- Apache Flink 教程
- Apache Flink - 首页
- Apache Flink - 大数据平台
- 批处理与实时处理
- Apache Flink - 简介
- Apache Flink - 架构
- Apache Flink - 系统要求
- Apache Flink - 设置/安装
- Apache Flink - API 概念
- Apache Flink - Table API 和 SQL
- 创建 Flink 应用程序
- Apache Flink - 运行 Flink 程序
- Apache Flink - 库
- Apache Flink - 机器学习
- Apache Flink - 使用案例
- Apache Flink - Flink 与 Spark 与 Hadoop 的比较
- Apache Flink - 总结
- Apache Flink 资源
- Apache Flink 快速指南
- Apache Flink - 有用资源
- Apache Flink - 讨论
Apache Flink 快速指南
Apache Flink - 大数据平台
过去十年中,数据的发展速度惊人;这催生了一个术语“大数据”。大数据没有固定的数据大小,任何传统系统(RDBMS)无法处理的数据都可以称为大数据。这些大数据可以是结构化、半结构化或非结构化格式。最初,数据有三个维度:容量、速度、多样性。现在,维度已经超出了这三个 V。我们现在添加了其他 V - 真实性、有效性、脆弱性、价值、可变性等。
大数据导致了多种工具和框架的出现,这些工具和框架有助于数据的存储和处理。有一些流行的大数据框架,例如 Hadoop、Spark、Hive、Pig、Storm 和 Zookeeper。它还为在医疗保健、金融、零售、电子商务等多个领域创建下一代产品提供了机会。
无论是跨国公司还是初创企业,每个人都利用大数据来存储和处理它,并做出更明智的决策。
Apache Flink - 批处理与实时处理
在 Big Data 方面,有两种类型的处理:
- 批处理
- 实时处理
基于一段时间内收集的数据进行的处理称为批处理。例如,银行经理希望处理过去一个月的历史数据(随时间推移收集),以了解过去一个月内有多少支票被取消。
基于即时数据进行处理以获得即时结果称为实时处理。例如,银行经理在欺诈交易(即时结果)发生后立即收到欺诈警报。
下表列出了批处理和实时处理之间的区别:
| 批处理 | 实时处理 |
|---|---|
静态文件 |
事件流 |
以分钟、小时、天等为周期进行处理 |
立即处理 纳秒 |
磁盘存储上的历史数据 |
内存存储 |
示例 - 生成账单 |
示例 - 自动取款机交易警报 |
如今,实时处理在每个组织中都被广泛使用。诸如欺诈检测、医疗保健中的实时警报和网络攻击警报等用例需要对即时数据进行实时处理;即使延迟几毫秒也会产生巨大的影响。
对于此类实时用例的理想工具应该是可以将数据作为流而不是批处理输入的工具。Apache Flink 就是这样的实时处理工具。
Apache Flink - 简介
Apache Flink 是一个实时处理框架,可以处理流数据。它是一个开源的流处理框架,用于构建高性能、可扩展和准确的实时应用程序。它具有真正的流模型,并且不将输入数据作为批处理或微批处理。
Apache Flink 由 Data Artisans 公司创立,现在由 Apache Flink 社区在 Apache 许可下开发。到目前为止,该社区拥有 479 多位贡献者和 15500 多次提交。
Apache Flink 生态系统
下图显示了 Apache Flink 生态系统的不同层:
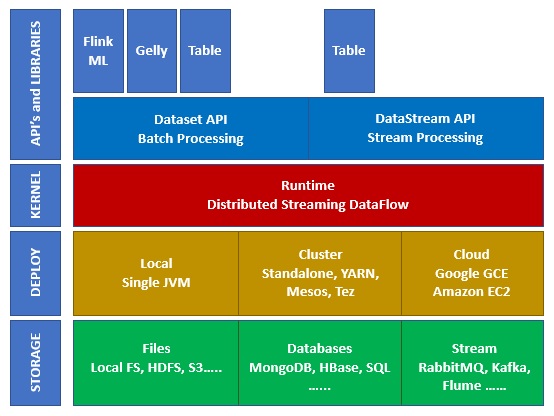
存储
Apache Flink 可以从多个选项中读取/写入数据。下面是一个基本的存储列表:
- HDFS(Hadoop 分布式文件系统)
- 本地文件系统
- S3
- RDBMS(MySQL、Oracle、MS SQL 等)
- MongoDB
- HBase
- Apache Kafka
- Apache Flume
部署
您可以以本地模式、集群模式或云模式部署 Apache Fink。集群模式可以是独立的、YARN、MESOS。
在云端,Flink 可以部署在 AWS 或 GCP 上。
内核
这是运行时层,它提供分布式处理、容错、可靠性、本地迭代处理能力等。
API 和库
这是 Apache Flink 的顶层也是最重要的一层。它具有 Dataset API,负责批处理,以及 Datastream API,负责流处理。还有其他库,如 Flink ML(用于机器学习)、Gelly(用于图处理)、Tables 用于 SQL。此层为 Apache Flink 提供了多种功能。
Apache Flink - 架构
Apache Flink 基于 Kappa 架构。Kappa 架构具有单个处理器 - 流,它将所有输入视为流,流引擎实时处理数据。Kappa 架构中的批处理是流处理的特例。
