- Beautiful Soup 教程
- Beautiful Soup - 首页
- Beautiful Soup - 概述
- Beautiful Soup - 网页抓取
- Beautiful Soup - 安装
- Beautiful Soup - 解析页面
- Beautiful Soup - 对象类型
- Beautiful Soup - 检查数据源
- Beautiful Soup - 抓取 HTML 内容
- Beautiful Soup - 通过标签导航
- Beautiful Soup - 通过 ID 查找元素
- Beautiful Soup - 通过 Class 查找元素
- Beautiful Soup - 通过属性查找元素
- Beautiful Soup - 搜索树结构
- Beautiful Soup - 修改树结构
- Beautiful Soup - 解析文档的一部分
- Beautiful Soup - 查找元素的所有子元素
- Beautiful Soup - 使用 CSS 选择器查找元素
- Beautiful Soup - 查找所有注释
- Beautiful Soup - 从 HTML 中抓取列表
- Beautiful Soup - 从 HTML 中抓取段落
- BeautifulSoup - 从 HTML 中抓取链接
- Beautiful Soup - 获取所有 HTML 标签
- Beautiful Soup - 获取标签内的文本
- Beautiful Soup - 查找所有标题
- Beautiful Soup - 提取标题标签
- Beautiful Soup - 提取电子邮件 ID
- Beautiful Soup - 抓取嵌套标签
- Beautiful Soup - 解析表格
- Beautiful Soup - 选择第 n 个子元素
- Beautiful Soup - 通过标签内的文本搜索
- Beautiful Soup - 移除 HTML 标签
- Beautiful Soup - 移除所有样式
- Beautiful Soup - 移除所有脚本
- Beautiful Soup - 移除空标签
- Beautiful Soup - 移除子元素
- Beautiful Soup - find 与 find_all 的区别
- Beautiful Soup - 指定解析器
- Beautiful Soup - 比较对象
- Beautiful Soup - 复制对象
- Beautiful Soup - 获取标签位置
- Beautiful Soup - 编码
- Beautiful Soup - 输出格式化
- Beautiful Soup - 美化输出
- Beautiful Soup - NavigableString 类
- Beautiful Soup - 将对象转换为字符串
- Beautiful Soup - 将 HTML 转换为文本
- Beautiful Soup - 解析 XML
- Beautiful Soup - 错误处理
- Beautiful Soup - 故障排除
- Beautiful Soup - 移植旧代码
- Beautiful Soup - 函数参考
- Beautiful Soup - contents 属性
- Beautiful Soup - children 属性
- Beautiful Soup - string 属性
- Beautiful Soup - strings 属性
- Beautiful Soup - stripped_strings 属性
- Beautiful Soup - descendants 属性
- Beautiful Soup - parent 属性
- Beautiful Soup - parents 属性
- Beautiful Soup - next_sibling 属性
- Beautiful Soup - previous_sibling 属性
- Beautiful Soup - next_siblings 属性
- Beautiful Soup - previous_siblings 属性
- Beautiful Soup - next_element 属性
- Beautiful Soup - previous_element 属性
- Beautiful Soup - next_elements 属性
- Beautiful Soup - previous_elements 属性
- Beautiful Soup - find 方法
- Beautiful Soup - find_all 方法
- Beautiful Soup - find_parents 方法
- Beautiful Soup - find_parent 方法
- Beautiful Soup - find_next_siblings 方法
- Beautiful Soup - find_next_sibling 方法
- Beautiful Soup - find_previous_siblings 方法
- Beautiful Soup - find_previous_sibling 方法
- Beautiful Soup - find_all_next 方法
- Beautiful Soup - find_next 方法
- Beautiful Soup - find_all_previous 方法
- Beautiful Soup - find_previous 方法
- Beautiful Soup - select 方法
- Beautiful Soup - append 方法
- Beautiful Soup - extend 方法
- Beautiful Soup - NavigableString 方法
- Beautiful Soup - new_tag 方法
- Beautiful Soup - insert 方法
- Beautiful Soup - insert_before 方法
- Beautiful Soup - insert_after 方法
- Beautiful Soup - clear 方法
- Beautiful Soup - extract 方法
- Beautiful Soup - decompose 方法
- Beautiful Soup - replace_with 方法
- Beautiful Soup - wrap 方法
- Beautiful Soup - unwrap 方法
- Beautiful Soup - smooth 方法
- Beautiful Soup - prettify 方法
- Beautiful Soup - encode 方法
- Beautiful Soup - decode 方法
- Beautiful Soup - get_text 方法
- Beautiful Soup - diagnose 方法
- Beautiful Soup 有用资源
- Beautiful Soup 快速指南
- Beautiful Soup - 有用资源
- Beautiful Soup - 讨论
Beautiful Soup 快速指南
Beautiful Soup - 概述
在当今世界,我们拥有大量非结构化数据/信息(主要是网络数据)可供免费使用。有时这些免费数据易于阅读,有时则不然。无论你的数据如何呈现,网页抓取都是一个非常有用的工具,可以将非结构化数据转换为更易于阅读和分析的结构化数据。换句话说,网页抓取是一种收集、整理和分析这些海量数据的方法。所以,让我们首先了解什么是网页抓取。
Beautiful Soup 简介
Beautiful Soup 是一个 Python 库,其名称来源于刘易斯·卡罗尔在《爱丽丝梦游仙境》中同名的一首诗。Beautiful Soup 是一个 Python 包,顾名思义,它解析不需要的数据,并通过修复不良 HTML 并以易于遍历的 XML 结构呈现给我们,从而帮助整理和格式化凌乱的网络数据。
简而言之,Beautiful Soup 是一个 Python 包,它允许我们从 HTML 和 XML 文档中提取数据。
HTML 树结构
在深入了解 Beautiful Soup 提供的功能之前,让我们首先了解 HTML 树结构。
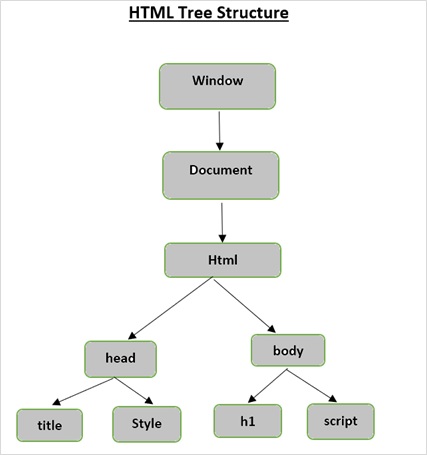
文档树中的根元素是 html,它可以有父节点、子节点和兄弟节点,这由它在树结构中的位置决定。要在 HTML 元素、属性和文本之间移动,必须在树结构中的节点之间移动。
假设网页如下所示:

它转换为以下 HTML 文档:
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<h1>Tutorialspoint Online Library</h1>
<p><b>It's all Free</b></p>
</body>
</html>
这仅仅意味着,对于上面的 HTML 文档,我们有如下 HTML 树结构:
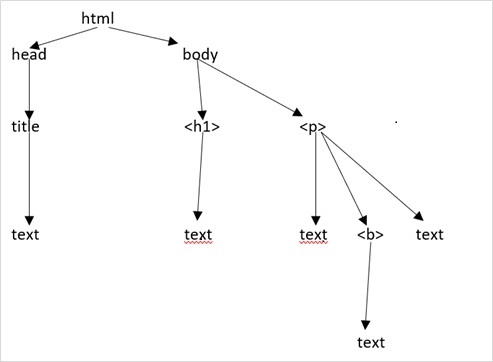
Beautiful Soup - 网页抓取
抓取仅仅是一个提取(从各种来源)、复制和筛选数据的过程。
当我们从网络(例如从网页或网站)抓取或提取数据或 Feed 时,称为网页抓取。
因此,网页抓取(也称为网页数据提取或网页收集)是从网络中提取数据。简而言之,网页抓取为开发人员提供了一种从互联网收集和分析数据的方法。
为什么要进行网页抓取?
网页抓取提供了一种强大的工具来自动化人类在浏览时执行的大部分操作。企业以多种方式使用网页抓取:
研究数据
智能分析师(如研究人员或记者)使用网页抓取器,而不是手动从网站收集和清理数据。
产品、价格和受欢迎程度比较
目前有一些服务使用网页抓取器从众多在线网站收集数据,并将其用于比较产品的受欢迎程度和价格。
SEO 监控
有许多 SEO 工具,如 Ahrefs、Seobility、SEMrush 等,用于竞争对手分析和从客户网站提取数据。
搜索引擎
一些大型 IT 公司的业务完全依赖于网页抓取。
销售和营销
通过网页抓取收集的数据可供营销人员分析不同的细分市场和竞争对手,或供销售专家用于销售内容营销或社交媒体推广服务。
为什么选择 Python 进行网页抓取?
Python 是最流行的网页抓取语言之一,因为它可以非常轻松地处理大多数与网络爬取相关的任务。
以下是选择 Python 进行网页抓取的一些原因:
易用性
大多数开发人员都认为 Python 非常易于编码。我们不必在任何地方使用花括号“{}”或分号“;” ,这使得它在开发网页抓取器时更易于阅读和使用。
强大的库支持
Python 为不同的需求提供了大量的库,因此它适用于网页抓取以及数据可视化、机器学习等。
易于理解的语法
Python 是一种非常易读的编程语言,因为 Python 语法易于理解。Python 非常具有表现力,代码缩进帮助用户区分代码中的不同块或范围。
动态类型语言
Python 是一种动态类型语言,这意味着分配给变量的数据会告诉我们它是什么类型的变量。它节省了大量时间,并使工作更快。
庞大的社区
Python 社区非常庞大,无论你在编写代码时遇到什么问题,都可以获得帮助。
Beautiful Soup - 安装
Beautiful Soup 是一个库,它简化了从网页抓取信息的过程。它位于 HTML 或 XML 解析器的顶部,提供了 Python 风格的习惯用法来迭代、搜索和修改解析树。
BeautifulSoup 包不是 Python 标准库的一部分,因此必须安装它。在安装最新版本之前,让我们根据 Python 的推荐方法创建一个虚拟环境。
虚拟环境允许我们为特定项目创建 Python 的隔离工作副本,而不会影响外部设置。
我们将使用 Python 标准库中的 venv 模块来创建虚拟环境。PIP 默认包含在 Python 3.4 或更高版本中。
使用以下命令在 Windows 上创建虚拟环境
C:\uses\user\>python -m venv myenv
在 Ubuntu Linux 上,在创建虚拟环境之前,如果需要,请更新 APT 存储库并安装 venv
mvl@GNVBGL3:~ $ sudo apt update && sudo apt upgrade -y mvl@GNVBGL3:~ $ sudo apt install python3-venv
然后使用以下命令创建虚拟环境
mvl@GNVBGL3:~ $ sudo python3 -m venv myenv
你需要激活虚拟环境。在 Windows 上使用以下命令
C:\uses\user\>cd myenv C:\uses\user\myenv>scripts\activate (myenv) C:\Users\users\user\myenv>
在 Ubuntu Linux 上,使用以下命令激活虚拟环境
mvl@GNVBGL3:~$ cd myenv mvl@GNVBGL3:~/myenv$ source bin/activate (myenv) mvl@GNVBGL3:~/myenv$
虚拟环境的名称显示在括号中。现在它已激活,我们可以在其中安装 BeautifulSoup 了。
(myenv) mvl@GNVBGL3:~/myenv$ pip3 install beautifulsoup4
Collecting beautifulsoup4
Downloading beautifulsoup4-4.12.2-py3-none-any.whl (142 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
143.0/143.0 KB 325.2 kB/s eta 0:00:00
Collecting soupsieve>1.2
Downloading soupsieve-2.4.1-py3-none-any.whl (36 kB)
Installing collected packages: soupsieve, beautifulsoup4
Successfully installed beautifulsoup4-4.12.2 soupsieve-2.4.1
请注意,Beautifulsoup4 的最新版本是 4.12.2,需要 Python 3.8 或更高版本。
如果你没有安装 easy_install 或 pip,可以下载 Beautiful Soup 4 源代码压缩包并使用 setup.py 安装它。
(myenv) mvl@GNVBGL3:~/myenv$ python setup.py install
要检查 Beautifulsoup 是否已正确安装,请在 Python 终端中输入以下命令:
>>> import bs4 >>> bs4.__version__ '4.12.2'
如果安装不成功,你将收到 ModuleNotFoundError 错误。
你还需要安装 requests 库。它是 Python 的 HTTP 库。
pip3 install requests
安装解析器
默认情况下,Beautiful Soup 支持 Python 标准库中包含的 HTML 解析器,但它也支持许多外部第三方 Python 解析器,如 lxml 解析器或 html5lib 解析器。
要安装 lxml 或 html5lib 解析器,请使用以下命令
pip3 install lxml pip3 install html5lib
这些解析器各有优缺点,如下所示:
解析器:Python 的 html.parser
用法 − BeautifulSoup(markup, "html.parser")
优点
- 内置
- 速度不错
- 宽容(从 Python 3.2 开始)
缺点
- 速度不如 lxml,宽容度不如 html5lib。
解析器:lxml 的 HTML 解析器
用法 − BeautifulSoup(markup, "lxml")
优点
- 非常快
- 宽松的
缺点
-
外部 C 依赖
解析器:lxml 的 XML 解析器
用法 − BeautifulSoup(markup, "lxml-xml")
或 BeautifulSoup(markup, "xml")
优点
- 非常快
- 目前唯一支持的 XML 解析器
缺点
- 外部 C 依赖
解析器:html5lib
用法 − BeautifulSoup(markup, "html5lib")
优点
- 极其宽松
- 以与网络浏览器相同的方式解析页面
- 创建有效的 HTML5
缺点
- 非常慢
- 外部 Python 依赖
Beautiful Soup - 解析页面
现在是时候在一个 html 页面中测试我们的 Beautiful Soup 包了(以网页 - https://tutorialspoint.com/index.htm 为例,您可以选择任何其他网页)并从中提取一些信息。
在下面的代码中,我们尝试从网页中提取标题 -
示例
from bs4 import BeautifulSoup import requests url = "https://tutorialspoint.com/index.htm" req = requests.get(url) soup = BeautifulSoup(req.content, "html.parser") print(soup.title)
输出
<title>Online Courses and eBooks Library<title>
一个常见的任务是从网页中提取所有 URL。为此,我们只需要添加下面的代码行 -
for link in soup.find_all('a'):
print(link.get('href'))
输出
下面显示了上述循环的部分输出 -
https://tutorialspoint.com/index.htm https://tutorialspoint.com/codingground.htm https://tutorialspoint.com/about/about_careers.htm https://tutorialspoint.com/whiteboard.htm https://tutorialspoint.com/online_dev_tools.htm https://tutorialspoint.com/business/index.asp https://tutorialspoint.com/market/teach_with_us.jsp https://#/tutorialspointindia https://www.instagram.com/tutorialspoint_/ https://twitter.com/tutorialspoint https://www.youtube.com/channel/UCVLbzhxVTiTLiVKeGV7WEBg https://tutorialspoint.com/categories/development https://tutorialspoint.com/categories/it_and_software https://tutorialspoint.com/categories/data_science_and_ai_ml https://tutorialspoint.com/categories/cyber_security https://tutorialspoint.com/categories/marketing https://tutorialspoint.com/categories/office_productivity https://tutorialspoint.com/categories/business https://tutorialspoint.com/categories/lifestyle https://tutorialspoint.com/latest/prime-packs https://tutorialspoint.com/market/index.asp https://tutorialspoint.com/latest/ebooks … …
要解析本地当前工作目录中存储的网页,请获取指向 html 文件的文件对象,并将其用作 BeautifulSoup() 构造函数的参数。
示例
from bs4 import BeautifulSoup
with open("index.html") as fp:
soup = BeautifulSoup(fp, 'html.parser')
print(soup)
输出
<html> <head> <title>Hello World</title> </head> <body> <h1 style="text-align:center;">Hello World</h1> </body> </html>
您还可以使用包含 HTML 脚本的字符串作为构造函数的参数,如下所示 -
from bs4 import BeautifulSoup
html = '''
<html>
<head>
<title>Hello World</title>
</head>
<body>
<h1 style="text-align:center;">Hello World</h1>
</body>
</html>
'''
soup = BeautifulSoup(html, 'html.parser')
print(soup)
Beautiful Soup 使用最佳可用的解析器来解析文档。除非另有指定,否则它将使用 HTML 解析器。
Beautiful Soup - 对象类型
当我们将 html 文档或字符串传递给 beautifulsoup 构造函数时,beautifulsoup 基本上将复杂的 html 页面转换为不同的 python 对象。下面我们将讨论 bs4 包中定义的四种主要类型的对象。
- 标签
- 可导航字符串
- BeautifulSoup
- 注释
标签对象
HTML 标签用于定义各种类型的內容。BeautifulSoup 中的标签对象对应于实际页面或文档中的 HTML 或 XML 标签。
示例
from bs4 import BeautifulSoup
soup = BeautifulSoup('<b class="boldest">TutorialsPoint</b>', 'lxml')
tag = soup.html
print (type(tag))
输出
<class 'bs4.element.Tag'>
标签包含许多属性和方法,标签的两个重要特征是其名称和属性。
名称 (tag.name)
每个标签都包含一个名称,可以通过“.name”作为后缀来访问。tag.name 将返回它所属的标签类型。
示例
from bs4 import BeautifulSoup
soup = BeautifulSoup('<b class="boldest">TutorialsPoint</b>', 'lxml')
tag = soup.html
print (tag.name)
输出
html
但是,如果我们更改标签名称,则 BeautifulSoup 生成的 HTML 标记中也会反映出来。
示例
from bs4 import BeautifulSoup
soup = BeautifulSoup('<b class="boldest">TutorialsPoint</b>', 'lxml')
tag = soup.html
tag.name = "strong"
print (tag)
输出
<strong><body><b class="boldest">TutorialsPoint</b></body></strong>
属性 (tag.attrs)
一个标签对象可以具有任意数量的属性。在上面的示例中,标签<b class="boldest">具有一个名为“class”的属性,其值为“boldest”。任何不是标签的东西,基本上都是一个属性,并且必须包含一个值。“attrs”返回属性及其值的字典。您也可以通过访问键来访问属性。
在下面的示例中,Beautifulsoup() 构造函数的字符串参数包含 HTML 输入标签。“attr”返回输入标签的属性。
示例
from bs4 import BeautifulSoup
soup = BeautifulSoup('<input type="text" name="name" value="Raju">', 'lxml')
tag = soup.input
print (tag.attrs)
输出
{'type': 'text', 'name': 'name', 'value': 'Raju'}
我们可以使用字典运算符或方法对标签的属性进行各种修改(添加/删除/修改)。
在下面的示例中,更新了 value 标签。更新后的 HTML 字符串显示了更改。
示例
from bs4 import BeautifulSoup
soup = BeautifulSoup('<input type="text" name="name" value="Raju">', 'lxml')
tag = soup.input
print (tag.attrs)
tag['value']='Ravi'
print (soup)
输出
<html><body><input name="name" type="text" value="Ravi"/></body></html>
我们添加了一个新的 id 标签,并删除了 value 标签。
示例
from bs4 import BeautifulSoup
soup = BeautifulSoup('<input type="text" name="name" value="Raju">', 'lxml')
tag = soup.input
tag['id']='nm'
del tag['value']
print (soup)
输出
<html><body><input id="nm" name="name" type="text"/></body></html>
多值属性
某些 HTML5 属性可以具有多个值。最常用的是 class 属性,它可以具有多个 CSS 值。其他包括“rel”、“rev”、“headers”、“accesskey”和“accept-charset”。Beautiful Soup 中的多值属性显示为列表。
示例
from bs4 import BeautifulSoup
css_soup = BeautifulSoup('<p class="body"></p>', 'lxml')
print ("css_soup.p['class']:", css_soup.p['class'])
css_soup = BeautifulSoup('<p class="body bold"></p>', 'lxml')
print ("css_soup.p['class']:", css_soup.p['class'])
输出
css_soup.p['class']: ['body'] css_soup.p['class']: ['body', 'bold']
但是,如果任何属性包含多个值,但它不是任何版本的 HTML 标准的多值属性,则 Beautiful Soup 将保留该属性 -
示例
from bs4 import BeautifulSoup
id_soup = BeautifulSoup('<p id="body bold"></p>', 'lxml')
print ("id_soup.p['id']:", id_soup.p['id'])
print ("type(id_soup.p['id']):", type(id_soup.p['id']))
输出
id_soup.p['id']: body bold type(id_soup.p['id']): <class 'str'>
可导航字符串对象
通常,某个字符串放置在某种类型的开始和结束标签中。浏览器的 HTML 引擎在呈现元素时会对字符串应用预期的效果。例如,在<b>Hello World</b>中,您会在<b>和</b>标签中间找到一个字符串,以便以粗体显示。
可导航字符串对象表示标签的内容。它是 bs4.element.NavigableString 类的对象。要访问内容,请将标签与“.string”一起使用。
示例
from bs4 import BeautifulSoup
soup = BeautifulSoup("<h2 id='message'>Hello, Tutorialspoint!</h2>", 'html.parser')
print (soup.string)
print (type(soup.string))
输出
Hello, Tutorialspoint! <class 'bs4.element.NavigableString'>
可导航字符串对象类似于 Python Unicode 字符串。它的一些功能支持遍历树和搜索树。可导航字符串可以使用 str() 函数转换为 Unicode 字符串。
示例
from bs4 import BeautifulSoup
soup = BeautifulSoup("<h2 id='message'>Hello, Tutorialspoint!</h2>",'html.parser')
tag = soup.h2
string = str(tag.string)
print (string)
输出
Hello, Tutorialspoint!
