
 数据结构
数据结构 网络
网络 关系数据库管理系统 (RDBMS)
关系数据库管理系统 (RDBMS) 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 编程
C 编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP使用 Pandas 处理日期和时间
Python 数据分析和处理的核心部分是使用 Pandas 处理日期和时间。强大的 Pandas 库提供了有效的方法来处理和检查时间序列数据。它提供了一个 DateTimeIndex,可以轻松地索引 DataFrames 并对其执行基于时间的操作。用户可以通过将字符串或其他表示形式转换为 Pandas DateTime 对象来为其数据构建 DateTimeIndexes,从而简化时间感知分析。该库支持重新采样、时间膨胀和日期范围创建,从而简化了基于时间的数据的组合和处理。此外,Pandas 还支持管理时区,从而能够进行大数据分析的 timestamp 转换和转换。
安装命令
在使用 Pandas 之前,必须在您的计算机系统上安装它。使用 Python 的包管理器 pip,运行以下命令:
pip install pandas
Pandas 的特性
DataFrame:DataFrame 是 Pandas 引入的一个新特性,它是一个二维标记数据结构,类似于电子表格或 SQL 表。它允许有效地管理行和列中的数据,并促进各种数据操作。
Series:Series 是一维标记数组,具有类似于列表或 NumPy 数组的附加功能。Series 充当 DataFrames 的基本单元,可以存储各种数据类型。
数据对齐:即使数据来自多个来源,Pandas 也会根据标签自动对齐数据,因此数据操作(如算术运算)也能正确执行。
数据清洗:Pandas 提供了各种处理缺失数据的方法,例如 dropna(),它删除 NaN 值,以及 fillna(),它使用指定的方法填充缺失值。
数据重塑:借助 Pandas 提供的灵活工具,用户可以使用 pivot_table()、melt() 和 stack()/unstack() 方法轻松地重塑数据。
分组和聚合:Pandas 提供的 groupby() 方法允许用户根据特定标准将数据分成组,然后对每个组应用聚合函数,例如 sum、mean、max 等。
合并、连接和串联:Pandas 通过 merge()、join() 和 concat() 等方法,使得可以无缝地集成和合并来自多个来源的数据。
时间序列分析:Pandas 提供了广泛的功能来处理时间序列数据,包括日期范围构建、基于时间的索引以及以不同频率重新采样。
数据 I/O:Pandas 可以读取和写入多种不同格式的数据,例如 CSV、Excel、SQL 数据库等。
基于标签的索引:Pandas 的多功能性和用户友好性,使得根据标签或条件轻松地切片、选择和更新数据。
数据可视化:Pandas 本身不处理数据可视化,但它可以轻松地与其他库(如 Matplotlib 和 Seaborn)交互,允许用户使用 Pandas 数据创建有用的图表和图形。
使用 Pandas 的基本程序
创建 DataFrame
创建 DateTimeIndex 和重新采样
过滤数据
创建 DataFrame
在基于 Python 的数据分析和处理中,创建一个 Pandas DataFrame 是一个关键步骤。Pandas 作为一个强大的库,提供了一个称为 DataFrame 的二维标记数据结构,类似于电子表格或 SQL 表。Pandas 允许将数据组织成行和列,从而简化数据管理和分析。
算法
导入 Pandas 库。
准备打算在 DataFrame 中使用的数据。您可以使用字典、字典列表、列表列表或 NumPy 数组。
使用 pd.DataFrame() 构造函数创建 DataFrame。将数据以及任何可选参数(包括列名和索引)传递给构造函数。
您可以选择使用 pd.DataFrame() 构造函数的 index 参数设置索引,使用 columns 参数设置列名。
现在 DataFrame 可用于编辑和数据分析。
示例
import pandas as pd
data_dict = {
'Name': ['Rahul', 'Anjali', 'Siddharth'],
'Age': [15, 33, 51],
'City': ['Mumbai', 'Goa', 'Jammu']
}
df1 = pd.DataFrame(data_dict)
dataListOfDicts = [
{'Name': 'Komal', 'Age': 25, 'City': 'Pune'},