下图显示了**Apache Flink 架构**。
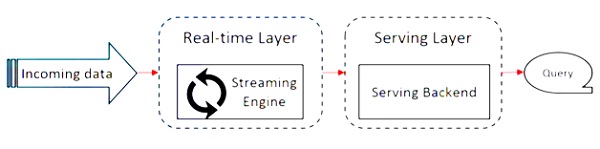
Kappa 架构的关键思想是通过单个流处理引擎处理批处理和实时数据。
大多数大数据框架都基于 Lambda 架构,该架构具有用于批处理和流数据的单独处理器。在 Lambda 架构中,您为批处理和流视图具有单独的代码库。为了查询和获取结果,需要合并代码库。不维护单独的代码库/视图并合并它们是一件痛苦的事情,但 Kappa 架构解决了这个问题,因为它只有一个视图 - 实时视图,因此不需要合并代码库。
这并不意味着 Kappa 架构取代了 Lambda 架构,它完全取决于用例和应用程序,决定哪种架构更可取。
下图显示了 Apache Flink 作业执行架构。
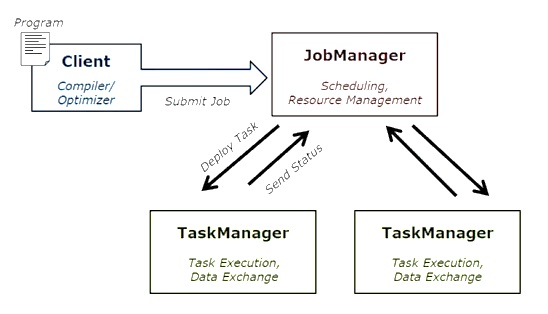
程序
它是您在 Flink 集群上运行的一段代码。
客户端
它负责获取代码(程序)并构建作业数据流图,然后将其传递给 JobManager。它还检索作业结果。
JobManager
在从客户端接收作业数据流图后,它负责创建执行图。它将作业分配给集群中的 TaskManager 并监督作业的执行。
TaskManager
它负责执行 JobManager 分配的所有任务。所有 TaskManager 都以指定的并行度在其单独的槽中运行任务。它负责将任务状态发送到 JobManager。
Apache Flink 的特性
Apache Flink 的特性如下:
它有一个流处理器,可以运行批处理和流程序。
它可以以闪电般的速度处理数据。
提供 Java、Scala 和 Python 的 API。
为所有常见操作提供 API,程序员非常容易使用。
以低延迟(纳秒)和高吞吐量处理数据。
它具有容错性。如果节点、应用程序或硬件发生故障,它不会影响集群。
可以轻松与 Apache Hadoop、Apache MapReduce、Apache Spark、HBase 和其他大数据工具集成。
可以自定义内存管理以获得更好的计算性能。
它具有高度可扩展性,可以扩展到集群中的数千个节点。
Apache Flink 中的窗口非常灵活。
提供图处理、机器学习、复杂事件处理库。
Apache Flink - 系统要求
以下是下载和使用 Apache Flink 的系统要求:
推荐的操作系统
- Microsoft Windows 10
- Ubuntu 16.04 LTS
- Apple macOS 10.13/High Sierra
内存要求
- 内存 - 最低 4 GB,推荐 8 GB
- 存储空间 - 30 GB
注意 - 必须安装 Java 8 并已设置环境变量。
Apache Flink - 设置/安装
在开始设置/安装 Apache Flink 之前,让我们检查一下我们的系统中是否安装了 Java 8。
Java - version
现在我们将继续下载 Apache Flink。
wget http://mirrors.estointernet.in/apache/flink/flink-1.7.1/flink-1.7.1-bin-scala_2.11.tgz
现在,解压缩 tar 文件。
tar -xzf flink-1.7.1-bin-scala_2.11.tgz

转到 Flink 的主目录。
cd flink-1.7.1/
启动 Flink 集群。
./bin/start-cluster.sh
打开 Mozilla 浏览器并访问以下 URL,它将打开 Flink Web 仪表板。
https://:8081
这就是 Apache Flink 仪表板的用户界面。
现在 Flink 集群已启动并运行。
Apache Flink - API 概念
Flink 有一套丰富的 API,开发人员可以使用这些 API 对批处理和实时数据执行转换。各种转换包括映射、过滤、排序、连接、分组和聚合。Apache Flink 的这些转换是在分布式数据上执行的。让我们讨论一下 Apache Flink 提供的不同 API。
Dataset API
Apache Flink 中的 Dataset API 用于对一段时间内的数据执行批处理操作。此 API 可用于 Java、Scala 和 Python。它可以对数据集应用各种转换,例如过滤、映射、聚合、连接和分组。
数据集是从诸如本地文件之类的源创建的,或者通过从特定源读取文件来创建,结果数据可以写入不同的接收器,例如分布式文件或命令行终端。此 API 受 Java 和 Scala 编程语言的支持。
这是一个 Dataset API 的 Wordcount 程序:
public class WordCountProg {
public static void main(String[] args) throws Exception {
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSet<String> text = env.fromElements(