就像 Python 字符串是不可变的,可导航字符串也不能就地修改。但是,使用 replace_with() 将标签的内部字符串替换为另一个字符串。
示例
from bs4 import BeautifulSoup
soup = BeautifulSoup("<h2 id='message'>Hello, Tutorialspoint!</h2>",'html.parser')
tag = soup.h2
tag.string.replace_with("OnLine Tutorials Library")
print (tag.string)
输出
OnLine Tutorials Library
BeautifulSoup 对象
BeautifulSoup 对象表示整个已解析的对象。但是,可以认为它类似于 Tag 对象。当我们尝试抓取 Web 资源时创建的对象。因为它类似于 Tag 对象,所以它支持解析和搜索文档树所需的功能。
示例
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
print (soup)
print (soup.name)
print ('type:',type(soup))
输出
<html> <head> <title>TutorialsPoint</title> </head> <body> <h2>Departmentwise Employees</h2> <ul> <li>Accounts</li> <ul> <li>Anand</li> <li>Mahesh</li> </ul> <li>HR</li> <ul> <li>Rani</li> <li>Ankita</li> </ul> </ul> </body> </html> [document] type: <class 'bs4.BeautifulSoup'>
BeautifulSoup 对象的 name 属性始终返回 [document]。
如果将 BeautifulSoup 对象作为参数传递给某个函数(例如 replace_with()),则可以组合两个已解析的文档。
示例
from bs4 import BeautifulSoup
obj1 = BeautifulSoup("<book><title>Python</title></book>", features="xml")
obj2 = BeautifulSoup("<b>Beautiful Soup parser</b>", "lxml")
obj2.find('b').replace_with(obj1)
print (obj2)
输出
<html><body><book><title>Python</title></book></body></html>
注释对象
HTML 和 XML 文档中<!-- 和 -->之间编写的任何文本都被视为注释。BeautifulSoup 可以将此类注释文本检测为 Comment 对象。
示例
from bs4 import BeautifulSoup markup = "<b><!--This is a comment text in HTML--></b>" soup = BeautifulSoup(markup, 'html.parser') comment = soup.b.string print (comment, type(comment))
输出
This is a comment text in HTML <class 'bs4.element.Comment'>
Comment 对象是一种特殊类型的 NavigableString 对象。prettify() 方法以特殊格式显示注释文本 -
示例
print (soup.b.prettify())
输出
<b> <!--This is a comment text in HTML--> </b>
Beautiful Soup - 检查数据源
为了使用 BeautifulSoup 和 Python 抓取网页,任何 Web 抓取项目的第一步都应该是探索您想要抓取的网站。因此,首先访问该网站以了解站点结构,然后开始提取与您相关的的信息。
让我们访问 TutorialsPoint 的 Python 教程主页。在浏览器中打开https://tutorialspoint.com/python3/index.htm。
使用开发者工具可以帮助您了解网站的结构。所有现代浏览器都安装了开发者工具。
如果使用 Chrome 浏览器,请从右上角菜单按钮 (⋮) 打开开发者工具,然后选择更多工具 → 开发者工具。
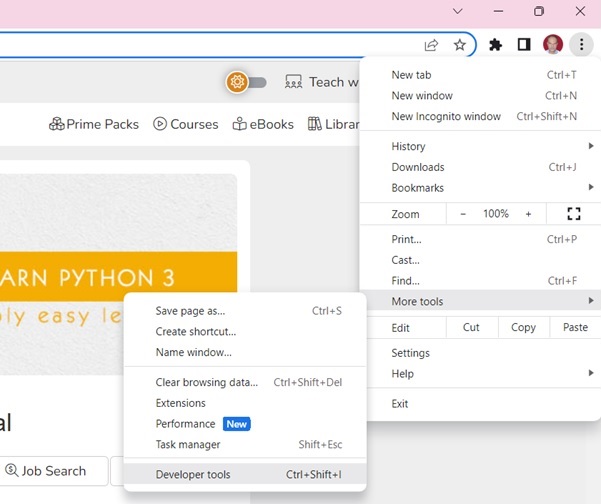
使用开发者工具,您可以浏览站点的文档对象模型 (DOM) 以更好地理解您的源代码。在开发者工具中选择“元素”选项卡。您将看到一个包含可点击 HTML 元素的结构。
教程页面在左侧边栏中显示了目录。右键单击任何章节,然后选择“检查”选项。
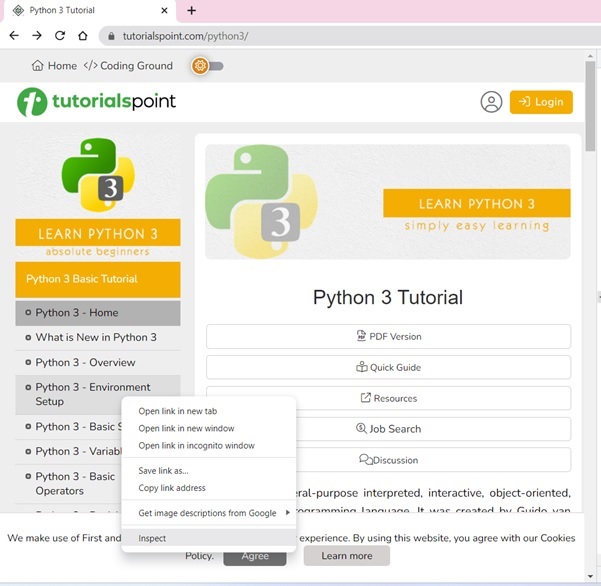
对于“元素”选项卡,找到对应于 TOC 列表的标签,如下面的图所示 -
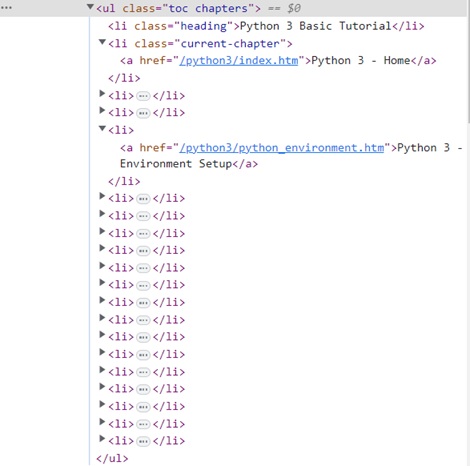
右键单击 HTML 元素,复制 HTML 元素,并将其粘贴到任何编辑器中。
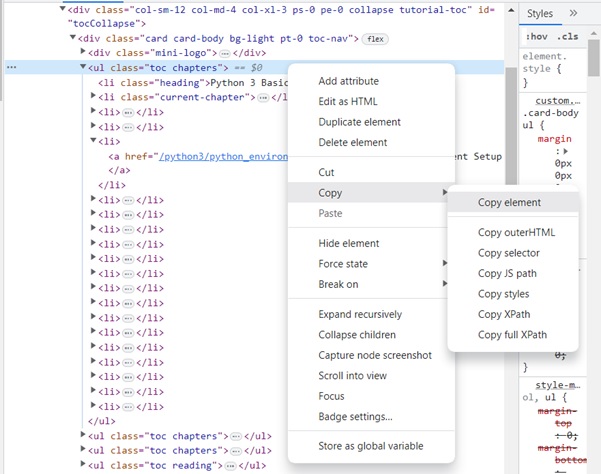
现在获得了<ul>..</ul>元素的 HTML 脚本。
<ul class="toc chapters"> <li class="heading">Python 3 Basic Tutorial</li> <li class="current-chapter"><a href="/python3/index.htm">Python 3 - Home</a></li> <li><a href="/python3/python3_whatisnew.htm">What is New in Python 3</a></li> <li><a href="/python3/python_overview.htm">Python 3 - Overview</a></li> <li><a href="/python3/python_environment.htm">Python 3 - Environment Setup</a></li> <li><a href="/python3/python_basic_syntax.htm">Python 3 - Basic Syntax</a></li> <li><a href="/python3/python_variable_types.htm">Python 3 - Variable Types</a></li> <li><a href="/python3/python_basic_operators.htm">Python 3 - Basic Operators</a></li> <li><a href="/python3/python_decision_making.htm">Python 3 - Decision Making</a></li> <li><a href="/python3/python_loops.htm">Python 3 - Loops</a></li> <li><a href="/python3/python_numbers.htm">Python 3 - Numbers</a></li> <li><a href="/python3/python_strings.htm">Python 3 - Strings</a></li> <li><a href="/python3/python_lists.htm">Python 3 - Lists</a></li> <li><a href="/python3/python_tuples.htm">Python 3 - Tuples</a></li> <li><a href="/python3/python_dictionary.htm">Python 3 - Dictionary</a></li> <li><a href="/python3/python_date_time.htm">Python 3 - Date & Time</a></li> <li><a href="/python3/python_functions.htm">Python 3 - Functions</a></li> <li><a href="/python3/python_modules.htm">Python 3 - Modules</a></li> <li><a href="/python3/python_files_io.htm">Python 3 - Files I/O</a></li> <li><a href="/python3/python_exceptions.htm">Python 3 - Exceptions</a></li> </ul>
我们现在可以将此脚本加载到 BeautifulSoup 对象中以解析文档树。
Beautiful Soup - 抓取 HTML 内容
从网站提取数据的过程称为 Web 抓取。网页可能包含 url、电子邮件地址、图像或任何其他内容,我们可以将其存储在文件或数据库中。手动搜索网站是一个繁琐的过程。有不同的 Web 抓取工具可以自动化此过程。
有时,使用“robots.txt”文件会禁止 Web 抓取。一些受欢迎的网站提供 API 以结构化的方式访问其数据。不道德的 Web 抓取可能会导致您的 IP 被阻止。
Python 广泛用于 Web 抓取。Python 标准库具有 urllib 包,可用于从 HTML 页面提取数据。由于 urllib 模块与标准库捆绑在一起,因此无需安装。
urllib 包是 Python 编程语言的 HTTP 客户端。urllib.request 模块在我们想要打开和读取 URL 时很有用。urllib 包中的其他模块有 -
urllib.error 定义了 urllib.request 命令引发的异常和错误。
urllib.parse 用于解析 URL。
urllib.robotparser 用于解析 robots.txt 文件。
使用 urllib 模块中的 urlopen() 函数从网站读取网页内容。
import urllib.request
response = urllib.request.urlopen('https://pythonlang.cn/')
html = response.read()
您也可以为此目的使用 requests 库。您需要先安装它才能使用。
pip3 install requests
在下面的代码中,抓取了https://tutorialspoint.com的主页 -
from bs4 import BeautifulSoup import requests url = "https://tutorialspoint.com/index.htm" req = requests.get(url)
然后使用 Beautiful Soup 解析通过上述两种方法中的任何一种获得的内容。
Beautiful Soup - 通过标签导航
任何 HTML 文档中重要的元素之一是标签,它们可能包含其他标签/字符串(标签的子元素)。Beautiful Soup 提供了不同的方法来导航和迭代标签的子元素。
搜索解析树最简单的方法是按名称搜索标签。
soup.head
soup.head 函数返回放在 HTML 页面<head> .. </head>元素内部的内容。
Consider the following HTML page to be scraped:
<html>
<head>
<title>TutorialsPoint</title>
<script>
document.write("Welcome to TutorialsPoint");
</script>
</head>
<body>
<h1>Tutorialspoint Online Library</h1>
<p><b>It's all Free</b></p>
</body>
</html>
以下代码提取<head>元素的内容
示例
from bs4 import BeautifulSoup
with open("index.html") as fp:
soup = BeautifulSoup(fp, 'html.parser')
print(soup.head)
输出
<head>
<title>TutorialsPoint</title>
<script>
document.write("Welcome to TutorialsPoint");
</script>
</head>
soup.body
类似地,要返回 HTML 页面的 body 部分的内容,请使用 soup.body
示例
from bs4 import BeautifulSoup
with open("index.html") as fp:
soup = BeautifulSoup(fp, 'html.parser')
print (soup.body)
输出
<body> <h1>Tutorialspoint Online Library</h1> <p><b>It's all Free</b></p> </body>
您还可以提取<body>标签中的特定标签(如第一个<h1>标签)。
示例
from bs4 import BeautifulSoup
with open("index.html") as fp:
soup = BeautifulSoup(fp, 'html.parser')
print(soup.body.h1)
输出
<h1>Tutorialspoint Online Library</h1>
soup.p
我们的 HTML 文件包含一个<p>标签。我们可以提取此标签的内容
示例
from bs4 import BeautifulSoup
with open("index.html") as fp:
soup = BeautifulSoup(fp, 'html.parser')
print(soup.p)
输出
<p><b>It's all Free</b></p>
Tag.contents
Tag 对象可能具有一个或多个 PageElements。Tag 对象的 contents 属性返回其中包含的所有元素的列表。
让我们在 index.html 文件的<head>标签中找到元素。
示例
from bs4 import BeautifulSoup
with open("index.html") as fp:
soup = BeautifulSoup(fp, 'html.parser')
tag = soup.head
print (tag.contents)
输出
['\n',
<title>TutorialsPoint</title>,
'\n',
<script>
document.write("Welcome to TutorialsPoint");
</script>,
'\n']
Tag.children
HTML 脚本中标签的结构是分层的。元素嵌套在另一个元素内部。例如,顶级<HTML>标签包含<HEAD>和<BODY>标签,每个标签都可能包含其他标签。
Tag 对象具有一个 children 属性,该属性返回一个列表迭代器对象,其中包含封闭的 PageElements。
为了演示 children 属性,我们将使用以下 HTML 脚本 (index.html)。在<body>部分,有两个<ul>列表元素,一个嵌套在另一个内部。换句话说,body 标签具有顶级列表元素,每个列表元素在其下方都有另一个列表。
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<h2>Departmentwise Employees</h2>
<ul>
<li>Accounts</li>
<ul>
<li>Anand</li>
<li>Mahesh</li>
</ul>
<li>HR</li>
<ul>
<li>Rani</li>
<li>Ankita</li>
</ul>
</ul>
</body>
</html>
以下 Python 代码给出了顶级<ul>标签的所有子元素的列表。
示例
from bs4 import BeautifulSoup
with open("index.html") as fp:
soup = BeautifulSoup(fp, 'html.parser')
tag = soup.ul
print (list(tag.children))
输出
['\n', <li>Accounts</li>, '\n', <ul> <li>Anand</li> <li>Mahesh</li> </ul>, '\n', <li>HR</li>, '\n', <ul> <li>Rani</li> <li>Ankita</li> </ul>, '\n']
由于 .children 属性返回一个列表迭代器,因此我们可以使用 for 循环来遍历层次结构。
示例
for child in tag.children: print (child)
输出
<li>Accounts</li> <ul> <li>Anand</li> <li>Mahesh</li> </ul> <li>HR</li> <ul> <li>Rani</li> <li>Ankita</li> </ul>
Tag.find_all()
此方法返回与提供的参数标签匹配的所有标签内容的结果集。
让我们考虑以下 HTML 页面 (index.html) -
<html>
<body>
<h1>Tutorialspoint Online Library</h1>
<p><b>It's all Free</b></p>
<a class="prog" href="https://tutorialspoint.com/java/java_overview.htm" id="link1">Java</a>
<a class="prog" href="https://tutorialspoint.com/cprogramming/index.htm" id="link2">C</a>
<a class="prog" href="https://tutorialspoint.com/python/index.htm" id="link3">Python</a>
<a class="prog" href="https://tutorialspoint.com/javascript/javascript_overview.htm" id="link4">JavaScript</a>
<a class="prog" href="https://tutorialspoint.com/ruby/index.htm" id="link5">C</a>
</body>
</html>
以下代码列出了所有具有<a>标签的元素
示例
from bs4 import BeautifulSoup
with open("index.html") as fp:
soup = BeautifulSoup(fp, 'html.parser')
result = soup.find_all("a")
print (result)
输出
[ <a class="prog" href="https://tutorialspoint.com/java/java_overview.htm" id="link1">Java</a>, <a class="prog" href="https://tutorialspoint.com/cprogramming/index.htm" id="link2">C</a>, <a class="prog" href="https://tutorialspoint.com/python/index.htm" id="link3">Python</a>, <a class="prog" href="https://tutorialspoint.com/javascript/javascript_overview.htm" id="link4">JavaScript</a>, <a class="prog" href="https://tutorialspoint.com/ruby/index.htm" id="link5">C</a> ]
Beautiful Soup - 通过 ID 查找元素
在 HTML 文档中,通常每个元素都分配一个唯一的 ID。这使得可以通过前端代码(如 JavaScript 函数)提取元素的值。
使用 BeautifulSoup,您可以通过其 ID 找到给定元素的内容。可以通过两种方法实现此目的 - find() 和 find_all(),以及 select()
使用 find() 方法
BeautifulSoup 对象的 find() 方法搜索第一个满足作为参数给定条件的元素。
让我们为此目的使用以下 HTML 脚本(作为 index.html)
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<form>
<input type = 'text' id = 'nm' name = 'name'>
<input type = 'text' id = 'age' name = 'age'>
<input type = 'text' id = 'marks' name = 'marks'>
</form>
</body>
</html>
以下 Python 代码查找其 id 为 nm 的元素
示例
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
obj = soup.find(id = 'nm')
print (obj)
输出
<input id="nm" name="name" type="text"/>
使用 find_all()
find_all() 方法也接受一个 filter 参数。它返回具有给定 id 的所有元素的列表。在某些 HTML 文档中,通常只有一个具有特定 id 的元素。因此,使用 find() 而不是 find_all() 更适合搜索给定的 id。
示例
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
obj = soup.find_all(id = 'nm')
print (obj)
输出
[<input id="nm" name="name" type="text"/>]
请注意,find_all() 方法返回一个列表。find_all() 方法还有一个 limit 参数。将 find_all() 的 limit 设置为 1 等效于 find()
obj = soup.find_all(id = 'nm', limit=1)
使用 select() 方法
BeautifulSoup 类中的 select() 方法接受 CSS 选择器作为参数。# 符号是 id 的 CSS 选择器。它后面跟着所需 id 的值传递给 select() 方法。它的作用与 find_all() 方法相同。
示例
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
obj = soup.select("#nm")
print (obj)
输出
[<input id="nm" name="name" type="text"/>]
使用 select_one()
与 find_all() 方法类似,select() 方法也返回一个列表。还有一个 select_one() 方法用于返回给定参数的第一个标签。
示例
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
obj = soup.select_one("#nm")
print (obj)
输出
<input id="nm" name="name" type="text"/>
Beautiful Soup - 通过 Class 查找元素
CSS(层叠样式表)是用于设计 HTML 元素外观的工具。CSS 规则控制 HTML 元素的不同方面,例如大小、颜色、对齐方式等。应用样式比定义 HTML 元素属性更有效。您可以将样式规则应用于每个 HTML 元素。与其分别对每个元素应用样式,不如使用 CSS 类将类似的样式应用于 HTML 元素组,以实现统一的网页外观。在 BeautifulSoup 中,可以找到使用 CSS 类设置样式的标签。在本章中,我们将使用以下方法搜索指定 CSS 类的元素:
- find_all() 和 find() 方法
- select() 和 select_one() 方法
CSS 中的类
CSS 中的类是指定与外观相关的不同特征(例如字体类型、大小和颜色、背景颜色、对齐方式等)的属性的集合。声明类时,类名前缀为点(.)。
.class {
css declarations;
}
CSS 类可以内联定义,也可以在需要包含在 HTML 脚本中的单独 css 文件中定义。CSS 类的典型示例如下:
.blue-text {
color: blue;
font-weight: bold;
}
您可以借助以下 BeautifulSoup 方法搜索使用特定类样式定义的 HTML 元素。
出于本章的目的,我们将使用以下 HTML 页面:
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<h2 class="heading">Departmentwise Employees</h2>
<ul>
<li class="mainmenu">Accounts</li>
<ul>
<li class="submenu">Anand</li>
<li class="submenu">Mahesh</li>
</ul>
<li class="mainmenu">HR</li>
<ul>
<li class="submenu">Rani</li>
<li class="submenu">Ankita</li>
</ul>
</ul>
</body>
</html>
使用 find() 和 find_all()
要搜索标签中使用的特定 CSS 类的元素,请使用 Tag 对象的attrs 属性,如下所示:
示例
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
obj = soup.find_all(attrs={"class": "mainmenu"})
print (obj)
输出
[<li class="mainmenu">Accounts</li>, <li class="mainmenu">HR</li>]
结果是所有具有 mainmenu 类的元素的列表
要获取 attrs 属性中提到的任何 CSS 类的元素列表,请将 find_all() 语句更改为:
obj = soup.find_all(attrs={"class": ["mainmenu", "submenu"]})
这将生成一个包含上面使用的任何 CSS 类的所有元素的列表。
[ <li class="mainmenu">Accounts</li>, <li class="submenu">Anand</li>, <li class="submenu">Mahesh</li>, <li class="mainmenu">HR</li>, <li class="submenu">Rani</li>, <li class="submenu">Ankita</li> ]
使用 select() 和 select_one()
您还可以使用 select() 方法,并将 CSS 选择器作为参数。点(.) 符号后跟类名用作 CSS 选择器。
示例
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
obj = soup.select(".heading")
print (obj)
输出
[<h2 class="heading">Departmentwise Employees</h2>]
select_one() 方法返回使用给定类找到的第一个元素。
obj = soup.select_one(".submenu")
Beautiful Soup - 通过属性查找元素
find() 和 find_all() 方法都旨在根据传递给这些方法的参数查找文档中一个或所有标签。您可以将 attrs 参数传递给这些函数。attrs 的值必须是一个字典,其中包含一个或多个标签属性及其值。
为了检查这些方法的行为,我们将使用以下 HTML 文档 (index.html)
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<form>
<input type = 'text' id = 'nm' name = 'name'>
<input type = 'text' id = 'age' name = 'age'>
<input type = 'text' id = 'marks' name = 'marks'>
</form>
</body>
</html>
使用 find_all()
以下程序返回所有具有 input type="text" 属性的标签的列表。
示例
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
obj = soup.find_all(attrs={"type":'text'})
print (obj)
输出
[<input id="nm" name="name" type="text"/>, <input id="age" name="age" type="text"/>, <input id="marks" name="marks" type="text"/>]
使用 find()
find() 方法返回已解析文档中第一个具有给定属性的标签。
obj = soup.find(attrs={"name":'marks'})
使用 select()
select() 方法可以通过将要比较的属性作为参数来调用。属性必须放在列表对象中。它返回所有具有给定属性的标签的列表。
在以下代码中,select() 方法返回所有具有 type 属性的标签。
示例
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
obj = soup.select("[type]")
print (obj)
输出
[<input id="nm" name="name" type="text"/>, <input id="age" name="age" type="text"/>, <input id="marks" name="marks" type="text"/>]
使用 select_one()
select_one() 方法与此类似,只是它返回满足给定过滤器的第一个标签。
obj = soup.select_one("[name='marks']")
输出
<input id="marks" name="marks" type="text"/>
Beautiful Soup - 搜索树结构
在本章中,我们将讨论 Beautiful Soup 中的不同方法,用于以不同方向遍历 HTML 文档树——向上和向下、左右以及来回。
我们将在本章的所有示例中使用以下 HTML 字符串:
html = """
<html><head><title>TutorialsPoint</title></head>
<body>
<p class="title"><b>Online Tutorials Library</b></p>
<p class="story">TutorialsPoint has an excellent collection of tutorials on:
<a href="https://tutorialspoint.com/Python" class="lang" id="link1">Python</a>,
<a href="https://tutorialspoint.com/Java" class="lang" id="link2">Java</a> and
<a href="https://tutorialspoint.com/PHP" class="lang" id="link3">PHP</a>;
Enhance your Programming skills.</p>
<p class="tutorial">...</p>
"""
所需标签的名称允许您导航解析树。例如 soup.head 将为您获取 <head> 元素:
示例
from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'html.parser') print (soup.head.prettify())
输出
<head>
<title>
TutorialsPoint
</title>
</head>
向下
一个标签可能包含在其内封闭的字符串或其他标签。Tag 对象的 .contents 属性返回属于它的所有子元素的列表。
示例
from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'html.parser') tag = soup.head print (list(tag.children))
输出
[<title>TutorialsPoint</title>]
返回的对象是一个列表,尽管在这种情况下,head 元素中只包含一个子标签。
.children
.children 属性也返回标签中所有封闭元素的列表。下面,body 标签中的所有元素都作为列表给出。
示例
from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'html.parser') tag = soup.body print (list(tag.children))
输出
['\n', <p class="title"><b>Online Tutorials Library</b></p>, '\n', <p class="story">TutorialsPoint has an excellent collection of tutorials on: <a class="lang" href="https://tutorialspoint.com/Python" id="link1">Python</a>, <a class="lang" href="https://tutorialspoint.com/Java" id="link2">Java</a> and <a class="lang" href="https://tutorialspoint.com/PHP" id="link3">PHP</a>; Enhance your Programming skills.</p>, '\n', <p class="tutorial">...</p>, '\n']
您可以使用 .children 生成器迭代标签的子元素,而不是将它们作为列表获取:
示例
tag = soup.body for child in tag.children: print (child)
输出
<p class="title"><b>Online Tutorials Library</b></p> <p class="story">TutorialsPoint has an excellent collection of tutorials on: <a class="lang" href="https://tutorialspoint.com/Python" id="link1">Python</a>, <a class="lang" href="https://tutorialspoint.com/Java" id="link2">Java</a> and <a class="lang" href="https://tutorialspoint.com/PHP" id="link3">PHP</a>; Enhance your Programming skills.</p> <p class="tutorial">...</p>
.descendents
.contents 和 .children 属性仅考虑标签的直接子元素。.descendants 属性允许您递归地迭代标签的所有子元素:它的直接子元素、其直接子元素的子元素,依此类推。
BeautifulSoup 对象位于所有标签层次结构的顶部。因此,它的 .descendents 属性包含 HTML 字符串中的所有元素。
示例
from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'html.parser') print (soup.descendants)
.descendents 属性返回一个生成器,可以使用 for 循环进行迭代。在这里,我们列出 head 标签的后代。
示例
from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'html.parser') tag = soup.head for element in tag.descendants: print (element)
输出
<title>TutorialsPoint</title> TutorialsPoint
head 标签包含一个 title 标签,该标签又包含一个 NavigableString 对象 TutorialsPoint。<head> 标签只有一个子元素,但它有两个后代:<title> 标签和 <title> 标签的子元素。但是 BeautifulSoup 对象只有一个直接子元素(<html> 标签),但它有许多后代。
示例
from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'html.parser') tags = list(soup.descendants) print (len(tags))
输出
27
向上
就像您可以使用 children 和 descendents 属性导航文档的下游一样,BeautifulSoup 提供 .parent 和 .parent 属性来导航标签的上游
.parent
每个标签和每个字符串都有一个包含它的父标签。您可以使用 parent 属性访问元素的父元素。在我们的示例中,<head> 标签是 <title> 标签的父元素。
示例
from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'html.parser') tag = soup.title print (tag.parent)
输出
<head><title>TutorialsPoint</title></head>
由于 title 标签包含一个字符串(NavigableString),因此字符串的父元素是 title 标签本身。
示例
from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'html.parser') tag = soup.title string = tag.string print (string.parent)
输出
<title>TutorialsPoint</title>
.parents
您可以使用 .parents 迭代元素的所有父元素。此示例使用 .parents 从文档深处隐藏的 <a> 标签遍历到文档的最顶部。在以下代码中,我们跟踪示例 HTML 字符串中第一个 <a> 标签的父元素。
示例
from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'html.parser') tag = soup.a print (tag.string) for parent in tag.parents: print (parent.name)
输出
Python p body html [document]
横向
出现在相同缩进级别的 HTML 标签称为同级。考虑以下 HTML 代码段
<p>
<b>
Hello
</b>
<i>
Python
</i>
</p>
在外部 <p> 标签中,我们在同一缩进级别上具有 <b> 和 <i> 标签,因此它们被称为同级。BeautifulSoup 使在同一级别的标签之间导航成为可能。
.next_sibling 和 .previous_sibling
这些属性分别返回同一级别上的下一个标签和同一级别上的上一个标签。
示例
from bs4 import BeautifulSoup
soup = BeautifulSoup("<p><b>Hello</b><i>Python</i></p>", 'html.parser')
tag1 = soup.b
print ("next:",tag1.next_sibling)
tag2 = soup.i
print ("previous:",tag2.previous_sibling)
输出
next: <i>Python</i> previous: <b>Hello</b>
由于 <b> 标签左侧没有同级,<i> 标签右侧也没有同级,因此在这两种情况下它都返回 Nobe。
示例
from bs4 import BeautifulSoup
soup = BeautifulSoup("<p><b>Hello</b><i>Python</i></p>", 'html.parser')
tag1 = soup.b
print ("next:",tag1.previous_sibling)
tag2 = soup.i
print ("previous:",tag2.next_sibling)
输出
next: None previous: None
.next_siblings 和 .previous_siblings
如果标签右侧或左侧有两个或多个同级,则可以使用 .next_siblings 和 .previous_siblings 属性分别导航它们。它们都返回生成器对象,以便可以使用 for 循环进行迭代。
让我们为此目的使用以下 HTML 代码段:
<p>
<b>
Excellent
</b>
<i>
Python
</i>
<u>
Tutorial
</u>
</p>
使用以下代码遍历下一个和上一个同级标签。
示例
from bs4 import BeautifulSoup
soup = BeautifulSoup("<p><b>Excellent</b><i>Python</i><u>Tutorial</u></p>", 'html.parser')
tag1 = soup.b
print ("next siblings:")
for tag in tag1.next_siblings:
print (tag)
print ("previous siblings:")
tag2 = soup.u
for tag in tag2.previous_siblings:
print (tag)
输出
next siblings: <i>Python</i> <u>Tutorial</u> previous siblings: <i>Python</i> <b>Excellent</b>
来回
在 Beautiful Soup 中,next_element 属性返回解析树中的下一个字符串或标签。另一方面,previous_element 属性返回解析树中的上一个字符串或标签。有时,next_element 和 previous_element 属性的返回值与 next_sibling 和 previous_sibling 属性相似。
.next_element 和 .previous_element
示例
html = """
<html><head><title>TutorialsPoint</title></head>
<body>
<p class="title"><b>Online Tutorials Library</b></p>
<p class="story">TutorialsPoint has an excellent collection of tutorials on:
<a href="https://tutorialspoint.com/Python" class="lang" id="link1">Python</a>,
<a href="https://tutorialspoint.com/Java" class="lang" id="link2">Java</a> and
<a href="https://tutorialspoint.com/PHP" class="lang" id="link3">PHP</a>;
Enhance your Programming skills.</p>
<p class="tutorial">...</p>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
tag = soup.find("a", id="link3")
print (tag.next_element)
tag = soup.find("a", id="link1")
print (tag.previous_element)
输出
PHP TutorialsPoint has an excellent collection of tutorials on:
id = "link3" 的 <a> 标签之后的 next_element 是字符串 PHP。类似地,previous_element 返回 id = "link1" 的 <a> 标签之前的字符串。
.next_elements 和 .previous_elements
Tag 对象的这些属性分别返回其后和其前所有标签和字符串的生成器。
Next elements 示例
tag = soup.find("a", id="link1")
for element in tag.next_elements:
print (element)
输出
Python , <a class="lang" href="https://tutorialspoint.com/Java" id="link2">Java</a> Java and <a class="lang" href="https://tutorialspoint.com/PHP" id="link3">PHP</a> PHP ; Enhance your Programming skills. <p class="tutorial">...</p> ...
