- Apache MXNet 教程
- Apache MXNet - 首页
- Apache MXNet - 简介
- Apache MXNet - 安装 MXNet
- Apache MXNet - 工具包和生态系统
- Apache MXNet - 系统架构
- Apache MXNet - 系统组件
- Apache MXNet - 统一算子 API
- Apache MXNet - 分布式训练
- Apache MXNet - Python 包
- Apache MXNet - NDArray
- Apache MXNet - Gluon
- Apache MXNet - KVStore 和可视化
- Apache MXNet - Python API ndarray
- Apache MXNet - Python API gluon
- Apache MXNet - Python API autograd 和初始化器
- Apache MXNet - Python API Symbol
- Apache MXNet - Python API Module
- Apache MXNet 有用资源
- Apache MXNet 快速指南
- Apache MXNet - 有用资源
- Apache MXNet - 讨论
Apache MXNet 快速指南
Apache MXNet - 简介
本章重点介绍 Apache MXNet 的功能,并讨论此深度学习软件框架的最新版本。
什么是 MXNet?
Apache MXNet 是一个强大的开源深度学习软件框架工具,帮助开发人员构建、训练和部署深度学习模型。在过去的几年里,从医疗保健到交通运输再到制造业,事实上,在日常生活的方方面面,深度学习的影响都非常广泛。如今,许多公司都寻求利用深度学习来解决一些难题,例如人脸识别、目标检测、光学字符识别 (OCR)、语音识别和机器翻译。
这就是 Apache MXNet 受以下机构支持的原因:
一些大型公司,例如英特尔、百度、微软、Wolfram Research 等。
公共云提供商,包括亚马逊网络服务 (AWS) 和微软 Azure。
一些大型研究机构,例如卡内基梅隆大学、麻省理工学院、华盛顿大学和香港科技大学。
为什么选择 Apache MXNet?
存在各种深度学习平台,例如 Torch7、Caffe、Theano、TensorFlow、Keras、Microsoft Cognitive Toolkit 等,您可能想知道为什么选择 Apache MXNet?让我们来看看其中的一些原因。
Apache MXNet 解决现有深度学习平台最大的问题之一。问题在于,为了使用深度学习平台,必须学习另一个不同编程风格的系统。
借助 Apache MXNet,开发人员可以充分利用 GPU 和云计算的能力。
Apache MXNet 可以加速任何数值计算,并特别注重加快大型 DNN(深度神经网络)的开发和部署。
它为用户提供了命令式和符号式编程的能力。
各种功能
如果您正在寻找一个灵活的深度学习库来快速开发尖端的深度学习研究或一个强大的平台来推动生产工作负载,那么您的搜索在 Apache MXNet 结束。这是因为它具有以下功能:
分布式训练
无论是多 GPU 还是多主机训练,都具有接近线性的扩展效率,Apache MXNet 允许开发人员充分利用其硬件。MXNet 还支持与 Horovod 集成,Horovod 是 Uber 创建的一个开源分布式深度学习框架。
对于此集成,Horovod 中定义了一些常见的分布式 API:
horovod.broadcast()
horovod.allgather()
horovod.allgather()
在这方面,MXNet 为我们提供了以下功能:
设备放置- 借助 MXNet,我们可以轻松指定每个数据结构 (DS)。
自动微分- Apache MXNet 自动执行微分,即导数计算。
多 GPU 训练- MXNet 允许我们根据可用 GPU 的数量实现扩展效率。
优化的预定义层- 我们可以在 MXNet 中编写自己的层,也可以优化预定义层以提高速度。
混合
Apache MXNet 为其用户提供混合前端。借助 Gluon Python API,它可以弥合其命令式和符号式功能之间的差距。可以通过调用其混合功能来实现。
更快的计算
线性运算(例如数十或数百个矩阵乘法)是深度神经网络的计算瓶颈。为了解决这个瓶颈,MXNet 提供了:
针对 GPU 的优化数值计算
针对分布式生态系统的优化数值计算
借助自动化常用工作流程,可以简要地表达标准神经网络。
语言绑定
MXNet 与 Python 和 R 等高级语言深度集成。它还支持其他编程语言,例如:
Scala
Julia
Clojure
Java
C/C++
Perl
我们不需要学习任何新的编程语言,相反,MXNet 结合混合功能,允许从 Python 到我们选择的编程语言中的部署异常平滑的过渡。
最新版本 MXNet 1.6.0
Apache 软件基金会 (ASF) 于 2020 年 2 月 21 日在 Apache 许可证 2.0 下发布了 Apache MXNet 的稳定版本 1.6.0。这是最后一个支持 Python 2 的 MXNet 版本,因为 MXNet 社区投票决定不再在后续版本中支持 Python 2。让我们来看看此版本为其用户带来的一些新功能。
与 NumPy 兼容的接口
由于其灵活性和通用性,NumPy 已被机器学习从业人员、科学家和学生广泛使用。但众所周知,如今,图形处理单元 (GPU) 等硬件加速器已越来越多地融入各种机器学习 (ML) 工具包中,NumPy 用户为了利用 GPU 的速度,需要切换到具有不同语法的新的框架。
借助 MXNet 1.6.0,Apache MXNet 正在朝着与 NumPy 兼容的编程体验迈进。新的接口为熟悉 NumPy 语法的从业人员提供了等效的可用性和表达能力。同时,MXNet 1.6.0 还使现有的 NumPy 系统能够利用 GPU 等硬件加速器来加快大规模计算。
与 Apache TVM 集成
Apache TVM 是一款面向 CPU、GPU 和专用加速器等硬件后端的开源端到端深度学习编译器堆栈,旨在弥合注重生产力的深度学习框架与注重性能的硬件后端之间的差距。借助最新的 MXNet 1.6.0 版本,用户可以利用 Apache(孵化) TVM 在 Python 编程语言中实现高性能运算符内核。此新功能的两个主要优点如下:
简化了以前的基于 C++ 的开发过程。
能够跨多个硬件后端(例如 CPU、GPU 等)共享相同的实现。
现有功能的改进
除了上述 MXNet 1.6.0 的功能外,它还在现有功能上提供了一些改进。改进如下:
对 GPU 的逐元素运算分组
众所周知,逐元素运算的性能受内存带宽限制,这就是为什么链接此类运算可能会降低整体性能的原因。Apache MXNet 1.6.0 执行逐元素运算融合,这实际上会在可能的情况下生成即时融合运算。这种逐元素运算融合还可以减少存储需求并提高整体性能。
简化常用表达式
MXNet 1.6.0 消除了冗余表达式并简化了常用表达式。这种增强还提高了内存使用率和总执行时间。
优化
MXNet 1.6.0 还为现有功能和运算符提供了各种优化,如下所示:
自动混合精度
Gluon Fit API
MKL-DNN
大型张量支持
TensorRT 集成
高阶梯度支持
运算符
运算符性能分析器
ONNX 导入/导出
Gluon API 的改进
Symbol API 的改进
100 多个错误修复
Apache MXNet - 安装 MXNet
要开始使用 MXNet,我们需要做的第一件事是在我们的计算机上安装它。Apache MXNet 几乎可以在所有可用的平台上运行,包括 Windows、Mac 和 Linux。
Linux 操作系统
我们可以通过以下方式在 Linux 操作系统上安装 MXNet:
图形处理单元 (GPU)
在这里,我们将使用 Pip、Docker 和 Source 等多种方法来安装 MXNet,当我们使用 GPU 进行处理时:
使用 Pip 方法
您可以使用以下命令在您的 Linus 操作系统上安装 MXNet:
pip install mxnet
Apache MXNet 还提供 MKL pip 包,在英特尔硬件上运行时,这些包速度更快。例如,此处mxnet-cu101mkl 表示:
该软件包使用 CUDA/cuDNN 构建
该软件包启用了 MKL-DNN
CUDA 版本为 10.1
对于其他选项,您还可以参考 https://pypi.ac.cn/project/mxnet/。
使用 Docker
您可以在 DockerHub 上找到带有 MXNet 的 Docker 镜像,该镜像位于 https://hub.docker.com/u/mxnet 让我们查看以下步骤,以使用 Docker 和 GPU 安装 MXNet:
步骤 1- 首先,按照位于 https://docs.container.net.cn/engine/install/ubuntu/ 的 Docker 安装说明。我们需要在我们的机器上安装 Docker。
步骤 2- 为了启用从 Docker 容器中使用 GPU,接下来我们需要安装 nvidia-docker-plugin。您可以按照 https://github.com/NVIDIA/nvidia-docker/wiki 中提供的安装说明进行操作。
步骤 3- 使用以下命令,您可以拉取 MXNet Docker 镜像:
$ sudo docker pull mxnet/python:gpu
现在,为了查看 mxnet/python docker 镜像拉取是否成功,我们可以列出 docker 镜像,如下所示:
$ sudo docker images
为了获得 MXNet 最快的推理速度,建议使用带有 Intel MKL-DNN 的最新 MXNet。请检查以下命令:
$ sudo docker pull mxnet/python:1.3.0_cpu_mkl $ sudo docker images
从源代码
要从源代码使用 GPU 构建 MXNet 共享库,首先我们需要设置 CUDA 和 cuDNN 的环境,如下所示:
下载并安装 CUDA 工具包,此处推荐 CUDA 9.2。
接下来下载 cuDNN 7.1.4。
现在我们需要解压缩文件。还需要更改到 cuDNN 根目录。还要将标头和库移动到本地 CUDA 工具包文件夹,如下所示:
tar xvzf cudnn-9.2-linux-x64-v7.1 sudo cp -P cuda/include/cudnn.h /usr/local/cuda/include sudo cp -P cuda/lib64/libcudnn* /usr/local/cuda/lib64 sudo chmod a+r /usr/local/cuda/include/cudnn.h /usr/local/cuda/lib64/libcudnn* sudo ldconfig
设置 CUDA 和 cuDNN 的环境后,请按照以下步骤从源代码构建 MXNet 共享库:
步骤 1- 首先,我们需要安装必要的软件包。这些依赖项在 Ubuntu 16.04 或更高版本上是必需的。
sudo apt-get update sudo apt-get install -y build-essential git ninja-build ccache libopenblas-dev libopencv-dev cmake
步骤 2- 在此步骤中,我们将下载 MXNet 源代码并进行配置。首先,让我们使用以下命令克隆存储库:
git clone –recursive https://github.com/apache/incubator-mxnet.git mxnet cd mxnet cp config/linux_gpu.cmake #for build with CUDA
步骤 3- 使用以下命令,您可以构建 MXNet 核心共享库:
rm -rf build mkdir -p build && cd build cmake -GNinja .. cmake --build .
关于上述步骤,有两点需要注意:
如果要构建 Debug 版本,则指定如下:
cmake -DCMAKE_BUILD_TYPE=Debug -GNinja ..
为了设置并行编译作业的数量,请指定以下内容:
cmake --build . --parallel N
成功构建 MXNet 核心共享库后,在MXNet 项目根目录中的build文件夹中,您将找到安装语言绑定(可选)所需的libmxnet.so。
中央处理器 (CPU)
在这里,我们将使用 Pip、Docker 和 Source 等多种方法来安装 MXNet,当我们使用 CPU 进行处理时:
使用 Pip 方法
您可以使用以下命令在您的 Linus 操作系统上安装 MXNet:
pip install mxnet
Apache MXNet 也提供支持 MKL-DNN 的 pip 包,在英特尔硬件上运行时速度更快。
pip install mxnet-mkl
使用 Docker
您可以在 DockerHub 上找到包含 MXNet 的 Docker 镜像,地址为 https://hub.docker.com/u/mxnet。下面我们来看看使用 Docker 和 CPU 安装 MXNet 的步骤:
步骤 1− 首先,按照 Docker 安装说明(位于 https://docs.container.net.cn/engine/install/ubuntu/)安装 Docker。
步骤 2− 使用以下命令,您可以拉取 MXNet Docker 镜像:
$ sudo docker pull mxnet/python
现在,为了查看 mxnet/python Docker 镜像是否成功拉取,我们可以列出 Docker 镜像,如下所示:
$ sudo docker images
为了获得 MXNet 最快的推理速度,建议使用最新的带有 Intel MKL-DNN 的 MXNet。
查看以下命令:
$ sudo docker pull mxnet/python:1.3.0_cpu_mkl $ sudo docker images
从源代码
要从源代码构建带有 CPU 的 MXNet 共享库,请按照以下步骤操作:
步骤 1- 首先,我们需要安装必要的软件包。这些依赖项在 Ubuntu 16.04 或更高版本上是必需的。
sudo apt-get update sudo apt-get install -y build-essential git ninja-build ccache libopenblas-dev libopencv-dev cmake
步骤 2− 在此步骤中,我们将下载 MXNet 源代码并进行配置。首先,让我们使用以下命令克隆存储库:
git clone –recursive https://github.com/apache/incubator-mxnet.git mxnet cd mxnet cp config/linux.cmake config.cmake
步骤 3− 使用以下命令,您可以构建 MXNet 核心共享库:
rm -rf build mkdir -p build && cd build cmake -GNinja .. cmake --build .
关于上述步骤,有两点需要注意:
如果要构建调试版本,则指定如下:
cmake -DCMAKE_BUILD_TYPE=Debug -GNinja ..
要设置并行编译作业的数量,请指定以下内容:
cmake --build . --parallel N
成功构建 MXNet 核心共享库后,您将在 MXNet 项目根目录下的 build 文件夹中找到 libmxnet.so,这是安装语言绑定(可选)所需的。
macOS
我们可以通过以下方式在 macOS 上安装 MXNet:
图形处理单元 (GPU)
如果您计划在 macOS 上使用 GPU 构建 MXNet,则没有可用的 Pip 和 Docker 方法。在这种情况下,唯一的方法是从源代码构建它。
从源代码
要从源代码构建带有 GPU 的 MXNet 共享库,首先我们需要为 CUDA 和 cuDNN 设置环境。您需要遵循位于 https://docs.nvda.net.cn 的NVIDIA CUDA 安装指南和位于 https://docs.nvda.net.cn/deeplearning 的cuDNN 安装指南(适用于 macOS)。
请注意,2019 年 CUDA 停止支持 macOS。事实上,未来的 CUDA 版本也可能不支持 macOS。
设置好 CUDA 和 cuDNN 的环境后,请按照以下步骤从源代码在 OS X (Mac) 上安装 MXNet:
步骤 1− 由于我们需要 OS X 上的一些依赖项,因此首先需要安装必要的软件包。
xcode-select –-install #Install OS X Developer Tools /usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)" #Install Homebrew brew install cmake ninja ccache opencv # Install dependencies
我们也可以在没有 OpenCV 的情况下构建 MXNet,因为 opencv 是一个可选的依赖项。
步骤 2− 在此步骤中,我们将下载 MXNet 源代码并进行配置。首先,让我们使用以下命令克隆存储库:
git clone –-recursive https://github.com/apache/incubator-mxnet.git mxnet cd mxnet cp config/linux.cmake config.cmake
对于支持 GPU 的版本,有必要先安装 CUDA 依赖项,因为当尝试在没有 GPU 的机器上构建支持 GPU 的版本时,MXNet 构建无法自动检测您的 GPU 架构。在这种情况下,MXNet 将针对所有可用的 GPU 架构。
步骤 3- 使用以下命令,您可以构建 MXNet 核心共享库:
rm -rf build mkdir -p build && cd build cmake -GNinja .. cmake --build .
关于上述步骤,有两点需要注意:
如果要构建 Debug 版本,则指定如下:
cmake -DCMAKE_BUILD_TYPE=Debug -GNinja ..
要设置并行编译作业的数量,请指定以下内容:
cmake --build . --parallel N
成功构建 MXNet 核心共享库后,您将在 MXNet 项目根目录下的 build 文件夹中找到 libmxnet.dylib,这是安装语言绑定(可选)所需的。
中央处理器 (CPU)
这里,我们将使用 Pip、Docker 和源代码三种方法来安装 MXNet(使用 CPU 进行处理):
使用 Pip 方法
您可以使用以下命令在您的 Linus 系统上安装 MXNet:
pip install mxnet
使用 Docker
您可以在 DockerHub 上找到包含 MXNet 的 Docker 镜像,地址为 https://hub.docker.com/u/mxnet。下面我们来看看使用 Docker 和 CPU 安装 MXNet 的步骤:
步骤 1− 首先,按照位于 https://docs.container.net.cn/docker-for-mac 的Docker 安装说明,我们需要在我们的机器上安装 Docker。
步骤 2− 使用以下命令,您可以拉取 MXNet Docker 镜像:
$ docker pull mxnet/python
现在,为了查看 mxnet/python Docker 镜像是否成功拉取,我们可以列出 Docker 镜像,如下所示:
$ docker images
为了获得 MXNet 最快的推理速度,建议使用最新的带有 Intel MKL-DNN 的 MXNet。查看以下命令:
$ docker pull mxnet/python:1.3.0_cpu_mkl $ docker images
从源代码
按照以下步骤从源代码在 OS X (Mac) 上安装 MXNet:
步骤 1− 由于我们需要 OS X 上的一些依赖项,因此首先需要安装必要的软件包。
xcode-select –-install #Install OS X Developer Tools /usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)" #Install Homebrew brew install cmake ninja ccache opencv # Install dependencies
我们也可以在没有 OpenCV 的情况下构建 MXNet,因为 opencv 是一个可选的依赖项。
步骤 2− 在此步骤中,我们将下载 MXNet 源代码并进行配置。首先,让我们使用以下命令克隆存储库:
git clone –-recursive https://github.com/apache/incubator-mxnet.git mxnet cd mxnet cp config/linux.cmake config.cmake
步骤 3− 使用以下命令,您可以构建 MXNet 核心共享库:
rm -rf build mkdir -p build && cd build cmake -GNinja .. cmake --build .
关于上述步骤,有两点需要注意:
如果要构建 Debug 版本,则指定如下:
cmake -DCMAKE_BUILD_TYPE=Debug -GNinja ..
要设置并行编译作业的数量,请指定以下内容:
cmake --build . --parallel N
成功构建 MXNet 核心共享库后,您将在 MXNet 项目根目录下的 build 文件夹中找到 libmxnet.dylib,这是安装语言绑定(可选)所需的。
Windows 系统
要在 Windows 上安装 MXNet,以下是先决条件:
最低系统要求
Windows 7、10、Server 2012 R2 或 Server 2016
Visual Studio 2015 或 2017(任何类型)
Python 2.7 或 3.6
pip
推荐系统要求
Windows 10、Server 2012 R2 或 Server 2016
Visual Studio 2017
至少一个支持 NVIDIA CUDA 的 GPU
支持 MKL 的 CPU:Intel® Xeon® 处理器、Intel® Core™ 处理器系列、Intel Atom® 处理器或 Intel® Xeon Phi™ 处理器
Python 2.7 或 3.6
pip
图形处理单元 (GPU)
使用 Pip 方法:
如果您计划在 Windows 上使用 NVIDIA GPU 构建 MXNet,则可以使用 Python 包安装支持 CUDA 的 MXNet,有两种方法:
安装 CUDA 支持
以下是我们可以使用的方法来设置支持 CUDA 的 MXNet。
步骤 1− 首先安装 Microsoft Visual Studio 2017 或 Microsoft Visual Studio 2015。
步骤 2− 接下来,下载并安装 NVIDIA CUDA。建议使用 CUDA 9.2 或 9.0 版本,因为过去在 CUDA 9.1 中发现了一些问题。
步骤 3− 现在,下载并安装 NVIDIA_CUDA_DNN。
步骤 4− 最后,使用以下 pip 命令安装支持 CUDA 的 MXNet:
pip install mxnet-cu92
安装 CUDA 和 MKL 支持
以下是我们可以使用的方法来设置支持 CUDA 和 MKL 的 MXNet。
步骤 1− 首先安装 Microsoft Visual Studio 2017 或 Microsoft Visual Studio 2015。
步骤 2− 接下来,下载并安装 Intel MKL
步骤 3− 现在,下载并安装 NVIDIA CUDA。
步骤 4− 现在,下载并安装 NVIDIA_CUDA_DNN。
步骤 5− 最后,使用以下 pip 命令安装支持 MKL 的 MXNet:
pip install mxnet-cu92mkl
从源代码
要从源代码构建带有 GPU 的 MXNet 核心库,我们有以下两种方法:
方法 1− 使用 Microsoft Visual Studio 2017 构建
要使用 Microsoft Visual Studio 2017 自行构建和安装 MXNet,您需要以下依赖项。
安装/更新 Microsoft Visual Studio。
如果您的机器上尚未安装 Microsoft Visual Studio,请先下载并安装它。
它会提示安装 Git。也请安装它。
如果您的机器上已经安装了 Microsoft Visual Studio,但您想更新它,则继续执行下一步修改您的安装。在这里,您将有机会更新 Microsoft Visual Studio。
按照位于 https://docs.microsoft.com/en-us 的 Visual Studio 安装程序的说明来修改各个组件。
在 Visual Studio Installer 应用程序中,根据需要进行更新。之后查找并选中 VC++ 2017 version 15.4 v14.11 toolset 并单击 Modify。
现在,使用以下命令将 Microsoft VS2017 的版本更改为 v14.11:
"C:\Program Files (x86)\Microsoft Visual Studio\2017\Community\VC\Auxiliary\Build\vcvars64.bat" -vcvars_ver=14.11
接下来,您需要下载并安装位于 https://cmake.com.cn/download/ 的 CMake。建议使用位于 https://cmake.com.cn/download/ 的 CMake v3.12.2,因为它已通过 MXNet 测试。
现在,下载并运行位于 https://sourceforge.net/projects/opencvlibrary/ 的 OpenCV 包,这将解压多个文件。您可以选择是否将它们放在另一个目录中。在这里,我们将使用路径 C:\utils(mkdir C:\utils) 作为我们的默认路径。
接下来,我们需要设置环境变量 OpenCV_DIR 以指向我们刚刚解压的 OpenCV 构建目录。为此,请打开命令提示符并键入 set OpenCV_DIR=C:\utils\opencv\build。
重要的一点是,如果您没有安装 Intel MKL(数学内核库),则可以安装它。
您可以使用的另一个开源包是 OpenBLAS。以下说明假设您使用的是 OpenBLAS。
因此,下载位于 https://sourceforge.net 的 OpenBlas 包,并解压文件,将其重命名为 OpenBLAS 并将其放在 C:\utils 下。
接下来,我们需要设置环境变量 OpenBLAS_HOME 以指向包含 include 和 lib 目录的 OpenBLAS 目录。为此,请打开命令提示符并键入 set OpenBLAS_HOME=C:\utils\OpenBLAS。
现在,下载并安装位于 https://developer.nvidia.com 的 CUDA。请注意,如果您已经安装了 CUDA,然后安装了 Microsoft VS2017,您现在需要重新安装 CUDA,以便您可以获得用于 Microsoft VS2017 集成的 CUDA 工具包组件。
接下来,您需要下载并安装 cuDNN。
接下来,您还需要下载并安装位于 https://gitforwindows.org/ 的 git。
安装所有必需的依赖项后,请按照以下步骤构建 MXNet 源代码:
步骤 1− 在 Windows 中打开命令提示符。
步骤 2− 现在,使用以下命令从 GitHub 下载 MXNet 源代码:
cd C:\ git clone https://github.com/apache/incubator-mxnet.git --recursive
步骤 3− 接下来,验证以下内容:
DCUDNN_INCLUDE 和 DCUDNN_LIBRARY 环境变量指向 CUDA 安装位置的 include 文件夹和 cudnn.lib 文件。
C:\incubator-mxnet 是您在上一步中刚刚克隆的源代码的位置。
步骤 4− 接下来,使用以下命令创建一个构建目录并转到该目录,例如:
mkdir C:\incubator-mxnet\build cd C:\incubator-mxnet\build
步骤 5− 现在,使用 cmake 编译 MXNet 源代码,如下所示:
cmake -G "Visual Studio 15 2017 Win64" -T cuda=9.2,host=x64 -DUSE_CUDA=1 -DUSE_CUDNN=1 -DUSE_NVRTC=1 -DUSE_OPENCV=1 -DUSE_OPENMP=1 -DUSE_BLAS=open -DUSE_LAPACK=1 -DUSE_DIST_KVSTORE=0 -DCUDA_ARCH_LIST=Common -DCUDA_TOOLSET=9.2 -DCUDNN_INCLUDE=C:\cuda\include -DCUDNN_LIBRARY=C:\cuda\lib\x64\cudnn.lib "C:\incubator-mxnet"
步骤 6− CMake 成功完成之后,使用以下命令编译 MXNet 源代码:
msbuild mxnet.sln /p:Configuration=Release;Platform=x64 /maxcpucount
方法 2:使用 Microsoft Visual Studio 2015 构建
要使用 Microsoft Visual Studio 2015 自行构建和安装 MXNet,您需要以下依赖项。
安装/更新 Microsoft Visual Studio 2015。从源代码构建 MXnet 的最低要求是 Microsoft Visual Studio 2015 的 Update 3。您可以使用 工具 -> 扩展和更新... | 产品更新 菜单进行升级。
接下来,您需要下载并安装CMake,可在https://cmake.com.cn/download/ 获取。建议使用CMake v3.12.2,同样可在https://cmake.com.cn/download/下载,因为它经过MXNet测试。
现在,下载并运行OpenCV软件包,可在https://excellmedia.dl.sourceforge.net获取,这将解压多个文件。您可以选择是否将它们放置在另一个目录中。
接下来,我们需要设置环境变量OpenCV_DIR,使其指向我们刚刚解压的OpenCV构建目录。为此,打开命令提示符并键入set OpenCV_DIR=C:\opencv\build\x64\vc14\bin。
重要的一点是,如果您没有安装 Intel MKL(数学内核库),则可以安装它。
您可以使用的另一个开源包是 OpenBLAS。以下说明假设您使用的是 OpenBLAS。
所以,下载OpenBLAS软件包,可在https://excellmedia.dl.sourceforge.net 获取,并解压文件,将其重命名为OpenBLAS,并将其放在C:\utils下。
接下来,我们需要设置环境变量OpenBLAS_HOME,使其指向包含include和lib目录的OpenBLAS目录。您可以在C:\Program files (x86)\OpenBLAS\找到该目录。
请注意,如果您已经安装了CUDA,然后安装了Microsoft VS2015,则现在需要重新安装CUDA,以便您可以获得用于Microsoft VS2017集成的CUDA工具包组件。
接下来,您需要下载并安装 cuDNN。
现在,我们需要设置环境变量CUDACXX,使其指向CUDA编译器(例如:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.1\bin\nvcc.exe)。
类似地,我们还需要设置环境变量CUDNN_ROOT,使其指向包含include、lib和bin目录的cuDNN目录(例如:C:\Downloads\cudnn-9.1-windows7-x64-v7\cuda)。
安装所有必需的依赖项后,请按照以下步骤构建 MXNet 源代码:
步骤1 - 首先,从GitHub下载MXNet源代码 -
cd C:\ git clone https://github.com/apache/incubator-mxnet.git --recursive
步骤2 - 接下来,使用CMake在./build中创建一个Visual Studio项目。
步骤3 - 现在,在Visual Studio中,我们需要打开解决方案文件.sln并编译它。这些命令将在./build/Release/或./build/Debug文件夹中生成一个名为mxnet.dll的库。
步骤4 - CMake成功完成之后,使用以下命令编译MXNet源代码。
