- AWS Athena 教程
- AWS Athena - 首页
- 什么是 AWS Athena?
- AWS Athena - 入门
- AWS Athena 如何工作?
- AWS Athena - 编写 SQL 查询
- AWS Athena - 性能优化
- AWS Athena - 数据安全
- AWS Athena - 成本管理
- AWS Athena 资源
- AWS Athena 快速指南
- AWS Athena - 资源
- AWS Athena - 讨论
AWS Athena 快速指南
AWS Athena 是一款无服务器、交互式查询服务,允许您使用标准 SQL 直接分析 Amazon Simple Storage Service (S3) 中的大型数据集。
- 与传统数据库相比,Athena 更好,因为它消除了配置、管理和扩展等管理任务的需求。
- Athena 为用户提供了更大的灵活性,因为它可以自动处理跨分区的数据。将数据上传到 Amazon S3 后,您可以立即开始查询数据。
- Athena 即使在大型数据集上也能实现高性能查询,因为它使用 Presto 分布式 SQL 引擎来运行查询。
- AWS Athena 支持多种格式,包括 CSV、JSON、Parquet 和 ORC。
数据分析师、开发人员或任何想要运行查询而无需数据仓库的人员都可以使用 Athena。
为什么选择 AWS Athena 进行数据查询?
在本节中,我们重点介绍了一系列充分的理由,说明您为什么应该选择 AWS Athena 而不是其他工具进行数据查询:
1. 无服务器架构
AWS Athena 最重要的优势之一是它完全是无服务器的。这意味着用户无需管理服务器、存储,也不必担心扩展基础设施。Athena 只允许用户进行数据查询。
2. 按查询付费模型
AWS Athena 遵循按查询付费模型。这意味着用户只需为查询扫描的数据付费。此功能使其具有成本效益。
3. 支持各种数据格式
Athena 支持各种数据格式,包括结构化、半结构化和非结构化格式。它可以查询存储为 CSV、JSON、Apache Parquet、Apache ORC 甚至 Apache Web 日志等日志格式的数据。
4. 易于与 AWS 服务集成
AWS Athena 可以轻松连接到其他 AWS 工具,这使得创建完整的数据管道变得容易。
例如,AWS Athena 可以很好地与 AWS Glue(用于数据组织)、AWS Lambda(用于实时处理)和 Amazon QuickSight(用于可视化数据和构建仪表板)配合使用。
5. Athena 提供安全的环境
AWS Athena 是安全的,因为它为您的数据提供了多层安全保护。它与 **AWS Identity and Access Management (IAM)** 集成,以控制对数据集的访问。
Athena 确保只有授权用户才能运行查询。用户还可以配置 **VPC 端点**,以确保所有数据查询都在安全和私有网络内运行。
6. 可扩展性和速度
AWS Athena 旨在处理大量数据。它会自动扩展自身以适应更大的数据集,并确保快速执行查询,而无论数据量如何。
Athena 即使对于复杂的查询也能实现高速性能,因为它使用 Presto 分布式 SQL 引擎来运行查询。
7. 易用性