Previous elements 示例
tag = soup.find("body")
for element in tag.previous_elements:
print (element)
输出
<html><head><title>TutorialsPoint</title></head>
Beautiful Soup - 修改树结构
Beautiful Soup 库的一个强大功能是能够操纵已解析的 HTML 或 XML 文档并修改其内容。
Beautiful Soup 库具有执行以下操作的不同函数:
将内容或新标签添加到文档的现有标签中
在现有标签或字符串之前或之后插入内容
清除现有标签的内容
修改标签元素的内容
添加内容
您可以使用 Tag 对象上的append() 方法添加到现有标签的内容中。它的工作原理类似于 Python 列表对象的 append() 方法。
在以下示例中,HTML 脚本有一个 <p> 标签。使用 append(),附加了其他文本。
示例
from bs4 import BeautifulSoup
markup = '<p>Hello</p>'
soup = BeautifulSoup(markup, 'html.parser')
print (soup)
tag = soup.p
tag.append(" World")
print (soup)
输出
<p>Hello</p> <p>Hello World</p>
使用 append() 方法,您可以在现有标签的末尾添加一个新标签。首先使用new_tag() 方法创建一个新的 Tag 对象,然后将其传递给 append() 方法。
示例
from bs4 import BeautifulSoup, Tag
markup = '<b>Hello</b>'
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.b
tag1 = soup.new_tag('i')
tag1.string = 'World'
tag.append(tag1)
print (soup.prettify())
输出
<b>
Hello
<i>
World
</i>
</b>
如果必须将字符串添加到文档中,则可以附加NavigableString 对象。
示例
from bs4 import BeautifulSoup, NavigableString
markup = '<b>Hello</b>'
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.b
new_string = NavigableString(" World")
tag.append(new_string)
print (soup.prettify())
输出
<b> Hello World </b>
从 Beautiful Soup 4.7 版开始,extend() 方法已添加到 Tag 类中。它将列表中的所有元素添加到标签中。
示例
from bs4 import BeautifulSoup markup = '<b>Hello</b>' soup = BeautifulSoup(markup, 'html.parser') tag = soup.b vals = ['World.', 'Welcome to ', 'TutorialsPoint'] tag.extend(vals) print (soup.prettify())
输出
<b> Hello World. Welcome to TutorialsPoint </b>
插入内容
您可以使用insert() 方法在 Tag 元素的子元素列表中的给定位置添加元素,而不是在末尾添加新元素。Beautiful Soup 中的 insert() 方法的行为类似于 Python 列表对象上的 insert()。
在以下示例中,一个新字符串在位置 1 添加到 <b> 标签中。生成的已解析文档显示了结果。
示例
from bs4 import BeautifulSoup, NavigableString markup = '<b>Excellent </b><u>from TutorialsPoint</u>' soup = BeautifulSoup(markup, 'html.parser') tag = soup.b tag.insert(1, "Tutorial ") print (soup.prettify())
输出
<b> Excellent Tutorial </b> <u> from TutorialsPoint </u>
Beautiful Soup 还有insert_before() 和insert_after() 方法。它们各自的目的是在给定的 Tag 对象之前或之后插入标签或字符串。以下代码显示字符串“Python 教程”已添加到 <b> 标签之后。
示例
from bs4 import BeautifulSoup, NavigableString
markup = '<b>Excellent </b><u>from TutorialsPoint</u>'
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.b
tag.insert_after("Python Tutorial")
print (soup.prettify())
输出
<b> Excellent </b> Python Tutorial <u> from TutorialsPoint </u>
另一方面,下面使用 insert_before() 方法,在 <b> 标签之前添加“这是一个”文本。
tag.insert_before("Here is an ")
print (soup.prettify())
输出
Here is an <b> Excellent </b> Python Tutorial <u> from TutorialsPoint </u>
清除内容
Beautiful Soup 提供了多种从文档树中删除元素内容的方法。每种方法都有其独特的特点。
clear() 方法是最直接的方法。它只是简单地删除指定 Tag 元素的内容。以下示例显示了它的用法。
示例
from bs4 import BeautifulSoup, NavigableString
markup = '<b>Excellent </b><u>from TutorialsPoint</u>'
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.find('u')
tag.clear()
print (soup.prettify())
输出
<b> Excellent </b> <u> </u>
可以看出,clear() 方法删除了内容,但保留了标签。
对于以下示例,我们解析以下 HTML 文档并在所有标签上调用 clear() 方法。
<html>
<body>
<p> The quick, brown fox jumps over a lazy dog.</p>
<p> DJs flock by when MTV ax quiz prog.</p>
<p> Junk MTV quiz graced by fox whelps.</p>
<p> Bawds jog, flick quartz, vex nymphs./p>
</body>
</html>
这是使用 clear() 方法的 Python 代码
示例
from bs4 import BeautifulSoup
fp = open('index.html')
soup = BeautifulSoup(fp, 'html.parser')
tags = soup.find_all()
for tag in tags:
tag.clear()
print (soup.prettify())
输出
<html> </html>
extract() 方法从文档树中删除标签或字符串,并返回已删除的对象。
示例
from bs4 import BeautifulSoup
fp = open('index.html')
soup = BeautifulSoup(fp, 'html.parser')
tags = soup.find_all()
for tag in tags:
obj = tag.extract()
print ("Extracted:",obj)
print (soup)
输出
Extracted: <html> <body> <p> The quick, brown fox jumps over a lazy dog.</p> <p> DJs flock by when MTV ax quiz prog.</p> <p> Junk MTV quiz graced by fox whelps.</p> <p> Bawds jog, flick quartz, vex nymphs.</p> </body> </html> Extracted: <body> <p> The quick, brown fox jumps over a lazy dog.</p> <p> DJs flock by when MTV ax quiz prog.</p> <p> Junk MTV quiz graced by fox whelps.</p> <p> Bawds jog, flick quartz, vex nymphs.</p> </body> Extracted: <p> The quick, brown fox jumps over a lazy dog.</p> Extracted: <p> DJs flock by when MTV ax quiz prog.</p> Extracted: <p> Junk MTV quiz graced by fox whelps.</p> Extracted: <p> Bawds jog, flick quartz, vex nymphs.</p>
您可以提取标签或字符串。以下示例显示了正在提取的 antag。
示例
html = '''
<ol id="HR">
<li>Rani</li>
<li>Ankita</li>
</ol>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
obj=soup.find('ol')
obj.find_next().extract()
print (soup)
输出
<ol id="HR"> <li>Ankita</li> </ol>
更改 extract() 语句以删除第一个 <li> 元素的内部文本。
示例
obj.find_next().string.extract()
输出
<ol id="HR"> <li>Ankita</li> </ol>
还有另一个方法 decompose(),它从树中删除标签,然后完全销毁它及其内容:
示例
html = '''
<ol id="HR">
<li>Rani</li>
<li>Ankita</li>
</ol>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
tag1=soup.find('ol')
tag2 = soup.find('li')
tag2.decompose()
print (soup)
print (tag2.decomposed)
输出
<ol id="HR"> <li>Ankita</li> </ol>
decomposed 属性返回 True 或 False——元素是否已被分解。
修改内容
我们将看看replace_with() 方法,它允许替换标签的内容。
就像 Python 字符串是不可变的,可导航字符串也不能就地修改。但是,使用 replace_with() 将标签的内部字符串替换为另一个字符串。
示例
from bs4 import BeautifulSoup
soup = BeautifulSoup("<h2 id='message'>Hello, Tutorialspoint!</h2>",'html.parser')
tag = soup.h2
tag.string.replace_with("OnLine Tutorials Library")
print (tag.string)
输出
OnLine Tutorials Library
这是另一个显示 replace_with() 用法的示例。如果您将 BeautifulSoup 对象作为参数传递给某个函数(例如 replace_with()),则可以组合两个已解析的文档。2524
示例
from bs4 import BeautifulSoup
obj1 = BeautifulSoup("<book><title>Python</title></book>", features="xml")
obj2 = BeautifulSoup("<b>Beautiful Soup parser</b>", "lxml")
obj2.find('b').replace_with(obj1)
print (obj2)
输出
<html><body><book><title>Python</title></book></body></html>
wrap() 方法将元素包装在您指定的标签中。它返回新的包装器。
from bs4 import BeautifulSoup
soup = BeautifulSoup("<p>Hello Python</p>", 'html.parser')
tag = soup.p
newtag = soup.new_tag('b')
tag.string.wrap(newtag)
print (soup)
输出
<p><b>Hello Python</b></p>
另一方面,unwrap() 方法用标签内的任何内容替换标签。它非常适合去除标记。
示例
from bs4 import BeautifulSoup
soup = BeautifulSoup("<p>Hello <b>Python</b></p>", 'html.parser')
tag = soup.p
tag.b.unwrap()
print (soup)
输出
<p>Hello Python</p>
Beautiful Soup - 解析文档的一部分
假设您想使用 Beautiful Soup 仅查看文档的 <a> 标签。通常,您会解析树并使用 find_all() 方法,并将所需的标签作为参数。
soup = BeautifulSoup(fp, "html.parser")
tags = soup.find_all('a')
但是,这也会非常耗时,并且会不必要地占用更多内存。相反,您可以创建一个 SoupStrainer 类对象,并将其用作 BeautifulSoup 构造函数的 parse_only 参数的值。
SoupStrainer 告诉 BeautifulSoup 要提取哪些部分,并且解析树仅包含这些元素。如果您将所需信息缩小到 HTML 的特定部分,这将加快搜索结果的速度。
product = SoupStrainer('div',{'id': 'products_list'})
soup = BeautifulSoup(html,parse_only=product)
以上代码行将仅从产品网站解析标题,标题可能位于标签字段内。
类似地,就像上面一样,我们可以使用其他 soupStrainer 对象从 HTML 标签解析特定信息。以下是一些示例 -
示例
from bs4 import BeautifulSoup, SoupStrainer
#Only "a" tags
only_a_tags = SoupStrainer("a")
#Will parse only the below mentioned "ids".
parse_only = SoupStrainer(id=["first", "third", "my_unique_id"])
soup = BeautifulSoup(my_document, "html.parser", parse_only=parse_only)
#parse only where string length is less than 10
def is_short_string(string):
return len(string) < 10
only_short_strings = SoupStrainer(string=is_short_string)
SoupStrainer 类接受与搜索树中的典型方法相同的参数:name、attrs、text 和 **kwargs。
请注意,如果您使用 html5lib 解析器,则此功能将不起作用,因为在这种情况下,无论如何都会解析整个文档。因此,您应该使用内置的 html.parser 或 lxml 解析器。
您还可以将 SoupStrainer 传递到“搜索树”中介绍的任何方法中。
from bs4 import SoupStrainer
a_tags = SoupStrainer("a")
soup = BeautifulSoup(html_doc, 'html.parser')
soup.find_all(a_tags)
Beautiful Soup - 查找元素的所有子元素
HTML 脚本中标签的结构是分层的。元素嵌套在另一个元素内部。例如,顶级 <HTML> 标签包含 <HEAD> 和 <BODY> 标签,每个标签都可能包含其他标签。顶级元素称为父元素。嵌套在父元素内部的元素是其子元素。借助 Beautiful Soup,我们可以找到父元素的所有子元素。在本章中,我们将了解如何获取 HTML 元素的子元素。
BeautifulSoup 类中有两种方法可以获取子元素。
- .children 属性
- findChildren() 方法
本章中的示例使用以下 HTML 脚本 (index.html)
<html> <head> <title>TutorialsPoint</title> </head> <body> <h2>Departmentwise Employees</h2> <ul id="dept"> <li>Accounts</li> <ul id='acc'> <li>Anand</li> <li>Mahesh</li> </ul> <li>HR</li> <ul id="HR"> <li>Rani</li> <li>Ankita</li> </ul> </ul> </body> </html>
使用 .children 属性
Tag 对象的 .children 属性以递归方式返回所有子元素的生成器。
以下 Python 代码给出了顶级 <ul> 标签的所有子元素的列表。我们首先获取与 <ul> 标签对应的 Tag 元素,然后读取其 .children 属性。
示例
from bs4 import BeautifulSoup
with open("index.html") as fp:
soup = BeautifulSoup(fp, 'html.parser')
tag = soup.ul
print (list(tag.children))
输出
['\n', <li>Accounts</li>, '\n', <ul> <li>Anand</li> <li>Mahesh</li> </ul>, '\n', <li>HR</li>, '\n', <ul> <li>Rani</li> <li>Ankita</li> </ul>, '\n']
由于 .children 属性返回一个列表迭代器,因此我们可以使用 for 循环来遍历层次结构。
for child in tag.children: print (child)
输出
<li>Accounts</li> <ul> <li>Anand</li> <li>Mahesh</li> </ul> <li>HR</li> <ul> <li>Rani</li> <li>Ankita</li> </ul>
使用 findChildren() 方法
findChildren() 方法提供了一种更全面的替代方案。它返回任何顶级标签下的所有子元素。
在 index.html 文档中,我们有两个嵌套的无序列表。顶级 <ul> 元素的 id 为 "dept",两个包含的列表的 id 分别为 "acc" 和 "HR"。
在以下示例中,我们首先实例化一个指向顶级 <ul> 元素的 Tag 对象,并提取其下的子元素列表。
from bs4 import BeautifulSoup
fp = open('index.html')
soup = BeautifulSoup(fp, 'html.parser')
tag = soup.find("ul", {"id": "dept"})
children = tag.findChildren()
for child in children:
print(child)
请注意,结果集以递归方式包含元素下的子元素。因此,在以下输出中,您将找到整个内部列表,以及其中的各个元素。
<li>Accounts</li> <ul id="acc"> <li>Anand</li> <li>Mahesh</li> </ul> <li>Anand</li> <li>Mahesh</li> <li>HR</li> <ul id="HR"> <li>Rani</li> <li>Ankita</li> </ul> <li>Rani</li> <li>Ankita</li>
让我们提取 id 为 'acc' 的内部 <ul> 元素下的子元素。代码如下 -
示例
from bs4 import BeautifulSoup
fp = open('index.html')
soup = BeautifulSoup(fp, 'html.parser')
tag = soup.find("ul", {"id": "acc"})
children = tag.findChildren()
for child in children:
print(child)
运行上述程序时,您将获得 id 为 acc 的 <ul> 下的 <li> 元素。
输出
<li>Anand</li> <li>Mahesh</li>
因此,BeautifulSoup 使解析任何顶级 HTML 元素下的子元素变得非常容易。
Beautiful Soup - 使用 CSS 选择器查找元素
在 Beautiful Soup 库中,select() 方法是抓取 HTML/XML 文档的重要工具。与 find() 和其他 find_*() 方法类似,select() 方法也有助于定位满足给定条件的元素。但是,find*() 方法根据标签名称及其属性搜索 PageElements,而 select() 方法根据给定的 CSS 选择器搜索文档树。
Beautiful Soup 还有 select_one() 方法。select() 和 select_one() 的区别在于,select() 返回属于 PageElement 并以 CSS 选择器为特征的所有元素的结果集;而 select_one() 返回满足基于 CSS 选择器选择标准的元素的第一个出现。
在 Beautiful Soup 4.7 版本之前,select() 方法只能支持常见的 CSS 选择器。随着 4.7 版本的发布,Beautiful Soup 集成了 Soup Sieve CSS 选择器库。因此,现在可以使用更多的选择器。在 4.12 版本中,除了现有的便捷方法 select() 和 select_one() 之外,还添加了一个 .css 属性。select() 方法的参数如下 -
select(selector, limit, **kwargs)
selector - 包含 CSS 选择器的字符串。
limit - 找到此数量的结果后,停止查找。
kwargs - 要传递的关键字参数。
如果将 limit 参数设置为 1,则它等效于 select_one() 方法。select() 方法返回 Tag 对象的结果集,而 select_one() 方法返回单个 Tag 对象。
Soup Sieve 库
Soup Sieve 是一个 CSS 选择器库。它已与 Beautiful Soup 4 集成,因此与 Beautiful Soup 包一起安装。它提供了使用现代 CSS 选择器选择、匹配和过滤文档树标签的功能。Soup Sieve 目前实现了从 CSS 级别 1 规范到 CSS 级别 4 的大多数 CSS 选择器,除了某些尚未实现的选择器。
Soup Sieve 库有不同类型的 CSS 选择器。基本 CSS 选择器为 -
类型选择器
通过节点名称匹配元素。例如 -
tags = soup.select('div')
示例
from bs4 import BeautifulSoup, NavigableString
markup = '''
<div id="Languages">
<p>Java</p> <p>Python</p> <p>C++</p>
</div>
'''
soup = BeautifulSoup(markup, 'html.parser')
tags = soup.select('div')
print (tags)
输出
[<div id="Languages"> <p>Java</p> <p>Python</p> <p>C++</p> </div>]
通用选择器 (*)
它匹配任何类型的元素。例如 -
tags = soup.select('*')
ID 选择器
它根据元素的 id 属性匹配元素。符号 # 表示 ID 选择器。例如 -
tags = soup.select("#nm")
示例
from bs4 import BeautifulSoup
html = '''
<form>
<input type = 'text' id = 'nm' name = 'name'>
<input type = 'text' id = 'age' name = 'age'>
<input type = 'text' id = 'marks' name = 'marks'>
</form>
'''
soup = BeautifulSoup(html, 'html.parser')
obj = soup.select("#nm")
print (obj)
输出
[<input id="nm" name="name" type="text"/>]
类选择器
它根据 class 属性中包含的值匹配元素。前缀为类名称的 . 符号是 CSS 类选择器。例如 -
tags = soup.select(".submenu")
示例
from bs4 import BeautifulSoup, NavigableString
markup = '''
<div id="Languages">
<p>Java</p> <p>Python</p> <p>C++</p>
</div>
'''
soup = BeautifulSoup(markup, 'html.parser')
tags = soup.select('div')
print (tags)
输出
[<div id="Languages"> <p>Java</p> <p>Python</p> <p>C++</p> </div>]
属性选择器
属性选择器根据元素的属性匹配元素。
soup.select('[attr]')
示例
from bs4 import BeautifulSoup
html = '''
<h1>Tutorialspoint Online Library</h1>
<p><b>It's all Free</b></p>
<a class="prog" href="https://tutorialspoint.com/java/java_overview.htm" id="link1">Java</a>
<a class="prog" href="https://tutorialspoint.com/cprogramming/index.htm" id="link2">C</a>
'''
soup = BeautifulSoup(html, 'html5lib')
print(soup.select('[href]'))
输出
[<a class="prog" href="https://tutorialspoint.com/java/java_overview.htm" id="link1">Java</a>, <a class="prog" href="https://tutorialspoint.com/cprogramming/index.htm" id="link2">C</a>]
伪类
CSS 规范定义了许多伪 CSS 类。伪类是添加到选择器中的关键字,用于定义所选元素的特殊状态。它为现有元素添加效果。例如,:link 选择尚未访问的链接(每个具有 href 属性的 <a> 和 <area> 元素)。
伪类选择器 nth-of-type 和 nth-child 非常广泛使用。
:nth-of-type()
选择器 :nth-of-type() 根据元素在兄弟元素组中的位置匹配给定类型的元素。关键字 even 和 odd 分别将从兄弟元素的子组中选择元素。
在以下示例中,选择了 <p> 类型的第二个元素。
示例
from bs4 import BeautifulSoup
html = '''
<p id="0"></p>
<p id="1"></p>
<span id="2"></span>
<span id="3"></span>
'''
soup = BeautifulSoup(html, 'html5lib')
print(soup.select('p:nth-of-type(2)'))
输出
[<p id="1"></p>]
:nth-child()
此选择器根据元素在一组兄弟元素中的位置匹配元素。关键字 even 和 odd 分别将选择在一组兄弟元素中位置为偶数或奇数的元素。
用法
:nth-child(even) :nth-child(odd) :nth-child(2)
示例
from bs4 import BeautifulSoup, NavigableString
markup = '''
<div id="Languages">
<p>Java</p> <p>Python</p> <p>C++</p>
</div>
'''
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.div
child = tag.select_one(':nth-child(2)')
print (child)
输出
<p>Python</p>
Beautiful Soup - 查找所有注释
在计算机代码中插入注释被认为是一种良好的编程实践。注释有助于理解程序的逻辑。它们也用作文档。您可以在 HTML 和 XML 脚本中添加注释,就像在用 C、Java、Python 等编写的程序中一样。BeautifulSoup API 可以帮助识别 HTML 文档中的所有注释。
在 HTML 和 XML 中,注释文本写在 <!-- 和 --> 标签之间。
<!-- Comment Text -->
BeutifulSoup 包(其内部名称为 bs4)将 Comment 定义为一个重要的对象。Comment 对象是一种特殊的 NavigableString 对象。因此,在 <!-- 和 --> 之间找到的任何 Tag 的 string 属性都被识别为 Comment。
示例
from bs4 import BeautifulSoup markup = "<b><!--This is a comment text in HTML--></b>" soup = BeautifulSoup(markup, 'html.parser') comment = soup.b.string print (comment, type(comment))
输出
This is a comment text in HTML <class 'bs4.element.Comment'>
要搜索 HTML 文档中注释的所有出现,我们将使用 find_all() 方法。如果没有参数,find_all() 将返回解析后的 HTML 文档中的所有元素。您可以将关键字参数 'string' 传递给 find_all() 方法。我们将为其分配函数 iscomment() 的返回值。
comments = soup.find_all(string=iscomment)
iscomment() 函数使用 isinstance() 函数验证标签中的文本是否为注释对象。
def iscomment(elem): return isinstance(elem, Comment)
comments 变量将存储给定 HTML 文档中的所有注释文本出现。我们将在示例代码中使用以下 index.html 文件 -
<html>
<head>
<!-- Title of document -->
<title>TutorialsPoint</title>
</head>
<body>
<!-- Page heading -->
<h2>Departmentwise Employees</h2>
<!-- top level list-->
<ul id="dept">
<li>Accounts</li>
<ul id='acc'>
<!-- first inner list -->
<li>Anand</li>
<li>Mahesh</li>
</ul>
<li>HR</li>
<ul id="HR">
<!-- second inner list -->
<li>Rani</li>
<li>Ankita</li>
</ul>
</ul>
</body>
</html>
以下 Python 程序抓取上述 HTML 文档,并查找其中的所有注释。
示例
from bs4 import BeautifulSoup, Comment
fp = open('index.html')
soup = BeautifulSoup(fp, 'html.parser')
def iscomment(elem):
return isinstance(elem, Comment)
comments = soup.find_all(string=iscomment)
print (comments)
输出
[' Title of document ', ' Page heading ', ' top level list', ' first inner list ', ' second inner list ']
以上输出显示了所有注释的列表。我们还可以对注释集合使用 for 循环。
示例
i=0 for comment in comments: i+=1 print (i,".",comment)
输出
1 . Title of document 2 . Page heading 3 . top level list 4 . first inner list 5 . second inner list
在本章中,我们学习了如何提取 HTML 文档中的所有注释字符串。
Beautiful Soup - 从 HTML 中抓取列表
网页通常以有序或无序列表的形式包含重要数据。使用 Beautiful Soup,我们可以轻松地提取 HTML 列表元素,将数据转换为 Python 对象,并将其存储在数据库中以供进一步分析。在本章中,我们将使用 find() 和 select() 方法从 HTML 文档中抓取列表数据。
搜索解析树最简单的方法是按其名称搜索标签。soup.<tag> 获取给定标签的内容。
HTML 提供 <ol> 和 <ul> 标签来组成有序和无序列表。与任何其他标签一样,我们可以获取这些标签的内容。
我们将使用以下 HTML 文档 -
<html>
<body>
<h2>Departmentwise Employees</h2>
<ul id="dept">
<li>Accounts</li>
<ul id='acc'>
<li>Anand</li>
<li>Mahesh</li>
</ul>
<li>HR</li>
<ol id="HR">
<li>Rani</li>
<li>Ankita</li>
</ol>
</ul>
</body>
</html>
按标签抓取列表
在上面的 HTML 文档中,我们有一个顶级 <ul> 列表,其中包含另一个 <ul> 标签和另一个 <ol> 标签。我们首先在 soup 对象中解析文档,并在 soup.ul Tag 对象中检索第一个 <ul> 的内容。
示例
from bs4 import BeautifulSoup
fp = open('index.html')
soup = BeautifulSoup(fp, 'html.parser')
lst=soup.ul
print (lst)
输出
<ul id="dept"> <li>Accounts</li> <ul id="acc"> <li>Anand</li> <li>Mahesh</li> </ul> <li>HR</li> <ol id="HR"> <li>Rani</li> <li>Ankita</li> </ol> </ul>
更改 lst 的值以指向 <ol> 元素以获取内部列表。
lst=soup.ol
输出
<ol id="HR"> <li>Rani</li> <li>Ankita</li> </ol>
使用 select() 方法
select() 方法主要用于使用 CSS 选择器获取数据。但是,您也可以向其传递标签。在这里,我们可以将 ol 标签传递给 select() 方法。select_one() 方法也可用。它获取给定标签的第一个出现。
示例
from bs4 import BeautifulSoup
fp = open('index.html')
soup = BeautifulSoup(fp, 'html.parser')
lst=soup.select("ol")
print (lst)
输出
[<ol id="HR"> <li>Rani</li> <li>Ankita</li> </ol>]
使用 find_all() 方法
find() 和 fin_all() 方法更全面。您可以将各种类型的过滤器(如标签、属性或字符串等)传递给这些方法。在这种情况下,我们想要获取列表标签的内容。
在以下代码中,find_all() 方法返回 <ul> 标签中所有元素的列表。
示例
from bs4 import BeautifulSoup
fp = open('index.html')
soup = BeautifulSoup(fp, 'html.parser')
lst=soup.find_all("ul")
print (lst)
我们可以通过包含 attrs 参数来细化搜索过滤器。在我们的 HTML 文档中,<ul> 和 <ol> 标签,我们已经指定了它们各自的 id 属性。因此,让我们获取具有 id="acc" 的 <ul> 元素的内容。
示例
from bs4 import BeautifulSoup
fp = open('index.html')
soup = BeautifulSoup(fp, 'html.parser')
lst=soup.find_all("ul", {"id":"acc"})
print (lst)
输出
[<ul id="acc"> <li>Anand</li> <li>Mahesh</li> </ul>]
这是一个其他示例。我们收集所有带有 <li> 标签的元素,其内部文本以 'A' 开头。find_all() 方法采用关键字参数 string。如果 startingwith() 函数返回 True,则它将获取文本的值。
示例
from bs4 import BeautifulSoup
def startingwith(ch):
return ch.startswith('A')
fp = open('index.html')
soup = BeautifulSoup(fp, 'html.parser')
lst=soup.find_all('li',string=startingwith)
print (lst)
输出
[<li>Accounts</li>, <li>Anand</li>, <li>Ankita</li>]
Beautiful Soup - 从 HTML 中抓取段落
HTML 文档中经常出现的标签之一是 <p> 标签,它标记段落文本。使用 Beautiful Soup,您可以轻松地从解析的文档树中提取段落。在本章中,我们将讨论以下使用 BeautifulSoup 库抓取段落的方法。
使用 <p> 标签抓取 HTML 段落
使用 find_all() 方法抓取 HTML 段落
使用 select() 方法抓取 HTML 段落
我们将使用以下 HTML 文档进行这些练习 -
<html>
<head>
<title>BeautifulSoup - Scraping Paragraph</title>
</head>
<body>
<p id='para1'>The quick, brown fox jumps over a lazy dog.</p>
<h2>Hello</h2>
<p>DJs flock by when MTV ax quiz prog.</p>
<p>Junk MTV quiz graced by fox whelps.</p>
<p>Bawds jog, flick quartz, vex nymphs.</p>
</body>
</html>
按 <p> 标签抓取
搜索解析树最简单的方法是按其名称搜索标签。因此,表达式 soup.p 指向抓取的文档中的第一个 <p> 标签。
para = soup.p
要获取所有后续的<p>标签,可以运行一个循环,直到soup对象中所有的<p>标签都被遍历完。以下程序显示了所有段落标签的美化输出。
示例
from bs4 import BeautifulSoup
fp = open('index.html')
soup = BeautifulSoup(fp, 'html.parser')
para = soup.p
print (para.prettify())
while True:
p = para.find_next('p')
if p is None:
break
print (p.prettify())
para=p
输出
<p> The quick, brown fox jumps over a lazy dog. </p> <p> DJs flock by when MTV ax quiz prog. </p> <p> Junk MTV quiz graced by fox whelps. </p> <p> Bawds jog, flick quartz, vex nymphs. </p>
使用 find_all() 方法
find_all()方法更全面。您可以将各种类型的过滤器(例如标签、属性或字符串等)传递给此方法。在本例中,我们想要获取<p>标签的内容。
在以下代码中,find_all()方法返回<p>标签中所有元素的列表。
示例
from bs4 import BeautifulSoup
fp = open('index.html')
soup = BeautifulSoup(fp, 'html.parser')
paras = soup.find_all('p')
for para in paras:
print (para.prettify())
输出
<p> The quick, brown fox jumps over a lazy dog. </p> <p> DJs flock by when MTV ax quiz prog. </p> <p> Junk MTV quiz graced by fox whelps. </p> <p> Bawds jog, flick quartz, vex nymphs. </p>
我们可以使用另一种方法来查找所有<p>标签。首先,使用find_all()获取所有标签的列表,并检查每个标签的Tag.name是否等于'p'。
示例
from bs4 import BeautifulSoup
fp = open('index.html')
soup = BeautifulSoup(fp, 'html.parser')
tags = soup.find_all()
paras = [tag.contents for tag in tags if tag.name=='p']
print (paras)
find_all()方法还有一个attrs参数。当您想要提取具有特定属性的<p>标签时,它非常有用。例如,在给定的文档中,第一个<p>元素具有id='para1'。要获取它,我们需要修改标签对象如下所示:
paras = soup.find_all('p', attrs={'id':'para1'})
使用 select() 方法
select()方法主要用于使用CSS选择器获取数据。但是,您也可以将标签传递给它。在这里,我们可以将<p>标签传递给select()方法。select_one()方法也可用。它获取<p>标签的第一次出现。
示例
from bs4 import BeautifulSoup
fp = open('index.html')
soup = BeautifulSoup(fp, 'html.parser')
paras = soup.select('p')
print (paras)
输出
[ <p>The quick, brown fox jumps over a lazy dog.</p>, <p>DJs flock by when MTV ax quiz prog.</p>, <p>Junk MTV quiz graced by fox whelps.</p>, <p>Bawds jog, flick quartz, vex nymphs.</p> ]
要过滤掉具有特定id的<p>标签,请使用如下所示的for循环:
示例
from bs4 import BeautifulSoup
fp = open('index.html')
soup = BeautifulSoup(fp, 'html.parser')
tags = soup.select('p')
for tag in tags:
if tag.has_attr('id') and tag['id']=='para1':
print (tag.contents)
输出
['The quick, brown fox jumps over a lazy dog.']