msbuild mxnet.sln /p:Configuration=Release;Platform=x64 /maxcpucount
中央处理器 (CPU)
这里,我们将使用 Pip、Docker 和源代码三种方法来安装 MXNet(使用 CPU 进行处理):
使用 Pip 方法
如果您计划在Windows上使用CPU构建MXNet,则可以使用Python包安装MXNet,方法有两种 -
使用CPU安装
使用以下命令使用Python安装使用CPU的MXNet -
pip install mxnet
使用Intel CPU安装
如上所述,MXNet也实验性地支持Intel MKL和MKL-DNN。使用以下命令使用Python安装使用Intel CPU的MXNet -
pip install mxnet-mkl
使用 Docker
您可以在DockerHub找到带有MXNet的Docker镜像,网址为https://hub.docker.com/u/mxnet。让我们看看以下步骤,使用Docker安装使用CPU的MXNet -
步骤1 - 首先,按照Docker安装说明进行操作,可在https://docs.container.net.cn/docker-for-mac/install查看。我们需要在我们的机器上安装Docker。
步骤 2− 使用以下命令,您可以拉取 MXNet Docker 镜像:
$ docker pull mxnet/python
现在,为了查看 mxnet/python Docker 镜像是否成功拉取,我们可以列出 Docker 镜像,如下所示:
$ docker images
为了获得 MXNet 最快的推理速度,建议使用最新的带有 Intel MKL-DNN 的 MXNet。
查看以下命令 -
$ docker pull mxnet/python:1.3.0_cpu_mkl $ docker images
在云端和设备上安装MXNet
本节重点介绍如何在云端和设备上安装Apache MXNet。让我们首先学习如何在云端安装MXNet。
在云端安装MXNet
您还可以在多个云提供商处获得支持图形处理单元(GPU)的Apache MXNet。您可以找到的其他两种支持如下: -
- GPU/CPU混合支持,用于可扩展推理等用例。
- 使用AWS Elastic Inference进行阶乘GPU支持。
以下是提供具有不同Apache MXNet虚拟机的GPU支持的云提供商:
阿里巴巴控制台
您可以使用阿里巴巴控制台创建可在https://docs.nvda.net.cn/ngc获取的NVIDIA GPU云虚拟机(VM)并使用Apache MXNet。
亚马逊网络服务
它还提供GPU支持,并为Apache MXNet提供以下服务:
Amazon SageMaker
它管理Apache MXNet模型的训练和部署。
AWS深度学习AMI
它为Python 2和Python 3提供了预安装的Conda环境,其中包含Apache MXNet、CUDA、cuDNN、MKL-DNN和AWS Elastic Inference。
在AWS上进行动态训练
它提供针对实验性手动EC2设置以及半自动CloudFormation设置的培训。
您可以使用可在https://aws.amazon.com获取的NVIDIA VM和亚马逊网络服务。
谷歌云平台
谷歌还提供可在https://console.cloud.google.com获取的NVIDIA GPU云镜像,可用于Apache MXNet。
微软Azure
Microsoft Azure Marketplace还提供可在https://azuremarketplace.microsoft.com获取的NVIDIA GPU云镜像,可用于Apache MXNet。
甲骨文云
甲骨文还提供可在https://docs.cloud.oracle.com获取的NVIDIA GPU云镜像,可用于Apache MXNet。
中央处理器 (CPU)
Apache MXNet可在每个云提供商的仅CPU实例上运行。安装方法多种多样,例如:
Python pip安装说明。
Docker说明。
预安装选项,例如亚马逊网络服务提供的AWS深度学习AMI(为Python 2和Python 3预安装了Conda环境,其中包含MXNet和MKL-DNN)。
在设备上安装MXNet
让我们学习如何在设备上安装MXNet。
树莓派
您还可以在树莓派3B设备上运行Apache MXNet,因为MXNet也支持基于Respbian ARM的操作系统。为了在树莓派3上顺利运行MXNet,建议使用内存超过1GB的设备和至少有4GB可用空间的SD卡。
以下方法可以帮助您为树莓派构建MXNet并安装库的Python绑定:
快速安装
预构建的Python wheel可以在带有Stretch的树莓派3B上用于快速安装。此方法的一个重要问题是,我们需要安装多个依赖项才能使Apache MXNet正常工作。
Docker安装
您可以按照Docker安装说明进行操作,可在https://docs.container.net.cn/engine/install/ubuntu/查看,以在您的机器上安装Docker。为此,我们也可以安装和使用社区版(CE)。
原生构建(从源代码)
为了从源代码安装MXNet,我们需要遵循以下两个步骤:
步骤1
从Apache MXNet C++源代码构建共享库
要在树莓派Wheezy及更高版本上构建共享库,我们需要以下依赖项:
Git - 从GitHub提取代码需要它。
Libblas - 线性代数运算需要它。
Libopencv - 计算机视觉相关操作需要它。但是,如果您想节省RAM和磁盘空间,它是可选的。
C++编译器 - 编译和构建MXNet源代码需要它。以下是支持C++ 11的受支持编译器:
G++(4.8或更高版本)
Clang(3.9-6)
使用以下命令安装上述依赖项:
sudo apt-get update sudo apt-get -y install git cmake ninja-build build-essential g++-4.9 c++-4.9 liblapack* libblas* libopencv* libopenblas* python3-dev python-dev virtualenv
接下来,我们需要克隆MXNet源代码存储库。为此,请在您的主目录中使用以下git命令:
git clone https://github.com/apache/incubator-mxnet.git --recursive cd incubator-mxnet
现在,借助以下命令,构建共享库:
mkdir -p build && cd build cmake \ -DUSE_SSE=OFF \ -DUSE_CUDA=OFF \ -DUSE_OPENCV=ON \ -DUSE_OPENMP=ON \ -DUSE_MKL_IF_AVAILABLE=OFF \ -DUSE_SIGNAL_HANDLER=ON \ -DCMAKE_BUILD_TYPE=Release \ -GNinja .. ninja -j$(nproc)
执行上述命令后,它将启动构建过程,该过程需要几个小时才能完成。您将在build目录中获得一个名为libmxnet.so的文件。
步骤2
安装Apache MXNet支持的特定语言包
在此步骤中,我们将安装MXNet Pythin绑定。为此,我们需要在MXNet目录中运行以下命令:
cd python pip install --upgrade pip pip install -e .
或者,使用以下命令,您还可以创建一个可以使用pip安装的whl包:
ci/docker/runtime_functions.sh build_wheel python/ $(realpath build)
NVIDIA Jetson设备
您还可以在NVIDIA Jetson设备(例如TX2或Nano)上运行Apache MXNet,因为MXNet也支持基于Ubuntu Arch64的操作系统。为了在NVIDIA Jetson设备上顺利运行MXNet,必须在您的Jetson设备上安装CUDA。
以下方法可以帮助您为NVIDIA Jetson设备构建MXNet:
使用Jetson MXNet pip wheel进行Python开发
从源代码
但是,在通过上述任何方法构建MXNet之前,您需要在Jetson设备上安装以下依赖项:
Python依赖项
为了使用Python API,我们需要以下依赖项:
sudo apt update sudo apt -y install \ build-essential \ git \ graphviz \ libatlas-base-dev \ libopencv-dev \ python-pip sudo pip install --upgrade \ pip \ setuptools sudo pip install \ graphviz==0.8.4 \ jupyter \ numpy==1.15.2
克隆MXNet源代码存储库
在您的主目录中使用以下git命令克隆MXNet源代码存储库:
git clone --recursive https://github.com/apache/incubator-mxnet.git mxnet
设置环境变量
将以下内容添加到您主目录中的.profile文件中:
export PATH=/usr/local/cuda/bin:$PATH export MXNET_HOME=$HOME/mxnet/ export PYTHONPATH=$MXNET_HOME/python:$PYTHONPATH
现在,使用以下命令立即应用更改:
source .profile
配置CUDA
在使用nvcc配置CUDA之前,您需要检查正在运行的CUDA版本:
nvcc --version
假设,如果您的设备或计算机上安装了多个CUDA版本,并且您想切换CUDA版本,则使用以下命令并将符号链接替换为您想要的版本:
sudo rm /usr/local/cuda sudo ln -s /usr/local/cuda-10.0 /usr/local/cuda
上述命令将切换到CUDA 10.0,该版本预安装在NVIDIA Jetson设备Nano上。
完成上述先决条件后,您现在可以在NVIDIA Jetson设备上安装MXNet。因此,让我们了解可以使用哪些方法安装MXNet:
使用Jetson MXNet pip wheel进行Python开发 - 如果您想使用准备好的Python wheel,则将其下载到您的Jetson并运行它:
MXNet 1.4.0(适用于Python 3),可在https://docs.container.net.cn获取
MXNet 1.4.0(适用于Python 2),可在https://docs.container.net.cn获取
原生构建(从源代码)
为了从源代码安装MXNet,我们需要遵循以下两个步骤:
步骤1
从Apache MXNet C++源代码构建共享库
要从Apache MXNet C++源代码构建共享库,您可以使用Docker方法或手动进行:
Docker方法
此方法首先需要安装Docker并能够在无需sudo的情况下运行(之前的步骤中也有说明)。完成后,运行以下命令通过Docker进行交叉编译:
$MXNET_HOME/ci/build.py -p jetson
手动方法
此方法需要编辑Makefile(使用以下命令)以安装具有CUDA绑定的MXNet,从而利用NVIDIA Jetson设备上的图形处理单元(GPU)
cp $MXNET_HOME/make/crosscompile.jetson.mk config.mk
编辑Makefile后,需要编辑config.mk文件以对NVIDIA Jetson设备进行一些额外更改。
为此,请更新以下设置:
更新CUDA路径:USE_CUDA_PATH = /usr/local/cuda
将 -gencode arch=compute-63, code=sm_62 添加到CUDA_ARCH设置中。
更新NVCC设置:NVCCFLAGS := -m64
启用OpenCV:USE_OPENCV = 1
现在,为了确保MXNet使用Pascal的硬件级低精度加速进行构建,我们需要如下编辑Mshadow Makefile:
MSHADOW_CFLAGS += -DMSHADOW_USE_PASCAL=1
最后,您可以使用以下命令构建完整的Apache MXNet库:
cd $MXNET_HOME make -j $(nproc)
执行上述命令后,将开始构建过程,该过程需要几个小时才能完成。您将在mxnet/lib目录中获得名为libmxnet.so的文件。
步骤2
安装Apache MXNet Python绑定
在此步骤中,我们将安装MXNet Python绑定。为此,我们需要在MXNet目录中运行以下命令:
cd $MXNET_HOME/python sudo pip install -e .
完成上述步骤后,您现在就可以在NVIDIA Jetson TX2或Nano设备上运行MXNet了。可以使用以下命令进行验证:
import mxnet mxnet.__version__
如果一切正常,它将返回版本号。
Apache MXNet - 工具包和生态系统
为了支持在许多领域进行深度学习应用程序的研究和开发,Apache MXNet为我们提供了丰富的工具包、库等等。让我们来探索一下:
工具包
以下是MXNet提供的一些最常用和最重要的工具包:
GluonCV
顾名思义,GluonCV是一个由MXNet支持的用于计算机视觉的Gluon工具包。它提供了计算机视觉 (CV) 领域最先进的深度学习 (DL) 算法的实现。借助GluonCV工具包,工程师、研究人员和学生可以轻松验证新想法和学习CV。
以下是GluonCV的一些特性:
它提供了用于重现最新研究报告中最新成果的训练脚本。
170多个高质量的预训练模型。
采用灵活的开发模式。
GluonCV易于优化。我们可以部署它而无需保留重量级的深度学习框架。
它提供了精心设计的API,大大降低了实现的复杂性。
社区支持。
易于理解的实现。
以下是GluonCV工具包支持的应用程序
图像分类
目标检测
语义分割
实例分割
姿态估计
视频动作识别
我们可以使用pip如下安装GluonCV:
pip install --upgrade mxnet gluoncv
GluonNLP
顾名思义,GluonNLP是由MXNet支持的用于自然语言处理 (NLP) 的Gluon工具包。它提供了NLP领域最先进的深度学习(DL) 模型的实现。
借助GluonNLP工具包,工程师、研究人员和学生可以构建文本数据管道和模型的模块。基于这些模型,他们可以快速原型化研究想法和产品。
以下是GluonNLP的一些特性
它提供了用于重现最新研究报告中最新成果的训练脚本。
一组用于常见NLP任务的预训练模型。
它提供了精心设计的API,大大降低了实现的复杂性。
社区支持。
它还提供教程来帮助您开始新的NLP任务。
以下是我们可以使用GluonNLP工具包实现的NLP任务:
词嵌入
语言模型
机器翻译
文本分类
情感分析
自然语言推理
文本生成
依存句法分析
命名实体识别
意图分类和槽位标注
我们可以使用pip如下安装GluonNLP:
pip install --upgrade mxnet gluonnlp
GluonTS
顾名思义,GluonTS是由MXNet支持的用于概率时间序列建模的Gluon工具包。
它提供以下功能:
随时可以训练的最先进 (SOTA) 深度学习模型。
用于加载和迭代时间序列数据集的实用程序。
构建块以定义您自己的模型。
借助GluonTS工具包,工程师、研究人员和学生可以在他们自己的数据上训练和评估任何内置模型,快速试验不同的解决方案,并为他们的时间序列任务提出解决方案。
他们还可以使用提供的抽象和构建块来创建自定义时间序列模型,并将其快速与基线算法进行基准测试。
我们可以使用pip如下安装GluonTS:
pip install gluonts
GluonFR
顾名思义,这是一个用于人脸识别 (FR) 的Apache MXNet Gluon工具包。它提供以下功能:
人脸识别领域最先进 (SOTA) 的深度学习模型。
SoftmaxCrossEntropyLoss、ArcLoss、TripletLoss、RingLoss、CosLoss/AMsoftmax、L2-Softmax、A-Softmax、CenterLoss、ContrastiveLoss和LGM Loss等的实现。
为了安装Gluon Face,我们需要Python 3.5或更高版本。我们还需要首先安装GluonCV和MXNet,如下所示:
pip install gluoncv --pre pip install mxnet-mkl --pre --upgrade pip install mxnet-cuXXmkl --pre –upgrade # if cuda XX is installed
安装完依赖项后,可以使用以下命令安装GluonFR:
从源代码安装
pip install git+https://github.com/THUFutureLab/gluon-face.git@master
Pip安装
pip install gluonfr
生态系统
现在让我们来探索MXNet丰富的库、包和框架:
Coach RL
Coach是由英特尔人工智能实验室创建的Python强化学习 (RL) 框架。它使使用最先进的RL算法进行轻松实验成为可能。Coach RL支持Apache MXNet作为后端,并允许简单地集成新环境来解决问题。
为了轻松扩展和重用现有组件,Coach RL很好地解耦了基本强化学习组件,例如算法、环境、神经网络架构、探索策略。
以下是Coach RL框架的代理和支持的算法:
价值优化代理
深度Q网络 (DQN)
双深度Q网络 (DDQN)
双Q网络
混合蒙特卡洛 (MMC)
持久优势学习 (PAL)
分类深度Q网络 (C51)
分位数回归深度Q网络 (QR-DQN)
N步Q学习
神经情景控制 (NEC)
归一化优势函数 (NAF)
彩虹
策略优化代理
策略梯度 (PG)
异步优势行动者评论家 (A3C)
深度确定性策略梯度 (DDPG)
近端策略优化 (PPO)
裁剪近端策略优化 (CPPO)
广义优势估计 (GAE)
具有经验回放的样本高效行动者评论家 (ACER)
软行动者评论家 (SAC)
双延迟深度确定性策略梯度 (TD3)
通用代理
直接未来预测 (DFP)
模仿学习代理
行为克隆 (BC)
条件模仿学习
分层强化学习代理
分层行动者评论家 (HAC)
深度图库
深度图库 (DGL) 由纽约大学和 AWS 上海团队开发,是一个 Python 包,它在 MXNet 之上提供了图神经网络 (GNN) 的简易实现。它还在其他现有的主要深度学习库(如 PyTorch、Gluon 等)之上提供了 GNN 的简易实现。
深度图库是免费软件。它可在 Ubuntu 16.04 或更高版本的所有 Linux 发行版、macOS X 和 Windows 7 或更高版本上使用。它还需要 Python 3.5 版本或更高版本。
以下是 DGL 的功能:
无需迁移成本 - 使用 DGL 不会产生迁移成本,因为它构建在流行的现有深度学习框架之上。
消息传递 - DGL 提供消息传递,并且对其具有多功能的控制。消息传递范围从低级操作(例如沿选定边发送)到高级控制(例如图范围内的特征更新)。
平滑的学习曲线 - DGL 易于学习和使用,因为强大的用户定义函数灵活且易于使用。
透明的速度优化 - DGL 通过自动批量计算和稀疏矩阵乘法来提供透明的速度优化。
高性能 - 为了实现最大效率,DGL 会自动批量处理在一个或多个图上一起进行的深度神经网络 (DNN) 训练。
简单友好的界面 - DGL 为我们提供了简单友好的界面,用于访问边缘特征以及操作图结构。
InsightFace
InsightFace,一个用于人脸分析的深度学习工具包,它提供了由 MXNet 支持的计算机视觉中最先进 (SOTA) 人脸分析算法的实现。它提供:
高质量的大型预训练模型集。
最先进 (SOTA) 的训练脚本。
InsightFace易于优化。我们可以部署它而无需保留重量级的深度学习框架。
它提供了精心设计的API,大大降低了实现的复杂性。
构建块以定义您自己的模型。
我们可以使用pip如下安装InsightFace:
pip install --upgrade insightface
请注意,在安装InsightFace之前,请根据您的系统配置安装正确的MXNet包。
Keras-MXNet
众所周知,Keras是用Python编写的用于高级神经网络 (NN) 的API,Keras-MXNet为Keras提供了后端支持。它可以在高性能和可扩展的Apache MXNet深度学习框架之上运行。
Keras-MXNet的功能如下:
允许用户轻松、流畅、快速地进行原型设计。这一切都通过用户友好性、模块化和可扩展性来实现。
支持卷积神经网络 (CNN) 和循环神经网络 (RNN),以及两者的组合。
在中央处理器 (CPU) 和图形处理单元 (GPU) 上都能完美运行。
可以在一个或多个GPU上运行。
为了使用此后端,您首先需要安装keras-mxnet,如下所示:
pip install keras-mxnet
现在,如果您使用的是GPU,则安装支持CUDA 9的MXNet,如下所示:
pip install mxnet-cu90
但是,如果您只使用CPU,则安装基本MXNet,如下所示:
pip install mxnet
MXBoard
MXBoard是用Python编写的日志记录工具,用于记录MXNet数据帧并在TensorBoard中显示。换句话说,MXBoard旨在遵循tensorboard-pytorch API。它支持TensorBoard中的大多数数据类型。
其中一些如下所示:
图
标量
直方图
嵌入
图像
文本
音频
精确率-召回率曲线
MXFusion
MXFusion是一个具有深度学习功能的模块化概率编程库。MXFusion允许我们充分利用模块化(深度学习库的关键特征)进行概率编程。它易于使用,并为用户提供了一个方便的界面来设计概率模型并将其应用于现实世界的问题。
MXFusion 已在 macOS 和 Linux 系统的 Python 3.4 及更高版本上验证。要安装 MXFusion,首先需要安装以下依赖项:
MXNet >= 1.3
Networkx >= 2.1
可以使用以下 pip 命令安装 MXFusion:
pip install mxfusion
TVM
Apache TVM 是一个开源的端到端深度学习编译器栈,支持 CPU、GPU 和专用加速器等硬件后端,旨在弥合注重生产力的深度学习框架和注重性能的硬件后端之间的差距。借助最新的 MXNet 1.6.0 版本,用户可以使用 Apache(孵化中) TVM 以 Python 编程语言实现高性能算子内核。
Apache TVM 最初是华盛顿大学 Paul G. Allen 计算机科学与工程学院 SAMPL 组的一个研究项目,现在它是在 Apache 软件基金会 (ASF) 孵化中的一个项目,由一个包含多个行业和学术机构的开源社区 (OSC) 在 Apache 方式下驱动。
以下是 Apache(孵化中) TVM 的主要功能:
简化了以前的基于 C++ 的开发过程。
支持在多个硬件后端(例如 CPU、GPU 等)上共享相同的实现。
TVM 提供了将各种框架(如 Keras、MXNet、PyTorch、TensorFlow、CoreML、DarkNet)中的深度学习模型编译成可在不同硬件后端上部署的最小模块。
它还提供基础架构来自动生成和优化张量算子,以获得更好的性能。
XFer
Xfer 是一个用 Python 编写的迁移学习框架。它主要接收一个 MXNet 模型,并训练一个元模型或修改该模型以适应新的目标数据集。
简单来说,Xfer 是一个 Python 库,允许用户快速轻松地迁移存储在深度神经网络 (DNN) 中的知识。
Xfer 可用于:
对任意数值格式的数据进行分类。
处理常见的图像或文本数据。
作为一个从特征提取到训练重新利用器(一个在目标任务中执行分类的对象)的管道。
以下是 Xfer 的功能:
资源效率
数据效率
轻松访问神经网络
不确定性建模
快速原型设计
用于从神经网络提取特征的实用程序
Apache MXNet - 系统架构
本章将帮助您了解 MXNet 系统架构。让我们从学习 MXNet 模块开始。
MXNet 模块
下图是 MXNet 系统架构,它显示了 **MXNet 模块及其交互**的主要模块和组件。
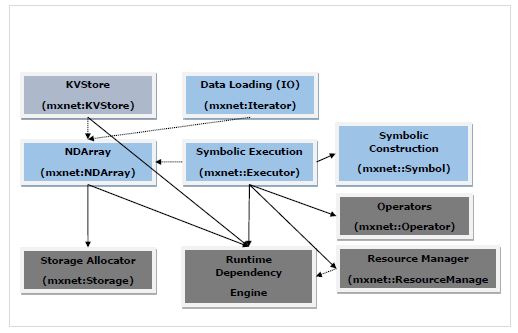
在上图中:
蓝色框中的模块是 **面向用户的模块**。
绿色框中的模块是 **系统模块**。
实线箭头表示高度依赖,即严重依赖接口。
虚线箭头表示轻度依赖,即为了方便和接口一致性而使用的数据结构。实际上,它可以用替代方案替换。
让我们更详细地讨论面向用户和系统模块。
面向用户的模块
面向用户的模块如下:
**NDArray** - 它为 Apache MXNet 提供灵活的命令式程序。它们是动态的异步 n 维数组。
**KVStore** - 它充当高效参数同步的接口。在 KVStore 中,KV 代表键值。所以,它是一个键值存储接口。
**数据加载 (IO)** - 此面向用户的模块用于高效的分布式数据加载和增强。
**符号执行** - 它是一个静态符号图执行器。它提供高效的符号图执行和优化。
**符号构建** - 此面向用户的模块为用户提供了一种构建计算图(即网络配置)的方法。
系统模块
系统模块如下:
**存储分配器** - 此系统模块顾名思义,在主机(即 CPU)和不同设备(即 GPU)上高效地分配和回收内存块。
**运行时依赖引擎** - 运行时依赖引擎模块根据其读/写依赖关系调度和执行操作。
**资源管理器** - 资源管理器 (RM) 系统模块管理全局资源,如随机数生成器和时间空间。
**算子** - 算子系统模块包含所有定义静态前向和梯度计算(即反向传播)的算子。
Apache MXNet - 系统组件
这里详细解释了 Apache MXNet 中的系统组件。首先,我们将研究 MXNet 中的执行引擎。
执行引擎
Apache MXNet 的执行引擎非常通用。我们可以将其用于深度学习以及任何特定领域的难题:按照其依赖关系执行一系列函数。它的设计方式是,具有依赖关系的函数被串行化,而没有依赖关系的函数可以并行执行。
核心接口
以下 API 是 Apache MXNet 执行引擎的核心接口:
virtual void PushSync(Fn exec_fun, Context exec_ctx, std::vector<VarHandle> const& const_vars, std::vector<VarHandle> const& mutate_vars) = 0;
上述 API 包含以下内容:
**exec_fun** - MXNet 的核心接口 API 允许我们将名为 exec_fun 的函数及其上下文信息和依赖关系推送到执行引擎。
**exec_ctx** - 上述函数 exec_fun 应在其执行的上下文信息。
**const_vars** - 这些是函数从中读取的变量。
**mutate_vars** - 这些是要修改的变量。
执行引擎向用户保证,任何两个修改公共变量的函数的执行都按其推送顺序串行化。
函数
以下是 Apache MXNet 执行引擎的函数类型:
using Fn = std::function<void(RunContext)>;
在上例函数中,**RunContext** 包含运行时信息。运行时信息应由执行引擎确定。**RunContext** 的语法如下:
struct RunContext {
// stream pointer which could be safely cast to
// cudaStream_t* type
void *stream;
};
以下是关于执行引擎函数的一些要点:
所有函数均由 MXNet 执行引擎的内部线程执行。
将阻塞函数推送到执行引擎不是一个好主意,因为这样函数将占用执行线程,并降低总吞吐量。
为此,MXNet 提供了另一个异步函数,如下所示:
using Callback = std::function<void()>; using AsyncFn = std::function<void(RunContext, Callback)>;
在这个 **AsyncFn** 函数中,我们可以传递线程的繁重部分,但是直到我们调用 **callback** 函数,执行引擎才认为该函数已完成。
上下文
在 **Context** 中,我们可以指定要在其中执行函数的上下文。这通常包括以下内容:
函数是否应在 CPU 或 GPU 上运行。
如果我们在 Context 中指定 GPU,则使用哪个 GPU。
Context 和 RunContext 之间存在巨大差异。Context 具有设备类型和设备 ID,而 RunContext 具有仅在运行时才能确定的信息。
VarHandle
VarHandle 用于指定函数的依赖关系,就像一个令牌(特别是执行引擎提供的令牌),我们可以用它来表示函数可以修改或使用的外部资源。
但是问题出现了,为什么我们需要使用 VarHandle?这是因为 Apache MXNet 引擎的设计与其他 MXNet 模块解耦。
以下是关于 VarHandle 的一些要点:
它很轻量级,因此创建、删除或复制变量几乎不会产生操作成本。
我们需要指定不可变变量,即将在 **const_vars** 中使用的变量。
我们需要指定可变变量,即将在 **mutate_vars** 中修改的变量。
执行引擎用于解决函数之间依赖关系的规则是,当其中一个函数修改至少一个公共变量时,任何两个函数的执行都按其推送顺序串行化。
要创建一个新变量,我们可以使用 **NewVar()** API。
要删除一个变量,我们可以使用 **PushDelete** API。
让我们用一个简单的例子来理解它的工作原理:
假设我们有两个函数 F1 和 F2,它们都修改变量 V2。在这种情况下,如果 F2 在 F1 之后推送,则保证 F2 在 F1 之后执行。另一方面,如果 F1 和 F2 都使用 V2,那么它们的实际执行顺序可能是随机的。
Push 和 Wait
**Push** 和 **wait** 是执行引擎的另外两个有用的 API。
以下是 **Push** API 的两个重要特性:
所有 Push API 都是异步的,这意味着 API 调用立即返回,无论推送的函数是否已完成。
Push API 不是线程安全的,这意味着一次只有一个线程应该进行引擎 API 调用。
现在,如果我们谈论 Wait API,以下几点表示它:
如果用户想要等待特定函数完成,则应在闭包中包含一个回调函数。包含后,在函数结束时调用该函数。
另一方面,如果用户想要等待涉及某个特定变量的所有函数完成,则应使用 **WaitForVar(var)** API。
如果有人想等待所有推送的函数完成,则使用 **WaitForAll ()** API。
用于指定函数的依赖关系,就像一个令牌。
运算符
Apache MXNet 中的算子是一个包含实际计算逻辑以及辅助信息并帮助系统执行优化的类。
算子接口
**Forward** 是核心算子接口,其语法如下:
virtual void Forward(const OpContext &ctx, const std::vector<TBlob> &in_data, const std::vector<OpReqType> &req, const std::vector<TBlob> &out_data, const std::vector<TBlob> &aux_states) = 0;
在 **Forward()** 中定义的 **OpContext** 的结构如下:
struct OpContext {
int is_train;
RunContext run_ctx;
std::vector<Resource> requested;
}
**OpContext** 描述算子的状态(是否处于训练或测试阶段),算子应在其运行的设备以及请求的资源。执行引擎的另外两个有用的 API。
从上面的 **Forward** 核心接口,我们可以理解请求的资源如下:
**in_data** 和 **out_data** 分别表示输入和输出张量。
**req** 表示计算结果如何写入 **out_data**。
**OpReqType** 可以定义为:
enum OpReqType {
kNullOp,
kWriteTo,
kWriteInplace,
kAddTo
};
与 **Forward** 算子类似,我们可以选择实现 **Backward** 接口,如下所示:
