
 数据结构
数据结构 网络
网络 RDBMS
RDBMS 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 编程
C 编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
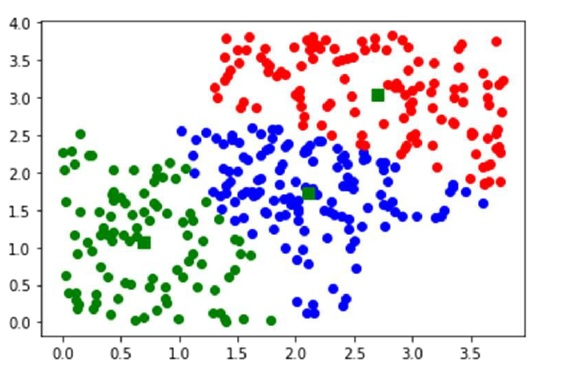
PHP使用 SciPy 分割随机数据为 3 个聚类来实施 K 均值聚类?
是的,我们还可以通过将随机数据分成 3 个聚类来实现 K 均值聚类算法。让我们通过以下示例理解一下 −
示例
#importing the required Python libraries:
import numpy as np
from numpy import vstack,array
from numpy.random import rand
from scipy.cluster.vq import whiten, kmeans, vq
from pylab import plot,show
#Random data generation:
data = vstack((rand(200,2) + array([.5,.5]),rand(150,2)))
#Normalizing the data:
data = whiten(data)
# computing K-Means with K = 3 (3 clusters)
centroids, mean_value = kmeans(data, 3)
print("Code book :
", centroids, "
")
print("Mean of Euclidean distances :", mean_value.round(4))
# mapping the centroids
clusters, _ = vq(data, centroids)
print("Cluster index :", clusters, "
")
#Plotting using numpy's logical indexing
plot(data[clusters==0,0],data[clusters==0,1],'ob',
data[clusters==1,0],data[clusters==1,1],'or',
data[clusters==2,0],data[clusters==2,1],'og')
plot(centroids[:,0],centroids[:,1],'sg',markersize=8)
show()输出
Code book : [[2.10418081 1.73089074] [2.69953885 3.04708713] [0.6994524 1.06646081]] Mean of Euclidean distances : 0.7661 Cluster index : [1 1 0 1 1 1 1 0 0 0 1 1 1 1 1 0 1 1 1 0 1 1 1 1 1 0 1 0 1 0 1 0 0 0 0 0 1 0 1 1 0 1 0 0 0 0 0 1 1 1 1 1 1 1 1 0 0 1 1 1 0 1 1 0 1 0 1 1 0 0 0 1 1 0 0 0 1 0 1 0 1 1 1 0 0 1 0 1 0 1 1 0 1 1 0 1 0 0 0 1 1 1 1 1 1 0 0 1 1 1 0 0 0 1 0 0 1 1 1 0 1 1 1 1 1 0 1 0 1 1 1 1 1 1 0 1 1 1 0 1 1 0 1 1 1 1 0 1 0 1 0 1 1 0 1 0 1 1 1 1 1 0 0 0 1 1 1 1 0 1 1 1 1 0 1 0 1 1 0 0 1 1 0 0 0 1 1 0 1 1 1 1 0 1 0 0 1 1 1 1 2 2 0 0 2 2 2 2 0 2 2 2 2 2 2 2 2 0 0 0 0 2 2 2 2 2 0 2 2 2 0 2 2 0 2 0 0 2 2 0 0 0 0 2 2 2 0 2 2 0 2 0 2 0 0 2 0 2 2 0 2 2 2 0 0 2 2 2 2 2 2 0 2 2 2 2 2 0 0 2 2 2 2 0 2 2 2 0 2 0 2 0 2 2 2 0 0 0 0 2 2 2 0 2 2 2 2 2 0 2 2 2 0 2 2 0 2 1 2 0 2 2 2 0 2 2 0 0 0 2 0 0 0 0 2 2 2 0 2 2 2 2 0 2 2 2 2 0 0 2]

更新于: 14-12-2021
147 查看

广告