- Apache MXNet 教程
- Apache MXNet - 首页
- Apache MXNet - 简介
- Apache MXNet - 安装 MXNet
- Apache MXNet - 工具包和生态系统
- Apache MXNet - 系统架构
- Apache MXNet - 系统组件
- Apache MXNet - 统一算子 API
- Apache MXNet - 分布式训练
- Apache MXNet - Python 包
- Apache MXNet - NDArray
- Apache MXNet - Gluon
- Apache MXNet - KVStore 和可视化
- Apache MXNet - Python API ndarray
- Apache MXNet - Python API Gluon
- Apache MXNet - Python API autograd 和初始化器
- Apache MXNet - Python API Symbol
- Apache MXNet - Python API Module
- Apache MXNet 有用资源
- Apache MXNet - 快速指南
- Apache MXNet - 有用资源
- Apache MXNet - 讨论
Apache MXNet - Python API Gluon
正如我们在前面的章节中讨论的那样,MXNet Gluon 为深度学习项目提供了一个清晰、简洁和简单的 API。它使 Apache MXNet 能够在不牺牲训练速度的情况下快速原型设计、构建和训练深度学习模型。
核心模块
让我们学习 Apache MXNet Python 应用编程接口 (API) Gluon 的核心模块。
gluon.nn
Gluon 在 gluon.nn 模块中提供了大量的内置神经网络层。这就是它被称为核心模块的原因。
方法及其参数
以下是mxnet.gluon.nn核心模块涵盖的一些重要方法及其参数:
| 方法及其参数 | 定义 |
|---|---|
| Activation(activation, **kwargs) | 顾名思义,此方法将激活函数应用于输入。 |
| AvgPool1D([pool_size, strides, padding, …]) | 这是针对时间序列数据的平均池化操作。 |
| AvgPool2D([pool_size, strides, padding, …]) | 这是针对空间数据的平均池化操作。 |
| AvgPool3D([pool_size, strides, padding, …]) | 这是针对 3D 数据的平均池化操作。数据可以是空间的或时空的。 |
| BatchNorm([axis, momentum, epsilon, center, …]) | 它表示批量归一化层。 |
| BatchNormReLU([axis, momentum, epsilon, …]) | 它也表示批量归一化层,但具有 ReLU 激活函数。 |
| Block([prefix, params]) | 它提供了所有神经网络层和模型的基类。 |
| Conv1D(channels, kernel_size[, strides, …]) | 此方法用于一维卷积层。例如,时间卷积。 |
| Conv1DTranspose(channels, kernel_size[, …]) | 此方法用于转置一维卷积层。 |
| Conv2D(channels, kernel_size[, strides, …]) | 此方法用于二维卷积层。例如,图像上的空间卷积。 |
| Conv2DTranspose(channels, kernel_size[, …]) | 此方法用于转置二维卷积层。 |
| Conv3D(channels, kernel_size[, strides, …]) | 此方法用于三维卷积层。例如,体积上的空间卷积。 |
| Conv3DTranspose(channels, kernel_size[, …]) | 此方法用于转置三维卷积层。 |
| Dense(units[, activation, use_bias, …]) | 此方法表示常规的全连接神经网络层。 |
| Dropout(rate[, axes]) | 顾名思义,此方法将 Dropout 应用于输入。 |
| ELU([alpha]) | 此方法用于指数线性单元 (ELU)。 |
| Embedding(input_dim, output_dim[, dtype, …]) | 它将非负整数转换为固定大小的密集向量。 |
| Flatten(**kwargs) | 此方法将输入展平为二维。 |
| GELU(**kwargs) | 此方法用于高斯指数线性单元 (GELU)。 |
| GlobalAvgPool1D([layout]) | 借助此方法,我们可以对时间序列数据进行全局平均池化操作。 |
| GlobalAvgPool2D([layout]) | 借助此方法,我们可以对空间数据进行全局平均池化操作。 |
| GlobalAvgPool3D([layout]) | 借助此方法,我们可以对 3D 数据进行全局平均池化操作。 |
| GlobalMaxPool1D([layout]) | 借助此方法,我们可以对一维数据进行全局最大池化操作。 |
| GlobalMaxPool2D([layout]) | 借助此方法,我们可以对二维数据进行全局最大池化操作。 |
| GlobalMaxPool3D([layout]) | 借助此方法,我们可以对三维数据进行全局最大池化操作。 |
| GroupNorm([num_groups, epsilon, center, …]) | 此方法将组归一化应用于 n 维输入数组。 |
| HybridBlock([prefix, params]) | 此方法支持使用Symbol和NDArray进行前向传播。 |
| HybridLambda(function[, prefix]) | 借助此方法,我们可以将运算符或表达式包装为 HybridBlock 对象。 |
| HybridSequential([prefix, params]) | 它按顺序堆叠 HybridBlock。 |
| InstanceNorm([axis, epsilon, center, scale, …]) | 此方法将实例归一化应用于 n 维输入数组。 |
实现示例
在下面的示例中,我们将使用 Block(),它提供了所有神经网络层和模型的基类。
from mxnet.gluon import Block, nn
class Model(Block):
def __init__(self, **kwargs):
super(Model, self).__init__(**kwargs)