virtual void Backward(const OpContext &ctx, const std::vector<TBlob> &out_grad, const std::vector<TBlob> &in_data, const std::vector<TBlob> &out_data, const std::vector<OpReqType> &req, const std::vector<TBlob> &in_grad, const std::vector<TBlob> &aux_states);
各种任务
**算子** 接口允许用户执行以下任务:
用户可以指定就地更新,并降低内存分配成本。
为了使其更清晰,用户可以隐藏 Python 中的一些内部参数。
用户可以定义张量和输出张量之间的关系。
为了执行计算,用户可以从系统获取额外的临时空间。
算子属性 (Operator Property)
众所周知,在卷积神经网络 (CNN) 中,一次卷积有多种实现方式。为了获得最佳性能,我们可能需要在这几种卷积之间切换。
因此,Apache MXNet 将算子的语义接口与实现接口分开。这种分离是通过**OperatorProperty**类实现的,它包含以下内容:
**InferShape** - InferShape 接口有两个用途,如下所示:
第一个用途是告诉系统每个输入和输出张量的尺寸,以便在**Forward**和**Backward**调用之前分配空间。
第二个用途是在运行之前执行大小检查,以确保没有错误。
语法如下:
virtual bool InferShape(mxnet::ShapeVector *in_shape, mxnet::ShapeVector *out_shape, mxnet::ShapeVector *aux_shape) const = 0;
**Request Resource** - 如果您的系统可以管理诸如 cudnnConvolutionForward 之类的操作的计算工作区呢?您的系统可以执行诸如重用空间等优化。在这里,MXNet 可以借助以下两个接口轻松实现这一点:
virtual std::vector<ResourceRequest> ForwardResource( const mxnet::ShapeVector &in_shape) const; virtual std::vector<ResourceRequest> BackwardResource( const mxnet::ShapeVector &in_shape) const;
但是,如果**ForwardResource**和**BackwardResource**返回非空数组会怎样?在这种情况下,系统通过**Operator**的**Forward**和**Backward**接口中的**ctx**参数提供相应的资源。
**反向依赖 (Backward dependency)** - Apache MXNet 有以下两种不同的算子签名来处理反向依赖:
void FullyConnectedForward(TBlob weight, TBlob in_data, TBlob out_data); void FullyConnectedBackward(TBlob weight, TBlob in_data, TBlob out_grad, TBlob in_grad); void PoolingForward(TBlob in_data, TBlob out_data); void PoolingBackward(TBlob in_data, TBlob out_data, TBlob out_grad, TBlob in_grad);
这里需要注意两点:
FullyConnectedForward 中的 out_data 未被 FullyConnectedBackward 使用,并且
PoolingBackward 需要 PoolingForward 的所有参数。
这就是为什么对于**FullyConnectedForward**,一旦使用过的**out_data**张量可以安全释放,因为反向函数不需要它。借助这个系统,可以尽早将一些张量作为垃圾回收。
**就地选项 (In place Option)** - Apache MXNet 为用户提供了另一个接口来节省内存分配的成本。该接口适用于输入和输出张量具有相同形状的逐元素操作。
以下是指定就地更新的语法:
创建算子的示例
借助 OperatorProperty,我们可以创建一个算子。为此,请按照以下步骤操作:
virtual std::vector<std::pair<int, void*>> ElewiseOpProperty::ForwardInplaceOption(
const std::vector<int> &in_data,
const std::vector<void*> &out_data)
const {
return { {in_data[0], out_data[0]} };
}
virtual std::vector<std::pair<int, void*>> ElewiseOpProperty::BackwardInplaceOption(
const std::vector<int> &out_grad,
const std::vector<int> &in_data,
const std::vector<int> &out_data,
const std::vector<void*> &in_grad)
const {
return { {out_grad[0], in_grad[0]} }
}
步骤1
创建算子 (Create Operator)
首先在 OperatorProperty 中实现以下接口:
virtual Operator* CreateOperator(Context ctx) const = 0;
示例如下:
class ConvolutionOp {
public:
void Forward( ... ) { ... }
void Backward( ... ) { ... }
};
class ConvolutionOpProperty : public OperatorProperty {
public:
Operator* CreateOperator(Context ctx) const {
return new ConvolutionOp;
}
};
步骤2
参数化算子 (Parameterize Operator)
如果您要实现卷积算子,则必须知道内核大小、步幅大小、填充大小等。为什么?因为这些参数应该在调用任何**Forward**或**backward**接口之前传递给算子。
为此,我们需要定义一个**ConvolutionParam**结构,如下所示:
#include <dmlc/parameter.h>
struct ConvolutionParam : public dmlc::Parameter<ConvolutionParam> {
mxnet::TShape kernel, stride, pad;
uint32_t num_filter, num_group, workspace;
bool no_bias;
};
现在,我们需要将其放入**ConvolutionOpProperty**中,并将其传递给算子,如下所示:
class ConvolutionOp {
public:
ConvolutionOp(ConvolutionParam p): param_(p) {}
void Forward( ... ) { ... }
void Backward( ... ) { ... }
private:
ConvolutionParam param_;
};
class ConvolutionOpProperty : public OperatorProperty {
public:
void Init(const vector<pair<string, string>& kwargs) {
// initialize param_ using kwargs
}
Operator* CreateOperator(Context ctx) const {
return new ConvolutionOp(param_);
}
private:
ConvolutionParam param_;
};
步骤 3
将算子属性类和参数类注册到 Apache MXNet
最后,我们需要将算子属性类和参数类注册到 MXNet。这可以使用以下宏来完成:
DMLC_REGISTER_PARAMETER(ConvolutionParam); MXNET_REGISTER_OP_PROPERTY(Convolution, ConvolutionOpProperty);
在上面的宏中,第一个参数是名称字符串,第二个是属性类名称。
Apache MXNet - 统一算子 API
本章提供有关 Apache MXNet 中统一算子应用程序编程接口 (API) 的信息。
SimpleOp
SimpleOp 是一个新的统一算子 API,它统一了不同的调用过程。一旦被调用,它就会返回到算子的基本元素。统一算子专为一元和二元运算而设计。这是因为大多数数学运算符处理一个或两个操作数,而更多的操作数使与依赖性相关的优化变得有用。
我们将通过一个示例来了解其 SimpleOp 统一算子的工作原理。在这个示例中,我们将创建一个充当**smooth l1 loss**的算子,它是 l1 和 l2 loss 的混合。我们可以定义并编写损失,如下所示:
loss = outside_weight .* f(inside_weight .* (data - label)) grad = outside_weight .* inside_weight .* f'(inside_weight .* (data - label))
这里,在上面的例子中:
.* 代表逐元素乘法
**f, f’** 是我们假设在**mshadow**中的 smooth l1 loss 函数。
将此特定损失实现为一元或二元运算符似乎是不可能的,但 MXNet 为其用户提供了符号执行中的自动微分,这将损失直接简化为 f 和 f’。这就是为什么我们当然可以将这个特定的损失实现为一元运算符。
定义形状 (Defining Shapes)
众所周知,MXNet 的**mshadow 库**需要显式内存分配,因此我们需要在任何计算发生之前提供所有数据形状。在定义函数和梯度之前,我们需要提供输入形状一致性和输出形状,如下所示:
typedef mxnet::TShape (*UnaryShapeFunction)(const mxnet::TShape& src, const EnvArguments& env); typedef mxnet::TShape (*BinaryShapeFunction)(const mxnet::TShape& lhs, const mxnet::TShape& rhs, const EnvArguments& env);
mxnet::Tshape 函数用于检查输入数据形状和指定的输出数据形状。如果您没有定义此函数,则默认输出形状将与输入形状相同。例如,对于二元运算符,lhs 和 rhs 的形状默认情况下被检查为相同。
现在让我们继续我们的**smooth l1 loss 示例**。为此,我们需要在头文件实现**smooth_l1_unary-inl.h**中定义一个 XPU 到 cpu 或 gpu。原因是在**smooth_l1_unary.cc**和**smooth_l1_unary.cu**中重用相同的代码。
#include <mxnet/operator_util.h>
#if defined(__CUDACC__)
#define XPU gpu
#else
#define XPU cpu
#endif
在我们的**smooth l1 loss 示例**中,输出与源具有相同的形状,我们可以使用默认行为。它可以写成如下:
inline mxnet::TShape SmoothL1Shape_(const mxnet::TShape& src,const EnvArguments& env) {
return mxnet::TShape(src);
}
定义函数 (Defining Functions)
我们可以创建一个只有一个输入的一元或二元函数,如下所示:
typedef void (*UnaryFunction)(const TBlob& src, const EnvArguments& env, TBlob* ret, OpReqType req, RunContext ctx); typedef void (*BinaryFunction)(const TBlob& lhs, const TBlob& rhs, const EnvArguments& env, TBlob* ret, OpReqType req, RunContext ctx);
以下是**RunContext ctx 结构**,其中包含运行时执行所需的信息:
struct RunContext {
void *stream; // the stream of the device, can be NULL or Stream<gpu>* in GPU mode
template<typename xpu> inline mshadow::Stream<xpu>* get_stream() // get mshadow stream from Context
} // namespace mxnet
现在,让我们看看如何将计算结果写入**ret**。
enum OpReqType {
kNullOp, // no operation, do not write anything
kWriteTo, // write gradient to provided space
kWriteInplace, // perform an in-place write
kAddTo // add to the provided space
};
现在,让我们继续我们的**smooth l1 loss 示例**。为此,我们将使用 UnaryFunction 来定义此算子的函数,如下所示:
template<typename xpu>
void SmoothL1Forward_(const TBlob& src,
const EnvArguments& env,
TBlob *ret,
OpReqType req,
RunContext ctx) {
using namespace mshadow;
using namespace mshadow::expr;
mshadow::Stream<xpu> *s = ctx.get_stream<xpu>();
real_t sigma2 = env.scalar * env.scalar;
MSHADOW_TYPE_SWITCH(ret->type_flag_, DType, {
mshadow::Tensor<xpu, 2, DType> out = ret->get<xpu, 2, DType>(s);
mshadow::Tensor<xpu, 2, DType> in = src.get<xpu, 2, DType>(s);
ASSIGN_DISPATCH(out, req,
F<mshadow_op::smooth_l1_loss>(in, ScalarExp<DType>(sigma2)));
});
}
定义梯度 (Defining Gradients)
除了**Input、TBlob**和**OpReqType**加倍之外,二元运算符的梯度函数具有相似的结构。让我们查看下面,我们使用各种类型的输入创建了一个梯度函数:
// depending only on out_grad typedef void (*UnaryGradFunctionT0)(const OutputGrad& out_grad, const EnvArguments& env, TBlob* in_grad, OpReqType req, RunContext ctx); // depending only on out_value typedef void (*UnaryGradFunctionT1)(const OutputGrad& out_grad, const OutputValue& out_value, const EnvArguments& env, TBlob* in_grad, OpReqType req, RunContext ctx); // depending only on in_data typedef void (*UnaryGradFunctionT2)(const OutputGrad& out_grad, const Input0& in_data0, const EnvArguments& env, TBlob* in_grad, OpReqType req, RunContext ctx);
如上所定义,**Input0、Input、OutputValue**和**OutputGrad**都共享**GradientFunctionArgument**的结构。它定义如下:
struct GradFunctionArgument {
TBlob data;
}
现在让我们继续我们的**smooth l1 loss 示例**。为了启用梯度的链式法则,我们需要将来自顶部的**out_grad**乘以**in_grad**的结果。
template<typename xpu>
void SmoothL1BackwardUseIn_(const OutputGrad& out_grad, const Input0& in_data0,
const EnvArguments& env,
TBlob *in_grad,
OpReqType req,
RunContext ctx) {
using namespace mshadow;
using namespace mshadow::expr;
mshadow::Stream<xpu> *s = ctx.get_stream<xpu>();
real_t sigma2 = env.scalar * env.scalar;
MSHADOW_TYPE_SWITCH(in_grad->type_flag_, DType, {
mshadow::Tensor<xpu, 2, DType> src = in_data0.data.get<xpu, 2, DType>(s);
mshadow::Tensor<xpu, 2, DType> ograd = out_grad.data.get<xpu, 2, DType>(s);
mshadow::Tensor<xpu, 2, DType> igrad = in_grad->get<xpu, 2, DType>(s);
ASSIGN_DISPATCH(igrad, req,
ograd * F<mshadow_op::smooth_l1_gradient>(src, ScalarExp<DType>(sigma2)));
});
}
将 SimpleOp 注册到 MXNet
创建形状、函数和梯度后,我们需要将它们都还原到 NDArray 算子以及符号算子中。为此,我们可以使用以下注册宏:
MXNET_REGISTER_SIMPLE_OP(Name, DEV)
.set_shape_function(Shape)
.set_function(DEV::kDevMask, Function<XPU>, SimpleOpInplaceOption)
.set_gradient(DEV::kDevMask, Gradient<XPU>, SimpleOpInplaceOption)
.describe("description");
**SimpleOpInplaceOption**可以定义如下:
enum SimpleOpInplaceOption {
kNoInplace, // do not allow inplace in arguments
kInplaceInOut, // allow inplace in with out (unary)
kInplaceOutIn, // allow inplace out_grad with in_grad (unary)
kInplaceLhsOut, // allow inplace left operand with out (binary)
kInplaceOutLhs // allow inplace out_grad with lhs_grad (binary)
};
现在让我们继续我们的**smooth l1 loss 示例**。为此,我们有一个依赖于输入数据的梯度函数,因此该函数不能就地编写。
MXNET_REGISTER_SIMPLE_OP(smooth_l1, XPU)
.set_function(XPU::kDevMask, SmoothL1Forward_<XPU>, kNoInplace)
.set_gradient(XPU::kDevMask, SmoothL1BackwardUseIn_<XPU>, kInplaceOutIn)
.set_enable_scalar(true)
.describe("Calculate Smooth L1 Loss(lhs, scalar)");
SimpleOp 上的 EnvArguments
众所周知,某些操作可能需要:
标量作为输入,例如梯度比例
一组控制行为的关键字参数
一个临时空间来加快计算速度。
使用 EnvArguments 的好处是它提供了额外的参数和资源,使计算更具可扩展性和效率。
示例
首先让我们定义如下结构:
struct EnvArguments {
real_t scalar; // scalar argument, if enabled
std::vector<std::pair<std::string, std::string> > kwargs; // keyword arguments
std::vector<Resource> resource; // pointer to the resources requested
};
接下来,我们需要从**EnvArguments.resource**请求额外的资源,例如**mshadow::Random
struct ResourceRequest {
enum Type { // Resource type, indicating what the pointer type is
kRandom, // mshadow::Random<xpu> object
kTempSpace // A dynamic temp space that can be arbitrary size
};
Type type; // type of resources
};
现在,注册将从**mxnet::ResourceManager**请求声明的资源请求。之后,它会将资源放在**EnvAgruments**中的**std::vector
我们可以使用以下代码访问资源:
auto tmp_space_res = env.resources[0].get_space(some_shape, some_stream); auto rand_res = env.resources[0].get_random(some_stream);
在我们的 smooth l1 loss 示例中,需要一个标量输入来标记损失函数的转折点。这就是为什么在注册过程中,我们在函数和梯度声明中使用**set_enable_scalar(true)**和**env.scalar**。
构建张量操作 (Building Tensor Operation)
这里出现的问题是为什么我们需要构建张量操作?原因如下:
计算利用 mshadow 库,有时我们没有现成的函数。
如果操作不是以逐元素的方式完成,例如 softmax loss 和梯度。
示例
这里,我们使用上面的 smooth l1 loss 示例。我们将创建两个映射器,即 smooth l1 loss 和梯度的标量情况:
namespace mshadow_op {
struct smooth_l1_loss {
// a is x, b is sigma2
MSHADOW_XINLINE static real_t Map(real_t a, real_t b) {
if (a > 1.0f / b) {
return a - 0.5f / b;
} else if (a < -1.0f / b) {
return -a - 0.5f / b;
} else {
return 0.5f * a * a * b;
}
}
};
}
Apache MXNet - 分布式训练
本章介绍 Apache MXNet 中的分布式训练。让我们首先了解 MXNet 中的计算模式。
计算模式 (Modes of Computation)
MXNet 是一款多语言 ML 库,为用户提供了以下两种计算模式:
命令式模式 (Imperative mode)
这种计算模式公开了一个类似于 NumPy API 的接口。例如,在 MXNet 中,使用以下命令式代码在 CPU 和 GPU 上构建一个全零张量:
import mxnet as mx tensor_cpu = mx.nd.zeros((100,), ctx=mx.cpu()) tensor_gpu= mx.nd.zeros((100,), ctx=mx.gpu(0))
正如我们在上面的代码中看到的,MXNet 指定了保存张量的位置,在 CPU 或 GPU 设备上。在上面的示例中,它位于位置 0。MXNet 达到了令人难以置信的设备利用率,因为所有计算都是延迟发生的,而不是立即发生的。
符号式模式 (Symbolic mode)
虽然命令式模式非常有用,但这种模式的缺点之一是其僵化性,即所有计算都需要预先知道,以及预定义的数据结构。
另一方面,符号式模式公开了一个类似于 TensorFlow 的计算图。它通过允许 MXNet 使用符号或变量而不是固定/预定义的数据结构来消除命令式 API 的缺点。之后,符号可以解释为一组操作,如下所示:
import mxnet as mx x = mx.sym.Variable(“X”) y = mx.sym.Variable(“Y”) z = (x+y) m = z/100
并行类型 (Kinds of Parallelism)
Apache MXNet 支持分布式训练。它使我们能够利用多台机器进行更快、更有效的训练。
以下是我们可以将训练神经网络的工作负载分布到多个设备(CPU 或 GPU 设备)上的两种方法:
数据并行 (Data Parallelism)
在这种并行性中,每个设备都存储模型的完整副本,并使用数据集的不同部分。设备还集体更新共享模型。我们可以将所有设备放在一台机器上或多台机器上。
模型并行 (Model Parallelism)
这是另一种并行性,当模型太大而无法放入设备内存时非常有用。在模型并行中,不同的设备被分配学习模型的不同部分的任务。这里需要注意的重要一点是,目前 Apache MXNet 只支持单机模型并行。
分布式训练的工作原理 (Working of distributed training)
以下概念是理解 Apache MXNet 中分布式训练工作原理的关键:
进程类型 (Types of processes)
进程相互通信以完成模型的训练。Apache MXNet 有以下三个进程:
工作节点 (Worker)
工作节点的任务是在一批训练样本上执行训练。工作节点将在处理每一批之前从服务器拉取权重。处理完批次后,工作节点会将梯度发送到服务器。
服务器 (Server)
MXNet 可以有多个服务器来存储模型的参数并与工作节点通信。
调度器 (Scheduler)
调度器的作用是设置集群,包括等待每个节点启动的消息以及节点正在侦听的端口。设置集群后,调度器让所有进程都知道集群中的其他每个节点。这是因为进程可以相互通信。只有一个调度器。
KV 存储 (KV Store)
KV 存储代表**键值**存储 (Key-Value store)。它是多设备训练的关键组件。它的重要性在于,在单机或多机上,参数在设备间的通信是通过一个或多个带有 KVStore 的服务器来传输参数的。让我们通过以下几点来了解 KVStore 的工作原理:
KVStore 中的每个值都由一个**键**和一个**值**表示。
网络中的每个参数数组都分配一个**键**,该参数数组的权重由**值**引用。
之后,工作节点在处理完一个批次后**推送**梯度。它们还在处理新批次之前**拉取**更新后的权重。
KVStore 服务器的概念仅在分布式训练期间存在,并且可以通过使用包含单词**dist** 的字符串参数调用**mxnet.kvstore.create** 函数来启用其分布式模式:
kv = mxnet.kvstore.create(‘dist_sync’)
键的分布
并非所有服务器都存储所有参数数组或键,而是将它们分布在不同的服务器上。KVStore 透明地处理这种跨不同服务器的键的分布,而哪个服务器存储特定键的决定是随机做出的。
如上所述,KVStore 确保每当拉取键时,其请求都会发送到拥有相应值的服务器。如果某个键的值很大怎么办?在这种情况下,它可能会跨不同的服务器共享。
分割训练数据
作为用户,我们希望每台机器都能处理数据集的不同部分,尤其是在以数据并行模式运行分布式训练时。我们知道,为了分割数据迭代器为单一工作器上的数据并行训练提供的样本批次,我们可以使用**mxnet.gluon.utils.split_and_load**,然后将批次的每一部分加载到将进一步处理它的设备上。
另一方面,在分布式训练的情况下,首先需要将数据集分成**n**个不同的部分,以便每个工作器获得不同的部分。获得后,每个工作器可以使用**split_and_load**再次将数据集的那一部分划分为单台机器上的不同设备。所有这些都是通过数据迭代器完成的。**mxnet.io.MNISTIterator** 和**mxnet.io.ImageRecordIter** 是 MXNet 中支持此功能的两个这样的迭代器。
权重更新
为了更新权重,KVStore 支持以下两种模式:
第一种方法聚合梯度并使用这些梯度更新权重。
在第二种方法中,服务器仅聚合梯度。
如果您使用的是 Gluon,可以通过传递**update_on_kvstore** 变量来选择上述方法。让我们通过创建**trainer** 对象来了解它:
trainer = gluon.Trainer(net.collect_params(), optimizer='sgd',
optimizer_params={'learning_rate': opt.lr,
'wd': opt.wd,
'momentum': opt.momentum,
'multi_precision': True},
kvstore=kv,
update_on_kvstore=True)
分布式训练模式
如果 KVStore 创建字符串包含单词 dist,则表示已启用分布式训练。以下是可以通过使用不同类型的 KVStore 来启用的不同分布式训练模式:
dist_sync
顾名思义,它表示同步分布式训练。在此模式下,所有工作器在每个批次的开始都使用相同的同步模型参数集。
此模式的缺点是,在每个批次之后,服务器必须等到从每个工作器接收梯度才能更新模型参数。这意味着如果一个工作器崩溃,它将阻止所有工作器的进度。
dist_async
顾名思义,它表示异步分布式训练。在此模式下,服务器接收来自一个工作器的梯度并立即更新其存储。服务器使用更新后的存储来响应任何进一步的拉取请求。
与**dist_sync 模式**相比,其优点在于,完成处理一个批次的工作器可以从服务器拉取当前参数并开始下一个批次。即使其他工作器尚未完成处理之前的批次,工作器也可以这样做。它也比 dist_sync 模式快,因为它可以在没有任何同步成本的情况下进行更多轮次的收敛。
dist_sync_device
此模式与**dist_sync** 模式相同。唯一的区别是,当每个节点上使用多个 GPU 时,**dist_sync_device** 在 GPU 上聚合梯度并更新权重,而**dist_sync** 在 CPU 内存上聚合梯度并更新权重。
它减少了 GPU 和 CPU 之间的昂贵通信。因此,它比**dist_sync** 快。缺点是它增加了 GPU 的内存使用量。
dist_async_device
此模式的工作方式与**dist_sync_device** 模式相同,但处于异步模式。
Apache MXNet - Python 包
在本章中,我们将学习 Apache MXNet 中可用的 Python 包。
重要的 MXNet Python 包
MXNet 具有以下重要的 Python 包,我们将逐一讨论:
Autograd(自动微分)
NDArray
KVStore
Gluon
可视化
首先让我们从 Apache MXNet 的**Autograd** Python 包开始。
Autograd
**Autograd** 代表**自动微分**,用于将梯度从损失度量反向传播回每个参数。它结合反向传播使用动态规划方法来有效地计算梯度。它也称为反向模式自动微分。这种技术在“扇入”情况下非常有效,在“扇入”情况下,许多参数会影响单个损失度量。
什么是梯度?
