
 数据结构
数据结构 网络
网络 关系型数据库管理系统
关系型数据库管理系统 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 编程
C 编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP使用 SciPy 的聚类方法
聚类是机器学习和数据科学中的一种技术,它涉及将相似的数据点或对象分组到聚类或子集中。聚类的目标是在数据中找到可能不明显的模式和结构,并将相关数据点分组在一起,以便进行进一步分析。在本文中,我们将了解如何借助 SciPy 库来实现聚类。
SciPy 为我们提供了各种科学计算工具来执行数值积分、优化、线性代数、信号处理等任务。它被研究人员、科学家、工程师和数据分析师用来在他们的工作中执行复杂的计算和分析。它建立在 NumPy 之上,并包含一个用于聚类的子模块。
一些可以使用 SciPy 实现的聚类算法包括:
K-Means − 这里目标是将数据集划分为 k 个聚类,其中 k 是一个固定数字,每个数据点都属于其均值(或质心)最接近的聚类。
层次聚类 − 这里我们创建一个聚类的层次结构,可以表示为树状图。它们进一步分为两种类型:凝聚聚类和分裂聚类。
每种方法都有其自身的优点和缺点,选择哪种方法取决于数据的特性和聚类的目标。scikit-learn 库也提供了聚类算法,具有更高级的功能,如高斯混合模型、贝叶斯高斯混合模型等。
使用 SciPy 的 K-Means 聚类
K-Means 算法的工作原理是首先将 k 个质心随机分配到数据集,然后迭代地将数据点重新分配到最近的质心,并根据新的聚类更新质心。重复此过程,直到聚类收敛或达到最大迭代次数。SciPy 库在 scipy.cluster.vq 模块中提供了 k-means 算法的实现。
使用的 dataset (kmeans_dataset.csv) 可以在此处获得。
示例
import pandas as pd
df = pd.read_csv("kmeans_dataset.csv")
X = df.values
from scipy.cluster.vq import kmeans,vq
# number of clusters
k = 4
# compute k-means clustering
centroids,_ = kmeans(X,k)
# a cluster for each data point
clusters,_ = vq(X,centroids)
# Plotting the data points in the clusters
import matplotlib.pyplot as plt
colors = ['r','g','b','y']
for i in range(k):
# select only data observations with cluster label == i
ds = X[np.where(clusters==i)]
# plot the data observations
plt.scatter(ds[:,0],ds[:,1],c=colors[i])