BeautifulSoup - 从 HTML 中抓取链接
在从具有网站的资源中抓取和分析内容时,您通常需要提取某个页面包含的所有链接。在本章中,我们将了解如何从HTML文档中提取链接。
HTML使用锚标签<a>来插入超链接。锚标签的href属性允许您建立链接。它使用以下语法:
<a href=="web page URL">hypertext</a>
使用find_all()方法,我们可以收集文档中的所有锚标签,然后打印每个锚标签的href属性的值。
在下面的示例中,我们提取了Google主页上找到的所有链接。我们使用requests库来收集https://google.com的HTML内容,将其解析为soup对象,然后收集所有<a>标签。最后,我们打印href属性。
示例
from bs4 import BeautifulSoup
import requests
url = "https://www.google.com/"
req = requests.get(url)
soup = BeautifulSoup(req.content, "html.parser")
tags = soup.find_all('a')
links = [tag['href'] for tag in tags]
for link in links:
print (link)
以下是运行上述程序时部分输出:
输出
https://www.google.co.in/imghp?hl=en&tab=wi https://maps.google.co.in/maps?hl=en&tab=wl https://play.google.com/?hl=en&tab=w8 https://www.youtube.com/?tab=w1 https://news.google.com/?tab=wn https://mail.google.com/mail/?tab=wm https://drive.google.com/?tab=wo https://www.google.co.in/intl/en/about/products?tab=wh http://www.google.co.in/history/optout?hl=en /preferences?hl=en https://#/ServiceLogin?hl=en&passive=true&continue=https://www.google.com/&ec=GAZAAQ /advanced_search?hl=en-IN&authuser=0 https://www.google.com/url?q=https://io.google/2023/%3Futm_source%3Dgoogle-hpp%26utm_medium%3Dembedded_marketing%26utm_campaign%3Dhpp_watch_live%26utm_content%3D&source=hpp&id=19035434&ct=3&usg=AOvVaw0qzqTkP5AEv87NM-MUDd_u&sa=X&ved=0ahUKEwiPzpjku-z-AhU1qJUCHVmqDJoQ8IcBCAU
但是,HTML文档可能具有不同协议方案的超链接,例如用于链接到电子邮件ID的mailto:协议,用于链接到电话号码的tel:方案,或用于链接到具有file:// URL方案的本地文件的链接。在这种情况下,如果我们有兴趣提取具有https://方案的链接,我们可以通过以下示例来实现。我们有一个包含不同类型超链接的HTML文档,其中仅提取了具有https://前缀的超链接。
html = '''
<p><a href="https://tutorialspoint.com">Web page link </a></p>
<p><a href="https://www.example.com">Web page link </a></p>
<p><a href="mailto:nowhere@mozilla.org">Email link</a></p>
<p><a href="tel:+4733378901">Telephone link</a></p>
'''
from bs4 import BeautifulSoup
import requests
soup = BeautifulSoup(html, "html.parser")
tags = soup.find_all('a')
links = [tag['href'] for tag in tags]
for link in links:
if link.startswith("https"):
print (link)
输出
https://tutorialspoint.com https://www.example.com
Beautiful Soup - 获取所有 HTML 标签
HTML中的标签就像Python或Java等传统编程语言中的关键字。标签具有预定义的行为,浏览器根据该行为呈现其内容。使用Beautiful Soup,可以收集给定HTML文档中的所有标签。
获取标签列表的最简单方法是将网页解析为soup对象,然后调用不带任何参数的find_all()方法。它返回一个列表生成器,为我们提供所有标签的列表。
让我们提取Google主页中所有标签的列表。
示例
from bs4 import BeautifulSoup import requests url = "https://www.google.com/" req = requests.get(url) soup = BeautifulSoup(req.content, "html.parser") tags = soup.find_all() print ([tag.name for tag in tags])
输出
['html', 'head', 'meta', 'meta', 'title', 'script', 'style', 'style', 'script', 'body', 'script', 'div', 'div', 'nobr', 'b', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'u', 'div', 'nobr', 'span', 'span', 'span', 'a', 'a', 'a', 'div', 'div', 'center', 'br', 'div', 'img', 'br', 'br', 'form', 'table', 'tr', 'td', 'td', 'input', 'input', 'input', 'input', 'input', 'div', 'input', 'br', 'span', 'span', 'input', 'span', 'span', 'input', 'script', 'input', 'td', 'a', 'input', 'script', 'div', 'div', 'br', 'div', 'style', 'div', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'span', 'div', 'div', 'a', 'a', 'a', 'a', 'p', 'a', 'a', 'script', 'script', 'script']
当然,您可能会得到这样一个列表,其中某个特定标签可能会出现多次。要获得唯一的标签列表(避免重复),请从标签对象列表中构造一个集合。
将上面代码中的print语句更改为
示例
print ({tag.name for tag in tags})
输出
{'body', 'head', 'p', 'a', 'meta', 'tr', 'nobr', 'script', 'br', 'img', 'b', 'form', 'center', 'span', 'div', 'input', 'u', 'title', 'style', 'td', 'table', 'html'}
要获取与某些文本关联的标签,请检查字符串属性,如果它不是None,则打印。
tags = soup.find_all()
for tag in tags:
if tag.string is not None:
print (tag.name, tag.string)
可能有一些不带文本但带有一个或多个属性的单例标签,例如<img>标签。以下循环构建了此类标签的列表。
在以下代码中,HTML字符串不是完整的HTML文档,因为它没有给出<html>和<body>标签。但是,html5lib和lxml解析器在解析文档树时会自行添加这些标签。因此,当我们提取标签列表时,也会看到额外的标签。
示例
html = '''
<h1 style="color:blue;text-align:center;">This is a heading</h1>
<p style="color:red;">This is a paragraph.</p>
<p>This is another paragraph</p>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html5lib")
tags = soup.find_all()
print ({tag.name for tag in tags} )
输出
{'head', 'html', 'p', 'h1', 'body'}
Beautiful Soup - 获取标签内的文本
HTML中有两种类型的标签。许多标签成对出现,分别是开始标签和结束标签。顶级<html>标签具有相应的结束</html>标签,这是一个主要示例。其他的有<body>和</body>、<p>和</p>、<h1>和</h1>等等。其他标签是自闭合标签,例如<img>和<a>。自闭合标签没有文本,就像大多数带有开始和结束符号的标签(例如<b>Hello</b>)一样。在本章中,我们将了解如何借助Beautiful Soup库获取此类标签内部的文本部分。
Beautiful Soup中有多种方法/属性可用于获取与标签对象关联的文本。
| 序号 | 方法及描述 |
|---|---|
| 1 | text属性 获取PageElement的所有子字符串,如果指定则使用分隔符连接。 |
| 2 | string属性 方便地从子元素获取字符串。 |
| 3 | strings属性 从当前PageElement下的所有子对象生成字符串部分。 |
| 4 | stripped_strings属性 与strings属性相同,但删除了换行符和空格。 |
| 5 | get_text()方法 返回此PageElement的所有子字符串,如果指定则使用分隔符连接。 |
考虑以下HTML文档:
<div id="outer">
<div id="inner">
<p>Hello<b>World</b></p>
<img src='logo.jpg'>
</div>
</div>
如果我们检索解析的文档树中每个标签的stripped_string属性,我们会发现两个div标签和p标签有两个NavigableString对象,分别是Hello和World。<b>标签包含world字符串,而<img>没有文本部分。
以下示例从给定HTML文档中的每个标签中获取文本:
示例
html = """
<div id="outer">
<div id="inner">
<p>Hello<b>World</b></p>
<img src='logo.jpg'>
</div>
</div>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
for tag in soup.find_all():
print ("Tag: {} attributes: {} ".format(tag.name, tag.attrs))
for txt in tag.stripped_strings:
print (txt)
print()
输出
Tag: div attributes: {'id': 'outer'}
Hello
World
Tag: div attributes: {'id': 'inner'}
Hello
World
Tag: p attributes: {}
Hello
World
Tag: b attributes: {}
World
Tag: img attributes: {'src': 'logo.jpg'}
Beautiful Soup - 查找所有标题
在本章中,我们将探讨如何使用BeautifulSoup在HTML文档中查找所有标题元素。HTML定义了从H1到H6的六种标题样式,每种标题样式的字体大小都逐渐减小。不同的页面部分使用合适的标签,例如主标题、章节标题、主题等。让我们以两种不同的方式使用find_all()方法来提取HTML文档中的所有标题元素。
我们将在本章的代码示例中使用以下HTML脚本(保存为index.html):
<html>
<head>
<title>BeautifulSoup - Scraping Headings</title>
</head>
<body>
<h2>Scraping Headings</h2>
<b>The quick, brown fox jumps over a lazy dog.</b>
<h3>Paragraph Heading</h3>
<p>DJs flock by when MTV ax quiz prog.</p>
<h3>List heading</h3>
<ul>
<li>Junk MTV quiz graced by fox whelps.</li>
<li>Bawds jog, flick quartz, vex nymphs.</li>
</ul>
</body>
</html>
示例1
在这种方法中,我们收集解析树中的所有标签,并检查每个标签的名称是否在所有标题标签的列表中找到。
from bs4 import BeautifulSoup
fp = open('index.html')
soup = BeautifulSoup(fp, 'html.parser')
headings = ['h1','h2','h3', 'h4', 'h5', 'h6']
tags = soup.find_all()
heads = [(tag.name, tag.contents[0]) for tag in tags if tag.name in headings]
print (heads)
这里,headings是所有标题样式h1到h6的列表。如果标签的名称是其中的任何一个,则该标签及其内容将被收集到名为heads的列表中。
输出
[('h2', 'Scraping Headings'), ('h3', 'Paragraph Heading'), ('h3', 'List heading')]
示例2
您可以将正则表达式传递给find_all()方法。请查看以下正则表达式。
re.compile('^h[1-6]$')
此正则表达式查找以h开头,h后面有一个数字,然后在数字后结束的所有标签。让我们在下面的代码中将其用作find_all()方法的参数:
from bs4 import BeautifulSoup
import re
fp = open('index.html')
soup = BeautifulSoup(fp, 'html.parser')
tags = soup.find_all(re.compile('^h[1-6]$'))
print (tags)
输出
[<h2>Scraping Headings</h2>, <h3>Paragraph Heading</h3>, <h3>List heading</h3>]
Beautiful Soup - 提取标题标签
<title>标签用于为页面提供出现在浏览器标题栏中的文本标题。它不是网页主要内容的一部分。title标签始终位于<head>标签内。
我们可以通过Beautiful Soup提取title标签的内容。我们解析HTML树并获取title标签对象。
示例
html = '''
<html>
<head>
<Title>Python Libraries</title>
</head>
<body>
<p Hello World</p>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html5lib")
title = soup.title
print (title)
输出
<title>Python Libraries</title>
在HTML中,我们可以将title属性与所有标签一起使用。title属性提供有关元素的附加信息。当鼠标悬停在元素上时,该信息作为工具提示文本显示。
我们可以使用以下代码片段提取每个标签的title属性的文本:
示例
html = '''
<html>
<body>
<p title='parsing HTML and XML'>Beautiful Soup</p>
<p title='HTTP library'>requests</p>
<p title='URL handling'>urllib</p>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html5lib")
tags = soup.find_all()
for tag in tags:
if tag.has_attr('title'):
print (tag.attrs['title'])
输出
parsing HTML and XML HTTP library URL handling
Beautiful Soup - 提取电子邮件 ID
从网页中提取电子邮件地址是BeautifulSoup等网络抓取库的重要应用。在任何网页中,电子邮件ID通常出现在锚<a>标签的href属性中。电子邮件ID使用mailto URL方案编写。很多时候,电子邮件地址可能作为普通文本出现在页面内容中(没有任何超链接)。在本章中,我们将使用BeautifulSoup库通过简单的技术从HTML页面获取电子邮件ID。
href属性中电子邮件ID的典型用法如下所示:
<a href = "mailto:xyz@abc.com">test link</a>
在第一个示例中,我们将考虑以下HTML文档,以从中提取超链接中的电子邮件ID:
<html>
<head>
<title>BeautifulSoup - Scraping Email IDs</title>
</head>
<body>
<h2>Contact Us</h2>
<ul>
<li><a href = "mailto:sales@company.com">Sales Enquiries</a></li>
<li><a href = "mailto:careers@company.com">Careers</a></li>
<li><a href = "mailto:partner@company.com">Partner with us</a></li>
</ul>
</body>
</html>
以下是查找电子邮件ID的Python代码。我们收集文档中的所有<a>标签,并检查该标签是否具有href属性。如果是,则其值从第6个字符开始的部分就是电子邮件ID。
from bs4 import BeautifulSoup
import re
fp = open("contact.html")
soup = BeautifulSoup(fp, "html.parser")
tags = soup.find_all("a")
for tag in tags:
if tag.has_attr("href") and tag['href'][:7]=='mailto:':
print (tag['href'][7:])
对于给定的HTML文档,电子邮件ID将按如下方式提取:
sales@company.com careers@company.com partner@company.com
在第二个示例中,我们假设电子邮件ID出现在文本中的任何位置。要提取它们,我们使用正则表达式搜索机制。正则表达式是一种复杂的字符模式。Python的re模块有助于处理正则表达式模式。以下正则表达式模式用于搜索电子邮件地址:
pat = r'[\w.+-]+@[\w-]+\.[\w.-]+'
对于此练习,我们将使用以下HTML文档,其中<li>标签包含电子邮件ID。
<html>
<head>
<title>BeautifulSoup - Scraping Email IDs</title>
</head>
<body>
<h2>Contact Us</h2>
<ul>
<li>Sales Enquiries: sales@company.com</a></li>
<li>Careers: careers@company.com</a></li>
<li>Partner with us: partner@company.com</a></li>
</ul>
</body>
</html>
使用电子邮件正则表达式,我们将查找模式在每个<li>标签字符串中的出现情况。以下是Python代码:
示例
from bs4 import BeautifulSoup
import re
def isemail(s):
pat = r'[\w.+-]+@[\w-]+\.[\w.-]+'
grp=re.findall(pat,s)
return (grp)
fp = open("contact.html")
soup = BeautifulSoup(fp, "html.parser")
tags = soup.find_all('li')
for tag in tags:
emails = isemail(tag.string)
if emails:
print (emails)
输出
['sales@company.com'] ['careers@company.com'] ['partner@company.com']
使用上面描述的简单技术,我们可以使用BeautifulSoup从网页中提取电子邮件ID。
Beautiful Soup - 抓取嵌套标签
HTML文档中标签或元素的排列具有层次结构的性质。标签可以嵌套到多个级别。例如,<head>和<body>标签嵌套在<html>标签内。类似地,一个或多个<li>标签可能位于<ul>标签内。在本章中,我们将了解如何抓取具有一个或多个嵌套在其中的子标签的标签。
让我们考虑以下HTML文档:
<div id="outer">
<div id="inner">
<p>Hello<b>World</b></p>
<img src='logo.jpg'>
</div>
</div>
在这种情况下,两个<div>标签和一个<p>标签有一个或多个嵌套在其中的子元素。而<img>和<b>标签没有任何子标签。
findChildren()方法返回标签下所有子元素的ResultSet。因此,如果标签没有任何子元素,则ResultSet将是一个空列表,例如[]。
以此为线索,以下代码查找文档树中每个标签下的标签并显示列表。
示例
html = """
<div id="outer">
<div id="inner">
<p>Hello<b>World</b></p>
<img src='logo.jpg'>
</div>
</div>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
for tag in soup.find_all():
print ("Tag: {} attributes: {}".format(tag.name, tag.attrs))
print ("Child tags: ", tag.findChildren())
print()
输出
Tag: div attributes: {'id': 'outer'}
Child tags: [<div id="inner">
<p>Hello<b>World</b></p>
<img src="logo.jpg"/>
</div>, <p>Hello<b>World</b></p>, <b>World</b>, <img src="logo.jpg"/>]
Tag: div attributes: {'id': 'inner'}
Child tags: [<p>Hello<b>World</b></p>, <b>World</b>, <img src="logo.jpg"/>]
Tag: p attributes: {}
Child tags: [<b>World</b>]
Tag: b attributes: {}
Child tags: []
Tag: img attributes: {'src': 'logo.jpg'}
Child tags: []
Beautiful Soup - 解析表格
除了文本内容之外,HTML文档还可以以HTML表格的形式包含结构化数据。使用Beautiful Soup,我们可以将表格数据提取到Python对象(例如列表或字典)中,如果需要,可以将其存储在数据库或电子表格中,并执行处理。在本章中,我们将使用Beautiful Soup解析HTML表格。
尽管Beautiful Soup没有用于提取表格数据的任何特殊函数或方法,但我们可以通过简单的抓取技术来实现它。就像任何表格(例如SQL或电子表格中的表格)一样,HTML表格由行和列组成。
HTML使用<table>标签来构建表格结构。有一个或多个嵌套的<tr>标签,每个标签代表一行。每一行都包含<td>标签,用于保存该行每个单元格中的数据。第一行通常用于列标题,标题放在<th>标签而不是<td>标签中。
以下HTML脚本在浏览器窗口中呈现一个简单的表格:
<html>
<body>
<h2>Beautiful Soup - Parse Table</h2>
<table border="1">
<tr>
<th>Name</th>
<th>Age</th>
<th>Marks</th>
</tr>
<tr class='data'>
<td>Ravi</td>
<td>23</td>
<td>67</td>
</tr>
<tr class='data'>
<td>Anil</td>
<td>27</td>
<td>84</td>
</tr>
</table>
</body>
</html>
请注意,数据行的外观使用CSS类data进行了自定义,以便将其与标题行区分开来。
现在我们将了解如何解析表格数据。首先,我们在 BeautifulSoup 对象中获取文档树。然后将所有列标题收集到一个列表中。
示例
from bs4 import BeautifulSoup
soup = BeautifulSoup(markup, "html.parser")
tbltag = soup.find('table')
headers = []
headings = tbltag.find_all('th')
for h in headings: headers.append(h.string)
然后获取在标题行之后具有 class='data' 属性的数据行标签。形成一个字典对象,其中列标题作为键,每个单元格中的对应值作为值,并将该字典对象追加到一个字典对象列表中。
rows = tbltag.find_all_next('tr', {'class':'data'})
trows=[]
for i in rows:
row = {}
data = i.find_all('td')
n=0
for j in data:
row[headers[n]] = j.string
n+=1
trows.append(row)
一个字典对象列表被收集到 trows 中。然后可以将其用于不同的目的,例如存储在 SQL 表中、保存为 JSON 或 pandas DataFrame 对象。
完整的代码如下所示:
markup = """
<html>
<body>
<p>Beautiful Soup - Parse Table</p>
<table>
<tr>
<th>Name</th>
<th>Age</th>
<th>Marks</th>
</tr>
<tr class='data'>
<td>Ravi</td>
<td>23</td>
<td>67</td>
</tr>
<tr class='data'>
<td>Anil</td>
<td>27</td>
<td>84</td>
</tr>
</table>
</body>
</html>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(markup, "html.parser")
tbltag = soup.find('table')
headers = []
headings = tbltag.find_all('th')
for h in headings: headers.append(h.string)
print (headers)
rows = tbltag.find_all_next('tr', {'class':'data'})
trows=[]
for i in rows:
row = {}
data = i.find_all('td')
n=0
for j in data:
row[headers[n]] = j.string
n+=1
trows.append(row)
print (trows)
输出
[{'Name': 'Ravi', 'Age': '23', 'Marks': '67'}, {'Name': 'Anil', 'Age': '27', 'Marks': '84'}]
Beautiful Soup - 选择第 n 个子元素
HTML 的特点是标签的层次顺序。例如,<html> 标签包含 <body> 标签,在 <body> 标签内部可能存在 <div> 标签,并且 <div> 标签可能进一步嵌套 <ul> 和 <li> 元素。findChildren() 方法和 .children 属性都返回一个 ResultSet(列表),其中包含元素下所有直接子标签。通过遍历列表,可以获取位于所需位置(第 n 个子元素)的子元素。
下面的代码使用 HTML 文档中 <div> 标签的 children 属性。由于 children 属性的返回类型是列表迭代器,因此我们将从中检索一个 Python 列表。我们还需要从迭代器中删除空格和换行符。完成后,我们可以获取所需的子元素。这里显示了 <div> 标签索引为 1 的子元素。
示例
from bs4 import BeautifulSoup, NavigableString
markup = '''
<div id="Languages">
<p>Java</p> <p>Python</p> <p>C++</p>
</div>
'''
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.div
children = tag.children
childlist = [child for child in children if child not in ['\n', ' ']]
print (childlist[1])
输出
<p>Python</p>
要使用 findChildren() 方法而不是 children 属性,请将语句更改为
children = tag.findChildren()
输出不会有任何变化。
定位第 n 个子元素的更有效方法是使用 select() 方法。select() 方法使用 CSS 选择器从当前元素获取所需的 PageElements。
Soup 和 Tag 对象通过其 .css 属性支持 CSS 选择器,该属性是 CSS 选择器 API 的接口。选择器实现由 Soup Sieve 包处理,该包与 bs4 包一起安装。
Soup Sieve 包定义了不同类型的 CSS 选择器,即简单、复合和复杂 CSS 选择器,它们由一个或多个类型选择器、ID 选择器、类选择器组成。这些选择器在 CSS 语言中定义。
Soup Sieve 中也有伪类选择器。CSS 伪类是添加到选择器中的一个关键字,用于指定所选元素的特殊状态。在本例中,我们将使用 :nth-child 伪类选择器。由于我们需要从 <div> 标签的第 2 个位置选择一个子元素,因此我们将 :nthchild(2) 传递给 select_one() 方法。
示例
from bs4 import BeautifulSoup, NavigableString
markup = '''
<div id="Languages">
<p>Java</p> <p>Python</p> <p>C++</p>
</div>
'''
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.div
child = tag.select_one(':nth-child(2)')
print (child)
输出
<p>Python</p>
我们得到了与 findChildren() 方法相同的结果。请注意,子元素编号从 1 开始,而不是像 Python 列表那样从 0 开始。
Beautiful Soup - 通过标签内的文本搜索
Beautiful Soup 提供了不同的方法来搜索给定 HTML 文档中的特定文本。在这里,我们为此目的使用 find() 方法的字符串参数。
在下面的示例中,我们使用 find() 方法搜索单词“by”。
示例
html = '''
<p> The quick, brown fox jumps over a lazy dog.</p>
<p> DJs flock by when MTV ax quiz prog.</p>
<p> Junk MTV quiz graced by fox whelps.</p>
<p> Bawds jog, flick quartz, vex nymphs./p>
'''
from bs4 import BeautifulSoup, NavigableString
def search(tag):
if 'by' in tag.text:
return True
soup = BeautifulSoup(html, 'html.parser')
tag = soup.find('p', string=search)
print (tag)
输出
<p> DJs flock by when MTV ax quiz prog.</p>
You can find all occurrences of the word with find_all() method
tag = soup.find_all('p', string=search)
print (tag)
输出
[<p> DJs flock by when MTV ax quiz prog.</p>, <p> Junk MTV quiz graced by fox whelps.</p>]
可能存在所需文本位于文档树内部某个子标签中的情况。我们需要首先找到一个没有其他元素的标签,然后检查所需文本是否在其中。
示例
html = ''' <p> The quick, brown fox jumps over a lazy dog.</p> <p> DJs flock by when MTV ax quiz prog.</p> <p> Junk MTV quiz graced by fox whelps.</p> <p> Bawds jog, flick quartz, vex nymphs./p> ''' from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'html.parser') tags = soup.find_all(lambda tag: len(tag.find_all()) == 0 and "by" in tag.text) for tag in tags: print (tag)
输出
<p> DJs flock by when MTV ax quiz prog.</p> <p> Junk MTV quiz graced by fox whelps.</p>
Beautiful Soup - 移除 HTML 标签
在本章中,我们将了解如何从 HTML 文档中删除所有标签。HTML 是一种标记语言,由预定义的标签组成。标签标记与其关联的特定文本,以便浏览器根据其预定义的含义呈现它。例如,用 <b> 标签标记的单词 Hello(例如 <b>Hello</b>),由浏览器以粗体显示。
如果我们想过滤掉 HTML 文档中不同标签之间的原始文本,我们可以使用 Beautiful Soup 库中的两种方法中的任何一种 - get_text() 或 extract()。
get_text() 方法收集文档中的所有原始文本部分并返回一个字符串。但是,原始文档树不会改变。
在下面的示例中,get_text() 方法删除了所有 HTML 标签。
示例
html = '''
<html>
<body>
<p> The quick, brown fox jumps over a lazy dog.</p>
<p> DJs flock by when MTV ax quiz prog.</p>
<p> Junk MTV quiz graced by fox whelps.</p>
<p> Bawds jog, flick quartz, vex nymphs.</p>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
text = soup.get_text()
print(text)
输出
The quick, brown fox jumps over a lazy dog. DJs flock by when MTV ax quiz prog. Junk MTV quiz graced by fox whelps. Bawds jog, flick quartz, vex nymphs.