AWS Athena 使用标准 SQL,因此对于熟悉 SQL 查询的任何人来说都很容易使用。其用户友好的界面使用户只需点击几下即可直接在其 S3 数据上运行 SQL 查询。
Athena 还通过自动创建表和架构来自您的数据来简化设置和运行查询的过程。
AWS Athena - 入门
设置您的 AWS Athena 环境很简单,并且对于有效地在存储在 Amazon S3 中的数据上运行 SQL 查询至关重要。
先决条件
在开始使用 AWS Athena 之前,以下是先决条件:
- 您必须拥有一个 **AWS 账户**才能使用 **AWS Athena**。
- 您应该拥有 **IAM 角色**,它允许 AWS Athena 访问您来自 Amazon S3 的数据。
- 您应该将您的 **数据存储在 Amazon S3 中**。
满足这些先决条件后,请按照以下步骤设置您的 AWS Athena 环境:
步骤 1:登录 AWS 控制台
首先,您需要登录 AWS 管理控制台。然后导航到 Amazon Athena 服务。您也可以在搜索栏中搜索 Athena。
步骤 2:创建 S3 存储桶
在运行查询之前,必须将您的数据存储在 Amazon S3 中。这是因为 AWS Athena 直接从 S3 查询数据。
如果您尚未创建存储桶,则首先通过转到 S3 服务并单击 **“创建存储桶”** 按钮来创建它。
步骤 3:配置 AWS Glue 数据目录
AWS Athena 需要一个数据目录来定义数据集的结构。为此,建议配置 AWS Glue 数据目录。
AWS Glue 可以自动与 Athena 集成,并帮助您将数据组织成表。在 AWS Glue 中,您需要创建一个爬虫,它扫描您的 S3 数据并在 Athena 数据目录中创建表架构。
步骤 4:设置 IAM 权限
Aws Athena 需要权限才能访问 S3 和其他 AWS 服务。您需要创建或分配一个具有 Athena 访问您的 S3 存储桶和 Glue 数据目录所需权限的 IAM 角色。
在 AWS Athena 中创建您的第一个查询
现在,您已经设置了 AWS Athena 环境,您可以准备在 Athena 中创建您的第一个查询。在 AWS Athena 中创建查询是一个非常简单的过程。它允许您毫不费力地分析数据。
按照以下步骤在 Athena 中创建您的第一个查询:
步骤 1:打开 Athena 控制台
首先,登录您的 AWS 管理控制台并导航到 Athena 服务。
步骤 2:选择您的数据库
接下来,打开 Athena 查询编辑器。现在选择存储数据所在的数据库。此数据库应包含您的表。
查看以下图像,其中我们选择了名为 **“tutorialpoint”** 的数据库:
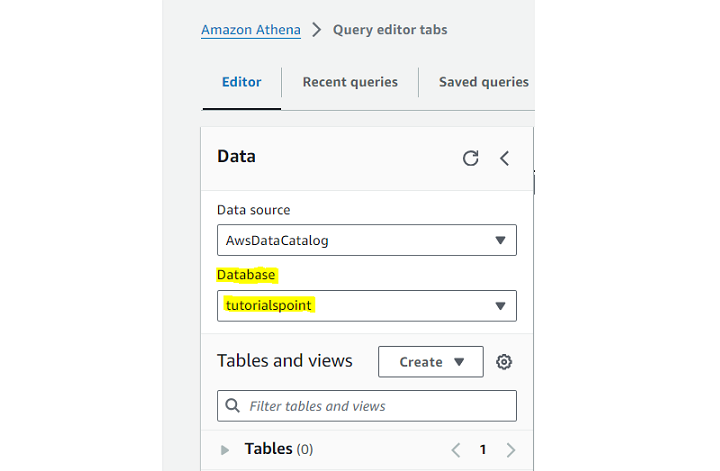
步骤 3:编写您的 SQL 查询
现在,您可以开始编写 SQL 查询了。使用您已创建并保存在所选数据库中的表。
步骤 4:运行查询
编写查询后,要运行它,请单击 **“运行查询”** 按钮。AWS Athena 将执行您的 SQL 语句并从指定的表中检索数据。
步骤 5:查看结果
查询执行完成后,它将在查询编辑器下方显示结果。您还可以将结果下载为各种格式,例如 CSV。
步骤 6:保存您的查询
您还可以保存您的查询,并在将来再次使用该查询。
通过按照上述步骤,您可以轻松地在 AWS Athena 中创建和运行您的第一个查询。
AWS Athena 如何工作?