# use name_scope to give child Blocks appropriate names.
with self.name_scope():
self.dense0 = nn.Dense(20)
self.dense1 = nn.Dense(20)
def forward(self, x):
x = mx.nd.relu(self.dense0(x))
return mx.nd.relu(self.dense1(x))
model = Model()
model.initialize(ctx=mx.cpu(0))
model(mx.nd.zeros((5, 5), ctx=mx.cpu(0)))
输出
您将看到以下输出:
[[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]] <NDArray 5x20 @cpu(0)*gt;
在下面的示例中,我们将使用 HybridBlock(),它支持使用 Symbol 和 NDArray 进行前向传播。
import mxnet as mx
from mxnet.gluon import HybridBlock, nn
class Model(HybridBlock):
def __init__(self, **kwargs):
super(Model, self).__init__(**kwargs)
# use name_scope to give child Blocks appropriate names.
with self.name_scope():
self.dense0 = nn.Dense(20)
self.dense1 = nn.Dense(20)
def forward(self, x):
x = nd.relu(self.dense0(x))
return nd.relu(self.dense1(x))
model = Model()
model.initialize(ctx=mx.cpu(0))
model.hybridize()
model(mx.nd.zeros((5, 5), ctx=mx.cpu(0)))
输出
输出如下:
[[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]] <NDArray 5x20 @cpu(0)>
gluon.rnn
Gluon 在 gluon.rnn 模块中提供了大量的内置循环神经网络 (RNN) 层。这就是它被称为核心模块的原因。
方法及其参数
以下是mxnet.gluon.nn核心模块涵盖的一些重要方法及其参数:
| 方法及其参数 | 定义 |
|---|---|
| BidirectionalCell(l_cell, r_cell[, …]) | 它用于双向循环神经网络 (RNN) 单元。 |
| DropoutCell(rate[, axes, prefix, params]) | 此方法将对给定的输入应用 dropout。 |
| GRU(hidden_size[, num_layers, layout, …]) | 它将多层门控循环单元 (GRU) RNN 应用于给定的输入序列。 |
| GRUCell(hidden_size[, …]) | 它用于门控整流单元 (GRU) 网络单元。 |
| HybridRecurrentCell([prefix, params]) | 此方法支持混合。 |
| HybridSequentialRNNCell([prefix, params]) | 借助此方法,我们可以顺序堆叠多个 HybridRNN 单元。 |
| LSTM(hidden_size[, num_layers, layout, …])0 | 它将多层长短期记忆 (LSTM) RNN 应用于给定的输入序列。 |
| LSTMCell(hidden_size[, …]) | 它用于长短期记忆 (LSTM) 网络单元。 |
| ModifierCell(base_cell) | 它是修饰符单元的基类。 |
| RNN(hidden_size[, num_layers, activation, …]) | 它将具有tanh或ReLU非线性的多层 Elman RNN 应用于给定的输入序列。 |
| RNNCell(hidden_size[, activation, …]) | 它用于 Elman RNN 循环神经网络单元。 |
| RecurrentCell([prefix, params]) | 它表示 RNN 单元的抽象基类。 |
| SequentialRNNCell([prefix, params]) | 借助此方法,我们可以顺序堆叠多个 RNN 单元。 |
| ZoneoutCell(base_cell[, zoneout_outputs, …]) | 此方法在基单元上应用 Zoneout。 |
实现示例
在下面的示例中,我们将使用 GRU(),它将多层门控循环单元 (GRU) RNN 应用于给定的输入序列。
layer = mx.gluon.rnn.GRU(100, 3) layer.initialize() input_seq = mx.nd.random.uniform(shape=(5, 3, 10)) out_seq = layer(input_seq) h0 = mx.nd.random.uniform(shape=(3, 3, 100)) out_seq, hn = layer(input_seq, h0) out_seq
输出
这将产生以下输出:
[[[ 1.50152072e-01 5.19012511e-01 1.02390535e-01 ... 4.35803324e-01 1.30406499e-01 3.30152437e-02] [ 2.91542172e-01 1.02243155e-01 1.73325196e-01 ... 5.65296151e-02 1.76546033e-02 1.66693389e-01] [ 2.22257316e-01 3.76294643e-01 2.11277917e-01 ... 2.28903517e-01 3.43954474e-01 1.52770668e-01]] [[ 1.40634328e-01 2.93247789e-01 5.50393537e-02 ... 2.30207980e-01 6.61415309e-02 2.70989928e-02] [ 1.11081995e-01 7.20834285e-02 1.08342394e-01 ... 2.28330195e-02 6.79589901e-03 1.25501186e-01] [ 1.15944080e-01 2.41565228e-01 1.18612610e-01 ... 1.14908054e-01 1.61080107e-01 1.15969211e-01]] ………………………….