{'Name': 'Bulbul', 'Age': 30, 'City': 'Agra'},
{'Name': 'Aarush', 'Age': 35, 'City': 'Meerut'}
]
df2 = pd.DataFrame(dataListOfDicts)
data_list_of_lists = [
['Anmol', 27, 'Hyderabad'],
['Tarun', 20, 'Mumbai'],
['Srijan', 31, 'Chandigarh']
]
df3 = pd.DataFrame(data_list_of_lists, columns=['Name', 'Age', 'City'])
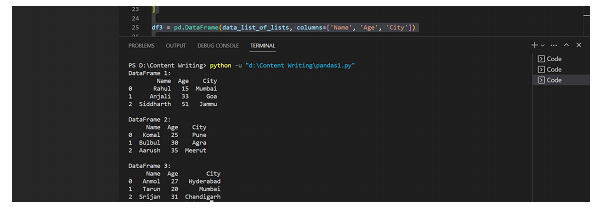
print("DataFrame 1:")
print(df1)
print("\nDataFrame 2:")
print(df2)
print("\nDataFrame 3:")
print(df3)
输出
创建 DateTimeIndex 和重新采样
在基于 Python 的数据分析和处理中,创建一个 Pandas DataFrame 是一个关键步骤。Pandas 作为一个强大的库,提供了一个称为 DataFrame 的二维标记数据结构,类似于电子表格或 SQL 表。Pandas 允许将数据组织成行和列,从而简化数据管理和分析。
算法
导入 Pandas 库。
准备一个包含日期或时间戳列的 DataFrame 数据。
使用 pd.to_datetime() 将日期或时间戳列转换为 Pandas DateTimeIndex。
使用 set_index() 函数将 DateTimeIndex 设置为 DataFrame 的索引。
使用 resample() 方法将数据重新采样到不同的频率后,您可以使用聚合函数(如 mean、sum 等)来获取新频率的值。
示例
import pandas as pd
data = {
'Date': ['2023-07-25', '2023-07-26', '2023-07-27', '2023-07-28', '2023-07-29'],
'Value': [10, 15, 8, 12, 20]
}
df = pd.DataFrame(data)
df['Date'] = pd.to_datetime(df['Date'])
df.set_index('Date', inplace=True)
monthly_data = df.resample('M').mean()
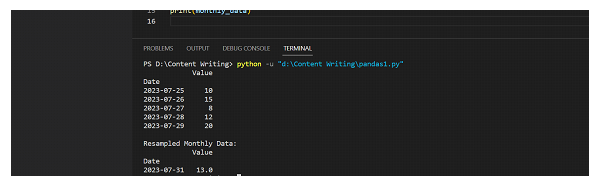
print(df)
print("\nResampled Monthly Data:")
print(monthly_data)
输出
过滤数据
Pandas 提供了强大的基于布尔索引的数据过滤功能。用户可以通过构建带有应用于 DataFrame 列的条件的布尔掩码,快速选择满足过滤条件的行。数据分析师可以使用此方法专注于相关信息,调查趋势,查找模式并对特定数据子集进行进一步研究。
算法
导入 Pandas 库。
数据准备可以在 DataFrame 中完成,或者例如从 CSV 文件读取数据。
结合布尔索引和条件来根据特定要求过滤数据。
将条件应用于一个或多个 DataFrame 列以创建布尔掩码。
使用布尔掩码选择满足过滤条件的行。
示例
import pandas as pd
data = {
'Name': ['Arushi', 'Shobhit', 'Tarun', 'Dishmeet', 'Evan'],
'Age': [25, 30, 35, 28, 40],
'City': ['Mumbai', 'Delhi', 'Goa', 'Bareilly', 'Agra']
}
df = pd.DataFrame(data)
filtered_df = df[df['Age'] > 30]
print(filtered_df)
输出
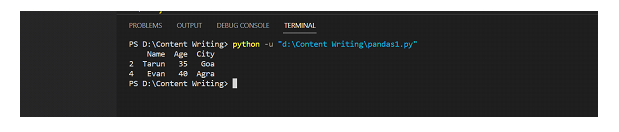
结论
Python 的 Pandas 库简化了时间和日期的处理,用于时间数据的处理。借助 Pandas 的 DateTimeIndex 和函数,用户可以有效地执行基于时间的索引、重新采样和时区管理。该库的灵活性使日期计算、过滤和时间序列可视化更加容易。它与其他 Python 工具的无缝集成增强了数据探索和操作。从银行和经济学到天气预报和社会趋势分析,Pandas 在各种应用中对于处理和分析与时间相关的数据至关重要。它使分析师能够获得有见地的知识。

241 次浏览