以下流程图说明了 Amazon Athena 的工作原理:
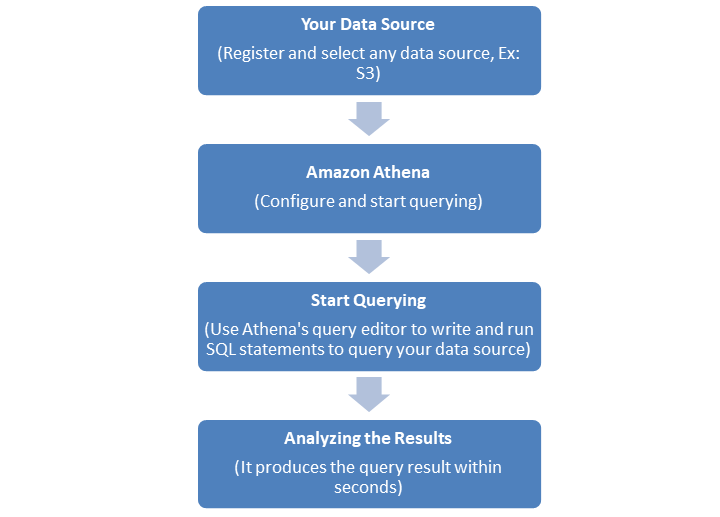
首先,您需要注册并 **选择您的数据源**。例如,**Amazon S3** 是一个流行的 AWS 数据源,您可以在其中存储您的表。
接下来,此数据源应与 Amazon Athena 集成。您首先需要配置 Athena。
配置并集成后,您可以使用 Athena 的查询编辑器编写和运行 SQL 语句来查询您的数据源。
Athena 将在几秒钟内提供查询结果。获取结果后,分析结果。您可以根据需要改进查询。
与 AWS S3 和其他 AWS 服务集成
将 AWS Athena 与 AWS S3 和其他 AWS 服务集成可以增强数据分析的功能并简化数据管道。
在本章的下一部分,我们提供了将 Athena 与 AWS S3 和其他 AWS 服务集成的分步指南。
将 AWS Athena 与 Amazon S3 集成
要将 AWS Athena 与 Amazon S3 集成,请按照以下步骤操作:
上传数据
首先,将您的数据集存储在 Amazon S3 中。Athena 可以直接从各种格式(如 CSV、JSON、Parquet、ORC 和 Avro)查询数据。
文件夹结构
接下来,您需要使用文件夹结构(如 **s3://your-bucket/folder/subfolder/data.csv**)组织您的数据。这使得查询更简单。
在 S3 中创建表和运行查询
现在,您可以创建表并在存储在 Amazon S3 中的数据上运行查询。
将 AWS Athena 与 AWS Glue 集成
要将 AWS Athena 与 AWS Glue 集成,请按照以下步骤操作:
设置 Glue 数据目录
首先,设置 AWS Glue 数据目录。它可以自动发现和编目您在 Amazon S3 中的数据。Glue 目录充当 Aws Athena 的集中式元数据存储库。
配置爬虫
接下来,我们需要配置一个 Glue 爬虫。为此,首先创建一个 Glue 爬虫并指定您的 Amazon S3 存储桶位置。Glue 爬虫扫描数据并创建元数据表。
使用 Athena 查询数据
Glue 编目您的数据后,表将自动显示在 AWS Athena 查询编辑器中。现在,您可以通过简单地选择表来查询数据。例如,一个简单的查询如下所示:
SELECT * FROM glue_catalog_database.table_name WHERE condition;
转换数据
AWS Glue 可用于 ETL 任务。您可以编写 Glue 作业,这些作业处理 Amazon S3 中的原始数据并将清理后的数据存储回 Amazon S3。
将 AWS Athena 与 AWS Lambda 集成
要将 AWS Athena 与 AWS Lambda 集成,请按照以下步骤操作:
创建 Lambda 函数
首先,编写一个 Lambda 函数,该函数使用 AWS SDK 触发 AWS Athena 查询。例如,S3 事件(如新文件上传)。
示例
查看以下示例:
import boto3
athena_client = boto3.client('athena')
def lambda_handler(event, context):
response = athena_client.start_query_execution(
QueryString='SELECT * FROM your_table LIMIT 10;',
QueryExecutionContext={
'Database': 'your_database'
},
ResultConfiguration={
'OutputLocation': 's3://your-output-bucket/'
}
)
return response
自动化事件驱动的查询
您还可以配置 Lambda 函数以根据事件运行 Aws Athena 查询。例如,事件可以是新数据上传到 S3。此集成允许用户进行实时或计划的数据处理。
将 AWS Athena 与 Amazon CloudWatch 集成
要将 AWS Athena 与 Amazon CloudWatch 集成,请按照以下步骤操作:
设置 CloudWatch 日志
首先,您需要设置 CloudWatch 日志。为此,请转到 Athena 设置并启用 CloudWatch 日志以监控查询执行。
跟踪查询性能
启用后,CloudWatch 允许您监控查询性能、执行时间和故障。它可以帮助您随着时间的推移优化成本和性能。
为查询失败设置警报
最后,您可以设置 CloudWatch 警报,当 Athena 查询失败或执行时间超过某个阈值时通知您。创建警报可确保可靠的数据处理。
AWS Athena - 编写 SQL 查询
在 AWS Athena 中运行任何查询之前,您需要创建一个引用 Amazon S3 中数据的表。Athena 使用按需架构方法,这意味着您在查询数据时定义数据结构,而不是在存储数据时定义。
让我们了解在 Athena 中创建表的步骤:
登录 AWS Athena 控制台
首先,从您的 AWS 管理控制台访问 Athena。
定义表架构
编写一个 SQL 查询来定义表结构。例如:
CREATE EXTERNAL TABLE IF NOT EXISTS your_table_name ( column1 STRING, column2 INT ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LOCATION 's3://your-bucket/folder/';
执行查询