"Hello",
"My Dataset API Flink Program");
DataSet<Tuple2<String, Integer>> wordCounts = text
.flatMap(new LineSplitter())
.groupBy(0)
.sum(1);
wordCounts.print();
}
public static class LineSplitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String line, Collector<Tuple2<String, Integer>> out) {
for (String word : line.split(" ")) {
out.collect(new Tuple2<String, Integer>(word, 1));
}
}
}
}
DataStream API
此 API 用于处理连续流中的数据。您可以对流数据执行各种操作,例如过滤、映射、窗口化、聚合。此数据流有各种来源,例如消息队列、文件、套接字流,结果数据可以写入不同的接收器,例如命令行终端。Java 和 Scala 编程语言都支持此 API。
这是一个 DataStream API 的流式 Wordcount 程序,其中您有连续的单词计数流,并且数据在第二个窗口中进行分组。
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
public class WindowWordCountProg {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Tuple2<String, Integer>> dataStream = env
.socketTextStream("localhost", 9999)
.flatMap(new Splitter())
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1);
dataStream.print();
env.execute("Streaming WordCount Example");
}
public static class Splitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String sentence, Collector<Tuple2<String, Integer>> out) throws Exception {
for (String word: sentence.split(" ")) {
out.collect(new Tuple2<String, Integer>(word, 1));
}
}
}
}
Apache Flink - Table API 和 SQL
Table API 是一种关系 API,具有类似 SQL 的表达式语言。此 API 可以执行批处理和流处理。它可以嵌入到 Java 和 Scala 的 Dataset 和 Datastream API 中。您可以从现有的 Dataset 和 Datastream 或外部数据源创建表。通过此关系 API,您可以执行诸如连接、聚合、选择和过滤等操作。无论输入是批处理还是流,查询的语义都保持相同。
这是一个 Table API 程序示例:
// for batch programs use ExecutionEnvironment instead of StreamExecutionEnvironment
val env = StreamExecutionEnvironment.getExecutionEnvironment
// create a TableEnvironment
val tableEnv = TableEnvironment.getTableEnvironment(env)
// register a Table
tableEnv.registerTable("table1", ...) // or
tableEnv.registerTableSource("table2", ...) // or
tableEnv.registerExternalCatalog("extCat", ...)
// register an output Table
tableEnv.registerTableSink("outputTable", ...);
// create a Table from a Table API query
val tapiResult = tableEnv.scan("table1").select(...)
// Create a Table from a SQL query
val sqlResult = tableEnv.sqlQuery("SELECT ... FROM table2 ...")