示例
hn
输出
这将产生以下输出:
[[[-6.08105101e-02 3.86217088e-02 6.64453954e-03 8.18805695e-02 3.85607071e-02 -1.36945639e-02 7.45836645e-03 -5.46515081e-03 9.49622393e-02 6.39371723e-02 -6.37890724e-03 3.82240303e-02 9.11015049e-02 -2.01375950e-02 -7.29381144e-02 6.93765879e-02 2.71829776e-02 -6.64435029e-02 -8.45306814e-02 -1.03075653e-01 6.72040805e-02 -7.06537142e-02 -3.93818803e-02 5.16211614e-03 -4.79770005e-02 1.10734522e-01 1.56721435e-02 -6.93409378e-03 1.16915874e-01 -7.95962065e-02 -3.06530762e-02 8.42394680e-02 7.60370195e-02 2.17055440e-01 9.85361822e-03 1.16660878e-01 4.08297703e-02 1.24978097e-02 8.25245082e-02 2.28673983e-02 -7.88266212e-02 -8.04114193e-02 9.28791538e-02 -5.70827350e-03 -4.46166918e-02 -6.41122833e-02 1.80885363e-02 -2.37745279e-03 4.37298454e-02 1.28888980e-01 -3.07202265e-02 2.50503756e-02 4.00907174e-02 3.37077095e-03 -1.78839862e-02 8.90695080e-02 6.30150884e-02 1.11416787e-01 2.12221760e-02 -1.13236710e-01 5.39616570e-02 7.80710578e-02 -2.28817668e-02 1.92073174e-02 ………………………….
在下面的示例中,我们将使用 LSTM(),它将长短期记忆 (LSTM) RNN 应用于给定的输入序列。
layer = mx.gluon.rnn.LSTM(100, 3) layer.initialize() input_seq = mx.nd.random.uniform(shape=(5, 3, 10)) out_seq = layer(input_seq) h0 = mx.nd.random.uniform(shape=(3, 3, 100)) c0 = mx.nd.random.uniform(shape=(3, 3, 100)) out_seq, hn = layer(input_seq,[h0,c0]) out_seq
输出
输出如下:
[[[ 9.00025964e-02 3.96071747e-02 1.83841765e-01 ... 3.95872220e-02 1.25569820e-01 2.15555862e-01] [ 1.55962542e-01 -3.10300849e-02 1.76772922e-01 ... 1.92474753e-01 2.30574399e-01 2.81707942e-02] [ 7.83204585e-02 6.53361529e-03 1.27262697e-01 ... 9.97719541e-02 1.28254429e-01 7.55299702e-02]] [[ 4.41036932e-02 1.35250352e-02 9.87644792e-02 ... 5.89378644e-03 5.23949116e-02 1.00922674e-01] [ 8.59075040e-02 -1.67027581e-02 9.69351009e-02 ... 1.17763653e-01 9.71239135e-02 2.25218050e-02] [ 4.34580036e-02 7.62207608e-04 6.37005866e-02 ... 6.14888743e-02 5.96345589e-02 4.72368896e-02]] ……………
示例
hn
输出
运行代码时,您将看到以下输出:
[ [[[ 2.21408084e-02 1.42750628e-02 9.53067932e-03 -1.22849066e-02 1.78788435e-02 5.99269159e-02 5.65306023e-02 6.42553642e-02 6.56616641e-03 9.80876666e-03 -1.15729487e-02 5.98640442e-02 -7.21173314e-03 -2.78371759e-02 -1.90690923e-02 2.21447181e-02 8.38765781e-03 -1.38521893e-02 -9.06938594e-03 1.21346042e-02 6.06449470e-02 -3.77471633e-02 5.65885007e-02 6.63008019e-02 -7.34188128e-03 6.46054149e-02 3.19911093e-02 4.11194898e-02 4.43960279e-02 4.92892228e-02 1.74766723e-02 3.40303481e-02 -5.23341820e-03 2.68163737e-02 -9.43402853e-03 -4.11836170e-02 1.55221792e-02 -5.05655073e-02 4.24557598e-03 -3.40388380e-02 ……………………