现在,在 Athena 查询编辑器中运行此查询以创建表。这将允许您引用指定 S3 存储桶中的数据。
在 Athena 中运行基本 SQL 查询
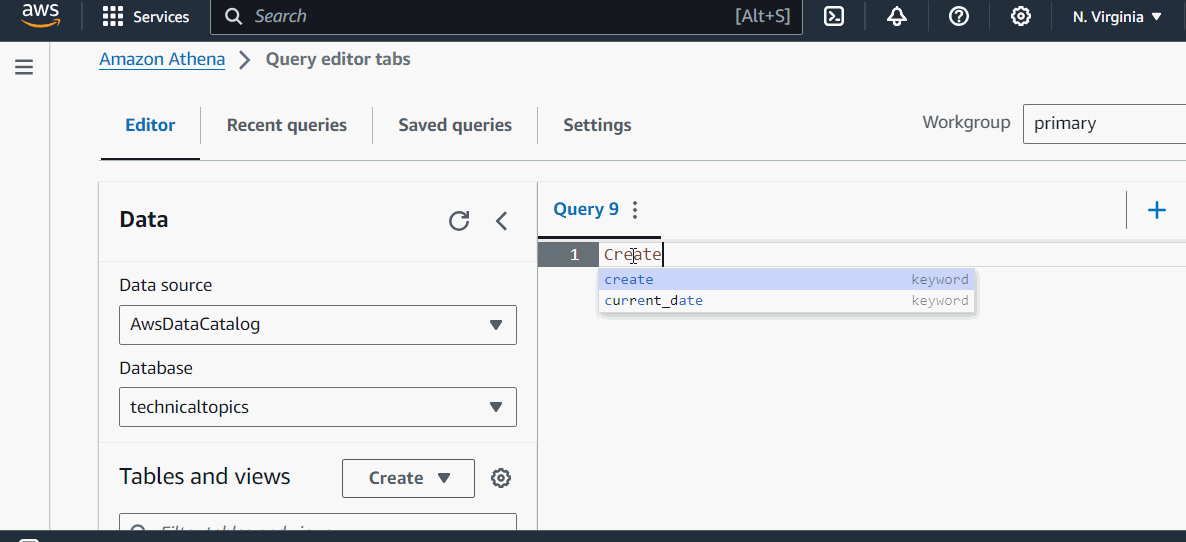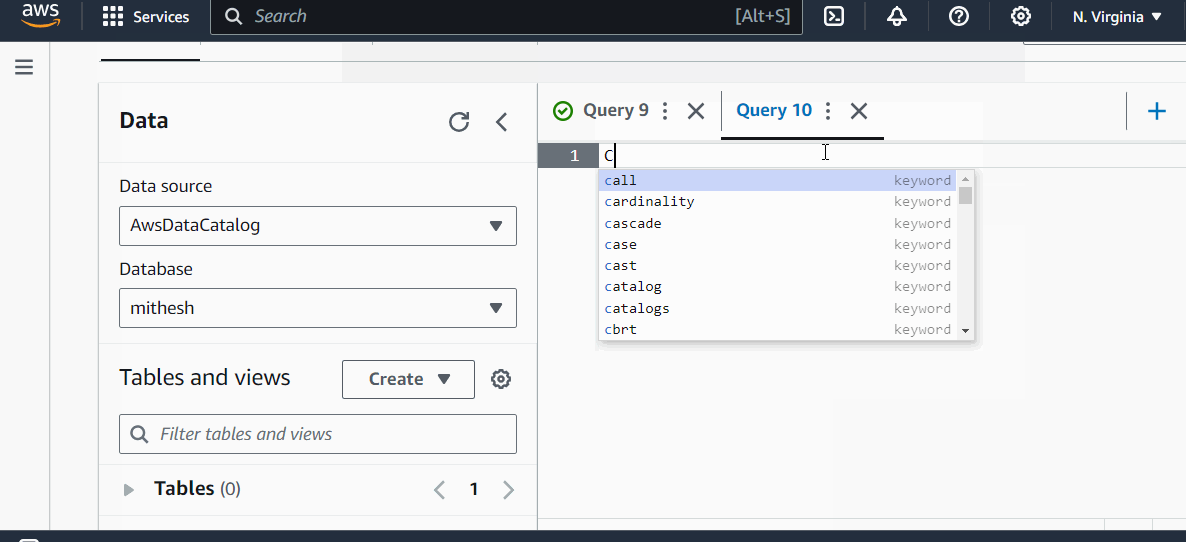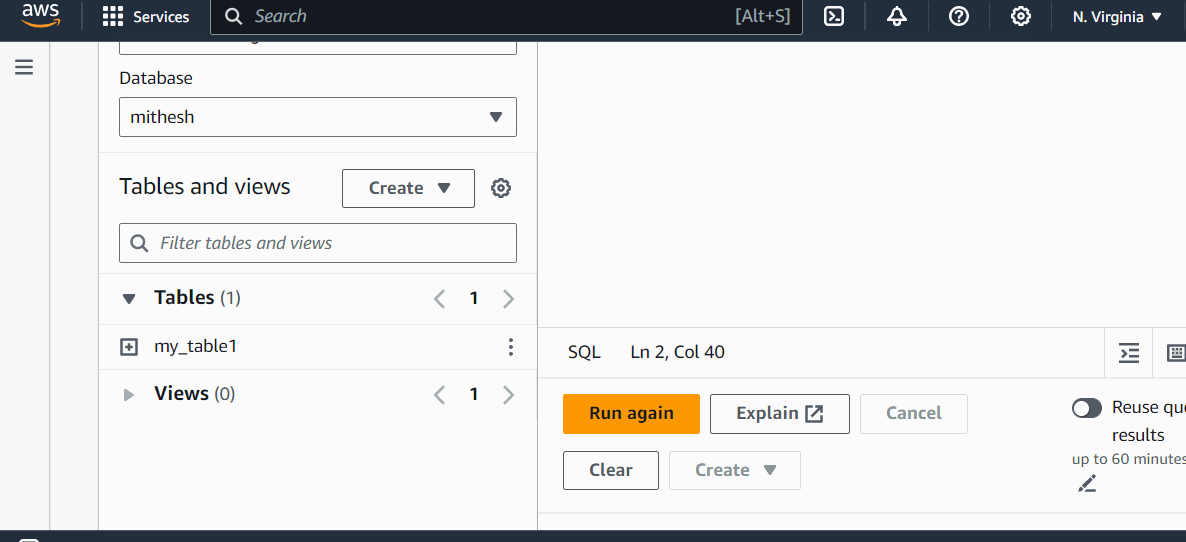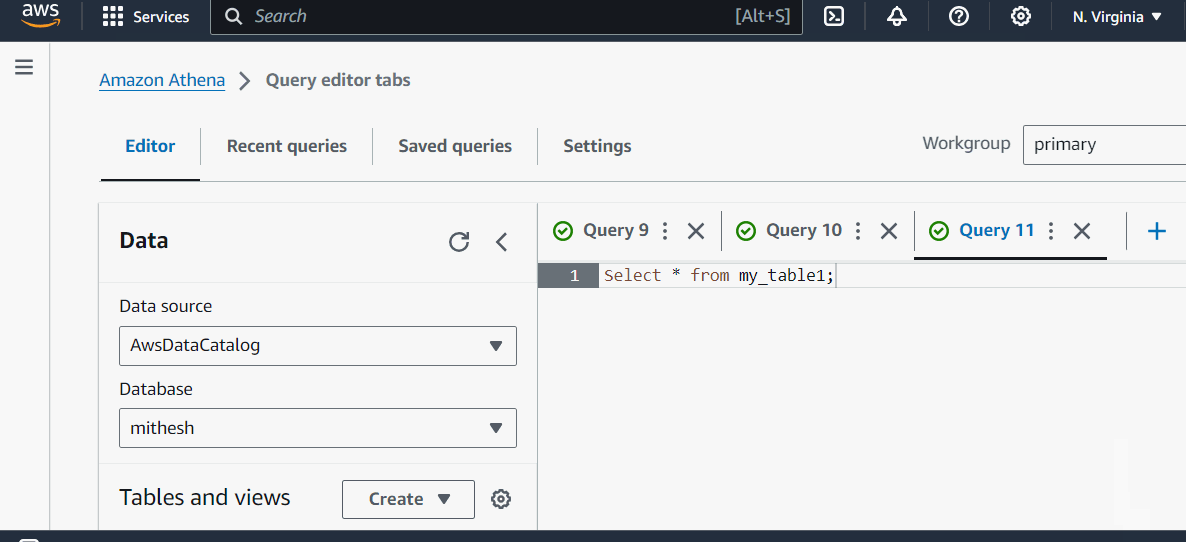
创建表后,您可以开始运行 SQL 查询来分析您的数据。Athena 支持标准 SQL,这使得熟悉 SQL 的用户可以轻松地编写查询。下面是一个简单查询示例:
SELECT * FROM your_table_name LIMIT 10;
此查询将从指定的表中获取前 10 行。您还可以像在任何基于 SQL 的数据库中一样过滤数据、连接多个表和使用聚合函数。
示例
让我们借助一个示例来理解它。在这里,我们在 Athena 查询编辑器中创建了一个数据库、一个表,然后对该表运行了一个查询:
AWS Athena - 性能优化
AWS Athena 是一种无服务器查询服务,允许您使用标准 SQL 分析存储在 Amazon S3 中的数据。但是,当我们处理大型数据集时,优化查询性能变得非常重要,以确保更快的执行时间并降低成本。
在本章中,我们重点介绍了一些提高 AWS Athena 中查询性能的最佳实践。
对您的数据进行分区
分区是优化 AWS Athena 中查询性能最有效的方法之一。您可以根据日期、区域或产品类别等列将数据划分为子集。它的好处是 AWS Athena 只扫描相关的分区,而不是整个数据集,这可以大大减少查询时间和扫描的数据量。
如何对数据进行分区?
您可以在创建表时使用 PARTITIONED BY 子句。
示例
查看以下示例:
CREATE EXTERNAL TABLE IF NOT EXISTS your_table_name ( column1 STRING, column2 INT ) PARTITIONED BY (year STRING, month STRING) LOCATION 's3://your-bucket/folder/';
创建表后,使用 MSCK REPAIR TABLE 命令加载分区,如下所示:
MSCK REPAIR TABLE your_table_name;
优化文件大小和格式
为了优化查询,您应该选择正确的文件大小和数据格式。让我们看看在查询时关于文件大小和文件格式的一些重要事项:
关于文件大小的重要事项
- Aws Athena 处理多个小文件的效率低下,因此小文件会导致更高的成本。因此,文件不应该太小。
- 另一方面,非常大的文件可能会降低性能,因为它们需要更长的时间来读取和处理。