// emit a Table API result Table to a TableSink, same for SQL result
tapiResult.insertInto("outputTable")
// execute
env.execute()
Apache Flink - 创建 Flink 应用程序
在本章中,我们将学习如何创建 Flink 应用程序。
打开 Eclipse IDE,单击“新建项目”,然后选择“Java 项目”。
输入项目名称,然后单击“完成”。
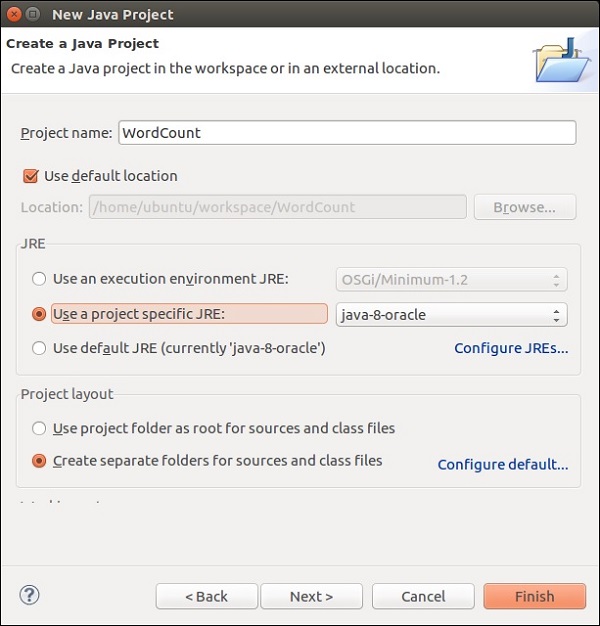
现在,单击“完成”,如下图所示。
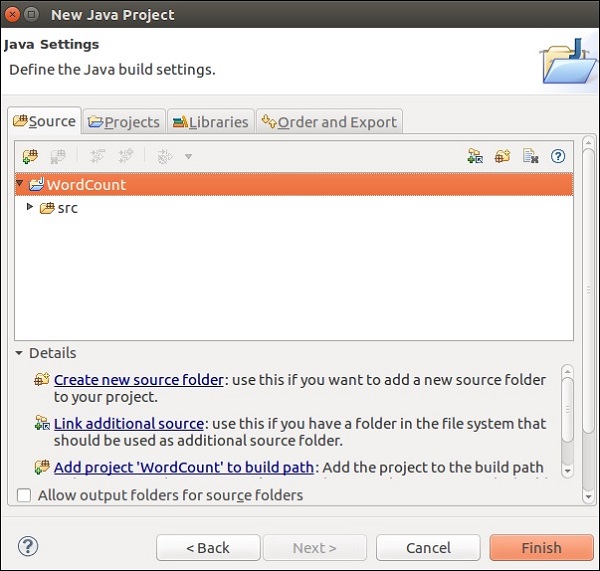
现在,右键单击**src**,然后转到“新建”>“类”。
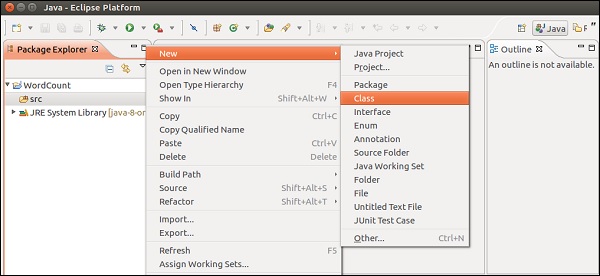
输入类名,然后单击“完成”。
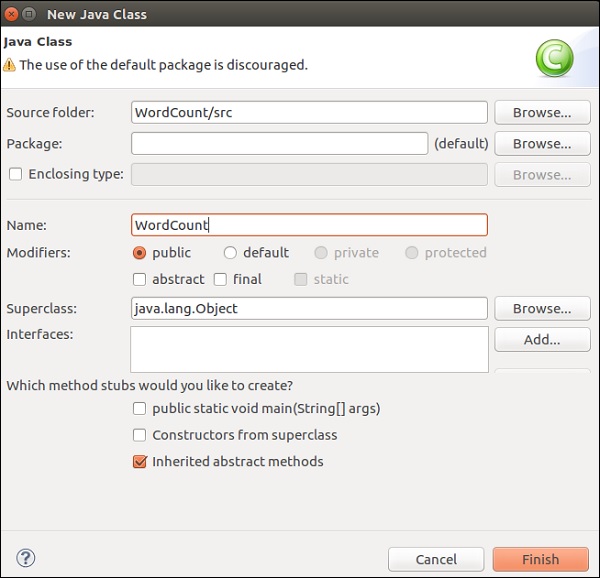
复制并粘贴以下代码到编辑器中。
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.util.Collector;
public class WordCount {
// *************************************************************************
// PROGRAM
// *************************************************************************
public static void main(String[] args) throws Exception {
final ParameterTool params = ParameterTool.fromArgs(args);
// set up the execution environment
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// make parameters available in the web interface
env.getConfig().setGlobalJobParameters(params);
// get input data
DataSet<String> text = env.readTextFile(params.get("input"));
DataSet<Tuple2<String, Integer>> counts =
// split up the lines in pairs (2-tuples) containing: (word,1)
text.flatMap(new Tokenizer())
// group by the tuple field "0" and sum up tuple field "1"
.groupBy(0)
.sum(1);
// emit result
if (params.has("output")) {
counts.writeAsCsv(params.get("output"), "\n", " ");
// execute program
env.execute("WordCount Example");
} else {
System.out.println("Printing result to stdout. Use --output to specify output path.");
counts.print();
}
}