梯度是神经网络训练过程的基础。它们基本上告诉我们如何改变网络的参数以提高其性能。
众所周知,神经网络 (NN) 由运算符组成,例如求和、乘积、卷积等。这些运算符在其计算中使用参数,例如卷积核中的权重。我们必须找到这些参数的最优值,而梯度则向我们展示了方法并引导我们找到解决方案。
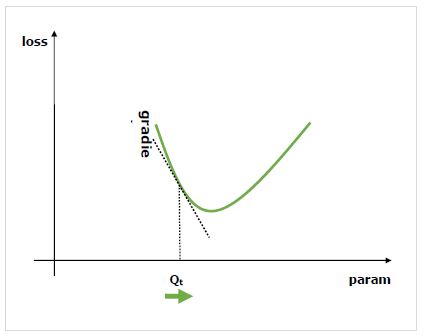
我们感兴趣的是改变参数对网络性能的影响,梯度告诉我们,当我们改变它所依赖的变量时,给定变量增加或减少的程度。性能通常使用我们试图最小化的损失度量来定义。例如,对于回归,我们可能会尝试最小化预测值和精确值之间的**L2** 损失,而对于分类,我们可能会最小化**交叉熵损失**。
一旦我们计算出每个参数相对于损失的梯度,我们就可以使用优化器,例如随机梯度下降。
如何计算梯度?
我们有以下选项来计算梯度:
**符号微分** - 第一个选项是符号微分,它计算每个梯度的公式。这种方法的缺点是,随着网络的深入和运算符的复杂化,它会很快导致非常长的公式。
**有限差分** - 另一个选项是使用有限差分,它尝试对每个参数进行细微的差异,并查看损失度量如何响应。这种方法的缺点是,它在计算上将非常昂贵,并且可能具有较差的数值精度。
**自动微分** - 以上方法缺点的解决方案是使用自动微分将梯度从损失度量反向传播回每个参数。传播允许我们使用动态规划方法有效地计算梯度。此方法也称为反向模式自动微分。
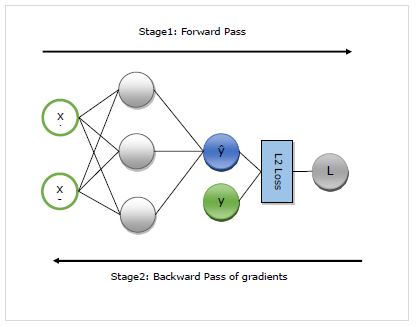
自动微分 (autograd)
在这里,我们将详细了解 autograd 的工作原理。它基本上分为以下两个阶段:
**阶段 1** - 此阶段称为训练的**“前向传递”**。顾名思义,在此阶段,它会创建网络用来进行预测和计算损失度量的运算符记录。
**阶段 2** - 此阶段称为训练的**“反向传递”**。顾名思义,在此阶段,它会通过此记录反向工作。向后移动,它会评估每个运算符的部分导数,一直回到网络参数。
autograd 的优点
以下是使用自动微分 (autograd) 的优点:
**灵活** - 它在定义网络时提供的灵活性是使用 autograd 的巨大好处之一。我们可以在每次迭代时更改操作。这些被称为动态图,在需要静态图的框架中实现起来要复杂得多。即使在这种情况下,autograd 仍然能够正确地反向传播梯度。
**自动** - Autograd 是自动的,即反向传播过程的复杂性由它为您处理。我们只需要指定我们感兴趣计算哪些梯度。
**高效** - Autograd 高效地计算梯度。
**可以使用原生 Python 控制流运算符** - 我们可以使用原生的 Python 控制流运算符,例如 if 条件和 while 循环。autograd 仍然能够有效且正确地反向传播梯度。
在 MXNet Gluon 中使用 autograd
在这里,我们将通过一个示例来了解如何在 MXNet Gluon 中使用**autograd**。
实现示例
在下面的示例中,我们将实现一个具有两层的神经网络模型。实现后,我们将使用 autograd 自动计算损失相对于每个权重参数的梯度:
首先导入 autogrard 和其他所需的包,如下所示:
from mxnet import autograd import mxnet as mx from mxnet.gluon.nn import HybridSequential, Dense from mxnet.gluon.loss import L2Loss
现在,我们需要定义网络,如下所示:
N_net = HybridSequential() N_net.add(Dense(units=3)) N_net.add(Dense(units=1)) N_net.initialize()
现在我们需要定义损失,如下所示:
loss_function = L2Loss()
接下来,我们需要创建虚拟数据,如下所示:
x = mx.nd.array([[0.5, 0.9]]) y = mx.nd.array([[1.5]])
现在,我们准备进行第一次通过网络的前向传递。我们希望 autograd 记录计算图,以便我们可以计算梯度。为此,我们需要在**autograd.record** 上下文的范围内运行网络代码,如下所示:
with autograd.record(): y_hat = N_net(x) loss = loss_function(y_hat, y)
现在,我们准备进行反向传播,我们首先对感兴趣的量调用反向方法。在我们的例子中,感兴趣的量是损失,因为我们试图计算损失相对于参数的梯度。
loss.backward()
现在,我们有了网络每个参数的梯度,优化器将使用这些梯度来更新参数值,以提高性能。让我们检查一下第一层的梯度,如下所示:
N_net[0].weight.grad()
输出
输出如下:
[[-0.00470527 -0.00846948] [-0.03640365 -0.06552657] [ 0.00800354 0.01440637]] <NDArray 3x2 @cpu(0)>
完整的实现示例
下面是完整的实现示例。
from mxnet import autograd import mxnet as mx from mxnet.gluon.nn import HybridSequential, Dense from mxnet.gluon.loss import L2Loss N_net = HybridSequential() N_net.add(Dense(units=3)) N_net.add(Dense(units=1)) N_net.initialize() loss_function = L2Loss() x = mx.nd.array([[0.5, 0.9]]) y = mx.nd.array([[1.5]]) with autograd.record(): y_hat = N_net(x) loss = loss_function(y_hat, y) loss.backward() N_net[0].weight.grad()
Apache MXNet - NDArray
在本章中,我们将讨论MXNet的多维数组格式,称为ndarray。
使用NDArray处理数据
首先,我们将了解如何使用NDArray处理数据。以下是相同的前提条件:
前提条件
要理解如何使用这种多维数组格式处理数据,我们需要满足以下前提条件
在Python环境中安装MXNet
Python 2.7.x 或 Python 3.x
实现示例
让我们借助下面的示例来了解基本功能:
首先,我们需要导入MXNet和来自MXNet的ndarray,如下所示:
import mxnet as mx from mxnet import nd
导入必要的库后,我们将使用以下基本功能
使用Python列表创建一个简单的1维数组
示例
x = nd.array([1,2,3,4,5,6,7,8,9,10]) print(x)
输出
输出如下所示:
[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.] <NDArray 10 @cpu(0)>
使用Python列表创建一个2维数组
示例
y = nd.array([[1,2,3,4,5,6,7,8,9,10], [1,2,3,4,5,6,7,8,9,10], [1,2,3,4,5,6,7,8,9,10]]) print(y)
输出
输出如下所示:
[[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.] [ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.] [ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.]] <NDArray 3x10 @cpu(0)>
创建一个没有初始化的NDArray
在这里,我们将使用.empty函数创建一个具有3行4列的矩阵。我们还将使用.full函数,它将采用一个额外的操作符来指定要在数组中填充的值。
示例
x = nd.empty((3, 4)) print(x) x = nd.full((3,4), 8) print(x)
输出
输出如下所示:
[[0.000e+00 0.000e+00 0.000e+00 0.000e+00] [0.000e+00 0.000e+00 2.887e-42 0.000e+00] [0.000e+00 0.000e+00 0.000e+00 0.000e+00]] <NDArray 3x4 @cpu(0)> [[8. 8. 8. 8.] [8. 8. 8. 8.] [8. 8. 8. 8.]] <NDArray 3x4 @cpu(0)>
使用.zeros函数创建一个全为零的矩阵
示例
x = nd.zeros((3, 8)) print(x)
输出
输出如下所示:
[[0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0.]] <NDArray 3x8 @cpu(0)>
使用.ones函数创建一个全为一的矩阵
示例
x = nd.ones((3, 8)) print(x)
输出
输出如下所示:
[[1. 1. 1. 1. 1. 1. 1. 1.] [1. 1. 1. 1. 1. 1. 1. 1.] [1. 1. 1. 1. 1. 1. 1. 1.]] <NDArray 3x8 @cpu(0)>
创建一个值随机采样的数组
示例
y = nd.random_normal(0, 1, shape=(3, 4)) print(y)
输出
输出如下所示:
[[ 1.2673576 -2.0345826 -0.32537818 -1.4583491 ] [-0.11176403 1.3606371 -0.7889914 -0.17639421] [-0.2532185 -0.42614475 -0.12548696 1.4022992 ]] <NDArray 3x4 @cpu(0)>
查找每个NDArray的维度
示例
y.shape
输出
输出如下所示:
(3, 4)
查找每个NDArray的大小
示例
y.size
输出
12
查找每个NDArray的数据类型
示例
y.dtype
输出
numpy.float32
NDArray操作
在本节中,我们将向您介绍MXNet的数组操作。NDArray支持大量的标准数学运算以及就地运算。
标准数学运算
以下是NDArray支持的标准数学运算:
逐元素加法
首先,我们需要导入MXNet和来自MXNet的ndarray,如下所示
import mxnet as mx
from mxnet import nd
x = nd.ones((3, 5))
y = nd.random_normal(0, 1, shape=(3, 5))
print('x=', x)
print('y=', y)
x = x + y
print('x = x + y, x=', x)
输出
输出如下所示:
x= [[1. 1. 1. 1. 1.] [1. 1. 1. 1. 1.] [1. 1. 1. 1. 1.]] <NDArray 3x5 @cpu(0)> y= [[-1.0554522 -1.3118273 -0.14674698 0.641493 -0.73820823] [ 2.031364 0.5932667 0.10228804 1.179526 -0.5444829 ] [-0.34249446 1.1086396 1.2756858 -1.8332436 -0.5289873 ]] <NDArray 3x5 @cpu(0)> x = x + y, x= [[-0.05545223 -0.3118273 0.853253 1.6414931 0.26179177] [ 3.031364 1.5932667 1.102288 2.1795259 0.4555171 ] [ 0.6575055 2.1086397 2.2756858 -0.8332436 0.4710127 ]] <NDArray 3x5 @cpu(0)>
逐元素乘法
示例
x = nd.array([1, 2, 3, 4]) y = nd.array([2, 2, 2, 1]) x * y
输出
您将看到以下输出:
[2. 4. 6. 4.] <NDArray 4 @cpu(0)>
幂运算
示例
nd.exp(x)
输出
运行代码后,您将看到以下输出
[ 2.7182817 7.389056 20.085537 54.59815 ] <NDArray 4 @cpu(0)>
矩阵转置计算矩阵乘积
示例
nd.dot(x, y.T)
输出
以下是代码的输出:
[16.] <NDArray 1 @cpu(0)>
就地操作
在上面的示例中,每次运行一个操作时,我们都会分配一个新的内存来存储其结果。
例如,如果我们写A = A+B,我们将取消引用A过去指向的矩阵,并将其指向新分配的内存。让我们使用Python的id()函数来了解下面的示例:
print('y=', y)
print('id(y):', id(y))
y = y + x
print('after y=y+x, y=', y)
print('id(y):', id(y))
输出
执行后,您将收到以下输出:
y= [2. 2. 2. 1.] <NDArray 4 @cpu(0)> id(y): 2438905634376 after y=y+x, y= [3. 4. 5. 5.] <NDArray 4 @cpu(0)> id(y): 2438905685664
事实上,我们也可以将结果赋值给以前分配的数组,如下所示:
print('x=', x)
z = nd.zeros_like(x)
print('z is zeros_like x, z=', z)
print('id(z):', id(z))
print('y=', y)
z[:] = x + y
print('z[:] = x + y, z=', z)
print('id(z) is the same as before:', id(z))
输出
输出如下所示:
x= [1. 2. 3. 4.] <NDArray 4 @cpu(0)> z is zeros_like x, z= [0. 0. 0. 0.] <NDArray 4 @cpu(0)> id(z): 2438905790760 y= [3. 4. 5. 5.] <NDArray 4 @cpu(0)> z[:] = x + y, z= [4. 6. 8. 9.] <NDArray 4 @cpu(0)> id(z) is the same as before: 2438905790760
从上面的输出中,我们可以看到x+y仍然会分配一个临时缓冲区来存储结果,然后再将其复制到z。所以现在,我们可以执行就地操作来更好地利用内存并避免临时缓冲区。为此,我们将为每个操作符指定out关键字参数,如下所示:
print('x=', x, 'is in id(x):', id(x))
print('y=', y, 'is in id(y):', id(y))
print('z=', z, 'is in id(z):', id(z))
nd.elemwise_add(x, y, out=z)
print('after nd.elemwise_add(x, y, out=z), x=', x, 'is in id(x):', id(x))
print('after nd.elemwise_add(x, y, out=z), y=', y, 'is in id(y):', id(y))
print('after nd.elemwise_add(x, y, out=z), z=', z, 'is in id(z):', id(z))
输出
执行上述程序后,您将得到以下结果:
x= [1. 2. 3. 4.] <NDArray 4 @cpu(0)> is in id(x): 2438905791152 y= [3. 4. 5. 5.] <NDArray 4 @cpu(0)> is in id(y): 2438905685664 z= [4. 6. 8. 9.] <NDArray 4 @cpu(0)> is in id(z): 2438905790760 after nd.elemwise_add(x, y, out=z), x= [1. 2. 3. 4.] <NDArray 4 @cpu(0)> is in id(x): 2438905791152 after nd.elemwise_add(x, y, out=z), y= [3. 4. 5. 5.] <NDArray 4 @cpu(0)> is in id(y): 2438905685664 after nd.elemwise_add(x, y, out=z), z= [4. 6. 8. 9.] <NDArray 4 @cpu(0)> is in id(z): 2438905790760
NDArray上下文
在Apache MXNet中,每个数组都有一个上下文,一个上下文可能是CPU,而其他上下文可能是多个GPU。当我们将工作部署到多台服务器时,情况可能会更糟。因此,我们需要智能地将数组分配给上下文。这将最大限度地减少在设备之间传输数据所花费的时间。
例如,尝试初始化一个数组,如下所示:
from mxnet import nd z = nd.ones(shape=(3,3), ctx=mx.cpu(0)) print(z)
输出
执行上述代码后,您应该看到以下输出:
[[1. 1. 1.] [1. 1. 1.] [1. 1. 1.]] <NDArray 3x3 @cpu(0)>
我们可以使用copyto()方法将给定的NDArray从一个上下文复制到另一个上下文,如下所示:
x_gpu = x.copyto(gpu(0)) print(x_gpu)
NumPy数组与NDArray
我们都熟悉NumPy数组,但Apache MXNet提供了自己的数组实现,名为NDArray。实际上,它最初的设计类似于NumPy,但有一个关键区别:
关键区别在于NumPy和NDArray中计算的执行方式。MXNet中的每个NDArray操作都是异步且非阻塞的,这意味着当我们编写类似c = a * b的代码时,该函数会被推送到执行引擎,它将启动计算。
这里,a和b都是NDArray。使用它的好处是,函数会立即返回,用户线程可以继续执行,即使之前的计算可能尚未完成。
执行引擎的工作原理
如果我们谈论执行引擎的工作原理,它会构建计算图。计算图可能会重新排序或组合一些计算,但它始终遵守依赖顺序。
例如,如果在编程代码的后面还有其他对“X”的操作,执行引擎将在“X”的结果可用后开始执行它们。执行引擎将为用户处理一些重要的工作,例如编写回调以启动后续代码的执行。
在Apache MXNet中,借助NDArray,要获得计算结果,我们只需要访问结果变量。代码流将被阻塞,直到计算结果被赋给结果变量。通过这种方式,它在仍然支持命令式编程模式的同时提高了代码性能。
将NDArray转换为NumPy数组
让我们学习如何在MXNet中将NDArray转换为NumPy数组。
结合少量低级运算符来使用高级运算符
有时,我们可以使用现有的运算符来组装一个高级运算符。最好的例子之一是np.full_like()运算符,它不存在于NDArray API中。它可以很容易地用现有运算符的组合来替换,如下所示
from mxnet import nd import numpy as np np_x = np.full_like(a=np.arange(7, dtype=int), fill_value=15) nd_x = nd.ones(shape=(7,)) * 15 np.array_equal(np_x, nd_x.asnumpy())
输出
我们将得到类似于以下的输出:
True
查找名称和/或签名不同的类似运算符
在所有运算符中,有些运算符的名称略有不同,但在功能方面是相似的。一个例子是nd.ravel_index()和np.ravel()函数。同样,有些运算符可能具有相似的名称,但它们的签名不同。一个例子是np.split()和nd.split()是相似的。
让我们通过以下编程示例来了解它
def pad_array123(data, max_length): data_expanded = data.reshape(1, 1, 1, data.shape[0]) data_padded = nd.pad(data_expanded, mode='constant', pad_width=[0, 0, 0, 0, 0, 0, 0, max_length - data.shape[0]], constant_value=0) data_reshaped_back = data_padded.reshape(max_length) return data_reshaped_back pad_array123(nd.array([1, 2, 3]), max_length=10)
输出
输出如下所示:
[1. 2. 3. 0. 0. 0. 0. 0. 0. 0.] <NDArray 10 @cpu(0)>
最小化阻塞调用的影响
在某些情况下,我们必须使用.asnumpy()或.asscalar()方法,但这将强制MXNet阻塞执行,直到可以检索结果。当我们认为该值的计算已经完成时,我们可以通过调用.asnumpy()或.asscalar()方法来最小化阻塞调用的影响。
实现示例
示例
from __future__ import print_function
import mxnet as mx
from mxnet import gluon, nd, autograd
from mxnet.ndarray import NDArray
from mxnet.gluon import HybridBlock
import numpy as np
class LossBuffer(object):
"""
Simple buffer for storing loss value
"""
def __init__(self):
self._loss = None
def new_loss(self, loss):
ret = self._loss
self._loss = loss
return ret
@property
def loss(self):
return self._loss
net = gluon.nn.Dense(10)
ce = gluon.loss.SoftmaxCELoss()
net.initialize()
data = nd.random.uniform(shape=(1024, 100))
label = nd.array(np.random.randint(0, 10, (1024,)), dtype='int32')
train_dataset = gluon.data.ArrayDataset(data, label)
train_data = gluon.data.DataLoader(train_dataset, batch_size=128, shuffle=True, num_workers=2)
trainer = gluon.Trainer(net.collect_params(), optimizer='sgd')
loss_buffer = LossBuffer()
for data, label in train_data:
with autograd.record():
out = net(data)
# This call saves new loss and returns previous loss
prev_loss = loss_buffer.new_loss(ce(out, label))
loss_buffer.loss.backward()
trainer.step(data.shape[0])
if prev_loss is not None:
print("Loss: {}".format(np.mean(prev_loss.asnumpy())))
输出
输出如下所示
Loss: 2.3373236656188965 Loss: 2.3656985759735107 Loss: 2.3613128662109375 Loss: 2.3197104930877686 Loss: 2.3054862022399902 Loss: 2.329197406768799 Loss: 2.318927526473999
Apache MXNet - Gluon
另一个最重要的MXNet Python包是Gluon。在本章中,我们将讨论这个包。Gluon为深度学习项目提供了一个清晰、简洁和简单的API。它使Apache MXNet能够在不牺牲训练速度的情况下对深度学习模型进行原型设计、构建和训练。
块
块构成了更复杂的网络设计的基石。在神经网络中,随着神经网络复杂性的增加,我们需要从设计单个神经元转向设计整个神经元层。例如,ResNet-152之类的NN设计通过由重复层的块组成,具有相当高的规律性。
示例
在下面的示例中,我们将为多层感知器编写一个简单的块代码,即块。
from mxnet import nd from mxnet.gluon import nn x = nd.random.uniform(shape=(2, 20)) N_net = nn.Sequential() N_net.add(nn.Dense(256, activation='relu')) N_net.add(nn.Dense(10)) N_net.initialize() N_net(x)
输出
这将产生以下输出
[[ 0.09543004 0.04614332 -0.00286655 -0.07790346 -0.05130241 0.02942038 0.08696645 -0.0190793 -0.04122177 0.05088576] [ 0.0769287 0.03099706 0.00856576 -0.044672 -0.06926838 0.09132431 0.06786592 -0.06187843 -0.03436674 0.04234696]] <NDArray 2x10 @cpu(0)>
从定义层到定义一个或多个层的块所需的步骤:
步骤1 - 块将数据作为输入。
步骤2 - 现在,块将以参数的形式存储状态。例如,在上例代码中,块包含两个隐藏层,我们需要一个地方来存储它的参数。
步骤3 - 接下来,块将调用前向函数执行前向传播。它也称为前向计算。作为第一次前向调用的部分,块以惰性方式初始化参数。
步骤4 - 最后,块将调用反向函数并计算相对于其输入的梯度。通常,此步骤会自动执行。
顺序块
顺序块是一种特殊的块,其中数据流经一系列块。在此过程中,每个块都应用于前一个块的输出,第一个块应用于输入数据本身。
让我们看看sequential类的使用方法:
from mxnet import nd
from mxnet.gluon import nn
class MySequential(nn.Block):
def __init__(self, **kwargs):
super(MySequential, self).__init__(**kwargs)
def add(self, block):
self._children[block.name] = block
def forward(self, x):
for block in self._children.values():
x = block(x)
return x
x = nd.random.uniform(shape=(2, 20))
N_net = MySequential()
N_net.add(nn.Dense(256, activation
='relu'))
N_net.add(nn.Dense(10))
N_net.initialize()
N_net(x)
输出
输出如下所示:
[[ 0.09543004 0.04614332 -0.00286655 -0.07790346 -0.05130241 0.02942038 0.08696645 -0.0190793 -0.04122177 0.05088576] [ 0.0769287 0.03099706 0.00856576 -0.044672 -0.06926838 0.09132431 0.06786592 -0.06187843 -0.03436674 0.04234696]] <NDArray 2x10 @cpu(0)>
自定义块
我们可以轻松地超越上面定义的顺序块的串联。但是,如果我们想进行自定义,那么Block类也为我们提供了所需的功能。Block类在nn模块中提供了一个模型构造函数。我们可以继承该模型构造函数来定义我们想要的模型。
在下面的示例中,MLP类重写了Block类的__init__和forward函数。
让我们看看它是如何工作的。
class MLP(nn.Block):
def __init__(self, **kwargs):
super(MLP, self).__init__(**kwargs)
self.hidden = nn.Dense(256, activation='relu') # Hidden layer
self.output = nn.Dense(10) # Output layer
def forward(self, x):
hidden_out = self.hidden(x)
return self.output(hidden_out)
x = nd.random.uniform(shape=(2, 20))
N_net = MLP()
N_net.initialize()
N_net(x)
输出
运行代码后,您将看到以下输出
[[ 0.07787763 0.00216403 0.01682201 0.03059879 -0.00702019 0.01668715 0.04822846 0.0039432 -0.09300035 -0.04494302] [ 0.08891078 -0.00625484 -0.01619131 0.0380718 -0.01451489 0.02006172 0.0303478 0.02463485 -0.07605448 -0.04389168]] <NDArray 2x10 @cpu(0)>
自定义层
Apache MXNet的Gluon API带有一些预定义的层。但是,在某些时候,我们可能会发现需要一个新的层。我们可以轻松地在Gluon API中添加一个新的层。在本节中,我们将了解如何从头开始创建一个新的层。
最简单的自定义层
要在Gluon API中创建一个新的层,我们必须创建一个继承自Block类的类,该类提供最基本的功能。我们可以直接或通过其他子类从它继承所有预定义的层。
为了创建新层,唯一需要实现的实例方法是forward (self, x)。此方法定义了在正向传播期间我们的层将执行的操作。如前所述,块的反向传播将由Apache MXNet自动完成。
示例
在下面的示例中,我们将定义一个新的层。我们还将实现forward()方法,通过将输入数据拟合到[0, 1]范围内来规范化输入数据。
from __future__ import print_function
import mxnet as mx
from mxnet import nd, gluon, autograd
from mxnet.gluon.nn import Dense
mx.random.seed(1)
class NormalizationLayer(gluon.Block):
def __init__(self):
super(NormalizationLayer, self).__init__()
def forward(self, x):
return (x - nd.min(x)) / (nd.max(x) - nd.min(x))
x = nd.random.uniform(shape=(2, 20))
N_net = NormalizationLayer()
N_net.initialize()
N_net(x)
输出
执行上述程序后,您将得到以下结果:
[[0.5216355 0.03835821 0.02284337 0.5945146 0.17334817 0.69329053 0.7782702 1. 0.5508242 0. 0.07058554 0.3677264 0.4366546 0.44362497 0.7192635 0.37616986 0.6728799 0.7032008 0.46907538 0.63514024] [0.9157533 0.7667402 0.08980197 0.03593295 0.16176797 0.27679572 0.07331014 0.3905285 0.6513384 0.02713427 0.05523694 0.12147208 0.45582628 0.8139887 0.91629887 0.36665893 0.07873632 0.78268915 0.63404864 0.46638715]] <NDArray 2x20 @cpu(0)>
混合
它可以定义为Apache MXNet用于创建前向计算的符号图的过程。混合允许MXNet通过优化计算符号图来提高计算性能。事实上,我们可能会发现,在实现现有层时,一个块继承自HybridBlock,而不是直接继承自Block。
以下是原因:
允许我们编写自定义层:HybridBlock允许我们编写自定义层,这些层可以在命令式编程和符号式编程中进一步使用。
提高计算性能− HybridBlock优化计算符号图,使MXNet能够提高计算性能。
示例
在这个例子中,我们将使用HybridBlock重写上面创建的示例层。
class NormalizationHybridLayer(gluon.HybridBlock):
def __init__(self):
super(NormalizationHybridLayer, self).__init__()
def hybrid_forward(self, F, x):
return F.broadcast_div(F.broadcast_sub(x, F.min(x)), (F.broadcast_sub(F.max(x), F.min(x))))
layer_hybd = NormalizationHybridLayer()
layer_hybd(nd.array([1, 2, 3, 4, 5, 6], ctx=mx.cpu()))
输出
输出如下所示
[0. 0.2 0.4 0.6 0.8 1. ] <NDArray 6 @cpu(0)>
混合化与GPU上的计算无关,可以在CPU和GPU上训练混合网络和非混合网络。
Block和HybridBlock的区别
如果我们将Block类和HybridBlock进行比较,我们会看到HybridBlock已经实现了它的forward()方法。HybridBlock定义了一个需要在创建层时实现的hybrid_forward()方法。F参数是forward()和hybrid_forward()之间主要的区别。在MXNet社区中,F参数被称为后端。F可以指mxnet.ndarray API(用于命令式编程)或mxnet.symbol API(用于符号式编程)。
如何将自定义层添加到网络中?