请注意,上面示例中的 soup 对象仍然包含 HTML 文档的解析树。
另一种方法是在从 soup 对象中提取之前收集包含在 Tag 对象中的字符串。在 HTML 中,某些标签没有字符串属性(我们可以说对于某些标签,例如 <html> 或 <body>,tag.string 为 None)。因此,我们将来自所有其他标签的字符串连接起来,以从 HTML 文档中获取纯文本。
以下程序演示了这种方法。
示例
html = '''
<html>
<body>
<p>The quick, brown fox jumps over a lazy dog.</p>
<p>DJs flock by when MTV ax quiz prog.</p>
<p>Junk MTV quiz graced by fox whelps.</p>
<p>Bawds jog, flick quartz, vex nymphs.</p>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
tags = soup.find_all()
string=''
for tag in tags:
#print (tag.name, tag.string)
if tag.string != None:
string=string+tag.string+'\n'
tag.extract()
print ("Document text after removing tags:")
print (string)
print ("Document:")
print (soup)
输出
Document text after removing tags: The quick, brown fox jumps over a lazy dog. DJs flock by when MTV ax quiz prog. Junk MTV quiz graced by fox whelps. Bawds jog, flick quartz, vex nymphs. Document:
clear() 方法删除标签对象的内部字符串,但不会返回它。类似地,decompose() 方法会销毁标签及其所有子元素。因此,这些方法不适合从 HTML 文档中检索纯文本。
Beautiful Soup - 移除所有样式
本章介绍如何从 HTML 文档中删除所有样式。级联样式表 (CSS) 用于控制 HTML 文档不同方面的外观。它包括使用特定字体、颜色、对齐方式、间距等样式化文本的呈现。CSS 以不同的方式应用于 HTML 标签。
一种是在 CSS 文件中定义不同的样式,并在 HTML 脚本中使用文档 <head> 部分中的 <link> 标签包含它。例如,
示例
<html>
<head>
<link rel="stylesheet" href="style.css">
</head>
<body>
. . .
. . .
</body>
</html>
HTML 脚本正文部分中的不同标签将使用 mystyle.css 文件中的定义。
另一种方法是在 HTML 文档本身的 <head> 部分中定义样式配置。正文部分中的标签将使用内部提供的定义进行呈现。
内部样式的示例:
<html>
<head>
<style>
p {
text-align: center;
color: red;
}
</style>
</head>
<body>
<p>para1.</p>
<p id="para1">para2</p>
<p>para3</p>
</body>
</html>
在任何一种情况下,要以编程方式删除样式,只需从 soup 对象中删除 head 标签。
from bs4 import BeautifulSoup soup = BeautifulSoup(html, "html.parser") soup.head.extract()
第三种方法是通过在标签本身中包含 style 属性来内联定义样式。style 属性可以包含一个或多个样式属性定义,例如颜色、大小等。例如
<body> <h1 style="color:blue;text-align:center;">This is a heading</h1> <p style="color:red;">This is a paragraph.</p> </body>
要从 HTML 文档中删除此类内联样式,您需要检查标签对象的 attrs 字典中是否定义了 style 键,如果已定义,则删除它。
tags=soup.find_all()
for tag in tags:
if tag.has_attr('style'):
del tag.attrs['style']
print (soup)
以下代码删除内联样式并删除 head 标签本身,以便生成的 HTML 树中不再有任何样式。
html = '''
<html>
<head>
<link rel="stylesheet" href="style.css">
</head>
<body>
<h1 style="color:blue;text-align:center;">This is a heading</h1>
<p style="color:red;">This is a paragraph.</p>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
soup.head.extract()
tags=soup.find_all()
for tag in tags:
if tag.has_attr('style'):
del tag.attrs['style']
print (soup.prettify())
输出
<html> <body> <h1> This is a heading </h1> <p> This is a paragraph. </p> </body> </html>
Beautiful Soup - 移除所有脚本
HTML 中经常使用的标签之一是 <script> 标签。它有助于在 HTML 中嵌入客户端脚本,例如 JavaScript 代码。在本章中,我们将使用 BeautifulSoup 从 HTML 文档中删除脚本标签。
<script> 标签有一个对应的 </script> 标签。在这两个标签之间,您可以包含对外部 JavaScript 文件的引用,或在 HTML 脚本本身中内联包含 JavaScript 代码。
要包含外部 Javascript 文件,使用的语法为:
<head> <script src="javascript.js"></script> </head>
然后,您可以从 HTML 内部调用在此文件中定义的函数。
您可以将 JavaScipt 代码放在 HTML 中的 <script> 和 </script> 代码之间,而不是引用外部文件。如果将其放在 HTML 文档的 <head> 部分,则该功能在整个文档树中可用。另一方面,如果将其放在 <body> 部分的任何位置,则 JavaScript 函数从该点开始可用。
<body>
<p>Hello World</p>
<script>
alert("Hello World")
</script>
</body>
使用 Beautiful 删除所有脚本标签很容易。您必须从解析树中收集所有脚本标签的列表,然后逐个提取它们。
示例
html = '''
<html>
<head>
<script src="javascript.js"></scrript>
</head>
<body>
<p>Hello World</p>
<script>
alert("Hello World")
</script>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
for tag in soup.find_all('script'):
tag.extract()
print (soup)
输出
<html> <head> </head> </html>
您也可以使用 decompose() 方法而不是 extract(),区别在于后者返回已删除的内容,而前者只是销毁它。为了使代码更简洁,您还可以使用列表推导式语法来实现删除了脚本标签的 soup 对象,如下所示:
[tag.decompose() for tag in soup.find_all('script')]
Beautiful Soup - 移除空标签
在 HTML 中,许多标签都有开始标签和结束标签。此类标签主要用于定义格式属性,例如 <b> 和 </b>、<h1> 和 </h1> 等。还有一些自闭合标签没有结束标签,也没有文本部分。例如 <img>、<br>、<input> 等。但是,在编写 HTML 时,可能会无意中插入诸如 <p></p> 之类的没有文本的标签。我们需要借助 Beautiful Soup 库函数删除此类空标签。
删除开始和结束符号之间没有任何文本的文本标签很容易。如果标签的内部文本长度为 0,则可以在标签上调用 extract() 方法。
for tag in tags:
if (len(tag.get_text(strip=True)) == 0):
tag.extract()
但是,这会删除 <hr>、<img> 和 <input> 等标签。这些都是自闭合或单例标签。即使与标签没有关联的文本,您也不希望关闭具有一个或多个属性的标签。因此,您必须检查标签是否具有任何属性以及 get_text() 是否返回 None。
在下面的示例中,HTML 字符串中同时存在空文本标签和一些单例标签的情况。该代码保留了具有属性的标签,但删除了没有任何嵌入文本的标签。
示例
html ='''
<html>
<body>
<p>Paragraph</p>
<embed type="image/jpg" src="Python logo.jpg" width="300" height="200">
<hr>
<b></b>
<p>
<a href="#">Link</a>
<ul>
<li>One</li>
</ul>
<input type="text" id="fname" name="fname">
<img src="img_orange_flowers.jpg" alt="Flowers">
</body>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
tags =soup.find_all()
for tag in tags:
if (len(tag.get_text(strip=True)) == 0):
if len(tag.attrs)==0:
tag.extract()
print (soup)
输出
<html> <body> <p>Paragraph</p> <embed height="200" src="Python logo.jpg" type="image/jpg" width="300"/> <p> <a href="#">Link</a> <ul> <li>One</li> </ul> <input id="fname" name="fname" type="text"/> <img alt="Flowers" src="img_orange_flowers.jpg"/> </p> </body> </html>
请注意,原始 html 代码有一个没有其结束 </p> 的 <p> 标签。解析器会自动插入结束标签。如果您将解析器更改为 lxml 或 html5lib,结束标签的位置可能会更改。
Beautiful Soup - 移除子元素
HTML 文档是不同标签的层次结构排列,其中一个标签可能在多个级别嵌套一个或多个标签。我们如何删除某个标签的子元素?使用 BeautifulSoup,这很容易做到。
Beautiful Soup 库中有两种主要方法可以删除某个标签。decompose() 方法和 extract() 方法,区别在于后者返回已删除的内容,而前者只是销毁它。
因此,要删除子元素,请为给定的 Tag 对象调用 findChildren() 方法,然后对每个子元素调用 extract() 或 decompose()。
考虑以下代码段:
soup = BeautifulSoup(fp, "html.parser") soup.decompose() print (soup)
这将销毁整个 soup 对象本身,它是文档的解析树。显然,我们不想这样做。
现在以下代码:
soup = BeautifulSoup(fp, "html.parser")
tags = soup.find_all()
for tag in tags:
for t in tag.findChildren():
t.extract()
在文档树中,<html> 是第一个标签,所有其他标签都是它的子元素,因此它将在循环的第一次迭代中删除除 <html> 和 </html> 之外的所有标签。
如果我们想要删除特定标签的子元素,可以更有效地使用它。例如,您可能希望删除 HTML 表格的标题行。
以下 HTML 脚本有一个表格,其中第一个 <tr> 元素的标题由 <th> 标签标记。
<html>
<body>
<h2>Beautiful Soup - Remove Child Elements</h2>
<table border="1">
<tr class='header'>
<th>Name</th>
<th>Age</th>
<th>Marks</th>
</tr>
<tr>
<td>Ravi</td>
<td>23</td>
<td>67</td>
</tr>
<tr>
<td>Anil</td>
<td>27</td>
<td>84</td>
</tr>
</table>
</body>
</html>
我们可以使用以下 Python 代码删除 <tr> 标签的所有子元素,包括 <th> 单元格。
示例
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, "html.parser")
tags = soup.find_all('tr', {'class':'header'})
for tag in tags:
for t in tag.findChildren():
t.extract()
print (soup)
输出
<html> <body> <h2>Beautiful Soup - Parse Table</h2> <table border="1"> <tr class="header"> </tr> <tr> <td>Ravi</td> <td>23</td> <td>67</td> </tr> <tr> <td>Anil</td> <td>27</td> <td>84</td> </tr> </table> </body> </html>
可以看出,<th> 元素已从解析树中删除。
Beautiful Soup - find 与 find_all 的区别
Beautiful Soup 库包含 find() 和 find_all() 方法。这两种方法是解析 HTML 或 XML 文档时最常用的方法之一。从特定的文档树中,您经常需要定位特定标签类型、具有特定属性或具有特定 CSS 样式等的 PageElement。这些条件作为参数传递给 find() 和 find_all() 方法。这两个方法的主要区别在于,find() 定位满足条件的第一个子元素,而 find_all() 方法搜索满足条件的所有子元素。
find() 方法的语法定义如下:
语法
find(name, attrs, recursive, string, **kwargs)
name 参数指定对标签名称的过滤。使用 attrs,可以设置对标签属性值的过滤。如果 recursive 参数为 True,则强制进行递归搜索。您可以将变量 kwargs 作为属性值过滤器字典传递。
soup.find(id = 'nm')
soup.find(attrs={"name":'marks'})
find_all() 方法接受 find() 方法的所有参数,此外还有一个 limit 参数。它是一个整数,将搜索限制为给定筛选条件出现的指定次数。如果未设置,find_all() 会在所述 PageElement 下的所有子元素中搜索条件。
soup.find_all('input')
lst=soup.find_all('li', limit =2)
如果 find_all() 方法的 limit 参数设置为 1,则它实际上充当 find() 方法。
两种方法的返回类型不同。find() 方法返回第一个找到的 Tag 对象或 NavigableString 对象。find_all() 方法返回一个 ResultSet,其中包含满足筛选条件的所有 PageElement。
以下示例演示了 find 和 find_all 方法之间的区别。
示例
from bs4 import BeautifulSoup
markup =open("index.html")
soup = BeautifulSoup(markup, 'html.parser')
ret1 = soup.find('input')
ret2 = soup.find_all ('input')
print (ret1, 'Return type of find:', type(ret1))
print (ret2)
print ('Return tyoe find_all:', type(ret2))
#set limit =1
ret3 = soup.find_all ('input', limit=1)
print ('find:', ret1)
print ('find_all:', ret3)
输出
<input id="nm" name="name" type="text"/> Return type of find: <class 'bs4.element.Tag'> [<input id="nm" name="name" type="text"/>, <input id="age" name="age" type="text"/>, <input id="marks" name="marks" type="text"/>] Return tyoe find_all: <class 'bs4.element.ResultSet'> find: <input id="nm" name="name" type="text"/> find_all: [<input id="nm" name="name" type="text"/>]
Beautiful Soup - 指定解析器
HTML 文档树被解析到 BeautifulSoup 类的对象中。此类的构造函数需要 HTML 字符串或指向 html 文件的文件对象作为必填参数。构造函数具有所有其他可选参数,其中重要的是 features。
BeautifulSoup(markup, features)
这里 markup 是一个 HTML 字符串或文件对象。features 参数指定要使用的解析器。它可以是特定的解析器,例如“lxml”、“lxml-xml”、“html.parser”或“html5lib”;或要使用的标记类型(“html”、“html5”、“xml”)。
如果未提供 features 参数,则 BeautifulSoup 会选择安装的最佳 HTML 解析器。Beautiful Soup 将 lxml 的解析器评为最佳,然后是 html5lib 的解析器,最后是 Python 的内置解析器。
您可以指定以下之一:
您要解析的标记类型。Beautiful Soup 当前支持“html”、“xml”和“html5”。
要使用的解析器库的名称。当前支持的选项为“lxml”、“html5lib”和“html.parser”(Python 的内置 HTML 解析器)。
要安装 lxml 或 html5lib 解析器,请使用以下命令:
pip3 install lxml pip3 install html5lib
这些解析器各有优缺点,如下所示:
解析器:Python 的 html.parser
用法 − BeautifulSoup(markup, "html.parser")
优点
- 内置
- 速度不错
- 宽容(从 Python 3.2 开始)
缺点
- 速度不如 lxml,宽容度不如 html5lib。
解析器:lxml 的 HTML 解析器
用法 − BeautifulSoup(markup, "lxml")
优点
- 非常快
- 宽松的
缺点
- 外部 C 依赖
解析器:lxml 的 XML 解析器
用法 − BeautifulSoup(markup, "lxml-xml")
或 BeautifulSoup(markup, "xml")
优点
- 非常快
- 目前唯一支持的 XML 解析器
缺点
- 外部 C 依赖
解析器:html5lib
用法 − BeautifulSoup(markup, "html5lib")
优点
- 极其宽松
- 以与网络浏览器相同的方式解析页面
- 创建有效的 HTML5
缺点
- 非常慢
- 外部 Python 依赖
不同的解析器将从同一文档创建不同的解析树。HTML 解析器和 XML 解析器之间存在最大的差异。这是一个简短的文档,作为 HTML 解析:
示例
from bs4 import BeautifulSoup
soup = BeautifulSoup("<a><b /></a>", "html.parser")
print (soup)
输出
<a><b></b></a>
空的 <b /> 标签不是有效的 HTML。因此,解析器将其转换为 <b></b> 标签对。
现在将同一文档作为 XML 解析。请注意,空的 <b /> 标签保持不变,并且该文档被赋予 XML 声明而不是放入 <html> 标签中。
示例
from bs4 import BeautifulSoup
soup = BeautifulSoup("<a><b /></a>", "xml")
print (soup)
输出
<?xml version="1.0" encoding="utf-8"?> <a><b/></a>
对于格式良好的 HTML 文档,所有 HTML 解析器都会产生类似的解析树,尽管一个解析器会比另一个解析器更快。
但是,如果 HTML 文档不完美,则不同类型的解析器会产生不同的结果。请参阅当“<a></p>” 使用不同的解析器解析时结果有何不同:
lxml 解析器
示例
from bs4 import BeautifulSoup
soup = BeautifulSoup("<a></p>", "lxml")
print (soup)
输出
<html><body><a></a></body></html>
请注意,悬挂的 </p> 标签被简单地忽略了。
html5lib 解析器
示例
from bs4 import BeautifulSoup
soup = BeautifulSoup("<a></p>", "html5lib")
print (soup)
输出
<html><head></head><body><a><p></p></a></body></html>
html5lib 将其与一个起始 <p> 标签配对。此解析器还向文档添加了一个空的 <head> 标签。
内置 html 解析器
示例
Built in from bs4 import BeautifulSoup
soup = BeautifulSoup("<a></p>", "html.parser")
print (soup)
输出
<a></a>
此解析器也会忽略结束 </p> 标签。但是,此解析器不会尝试通过添加 <body> 标签来创建格式良好的 HTML 文档,甚至不费心添加 <html> 标签。
html5lib 解析器使用 HTML5 标准中包含的技术,因此它对成为“正确”方法拥有最佳主张。
Beautiful Soup - 比较对象
根据 beautiful soup,如果两个可导航字符串或标签对象表示相同的 HTML/XML 标记,则它们相等。
现在让我们看看下面的示例,其中两个 <b> 标签被视为相等,即使它们位于对象树的不同部分,因为它们都看起来像“<b>Java</b>”。
示例
from bs4 import BeautifulSoup
markup = "<p>Learn <i>Python</i>, <b>Java</b>, advanced <i>Python</i> and advanced <b>Java</b>! from Tutorialspoint</p>"
soup = BeautifulSoup(markup, "html.parser")
b1 = soup.find('b')
b2 = b1.find_next('b')
print(b1== b2)
print(b1 is b2)
输出
True False
在以下示例中,比较了两个 NavigableString 对象。
示例
from bs4 import BeautifulSoup
markup = "<p>Learn <i>Python</i>, <b>Java</b>, advanced <i>Python</i> and advanced <b>Java</b>! from Tutorialspoint</p>"
soup = BeautifulSoup(markup, "html.parser")
i1 = soup.find('i')
i2 = i1.find_next('i')
print(i1.string== i2.string)
print(i1.string is i2.string)
输出
True False
Beautiful Soup - 复制对象
要创建任何标签或 NavigableString 的副本,请使用 Python 标准库中 copy 模块的 copy() 函数。
示例
from bs4 import BeautifulSoup
import copy
markup = "<p>Learn <b>Python, Java</b>, <i>advanced Python and advanced Java</i>! from Tutorialspoint</p>"
soup = BeautifulSoup(markup, "html.parser")
i1 = soup.find('i')
icopy = copy.copy(i1)
print (icopy)
输出
<i>advanced Python and advanced Java</i>
尽管两个副本(原始副本和复制副本)包含相同的标记,但是这两个副本不表示相同的对象。
print (i1 == icopy) print (i1 is icopy)
输出
True False
复制的对象完全与原始 Beautiful Soup 对象树分离,就像在它上面调用了 extract() 一样。
print (icopy.parent)
输出
None
Beautiful Soup - 获取标签位置
Beautiful Soup 中的 Tag 对象拥有两个有用的属性,它们提供了有关其在 HTML 文档中的位置的信息。它们是:
sourceline - 找到标签的行号
sourcepos - 找到标签所在行的标签的起始索引。
这些属性受 Python 的内置解析器 html.parser 和 html5lib 解析器支持。当您使用 lmxl 解析器时,它们不可用。
在以下示例中,HTML 字符串使用 html.parser 进行解析,我们找到 HTML 字符串中 <p> 标签的行号和位置。
示例
html = '''
<html>
<body>
<p>Web frameworks</p>
<ul>
<li>Django</li>
<li>Flask</li>
</ul>
<p>GUI frameworks</p>
<ol>
<li>Tkinter</li>
<li>PyQt</li>
</ol>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
p_tags = soup.find_all('p')
for p in p_tags:
print (p.sourceline, p.sourcepos, p.string)
输出
4 0 Web frameworks 9 0 GUI frameworks
对于 html.parser,这些数字表示初始小于号的位置,在本例中为 0。当使用 html5lib 解析器时,它略有不同。
示例
html = '''
<html>
<body>
<p>Web frameworks</p>
<ul>
<li>Django</li>
<li>Flask</li>
</ul>
<p>GUI frameworks</p>
<ol>
<li>Tkinter</li>
<li>PyQt</li>
</ol>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html5lib')
li_tags = soup.find_all('li')
for l in li_tags:
print (l.sourceline, l.sourcepos, l.string)
输出
6 3 Django 7 3 Flask 11 3 Tkinter 12 3 PyQt
当使用 html5lib 时,sourcepos 属性返回最终大于号的位置。
Beautiful Soup - 编码
所有 HTML 或 XML 文档都以某种特定的编码(如 ASCII 或 UTF-8)编写。但是,当您将该 HTML/XML 文档加载到 BeautifulSoup 中时,它已转换为 Unicode。
示例
from bs4 import BeautifulSoup markup = "<p>I will display £</p>" soup = BeautifulSoup(markup, "html.parser") print (soup.p) print (soup.p.string)
输出
<p>I will display £</p> I will display £
上述行为是因为 BeautifulSoup 在内部使用名为 Unicode、Dammit 的子库来检测文档的编码,然后将其转换为 Unicode。
但是,并非总是如此,Unicode、Dammit 的猜测都是正确的。由于逐字节搜索文档以猜测编码,因此需要花费大量时间。如果您已经知道编码,则可以通过将其作为 from_encoding 传递给 BeautifulSoup 构造函数来节省一些时间并避免错误。
以下是一个示例,其中 BeautifulSoup 将 ISO-8859-8 文档错误识别为 ISO-8859-7:
示例
from bs4 import BeautifulSoup markup = b"<h1>\xed\xe5\xec\xf9</h1>" soup = BeautifulSoup(markup, 'html.parser') print (soup.h1) print (soup.original_encoding)
输出
<h1>翴檛</h1> ISO-8859-7
要解决上述问题,请使用 from_encoding 将其传递给 BeautifulSoup:
示例
from bs4 import BeautifulSoup markup = b"<h1>\xed\xe5\xec\xf9</h1>" soup = BeautifulSoup(markup, "html.parser", from_encoding="iso-8859-8") print (soup.h1) print (soup.original_encoding)
输出
<h1>םולש</h1> iso-8859-8
从 BeautifulSoup 4.4.0 开始添加的另一个新功能是 exclude_encoding。当您不知道正确的编码,但确定 Unicode、Dammit 显示错误结果时,可以使用它。
soup = BeautifulSoup(markup, exclude_encodings=["ISO-8859-7"])
输出编码
无论输入到 BeautifulSoup 的文档是什么,来自 BeautifulSoup 的输出都是 UTF-8 文档。以下是一个文档,其中波兰字符以 ISO-8859-2 格式存在。
示例
markup = """
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<HTML>
<HEAD>
<META HTTP-EQUIV="content-type" CONTENT="text/html; charset=iso-8859-2">
</HEAD>
<BODY>
ą ć ę ł ń ó ś ź ż Ą Ć Ę Ł Ń Ó Ś Ź Ż
</BODY>
</HTML>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(markup, "html.parser", from_encoding="iso-8859-8")
print (soup.prettify())
输出
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<html>
<head>
<meta content="text/html; charset=utf-8" http-equiv="content-type"/>
</head>
<body>
ą ć ę ł ń ó ś ź ż Ą Ć Ę Ł Ń Ó Ś Ź Ż
</body>
</html>
在上面的示例中,如果您注意到了,<meta> 标签已被重写以反映从 BeautifulSoup 生成的文档现在采用 UTF-8 格式。
如果您不希望生成的输出为 UTF-8,则可以在 prettify() 中分配所需的编码。
print(soup.prettify("latin-1"))
输出
b'<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">\n<html>\n <head>\n <meta content="text/html; charset=latin-1" http-equiv="content-type"/>\n </head>\n <body>\n ą ć ę ł ń \xf3 ś ź ż Ą Ć Ę Ł Ń \xd3 Ś Ź Ż\n </body>\n</html>\n'
在上面的示例中,我们对整个文档进行了编码,但是您可以对 soup 中的任何特定元素进行编码,就像它们是 python 字符串一样:
soup.p.encode("latin-1")
soup.h1.encode("latin-1")
输出
b'<p>My first paragraph.</p>' b'<h1>My First Heading</h1>'
任何无法在您选择的编码中表示的字符都将转换为数字 XML 实体引用。以下是一个这样的示例:
markup = u"<b>\N{SNOWMAN}</b>"
snowman_soup = BeautifulSoup(markup)
tag = snowman_soup.b
print(tag.encode("utf-8"))
输出
b'<b>\xe2\x98\x83</b>'
如果您尝试在“latin-1”或“ascii”中对其进行编码,它将生成“☃”,表示没有该字符的表示形式。
print (tag.encode("latin-1"))
print (tag.encode("ascii"))
输出
b'<b>☃</b>' b'<b>☃</b>'
Unicode、Dammit
Unicode、Dammit 主要用于传入文档格式未知(主要是外语)且我们希望以某种已知格式(Unicode)进行编码,并且我们不需要 Beautifulsoup 执行所有这些操作的情况。
Beautiful Soup - 输出格式化
如果传递给 BeautifulSoup 构造函数的 HTML 字符串包含任何 HTML 实体,它们将转换为 Unicode 字符。
HTML 实体是以 & 开头并以 ; 结尾的字符串。它们用于显示保留字符(否则将被解释为 HTML 代码)。一些 HTML 实体示例如下:
| < | 小于 | < | < |
| > | 大于 | > | > |
| & | 和号 | & | & |
| " | 双引号 | " | " |
| ' | 单引号 | ' | ' |
| " | 左双引号 | “ | “ |
| " | 右双引号 | ” | ” |
| £ | 英镑 | £ | £ |
| ¥ | 日元 | ¥ | ¥ |
| € | 欧元 | € | € |
| © | 版权 | © | © |
默认情况下,输出时唯一转义的字符是裸和号和尖括号。它们将转换为“&”、“<”和“>”。
对于其他字符,它们将转换为 Unicode 字符。
示例
from bs4 import BeautifulSoup
soup = BeautifulSoup("Hello “World!”", 'html.parser')
print (str(soup))
输出
Hello "World!"