// *************************************************************************
// USER FUNCTIONS
// *************************************************************************
public static final class Tokenizer implements FlatMapFunction<String, Tuple2<String, Integer>> {
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
// normalize and split the line
String[] tokens = value.toLowerCase().split("\\W+");
// emit the pairs
for (String token : tokens) {
if (token.length() > 0) {
out.collect(new Tuple2<>(token, 1));
}
}
}
}
}
您将在编辑器中看到许多错误,因为需要将 Flink 库添加到此项目中。
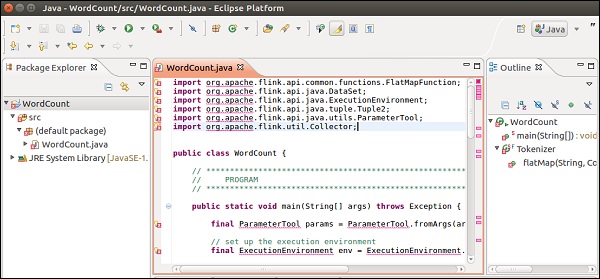
右键点击项目 >> 构建路径 >> 配置构建路径。
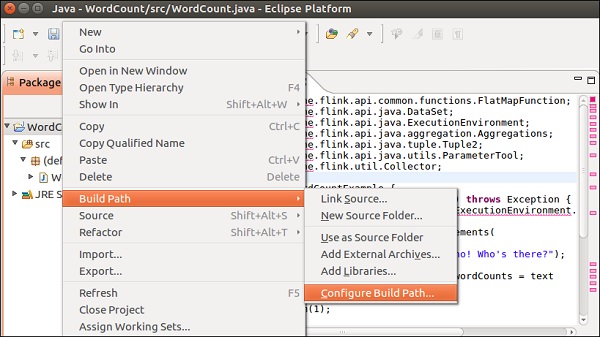
选择“库”选项卡,然后点击“添加外部JAR文件”。
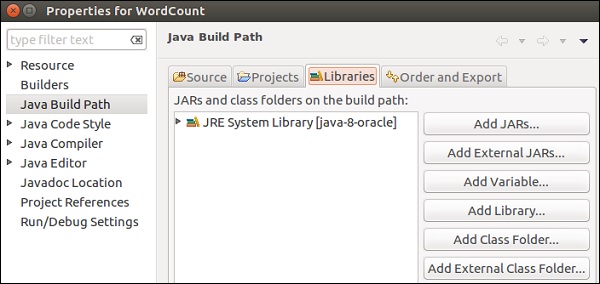
转到Flink的lib目录,选择所有4个库,然后点击“确定”。
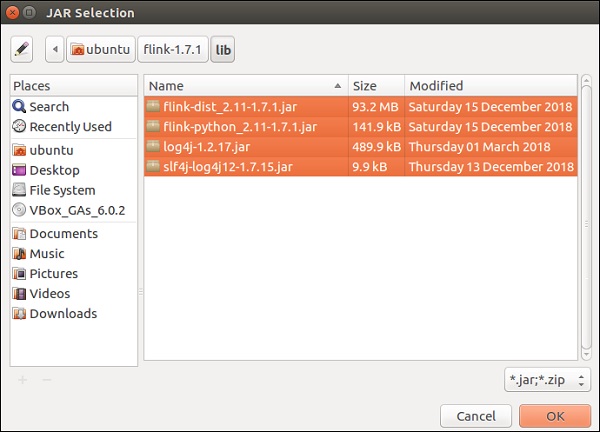
转到“顺序和导出”选项卡,选择所有库,然后点击“确定”。
您会看到错误已经消失了。
现在,让我们导出此应用程序。右键点击项目,然后点击“导出”。
选择JAR文件,然后点击“下一步”。
指定目标路径,然后点击“下一步”。
点击“下一步”。
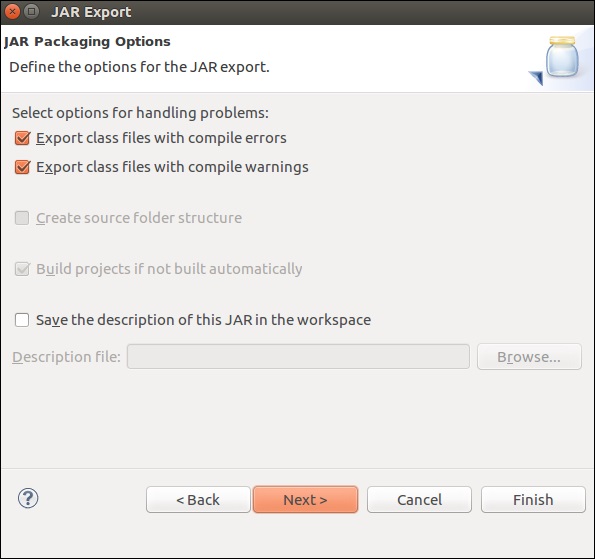
点击“浏览”,选择主类(WordCount),然后点击“完成”。
注意 - 如果出现任何警告,请点击“确定”。
运行以下命令。它将进一步运行您刚刚创建的Flink应用程序。
./bin/flink run /home/ubuntu/wordcount.jar --input README.txt --output /home/ubuntu/output

Apache Flink - 运行 Flink 程序
在本章中,我们将学习如何运行Flink程序。
让我们在Flink集群上运行Flink单词计数示例。
转到Flink的主目录,并在终端中运行以下命令。
bin/flink run examples/batch/WordCount.jar -input README.txt -output /home/ubuntu/flink-1.7.1/output.txt

转到Flink仪表板,您将能够看到一个已完成的作业及其详细信息。
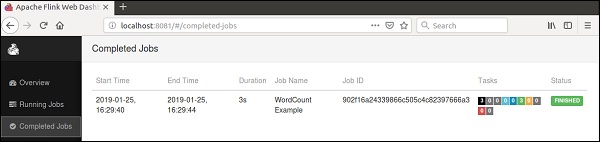
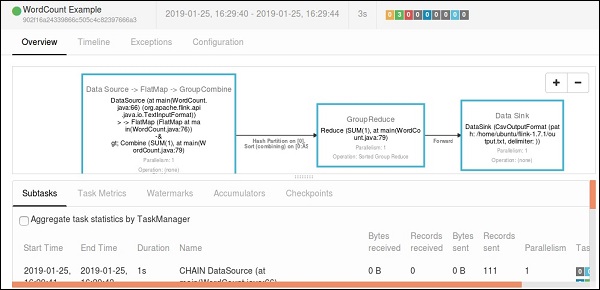
如果您点击“已完成作业”,您将获得作业的详细概述。
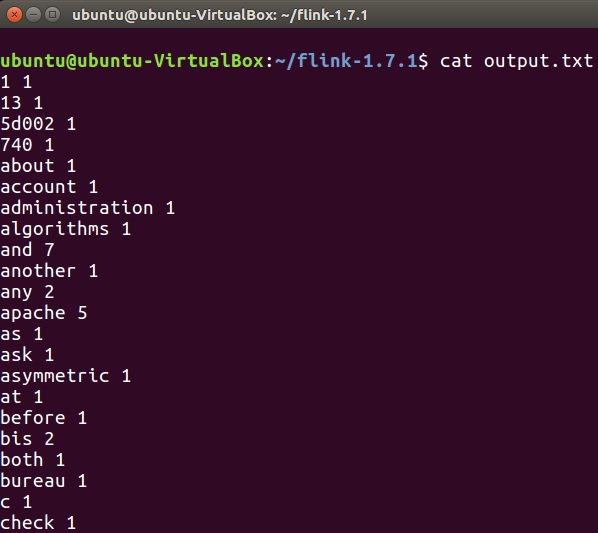
要检查单词计数程序的输出,请在终端中运行以下命令。
cat output.txt
Apache Flink - 库
在本章中,我们将了解Apache Flink的不同库。
复杂事件处理(CEP)