这些层不是单独使用自定义层,而是与预定义层一起使用。我们可以使用Sequential或HybridSequential容器来形成一个顺序神经网络。如前所述,Sequential容器继承自Block,HybridSequential分别继承自HybridBlock。
示例
在下面的例子中,我们将创建一个具有自定义层的神经网络。Dense (5)层的输出将成为NormalizationHybridLayer的输入。NormalizationHybridLayer的输出将成为Dense (1)层的输入。
net = gluon.nn.HybridSequential() with net.name_scope(): net.add(Dense(5)) net.add(NormalizationHybridLayer()) net.add(Dense(1)) net.initialize(mx.init.Xavier(magnitude=2.24)) net.hybridize() input = nd.random_uniform(low=-10, high=10, shape=(10, 2)) net(input)
输出
您将看到以下输出:
[[-1.1272651] [-1.2299833] [-1.0662932] [-1.1805027] [-1.3382034] [-1.2081106] [-1.1263978] [-1.2524893] [-1.1044774] [-1.316593 ]] <NDArray 10x1 @cpu(0)>
自定义层参数
在一个神经网络中,一个层有一组与其相关的参数。我们有时称它们为权重,它是层的内部状态。这些参数扮演着不同的角色:
有时这些是我们想要在反向传播步骤中学习的参数。
有时这些只是我们想要在正向传递中使用的常数。
如果我们谈论编程概念,块的这些参数(权重)通过ParameterDict类存储和访问,这有助于它们的初始化、更新、保存和加载。
示例
在下面的例子中,我们将定义以下两组参数:
参数权重 - 这是可训练的,其形状在构造阶段是未知的。它将在第一次正向传播运行时推断出来。
参数比例 - 这是一个常数,其值不会改变。与参数权重相反,它的形状在构造期间定义。
class NormalizationHybridLayer(gluon.HybridBlock):
def __init__(self, hidden_units, scales):
super(NormalizationHybridLayer, self).__init__()
with self.name_scope():
self.weights = self.params.get('weights',
shape=(hidden_units, 0),
allow_deferred_init=True)
self.scales = self.params.get('scales',
shape=scales.shape,
init=mx.init.Constant(scales.asnumpy()),
differentiable=False)
def hybrid_forward(self, F, x, weights, scales):
normalized_data = F.broadcast_div(F.broadcast_sub(x, F.min(x)),
(F.broadcast_sub(F.max(x), F.min(x))))
weighted_data = F.FullyConnected(normalized_data, weights, num_hidden=self.weights.shape[0], no_bias=True)
scaled_data = F.broadcast_mul(scales, weighted_data)
return scaled_data
Apache MXNet - KVStore 和可视化
本章介绍python包KVStore和可视化。
KVStore包
KV存储代表键值存储。它是用于多设备训练的关键组件。它很重要,因为参数在单个设备以及跨多个机器上的设备之间的通信是通过一个或多个服务器与KVStore进行参数传输的。
让我们通过以下几点来了解KVStore的工作原理
KVStore 中的每个值都由一个**键**和一个**值**表示。
网络中的每个参数数组都分配一个**键**,该参数数组的权重由**值**引用。
之后,工作节点在处理完一个批次后**推送**梯度。它们还在处理新批次之前**拉取**更新后的权重。
简单来说,我们可以说KVStore是一个数据共享的地方,每个设备都可以将数据推入和拉出。
数据推入和拉出
KVStore可以被认为是跨不同设备(如GPU和计算机)共享的单个对象,每个设备都可以将数据推入和拉出。
以下是设备需要遵循的将数据推入和拉出的实现步骤
实现步骤
初始化 - 第一步是初始化值。在这里,对于我们的示例,我们将一个(int, NDArray)对初始化到KVStrore中,然后将值拉出:
import mxnet as mx
kv = mx.kv.create('local') # create a local KVStore.
shape = (3,3)
kv.init(3, mx.nd.ones(shape)*2)
a = mx.nd.zeros(shape)
kv.pull(3, out = a)
print(a.asnumpy())
输出
这将产生以下输出:
[[2. 2. 2.] [2. 2. 2.] [2. 2. 2.]]
推送、聚合和更新 - 初始化后,我们可以将具有相同形状的新值推送到KVStore中的同一键:
kv.push(3, mx.nd.ones(shape)*8) kv.pull(3, out = a) print(a.asnumpy())
输出
输出如下所示:
[[8. 8. 8.] [8. 8. 8.] [8. 8. 8.]]
用于推送的数据可以存储在任何设备上,例如GPU或计算机。我们还可以将多个值推送到同一个键。在这种情况下,KVStore将首先将所有这些值相加,然后按如下方式推送聚合值:
contexts = [mx.cpu(i) for i in range(4)] b = [mx.nd.ones(shape, ctx) for ctx in contexts] kv.push(3, b) kv.pull(3, out = a) print(a.asnumpy())
输出
您将看到以下输出:
[[4. 4. 4.] [4. 4. 4.] [4. 4. 4.]]
对于您应用的每次推送,KVStore都会将推送的值与已存储的值合并。这将借助更新器完成。这里,默认更新器为ASSIGN。
def update(key, input, stored):
print("update on key: %d" % key)
stored += input * 2
kv.set_updater(update)
kv.pull(3, out=a)
print(a.asnumpy())
输出
执行上述代码后,您应该看到以下输出:
[[4. 4. 4.] [4. 4. 4.] [4. 4. 4.]]
示例
kv.push(3, mx.nd.ones(shape)) kv.pull(3, out=a) print(a.asnumpy())
输出
以下是代码的输出:
update on key: 3 [[6. 6. 6.] [6. 6. 6.] [6. 6. 6.]]
拉取 - 与推送一样,我们也可以通过一次调用将值拉取到多个设备上:
b = [mx.nd.ones(shape, ctx) for ctx in contexts] kv.pull(3, out = b) print(b[1].asnumpy())
输出
输出如下所示:
[[6. 6. 6.] [6. 6. 6.] [6. 6. 6.]]
完整的实现示例
下面是完整的实现示例:
import mxnet as mx
kv = mx.kv.create('local')
shape = (3,3)
kv.init(3, mx.nd.ones(shape)*2)
a = mx.nd.zeros(shape)
kv.pull(3, out = a)
print(a.asnumpy())
kv.push(3, mx.nd.ones(shape)*8)
kv.pull(3, out = a) # pull out the value
print(a.asnumpy())
contexts = [mx.cpu(i) for i in range(4)]
b = [mx.nd.ones(shape, ctx) for ctx in contexts]
kv.push(3, b)
kv.pull(3, out = a)
print(a.asnumpy())
def update(key, input, stored):
print("update on key: %d" % key)
stored += input * 2
kv._set_updater(update)
kv.pull(3, out=a)
print(a.asnumpy())
kv.push(3, mx.nd.ones(shape))
kv.pull(3, out=a)
print(a.asnumpy())
b = [mx.nd.ones(shape, ctx) for ctx in contexts]
kv.pull(3, out = b)
print(b[1].asnumpy())
处理键值对
我们上面实现的所有操作都涉及单个键,但KVStore还提供键值对列表的接口:
对于单个设备
以下是一个示例,用于显示单个设备的键值对列表的KVStore接口:
keys = [5, 7, 9] kv.init(keys, [mx.nd.ones(shape)]*len(keys)) kv.push(keys, [mx.nd.ones(shape)]*len(keys)) b = [mx.nd.zeros(shape)]*len(keys) kv.pull(keys, out = b) print(b[1].asnumpy())
输出
您将收到以下输出:
update on key: 5 update on key: 7 update on key: 9 [[3. 3. 3.] [3. 3. 3.] [3. 3. 3.]]
对于多个设备
以下是一个示例,用于显示多个设备的键值对列表的KVStore接口:
b = [[mx.nd.ones(shape, ctx) for ctx in contexts]] * len(keys) kv.push(keys, b) kv.pull(keys, out = b) print(b[1][1].asnumpy())
输出
您将看到以下输出:
update on key: 5 update on key: 7 update on key: 9 [[11. 11. 11.] [11. 11. 11.] [11. 11. 11.]]
可视化包
可视化包是Apache MXNet包,用于将神经网络(NN)表示为由节点和边组成的计算图。
可视化神经网络
在下面的示例中,我们将使用mx.viz.plot_network来可视化神经网络。以下是先决条件:
前提条件
Jupyter notebook
Graphviz库
实现示例
在下面的示例中,我们将可视化一个用于线性矩阵分解的示例NN:
import mxnet as mx
user = mx.symbol.Variable('user')
item = mx.symbol.Variable('item')
score = mx.symbol.Variable('score')
# Set the dummy dimensions
k = 64
max_user = 100
max_item = 50
# The user feature lookup
user = mx.symbol.Embedding(data = user, input_dim = max_user, output_dim = k)
# The item feature lookup
item = mx.symbol.Embedding(data = item, input_dim = max_item, output_dim = k)
# predict by the inner product and then do sum
N_net = user * item
N_net = mx.symbol.sum_axis(data = N_net, axis = 1)
N_net = mx.symbol.Flatten(data = N_net)
# Defining the loss layer
N_net = mx.symbol.LinearRegressionOutput(data = N_net, label = score)
# Visualize the network
mx.viz.plot_network(N_net)
Apache MXNet - Python API ndarray
本章解释了Apache MXNet中提供的ndarray库。
Mxnet.ndarray
Apache MXNet的NDArray库定义了所有数学计算的核心DS(数据结构)。NDArray的两个基本工作如下:
它支持在各种硬件配置上的快速执行。
它自动跨可用硬件并行化多个操作。
下面给出的示例显示了如何使用来自普通Python列表的一维和二维“数组”来创建NDArray:
import mxnet as mx from mxnet import nd x = nd.array([1,2,3,4,5,6,7,8,9,10]) print(x)
输出
输出如下所示
[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.] <NDArray 10 @cpu(0)>
示例
y = nd.array([[1,2,3,4,5,6,7,8,9,10], [1,2,3,4,5,6,7,8,9,10], [1,2,3,4,5,6,7,8,9,10]]) print(y)
输出
这将产生以下输出:
[[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.] [ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.] [ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.]] <NDArray 3x10 @cpu(0)>
现在让我们详细讨论MXNet的ndarray API的类、函数和参数。
类
下表包含MXNet的ndarray API的类:
| 类 | 定义 |
|---|---|
| CachedOp(sym[, flags]) | 它用于缓存操作句柄。 |
| NDArray(handle[, writable]) | 它用作表示固定大小项的多维同质数组的数组对象。 |
函数及其参数
以下是mxnet.ndarray API涵盖的一些重要函数及其参数:
| 函数及其参数 | 定义 |
|---|---|
| Activation([data, act_type, out, name]) | 它将激活函数逐元素应用于输入。它支持relu、sigmoid、tanh、softrelu、softsign激活函数。 |
| BatchNorm([data, gamma, beta, moving_mean, …]) | 它用于批量归一化。此函数通过均值和方差归一化数据批次。它应用比例gamma和偏移beta。 |
| BilinearSampler([data, grid, cudnn_off, …]) |
此函数将双线性采样应用于输入特征图。实际上,它是“空间变换网络”的关键。 如果您熟悉OpenCV中的remap函数,则此函数的使用与该函数非常相似。唯一的区别是它有反向传递。 |
| BlockGrad([data, out, name]) | 顾名思义,此函数停止梯度计算。它基本上阻止输入的累积梯度在反向方向上流经此运算符。 |
| cast([data, dtype, out, name]) | 此函数将输入的所有元素转换为新类型。 |
实现示例
在下面的示例中,我们将使用BilinierSampler()函数将数据缩小两倍,并将数据水平移动-1像素:
import mxnet as mx from mxnet import nd data = nd.array([[[[2, 5, 3, 6], [1, 8, 7, 9], [0, 4, 1, 8], [2, 0, 3, 4]]]]) affine_matrix = nd.array([[2, 0, 0], [0, 2, 0]]) affine_matrix = nd.reshape(affine_matrix, shape=(1, 6)) grid = nd.GridGenerator(data=affine_matrix, transform_type='affine', target_shape=(4, 4)) output = nd.BilinearSampler(data, grid)
输出
执行上述代码时,您应该看到以下输出
[[[[0. 0. 0. 0. ] [0. 4.0000005 6.25 0. ] [0. 1.5 4. 0. ] [0. 0. 0. 0. ]]]] <NDArray 1x1x4x4 @cpu(0)>
上述输出显示了数据缩小两倍。
将数据移动-1像素的示例如下:
import mxnet as mx from mxnet import nd data = nd.array([[[[2, 5, 3, 6], [1, 8, 7, 9], [0, 4, 1, 8], [2, 0, 3, 4]]]]) warp_matrix = nd.array([[[[1, 1, 1, 1], [1, 1, 1, 1], [1, 1, 1, 1], [1, 1, 1, 1]], [[0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0]]]]) grid = nd.GridGenerator(data=warp_matrix, transform_type='warp') output = nd.BilinearSampler(data, grid)
输出
输出如下所示:
[[[[5. 3. 6. 0.] [8. 7. 9. 0.] [4. 1. 8. 0.] [0. 3. 4. 0.]]]] <NDArray 1x1x4x4 @cpu(0)>
类似地,以下示例显示了cast()函数的使用:
nd.cast(nd.array([300, 10.1, 15.4, -1, -2]), dtype='uint8')
输出
执行后,您将收到以下输出:
[ 44 10 15 255 254] <NDArray 5 @cpu(0)>
ndarray.contrib
Contrib NDArray API在ndarray.contrib包中定义。它通常为新功能提供许多有用的实验性API。此API作为社区尝试新功能的地方。特性贡献者也将获得反馈。
函数及其参数
以下是mxnet.ndarray.contrib API涵盖的一些重要函数及其参数:
| 函数及其参数 | 定义 |
|---|---|
| rand_zipfian(true_classes, num_sampled, …) | 此函数从近似齐夫分布中抽取随机样本。此函数的基本分布是齐夫分布。此函数随机抽取num_sampled个候选样本,并且sampled_candidates的元素是从上面给出的基本分布中抽取的。 |
| foreach(body, data, init_states) | 顾名思义,此函数在维度0上对NDArrays运行带有用户定义计算的for循环。此函数模拟for循环,body具有for循环迭代的计算。 |
| while_loop(cond, func, loop_vars[, …]) | 顾名思义,此函数运行带有用户定义计算和循环条件的while循环。此函数模拟一个while循环,如果条件满足,则逐字进行自定义计算。 |
| cond(pred, then_func, else_func) | 顾名思义,此函数使用用户定义的条件和计算运行if-then-else。此函数模拟一个if类型的分支,根据指定的条件选择执行两个自定义计算中的一个。 |
| isinf(data) | 此函数执行逐元素检查以确定NDArray是否包含无限元素。 |
| getnnz([data, axis, out, name]) | 此函数为我们提供稀疏张量的存储值的个数。它还包括显式零。它只支持CPU上的CSR矩阵。 |
| requantize([data, min_range, max_range, …]) | 此函数将以int32量化并具有相应阈值的数据重新量化为int8,使用在运行时计算或来自校准的最小和最大阈值。 |
实现示例
在下面的示例中,我们将使用rand_zipfian函数从近似齐夫分布中抽取随机样本:
import mxnet as mx from mxnet import nd trueclass = mx.nd.array([2]) samples, exp_count_true, exp_count_sample = mx.nd.contrib.rand_zipfian(trueclass, 3, 4) samples
输出
您将看到以下输出:
[0 0 1] <NDArray 3 @cpu(0)>
示例
exp_count_true
输出
输出如下所示
[0.53624076] <NDArray 1 @cpu(0)>
示例
exp_count_sample
输出
这将产生以下输出
[1.29202967 1.29202967 0.75578891] <NDArray 3 @cpu(0)>
在下面的示例中,我们将使用while_loop函数运行用户定义计算和循环条件的while循环
cond = lambda i, s: i <= 7 func = lambda i, s: ([i + s], [i + 1, s + i]) loop_var = (mx.nd.array([0], dtype="int64"), mx.nd.array([1], dtype="int64")) outputs, states = mx.nd.contrib.while_loop(cond, func, loop_vars, max_iterations=10) outputs
输出
输出如下所示:
[ [[ 1] [ 2] [ 4] [ 7] [ 11] [ 16] [ 22] [ 29] [3152434450384] [ 257]] <NDArray 10x1 @cpu(0)>]
示例
States
输出
这将产生以下输出:
[ [8] <NDArray 1 @cpu(0)>, [29] <NDArray 1 @cpu(0)>]
ndarray.image
Image NDArray API在ndarray.image包中定义。顾名思义,它通常用于图像及其特征。
函数及其参数
以下是mxnet.ndarray.image API涵盖的一些重要函数及其参数:
| 函数及其参数 | 定义 |
|---|---|
| adjust_lighting([data, alpha, out, name]) | 顾名思义,此函数调整输入的光照级别。它遵循AlexNet样式。 |
| crop([data, x, y, width, height, out, name]) | 借助此函数,我们可以将形状为(H x W x C)或(N x H x W x C)的图像NDArray裁剪为用户指定的大小。 |
| normalize([data, mean, std, out, name]) | 它将使用均值和标准差(SD)对形状为(C x H x W)或(N x C x H x W)的张量进行归一化。 |
| random_crop([data, xrange, yrange, width, …]) | 与crop()类似,它会随机裁剪形状为(H x W x C)或(N x H x W x C)的图像NDArray到用户指定的大小。如果src小于该大小,它将对结果进行上采样。 |
| random_lighting([data, alpha_std, out, name]) | 顾名思义,此函数会随机添加PCA噪声。它也遵循AlexNet样式。 |
| random_resized_crop([data, xrange, yrange, …]) | 它还会随机裁剪形状为(H x W x C)或(N x H x W x C)的图像NDArray到指定的大小。如果src小于该大小,它将对结果进行上采样。它还将随机化区域和纵横比。 |
| resize([data, size, keep_ratio, interp, …]) | 顾名思义,此函数将调整形状为 (H x W x C) 或 (N x H x W x C) 的图像 NDArray 的大小到用户指定的大小。 |
| to_tensor([data, out, name]) | 它将形状为 (H x W x C) 或 (N x H x W x C) 且值在 [0, 255] 范围内的图像 NDArray 转换为形状为 (C x H x W) 或 (N x C x H x W) 且值在 [0, 1] 范围内的张量 NDArray。 |
实现示例
在下面的示例中,我们将使用 to_tensor 函数将形状为 (H x W x C) 或 (N x H x W x C) 且值在 [0, 255] 范围内的图像 NDArray 转换为形状为 (C x H x W) 或 (N x C x H x W) 且值在 [0, 1] 范围内的张量 NDArray。
import numpy as np img = mx.nd.random.uniform(0, 255, (4, 2, 3)).astype(dtype=np.uint8) mx.nd.image.to_tensor(img)
输出
您将看到以下输出:
[[[0.972549 0.5058824 ] [0.6039216 0.01960784] [0.28235295 0.35686275] [0.11764706 0.8784314 ]] [[0.8745098 0.9764706 ] [0.4509804 0.03529412] [0.9764706 0.29411766] [0.6862745 0.4117647 ]] [[0.46666667 0.05490196] [0.7372549 0.4392157 ] [0.11764706 0.47843137] [0.31764707 0.91764706]]] <NDArray 3x4x2 @cpu(0)>
示例
img = mx.nd.random.uniform(0, 255, (2, 4, 2, 3)).astype(dtype=np.uint8) mx.nd.image.to_tensor(img)
输出
运行代码后,您将看到以下输出:
[[[[0.0627451 0.5647059 ] [0.2627451 0.9137255 ] [0.57254905 0.27450982] [0.6666667 0.64705884]] [[0.21568628 0.5647059 ] [0.5058824 0.09019608] [0.08235294 0.31764707] [0.8392157 0.7137255 ]] [[0.6901961 0.8627451 ] [0.52156866 0.91764706] [0.9254902 0.00784314] [0.12941177 0.8392157 ]]] [[[0.28627452 0.39607844] [0.01960784 0.36862746] [0.6745098 0.7019608 ] [0.9607843 0.7529412 ]] [[0.2627451 0.58431375] [0.16470589 0.00392157] [0.5686275 0.73333335] [0.43137255 0.57254905]] [[0.18039216 0.54901963] [0.827451 0.14509805] [0.26666668 0.28627452] [0.24705882 0.39607844]]]] <NDArgt;ray 2x3x4x2 @cpu(0)>
在下面的示例中,我们将使用normalize函数对形状为 (C x H x W) 或 (N x C x H x W) 、具有均值和标准差 (SD)的张量进行标准化。
img = mx.nd.random.uniform(0, 1, (3, 4, 2)) mx.nd.image.normalize(img, mean=(0, 1, 2), std=(3, 2, 1))
输出
这将产生以下输出:
[[[ 0.29391178 0.3218054 ] [ 0.23084386 0.19615503] [ 0.24175143 0.21988946] [ 0.16710812 0.1777354 ]] [[-0.02195817 -0.3847335 ] [-0.17800489 -0.30256534] [-0.28807247 -0.19059572] [-0.19680339 -0.26256624]] [[-1.9808068 -1.5298678 ] [-1.6984252 -1.2839255 ] [-1.3398265 -1.712009 ] [-1.7099224 -1.6165378 ]]] <NDArray 3x4x2 @cpu(0)>
示例
img = mx.nd.random.uniform(0, 1, (2, 3, 4, 2)) mx.nd.image.normalize(img, mean=(0, 1, 2), std=(3, 2, 1))
输出
执行上述代码后,您应该看到以下输出:
[[[[ 2.0600514e-01 2.4972327e-01] [ 1.4292289e-01 2.9281738e-01] [ 4.5158025e-02 3.4287784e-02] [ 9.9427439e-02 3.0791296e-02]] [[-2.1501756e-01 -3.2297665e-01] [-2.0456362e-01 -2.2409186e-01] [-2.1283737e-01 -4.8318747e-01] [-1.7339960e-01 -1.5519112e-02]] [[-1.3478968e+00 -1.6790028e+00] [-1.5685816e+00 -1.7787373e+00] [-1.1034534e+00 -1.8587360e+00] [-1.6324382e+00 -1.9027401e+00]]] [[[ 1.4528830e-01 3.2801408e-01] [ 2.9730779e-01 8.6780310e-02] [ 2.6873133e-01 1.7900752e-01] [ 2.3462953e-01 1.4930873e-01]] [[-4.4988656e-01 -4.5021546e-01] [-4.0258706e-02 -3.2384416e-01] [-1.4287934e-01 -2.6537544e-01] [-5.7649612e-04 -7.9429924e-02]] [[-1.8505517e+00 -1.0953522e+00] [-1.1318740e+00 -1.9624406e+00] [-1.8375070e+00 -1.4916846e+00] [-1.3844404e+00 -1.8331525e+00]]]] <NDArray 2x3x4x2 @cpu(0)>
ndarray.random
随机 NDArray API 定义在 ndarray.random 包中。顾名思义,它是 MXNet 的随机分布生成器 NDArray API。
函数及其参数
以下是mxnet.ndarray.random API涵盖的一些重要函数及其参数:
| 函数及其参数 | 定义 |
|---|---|
| uniform([low, high, shape, dtype, ctx, out]) | 它从均匀分布中生成随机样本。 |
| normal([loc, scale, shape, dtype, ctx, out]) | 它从正态 (高斯) 分布中生成随机样本。 |
| randn(*shape, **kwargs) | 它从正态 (高斯) 分布中生成随机样本。 |
| exponential([scale, shape, dtype, ctx, out]) | 它从指数分布中生成样本。 |
| gamma([alpha, beta, shape, dtype, ctx, out]) | 它从伽马分布中生成随机样本。 |
| multinomial(data[, shape, get_prob, out, dtype]) | 它从多个多项分布中生成并发采样。 |
| negative_binomial([k, p, shape, dtype, ctx, out]) | 它从负二项分布中生成随机样本。 |
| generalized_negative_binomial([mu, alpha, …]) | 它从广义负二项分布中生成随机样本。 |
| shuffle(data, **kwargs) | 它随机打乱元素。 |
| randint(low, high[, shape, dtype, ctx, out]) | 它从离散均匀分布中生成随机样本。 |
| exponential_like([data, lam, out, name]) | 它根据输入数组形状从指数分布中生成随机样本。 |
| gamma_like([data, alpha, beta, out, name]) | 它根据输入数组形状从伽马分布中生成随机样本。 |
| generalized_negative_binomial_like([data, …]) | 它根据输入数组形状从广义负二项分布中生成随机样本。 |
| negative_binomial_like([data, k, p, out, name]) | 它根据输入数组形状从负二项分布中生成随机样本。 |
| normal_like([data, loc, scale, out, name]) | 它根据输入数组形状从正态 (高斯) 分布中生成随机样本。 |
| poisson_like([data, lam, out, name]) | 它根据输入数组形状从泊松分布中生成随机样本。 |
| uniform_like([data, low, high, out, name]) | 它根据输入数组形状从均匀分布中生成随机样本。 |
实现示例
在下面的示例中,我们将从均匀分布中抽取随机样本。为此,我们将使用uniform()函数。
mx.nd.random.uniform(0, 1)
输出
输出如下所示:
[0.12381998] <NDArray 1 @cpu(0)>
示例
mx.nd.random.uniform(-1, 1, shape=(2,))
输出
输出如下所示:
[0.558102 0.69601643] <NDArray 2 @cpu(0)>
示例
low = mx.nd.array([1,2,3]) high = mx.nd.array([2,3,4]) mx.nd.random.uniform(low, high, shape=2)
输出
您将看到以下输出:
[[1.8649333 1.8073189] [2.4113967 2.5691009] [3.1399727 3.4071832]] <NDArray 3x2 @cpu(0)>
在下面的示例中,我们将从广义负二项分布中抽取随机样本。为此,我们将使用generalized_negative_binomial()函数。
mx.nd.random.generalized_negative_binomial(10, 0.5)
输出
执行上述代码后,您应该看到以下输出:
[1.] <NDArray 1 @cpu(0)>
示例
mx.nd.random.generalized_negative_binomial(10, 0.5, shape=(2,))
输出
输出如下所示:
[16. 23.] <NDArray 2 @cpu(0)>
示例
mu = mx.nd.array([1,2,3]) alpha = mx.nd.array([0.2,0.4,0.6]) mx.nd.random.generalized_negative_binomial(mu, alpha, shape=2)
输出
以下是代码的输出:
[[0. 0.] [4. 1.] [9. 3.]] <NDArray 3x2 @cpu(0)>
ndarray.utils
实用程序 NDArray API 定义在 ndarray.utils 包中。顾名思义,它为 NDArray 和 BaseSparseNDArray 提供实用程序函数。
函数及其参数
以下是mxnet.ndarray.utils API涵盖的一些重要函数及其参数:
| 函数及其参数 | 定义 |
|---|---|
| zeros(shape[, ctx, dtype, stype]) | 此函数将返回一个具有给定形状和类型的新数组,其中填充为零。 |
| empty(shape[, ctx, dtype, stype]) | 它将返回一个具有给定形状和类型的新数组,但不初始化条目。 |
| array(source_array[, ctx, dtype]) | 顾名思义,此函数将从任何公开数组接口的对象创建一个数组。 |
| load(fname) | 它将从文件中加载一个数组。 |
| load_frombuffer(buf) | 顾名思义,此函数将从缓冲区加载数组字典或列表。 |
| save(fname, data) | 此函数将数组列表或 str->array 字典保存到文件中。 |
实现示例
在下面的示例中,我们将返回一个具有给定形状和类型的新数组,其中填充为零。为此,我们将使用zeros()函数。
mx.nd.zeros((1,2), mx.cpu(), stype='csr')
输出
这将产生以下输出:
<CSRNDArray 1x2 @cpu(0)>
示例
mx.nd.zeros((1,2), mx.cpu(), 'float16', stype='row_sparse').asnumpy()
输出
您将收到以下输出:
array([[0., 0.]], dtype=float16)
在下面的示例中,我们将保存一个数组列表和一个字符串字典。为此,我们将使用save()函数。
示例
x = mx.nd.zeros((2,3))
y = mx.nd.ones((1,4))
mx.nd.save('list', [x,y])
mx.nd.save('dict', {'x':x, 'y':y})
mx.nd.load('list')
输出
执行后,您将收到以下输出:
[ [[0. 0. 0.] [0. 0. 0.]] <NDArray 2x3 @cpu(0)>, [[1. 1. 1. 1.]] <NDArray 1x4 @cpu(0)>]
示例
mx.nd.load('my_dict')
输出
输出如下所示:
{'x':
[[0. 0. 0.]
[0. 0. 0.]]
<NDArray 2x3 @cpu(0)>, 'y':
[[1. 1. 1. 1.]]
<NDArray 1x4 @cpu(0)>}
Apache MXNet - Python API gluon
正如我们在前面章节中讨论的那样,MXNet Gluon 为深度学习项目提供了一个清晰、简洁和简单的 API。它使 Apache MXNet 能够在不牺牲训练速度的情况下对深度学习模型进行原型设计、构建和训练。
核心模块
让我们学习 Apache MXNet Python 应用程序编程接口 (API) gluon 的核心模块。
gluon.nn
Gluon 在 gluon.nn 模块中提供了大量的内置 NN 层。这就是它被称为核心模块的原因。
方法及其参数
以下是mxnet.gluon.nn核心模块涵盖的一些重要方法及其参数:
| 方法及其参数 | 定义 |
|---|---|
| Activation(activation, **kwargs) | 顾名思义,此方法将激活函数应用于输入。 |
| AvgPool1D([pool_size, strides, padding, …]) | 这是用于时间数据的平均池化操作。 |
| AvgPool2D([pool_size, strides, padding, …]) | 这是用于空间数据的平均池化操作。 |
| AvgPool3D([pool_size, strides, padding, …]) | 这是用于 3D 数据的平均池化操作。数据可以是空间的或时空的。 |
| BatchNorm([axis, momentum, epsilon, center, …]) | 它表示批量归一化层。 |
| BatchNormReLU([axis, momentum, epsilon, …]) | 它也表示批量归一化层,但具有 Relu 激活函数。 |
| Block([prefix, params]) | 它为所有神经网络层和模型提供基类。 |
| Conv1D(channels, kernel_size[, strides, …]) | 此方法用于一维卷积层。例如,时间卷积。 |
| Conv1DTranspose(channels, kernel_size[, …]) | 此方法用于转置一维卷积层。 |
| Conv2D(channels, kernel_size[, strides, …]) | 此方法用于二维卷积层。例如,图像上的空间卷积。 |
| Conv2DTranspose(channels, kernel_size[, …]) | 此方法用于转置二维卷积层。 |
| Conv3D(channels, kernel_size[, strides, …]) | 此方法用于三维卷积层。例如,体积上的空间卷积。 |
| Conv3DTranspose(channels, kernel_size[, …]) | 此方法用于转置三维卷积层。 |
| Dense(units[, activation, use_bias, …]) | 此方法表示常规密集连接的 NN 层。 |
| Dropout(rate[, axes]) | 顾名思义,此方法将 Dropout 应用于输入。 |
| ELU([alpha]) | 此方法用于指数线性单元 (ELU)。 |
| Embedding(input_dim, output_dim[, dtype, …]) | 它将非负整数转换为固定大小的密集向量。 |
| Flatten(**kwargs) | 此方法将输入展平为二维。 |
| GELU(**kwargs) | 此方法用于高斯指数线性单元 (GELU)。 |
| GlobalAvgPool1D([layout]) | 借助此方法,我们可以对时间数据进行全局平均池化操作。 |
| GlobalAvgPool2D([layout]) | 借助此方法,我们可以对空间数据进行全局平均池化操作。 |
| GlobalAvgPool3D([layout]) | 借助此方法,我们可以对 3D 数据进行全局平均池化操作。 |
| GlobalMaxPool1D([layout]) | 借助此方法,我们可以对一维数据进行全局最大池化操作。 |
| GlobalMaxPool2D([layout]) | 借助此方法,我们可以对二维数据进行全局最大池化操作。 |
| GlobalMaxPool3D([layout]) | 借助此方法,我们可以对三维数据进行全局最大池化操作。 |
| GroupNorm([num_groups, epsilon, center, …]) | 此方法将组归一化应用于 n 维输入数组。 |
| HybridBlock([prefix, params]) | 此方法支持使用Symbol和NDArray进行前向传播。 |
| HybridLambda(function[, prefix]) | 借助此方法,我们可以将运算符或表达式包装为 HybridBlock 对象。 |
| HybridSequential([prefix, params]) | 它按顺序堆叠 HybridBlocks。 |
| InstanceNorm([axis, epsilon, center, scale, …]) | 此方法将实例归一化应用于 n 维输入数组。 |
实现示例
在下面的示例中,我们将使用 Block(),它为所有神经网络层和模型提供基类。
from mxnet.gluon import Block, nn
class Model(Block):
def __init__(self, **kwargs):
super(Model, self).__init__(**kwargs)
# use name_scope to give child Blocks appropriate names.
with self.name_scope():
self.dense0 = nn.Dense(20)
self.dense1 = nn.Dense(20)
def forward(self, x):
x = mx.nd.relu(self.dense0(x))
return mx.nd.relu(self.dense1(x))
model = Model()
model.initialize(ctx=mx.cpu(0))
model(mx.nd.zeros((5, 5), ctx=mx.cpu(0)))
输出
您将看到以下输出:
[[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]] <NDArray 5x20 @cpu(0)*gt;
在下面的示例中,我们将使用 HybridBlock(),它支持使用 Symbol 和 NDArray 进行前向传播。
import mxnet as mx
from mxnet.gluon import HybridBlock, nn
class Model(HybridBlock):
def __init__(self, **kwargs):
super(Model, self).__init__(**kwargs)
# use name_scope to give child Blocks appropriate names.
with self.name_scope():
self.dense0 = nn.Dense(20)
self.dense1 = nn.Dense(20)
def forward(self, x):
x = nd.relu(self.dense0(x))
return nd.relu(self.dense1(x))
model = Model()
model.initialize(ctx=mx.cpu(0))
model.hybridize()
model(mx.nd.zeros((5, 5), ctx=mx.cpu(0)))
输出
输出如下所示:
[[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]] <NDArray 5x20 @cpu(0)>
gluon.rnn
Gluon 在 gluon.rnn 模块中提供了大量的内置循环神经网络 (RNN) 层。这就是它被称为核心模块的原因。
方法及其参数
以下是mxnet.gluon.nn核心模块涵盖的一些重要方法及其参数:
| 方法及其参数 | 定义 |
|---|---|
| BidirectionalCell(l_cell, r_cell[, …]) | 它用于双向循环神经网络 (RNN) 单元。 |
| DropoutCell(rate[, axes, prefix, params]) | 此方法将对给定输入应用 dropout。 |
| GRU(hidden_size[, num_layers, layout, …]) | 它将多层门控循环单元 (GRU) RNN 应用于给定的输入序列。 |
| GRUCell(hidden_size[, …]) | 它用于门控整流单元 (GRU) 网络单元。 |
| HybridRecurrentCell([prefix, params]) | 此方法支持混合。 |
| HybridSequentialRNNCell([prefix, params]) | 借助此方法,我们可以顺序堆叠多个 HybridRNN 单元。 |
| LSTM(hidden_size[, num_layers, layout, …])0 | 它将多层长短期记忆 (LSTM) RNN 应用于给定的输入序列。 |
| LSTMCell(hidden_size[, …]) | 它用于长短期记忆 (LSTM) 网络单元。 |
| ModifierCell(base_cell) | 它是修饰符单元的基类。 |
| RNN(hidden_size[, num_layers, activation, …]) | 它将具有tanh或ReLU非线性的多层 Elman RNN 应用于给定的输入序列。 |
| RNNCell(hidden_size[, activation, …]) | 它用于 Elman RNN 循环神经网络单元。 |
| RecurrentCell([prefix, params]) | 它表示 RNN 单元的抽象基类。 |
| SequentialRNNCell([prefix, params]) | 借助此方法,我们可以顺序堆叠多个 RNN 单元。 |
| ZoneoutCell(base_cell[, zoneout_outputs, …]) | 此方法将 Zoneout 应用于基单元。 |
实现示例
在下面的示例中,我们将使用 GRU(),它将多层门控循环单元 (GRU) RNN 应用于给定的输入序列。
layer = mx.gluon.rnn.GRU(100, 3) layer.initialize() input_seq = mx.nd.random.uniform(shape=(5, 3, 10)) out_seq = layer(input_seq) h0 = mx.nd.random.uniform(shape=(3, 3, 100)) out_seq, hn = layer(input_seq, h0) out_seq
输出
这将产生以下输出:
[[[ 1.50152072e-01 5.19012511e-01 1.02390535e-01 ... 4.35803324e-01 1.30406499e-01 3.30152437e-02] [ 2.91542172e-01 1.02243155e-01 1.73325196e-01 ... 5.65296151e-02 1.76546033e-02 1.66693389e-01] [ 2.22257316e-01 3.76294643e-01 2.11277917e-01 ... 2.28903517e-01 3.43954474e-01 1.52770668e-01]] [[ 1.40634328e-01 2.93247789e-01 5.50393537e-02 ... 2.30207980e-01 6.61415309e-02 2.70989928e-02] [ 1.11081995e-01 7.20834285e-02 1.08342394e-01 ... 2.28330195e-02 6.79589901e-03 1.25501186e-01] [ 1.15944080e-01 2.41565228e-01 1.18612610e-01 ... 1.14908054e-01 1.61080107e-01 1.15969211e-01]] ………………………….
示例
hn
输出
这将产生以下输出:
[[[-6.08105101e-02 3.86217088e-02 6.64453954e-03 8.18805695e-02 3.85607071e-02 -1.36945639e-02 7.45836645e-03 -5.46515081e-03 9.49622393e-02 6.39371723e-02 -6.37890724e-03 3.82240303e-02 9.11015049e-02 -2.01375950e-02 -7.29381144e-02 6.93765879e-02 2.71829776e-02 -6.64435029e-02 -8.45306814e-02 -1.03075653e-01 6.72040805e-02 -7.06537142e-02 -3.93818803e-02 5.16211614e-03 -4.79770005e-02 1.10734522e-01 1.56721435e-02 -6.93409378e-03 1.16915874e-01 -7.95962065e-02 -3.06530762e-02 8.42394680e-02 7.60370195e-02 2.17055440e-01 9.85361822e-03 1.16660878e-01 4.08297703e-02 1.24978097e-02 8.25245082e-02 2.28673983e-02 -7.88266212e-02 -8.04114193e-02 9.28791538e-02 -5.70827350e-03 -4.46166918e-02 -6.41122833e-02 1.80885363e-02 -2.37745279e-03 4.37298454e-02 1.28888980e-01 -3.07202265e-02 2.50503756e-02 4.00907174e-02 3.37077095e-03 -1.78839862e-02 8.90695080e-02 6.30150884e-02 1.11416787e-01 2.12221760e-02 -1.13236710e-01 5.39616570e-02 7.80710578e-02 -2.28817668e-02 1.92073174e-02 ………………………….