训练模块
Gluon 中的训练模块如下:
gluon.loss
在mxnet.gluon.loss模块中,Gluon 提供了预定义的损失函数。基本上,它包含用于训练神经网络的损失函数。这就是它被称为训练模块的原因。
方法及其参数
以下是mxnet.gluon.loss训练模块涵盖的一些重要方法及其参数:
| 方法及其参数 | 定义 |
|---|---|
| Loss(weight, batch_axis, **kwargs) | 它充当损失函数的基类。 |
| L2Loss([weight, batch_axis]) | 它计算标签和预测 (pred)之间的均方误差 (MSE)。 |
| L1Loss([weight, batch_axis]) | 它计算标签和pred之间的平均绝对误差 (MAE)。 |
| SigmoidBinaryCrossEntropyLoss([…]) | 此方法用于二元分类的交叉熵损失。 |
| SigmoidBCELoss | 此方法用于二元分类的交叉熵损失。 |
| SoftmaxCrossEntropyLoss([axis, …]) | 它计算 softmax 交叉熵损失 (CEL)。 |
| SoftmaxCELoss | 它也计算 softmax 交叉熵损失。 |
| KLDivLoss([from_logits, axis, weight, …]) | 它用于 Kullback-Leibler 散度损失。 |
| CTCLoss([layout, label_layout, weight]) | 它用于连接时序分类损失 (TCL)。 |
| HuberLoss([rho, weight, batch_axis]) | 它计算平滑的 L1 损失。如果绝对误差超过 rho,则平滑的 L1 损失将等于 L1 损失,否则等于 L2 损失。 |
| HingeLoss([margin, weight, batch_axis]) | 此方法计算通常在 SVM 中使用的铰链损失函数。 |
| SquaredHingeLoss([margin, weight, batch_axis]) | 此方法计算在 SVM 中使用的软边缘损失函数。 |
| LogisticLoss([weight, batch_axis, label_format]) | 此方法计算逻辑损失。 |
| TripletLoss([margin, weight, batch_axis]) | 此方法根据三个输入张量和一个正边距计算三元组损失。 |
| PoissonNLLLoss([weight, from_logits, …]) | 该函数计算负对数似然损失。 |
| CosineEmbeddingLoss([weight, batch_axis, margin]) | 该函数计算向量之间的余弦距离。 |
| SDMLLoss([smoothing_parameter, weight, …]) | 此方法根据两个输入张量和一个平滑权重 SDM 损失计算批处理平滑深度度量学习 (SDML) 损失。它使用小批量中的非配对样本作为潜在的负样本,学习配对样本之间的相似性。 |
示例
众所周知,mxnet.gluon.loss.loss将计算标签和预测 (pred) 之间的 MSE(均方误差)。它是借助以下公式完成的:
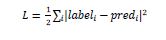
gluon.parameter
mxnet.gluon.parameter是一个容器,它保存 Block 的参数,即权重。
方法及其参数
以下是mxnet.gluon.parameter训练模块涵盖的一些重要方法及其参数:
| 方法及其参数 | 定义 |
|---|---|
| cast(dtype) | 此方法将把此参数的数据和梯度转换为新的数据类型。 |
| data([ctx]) | 此方法将返回此参数在一个上下文上的副本。 |
| grad([ctx]) | 此方法将返回此参数在一个上下文上的梯度缓冲区。 |
| initialize([init, ctx, default_init, …]) | 此方法将初始化参数和梯度数组。 |
| list_ctx() | 此方法将返回此参数已初始化的上下文列表。 |
| list_data() | 此方法将返回此参数在所有上下文上的副本。顺序与创建顺序相同。 |
| list_grad() | 此方法将返回所有上下文上的梯度缓冲区。顺序与values()相同。 |
| list_row_sparse_data(row_id) | 此方法将返回所有上下文上“row_sparse”参数的副本。顺序与创建顺序相同。 |