FlinkCEP是Apache Flink中的一个API,它分析连续流数据上的事件模式。这些事件是近乎实时的,具有高吞吐量和低延迟。此API主要用于传感器数据,这些数据实时传入,处理起来非常复杂。
CEP分析输入流的模式并很快给出结果。它能够在事件模式复杂的情况下提供实时通知和警报。FlinkCEP可以连接到不同类型的输入源并在其中分析模式。
以下是带有CEP的示例架构:
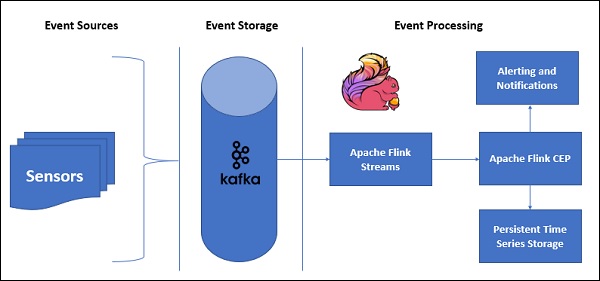
传感器数据将来自不同的来源,Kafka将充当分布式消息框架,它将流分发到Apache Flink,FlinkCEP将分析复杂的事件模式。
您可以使用Pattern API在Apache Flink中编写用于复杂事件处理的程序。它允许您确定要从连续流数据中检测的事件模式。以下是一些最常用的CEP模式:
开始
用于定义起始状态。以下程序显示了如何在Flink程序中定义它:
Pattern<Event, ?> next = start.next("next");
其中
用于在当前状态中定义过滤器条件。
patternState.where(new FilterFunction <Event>() {
@Override
public boolean filter(Event value) throws Exception {
}
});
下一页
用于附加新的模式状态以及传递先前模式所需的匹配事件。
Pattern<Event, ?> next = start.next("next");
后跟
用于附加新的模式状态,但此处两个匹配事件之间可能会发生其他事件。
Pattern<Event, ?> followedBy = start.followedBy("next");
Gelly
Apache Flink的图API是Gelly。Gelly用于使用一组方法和实用程序在Flink应用程序上执行图分析。您可以使用Apache Flink API以分布式方式使用Gelly分析大型图。还有其他图库,例如Apache Giraph,用于相同目的,但由于Gelly是在Apache Flink之上使用的,因此它使用单个API。这在开发和操作方面非常有帮助。
让我们使用Apache Flink API - Gelly运行一个示例。
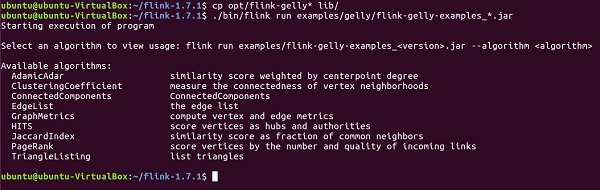
首先,您需要将2个Gelly jar文件从Apache Flink的opt目录复制到其lib目录。然后运行flink-gelly-examples jar。
cp opt/flink-gelly* lib/ ./bin/flink run examples/gelly/flink-gelly-examples_*.jar
现在让我们运行PageRank示例。
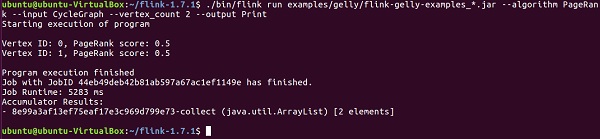
PageRank计算每个顶点的分数,它是通过入边传输的PageRank分数的总和。每个顶点的分数平均分配到出边。高分顶点与其他高分顶点链接。
结果包含顶点ID和PageRank分数。
usage: flink run examples/flink-gelly-examples_<version>.jar --algorithm PageRank [algorithm options] --input <input> [input options] --output <output> [output options] ./bin/flink run examples/gelly/flink-gelly-examples_*.jar --algorithm PageRank --input CycleGraph --vertex_count 2 --output Print
Apache Flink - 机器学习