如果您随后将文档转换为字节字符串,则 Unicode 字符将编码为 UTF-8。您将无法取回 HTML 实体:
示例
from bs4 import BeautifulSoup
soup = BeautifulSoup("Hello “World!”", 'html.parser')
print (soup.encode())
输出
b'Hello \xe2\x80\x9cWorld!\xe2\x80\x9d'
要更改此行为,请为 prettify() 方法的 formatter 参数提供一个值。formatter 有以下可能的值。
formatter="minimal" - 这是默认值。字符串将仅被处理到足以确保 Beautiful Soup 生成有效的 HTML/XML。
formatter="html" - Beautiful Soup 将尽可能地将 Unicode 字符转换为 HTML 实体。
formatter="html5" - 它类似于 formatter="html",但 Beautiful Soup 将省略 HTML 空标签(如“br”)中的结束斜杠。
formatter=None - Beautiful Soup 根本不会修改输出的字符串。这是最快的选项,但可能导致 Beautiful Soup 生成无效的 HTML/XML。
示例
from bs4 import BeautifulSoup
french = "<p>Il a dit <<Sacré bleu!>></p>"
soup = BeautifulSoup(french, 'html.parser')
print ("minimal: ")
print(soup.prettify(formatter="minimal"))
print ("html: ")
print(soup.prettify(formatter="html"))
print ("None: ")
print(soup.prettify(formatter=None))
输出
minimal: <p> Il a dit <<Sacré bleu!>> </p> html: <p> Il a dit <<Sacré bleu!>> </p> None: <p> Il a dit <<Sacré bleu!>> </p>
此外,Beautiful Soup 库还提供了 formatter 类。您可以将任何这些类的对象作为参数传递给 prettify() 方法。
HTMLFormatter 类 - 用于自定义 HTML 文档的格式规则。
XMLFormatter 类 - 用于自定义 XML 文档的格式规则。
Beautiful Soup - 美化输出
要显示 HTML 文档的整个解析树或特定标签的内容,您可以使用 print() 函数或调用 str() 函数。
示例
from bs4 import BeautifulSoup
soup = BeautifulSoup("<h1>Hello World</h1>", "lxml")
print ("Tree:",soup)
print ("h1 tag:",str(soup.h1))
输出
Tree: <html><body><h1>Hello World</h1></body></html> h1 tag: <h1>Hello World</h1>
str() 函数返回一个以 UTF-8 编码的字符串。
要获得格式良好的 Unicode 字符串,请使用 Beautiful Soup 的 prettify() 方法。它格式化 Beautiful Soup 解析树,以便每个标签都位于自己的单独行并带有缩进。它允许您轻松地可视化 Beautiful Soup 解析树的结构。
考虑以下 HTML 字符串。
<p>The quick, <b>brown fox</b> jumps over a lazy dog.</p>
使用 prettify() 方法,我们可以更好地理解其结构:
html = ''' <p>The quick, <b>brown fox</b> jumps over a lazy dog.</p> ''' from bs4 import BeautifulSoup soup = BeautifulSoup(html, "lxml") print (soup.prettify())
输出
<html>
<body>
<p>
The quick,
<b>
brown fox
</b>
jumps over a lazy dog.
</p>
</body>
</html>
您可以在文档中的任何 Tag 对象上调用 prettify()。
print (soup.b.prettify())
输出
<b> brown fox </b>
prettify() 方法用于理解文档的结构。但是,它不应用于重新格式化它,因为它添加了空格(以换行符的形式),并更改了 HTML 文档的含义。
He prettify() 方法可以选择提供 formatter 参数来指定要使用的格式。
Beautiful Soup - NavigableString 类
Beautiful Soup API 中一个主要的常用对象是 NavigableString 类对象。它表示大多数 HTML 标签的开始和结束标记之间的字符串或文本。例如,如果 <b>Hello</b> 是要解析的标记,则 Hello 就是 NavigableString。
NavigableString 类是 bs4 包中 PageElement 类的子类,同时也是 Python 内置的 str 类的子类。因此,它继承了 PageElement 方法,如 find_*()、insert、append、wrap、unwrap 方法,以及 str 类的方法,如 upper、lower、find、isalpha 等。
此类的构造函数接受一个参数,一个 str 对象。
示例
from bs4 import NavigableString
new_str = NavigableString('world')
现在可以使用此 NavigableString 对象对解析后的树执行各种操作,例如 append、insert、find 等。
在下面的示例中,我们将新创建的 NavigableString 对象追加到现有的 Tab 对象。
示例
from bs4 import BeautifulSoup, NavigableString
markup = '<b>Hello</b>'
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.b
new_str = NavigableString('world')
tag.append(new_str)
print (soup)
输出
<b>Helloworld</b>
请注意,NavigableString 是一个 PageElement,因此它也可以追加到 Soup 对象。检查如果这样做会有什么区别。
示例
new_str = NavigableString('world')
soup.append(new_str)
print (soup)
输出
<b>Hello</b>world
如我们所见,字符串出现在 <b> 标签之后。
Beautiful Soup 提供了一个 new_string() 方法。创建一个与此 BeautifulSoup 对象关联的新 NavigableString。
让我们使用 new_string() 方法创建一个 NavigableString 对象,并将其添加到 PageElements 中。
示例
from bs4 import BeautifulSoup, NavigableString
markup = '<b>Hello</b>'
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.b
ns=soup.new_string(' World')
tag.append(ns)
print (tag)
soup.append(ns)
print (soup)
输出
<b>Hello World</b> <b>Hello</b> World
我们在这里发现了一个有趣的行为。NavigableString 对象被添加到树中的一个标签中,以及 Soup 对象本身。虽然标签显示了追加的字符串,但在 Soup 对象中,文本 World 被追加,但它没有显示在标签中。这是因为 new_string() 方法创建了一个与 Soup 对象关联的 NavigableString。
Beautiful Soup - 将对象转换为字符串
Beautiful Soup API 有三种主要类型的对象:Soup 对象、Tag 对象和 NavigableString 对象。让我们找出如何将这些对象中的每一个转换为字符串。在 Python 中,字符串是 str 对象。
假设我们有以下 HTML 文档
html = ''' <p>Hello <b>World</b></p> '''
让我们将此字符串作为 BeautifulSoup 构造函数的参数。然后,Soup 对象使用 Python 的内置 str() 函数转换为字符串对象。
此 HTML 字符串的解析树将根据您使用的解析器构建。内置的 html 解析器不会添加 <html> 和 <body> 标签。
示例
from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'html.parser') print (str(soup))
输出
<p>Hello <b>World</b></p>
另一方面,html5lib 解析器在插入正式标签(如 <html> 和 <body>)后构建树。
from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'html5lib') print (str(soup))
输出
<html><head></head><body><p>Hello <b>World</b></p> </body></html>
Tag 对象有一个字符串属性,它返回一个 NavigableString 对象。
tag = soup.find('b')
obj = (tag.string)
print (type(obj),obj)
输出
string <class 'bs4.element.NavigableString'> World
Tag 对象还定义了一个 Text 属性。它返回标签中包含的文本,剥离所有内部标签和属性。
如果 HTML 字符串为 -
html = ''' <p>Hello <div id='id'>World</div></p> '''
我们尝试获取 <p> 标签的 text 属性
tag = soup.find('p')
obj = (tag.text)
print ( type(obj), obj)
输出
<class 'str'> Hello World
您还可以使用 get_text() 方法,该方法返回表示标签内文本的字符串。该函数实际上是 text 属性的包装器,因为它也去除了内部标签和属性,并返回一个字符串
obj = tag.get_text() print (type(obj),obj)
输出
<class 'str'> Hello World
Beautiful Soup - 将 HTML 转换为文本
像 Beautiful Soup 库这样的 Web 爬虫的一个重要且经常需要的应用是从 HTML 脚本中提取文本。您可能需要丢弃所有标签以及与每个标签关联的属性(如果有),并分离出文档中的原始文本。Beautiful Soup 中的 get_text() 方法适合此目的。
这是一个演示 get_text() 方法用法的基本示例。通过删除所有 HTML 标签,您可以获取 HTML 文档中的所有文本。
示例
html = '''
<html>
<body>
<p> The quick, brown fox jumps over a lazy dog.</p>
<p> DJs flock by when MTV ax quiz prog.</p>
<p> Junk MTV quiz graced by fox whelps.</p>
<p> Bawds jog, flick quartz, vex nymphs.</p>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
text = soup.get_text()
print(text)
输出
The quick, brown fox jumps over a lazy dog. DJs flock by when MTV ax quiz prog. Junk MTV quiz graced by fox whelps. Bawds jog, flick quartz, vex nymphs.
get_text() 方法有一个可选的分隔符参数。在下面的示例中,我们将 get_text() 方法的分隔符参数指定为 '#'。
html = ''' <p>The quick, brown fox jumps over a lazy dog.</p> <p>DJs flock by when MTV ax quiz prog.</p> <p>Junk MTV quiz graced by fox whelps.</p> <p>Bawds jog, flick quartz, vex nymphs.</p> ''' from bs4 import BeautifulSoup soup = BeautifulSoup(html, "html.parser") text = soup.get_text(separator='#') print(text)
输出
#The quick, brown fox jumps over a lazy dog.# #DJs flock by when MTV ax quiz prog.# #Junk MTV quiz graced by fox whelps.# #Bawds jog, flick quartz, vex nymphs.#
get_text() 方法还有另一个参数 strip,它可以是 True 或 False。让我们检查当 strip 参数设置为 True 时产生的效果。默认情况下它为 False。
html = ''' <p>The quick, brown fox jumps over a lazy dog.</p> <p>DJs flock by when MTV ax quiz prog.</p> <p>Junk MTV quiz graced by fox whelps.</p> <p>Bawds jog, flick quartz, vex nymphs.</p> ''' from bs4 import BeautifulSoup soup = BeautifulSoup(html, "html.parser") text = soup.get_text(strip=True) print(text)
输出
The quick, brown fox jumps over a lazy dog.DJs flock by when MTV ax quiz prog.Junk MTV quiz graced by fox whelps.Bawds jog, flick quartz, vex nymphs.
Beautiful Soup - 解析 XML
BeautifulSoup 还可以解析 XML 文档。您需要将 fatures='xml' 参数传递给 Beautiful() 构造函数。
假设我们在当前工作目录中有以下 books.xml -
示例
<?xml version="1.0" ?>
<books>
<book>
<title>Python</title>
<author>TutorialsPoint</author>
<price>400</price>
</book>
</books>
以下代码解析给定的 XML 文件 -
from bs4 import BeautifulSoup
fp = open("books.xml")
soup = BeautifulSoup(fp, features="xml")
print (soup)
print ('type:', type(soup))
执行上述代码后,您应该得到以下结果 -
<?xml version="1.0" encoding="utf-8"?> <books> <book> <title>Python</title> <author>TutorialsPoint</author> <price>400</price> </book> </books> type: <class 'bs4.BeautifulSoup'>
XML 解析器错误
默认情况下,BeautifulSoup 包将文档解析为 HTML,但是,它非常易于使用,并且可以使用 beautifulsoup4 以非常优雅的方式处理格式错误的 XML。
要将文档解析为 XML,您需要安装 lxml 解析器,只需将“xml”作为第二个参数传递给 Beautifulsoup 构造函数 -
soup = BeautifulSoup(markup, "lxml-xml")
或
soup = BeautifulSoup(markup, "xml")
一个常见的 XML 解析错误是 -
AttributeError: 'NoneType' object has no attribute 'attrib'
这可能发生在使用 find() 或 findall() 函数时缺少或未定义某些元素的情况下。
Beautiful Soup - 错误处理
在尝试使用 Beautiful Soup 解析 HTML/XML 文档时,您可能会遇到错误,这些错误不是来自您的脚本,而是来自代码段的结构,因为 BeautifulSoup API 会抛出错误。
默认情况下,BeautifulSoup 包将文档解析为 HTML,但是,它非常易于使用,并且可以使用 beautifulsoup4 以非常优雅的方式处理格式错误的 XML。
要将文档解析为 XML,您需要安装 lxml 解析器,只需将“xml”作为第二个参数传递给 Beautifulsoup 构造函数 -
soup = BeautifulSoup(markup, "lxml-xml")
或
soup = BeautifulSoup(markup, "xml")
一个常见的 XML 解析错误是 -
AttributeError: 'NoneType' object has no attribute 'attrib'
这可能发生在使用 find() 或 findall() 函数时缺少或未定义某些元素的情况下。
除了上述解析错误之外,您可能会遇到其他解析问题,例如环境问题,您的脚本可能在一个操作系统中工作,但在另一个操作系统中不工作,或者可能在一个虚拟环境中工作,但在另一个虚拟环境中不工作,或者可能在虚拟环境外部不工作。所有这些问题可能是因为这两个环境具有不同的解析器库可用。
建议了解或检查您当前工作环境中的默认解析器。您可以检查当前工作环境中可用的当前默认解析器,或者显式地将所需的解析器库作为第二个参数传递给 BeautifulSoup 构造函数。
由于 HTML 标签和属性不区分大小写,因此所有三个 HTML 解析器都将标签和属性名称转换为小写。但是,如果您想保留混合大小写或大写标签和属性,那么最好将文档解析为 XML。
UnicodeEncodeError
让我们看一下下面的代码段 -
示例
soup = BeautifulSoup(response, "html.parser") print (soup)
输出
UnicodeEncodeError: 'charmap' codec can't encode character '\u011f'
上述问题可能是由于两种主要情况造成的。您可能正在尝试打印控制台不知道如何显示的 Unicode 字符。其次,您正在尝试写入文件,并且传递了一个默认编码不支持的 Unicode 字符。
解决上述问题的一种方法是在将响应文本/字符转换为 Soup 之前对其进行编码以获得所需的结果,如下所示 -
responseTxt = response.text.encode('UTF-8')
KeyError: [attr]
当您访问 tag['attr'] 时,而所讨论的标签未定义 attr 属性时,就会发生这种情况。最常见的错误是:“KeyError: 'href'”和“KeyError: 'class'”。如果您不确定是否定义了 attr,请使用 tag.get('attr')。
for item in soup.fetch('a'):
try:
if (item['href'].startswith('/') or "tutorialspoint" in item['href']):
(...)
except KeyError:
pass # or some other fallback action
AttributeError
您可能会遇到如下 AttributeError -
AttributeError: 'list' object has no attribute 'find_all'
上述错误主要发生是因为您期望 find_all() 返回单个标签或字符串。但是,soup.find_all 返回一个 Python 元素列表。
您需要做的就是遍历列表并从这些元素中捕获数据。
为了避免在解析结果时出现上述错误,将绕过该结果以确保格式错误的代码段不会插入数据库中 -
except(AttributeError, KeyError) as er: pass
Beautiful Soup - 故障排除
如果您在尝试解析 HTML/XML 文档时遇到问题,则更有可能是因为所使用的解析器如何解释文档。为了帮助您找到并纠正问题,Beautiful Soup API 提供了一个 diagnose() 实用程序。
Beautiful Soup 中的 diagnose() 方法是用于隔离常见问题的诊断套件。如果您难以理解 Beautiful Soup 对文档做了什么,请将文档作为参数传递给 diagnose() 函数。一个报告将向您展示不同的解析器如何处理文档,并告诉您是否缺少解析器。
diagnose() 方法在 bs4.diagnose 模块中定义。它的输出以如下消息开头 -
示例
diagnose(markup)
输出
Diagnostic running on Beautiful Soup 4.12.2 Python version 3.11.2 (tags/v3.11.2:878ead1, Feb 7 2023, 16:38:35) [MSC v.1934 64 bit (AMD64)] Found lxml version 4.9.2.0 Found html5lib version 1.1 Trying to parse your markup with html.parser Here's what html.parser did with the markup:
如果它找不到任何这些解析器,也会出现相应的提示。
I noticed that html5lib is not installed. Installing it may help.
如果提供给 diagnose() 方法的 HTML 文档格式正确,则任何解析器解析的树都将相同。但是,如果格式不正确,则不同的解析器会进行不同的解释。如果您没有获得预期的树,则更改解析器可能会有所帮助。
有时,您可能为 XML 文档选择了 HTML 解析器。HTML 解析器在错误地解析文档时会添加所有 HTML 标签。查看输出,您将意识到错误并可以帮助纠正。
如果 Beautiful Soup 抛出 HTMLParser.HTMLParseError,请尝试更改解析器。
解析错误 HTMLParser.HTMLParseError: malformed start tag 和 HTMLParser.HTMLParseError: bad end tag 均由 Python 的内置 HTML 解析器库生成,解决方法是安装 lxml 或 html5lib。
如果您遇到 SyntaxError: Invalid syntax (在 ROOT_TAG_NAME = '[document]' 行上),这是因为在 Python 3 下运行旧版 Python 2 的 Beautiful Soup,而没有转换代码。
带有消息 No module named HTMLParser 的 ImportError 是因为在 Python 3 下运行旧版 Python 2 的 Beautiful Soup。
而 ImportError: No module named html.parser - 是因为在 Python 2 下运行 Python 3 版的 Beautiful Soup 造成的。
如果您收到 ImportError: No module named BeautifulSoup - 通常情况下,这是因为在未安装 BS3 的系统上运行 Beautiful Soup 3 代码。或者,在编写 Beautiful Soup 4 代码时不知道包名称已更改为 bs4。
最后,ImportError: No module named bs4 - 是因为您尝试在未安装 BS4 的系统上运行 Beautiful Soup 4 代码。
Beautiful Soup - 移植旧代码
您可以通过在 import 语句中进行以下更改,使早期版本的 Beautiful Soup 中的代码与最新版本兼容 -
示例
from BeautifulSoup import BeautifulSoup #becomes this: from bs4 import BeautifulSoup
如果您收到 ImportError“No module named BeautifulSoup”,则表示您正在尝试运行 Beautiful Soup 3 代码,但您只安装了 Beautiful Soup 4。类似地,如果您收到 ImportError“No module named bs4”,因为您正在尝试运行 Beautiful Soup 4 代码,但您只安装了 Beautiful Soup 3。
Beautiful Soup 3 使用 Python 的 SGMLParser,这是一个已在 Python 3.0 中删除的模块。Beautiful Soup 4 默认使用 html.parser,但您也可以使用 lxml 或 html5lib。
尽管 BS4 与 BS3 大致向后兼容,但其大多数方法已被弃用,并为符合 PEP 8 标准而改用了新名称。
以下是一些示例 -
replaceWith -> replace_with findAll -> find_all findNext -> find_next findParent -> find_parent findParents -> find_parents findPrevious -> find_previous getText -> get_text nextSibling -> next_sibling previousSibling -> previous_sibling
Beautiful Soup - contents 属性
方法描述
contents 属性可用于 Soup 对象和 Tag 对象。它返回对象内部的所有内容,所有直接子元素和文本节点(即 Navigable String)的列表。
语法
Tag.contents
返回值
contents 属性返回 Tag/Soup 对象中子元素和字符串的列表。
示例1
标签对象的內容 -
from bs4 import BeautifulSoup
markup = '''
<div id="Languages">
<p>Java</p>
<p>Python</p>
<p>C++</p>
</div>
'''
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.div
print (tag.contents)
输出
['\n', <p>Java</p>, '\n', <p>Python</p>, '\n', <p>C++</p>, '\n']
示例2
整个文档的內容 -
from bs4 import BeautifulSoup, NavigableString
markup = '''
<div id="Languages">
<p>Java</p> <p>Python</p> <p>C++</p>
</div>
'''
soup = BeautifulSoup(markup, 'html.parser')
print (soup.contents)
输出
['\n', <div id="Languages"> <p>Java</p> <p>Python</p> <p>C++</p> </div>, '\n']
示例 3
请注意,NavigableString 对象没有 contents 属性。如果尝试访问它,会引发 AttributeError。
from bs4 import BeautifulSoup, NavigableString
markup = '''
<div id="Languages">
<p>Java</p> <p>Python</p> <p>C++</p>
</div>
'''
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.p
s=tag.contents[0]
print (s.contents)
输出
Traceback (most recent call last):
File "C:\Users\user\BeautifulSoup\2.py", line 11, in <module>
print (s.contents)
^^^^^^^^^^
File "C:\Users\user\BeautifulSoup\Lib\site-packages\bs4\element.py", line 984, in __getattr__
raise AttributeError(
AttributeError: 'NavigableString' object has no attribute 'contents'
Beautiful Soup - children 属性
方法描述
Beautiful Soup 库中的 Tag 对象具有 children 属性。它返回一个生成器,用于迭代直接子元素和文本节点(即 Navigable String)。
语法
Tag.children
返回值
该属性返回一个生成器,您可以使用它来迭代 PageElement 的直接子元素。
示例1
from bs4 import BeautifulSoup, NavigableString
markup = '''
<div id="Languages">
<p>Java</p> <p>Python</p> <p>C++</p>
</div>
'''
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.div
children = tag.children
for child in children:
print (child)
输出
<p>Java</p> <p>Python</p> <p>C++</p>
示例2
soup 对象也具有 children 属性。
from bs4 import BeautifulSoup, NavigableString
markup = '''
<div id="Languages">
<p>Java</p> <p>Python</p> <p>C++</p>
</div>
'''
soup = BeautifulSoup(markup, 'html.parser')
children = soup.children
for child in children:
print (child)
输出
<div id="Languages"> <p>Java</p> <p>Python</p> <p>C++</p> </div>
示例 3
在以下示例中,我们将 NavigableString 对象追加到 <p> 标签并获取子元素列表。
from bs4 import BeautifulSoup, NavigableString
markup = '''
<div id="Languages">
<p>Java</p> <p>Python</p> <p>C++</p>
</div>
'''
soup = BeautifulSoup(markup, 'html.parser')
soup.p.extend(['and', 'JavaScript'])
children = soup.p.children
for child in children:
print (child)
输出
Java and JavaScript
Beautiful Soup - string 属性
方法描述
在 Beautiful Soup 中,soup 和 Tag 对象有一个便捷属性 - string 属性。它返回 PageElement、Soup 或 Tag 中的单个字符串。如果此元素只有一个字符串子元素,则返回相应的 NavigableString。如果此元素有一个子标签,则返回值是子标签的 'string' 属性,如果元素本身是一个字符串(没有子元素),则 string 属性返回 None。
语法
Tag.string
示例1
以下代码包含一个 HTML 字符串,其中包含一个 <div> 标签,该标签包含三个 <p> 元素。我们找到第一个 <p> 标签的 string 属性。
from bs4 import BeautifulSoup, NavigableString
markup = '''
<div id="Languages">
<p>Java</p> <p>Python</p> <p>C++</p>
</div>
'''
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.p
navstr = tag.string
print (navstr, type(navstr))
nav_str = str(navstr)
print (nav_str, type(nav_str))
输出
Java <class 'bs4.element.NavigableString'> Java <class 'str'>
string 属性返回一个 NavigableString。可以使用 str() 函数将其转换为常规的 Python 字符串。
示例2
包含子元素的元素的 string 属性返回 None。使用 <div> 标签进行检查。
tag = soup.div navstr = tag.string print (navstr)
输出
None
Beautiful Soup - strings 属性
方法描述
对于任何具有多个子元素的 PageElement,可以使用 strings 属性获取每个子元素的内部文本。与 string 属性不同,strings 处理元素包含多个子元素的情况。strings 属性返回一个生成器对象。它会产生一系列与每个子元素对应的 NavigableStrings。
语法
Tag.strings
示例1
您可以检索 soup 以及标签对象的 strings 属性的值。在以下示例中,检查了 soup 对象的 stings 属性。
from bs4 import BeautifulSoup, NavigableString
markup = '''
<div id="Languages">
<p>Java</p> <p>Python</p> <p>C++</p>
</div>
'''
soup = BeautifulSoup(markup, 'html.parser')
print ([string for string in soup.strings])
输出
['\n', '\n', 'Java', ' ', 'Python', ' ', 'C++', '\n', '\n']
请注意列表中的换行符和空格。我们可以使用 stripped_strings 属性将其删除。
示例2
现在,我们获得 <div> 标签的 strings 属性返回的生成器对象。使用循环打印字符串。
tag = soup.div navstrs = tag.strings for navstr in navstrs: print (navstr)
输出
Java Python C++
请注意,输出中出现了换行符和空格,可以使用 stripped_strings 属性将其删除。
Beautiful Soup - stripped_strings 属性
方法描述
Tag/Soup 对象的 stripped_strings 属性返回的结果与 strings 属性类似,只是额外换行符和空格被删除了。因此,可以说 stripped_strings 属性导致生成一系列属于正在使用对象的内部元素的 NavigableString 对象。
语法
Tag.stripped_strings
示例1
在下面的示例中,在应用剥离后,显示了在 BeautifulSoup 对象中解析的文档树中所有元素的字符串。
from bs4 import BeautifulSoup, NavigableString
markup = '''
<div id="Languages">
<p>Java</p> <p>Python</p> <p>C++</p>
</div>
'''
soup = BeautifulSoup(markup, 'html.parser')
print ([string for string in soup.stripped_strings])
输出
['Java', 'Python', 'C++']
与 strings 属性的输出相比,您可以看到换行符和空格被删除了。
示例2
在这里,我们提取 <div> 标签下每个子元素的 NavigableStrings。
tag = soup.div navstrs = tag.stripped_strings for navstr in navstrs: print (navstr)
输出
Java Python C++
Beautiful Soup - descendants 属性
方法描述
使用 Beautiful Soup API 中 PageElement 对象的 descendants 属性,您可以遍历其下所有子元素的列表。此属性返回一个生成器对象,可以使用它以广度优先的顺序检索子元素。
在搜索树结构时,广度优先遍历从树根开始,在移至下一深度级别的节点之前,先探索当前深度处的全部节点。
语法
tag.descendants
返回值
descendants 属性返回一个生成器对象。
示例1
在下面的代码中,我们有一个 HTML 文档,其中嵌套了无序列表标签。我们以广度优先的方式遍历解析的子元素。
html = '''
<ul id='outer'>
<li class="mainmenu">Accounts</li>
<ul>
<li class="submenu">Anand</li>
<li class="submenu">Mahesh</li>
</ul>
<li class="mainmenu">HR</li>
<ul>
<li class="submenu">Anil</li>
<li class="submenu">Milind</li>
</ul>
</ul>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
tag = soup.find('ul', {'id': 'outer'})
tags = soup.descendants
for desc in tags:
print (desc)
输出
<ul id="outer"> <li class="mainmenu">Accounts</li> <ul> <li class="submenu">Anand</li> <li class="submenu">Mahesh</li> </ul> <li class="mainmenu">HR</li> <ul> <li class="submenu">Anil</li> <li class="submenu">Milind</li> </ul> </ul> <li class="mainmenu">Accounts</li> Accounts <ul> <li class="submenu">Anand</li> <li class="submenu">Mahesh</li> </ul> <li class="submenu">Anand</li> Anand <li class="submenu">Mahesh</li> Mahesh <li class="mainmenu">HR</li> HR <ul> <li class="submenu">Anil</li> <li class="submenu">Milind</li> </ul> <li class="submenu">Anil</li> Anil <li class="submenu">Milind</li> Milind
示例2
在以下示例中,我们列出 <head> 标签的后代。
html = """ <html><head><title>TutorialsPoint</title></head> <body> <p>Hello World</p> """ from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'html.parser') tag = soup.head for element in tag.descendants: print (element)
输出
<title>TutorialsPoint</title> TutorialsPoint
Beautiful Soup - parent 属性
方法描述
Beautiful Soup 库中的 parent 属性返回所述 PegeElement 的直接父元素。parents 属性返回值的类型是 Tag 对象。对于 BeautifulSoup 对象,其父元素是文档对象。
语法
Element.parent
返回值
parent 属性返回一个 Tag 对象。对于 Soup 对象,它返回文档对象。
示例1
此示例使用 .parent 属性查找示例 HTML 字符串中第一个 <p> 标签的直接父元素。
html = """
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<p>Hello World</p>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
tag = soup.p
