- Beautiful Soup 教程
- Beautiful Soup - 首页
- Beautiful Soup - 概述
- Beautiful Soup - 网页抓取
- Beautiful Soup - 安装
- Beautiful Soup - 解析页面
- Beautiful Soup - 对象类型
- Beautiful Soup - 检查数据源
- Beautiful Soup - 抓取HTML内容
- Beautiful Soup - 通过标签导航
- Beautiful Soup - 通过ID查找元素
- Beautiful Soup - 通过类查找元素
- Beautiful Soup - 通过属性查找元素
- Beautiful Soup - 搜索树结构
- Beautiful Soup - 修改树结构
- Beautiful Soup - 解析文档的一部分
- Beautiful Soup - 查找元素的所有子元素
- Beautiful Soup - 使用CSS选择器查找元素
- Beautiful Soup - 查找所有注释
- Beautiful Soup - 从HTML中抓取列表
- Beautiful Soup - 从HTML中抓取段落
- BeautifulSoup - 从HTML中抓取链接
- Beautiful Soup - 获取所有HTML标签
- Beautiful Soup - 获取标签内的文本
- Beautiful Soup - 查找所有标题
- Beautiful Soup - 提取标题标签
- Beautiful Soup - 提取邮箱ID
- Beautiful Soup - 抓取嵌套标签
- Beautiful Soup - 解析表格
- Beautiful Soup - 选择第n个子元素
- Beautiful Soup - 通过标签内的文本搜索
- Beautiful Soup - 删除HTML标签
- Beautiful Soup - 删除所有样式
- Beautiful Soup - 删除所有脚本
- Beautiful Soup - 删除空标签
- Beautiful Soup - 删除子元素
- Beautiful Soup - find vs find_all
- Beautiful Soup - 指定解析器
- Beautiful Soup - 比较对象
- Beautiful Soup - 复制对象
- Beautiful Soup - 获取标签位置
- Beautiful Soup - 编码
- Beautiful Soup - 输出格式
- Beautiful Soup - 美化输出
- Beautiful Soup - NavigableString 类
- Beautiful Soup - 将对象转换为字符串
- Beautiful Soup - 将HTML转换为文本
- Beautiful Soup - 解析XML
- Beautiful Soup - 错误处理
- Beautiful Soup - 故障排除
- Beautiful Soup - 移植旧代码
- Beautiful Soup - 函数参考
- Beautiful Soup - contents 属性
- Beautiful Soup - children 属性
- Beautiful Soup - string 属性
- Beautiful Soup - strings 属性
- Beautiful Soup - stripped_strings 属性
- Beautiful Soup - descendants 属性
- Beautiful Soup - parent 属性
- Beautiful Soup - parents 属性
- Beautiful Soup - next_sibling 属性
- Beautiful Soup - previous_sibling 属性
- Beautiful Soup - next_siblings 属性
- Beautiful Soup - previous_siblings 属性
- Beautiful Soup - next_element 属性
- Beautiful Soup - previous_element 属性
- Beautiful Soup - next_elements 属性
- Beautiful Soup - previous_elements 属性
- Beautiful Soup - find 方法
- Beautiful Soup - find_all 方法
- Beautiful Soup - find_parents 方法
- Beautiful Soup - find_parent 方法
- Beautiful Soup - find_next_siblings 方法
- Beautiful Soup - find_next_sibling 方法
- Beautiful Soup - find_previous_siblings 方法
- Beautiful Soup - find_previous_sibling 方法
- Beautiful Soup - find_all_next 方法
- Beautiful Soup - find_next 方法
- Beautiful Soup - find_all_previous 方法
- Beautiful Soup - find_previous 方法
- Beautiful Soup - select 方法
- Beautiful Soup - append 方法
- Beautiful Soup - extend 方法
- Beautiful Soup - NavigableString 方法
- Beautiful Soup - new_tag 方法
- Beautiful Soup - insert 方法
- Beautiful Soup - insert_before 方法
- Beautiful Soup - insert_after 方法
- Beautiful Soup - clear 方法
- Beautiful Soup - extract 方法
- Beautiful Soup - decompose 方法
- Beautiful Soup - replace_with 方法
- Beautiful Soup - wrap 方法
- Beautiful Soup - unwrap 方法
- Beautiful Soup - smooth 方法
- Beautiful Soup - prettify 方法
- Beautiful Soup - encode 方法
- Beautiful Soup - decode 方法
- Beautiful Soup - get_text 方法
- Beautiful Soup - diagnose 方法
- Beautiful Soup 有用资源
- Beautiful Soup - 快速指南
- Beautiful Soup - 有用资源
- Beautiful Soup - 讨论
Beautiful Soup - 概述
在当今世界,我们拥有大量的非结构化数据/信息(主要是网页数据)可免费获取。有时这些免费数据易于阅读,有时则不然。无论您的数据如何呈现,网页抓取都是将非结构化数据转换为易于阅读和分析的结构化数据非常有用的工具。换句话说,网页抓取是一种收集、组织和分析海量数据的方法。那么,让我们首先了解什么是网页抓取。
Beautiful Soup 简介
Beautiful Soup 是一个 Python 库,其名称源于刘易斯·卡罗尔在《爱丽丝梦游仙境》中同名诗歌。Beautiful Soup 是一个 Python 包,顾名思义,它解析不需要的数据,并通过修复错误的 HTML 并以易于遍历的 XML 结构呈现给我们,从而帮助组织和格式化混乱的网页数据。
简而言之,Beautiful Soup 是一个 Python 包,允许我们从 HTML 和 XML 文档中提取数据。
HTML 树结构
在深入了解 Beautiful Soup 提供的功能之前,让我们首先了解 HTML 树结构。
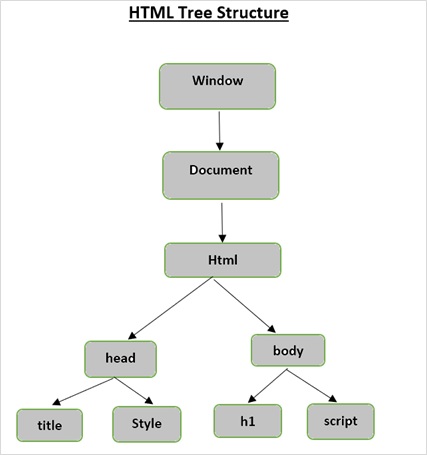
文档树中的根元素是 html,它可以有父节点、子节点和兄弟节点,这由它在树结构中的位置决定。要在 HTML 元素、属性和文本之间移动,您必须在树结构中的节点之间移动。
让我们假设网页如下所示:

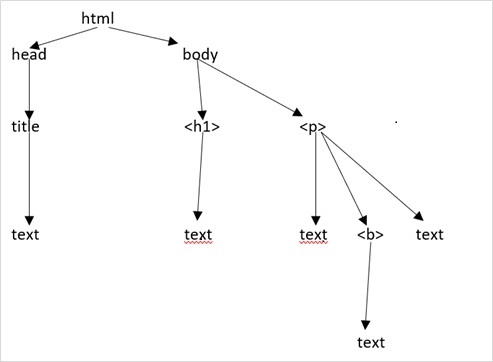
这转换为如下所示的 html 文档:
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<h1>Tutorialspoint Online Library</h1>
<p><b>It's all Free</b></p>
</body>
</html>
这仅仅意味着,对于上面的 html 文档,我们有如下所示的 html 树结构:
广告