Apache Flink的机器学习库称为FlinkML。由于机器学习的使用在过去5年中呈指数级增长,因此Flink社区决定在其生态系统中也添加此机器学习APO。FlinkML中的贡献者和算法列表正在增加。此API尚未成为二进制分发的一部分。
以下是用FlinkML进行线性回归的示例:
// LabeledVector is a feature vector with a label (class or real value) val trainingData: DataSet[LabeledVector] = ... val testingData: DataSet[Vector] = ... // Alternatively, a Splitter is used to break up a DataSet into training and testing data. val dataSet: DataSet[LabeledVector] = ... val trainTestData: DataSet[TrainTestDataSet] = Splitter.trainTestSplit(dataSet) val trainingData: DataSet[LabeledVector] = trainTestData.training val testingData: DataSet[Vector] = trainTestData.testing.map(lv => lv.vector) val mlr = MultipleLinearRegression() .setStepsize(1.0) .setIterations(100) .setConvergenceThreshold(0.001) mlr.fit(trainingData) // The fitted model can now be used to make predictions val predictions: DataSet[LabeledVector] = mlr.predict(testingData)
在flink-1.7.1/examples/batch/路径中,您将找到KMeans.jar文件。让我们运行此示例FlinkML示例。
此示例程序使用默认点和质心数据集运行。
./bin/flink run examples/batch/KMeans.jar --output Print

Apache Flink - 使用案例
在本章中,我们将了解Apache Flink中的一些测试用例。
Apache Flink - Bouygues Telecom
Bouygues Telecom是法国最大的电信公司之一。它拥有1100多万移动用户和250多万固定用户。Bouygues在巴黎举行的Hadoop小组会议上第一次听说Apache Flink。从那时起,他们一直在将Flink用于多种用例。他们每天通过Apache Flink实时处理数十亿条消息。
以下是Bouygues对Apache Flink的评价:“我们最终选择了Flink,因为该系统支持真正的流处理 - 同时在API和运行时级别,为我们提供了我们正在寻找的可编程性和低延迟。此外,与其他解决方案相比,我们能够在很短的时间内启动并运行我们的Flink系统,这使得开发人员能够有更多资源来扩展系统中的业务逻辑。”
在Bouygues,客户体验是重中之重。他们实时分析数据,以便能够向其工程师提供以下见解:
通过其网络的实时客户体验
网络上发生的全球事件
网络评估和运营
他们创建了一个名为LUX(Logged User Experience)的系统,该系统处理来自网络设备的大量日志数据以及内部数据参考,以提供体验质量指标,这些指标将记录其客户体验并构建警报功能,以便在60秒内检测数据使用中的任何故障。