- 建议将文件大小保持在128 MB 到 1 GB 之间,以在效率和性能之间取得平衡。
关于文件格式的重要事项
列式格式(如 Parquet 和 ORC)非常适合 AWS Athena。这些格式按列而不是按行存储数据,这意味着 Athena 只读取您查询的列。
例如,如果您只查询包含 10 列的数据集中 3 列,则列式格式将只扫描所需的 3 列。这使得查询更快并减少了扫描的数据量。
Parquet 和ORC 等格式还支持数据压缩,这可以进一步提高性能。
使用压缩
您应该在将数据存储到 Amazon S3 之前对其进行压缩,因为它可以提高 AWS Athena 中的查询性能。众所周知,压缩减少了数据的大小,这意味着 Athena 在执行查询时需要扫描的数据更少。
Gzip、Snappy 和Zlib 是 Athena 中支持的一些压缩格式。
使用选择性查询限制数据扫描
如果您想优化性能并降低查询成本,请尝试不要使用 Athena 中的SELECT* 查询扫描整个表。相反,始终只选择分析所需的特定列。您扫描的数据越多,Athena 处理查询所需的时间和资源就越多,这将增加执行时间和成本。
例如,使用如下查询代替SELECT*:
SELECT column1, column2 FROM your_table WHERE condition;
对重复查询使用缓存
AWS Athena 为我们提供了结果缓存功能,该功能可以存储查询结果长达 45 天。如果您在 45 天内运行相同的查询,Athena 将立即返回缓存的结果,而无需重新处理数据,这意味着它不需要扫描新数据。
此出色的功能不仅提高了性能,还降低了查询成本。
AWS Athena - 数据安全
当您使用 AWS Athena 等云服务时,数据安全成为重中之重。在本章中,我们重点介绍了 AWS Athena 中数据安全的一些关键方面:
管理访问控制和权限
AWS Athena 与 AWS Identity and Access Management (IAM) 集成,使您可以控制谁可以访问您的数据以及他们可以执行哪些操作。
正确配置“访问控制和权限”可确保只有授权用户才能查询或管理 Athena 中的数据。
使用 AWS IAM 进行访问控制
IAM 是管理对 AWS 资源访问的主要工具之一。使用 IAM,您可以创建用户帐户、分配角色并根据工作职能定义权限。
让我们看看如何使用 IAM 管理“访问控制”:
创建 IAM 角色和用户
AWS Athena 允许您为具有特定权限的不同用户创建 IAM 角色。例如,数据分析师只需要访问查询数据权限,而数据工程师则需要创建和修改表的完全访问权限。
使用细粒度权限
在 AWS Athena 中,您还可以设置细粒度权限以限制对特定操作的访问,例如查询数据或更改表结构。
例如,IAM 策略可以授予运行 SQL 查询的权限,但阻止用户修改表。