# plot the centroids
plt.scatter(centroids[i,0],centroids[i,1],marker='x',s=200, c='black')
plt.show()
输出
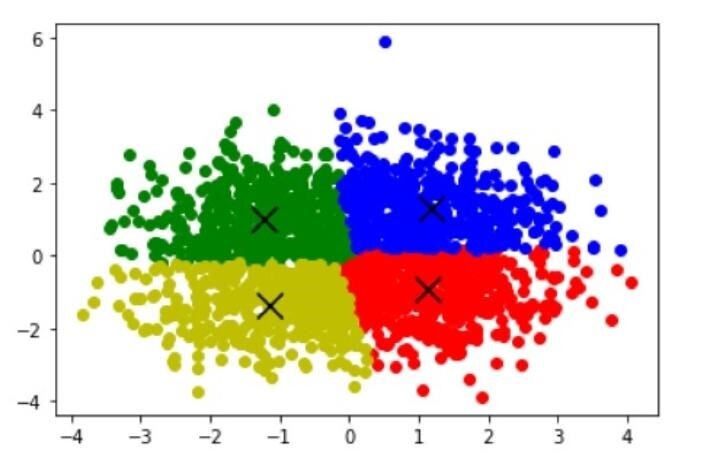
上述代码将数据点分组为 4 个聚类,并根据其聚类分配用不同的颜色绘制数据点。聚类质心用“x”标记表示。
可以调整聚类数量以适应您的数据和问题。
在本例中,我使用了上面给出的链接中的数据集,然后使用 k-means 算法进行聚类并可视化结果。
请记住,k-means 算法对初始条件敏感,因此如果使用不同的初始质心多次运行它,结果可能会有所不同。
使用 SciPy 的层次聚类
层次聚类是一种聚类方法,它创建聚类的层次结构,其中每个聚类都是前一个聚类的子集。层次结构表示为树状结构,称为树状图。这是一种强大的方法,用于探索和可视化大型数据集的结构。尽管如此,对于大型数据集来说,它在计算上可能代价高昂,并且对所使用的链接方法敏感。
示例
from scipy.cluster.hierarchy import linkage, dendrogram, cut_tree # sample data points data = [[1, 2], [1, 4], [1, 0], [4, 2], [4, 4], [4, 0]] # create linkage matrix Z = linkage(data, method='ward') # create dendrogram dendrogram(Z) # cut the dendrogram at a threshold to obtain clusters clusters = cut_tree(Z, height=2) import matplotlib.pyplot as plt plt.figure() dendrogram(Z, labels = ["data1","data2","data3","data4","data5","data6"]) plt.show()
输出
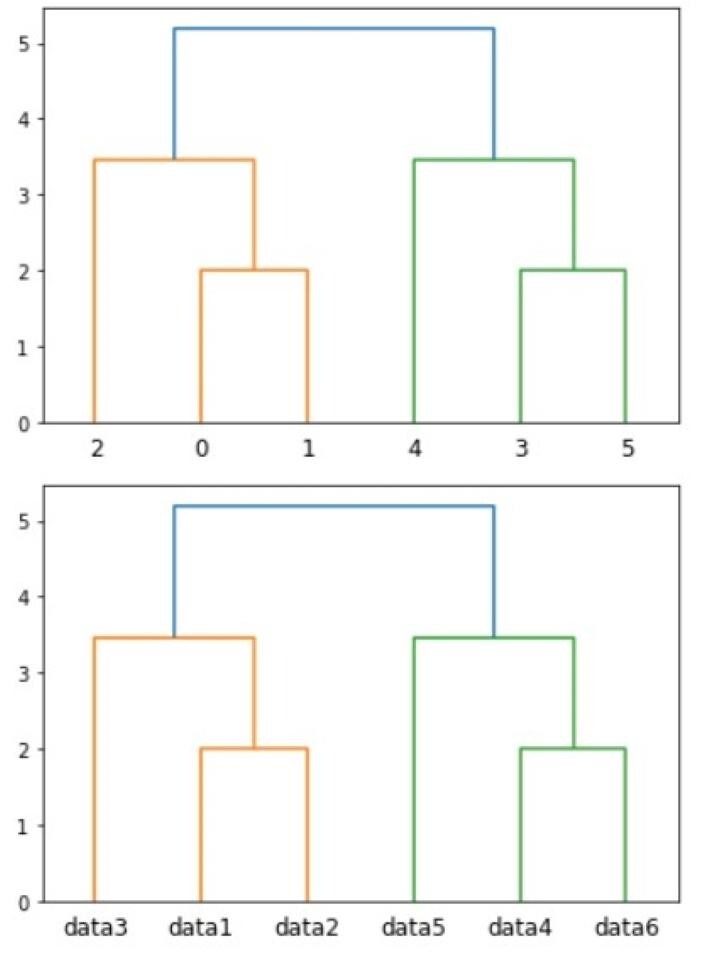
上述代码将使用链接方法“ward”将数据点分组到聚类中,该方法最大程度地减少了被链接的聚类之间距离的方差。dendrogram 函数用于绘制树状图,它是层次聚类解决方案的可视化。cut_tree 函数用于在给定阈值处从树状图中提取聚类。cut_tree 函数的输出是每个数据点的聚类标签列表。也可以使用 matplotlib 库可视化树状图并自定义外观,例如线条、标签等的颜色和大小。
结论
SciPy 并非适用于所有类型的聚类,但它可以高效地执行 k-means 和层次聚类。SciPy 的 k-means 算法是一种简单有效的方法,用于将数据集划分为固定数量的聚类。层次聚类是一种创建聚类层次结构的方法,其中每个聚类都是前一个聚类的子集。像 DBSCAN 这样广泛使用的算法无法使用 SciPy 实现。
因此,如果您正在寻找各种聚类算法,并内置支持预处理、评估和更多灵活性,那么 scikit-learn 是最佳选择。

142 次查看
