDBMS) 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C语言编程
C语言编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP机器学习中的聚类
在机器学习中,聚类是一种从数据集中提取知识和发现隐藏模式的基本方法。聚类技术使我们能够搜索大量数据并通过将相关数据点组合在一起找到重要的结构。此过程有助于数据探索、细分和理解数据片段之间错综复杂的关系。我们可以通过自主定位集群来从未标记的数据中提取重要见解,而无需预先确定的标签。客户细分、异常检测、图像和文档组织以及基因组学研究只是聚类至关重要的几个现实世界应用。在本文中,我们将仔细研究机器学习中的聚类。
理解聚类
聚类是根据数据点的内在特性将相关数据点组合在一起的过程,它是一种基本的机器学习方法。聚类旨在无需使用标签或类别的情况下揭示数据集中潜在的模式、结构和关系。聚类属于无监督学习的范畴,它使用未标记的数据而不是标记的数据来实现其探索和知识发现的目标。
在聚类的上下文中,数据点是指数据集中特定的实例或观察结果。一组精确反映这些数据片段特征的特性或属性作为其表示。作为聚类中的一个关键概念,数据点之间的相似性表示它们基于其特征值有多相似或相关。在考虑属性变化的大小和方向的同时,差异性量化了数据点之间差异的程度。
聚类的类型
K均值聚类
K均值聚类是最著名和最简单的聚类方法之一。数据将被分成K个独特的集群,其中K是一个预定的值。该方法迭代地将数据点分配给最接近的质心(代表点),然后更新质心,直到达到收敛。对于大型数据集,K均值聚类效率很高,尽管它对质心的初始选择很敏感。
这是一个代码示例
from sklearn.cluster import KMeans import matplotlib.pyplot as plt # Creating a sample dataset for K-means clustering X = [[1, 2], [1.5, 1.8], [5, 8], [8, 8], [1, 0.6], [9, 11]] # Applying K-means clustering with K=2 kmeans = KMeans(n_clusters=2) kmeans.fit(X) # Visualizing the clustering result labels = kmeans.labels_ centroids = kmeans.cluster_centers_ for i in range(len(X)): plt.scatter(X[i][0], X[i][1], c='blue' if labels[i] == 0 else 'red') plt.scatter(centroids[:, 0], centroids[:, 1], marker='x', s=150, linewidths=5, c='black') plt.show()
输出
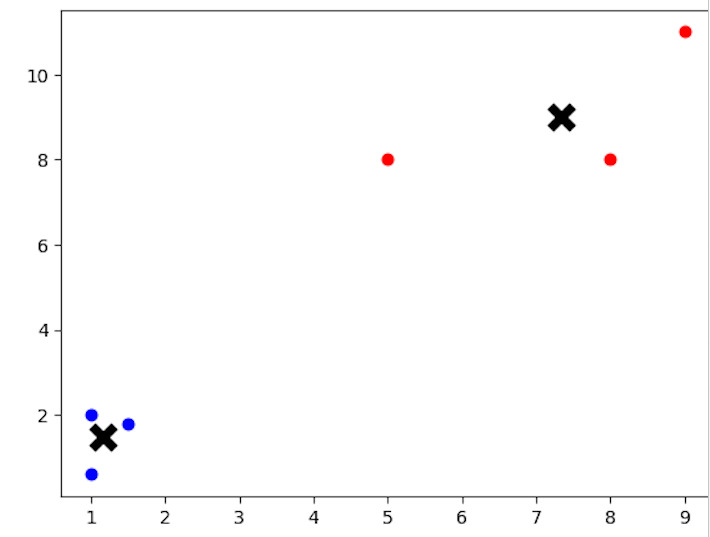
代码中,变量X表示的样本数据集应用了K均值聚类技术。使用scikit-learn工具包中的KMeans类执行聚类。此示例中的数据集包含6个具有二维坐标的数据点。我们通过设置n_clusters=2来告诉算法在数据中查找两个集群。在K均值模型拟合之后,代码绘制数据点和质心,每个数据点根据其分配的集群着色,以显示聚类结果。
层次聚类
层次聚类通过逐步合并或拆分集群来组织它们成一个层次结构。它可以分为两大类:凝聚式聚类和分裂式聚类。凝聚式聚类从将每个数据点视为一个单独的集群开始,然后逐渐合并最相似的集群,直到只剩下一个集群。
另一方面,分裂式聚类从将整个数据集作为一个单独的集群开始,并递归地将其分成更小的集群,从而为每个数据点生成不同的集群。
这是一个代码示例