为了实现这一点,他们需要一个能够实时处理海量数据、易于设置并提供丰富的API来处理流数据的框架。Apache Flink非常适合Bouygues Telecom。
Apache Flink - 阿里巴巴
阿里巴巴是全球最大的电子商务零售公司,2015年收入为3940亿美元。阿里巴巴搜索是所有客户的入口点,它显示所有搜索并相应地推荐。
阿里巴巴在其搜索引擎中使用Apache Flink,以便为每个用户以最高的准确性和相关性实时显示结果。
阿里巴巴正在寻找一个框架,该框架:
在维护整个搜索基础设施过程的单个代码库方面非常敏捷。
为网站上产品的可用性变化提供低延迟。
一致且经济高效。
Apache Flink满足了上述所有要求。他们需要一个具有单个处理引擎的框架,并且可以使用相同的引擎处理批处理和流数据,而这正是Apache Flink所做的。
他们还使用Blink(Flink的分支版本)来满足其搜索的一些独特要求。他们还在其搜索中使用Apache Flink的Table API并进行了一些改进。
以下是阿里巴巴对apache Flink的评价:“回顾过去,毫无疑问,Blink和Flink在阿里巴巴取得了巨大进步。没有人想到我们会在一年内取得如此大的进步,我们非常感谢社区中帮助我们的人。Flink已被证明可以在非常大的规模上工作。我们比以往任何时候都更加致力于继续与社区合作,推动Flink向前发展!”
Apache Flink - Flink 与 Spark 与 Hadoop 的比较
这是一个综合表,显示了三个最流行的大数据框架之间的比较:Apache Flink、Apache Spark和Apache Hadoop。
| Apache Hadoop | Apache Spark | Apache Flink | |
|---|---|---|---|
起源年份 |
2005 | 2009 | 2009 |
起源地 |
MapReduce(谷歌)Hadoop(雅虎) | 加州大学伯克利分校 | 柏林工业大学 |
数据处理引擎 |
批处理 | 批处理 | 流处理 |
处理速度 |
比Spark和Flink慢 | 比Hadoop快100倍 | 比Spark快 |
编程语言 |
Java、C、C++、Ruby、Groovy、Perl、Python | Java、Scala、Python和R | Java和Scala |
编程模型 |
MapReduce | 弹性分布式数据集(RDD) | 循环数据流 |
数据传输 |
批处理 | 批处理 | 流水线和批处理 |
内存管理 |
基于磁盘 | JVM管理 | 主动管理 |
延迟 |
低 | 中 | 低 |
吞吐量 |
中 | 高 | 高 |
优化 |
手动 | 手动 | 自动 |
API |
低级 | 高级 | 高级 |
流处理支持 |
否 | Spark Streaming | Flink Streaming |
SQL支持 |
Hive、Impala | SparkSQL | Table API和SQL |
图支持 |
否 | GraphX | Gelly |
机器学习支持 |
否 | SparkML | FlinkML |
Apache Flink - 总结
我们在上一章看到的比较表总结了要点。Apache Flink是最适合实时处理和用例的框架。其单引擎系统是独一无二的,可以使用不同的API(如Dataset和DataStream)处理批处理和流数据。
但这并不意味着Hadoop和Spark已经过时,选择最适合的大数据框架始终取决于用例并因用例而异。可能会有几种用例,其中Hadoop和Flink或Spark和Flink的组合可能更合适。
尽管如此,Flink目前仍然是最佳的实时处理框架。Apache Flink的增长令人惊叹,其社区的贡献者数量也与日俱增。
Flink快乐!