限制对 Amazon S3 的访问
您可以应用存储桶策略,允许特定的 IAM 用户或角色仅访问某些数据集或文件夹。
数据加密
AWS Athena 中数据安全的另一个重要组成部分是加密。它确保您的数据在静态和传输过程中都受到保护。
Athena 提供多种加密选项,可帮助您保护敏感数据并满足监管合规性要求。
加密静态数据
下面是您可以用来加密存储在 Amazon S3 中的数据的两种方法:
- S3 托管加密 (SSE-S3)
- AWS Key Management Service (KMS)
加密传输中的数据
除了静态加密外,AWS Athena 还可以使用安全套接字层 (SSL) 加密来加密传输中的数据。
SSL 确保在 Athena 和其他服务(例如 Amazon S3)之间传输的任何数据都已加密。
AWS Athena 中的合规性功能
为了满足合规性要求,AWS Athena 还与各种 AWS 服务集成:
AWS CloudTrail
AWS CloudTrail 记录在 Athena 中执行的所有操作。这些日志提供了详细的审计跟踪,可帮助您跟踪用户活动并检测未经授权的访问或可疑行为。
AWS Config
AWS Config 可帮助您监控 Athena 配置中的任何更改。它确保符合组织策略。
AWS Athena - 成本管理
AWS Athena 采用按使用付费定价模式,为用户提供了极大的灵活性。在本章中,我们将简要解释 Athena 如何向您收费以及您可以遵循的策略以最大程度地降低 AWS Athena 的成本。
了解 Athena 定价和查询成本
AWS Athena 根据查询扫描的数据量收费。它扫描的数据越多,成本就越高。您需要按扫描的数据量(TB)付费。目前,扫描 1 TB 数据的成本约为5 美元,但这可能因区域而异。
例如,假设您查询 500 GB 的数据集,并且 Athena 需要扫描整个数据集,则成本将为2.50 美元。
Athena 定价如何运作?
Athena 定价主要取决于以下三个因素:
扫描的数据
每次运行查询时,Athena 都需要从 Amazon S3 扫描相关数据。总成本将基于查询期间扫描了多少数据。
未压缩数据
未压缩数据占用更多空间。这意味着当您对非结构化数据运行查询时,Athena 将需要扫描更多数据。这会增加成本。
存储在 S3 中的结果
运行查询时,查询结果将保存到 S3。您需要支付标准的 S3 存储成本。
最大程度地降低 AWS Athena 成本的策略
以下是一些您可以实施的策略,以最大程度地降低 AWS Athena 的成本:
- 使用压缩来减小数据大小
- 对您的数据进行分区
- 仅选择所需的列
- 优化文件大小
- 使用缓存限制查询结果
- 监控查询使用情况和成本
了解 Athena 成本的计算方式并应用策略来最大程度地降低这些成本对于有效的成本管理至关重要。