from sklearn.cluster import AgglomerativeClustering import matplotlib.pyplot as plt import numpy as np # Creating a sample dataset for hierarchical clustering np.random.seed(0) X = np.random.randn(10, 2) # Applying hierarchical clustering hierarchical = AgglomerativeClustering(n_clusters=2) hierarchical.fit(X) # Visualizing the clustering result labels = hierarchical.labels_ for i in range(len(X)): plt.scatter(X[i, 0], X[i, 1], c='blue' if labels[i] == 0 else 'red') plt.show()
输出
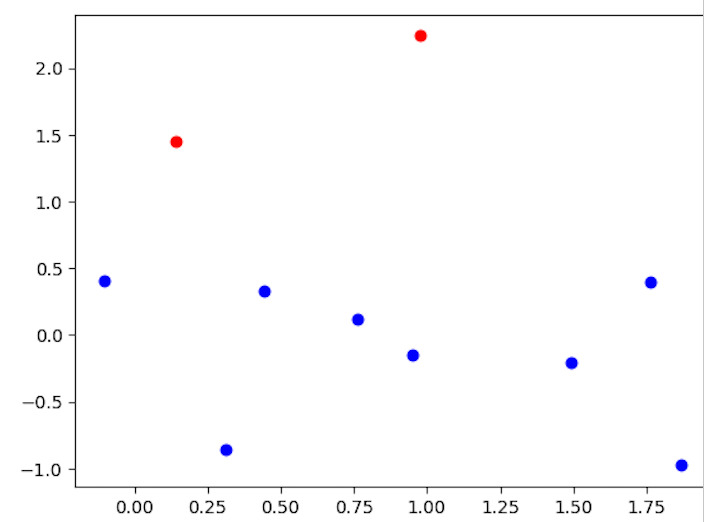
代码使用Scikit-Learn的AgglomerativeClustering类来说明层次聚类。它创建一个样本数据集,由变量X表示,包含10个数据点和2维坐标。将所需的集群数量n_clusters=2应用于层次聚类方法。然后,代码绘制数据点,根据其分配的集群为每个点着色,以查看聚类结果。
基于密度的聚类 (DBSCAN)
例如,DBSCAN(基于密度的应用空间聚类带有噪声)根据特征空间中数据点的密度查找集群。在将稀疏区域中的数据点分类为噪声或异常值的同时,它将彼此足够接近且密集的数据点聚类在一起。在处理形状不规则的集群和密度变化的集群时,基于密度的聚类非常有效。
这是一个代码示例
from sklearn.cluster import DBSCAN import matplotlib.pyplot as plt import numpy as np # Creating a sample dataset for density-based clustering np.random.seed(0) X = np.concatenate((np.random.randn(10, 2) + 2, np.random.randn(10, 2) - 2)) # Applying DBSCAN clustering dbscan = DBSCAN(eps=0.6, min_samples=2) dbscan.fit(X) # Visualizing the clustering result labels = dbscan.labels_ for i in range(len(X)): plt.scatter(X[i, 0], X[i, 1], c='blue' if labels[i] == 0 else 'red') plt.show()
输出
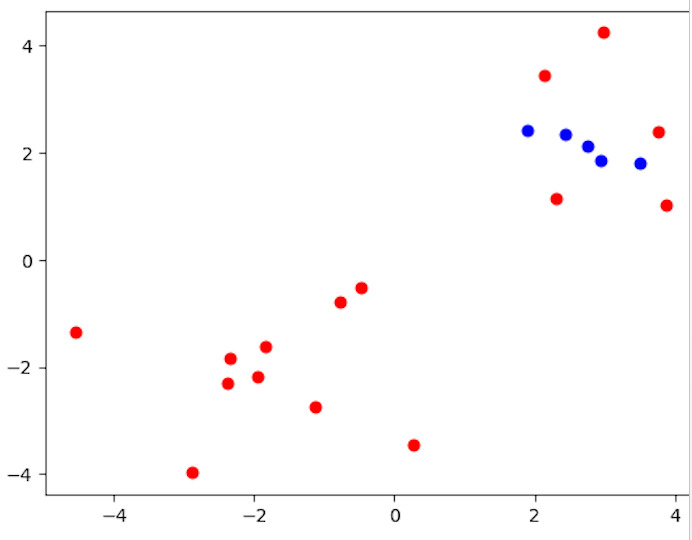
代码使用scikit-learn的DBSCAN类来说明基于密度的聚类。它生成一个包含20个二维数据点的样本数据集,由变量X表示。使用DBSCAN方法时,使用参数eps=0.6(两个样本之间被视为属于同一邻域的最大距离)和min_samples=2(一个点被视为核心点的邻域中的最小样本数)。然后,代码绘制数据点,根据其所属的集群为每个点着色,以查看聚类结果。
结论
聚类对于从数据集中获取有见地的信息和发现隐藏模式至关重要。聚类技术通过自动分组相关的数据片段,简化了跨学科的不同应用,并实现了数据驱动的决策。通过理解各种聚类算法、使用合适的评估指标并在实际情况下应用它们,我们能够利用机器学习中聚类的潜力,为知识发现和创新开辟新的可能性。

392 次浏览