下面的例子中,我们将使用 LSTM(),它将长短期记忆 (LSTM) RNN 应用于给定的输入序列。
layer = mx.gluon.rnn.LSTM(100, 3) layer.initialize() input_seq = mx.nd.random.uniform(shape=(5, 3, 10)) out_seq = layer(input_seq) h0 = mx.nd.random.uniform(shape=(3, 3, 100)) c0 = mx.nd.random.uniform(shape=(3, 3, 100)) out_seq, hn = layer(input_seq,[h0,c0]) out_seq
输出
输出如下所示:
[[[ 9.00025964e-02 3.96071747e-02 1.83841765e-01 ... 3.95872220e-02 1.25569820e-01 2.15555862e-01] [ 1.55962542e-01 -3.10300849e-02 1.76772922e-01 ... 1.92474753e-01 2.30574399e-01 2.81707942e-02] [ 7.83204585e-02 6.53361529e-03 1.27262697e-01 ... 9.97719541e-02 1.28254429e-01 7.55299702e-02]] [[ 4.41036932e-02 1.35250352e-02 9.87644792e-02 ... 5.89378644e-03 5.23949116e-02 1.00922674e-01] [ 8.59075040e-02 -1.67027581e-02 9.69351009e-02 ... 1.17763653e-01 9.71239135e-02 2.25218050e-02] [ 4.34580036e-02 7.62207608e-04 6.37005866e-02 ... 6.14888743e-02 5.96345589e-02 4.72368896e-02]] ……………
示例
hn
输出
运行代码后,您将看到以下输出:
[ [[[ 2.21408084e-02 1.42750628e-02 9.53067932e-03 -1.22849066e-02 1.78788435e-02 5.99269159e-02 5.65306023e-02 6.42553642e-02 6.56616641e-03 9.80876666e-03 -1.15729487e-02 5.98640442e-02 -7.21173314e-03 -2.78371759e-02 -1.90690923e-02 2.21447181e-02 8.38765781e-03 -1.38521893e-02 -9.06938594e-03 1.21346042e-02 6.06449470e-02 -3.77471633e-02 5.65885007e-02 6.63008019e-02 -7.34188128e-03 6.46054149e-02 3.19911093e-02 4.11194898e-02 4.43960279e-02 4.92892228e-02 1.74766723e-02 3.40303481e-02 -5.23341820e-03 2.68163737e-02 -9.43402853e-03 -4.11836170e-02 1.55221792e-02 -5.05655073e-02 4.24557598e-03 -3.40388380e-02 ……………………
训练模块
Gluon 中的训练模块如下:
gluon.loss
在 **mxnet.gluon.loss** 模块中,Gluon 提供了预定义的损失函数。基本上,它包含用于训练神经网络的损失函数。这就是它被称为训练模块的原因。
方法及其参数
以下是 **mxnet.gluon.loss** 训练模块涵盖的一些重要方法及其参数
| 方法及其参数 | 定义 |
|---|---|
| Loss(weight, batch_axis, **kwargs) | 这是损失函数的基类。 |
| L2Loss([weight, batch_axis]) | 它计算 **标签 (label)** 和 **预测 (prediction/pred)** 之间的均方误差 (MSE)。 |
| L1Loss([weight, batch_axis]) | 它计算 **标签 (label)** 和 **pred** 之间的平均绝对误差 (MAE)。 |
| SigmoidBinaryCrossEntropyLoss([…]) | 此方法用于二元分类的交叉熵损失。 |
| SigmoidBCELoss | 此方法用于二元分类的交叉熵损失。 |
| SoftmaxCrossEntropyLoss([axis, …]) | 它计算 softmax 交叉熵损失 (CEL)。 |
| SoftmaxCELoss | 它也计算 softmax 交叉熵损失。 |
| KLDivLoss([from_logits, axis, weight, …]) | 它用于 Kullback-Leibler 散度损失。 |
| CTCLoss([layout, label_layout, weight]) | 它用于连接性时间分类损失 (TCL)。 |
| HuberLoss([rho, weight, batch_axis]) | 它计算平滑的 L1 损失。如果绝对误差超过 rho,则平滑的 L1 损失等于 L1 损失;否则等于 L2 损失。 |
| HingeLoss([margin, weight, batch_axis]) | 此方法计算常用于 SVM 的 Hinge 损失函数。 |
| SquaredHingeLoss([margin, weight, batch_axis]) | 此方法计算用于 SVM 的软间隔损失函数。 |
| LogisticLoss([weight, batch_axis, label_format]) | 此方法计算逻辑损失。 |
| TripletLoss([margin, weight, batch_axis]) | 此方法给定三个输入张量和一个正边距,计算三元组损失。 |
| PoissonNLLLoss([weight, from_logits, …]) | 该函数计算负对数似然损失。 |
| CosineEmbeddingLoss([weight, batch_axis, margin]) | 该函数计算向量之间的余弦距离。 |
| SDMLLoss([smoothing_parameter, weight, …]) | 此方法给定两个输入张量和一个平滑权重 SDM 损失,计算批量平滑深度度量学习 (SDML) 损失。它通过使用小批量中的非配对样本作为潜在的负样本,学习配对样本之间的相似性。 |
示例
众所周知,**mxnet.gluon.loss.loss** 将计算标签和预测 (pred) 之间的 MSE(均方误差)。这是通过以下公式完成的
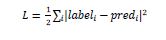
gluon.parameter
**mxnet.gluon.parameter** 是一个容器,它保存块的参数,即权重。
方法及其参数
以下是 **mxnet.gluon.parameter** 训练模块涵盖的一些重要方法及其参数:
| 方法及其参数 | 定义 |
|---|---|
| cast(dtype) | 此方法将把此参数的数据和梯度转换为新的数据类型。 |
| data([ctx]) | 此方法将返回此参数在一个上下文上的副本。 |
| grad([ctx]) | 此方法将返回此参数在一个上下文上的梯度缓冲区。 |
| initialize([init, ctx, default_init, …]) | 此方法将初始化参数和梯度数组。 |
| list_ctx() | 此方法将返回此参数已在其上初始化的上下文列表。 |
| list_data() | 此方法将返回此参数在所有上下文上的副本。这将按照创建顺序进行。 |
| list_grad() | 此方法将返回所有上下文上的梯度缓冲区。这将按照与 **values()** 相同的顺序进行。 |
| list_row_sparse_data(row_id) | 此方法将返回“row_sparse”参数在所有上下文上的副本。这将按照创建顺序进行。 |
| reset_ctx(ctx) | 此方法将参数重新分配到其他上下文。 |
| row_sparse_data(row_id) | 此方法将返回“row_sparse”参数与 row_id 相同上下文上的副本。 |
| set_data(data) | 此方法将设置此参数在所有上下文上的值。 |
| var() | 此方法将返回表示此参数的符号。 |
| zero_grad() | 此方法将把所有上下文上的梯度缓冲区设置为 0。 |
实现示例
在下面的例子中,我们将使用 initialize() 方法初始化参数和梯度数组,如下所示:
weight = mx.gluon.Parameter('weight', shape=(2, 2))
weight.initialize(ctx=mx.cpu(0))
weight.data()
输出
输出如下所示:
[[-0.0256899 0.06511251] [-0.00243821 -0.00123186]] <NDArray 2x2 @cpu(0)>
示例
weight.grad()
输出
输出如下所示:
[[0. 0.] [0. 0.]] <NDArray 2x2 @cpu(0)>
示例
weight.initialize(ctx=[mx.gpu(0), mx.gpu(1)]) weight.data(mx.gpu(0))
输出
您将看到以下输出:
[[-0.00873779 -0.02834515] [ 0.05484822 -0.06206018]] <NDArray 2x2 @gpu(0)>
示例
weight.data(mx.gpu(1))
输出
执行上述代码后,您应该看到以下输出:
[[-0.00873779 -0.02834515] [ 0.05484822 -0.06206018]] <NDArray 2x2 @gpu(1)>
gluon.trainer
mxnet.gluon.trainer 将优化器应用于一组参数。它应该与 autograd 一起使用。
方法及其参数
以下是 **mxnet.gluon.trainer** 训练模块涵盖的一些重要方法及其参数:
| 方法及其参数 | 定义 |
|---|---|
| allreduce_grads() | 此方法将减少每个参数(权重)的不同上下文中的梯度。 |
| load_states(fname) | 顾名思义,此方法将加载训练器状态。 |
| save_states(fname) | 顾名思义,此方法将保存训练器状态。 |
| set_learning_rate(lr) | 此方法将设置优化器的新学习率。 |
| step(batch_size[, ignore_stale_grad]) | 此方法将进行一步参数更新。它应该在 **autograd.backward()** 之后和 **record()** 作用域之外调用。 |
| update(batch_size[, ignore_stale_grad]) | 此方法也将进行一步参数更新。它应该在 **autograd.backward()** 之后和 **record()** 作用域之外调用,以及在 trainer.update() 之后。 |
数据模块
Gluon 的数据模块解释如下:
gluon.data
Gluon 在 gluon.data 模块中提供了大量的内置数据集实用程序。这就是它被称为数据模块的原因。
类及其参数
以下是 mxnet.gluon.data 核心模块涵盖的一些重要方法及其参数。这些方法通常与数据集、采样和 DataLoader 相关。
| 方法及其参数 | 定义 |
|---|---|
| ArrayDataset(*args) | 此方法表示一个数据集,它组合了两个或多个数据集状对象。例如,数据集、列表、数组等。 |
| BatchSampler(sampler, batch_size[, last_batch]) | 此方法包装另一个 **Sampler**。包装后,它返回样本的小批量。 |
| DataLoader(dataset[, batch_size, shuffle, …]) | 类似于 BatchSampler,但此方法从数据集中加载数据。加载后,它返回数据的小批量。 |
| 这表示抽象数据集类。 | |
| FilterSampler(fn, dataset) | 此方法表示来自数据集的样本元素,对于这些元素,fn(函数)返回 **True**。 |
| RandomSampler(length) | 此方法表示从 [0, length) 中随机抽取样本元素,不放回。 |
| RecordFileDataset(filename) | 它表示一个包装 RecordIO 文件的数据集。文件的扩展名为 **.rec**。 |
| Sampler | 这是采样器的基类。 |
| SequentialSampler(length[, start]) | 它表示按顺序从集合 [start, start+length) 中抽取样本元素。 |
| 它表示按顺序从集合 [start, start+length) 中抽取样本元素。 | 这表示简单的数据集包装器,尤其适用于列表和数组。 |
实现示例
在下面的例子中,我们将使用 **gluon.data.BatchSampler()** API,它包装另一个采样器。它返回样本的小批量。
import mxnet as mx from mxnet.gluon import data sampler = mx.gluon.data.SequentialSampler(15) batch_sampler = mx.gluon.data.BatchSampler(sampler, 4, 'keep') list(batch_sampler)
输出
输出如下所示:
[[0, 1, 2, 3], [4, 5, 6, 7], [8, 9, 10, 11], [12, 13, 14]]
gluon.data.vision.datasets
Gluon 在 **gluon.data.vision.datasets** 模块中提供了大量预定义的视觉数据集函数。
类及其参数
MXNet 为我们提供了有用且重要的数据集,其类和参数如下所示:
| 类及其参数 | 定义 |
|---|---|
| MNIST([root, train, transform]) | 这是一个有用的数据集,它为我们提供了手写数字。MNIST 数据集的网址是 http://yann.lecun.com/exdb/mnist |
| FashionMNIST([root, train, transform]) | 此数据集包含 Zalando 的文章图像,其中包含时尚产品。它是原始 MNIST 数据集的直接替代品。您可以从 https://github.com/zalandoresearch/fashion-mnist 获取此数据集 |
| CIFAR10([root, train, transform]) | 这是一个来自 https://www.cs.toronto.edu/~kriz/cifar.html 的图像分类数据集。在此数据集中,每个样本都是形状为 (32, 32, 3) 的图像。 |
| CIFAR100([root, fine_label, train, transform]) | 这是一个来自 https://www.cs.toronto.edu/~kriz/cifar.html 的 CIFAR100 图像分类数据集。它也包含每个样本都是形状为 (32, 32, 3) 的图像。 |
| ImageRecordDataset (filename[, flag, transform]) | 此数据集包装了一个包含图像的 RecordIO 文件。在此文件中,每个样本都是一个图像及其对应的标签。 |
| ImageFolderDataset (root[, flag, transform]) | 这是一个用于加载存储在文件夹结构中的图像文件的数据集。 |
| ImageListDataset ([root, imglist, flag]) | 这是一个用于加载由条目列表指定的图像文件的数据集。 |
示例
在下面的例子中,我们将展示 ImageListDataset() 的用法,它用于加载由条目列表指定的图像文件:
# written to text file *.lst 0 0 root/cat/0001.jpg 1 0 root/cat/xxxa.jpg 2 0 root/cat/yyyb.jpg 3 1 root/dog/123.jpg 4 1 root/dog/023.jpg 5 1 root/dog/wwww.jpg # A pure list, each item is a list [imagelabel: float or list of float, imgpath] [[0, root/cat/0001.jpg] [0, root/cat/xxxa.jpg] [0, root/cat/yyyb.jpg] [1, root/dog/123.jpg] [1, root/dog/023.jpg] [1, root/dog/wwww.jpg]]
实用程序模块
Gluon 中的实用程序模块如下:
gluon.utils
Gluon 在 gluon.utils 模块中提供了大量的内置并行化实用程序优化器。它提供了各种用于训练的实用程序。这就是它被称为实用程序模块的原因。
函数及其参数
以下是此名为 **gluon.utils** 的实用程序模块中包含的函数及其参数:
| 函数及其参数 | 定义 |
|---|---|
| split_data(data, num_slice[, batch_axis, …]) | 此函数通常用于数据并行化,每个切片都会发送到一个设备,即 GPU。它沿 **batch_axis** 将 NDArray 分割成 **num_slice** 个切片。 |
| split_and_load(data, ctx_list[, batch_axis, …]) | 此函数沿 **batch_axis** 将 NDArray 分割成 **len(ctx_list)** 个切片。与上面的 split_data() 函数唯一的区别是,它还将每个切片加载到 **ctx_list** 中的一个上下文中。 |
| clip_global_norm(arrays, max_norm[, …]) | 此函数的作用是以这样的方式重新缩放 NDArrays,使其 2 范数之和小于 **max_norm**。 |
| check_sha1(filename, sha1_hash) | 此函数将检查文件内容的 sha1 哈希是否与预期哈希匹配。 |
| download(url[, path, overwrite, sha1_hash, …]) | 顾名思义,此函数将下载给定的 URL。 |
| replace_file(src, dst) | 此函数将实现原子的 **os.replace**。这将在 Linux 和 OSX 上完成。 |
Python API Autograd 和初始化器
本章介绍 MXNet 中的 autograd 和初始化器 API。
mxnet.autograd
这是 MXNet 的用于 NDArray 的 autograd API。它具有以下类:
类:Function()
它用于 autograd 中的自定义微分。它可以写成 **mxnet.autograd.Function**。如果由于某种原因,用户不想使用默认链式法则计算的梯度,则他/她可以使用 mxnet.autograd 的 Function 类来自定义微分计算。它具有两个方法,即 Forward() 和 Backward()。
让我们通过以下几点来了解这个类的运作机制:
首先,我们需要在forward方法中定义我们的计算。
然后,我们需要在backward方法中提供自定义的微分。
现在,在梯度计算过程中,mxnet.autograd将使用用户定义的backward函数,而不是用户自定义的backward函数。我们也可以在forward和backward中将数据转换为numpy数组并转换回来,以进行一些操作。
示例
在使用mxnet.autograd.function类之前,让我们定义一个带有backward和forward方法的稳定sigmoid函数,如下所示:
class sigmoid(mx.autograd.Function):
def forward(self, x):
y = 1 / (1 + mx.nd.exp(-x))
self.save_for_backward(y)
return y
def backward(self, dy):
y, = self.saved_tensors
return dy * y * (1-y)
现在,function类可以按如下方式使用:
func = sigmoid() x = mx.nd.random.uniform(shape=(10,)) x.attach_grad() with mx.autograd.record(): m = func(x) m.backward() dx_grad = x.grad.asnumpy() dx_grad
输出
运行代码后,您将看到以下输出:
array([0.21458015, 0.21291625, 0.23330082, 0.2361367 , 0.23086983, 0.24060014, 0.20326573, 0.21093895, 0.24968489, 0.24301809], dtype=float32)
方法及其参数
以下是mxnet.autograd.function类的使用方法及其参数:
| 方法及其参数 | 定义 |
|---|---|
| forward (heads[, head_grads, retain_graph, …]) | 此方法用于前向计算。 |
| backward(heads[, head_grads, retain_graph, …]) | 此方法用于反向计算。它计算heads相对于先前标记的变量的梯度。此方法的输入数量与forward的输出数量相同。它也返回与forward输入一样多的NDArray。 |
| get_symbol(x) | 此方法用于检索记录的计算历史作为**Symbol**。 |
| grad(heads, variables[, head_grads, …]) | 此方法计算heads相对于variables的梯度。计算完成后,梯度将作为新的NDArrays返回,而不是存储到variable.grad中。 |
| is_recording() | 借助此方法,我们可以获取记录和未记录的状态。 |
| is_training() | 借助此方法,我们可以获取训练和预测的状态。 |
| mark_variables(variables, gradients[, grad_reqs]) | 此方法将NDArrays标记为变量,以便为autograd计算梯度。此方法与变量中的函数.attach_grad()相同,唯一的区别是通过此调用我们可以将梯度设置为任何值。 |
| pause([train_mode]) | 此方法返回一个作用域上下文,用于在'with'语句中使用,用于不需要计算梯度的代码。 |
| predict_mode() | 此方法返回一个作用域上下文,用于在'with'语句中使用,其中前向传递行为设置为推理模式,而不会更改记录状态。 |
| record([train_mode]) | 它将返回一个**autograd**记录作用域上下文,用于在'with'语句中使用,并捕获需要计算梯度的代码。 |
| set_recording(is_recording) | 与is_recording()类似,借助此方法,我们可以获取记录和未记录的状态。 |
| set_training(is_training) | 与is_training()类似,借助此方法,我们可以将状态设置为训练或预测。 |
| train_mode() | 此方法将返回一个作用域上下文,用于在'with'语句中使用,其中前向传递行为设置为训练模式,而不会更改记录状态。 |
实现示例
在下面的示例中,我们将使用mxnet.autograd.grad()方法来计算head相对于variables的梯度:
x = mx.nd.ones((2,)) x.attach_grad() with mx.autograd.record(): z = mx.nd.elemwise_add(mx.nd.exp(x), x) dx_grad = mx.autograd.grad(z, [x], create_graph=True) dx_grad
输出
输出如下所示:
[ [3.7182817 3.7182817] <NDArray 2 @cpu(0)>]
我们可以使用mxnet.autograd.predict_mode()方法返回一个作用域,用于在'with'语句中使用:
with mx.autograd.record(): y = model(x) with mx.autograd.predict_mode(): y = sampling(y) backward([y])
mxnet.initializer
这是MXNet的权重初始化器API。它具有以下类:
类及其参数
以下是**mxnet.autograd.function**类的使用方法及其参数
| 类及其参数 | 定义 |
|---|---|
| Bilinear() | 借助此类,我们可以为上采样层初始化权重。 |
| Constant(value) | 此类将权重初始化为给定值。该值可以是标量,也可以是与要设置的参数形状匹配的NDArray。 |
| FusedRNN(init, num_hidden, num_layers, mode) | 顾名思义,此类初始化融合循环神经网络(RNN)层的参数。 |
| InitDesc | 它充当初始化模式的描述符。 |
| Initializer(**kwargs) | 这是初始化器的基类。 |
| LSTMBias([forget_bias]) | 此类将LSTMCell的所有偏差初始化为0.0,但忘记门的偏差设置为自定义值除外。 |
| Load(param[, default_init, verbose]) | 此类通过从文件或字典加载数据来初始化变量。 |
| MSRAPrelu([factor_type, slope]) | 顾名思义,此类根据MSRA论文初始化权重。 |
| Mixed(patterns, initializers) | 它使用多个初始化器初始化参数。 |
| Normal([sigma]) | Normal()类使用从均值为零、标准差(SD)为**sigma**的正态分布中采样的随机值初始化权重。 |
| One() | 它将参数的权重初始化为一。 |
| Orthogonal([scale, rand_type]) | 顾名思义,此类将权重初始化为正交矩阵。 |
| Uniform([scale]) | 它使用从给定范围内均匀采样的随机值初始化权重。 |
| Xavier([rnd_type, factor_type, magnitude]) | 它实际上返回一个对权重执行“Xavier”初始化的初始化器。 |
| Zero() | 它将参数的权重初始化为零。 |
实现示例
在下面的示例中,我们将使用mxnet.init.Normal()类创建一个初始化器并检索其参数:
init = mx.init.Normal(0.8) init.dumps()
输出
输出如下所示:
'["normal", {"sigma": 0.8}]'
示例
init = mx.init.Xavier(factor_type="in", magnitude=2.45) init.dumps()
输出
输出如下所示:
'["xavier", {"rnd_type": "uniform", "factor_type": "in", "magnitude": 2.45}]'
在下面的示例中,我们将使用mxnet.initializer.Mixed()类使用多个初始化器初始化参数:
init = mx.initializer.Mixed(['bias', '.*'], [mx.init.Zero(), mx.init.Uniform(0.1)]) module.init_params(init) for dictionary in module.get_params(): for key in dictionary: print(key) print(dictionary[key].asnumpy())
输出
输出如下所示:
fullyconnected1_weight [[ 0.0097627 0.01856892 0.04303787]] fullyconnected1_bias [ 0.]
Apache MXNet - Python API Symbol
在本章中,我们将学习MXNet中一个称为Symbol的接口。
Mxnet.ndarray
Apache MXNet的Symbol API是符号编程的接口。Symbol API具有以下功能:
计算图
减少内存使用
预先使用函数优化
下面的示例显示了如何使用MXNet的Symbol API创建一个简单的表达式:
使用来自常规Python列表的1-D和2-D“数组”创建NDArray:
import mxnet as mx
# Two placeholders namely x and y will be created with mx.sym.variable
x = mx.sym.Variable('x')
y = mx.sym.Variable('y')
# The symbol here is constructed using the plus ‘+’ operator.
z = x + y
输出
您将看到以下输出:
<Symbol _plus0>
示例
(x, y, z)
输出
输出如下所示:
(<Symbol x>, <Symbol y>, <Symbol _plus0>)
现在让我们详细讨论MXNet的ndarray API的类、函数和参数。
类
下表包含MXNet的Symbol API的类:
| 类 | 定义 |
|---|---|
| Symbol(handle) | 此类即symbol是Apache MXNet的符号图。 |
函数及其参数
以下是mxnet.Symbol API涵盖的一些重要函数及其参数:
| 函数及其参数 | 定义 |
|---|---|
| Activation([data, act_type, out, name]) | 它将激活函数逐元素应用于输入。它支持**relu、sigmoid、tanh、softrelu、softsign**激活函数。 |
| BatchNorm([data, gamma, beta, moving_mean, …]) | 它用于批量归一化。此函数通过均值和方差对数据批进行归一化。它应用比例**gamma**和偏移**beta**。 |
| BilinearSampler([data, grid, cudnn_off, …]) | 此函数将双线性采样应用于输入特征图。实际上,它是“空间变换网络”的关键。如果您熟悉OpenCV中的remap函数,则此函数的使用与之非常相似。唯一的区别在于它具有反向传播。 |
| BlockGrad([data, out, name]) | 顾名思义,此函数停止梯度计算。它基本上阻止输入的累积梯度在反向方向上流经此运算符。 |
| cast([data, dtype, out, name]) | 此函数将输入的所有元素转换为新类型。 |
| 此函数将输入的所有元素转换为新类型。 | 此函数顾名思义,返回一个给定形状和类型的新的符号,填充为零。 |
| ones(shape[, dtype]) | 此函数顾名思义,返回一个给定形状和类型的新的符号,填充为一。 |
| full(shape, val[, dtype]) | 此函数顾名思义,返回一个给定形状和类型的新的数组,填充为给定值**val**。 |
| arange(start[, stop, step, repeat, …]) | 它将在给定区间内返回均匀间隔的值。这些值是在半开区间[start, stop)内生成的,这意味着该区间包含**start**但不包含**stop**。 |
| linspace(start, stop, num[, endpoint, name, …]) | 它将在指定的区间内返回均匀间隔的数字。与函数arange()类似,这些值是在半开区间[start, stop)内生成的,这意味着该区间包含**start**但不包含**stop**。 |
| histogram(a[, bins, range]) | 顾名思义,此函数将计算输入数据的直方图。 |
| power(base, exp) | 顾名思义,此函数将返回**base**元素按**exp**元素的幂进行逐元素计算的结果。两个输入,即base和exp,都可以是Symbol或标量。这里需要注意的是不允许广播。如果您想使用广播功能,可以使用**broadcast_pow**。 |
| SoftmaxActivation([data, mode, name, attr, out]) | 此函数将softmax激活应用于输入。它用于内部层。它实际上已弃用,我们可以使用**softmax()**代替。 |
实现示例
在下面的示例中,我们将使用函数**power()**,它将返回base元素按exp元素的幂进行逐元素计算的结果
import mxnet as mx mx.sym.power(3, 5)
输出
您将看到以下输出:
243
示例
x = mx.sym.Variable('x')
y = mx.sym.Variable('y')
z = mx.sym.power(x, 3)
z.eval(x=mx.nd.array([1,2]))[0].asnumpy()
输出
这将产生以下输出:
array([1., 8.], dtype=float32)
示例
z = mx.sym.power(4, y) z.eval(y=mx.nd.array([2,3]))[0].asnumpy()
输出
执行上述代码后,您应该看到以下输出:
array([16., 64.], dtype=float32)
示例
z = mx.sym.power(x, y) z.eval(x=mx.nd.array([4,5]), y=mx.nd.array([2,3]))[0].asnumpy()
输出
输出如下所示:
array([ 16., 125.], dtype=float32)
在下面的示例中,我们将使用函数**SoftmaxActivation()(或softmax())**,它将应用于输入,并用于内部层。
input_data = mx.nd.array([[2., 0.9, -0.5, 4., 8.], [4., -.7, 9., 2., 0.9]]) soft_max_act = mx.nd.softmax(input_data) print (soft_max_act.asnumpy())
输出
您将看到以下输出:
[[2.4258138e-03 8.0748333e-04 1.9912292e-04 1.7924475e-02 9.7864312e-01] [6.6843745e-03 6.0796250e-05 9.9204916e-01 9.0463174e-04 3.0112563e-04]]
symbol.contrib
Contrib NDArray API在symbol.contrib包中定义。它通常为新功能提供许多有用的实验性API。此API作为社区尝试新功能的地方。功能贡献者也将获得反馈。
函数及其参数
以下是**mxnet.symbol.contrib API**涵盖的一些重要函数及其参数:
| 函数及其参数 | 定义 |
|---|---|
| rand_zipfian(true_classes, num_sampled, …) | 此函数从近似齐夫分布中抽取随机样本。此函数的基本分布是齐夫分布。此函数随机抽取num_sampled个候选样本,并且sampled_candidates的元素是从上面给出的基本分布中抽取的。 |
| foreach(body, data, init_states) | 顾名思义,此函数在维度0上对NDArrays运行一个具有用户定义计算的循环。此函数模拟for循环,body具有for循环迭代的计算。 |
| while_loop(cond, func, loop_vars[, …]) | 顾名思义,此函数运行带有用户定义计算和循环条件的while循环。此函数模拟一个while循环,如果条件满足,则逐字进行自定义计算。 |
| cond(pred, then_func, else_func) | 顾名思义,此函数使用用户定义的条件和计算运行if-then-else。此函数模拟if类型的分支,根据指定的条件选择执行两个自定义计算之一。 |
| getnnz([data, axis, out, name]) | 此函数为我们提供稀疏张量的存储值的个数。它还包括显式零。它只支持CPU上的CSR矩阵。 |
| requantize([data, min_range, max_range, …]) | 此函数使用最小和最大阈值(在运行时计算或来自校准)将以int32和相应阈值量化的给定数据重新量化为int8。 |
| index_copy([old_tensor, index_vector, …]) | 此函数通过按索引向量中给出的顺序选择索引,将**new_tensor**的元素复制到**old_tensor**中。此运算符的输出将是一个新张量,其中包含old_tensor的其余元素和new_tensor的已复制元素。 |
| interleaved_matmul_encdec_qk([queries, …]) | 此运算符计算多头注意力中查询和键的投影之间的矩阵乘法,用作编码器-解码器。条件是输入应该是查询投影的张量,其布局如下:(seq_length, batch_size, num_heads*, head_dim)。 |
实现示例
在下面的示例中,我们将使用rand_zipfian函数从近似齐夫分布中抽取随机样本:
import mxnet as mx
true_cls = mx.sym.Variable('true_cls')
samples, exp_count_true, exp_count_sample = mx.sym.contrib.rand_zipfian(true_cls, 5, 6)