| reset_ctx(ctx) | 此方法将参数重新分配到其他上下文。 |
| row_sparse_data(row_id) | 此方法将返回与row_id相同上下文上的“row_sparse”参数的副本。 |
| set_data(data) | 此方法将设置此参数在所有上下文上的值。 |
| var() | 此方法将返回表示此参数的符号。 |
| zero_grad() | 此方法将所有上下文上的梯度缓冲区设置为0。 |
实现示例
在下面的示例中,我们将使用initialize()方法初始化参数和梯度数组,如下所示:
weight = mx.gluon.Parameter('weight', shape=(2, 2))
weight.initialize(ctx=mx.cpu(0))
weight.data()
输出
输出如下:
[[-0.0256899 0.06511251] [-0.00243821 -0.00123186]] <NDArray 2x2 @cpu(0)>
示例
weight.grad()
输出
输出如下所示:
[[0. 0.] [0. 0.]] <NDArray 2x2 @cpu(0)>
示例
weight.initialize(ctx=[mx.gpu(0), mx.gpu(1)]) weight.data(mx.gpu(0))
输出
您将看到以下输出:
[[-0.00873779 -0.02834515] [ 0.05484822 -0.06206018]] <NDArray 2x2 @gpu(0)>
示例
weight.data(mx.gpu(1))
输出
执行上述代码后,您应该看到以下输出:
[[-0.00873779 -0.02834515] [ 0.05484822 -0.06206018]] <NDArray 2x2 @gpu(1)>
gluon.trainer
mxnet.gluon.trainer 将优化器应用于一组参数。它应该与autograd一起使用。
方法及其参数
以下是mxnet.gluon.trainer训练模块中涵盖的一些重要方法及其参数:
| 方法及其参数 | 定义 |
|---|---|
| allreduce_grads() | 此方法将减少每个参数(权重)的不同上下文中的梯度。 |
| load_states(fname) | 顾名思义,此方法将加载训练器状态。 |
| save_states(fname) | 顾名思义,此方法将保存训练器状态。 |
| set_learning_rate(lr) | 此方法将设置优化器的新学习率。 |
| step(batch_size[, ignore_stale_grad]) | 此方法将执行一步参数更新。它应该在autograd.backward()之后以及record()作用域之外调用。 |
| update(batch_size[, ignore_stale_grad]) | 此方法也执行一步参数更新。它应该在autograd.backward()之后以及record()作用域之外调用,并且在trainer.update()之后调用。 |
数据模块
Gluon的数据模块解释如下:
gluon.data
Gluon在gluon.data模块中提供了大量内置的数据集实用程序。这就是它被称为数据模块的原因。
类及其参数
以下是mxnet.gluon.data核心模块中涵盖的一些重要方法及其参数。这些方法通常与数据集、采样和DataLoader相关。
| 方法及其参数 | 定义 |
|---|---|
| ArrayDataset(*args) | 此方法表示一个数据集,它组合了两个或多个数据集类对象。例如,数据集、列表、数组等。 |
| BatchSampler(sampler, batch_size[, last_batch]) | 此方法包装另一个Sampler。包装后,它将返回样本的小批量。 |
| DataLoader(dataset[, batch_size, shuffle, …]) | 类似于BatchSampler,但此方法从数据集加载数据。加载后,它将返回数据的小批量。 |
| 这表示抽象数据集类。 | |
| FilterSampler(fn, dataset) | 此方法表示来自数据集的样本元素,对于这些元素,fn(函数)返回True。 |
| RandomSampler(length) | 此方法表示从[0, length)随机采样元素,不放回。 |
| RecordFileDataset(filename) | 它表示一个包装RecordIO文件的数据集。文件的扩展名为.rec。 |
| 采样器 | 这是采样器的基类。 |
| SequentialSampler(length[, start]) | 它表示按顺序从集合[start, start+length)中采样元素。 |
| 它表示按顺序从集合[start, start+length)中采样元素。 | 这表示简单的Dataset包装器,特别是用于列表和数组。 |
实现示例
在下面的示例中,我们将使用gluon.data.BatchSampler() API,它包装另一个采样器。它返回样本的小批量。