print (tag.parent.name)
输出
body
示例2
在以下示例中,我们看到 <title> 标签包含在 <head> 标签内。因此,<title> 标签的 parent 属性返回 <head> 标签。
html = """
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<p>Hello World</p>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
tag = soup.title
print (tag.parent)
输出
<head><title>TutorialsPoint</title></head>
示例 3
Python 内置的 HTML 解析器的行为与 html5lib 和 lxml 解析器略有不同。内置解析器不会尝试根据提供的字符串构建完美的文档。如果字符串中不存在 body 或 html 等其他父标签,它不会添加这些标签。另一方面,html5lib 和 lxml 解析器会添加这些标签以使文档成为完美的 HTML 文档。
html = """ <p><b>Hello World</b></p> """ from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'html.parser') print (soup.p.parent.name) soup = BeautifulSoup(html, 'html5lib') print (soup.p.parent.name)
输出
[document] Body
由于 HTML 解析器不会添加其他标签,因此解析后的 soup 的父元素是文档对象。但是,当我们使用 html5lib 时,父标签的 name 属性是 Body。
Beautiful Soup - parents 属性
方法描述
Beautiful Soup 库中的 parents 属性以递归方式检索所述 PegeElement 的所有父元素。parents 属性返回值的类型是生成器,借助它我们可以自下而上地列出父元素。
语法
Element.parents
返回值
parents 属性返回一个生成器对象。
示例1
此示例使用 .parents 从文档深处嵌套的 <a> 标签遍历到文档的最顶部。在以下代码中,我们跟踪示例 HTML 字符串中第一个 <p> 标签的父元素。
html = """ <html><head><title>TutorialsPoint</title></head> <body> <p>Hello World</p> """ from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'html.parser') tag = soup.p for element in tag.parents: print (element.name)
输出
body html [document]
请注意,BeautifulSoup 对象的父元素是 [document]。
示例2
在以下示例中,我们看到 <b> 标签包含在 <p> 标签内。上面的两个 div 标签具有 id 属性。我们尝试仅打印具有 id 属性的元素。has_attr() 方法用于此目的。
html = """
<div id="outer">
<div id="inner">
<p>Hello<b>World</b></p>
</div>
</div>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
tag = soup.b
for parent in tag.parents:
if parent.has_attr("id"):
print(parent["id"])
输出
inner outer
Beautiful Soup - next_sibling 属性
方法描述
出现在相同缩进级别的 HTML 标签称为同级元素。PageElement 的 next_sibling 属性返回同一级别或同一父元素下的下一个标签。
语法
element.next_sibling
返回值类型
next_sibling 属性返回一个 PageElement、一个 Tag 或一个 NavigableString 对象。
示例1
index.html 薪资页面包含一个 HTML 表单,其中包含三个输入元素,每个元素都有一个 name 属性。在以下示例中,找到 name 属性为 nm 的输入标签的下一个同级元素。
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
tag = soup.find('input', {'name':'age'})
print (tag.find_previous())
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
tag = soup.find('input', {'id':'nm'})
sib = tag.next_sibling
print (sib)
输出
<input id="nm" name="name" type="text"/>
示例2
在下一个示例中,我们有一个 HTML 文档,其中包含几个标签位于 <p> 标签内。next_sibling 属性返回其 <b> 标签旁边的标签。
from bs4 import BeautifulSoup
soup = BeautifulSoup("<p><b>Hello</b><i>Python</i></p>", 'html.parser')
tag1 = soup.b
print ("next:",tag1.next_sibling)
输出
next: <i>Python</i>
示例 3
考虑以下文档中的 HTML 字符串。它在同一级别有两个 <p> 标签。第一个 <p> 的 next_sibling 应该给出第二个 <p> 标签的內容。
html = '''
<p><b>Hello</b><i>Python</i></p>
<p>TutorialsPoint</p>
'''
soup = BeautifulSoup(html, 'html.parser')
tag1 = soup.p
print ("next:",tag1.next_sibling)
输出
next:
next: 这个词后面的空行是意外的。但这是因为第一个 <p> 标签后面有 \n 字符。将打印语句更改为如下所示,以获取 next_sibling 的內容。
tag1 = soup.p
print ("next:",tag1.next_sibling.next_sibling)
输出
next: <p>TutorialsPoint</p>
Beautiful Soup - previous_sibling 属性
方法描述
出现在相同缩进级别的 HTML 标签称为同级元素。PageElement 的 previous_sibling 属性返回同一级别或同一父元素下之前的一个标签(出现在当前标签之前的标签)。此属性封装了 find_previous_sibling() 方法。
语法
element.previous_sibling
返回值类型
previous_sibling 属性返回一个 PageElement、一个 Tag 或一个 NavigableString 对象。
示例1
在以下代码中,HTML 字符串包含 <p> 标签内的两个相邻标签。它显示了其前面出现的 <b> 标签的同级标签。
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup("<p><b>Hello</b><i>Python</i></p>", 'html.parser')
tag = soup.i
sibling = tag.previous_sibling
print (sibling)
输出
<b>Hello</b>
示例2
我们正在使用 index.html 文件进行解析。该页面包含一个 HTML 表单,其中包含三个输入元素。哪个元素是 id 属性为 age 的输入元素的前一个同级元素?以下代码显示了它 -
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
tag = soup.find('input', {'id':'age'})
sib = tag.previous_sibling.previous_sibling
print (sib)
输出
<input id="nm" name="name" type="text"/>
示例 3
首先,我们找到包含字符串“Tutorial”的 <p> 标签,然后找到其之前的标签。
html = '''
<p>Excellent</p><p>Python</p><p>Tutorial</p>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
tag = soup.find('p', string='Tutorial')
print (tag.previous_sibling)
输出
<p>Python</p>
Beautiful Soup - next_siblings 属性
方法描述
出现在相同缩进级别的 HTML 标签称为同级元素。Beautiful Soup 中的 next_siblings 属性返回一个生成器对象,用于迭代同一父元素下所有后续标签和字符串。
语法
element.next_siblings
返回值类型
next_siblings 属性返回一个同级 PageElement 的生成器。
示例1
在 index.html 中的 HTML 表单代码包含三个输入元素。以下脚本使用 next_siblings 属性收集 id 属性为 nm 的输入元素的下一个同级元素。
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
tag = soup.find('input', {'id':'nm'})
siblings = tag.next_siblings
print (list(siblings))
输出
['\n', <input id="age" name="age" type="text"/>, '\n', <input id="marks" name="marks" type="text"/>, '\n']
示例2
让我们为此目的使用以下 HTML 代码段:
使用以下代码遍历下一个同级标签。
from bs4 import BeautifulSoup
soup = BeautifulSoup("<p><b>Excellent</b><i>Python</i><u>Tutorial</u></p>", 'html.parser')
tag1 = soup.b
print ("next siblings:")
for tag in tag1.next_siblings:
print (tag)
输出
next siblings: <i>Python</i> <u>Tutorial</u>
示例 3
下一个示例显示 <head> 标签只有一个以 body 标签形式出现的下一个同级元素。
html = '''
<html>
<head>
<title>Hello</title>
</head>
<body>
<p>Excellent</p><p>Python</p><p>Tutorial</p>
</body>
</head>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
tags = soup.head.next_siblings
print ("next siblings:")
for tag in tags:
print (tag)
输出
next siblings: <body> <p>Excellent</p><p>Python</p><p>Tutorial</p> </body>
这些额外的行是由于生成器中的换行符造成的。
Beautiful Soup - previous_siblings 属性
方法描述
出现在相同缩进级别的 HTML 标签称为同级元素。Beautiful Soup 中的 previous_siblings 属性返回一个生成器对象,用于迭代同一父元素下当前标签之前的所有标签和字符串。这会提供与 find_previous_siblings() 方法类似的输出。
语法
element.previous_siblings
返回值类型
previous_siblings 属性返回一个同级 PageElement 的生成器。
示例1
以下示例解析给定的 HTML 字符串,该字符串在外部 <p> 标签内嵌入了几个标签。<u> 标签的前一个同级元素借助 previous_siblings 属性获取。
from bs4 import BeautifulSoup
soup = BeautifulSoup("<p><b>Excellent</b><i>Python</i><u>Tutorial</u></p>", 'html.parser')
tag1 = soup.u
print ("previous siblings:")
for tag in tag1.previous_siblings:
print (tag)
输出
previous siblings: <i>Python</i> <b>Excellent</b>
示例2
在以下示例中使用的 index.html 文件中,HTML 表单中有三个输入元素。我们找出在 <form> 标签下,id 设置为 marks 的元素之前有哪些同级标签。
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
tag = soup.find('input', {'id':'marks'})
sibs = tag.previous_siblings
print ("previous siblings:")
for sib in sibs:
print (sib)
输出
previous siblings: <input id="age" name="age" type="text"/> <input id="nm" name="name" type="text"/>
示例 3
顶级 <html> 标签始终有两个同级标签 - head 和 body。因此,<body> 标签只有一个前一个同级元素,即 head,如下面的代码所示 -
html = '''
<html>
<head>
<title>Hello</title>
</head>
<body>
<p>Excellent</p><p>Python</p><p>Tutorial</p>
</body>
</head>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
tags = soup.body.previous_siblings
print ("previous siblings:")
for tag in tags:
print (tag)
输出
previous siblings: <head> <title>Hello</title> </head>
Beautiful Soup - next_element 属性
方法描述
在 Beautiful Soup 库中,next_element 属性返回紧接在当前 PageElement 后面的 Tag 或 NavigableString,即使它位于父树之外。还有一个 next 属性具有类似的行为。
语法
Element.next_element
返回值
next_element 和 next 属性返回紧接在当前标签后面的标签或 NavigableString。
示例1
在从给定 HTML 字符串解析的文档树中,我们找到 <b> 标签的 next_element。
html = '''
<p><b>Excellent</b><p>Python</p><p id='id1'>Tutorial</p></p>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
tag = soup.b
print (tag)
nxt = tag.next_element
print ("Next:",nxt)
nxt = tag.next_element.next_element
print ("Next:",nxt)
输出
<b>Excellent</b> Next: Excellent Next: <p>Python</p>
输出有点奇怪,因为 <b>Excellent</b> 的下一个元素显示为“Excellent”,这是因为内部字符串被注册为下一个元素。为了获得所需的结果(<p>Python</p>)作为下一个元素,获取内部 NavigableString 对象的 next_element 属性。
示例2
Beautiful Soup PageElements 也支持 next 属性,该属性类似于 next_element 属性。
html = '''
<p><b>Excellent</b><p>Python</p><p id='id1'>Tutorial</p></p>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
tag = soup.b
print (tag)
nxt = tag.next
print ("Next:",nxt)
nxt = tag.next.next
print ("Next:",nxt)
输出
<b>Excellent</b> Next: Excellent Next: <p>Python</p>
示例 3
在下一个示例中,我们尝试确定 <body> 标签后面的元素。由于它后面跟着一个换行符 (\n),我们需要找到 body 标签后面元素的下一个元素。它恰好是 <h1> 标签。
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
tag = soup.find('body')
nxt = tag.next_element.next
print ("Next:",nxt)
输出
Next: <h1>TutorialsPoint</h1>
Beautiful Soup - previous_element 属性
方法描述
在 Beautiful Soup 库中,previous_element 属性返回紧接在当前 PageElement 之前的 Tag 或 NavigableString,即使它位于父树之外。还有一个 previous 属性具有类似的行为。
语法
Element.previous_element
返回值
previous_element 和 previous 属性返回紧接在当前标签之前的标签或 NavigableString。
示例1
在从给定 HTML 字符串解析的文档树中,我们找到 <p id='id1'> 标签的 previous_element。
html = '''
<p><b>Excellent</b><p>Python</p><p id='id1'>Tutorial</p></p>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
tag = soup.find('p', id='id1')
print (tag)
pre = tag.previous_element
print ("Previous:",pre)
pre = tag.previous_element.previous_element
print ("Previous:",pre)
输出
<p id="id1">Tutorial</p> Previous: Python Previous: <p>Python</p>
输出有点奇怪,因为显示的前一个元素为“Python”,这是因为内部字符串被注册为前一个元素。为了获得所需的结果(<p>Python</p>)作为前一个元素,获取内部 NavigableString 对象的 previous_element 属性。
示例2
Beautiful Soup PageElements 也支持 previous 属性,该属性类似于 previous_element 属性。
html = '''
<p><b>Excellent</b><p>Python</p><p id='id1'>Tutorial</p></p>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
tag = soup.find('p', id='id1')
print (tag)
pre = tag.previous
print ("Previous:",pre)
pre = tag.previous.previous
print ("Previous:",pre)
输出
<p id="id1">Tutorial</p> Previous: Python Previous: <p>Python</p>
示例 3
在下一个示例中,我们尝试确定 id 属性为“age”的 <input> 标签后面的元素。
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html5lib')
tag = soup.find('input', id='age')
pre = tag.previous_element.previous
print ("Previous:",pre)
输出
Previous: <input id="nm" name="name" type="text"/>
Beautiful Soup - next_elements 属性
方法描述
在 Beautiful Soup 库中,next_elements 属性返回一个生成器对象,其中包含解析树中后续的字符串或标签。
语法
Element.next_elements
返回值
next_elements 属性返回一个生成器。
示例1
next_elements 属性返回以下文档字符串中 <b> 标签后面的标签和 NavibaleStrings -
html = '''
<p><b>Excellent</b><p>Python</p><p id='id1'>Tutorial</p></p>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
tag = soup.find('b')
nexts = tag.next_elements
print ("Next elements:")
for next in nexts:
print (next)
输出
Next elements: ExcellentPython
Python <p id="id1">Tutorial</p> Tutorial
示例2
下面列出了 <p> 标签后面的所有元素 -
from bs4 import BeautifulSoup
html = '''
<p>
<b>Excellent</b><i>Python</i>
</p>
<u>Tutorial</u>
'''
soup = BeautifulSoup(html, 'html.parser')
tag1 = soup.find('p')
print ("Next elements:")
print (list(tag1.next_elements))
输出
Next elements: ['\n', <b>Excellent</b>, 'Excellent', <i>Python</i>, 'Python', '\n', '\n', <u>Tutorial</u>, 'Tutorial', '\n']
示例 3
下面列出了 index.html 的 HTML 表单中输入标签后面的元素 -
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html5lib')
tag = soup.find('input')
nexts = soup.previous_elements
print ("Next elements:")
for next in nexts:
print (next)
输出
Next elements: <input id="age" name="age" type="text"/> <input id="marks" name="marks" type="text"/>
Beautiful Soup - previous_elements 属性
方法描述
在 Beautiful Soup 库中,previous_elements 属性返回一个生成器对象,其中包含解析树中之前的字符串或标签。
语法
Element.previous_elements
返回值
previous_elements 属性返回一个生成器。
示例1
previous_elements 属性返回在以下文档字符串中 <p> 标签之前出现的标签和 NavigableStrings。
html = '''
<p><b>Excellent</b><p>Python</p><p id='id1'>Tutorial</p></p>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
tag = soup.find('p', id='id1')
pres = tag.previous_elements
print ("Previous elements:")
for pre in pres:
print (pre)
输出
Previous elements: Python <p>Python</p> Excellent <b>Excellent</b> <p><b>Excellent</b><p>Python</p><p id="id1">Tutorial</p></p>
示例2
下面列出了 <u> 标签之前出现的所有元素。
from bs4 import BeautifulSoup
html = '''
<p>
<b>Excellent</b><i>Python</i>
</p>
<u>Tutorial</u>
'''
soup = BeautifulSoup(html, 'html.parser')
tag1 = soup.find('u')
print ("previous elements:")
print (list(tag1.previous_elements))
输出
previous elements: ['\n', '\n', 'Python', <i>Python</i>, 'Excellent', <b>Excellent</b>, '\n', <p> <b>Excellent</b><i>Python</i> </p>, '\n']
示例 3
BeautifulSoup 对象本身没有任何前置元素。
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html5lib')
tag = soup.find('input', id='marks')
pres = soup.previous_elements
print ("Previous elements:")
for pre in pres:
print (pre.name)
输出
Previous elements:
Beautiful Soup - find() 方法
方法描述
Beautiful Soup 中的 find() 方法在该 PageElement 的子元素中查找与给定条件匹配的第一个元素并返回它。
语法
Soup.find(name, attrs, recursive, string, **kwargs)
参数
name - 标签名称的过滤器。
attrs - 属性值的过滤器字典。
recursive - 如果为 True,则 find() 将执行递归搜索。否则,只考虑直接子元素。
limit - 在找到指定数量的匹配项后停止查找。
kwargs - 属性值的过滤器字典。
返回值
find() 方法返回 Tag 对象或 NavigableString 对象。
示例1
让我们为此目的使用以下 HTML 脚本(作为 index.html)
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<form>
<input type = 'text' id = 'nm' name = 'name'>
<input type = 'text' id = 'age' name = 'age'>
<input type = 'text' id = 'marks' name = 'marks'>
</form>
</body>
</html>
以下 Python 代码查找其 id 为 nm 的元素
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
obj = soup.find(id = 'nm')
print (obj)
输出
<input id="nm" name="name" type="text"/>
示例2
find() 方法返回已解析文档中第一个具有给定属性的标签。
obj = soup.find(attrs={"name":'marks'})
输出
<input id="marks" name="marks" type="text"/>
示例 3
如果 find() 找不到任何内容,则返回 None。
obj = soup.find('dummy')
print (obj)
输出
None
Beautiful Soup - find_all() 方法
方法描述
Beautiful Soup 中的 find_all() 方法在该 PageElement 的子元素中查找与给定条件匹配的元素,并返回所有元素的列表。
语法
Soup.find_all(name, attrs, recursive, string, **kwargs)
参数
name - 标签名称的过滤器。
attrs - 属性值的过滤器字典。
recursive - 如果为 True,则 find() 将执行递归搜索。否则,只考虑直接子元素。
limit - 在找到指定数量的匹配项后停止查找。
kwargs - 属性值的过滤器字典。
返回值类型
find_all() 方法返回一个 ResultSet 对象,它是一个列表生成器。
示例1
当我们可以为 name 传入一个值时,Beautiful Soup 只考虑具有特定名称的标签。文本字符串将被忽略,名称不匹配的标签也将被忽略。在这个例子中,我们将 title 传递给 find_all() 方法。
from bs4 import BeautifulSoup
html = open('index.html')
soup = BeautifulSoup(html, 'html.parser')
obj = soup.find_all('input')
print (obj)
输出
[<input id="nm" name="name" type="text"/>, <input id="age" name="age" type="text"/>, <input id="marks" name="marks" type="text"/>]
示例2
我们将在本例中使用以下 HTML 脚本。
<html>
<body>
<h2>Departmentwise Employees</h2>
<ul id="dept">
<li>Accounts</li>
<ul id='acc'>
<li>Anand</li>
<li>Mahesh</li>
</ul>
<li>HR</li>
<ol id="HR">
<li>Rani</li>
<li>Ankita</li>
</ol>
</ul>
</body>
</html>
我们可以将字符串传递给 find_all() 方法的 name 参数。使用字符串,您可以搜索字符串而不是标签。您可以传入字符串、正则表达式、列表、函数或值 True。
在本例中,一个函数被传递给 name 参数。所有以 'A' 开头的名称都由 find_all() 方法返回。
from bs4 import BeautifulSoup
def startingwith(ch):
return ch.startswith('A')
soup = BeautifulSoup(html, 'html.parser')
lst=soup.find_all(string=startingwith)
print (lst)
输出
['Accounts', 'Anand', 'Ankita']
示例 3
在本例中,我们将 limit=2 参数传递给 find_all() 方法。该方法返回 <li> 标签的前两个出现。
soup = BeautifulSoup(html, 'html.parser')
lst=soup.find_all('li', limit =2)
print (lst)
输出
[<li>Accounts</li>, <li>Anand</li>]
Beautiful Soup - find_parents() 方法
方法描述
BeautifulSoup 包中的 find_parent() 方法查找与给定条件匹配的该元素的所有父元素。
语法
find_parents( name, attrs, limit, **kwargs)
参数
name - 标签名称的过滤器。
attrs - 属性值的过滤器字典。
limit - 在找到指定数量的匹配项后停止查找。
kwargs - 属性值的过滤器字典。
返回值类型
find_parents() 方法返回一个 ResultSet,其中包含所有父元素,并以相反的顺序排列。
示例1
我们将在本例中使用以下 HTML 脚本。
<html>
<body>
<h2>Departmentwise Employees</h2>
<ul id="dept">
<li>Accounts</li>
<ul id='acc'>
<li>Anand</li>
<li>Mahesh</li>
</ul>
<li>HR</li>
<ol id="HR">
<li>Rani</li>
<li>Ankita</li>
</ol>
</ul>
</body>
</html>
输出
ul body html [document]
请注意,BeautifulSoup 对象的 name 属性始终返回 [document]。
示例2
在本例中,limit 参数被传递给 find_parents() 方法,以将父级搜索限制在向上两级。
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
obj=soup.find('li')
parents=obj.find_parents(limit=2)
for parent in parents:
print (parent.name)
输出
ul body
Beautiful Soup - find_parent() 方法
方法描述
BeautifulSoup 包中的 find_parent() 方法查找与给定条件匹配的该 PageElement 的最近父元素。
语法
find_parent( name, attrs, **kwargs)
参数
name - 标签名称的过滤器。
attrs - 属性值的过滤器字典。
kwargs - 属性值的过滤器字典。
返回值类型
find_parent() 方法返回 Tag 对象或 NavigableString 对象。
示例1
我们将在本例中使用以下 HTML 脚本。
<html>
<body>
<h2>Departmentwise Employees</h2>
<ul id="dept">
<li>Accounts</li>
<ul id='acc'>
<li>Anand</li>
<li>Mahesh</li>
</ul>
<li>HR</li>
<ol id="HR">
<li>Rani</li>
<li>Ankita</li>
</ol>
</ul>
</body>
</html>
在下面的示例中,我们查找作为字符串 'HR' 父级的标签的名称。
from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'html.parser') obj=soup.find(string='HR') print (obj.find_parent().name)
输出
li
示例2
<body> 标签始终包含在顶级 <html> 标签中。在下面的示例中,我们使用 find_parent() 方法确认此事实。
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
obj=soup.find('body')
print (obj.find_parent().name)
输出
html
Beautiful Soup - find_next_siblings() 方法
方法描述
find_next_siblings() 方法类似于 next_sibling 属性。它查找与给定条件匹配并在文档中随后出现的该 PageElement 相同级别的所有同级元素。
语法
find_fnext_siblings(name, attrs, string, limit, **kwargs)
参数
name - 标签名称的过滤器。
attrs - 属性值的过滤器字典。
string - 要搜索的字符串(而不是标签)。
limit - 在找到指定数量的匹配项后停止查找。
kwargs - 属性值的过滤器字典。
返回值类型
find_next_siblings() 方法返回 Tag 对象或 NavigableString 对象的列表。
示例1
让我们为此目的使用以下 HTML 代码段:
<p>
<b>
Excellent
</b>
<i>
Python
</i>
<u>
Tutorial
</u>
</p>
在下面的代码中,我们尝试查找 <b> 标签的所有同级元素。在用于抓取的 HTML 字符串中,同一级别还有两个标签。
from bs4 import BeautifulSoup
soup = BeautifulSoup("<p><b>Excellent</b><i>Python</i><u>Tutorial</u></p>", 'html.parser')
tag1 = soup.find('b')
print ("next siblings:")
for tag in tag1.find_next_siblings():
print (tag)
输出
find_next_siblings() 的 ResultSet 正在借助 for 循环进行迭代。
next siblings: <i>Python</i> <u>Tutorial</u>
示例2
如果在标签之后没有要找到的同级元素,则此方法将返回一个空列表。
from bs4 import BeautifulSoup
soup = BeautifulSoup("<p><b>Excellent</b><i>Python</i><u>Tutorial</u></p>", 'html.parser')
tag1 = soup.find('u')
print ("next siblings:")
print (tag1.find_next_siblings())
输出
next siblings: []
Beautiful Soup - find_next_sibling() 方法
方法描述
Beautiful Soup 中的 find_next_sibling() 方法查找与给定条件匹配并在文档中随后出现的该 PageElement 相同级别的最近同级元素。此方法类似于 next_sibling 属性。
语法
find_fnext_sibling(name, attrs, string, **kwargs)
参数
name - 标签名称的过滤器。
attrs - 属性值的过滤器字典。
string - 要搜索的字符串(而不是标签)。
kwargs - 属性值的过滤器字典。
返回值类型
find_next_sibling() 方法返回 Tag 对象或 NavigableString 对象。
示例1
from bs4 import BeautifulSoup
soup = BeautifulSoup("<p><b>Hello</b><i>Python</i></p>", 'html.parser')
tag1 = soup.find('b')
print ("next:",tag1.find_next_sibling())
输出
next: <i>Python</i>
示例2
如果下一个节点不存在,则该方法返回 None。
from bs4 import BeautifulSoup
soup = BeautifulSoup("<p><b>Hello</b><i>Python</i></p>", 'html.parser')
tag1 = soup.find('i')
print ("next:",tag1.find_next_sibling())
输出
next: None
Beautiful Soup - find_previous_siblings() 方法
方法描述
Beautiful Soup 包中的 find_previous_siblings() 方法返回所有在文档中出现在该 PAgeElement 之前并与给定条件匹配的同级元素。
语法
find_previous_siblings(name, attrs, string, limit, **kwargs)
参数
name - 标签名称的过滤器。
attrs - 属性值的过滤器字典。
string - 具有特定文本的 NavigableString 的过滤器。
limit - 在找到这么多结果后停止查找。
kwargs - 属性值的过滤器字典。
返回值
find_previous_siblings() 方法返回一个 PageElements 的 ResultSet。
示例1
让我们为此目的使用以下 HTML 代码段:
<p>
<b>
Excellent
</b>
<i>
Python
</i>
<u>
Tutorial
</u>
</p>
在下面的代码中,我们尝试查找 <> 标签的所有同级元素。在用于抓取的 HTML 字符串中,同一级别还有两个标签。
from bs4 import BeautifulSoup
soup = BeautifulSoup("<p><b>Excellent</b><i>Python</i><u>Tutorial</u></p>", 'html.parser')
tag1 = soup.find('u')
print ("previous siblings:")
for tag in tag1.find_previous_siblings():
print (tag)
