
 数据结构
数据结构 网络
网络 关系数据库管理系统(RDBMS)
关系数据库管理系统(RDBMS) 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C语言编程
C语言编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP机器学习中的Mini Batch K-means聚类算法
介绍
聚类是一种将数据点分组到各个子组的技术,使得每个子组中的每个点都相似。它是一种无监督算法,没有标签或真实值。Mini Batch K Means是K-Means算法的一个变体,它从内存中随机抽取批次进行训练。
在本文中,让我们详细了解Mini Batch K-Means。在继续Mini Batch K-Means之前,让我们先看看一般的K-Means。
K-Means聚类方法
K-Means是一种迭代方法,它试图将数据点分组到K个不同的子组中,使得它们互不重叠。同一个簇内的点尽可能相似,而不同簇之间的点尽可能不同。该算法还使簇内点与簇中心的距离之和尽可能小,而簇间距离尽可能大。一个点可以属于一个簇或子组。
Mini Batch K-Means聚类
Mini Batch K-Means聚类的基本概念是在内存中存储固定大小的小批量数据点。在每次迭代中,从数据集中随机抽取一个mini-batch,并且只使用mini-batch中的数据点来更新聚类的中心点。这使我们避免了像K-Means算法那样一次性使用整个数据集,从而解决了任何内存问题。该算法收敛速度更快。学习率通常随着迭代次数的增加而减小,因为它与分配的数据成反比。在mini-batch中,簇的更新是使用数据和原型的凸组合进行的,并且学习率随着迭代次数的增加而减小。当重复次数增加时,添加新数据的效应减小,收敛速度加快,并且当连续两次迭代中质心没有受到影响时,观察到收敛。
Mini Batch K-Means聚类的工作原理
随机初始化簇的中心点。
从原始数据集中随机选择一个mini-batch数据。
将每个数据点分配到与其最近的中心点。
使用从mini-batch中分配的点计算簇中心点。
重复步骤2到4,直到中心点位置不再变化。
获得最终的簇。
Minibatch K-Means的Python实现
在下面的例子中,我们对2000个数据点使用了带有mini-batch的KMeans聚类。定义初始聚类中心,然后使用数据训练模型以找到最终的聚类中心并绘制它们。
from sklearn.cluster import MiniBatchKMeans
from sklearn.datasets import make_blobs as blobs
import matplotlib.pyplot as plt
import timeit as t
c = [[50, 50],[1900, 0],[1900, 900],[0, 1900]]
data, data_labels = blobs(n_samples = 2000, centers = c, cluster_std = 200)
color = ['pink', 'violet', 'green', 'blue']
for i in range(len(data)):
plt.scatter(data[i][0], data[i][1], color = color[data_labels[i]], alpha = 0.4)
k_means = MiniBatchKMeans(n_clusters=4, batch_size = 40)
st = t.default_timer()
k_means.fit(data)
e = t.default_timer()
label_a = k_means.labels_
cnt = k_means.cluster_centers_
print("Time taken : ",e-st)
for i in range(len(data)):
plt.scatter(data[i][0],data[i][1], color = color[label_a[i]], alpha = 0.4)
for i in range(len(cnt)):
plt.scatter(cnt[i][0], cnt[i][1], color = 'black')
输出
Time taken : 0.01283279599999787
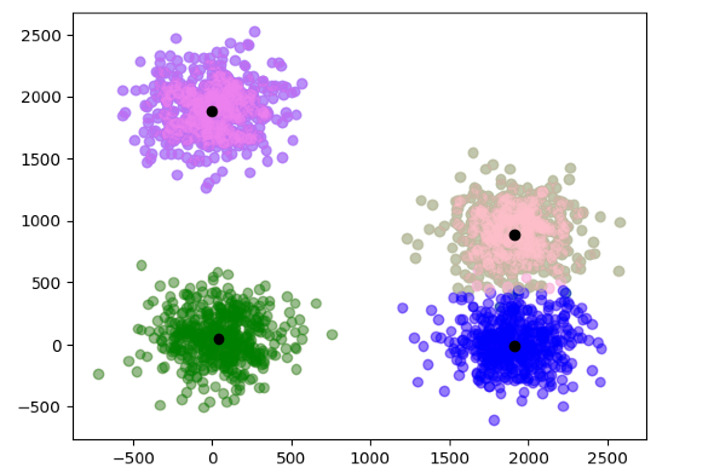
Mini Batch K-means的优势
与K-Means算法相比,它可以处理更大的数据集。
它的计算成本更低。
它的收敛速度更快。
结论
Mini-batch K-Means是一种比传统K-means更好、更新的方法,它解决了一些缺点,例如使用更少的内存、在内存中处理大型数据集以及更快的收敛速度。

793 次浏览