samples.eval(true_cls=mx.nd.array([3]))[0].asnumpy()
输出
您将看到以下输出:
array([4, 0, 2, 1, 5], dtype=int64)
示例
exp_count_true.eval(true_cls=mx.nd.array([3]))[0].asnumpy()
输出
输出如下所示:
array([0.57336551])
示例
exp_count_sample.eval(true_cls=mx.nd.array([3]))[0].asnumpy()
输出
您将看到以下输出:
array([1.78103594, 0.46847373, 1.04183923, 0.57336551, 1.04183923])
下面的例子中,我们将使用函数while_loop来运行用户定义的计算和循环条件的while循环。
cond = lambda i, s: i <= 7
func = lambda i, s: ([i + s], [i + 1, s + i])
loop_vars = (mx.sym.var('i'), mx.sym.var('s'))
outputs, states = mx.sym.contrib.while_loop(cond, func, loop_vars, max_iterations=10)
print(outputs)
输出
输出如下所示
[<Symbol _while_loop0>]
示例
Print(States)
输出
这将产生以下输出:
[<Symbol _while_loop0>, <Symbol _while_loop0>]
下面的例子中,我们将使用函数index_copy将new_tensor的元素复制到old_tensor中。
import mxnet as mx a = mx.nd.zeros((6,3)) b = mx.nd.array([[1,2,3],[4,5,6],[7,8,9]]) index = mx.nd.array([0,4,2]) mx.nd.contrib.index_copy(a, index, b)
输出
执行上述代码后,您应该看到以下输出:
[[1. 2. 3.] [0. 0. 0.] [7. 8. 9.] [0. 0. 0.] [4. 5. 6.] [0. 0. 0.]] <NDArray 6x3 @cpu(0)>
symbol.image
图像符号API定义在symbol.image包中。顾名思义,它通常用于图像及其特征。
函数及其参数
以下是mxnet.symbol.image API涵盖的一些重要函数及其参数:
| 函数及其参数 | 定义 |
|---|---|
| adjust_lighting([data, alpha, out, name]) | 顾名思义,此函数调整输入的光照级别。它遵循AlexNet样式。 |
| crop([data, x, y, width, height, out, name]) | 借助此函数,我们可以将形状为(H x W x C)或(N x H x W x C)的图像NDArray裁剪到用户给定的尺寸。 |
| normalize([data, mean, std, out, name]) | 它将使用均值和标准差(SD)对形状为(C x H x W)或(N x C x H x W)的张量进行标准化。 |
| random_crop([data, xrange, yrange, width, …]) | 类似于crop(),它会随机裁剪形状为(H x W x C)或(N x H x W x C)的图像NDArray到用户给定的尺寸。如果src小于size,它将对结果进行上采样。 |
| random_lighting([data, alpha_std, out, name]) | 顾名思义,此函数会随机添加PCA噪声。它也遵循AlexNet样式。 |
| random_resized_crop([data, xrange, yrange, …]) | 它也会将形状为(H x W x C)或(N x H x W x C)的图像NDArray随机裁剪到给定尺寸。如果src小于size,它将对结果进行上采样。它也会随机化面积和纵横比。 |
| resize([data, size, keep_ratio, interp, …]) | 顾名思义,此函数将调整形状为 (H x W x C) 或 (N x H x W x C) 的图像 NDArray 的大小到用户指定的大小。 |
| to_tensor([data, out, name]) | 它将形状为 (H x W x C) 或 (N x H x W x C) 且值在 [0, 255] 范围内的图像 NDArray 转换为形状为 (C x H x W) 或 (N x C x H x W) 且值在 [0, 1] 范围内的张量 NDArray。 |
实现示例
在下面的示例中,我们将使用 to_tensor 函数将形状为 (H x W x C) 或 (N x H x W x C) 且值在 [0, 255] 范围内的图像 NDArray 转换为形状为 (C x H x W) 或 (N x C x H x W) 且值在 [0, 1] 范围内的张量 NDArray。
import numpy as np img = mx.sym.random.uniform(0, 255, (4, 2, 3)).astype(dtype=np.uint8) mx.sym.image.to_tensor(img)
输出
输出如下所示:
<Symbol to_tensor4>
示例
img = mx.sym.random.uniform(0, 255, (2, 4, 2, 3)).astype(dtype=np.uint8) mx.sym.image.to_tensor(img)
输出
输出如下所示
<Symbol to_tensor5>
在下面的例子中,我们将使用函数normalize()来使用均值和标准差(SD)对形状为(C x H x W)或(N x C x H x W)的张量进行标准化。
img = mx.sym.random.uniform(0, 1, (3, 4, 2)) mx.sym.image.normalize(img, mean=(0, 1, 2), std=(3, 2, 1))
输出
以下是代码的输出:
<Symbol normalize0>
示例
img = mx.sym.random.uniform(0, 1, (2, 3, 4, 2)) mx.sym.image.normalize(img, mean=(0, 1, 2), std=(3, 2, 1))
输出
输出如下所示:
<Symbol normalize1>
symbol.random
随机符号API定义在symbol.random包中。顾名思义,它是MXNet的随机分布生成器符号API。
函数及其参数
以下是mxnet.symbol.random API涵盖的一些重要函数及其参数:
| 函数及其参数 | 定义 |
|---|---|
| uniform([low, high, shape, dtype, ctx, out]) | 它从均匀分布中生成随机样本。 |
| normal([loc, scale, shape, dtype, ctx, out]) | 它从正态 (高斯) 分布中生成随机样本。 |
| randn(*shape, **kwargs) | 它从正态 (高斯) 分布中生成随机样本。 |
| poisson([lam, shape, dtype, ctx, out]) | 它从泊松分布中生成随机样本。 |
| exponential([scale, shape, dtype, ctx, out]) | 它从指数分布中生成样本。 |
| gamma([alpha, beta, shape, dtype, ctx, out]) | 它从伽马分布中生成随机样本。 |
| multinomial(data[, shape, get_prob, out, dtype]) | 它从多个多项分布中生成并发采样。 |
| negative_binomial([k, p, shape, dtype, ctx, out]) | 它从负二项分布中生成随机样本。 |
| generalized_negative_binomial([mu, alpha, …]) | 它从广义负二项分布中生成随机样本。 |
| shuffle(data, **kwargs) | 它随机打乱元素。 |
| randint(low, high[, shape, dtype, ctx, out]) | 它从离散均匀分布中生成随机样本。 |
| exponential_like([data, lam, out, name]) | 它根据输入数组形状从指数分布中生成随机样本。 |
| gamma_like([data, alpha, beta, out, name]) | 它根据输入数组形状从伽马分布中生成随机样本。 |
| generalized_negative_binomial_like([data, …]) | 它根据输入数组形状从广义负二项分布中生成随机样本。 |
| negative_binomial_like([data, k, p, out, name]) | 它根据输入数组形状从负二项分布中生成随机样本。 |
| normal_like([data, loc, scale, out, name]) | 它根据输入数组形状从正态(高斯)分布中生成随机样本。 |
| poisson_like([data, lam, out, name]) | 它根据输入数组形状从泊松分布中生成随机样本。 |
| uniform_like([data, low, high, out, name]) | 它根据输入数组形状从均匀分布中生成随机样本。 |
实现示例
在下面的例子中,我们将使用shuffle()函数随机打乱元素。它将沿着第一个轴打乱数组。
data = mx.nd.array([[0, 1, 2], [3, 4, 5], [6, 7, 8],[9,10,11]])
x = mx.sym.Variable('x')
y = mx.sym.random.shuffle(x)
y.eval(x=data)
输出
您将看到以下输出
[ [[ 9. 10. 11.] [ 0. 1. 2.] [ 6. 7. 8.] [ 3. 4. 5.]] <NDArray 4x3 @cpu(0)>]
示例
y.eval(x=data)
输出
执行上述代码后,您应该看到以下输出:
[ [[ 6. 7. 8.] [ 0. 1. 2.] [ 3. 4. 5.] [ 9. 10. 11.]] <NDArray 4x3 @cpu(0)>]
在下面的例子中,我们将从广义负二项分布中抽取随机样本。为此,我们将使用函数generalized_negative_binomial()。
mx.sym.random.generalized_negative_binomial(10, 0.1)
输出
输出如下所示:
<Symbol _random_generalized_negative_binomial0>
symbol.sparse
稀疏符号API定义在mxnet.symbol.sparse包中。顾名思义,它提供稀疏神经网络图和CPU上的自动微分。
函数及其参数
以下是mxnet.symbol.sparse API涵盖的一些重要函数(包括符号创建例程、符号操作例程、数学函数、三角函数、双曲函数、约简函数、舍入、幂运算、神经网络)及其参数:
| 函数及其参数 | 定义 |
|---|---|
| ElementWiseSum(*args, **kwargs) | 此函数将逐元素相加所有输入参数。例如,𝑎𝑑𝑑_𝑛(𝑎1,𝑎2,…𝑎𝑛=𝑎1+𝑎2+⋯+𝑎𝑛)。在这里,我们可以看到add_n可能比调用n次add更高效。 |
| Embedding([data, weight, input_dim, …]) | 它将整数索引映射到向量表示,即嵌入。它实际上是将单词映射到高维空间中的实值向量,这称为词嵌入。 |
| LinearRegressionOutput([data, label, …]) | 它在反向传播期间计算并优化平方损失,在正向传播期间只给出输出数据。 |
| LogisticRegressionOutput([data, label, …]) | 应用逻辑函数,也称为 sigmoid 函数,到输入。该函数计算为 1/1+exp (−x)。 |
| MAERegressionOutput([data, label, …]) | 此运算符计算输入的平均绝对误差。MAE实际上是对应于绝对误差期望值的风险度量。 |
| abs([data, name, attr, out]) | 顾名思义,此函数将返回输入的逐元素绝对值。 |
| adagrad_update([weight, grad, history, lr, …]) | 它是AdaGrad优化器的更新函数。 |
| adam_update([weight, grad, mean, var, lr, …]) | 它是Adam优化器的更新函数。 |
| add_n(*args, **kwargs) | 顾名思义,它将逐元素相加所有输入参数。 |
| arccos([data, name, attr, out]) | 此函数将返回输入数组的逐元素反余弦。 |
| dot([lhs, rhs, transpose_a, transpose_b, …]) | 顾名思义,它将给出两个数组的点积。这取决于输入数组的维度:一维:向量的内积;二维:矩阵乘法;N维:第一个输入的最后一个轴和第二个输入的第一个轴上的求和积。 |
| elemwise_add([lhs, rhs, name, attr, out]) | 顾名思义,它将逐元素相加参数。 |
| elemwise_div([lhs, rhs, name, attr, out]) | 顾名思义,它将逐元素相除参数。 |
| elemwise_mul([lhs, rhs, name, attr, out]) | 顾名思义,它将逐元素相乘参数。 |
| elemwise_sub([lhs, rhs, name, attr, out]) | 顾名思义,它将逐元素相减参数。 |
| exp([data, name, attr, out]) | 此函数将返回给定输入的逐元素指数值。 |
| sgd_update([weight, grad, lr, wd, …]) | 它充当随机梯度下降优化器的更新函数。 |
| sigmoid([data, name, attr, out]) | 顾名思义,它将逐元素计算x的sigmoid值。 |
| sign([data, name, attr, out]) | 它将返回给定输入的逐元素符号。 |
| sin([data, name, attr, out]) | 顾名思义,此函数将计算给定输入数组的逐元素正弦值。 |
实现示例
在下面的例子中,我们将使用ElementWiseSum()函数随机打乱元素。它将整数索引映射到向量表示,即词嵌入。
input_dim = 4 output_dim = 5
示例
/* Here every row in weight matrix y represents a word. So, y = (w0,w1,w2,w3) y = [[ 0., 1., 2., 3., 4.], [ 5., 6., 7., 8., 9.], [ 10., 11., 12., 13., 14.], [ 15., 16., 17., 18., 19.]] /* Here input array x represents n-grams(2-gram). So, x = [(w1,w3), (w0,w2)] x = [[ 1., 3.], [ 0., 2.]] /* Now, Mapped input x to its vector representation y. Embedding(x, y, 4, 5) = [[[ 5., 6., 7., 8., 9.], [ 15., 16., 17., 18., 19.]], [[ 0., 1., 2., 3., 4.], [ 10., 11., 12., 13., 14.]]]
Apache MXNet - Python API Module
Apache MXNet的模块API类似于前馈模型,它更容易组合,类似于Torch模块。它包含以下类:
BaseModule([logger])
它表示模块的基类。模块可以被认为是计算组件或计算机器。模块的任务是执行前向和反向传递。它还会更新模型中的参数。
方法
下表显示了BaseModule类包含的方法:
| 方法 | 定义 |
|---|---|
| backward([out_grads]) | 顾名思义,此方法实现了反向计算。 |
| bind(data_shapes[, label_shapes, …]) | 它绑定符号以构建执行器,在可以使用模块进行计算之前这是必要的。 |
| fit(train_data[, eval_data, eval_metric, …]) | 此方法训练模块参数。 |
| forward(data_batch[, is_train]) | 顾名思义,此方法实现了正向计算。此方法支持具有各种形状的数据批次,例如不同的批次大小或不同的图像大小。 |
| forward_backward(data_batch) | 这是一个方便的函数,顾名思义,它同时调用正向和反向。 |
| get_input_grads([merge_multi_context]) | 此方法将获取输入的梯度,这些梯度是在之前的反向计算中计算的。 |
| get_outputs([merge_multi_context]) | 顾名思义,此方法将获取先前正向计算的输出。 |
| get_params() | 它获取参数,特别是那些可能是用于在设备上进行计算的实际参数副本的参数。 |
| get_states([merge_multi_context]) | |
| init_optimizer([kvstore, optimizer, …]) | 此方法安装并初始化优化器。它还为分布式训练初始化kvstore。 |
| init_params([initializer, arg_params, …]) | 顾名思义,此方法将初始化参数和辅助状态。 |
| install_monitor(mon) | 此方法将在所有执行器上安装监控器。 |
| iter_predict(eval_data[, num_batch, reset, …]) | 此方法将迭代预测。 |
| load_params(fname) | 顾名思义,它将从文件中加载模型参数。 |
| predict(eval_data[, num_batch, …]) | 它将运行预测并收集输出。 |
| prepare(data_batch[, sparse_row_id_fn]) | 该运算符准备模块以处理给定的数据批次。 |
| save_params(fname) | 顾名思义,此函数将模型参数保存到文件中。 |
| score(eval_data, eval_metric[, num_batch, …]) | 它在eval_data上运行预测,并根据给定的eval_metric评估性能。 |
| set_params(arg_params, aux_params[, …]) | 此方法将分配参数和辅助状态值。 |
| set_states([states, value]) | 顾名思义,此方法设置状态的值。 |
| update() | 此方法根据已安装的优化器更新给定的参数。它还更新在上一个前向-反向批次中计算的梯度。 |
| update_metric(eval_metric, labels[, pre_sliced]) | 顾名思义,此方法评估并累积上一个正向计算输出的评估指标。 |
| backward([out_grads]) | 顾名思义,此方法实现了反向计算。 |
| bind(data_shapes[, label_shapes, …]) | 它设置桶并为默认桶键绑定执行器。此方法表示BucketingModule的绑定。 |
| forward(data_batch[, is_train]) | 顾名思义,此方法实现了正向计算。此方法支持具有各种形状的数据批次,例如不同的批次大小或不同的图像大小。 |
| get_input_grads([merge_multi_context]) | 此方法将获取输入的梯度,这些梯度是在之前的反向计算中计算的。 |
| get_outputs([merge_multi_context]) | 顾名思义,此方法将获取先前正向计算的输出。 |
| get_params() | 它获取当前参数,特别是那些可能是用于在设备上进行计算的实际参数副本的参数。 |
| get_states([merge_multi_context]) | 此方法将从所有设备获取状态。 |
| init_optimizer([kvstore, optimizer, …]) | 此方法安装并初始化优化器。它还为分布式训练初始化kvstore。 |
| init_params([initializer, arg_params, …]) | 顾名思义,此方法将初始化参数和辅助状态。 |
| install_monitor(mon) | 此方法将在所有执行器上安装监控器。 |
| load(prefix, epoch[, sym_gen, …]) | 此方法将根据先前保存的检查点创建一个模型。 |
| load_dict([sym_dict, sym_gen, …]) | 此方法将根据将bucket_key映射到符号的字典 (dict) 创建模型。它还共享arg_params 和aux_params。 |
| prepare(data_batch[, sparse_row_id_fn]) | 该运算符准备模块以处理给定的数据批次。 |
| save_checkpoint(prefix, epoch[, remove_amp_cast]) | 顾名思义,此方法将BucketingModule中所有bucket的当前进度保存到检查点。建议使用mx.callback.module_checkpoint作为epoch_end_callback在训练期间保存。 |
| set_params(arg_params, aux_params[,…]) | 顾名思义,此函数将分配参数和辅助状态值。 |
| set_states([states, value]) | 顾名思义,此方法设置状态的值。 |
| switch_bucket(bucket_key, data_shapes[, …]) | 它将切换到不同的bucket。 |
| update() | 此方法根据已安装的优化器更新给定的参数。它还更新在上一个前向-反向批次中计算的梯度。 |
| update_metric(eval_metric, labels[, pre_sliced]) | 顾名思义,此方法评估并累积上一个正向计算输出的评估指标。 |
属性
下表显示了BaseModule类的方法中包含的属性:
| 属性 | 定义 |
|---|---|
| data_names | 它包含此模块所需数据的名称列表。 |
| data_shapes | 它包含指定此模块的数据输入的(名称,形状)对列表。 |
| label_shapes | 它显示指定此模块的标签输入的(名称,形状)对列表。 |
| output_names | 它包含此模块输出的名称列表。 |
| output_shapes | 它包含指定此模块输出的(名称,形状)对列表。 |
| symbol | 顾名思义,此属性获取与此模块关联的符号。 |
data_shapes:您可以参考以下链接了解更多详情:https://mxnet.apache.org output_shapes:更多信息
output_shapes:更多信息请访问 https://mxnet.apache.org/api/python
BucketingModule(sym_gen[…])
它表示Module的Bucketingmodule类,该类有助于有效处理长度可变的输入。
方法
下表显示了BucketingModule类中包含的方法:
属性
下表显示了BaseModule类的方法中包含的属性:
| 属性 | 定义 |
|---|---|
| data_names | 它包含此模块所需数据的名称列表。 |
| data_shapes | 它包含指定此模块的数据输入的(名称,形状)对列表。 |
| label_shapes | 它显示指定此模块的标签输入的(名称,形状)对列表。 |
| output_names | 它包含此模块输出的名称列表。 |
| output_shapes | 它包含指定此模块输出的(名称,形状)对列表。 |
| Symbol | 顾名思义,此属性获取与此模块关联的符号。 |
data_shapes − 更多信息请参考以下链接:https://mxnet.apache.org/api/python/docs
output_shapes− 更多信息请参考以下链接:https://mxnet.apache.org/api/python/docs
Module(symbol[,data_names, label_names,…])
它表示包装symbol的基本模块。
方法
下表显示了Module类中包含的方法:
| 方法 | 定义 |
|---|---|
| backward([out_grads]) | 顾名思义,此方法实现了反向计算。 |
| bind(data_shapes[, label_shapes, …]) | 它绑定符号以构建执行器,在可以使用模块进行计算之前这是必要的。 |
| borrow_optimizer(shared_module) | 顾名思义,此方法将从共享模块借用优化器。 |
| forward(data_batch[, is_train]) | 顾名思义,此方法实现了前向计算。此方法支持具有各种形状的数据批次,例如不同的批次大小或不同的图像大小。 |
| get_input_grads([merge_multi_context]) | 此方法将获取输入的梯度,这些梯度是在之前的反向计算中计算的。 |
| get_outputs([merge_multi_context]) | 顾名思义,此方法将获取先前正向计算的输出。 |
| get_params() | 它获取参数,特别是那些可能是用于在设备上进行计算的实际参数副本的参数。 |
| get_states([merge_multi_context]) | 此方法将从所有设备获取状态 |
| init_optimizer([kvstore, optimizer, …]) | 此方法安装并初始化优化器。它还为分布式训练初始化kvstore。 |
| init_params([initializer, arg_params, …]) | 顾名思义,此方法将初始化参数和辅助状态。 |
| install_monitor(mon) | 此方法将在所有执行器上安装监控器。 |
| load(prefix, epoch[, sym_gen, …]) | 此方法将根据先前保存的检查点创建一个模型。 |
| load_optimizer_states(fname) | 此方法将加载优化器,即从文件加载更新器状态。 |
| prepare(data_batch[, sparse_row_id_fn]) | 该运算符准备模块以处理给定的数据批次。 |
| reshape(data_shapes[, label_shapes]) | 顾名思义,此方法将为新的输入形状重新调整模块。 |
| save_checkpoint(prefix, epoch[, …]) | 它将当前进度保存到检查点。 |
| save_optimizer_states(fname) | 此方法将优化器或更新器状态保存到文件。 |
| set_params(arg_params, aux_params[,…]) | 顾名思义,此函数将分配参数和辅助状态值。 |
| set_states([states, value]) | 顾名思义,此方法设置状态的值。 |
| update() | 此方法根据已安装的优化器更新给定的参数。它还更新在上一个前向-反向批次中计算的梯度。 |
| update_metric(eval_metric, labels[, pre_sliced]) | 顾名思义,此方法评估并累积上一个正向计算输出的评估指标。 |
属性
下表显示了Module类的方法中包含的属性:
| 属性 | 定义 |
|---|---|
| data_names | 它包含此模块所需数据的名称列表。 |
| data_shapes | 它包含指定此模块的数据输入的(名称,形状)对列表。 |
| label_shapes | 它显示指定此模块的标签输入的(名称,形状)对列表。 |
| output_names | 它包含此模块输出的名称列表。 |
| output_shapes | 它包含指定此模块输出的(名称,形状)对列表。 |
| label_names | 它包含此模块所需标签的名称列表。 |
data_shapes: 访问以下链接了解更多详情:https://mxnet.apache.org/api/python/docs/api/module
output_shapes: 此处提供的链接 https://mxnet.apache.org/api/python/docs/api/module/index.html 将提供其他重要信息。
PythonLossModule([name,data_names,…])
此类的基类是mxnet.module.python_module.PythonModule。PythonLossModule类是一个方便的模块类,它将所有或许多模块API实现为空函数。
方法
下表显示了PythonLossModule类中包含的方法
| 方法 | 定义 |
|---|---|
| backward([out_grads]) | 顾名思义,此方法实现了反向计算。 |
| forward(data_batch[, is_train]) | 顾名思义,此方法实现了前向计算。此方法支持具有各种形状的数据批次,例如不同的批次大小或不同的图像大小。 |
| get_input_grads([merge_multi_context]) | 此方法将获取输入的梯度,这些梯度是在之前的反向计算中计算的。 |
| get_outputs([merge_multi_context]) | 顾名思义,此方法将获取先前正向计算的输出。 |
| install_monitor(mon) | 此方法将在所有执行器上安装监控器。 |
PythonModule([data_names,label_names…])
此类的基类是mxnet.module.base_module.BaseModule。PythonModule类也是一个方便的模块类,它将所有或许多模块API实现为空函数。
方法
下表显示了PythonModule类中包含的方法:
| 方法 | 定义 |
|---|---|
| bind(data_shapes[, label_shapes, …]) | 它绑定符号以构建执行器,在可以使用模块进行计算之前这是必要的。 |
| get_params() | 它获取参数,特别是那些可能是用于在设备上进行计算的实际参数副本的参数。 |
| init_optimizer([kvstore, optimizer, …]) | 此方法安装并初始化优化器。它还为分布式训练初始化kvstore。 |
| init_params([initializer, arg_params, …]) | 顾名思义,此方法将初始化参数和辅助状态。 |
| update() | 此方法根据已安装的优化器更新给定的参数。它还更新在上一个前向-反向批次中计算的梯度。 |
| update_metric(eval_metric, labels[, pre_sliced]) | 顾名思义,此方法评估并累积上一个正向计算输出的评估指标。 |
属性
下表显示了PythonModule类的方法中包含的属性:
| 属性 | 定义 |
|---|---|
| data_names | 它包含此模块所需数据的名称列表。 |
| data_shapes | 它包含指定此模块的数据输入的(名称,形状)对列表。 |
| label_shapes | 它显示指定此模块的标签输入的(名称,形状)对列表。 |
| output_names | 它包含此模块输出的名称列表。 |
| output_shapes | 它包含指定此模块输出的(名称,形状)对列表。 |
data_shapes − 更多详情请访问以下链接:https://mxnet.apache.org
output_shapes − 更多详情请访问以下链接:https://mxnet.apache.org
SequentialModule([logger])
此类的基类是mxnet.module.base_module.BaseModule。SequentialModule类也是一个容器模块,可以将两个以上(多个)模块链接在一起。
方法
下表显示了SequentialModule类中包含的方法
| 方法 | 定义 |
|---|---|
| add(module, **kwargs) | 这是此类最重要的函数。它将模块添加到链中。 |
| backward([out_grads]) | 顾名思义,此方法实现了反向计算。 |
| bind(data_shapes[, label_shapes, …]) | 它绑定符号以构建执行器,在可以使用模块进行计算之前这是必要的。 |
| forward(data_batch[, is_train]) | 顾名思义,此方法实现了正向计算。此方法支持具有各种形状的数据批次,例如不同的批次大小或不同的图像大小。 |
| get_input_grads([merge_multi_context]) | 此方法将获取输入的梯度,这些梯度是在之前的反向计算中计算的。 |
| get_outputs([merge_multi_context]) | 顾名思义,此方法将获取先前正向计算的输出。 |
| get_params() | 它获取参数,特别是那些可能是用于在设备上进行计算的实际参数副本的参数。 |
| init_optimizer([kvstore, optimizer, …]) | 此方法安装并初始化优化器。它还为分布式训练初始化kvstore。 |
| init_params([initializer, arg_params, …]) | 顾名思义,此方法将初始化参数和辅助状态。 |
| install_monitor(mon) | 此方法将在所有执行器上安装监控器。 |
| update() | 此方法根据已安装的优化器更新给定的参数。它还更新在上一个前向-反向批次中计算的梯度。 |
| update_metric(eval_metric, labels[, pre_sliced]) | 顾名思义,此方法评估并累积上一个正向计算输出的评估指标。 |
属性
下表显示了BaseModule类的方法中包含的属性:
| 属性 | 定义 |
|---|---|
| data_names | 它包含此模块所需数据的名称列表。 |
| data_shapes | 它包含指定此模块的数据输入的(名称,形状)对列表。 |
| label_shapes | 它显示指定此模块的标签输入的(名称,形状)对列表。 |
| output_names | 它包含此模块输出的名称列表。 |
| output_shapes | 它包含指定此模块输出的(名称,形状)对列表。 |
| output_shapes | 它包含指定此模块输出的(名称,形状)对列表。 |
data_shapes − 此处提供的链接 https://mxnet.apache.org 将帮助您更详细地了解该属性。
output_shapes − 更多详情请访问以下链接:https://mxnet.apache.org/api
实现示例
在下面的示例中,我们将创建一个mxnet模块。
import mxnet as mx
input_data = mx.symbol.Variable('input_data')
f_connected1 = mx.symbol.FullyConnected(data, name='f_connected1', num_hidden=128)
activation_1 = mx.symbol.Activation(f_connected1, name='relu1', act_type="relu")
f_connected2 = mx.symbol.FullyConnected(activation_1, name = 'f_connected2', num_hidden = 64)
activation_2 = mx.symbol.Activation(f_connected2, name='relu2',
act_type="relu")
f_connected3 = mx.symbol.FullyConnected(activation_2, name='fc3', num_hidden=10)
out = mx.symbol.SoftmaxOutput(f_connected3, name = 'softmax')
mod = mx.mod.Module(out)
print(out)
输出
输出如下所示:
<Symbol softmax>
示例
print(mod)
输出
输出如下所示:
<mxnet.module.module.Module object at 0x00000123A9892F28>
在下面的示例中,我们将实现前向计算
import mxnet as mx
from collections import namedtuple
Batch = namedtuple('Batch', ['data'])
data = mx.sym.Variable('data')
out = data * 2
mod = mx.mod.Module(symbol=out, label_names=None)
mod.bind(data_shapes=[('data', (1, 10))])
mod.init_params()
data1 = [mx.nd.ones((1, 10))]
mod.forward(Batch(data1))
print (mod.get_outputs()[0].asnumpy())
输出
执行上述代码后,您应该看到以下输出:
[[2. 2. 2. 2. 2. 2. 2. 2. 2. 2.]]
示例
data2 = [mx.nd.ones((3, 5))] mod.forward(Batch(data2)) print (mod.get_outputs()[0].asnumpy())
输出
以下是代码的输出:
[[2. 2. 2. 2. 2.] [2. 2. 2. 2. 2.] [2. 2. 2. 2. 2.]]