import mxnet as mx from mxnet.gluon import data sampler = mx.gluon.data.SequentialSampler(15) batch_sampler = mx.gluon.data.BatchSampler(sampler, 4, 'keep') list(batch_sampler)
输出
输出如下:
[[0, 1, 2, 3], [4, 5, 6, 7], [8, 9, 10, 11], [12, 13, 14]]
gluon.data.vision.datasets
Gluon在gluon.data.vision.datasets模块中提供了大量预定义的视觉数据集函数。
类及其参数
MXNet为我们提供了有用且重要的数据集,其类和参数如下所示:
| 类及其参数 | 定义 |
|---|---|
| MNIST([root, train, transform]) | 这是一个有用的数据集,它为我们提供了手写数字。MNIST数据集的网址是http://yann.lecun.com/exdb/mnist |
| FashionMNIST([root, train, transform]) | 此数据集包含Zalando的商品图像,包含时尚产品。它是原始MNIST数据集的直接替代品。您可以从此处获取此数据集:https://github.com/zalandoresearch/fashion-mnist |
| CIFAR10([root, train, transform]) | 这是一个来自https://www.cs.toronto.edu/~kriz/cifar.html的图像分类数据集。在此数据集中,每个样本都是形状为(32, 32, 3)的图像。 |
| CIFAR100([root, fine_label, train, transform]) | 这是一个来自https://www.cs.toronto.edu/~kriz/cifar.html的CIFAR100图像分类数据集。它也具有每个样本都是形状为(32, 32, 3)的图像。 |
| ImageRecordDataset (filename[, flag, transform]) | 此数据集包装了一个包含图像的RecordIO文件。在此文件中,每个样本都是一个图像及其对应的标签。 |
| ImageFolderDataset (root[, flag, transform]) | 这是一个用于加载存储在文件夹结构中的图像文件的数据集。 |
| ImageListDataset ([root, imglist, flag]) | 这是一个用于加载由条目列表指定的图像文件的数据集。 |
示例
在下面的示例中,我们将展示ImageListDataset()的使用,它用于加载由条目列表指定的图像文件:
# written to text file *.lst 0 0 root/cat/0001.jpg 1 0 root/cat/xxxa.jpg 2 0 root/cat/yyyb.jpg 3 1 root/dog/123.jpg 4 1 root/dog/023.jpg 5 1 root/dog/wwww.jpg # A pure list, each item is a list [imagelabel: float or list of float, imgpath] [[0, root/cat/0001.jpg] [0, root/cat/xxxa.jpg] [0, root/cat/yyyb.jpg] [1, root/dog/123.jpg] [1, root/dog/023.jpg] [1, root/dog/wwww.jpg]]
实用程序模块
Gluon中的实用程序模块如下所示:
gluon.utils
Gluon在gluon.utils模块中提供了大量内置的并行化实用程序优化器。它提供了各种用于训练的实用程序。这就是它被称为实用程序模块的原因。
函数及其参数
以下是此名为gluon.utils的实用程序模块中包含的函数及其参数:
| 函数及其参数 | 定义 |
|---|---|
| split_data(data, num_slice[, batch_axis, …]) | 此函数通常用于数据并行化,每个切片都发送到一个设备,即GPU。它将NDArray沿batch_axis分成num_slice个切片。 |
| split_and_load(data, ctx_list[, batch_axis, …]) | 此函数将NDArray沿batch_axis分成len(ctx_list)个切片。与上面的split_data()函数唯一的区别在于,它还将每个切片加载到ctx_list中的一个上下文中。 |
| clip_global_norm(arrays, max_norm[, …]) | 此函数的作用是以这样一种方式重新缩放NDArrays,即它们的2范数之和小于max_norm。 |
| check_sha1(filename, sha1_hash) | 此函数将检查文件内容的sha1哈希是否与预期哈希匹配。 |
| download(url[, path, overwrite, sha1_hash, …]) | 顾名思义,此函数将下载给定的URL。 |
| replace_file(src, dst) | 此函数将实现原子os.replace。它将在Linux和OSX上完成。 |