输出
<i>Python</i> <b>Excellent</b>
示例2
网页 (index.html) 有一个包含三个输入元素的 HTML 表单。我们找到一个 id 属性为 marks 的元素,然后找到它的前置同级元素。
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
tag = soup.find('input', {'id':'marks'})
sibs = tag.find_previous_sibling()
print (sibs)
输出
[<input id="age" name="age" type="text"/>, <input id="nm" name="name" type="text"/>]
示例 3
HTML 字符串有两个 <p> 标签。我们找出 id1 作为其 id 属性的标签之前的同级元素。
html = '''
<p><b>Excellent</b><p>Python</p><p id='id1'>Tutorial</p></p>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
tag = soup.find('p', id='id1')
ptags = tag.find_previous_siblings()
for ptag in ptags:
print ("Tag: {}, Text: {}".format(ptag.name, ptag.text))
输出
Tag: p, Text: Python Tag: b, Text: Excellent
Beautiful Soup - find_previous_sibling() 方法
方法描述
Beautiful Soup 中的 find_previous_sibling() 方法返回与给定条件匹配并在文档中较早出现的该 PageElement 的最近同级元素。
语法
find_previous_sibling(name, attrs, string, **kwargs)
参数
name - 标签名称的过滤器。
attrs - 属性值的过滤器字典。
string - 具有特定文本的 NavigableString 的过滤器。
kwargs - 属性值的过滤器字典。
返回值
find_previous_sibling() 方法返回一个 PageElement,它可以是 Tag 或 NavigableString。
示例1
从以下示例中使用的 HTML 字符串中,我们找出 <i> 标签的前置同级元素,其标签名称为 'u'。
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup("<p><u>Excellent</u><b>Hello</b><i>Python</i></p>", 'html.parser')
tag = soup.i
sibling = tag.find_previous_sibling('u')
print (sibling)
输出
<u>Excellent</u>
示例2
网页 (index.html) 有一个包含三个输入元素的 HTML 表单。我们找到一个 id 属性为 marks 的元素,然后找到其前置同级元素,该元素的 id 设置为 nm。
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
tag = soup.find('input', {'id':'marks'})
sib = tag.find_previous_sibling(id='nm')
print (sib)
输出
<input id="nm" name="name" type="text"/>
示例 3
在下面的代码中,HTML 字符串有两个 <p> 元素和外部 <p> 标签内的字符串。我们使用 find_previous_string() 方法搜索 <p>Tutorial</p> 标签的 NavigableString 对象同级元素。
html = '''
<p>Excellent<p>Python</p><p>Tutorial</p></p>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
tag = soup.find('p', string='Tutorial')
ptag = tag.find_previous_sibling(string='Excellent')
print (ptag, type(ptag))
输出
Excellent <class 'bs4.element.NavigableString'>
Beautiful Soup - find_all_next() 方法
方法描述
Beautiful Soup 中的 find_all_next() 方法查找与给定条件匹配并在文档中出现在此元素之后的 PageElements。此方法返回标签或 NavigableString 对象,并且该方法接受与 find_all() 完全相同的参数。
语法
find_all_next(name, attrs, string, limit, **kwargs)
参数
name - 标签名称的过滤器。
attrs - 属性值的过滤器字典。
recursive - 如果为 True,则 find() 将执行递归搜索。否则,只考虑直接子元素。
limit - 在找到指定数量的匹配项后停止查找。
kwargs - 属性值的过滤器字典。
返回值
此方法返回一个包含 PageElements(标签或 NavigableString 对象)的 ResultSet。
示例1
使用 index.html 作为本例的 HTML 文档,我们首先找到 <form> 标签,然后使用 find_all_next() 方法收集其后的所有元素。
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
tag = soup.form
tags = tag.find_all_next()
print (tags)
输出
[<input id="nm" name="name" type="text"/>, <input id="age" name="age" type="text"/>, <input id="marks" name="marks" type="text"/>]
示例2
在这里,我们对 find_all_next() 方法应用一个过滤器,以收集所有在 <form> 之后的标签,其 id 为 nm 或 age。
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
tag = soup.form
tags = tag.find_all_next(id=['nm', 'age'])
print (tags)
输出
[<input id="nm" name="name" type="text"/>, <input id="age" name="age" type="text"/>]
示例 3
如果我们检查 body 标签后面的标签,它包括一个 <h1> 标签以及 <form> 标签,其中包含三个输入元素。
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
tag = soup.body
tags = tag.find_all_next()
print (tags)
输出
<h1>TutorialsPoint</h1> <form> <input id="nm" name="name" type="text"/> <input id="age" name="age" type="text"/> <input id="marks" name="marks" type="text"/> </form> <input id="nm" name="name" type="text"/> <input id="age" name="age" type="text"/> <input id="marks" name="marks" type="text"/>
Beautiful Soup - find_next() 方法
方法描述
Beautiful Soup 中的 find_next() 方法查找与给定条件匹配并在文档中随后出现的第一个 PageElement。返回文档中当前标签后面出现的第一个标签或 NavigableString。与所有其他 find 方法一样,此方法具有以下语法。
语法
find_next(name, attrs, string, **kwargs)
参数
name - 标签名称的过滤器。
attrs - 属性值的过滤器字典。
string - 具有特定文本的 NavigableString 的过滤器。
kwargs - 属性值的过滤器字典。
返回值
此 find_next() 方法返回一个 Tag 或 NavigableString。
示例1
本例使用了以下脚本的网页 index.html。
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<h1>TutorialsPoint</h1>
<form>
<input type = 'text' id = 'nm' name = 'name'>
<input type = 'text' id = 'age' name = 'age'>
<input type = 'text' id = 'marks' name = 'marks'>
</form>
</body>
</html>
我们首先找到 <form> 标签,然后找到它旁边的标签。
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
tag = soup.h1
print (tag.find_next())
输出
<form> <input id="nm" name="name" type="text"/> <input id="age" name="age" type="text"/> <input id="marks" name="marks" type="text"/> </form>
示例2
在本例中,我们首先找到 <input> 标签,其 name='age',并获取其下一个标签。
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
tag = soup.find('input', {'name':'age'})
print (tag.find_next())
输出
<input id="marks" name="marks" type="text"/>
示例 3
<head> 标签旁边的标签恰好是 <title> 标签。
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
tag = soup.head
print (tag.find_next())
输出
<title>TutorialsPoint</title>
Beautiful Soup - find_all_previous() 方法
方法描述
Beautiful Soup 中的 find_all_previous() 方法从该 PageElement 向文档中反向查找,并查找与给定条件匹配并在当前元素之前出现的 PageElements。它返回文档中当前标签之前出现的 PageElements 的 ResultsSet。与所有其他 find 方法一样,此方法具有以下语法。
语法
find_previous(name, attrs, string, limit, **kwargs)
参数
name - 标签名称的过滤器。
attrs - 属性值的过滤器字典。
string - 具有特定文本的 NavigableString 的过滤器。
limit - 在找到这么多结果后停止查找。
kwargs - 属性值的过滤器字典。
返回值
find_all_previous() 方法返回 Tag 或 NavigableString 对象的 ResultSet。如果 limit 参数为 1,则该方法等效于 find_previous() 方法。
示例1
在本例中,显示了第一个输入标签之前出现的每个对象的 name 属性。
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
tag = soup.find('input')
for t in tag.find_all_previous():
print (t.name)
输出
form h1 body title head html
示例2
在正在考虑的 HTML 文档 (index.html) 中,有三个输入元素。使用以下代码,我们打印 <input> 标签(其 nm 属性为 marks)之前所有前置标签的标签名称。为了区分它之前的两个输入标签,我们还打印 attrs 属性。请注意,其他标签没有任何属性。
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
tag = soup.find('input', {'name':'marks'})
pretags = tag.find_all_previous()
for pretag in pretags:
print (pretag.name, pretag.attrs)
输出
input {'type': 'text', 'id': 'age', 'name': 'age'}
input {'type': 'text', 'id': 'nm', 'name': 'name'}
form {}
h1 {}
body {}
title {}
head {}
html {}
示例 3
BeautifulSoup 对象存储整个文档的树。它没有任何前置元素,如下面的示例所示。
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
tags = soup.find_all_previous()
print (tags)
输出
[]
Beautiful Soup - find_previous() 方法
方法描述
Beautiful Soup 中的 find_previous() 方法从该 PageElement 向文档中反向查找,并查找与给定条件匹配的第一个 PageElement。它返回文档中当前标签之前出现的第一个标签或 NavigableString。与所有其他 find 方法一样,此方法具有以下语法。
语法
find_previous(name, attrs, string, **kwargs)
参数
name - 标签名称的过滤器。
attrs - 属性值的过滤器字典。
string - 具有特定文本的 NavigableString 的过滤器。
kwargs - 属性值的过滤器字典。
返回值
find_previous() 方法返回一个 Tag 或 NavigableString 对象。
示例1
在下面的示例中,我们尝试查找 <body> 标签之前的对象是哪个。它恰好是 <title> 元素。
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
tag = soup.body
print (tag.find_previous())
输出
<title>TutorialsPoint</title>
示例2
在本例中使用的 HTML 文档中有三个输入元素。以下代码找到 name 属性为 age 的输入元素,并查找其前置元素。
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
tag = soup.find('input', {'name':'age'})
print (tag.find_previous())
输出
<input id="nm" name="name" type="text"/>
示例 3
<title> 之前的元素恰好是 <head> 元素。
from bs4 import BeautifulSoup
fp = open("index.html")
soup = BeautifulSoup(fp, 'html.parser')
tag = soup.find('title')
print (tag.find_previous())
输出
<head> <title>TutorialsPoint</title> </head>
Beautiful Soup - select() 方法
方法描述
在 Beautiful Soup 库中,select() 方法是抓取 HTML/XML 文档的重要工具。与 find() 和 find_() 方法类似,select() 方法也有助于定位满足给定条件的元素。文档树中元素的选择是根据作为参数传递给它的 CSS 选择器完成的。
Beautiful Soup 还有 select_one() 方法。select() 和 select_one() 的区别在于,select() 返回属于 PageElement 并以 CSS 选择器为特征的所有元素的结果集;而 select_one() 返回满足基于 CSS 选择器选择标准的元素的第一个出现。
在 Beautiful Soup 4.7 版之前,select() 方法只能支持常见的 CSS 选择器。在 4.7 版中,Beautiful Soup 与 Soup Sieve CSS 选择器库集成。因此,现在可以使用更多的选择器。在 4.12 版中,除了现有的便捷方法 select() 和 select_one() 之外,还添加了一个 .css 属性。
语法
select(selector, limit, **kwargs)
参数
selector - 包含 CSS 选择器的字符串。
limit - 找到此数量的结果后,停止查找。
kwargs - 要传递的关键字参数。
如果 limit 参数设置为 1,则它将等效于 select_one() 方法。
返回值
select() 方法返回一个 Tag 对象的 ResultSet。select_one() 方法返回一个单独的 Tag 对象。
Soup Sieve 库有不同类型的 CSS 选择器。基本 CSS 选择器为 -
类型选择器根据节点名称匹配元素。例如。
tags = soup.select('div')
通用选择器 (*) 匹配任何类型的元素。示例。
tags = soup.select('*')
ID 选择器根据元素的 id 属性匹配元素。符号 # 表示 ID 选择器。示例。
tags = soup.select("#nm")
类选择器根据 class 属性中包含的值匹配元素。以 . 为前缀的类名称是 CSS 类选择器。示例。
tags = soup.select(".submenu")
示例:类型选择器
from bs4 import BeautifulSoup, NavigableString
markup = '''
<div id="Languages">
<p>Java</p> <p>Python</p> <p>C++</p>
</div>
'''
soup = BeautifulSoup(markup, 'html.parser')
tags = soup.select('div')
print (tags)
输出
[<div id="Languages"> <p>Java</p> <p>Python</p> <p>C++</p> </div>]
示例:ID 选择器
from bs4 import BeautifulSoup
html = '''
<form>
<input type = 'text' id = 'nm' name = 'name'>
<input type = 'text' id = 'age' name = 'age'>
<input type = 'text' id = 'marks' name = 'marks'>
</form>
'''
soup = BeautifulSoup(html, 'html.parser')
obj = soup.select("#nm")
print (obj)
输出
[<input id="nm" name="name" type="text"/>]
示例:类选择器
html = '''
<ul>
<li class="mainmenu">Accounts</li>
<ul>
<li class="submenu">Anand</li>
<li class="submenu">Mahesh</li>
</ul>
<li class="mainmenu">HR</li>
<ul>
<li class="submenu">Rani</li>
<li class="submenu">Ankita</li>
</ul>
</ul>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
tags = soup.select(".mainmenu")
print (tags)
输出
[<li class="mainmenu">Accounts</li>, <li class="mainmenu">HR</li>]
Beautiful Soup - append() 方法
方法描述
Beautiful Soup 中的 `append()` 方法将给定的字符串或另一个标签添加到当前 Tag 对象内容的末尾。`append()` 方法的工作方式类似于 Python 列表对象的 `append()` 方法。
语法
append(obj)
参数
obj − 任何 PageElement,可以是字符串、NavigableString 对象或 Tag 对象。
返回值类型
`append()` 方法不会返回新对象。
示例1
在以下示例中,HTML 脚本包含一个 <p> 标签。使用 `append()`,附加了额外的文本。在以下示例中,HTML 脚本包含一个 <p> 标签。使用 `append()`,附加了额外的文本。
from bs4 import BeautifulSoup
markup = '<p>Hello</p>'
soup = BeautifulSoup(markup, 'html.parser')
print (soup)
tag = soup.p
tag.append(" World")
print (soup)
输出
<p>Hello</p> <p>Hello World</p>
示例2
使用 `append()` 方法,可以在现有标签的末尾添加一个新标签。首先使用 `new_tag()` 方法创建一个新的 Tag 对象,然后将其传递给 `append()` 方法。
from bs4 import BeautifulSoup, Tag
markup = '<b>Hello</b>'
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.b
tag1 = soup.new_tag('i')
tag1.string = 'World'
tag.append(tag1)
print (soup.prettify())
输出
<b>
Hello
<i>
World
</i>
</b>
示例 3
如果需要向文档中添加字符串,可以附加一个 NavigableString 对象。
from bs4 import BeautifulSoup, NavigableString
markup = '<b>Hello</b>'
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.b
new_string = NavigableString(" World")
tag.append(new_string)
print (soup.prettify())
输出
<b> Hello World </b>
Beautiful Soup - extend() 方法
方法描述
Beautiful Soup 中的 `extend()` 方法从 4.7 版开始添加到 Tag 类中。它将列表中的所有元素添加到标签中。此方法类似于标准 Python 列表的 `extend()` 方法 - 它接收一个字符串数组,将其附加到标签的内容中。
语法
extend(tags)
参数
tags − 要附加的字符串或 NavigableString 对象列表。
返回值类型
`extend()` 方法不会返回任何新对象。
示例
from bs4 import BeautifulSoup markup = '<b>Hello</b>' soup = BeautifulSoup(markup, 'html.parser') tag = soup.b vals = ['World.', 'Welcome to ', 'TutorialsPoint'] tag.extend(vals) print (soup.prettify())
输出
<b> Hello World. Welcome to TutorialsPoint </b>
Beautiful Soup - NavigableString() 方法
方法描述
bs4 包中的 `NavigableString()` 方法是 NavigableString 类的构造方法。NavigableString 表示已解析文档的最内层子元素。此方法将常规 Python 字符串转换为 NavigableString。相反,内置的 `str()` 方法将 NavigableString 对象转换为 Unicode 字符串。
语法
NavigableString(string)
参数
string − Python 的 `str` 类的对象。
返回值
`NavigableString()` 方法返回一个 NavigableString 对象。
示例1
在下面的代码中,HTML 字符串包含一个空的 <b> 标签。我们在其中添加了一个 NavigableString 对象。
html = """
<p><b></b></p>
"""
from bs4 import BeautifulSoup, NavigableString
soup = BeautifulSoup(html, 'html.parser')
navstr = NavigableString("Hello World")
soup.b.append(navstr)
print (soup)
输出
<p><b>Hello World</b></p>
示例2
在此示例中,我们看到两个 NavigableString 对象被附加到一个空的 <b> 标签。该标签响应 `strings` 属性而不是 `string` 属性。它是一个 NavigableString 对象的生成器。
html = """
<p><b></b></p>
"""
from bs4 import BeautifulSoup, NavigableString
soup = BeautifulSoup(html, 'html.parser')
navstr = NavigableString("Hello")
soup.b.append(navstr)
navstr = NavigableString("World")
soup.b.append(navstr)
for s in soup.b.strings:
print (s, type(s))
输出
Hello <class 'bs4.element.NavigableString'> World <class 'bs4.element.NavigableString'>
示例 3
如果访问 <b> 标签对象的 `stripped_strings` 属性而不是 `strings` 属性,我们将获得一个 Unicode 字符串(即 `str` 对象)的生成器。
html = """
<p><b></b></p>
"""
from bs4 import BeautifulSoup, NavigableString
soup = BeautifulSoup(html, 'html.parser')
navstr = NavigableString("Hello")
soup.b.append(navstr)
navstr = NavigableString("World")
soup.b.append(navstr)
for s in soup.b.stripped_strings:
print (s, type(s))
输出
Hello <class 'str'> World <class 'str'>
Beautiful Soup - new_tag() 方法
Beautiful Soup 库中的 `new_tag()` 方法创建一个新的 Tag 对象,该对象与现有的 BeautifulSoup 对象关联。可以使用此工厂方法将新标签附加或插入到文档树中。
语法
new_tag(name, namespace, nsprefix, attrs, sourceline, sourcepos, **kwattrs)
参数
name − 新标签的名称。
namespace − 新标签的 XML 命名空间的 URI,可选。
prefix − 新标签的 XML 命名空间的前缀,可选。
attrs − 此标签的属性值的字典。
sourceline − 在源文档中找到此标签的行号。
sourcepos − 在 `sourceline` 中找到此标签的字符位置。
kwattrs − 新标签的属性值的关键字参数。
返回值
此方法返回一个新的 Tag 对象。
示例1
以下示例显示了 `new_tag()` 方法的使用。一个用于 <a> 元素的新标签。标签对象使用 `href` 和 `string` 属性进行初始化,然后插入到文档树中。
from bs4 import BeautifulSoup
soup = BeautifulSoup('<p>Welcome to <b>online Tutorial library</b></p>', 'html.parser')
tag = soup.new_tag('a')
tag.attrs['href'] = "www.tutorialspoint.com"
tag.string = "Tutorialspoint"
soup.b.insert_before(tag)
print (soup)
输出
<p>Welcome to <a href="www.tutorialspoint.com">Tutorialspoint</a><b>online Tutorial library</b></p>
示例2
在以下示例中,我们有一个包含两个输入元素的 HTML 表单。我们创建一个新的输入标签并将其附加到表单标签。
html = '''
<form>
<input type = 'text' id = 'nm' name = 'name'>
<input type = 'text' id = 'age' name = 'age'>
</form>'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
tag = soup.form
newtag=soup.new_tag('input', attrs={'type':'text', 'id':'marks', 'name':'marks'})
tag.append(newtag)
print (soup)
输出
<form> <input id="nm" name="name" type="text"/> <input id="age" name="age" type="text"/> <input id="marks" name="marks" type="text"/></form>
示例 3
这里我们在 HTML 字符串中有一个空的 <p> 标签。一个新的标签被插入到其中。
from bs4 import BeautifulSoup
soup = BeautifulSoup('<p></p>', 'html.parser')
tag = soup.new_tag('b')
tag.string = "Hello World"
soup.p.insert(0,tag)
print (soup)
输出
<p><b>Hello World</b></p>
Beautiful Soup - insert() 方法
方法描述
Beautiful Soup 中的 `insert()` 方法在 Tag 元素的子元素列表中的给定位置添加一个元素。Beautiful Soup 中的 `insert()` 方法的行为类似于 Python 列表对象上的 `insert()`。
语法
insert(position, child)
参数
position − 应插入新 PageElement 的位置。
child − 要插入的 PageElement。
返回值类型
`insert()` 方法不会返回任何新对象。
示例1
在以下示例中,一个新字符串在位置 1 添加到 <b> 标签中。生成的已解析文档显示了结果。
from bs4 import BeautifulSoup, NavigableString markup = '<b>Excellent </b><u>from TutorialsPoint</u>' soup = BeautifulSoup(markup, 'html.parser') tag = soup.b tag.insert(1, "Tutorial ") print (soup.prettify())
输出
<b> Excellent Tutorial </b> <u> from TutorialsPoint </u>
示例2
在以下示例中,`insert()` 方法用于将列表中的字符串依次插入 HTML 标记中的 <p> 标签。
from bs4 import BeautifulSoup, NavigableString
markup = '<p>Excellent Tutorials from TutorialsPoint</p>'
soup = BeautifulSoup(markup, 'html.parser')
langs = ['Python', 'Java', 'C']
i=0
for lang in langs:
i+=1
tag = soup.new_tag('p')
tag.string = lang
soup.p.insert(i, tag)
print (soup.prettify())
输出
<p>
Excellent Tutorials from TutorialsPoint
<p>
Python
</p>
<p>
Java
</p>
<p>
C
</p>
</p>
Beautiful Soup - insert_before() 方法
方法描述
Beautiful Soup 中的 `insert_before()` 方法在解析树中的其他内容之前立即插入标签或字符串。插入的元素成为此元素的直接前驱。插入的元素可以是标签或字符串。
语法
insert_before(*args)
参数
args − 一个或多个元素,可以是标签或字符串。
返回值
此 `insert_before()` 方法不会返回任何新对象。
示例1
以下示例在给定的 HTML 标记字符串中的 "Excellent" 之前插入文本 "Here is an"。
from bs4 import BeautifulSoup, NavigableString
markup = '<b>Excellent</b> Python Tutorial <u>from TutorialsPoint</u>'
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.b
tag.insert_before("Here is an ")
print (soup.prettify())
输出
Here is an <b> Excellent </b> Python Tutorial <u> from TutorialsPoint </u>
示例2
您还可以在一个标签之前插入一个标签。看看这个例子。
from bs4 import BeautifulSoup, NavigableString
markup = '<P>Excellent <b>Tutorial</b> from TutorialsPoint</u>'
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.b
tag1 = soup.new_tag('b')
tag1.string = "Python "
tag.insert_before(tag1)
print (soup.prettify())
输出
<p>
Excellent
<b>
Python
</b>
<b>
Tutorial
</b>
from TutorialsPoint
</p>
示例 3
以下代码传递多个要插入到 <b> 标签之前的字符串。
from bs4 import BeautifulSoup
markup = '<p>There are <b>Tutorials</b> <u>from TutorialsPoint</u></p>'
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.b
tag.insert_before("many ", 'excellent ')
print (soup.prettify())
输出
<p>
There are
many
excellent
<b>
Tutorials
</b>
<u>
from TutorialsPoint
</u>
</p>
Beautiful Soup - insert_after() 方法
方法描述
Beautiful Soup 中的 `insert_after()` 方法在解析树中的其他内容之后立即插入标签或字符串。插入的元素成为此元素的直接后继。插入的元素可以是标签或字符串。
语法
insert_after(*args)
参数
args − 一个或多个元素,可以是标签或字符串。
返回值
此 `insert_after()` 方法不会返回任何新对象。
示例1
以下代码在第一个 <b> 标签之后插入字符串 "Python"。
from bs4 import BeautifulSoup
markup = '<p>An <b>Excellent</b> Tutorial <u>from TutorialsPoint</u>'
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.b
tag.insert_after("Python ")
print (soup.prettify())
输出
<p>
An
<b>
Excellent
</b>
Python
Tutorial
<u>
from TutorialsPoint
</u>
</p>
示例2
您还可以在一个标签之前插入一个标签。看看这个例子。
from bs4 import BeautifulSoup, NavigableString
markup = '<P>Excellent <b>Tutorial</b> from TutorialsPoint</p>'
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.b
tag1 = soup.new_tag('b')
tag1.string = "on Python "
tag.insert_after(tag1)
print (soup.prettify())
输出
<p>
Excellent
<b>
Tutorial
</b>
<b>
on Python
</b>
from TutorialsPoint
</p>
示例 3
可以在某些标签之后插入多个标签或字符串。
from bs4 import BeautifulSoup, NavigableString
markup = '<P>Excellent <b>Tutorials</b> from TutorialsPoint</p>'
soup = BeautifulSoup(markup, 'html.parser')
tag = soup.p
tag1 = soup.new_tag('i')
tag1.string = 'and Java'
tag.insert_after("on Python", tag1)
print (soup.prettify())
输出
<p>
Excellent
<b>
Tutorials
</b>
from TutorialsPoint
</p>
on Python
<i>
and Java
</i>
Beautiful Soup - clear() 方法
方法描述
Beautiful Soup 库中的 `clear()` 方法删除标签的内部内容,同时保持标签完整。如果存在任何子元素,则会对它们调用 `extract()` 方法。如果 `decompose` 参数设置为 True,则会调用 `decompose()` 方法而不是 `extract()`。
语法
clear(decompose=False)
参数
decompose − 如果为 True,则将调用 `decompose()`(一种更具破坏性的方法)而不是 `extract()`。
返回值
`clear()` 方法不会返回任何对象。
示例1
由于 `clear()` 方法是在表示整个文档的 soup 对象上调用的,因此所有内容都将被删除,使文档为空白。
html = '''
<html>
<body>
<p>The quick, brown fox jumps over a lazy dog.</p>
<p>DJs flock by when MTV ax quiz prog.</p>
<p>Junk MTV quiz graced by fox whelps.</p>
<p>Bawds jog, flick quartz, vex nymphs.</p>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
soup.clear()
print(soup)
输出
示例2
在以下示例中,我们找到所有 <p> 标签并在每个标签上调用 `clear()` 方法。
html = '''
<html>
<body>
<p>The quick, brown fox jumps over a lazy dog.</p>
<p>DJs flock by when MTV ax quiz prog.</p>
<p>Junk MTV quiz graced by fox whelps.</p>
<p>Bawds jog, flick quartz, vex nymphs.</p>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
tags = soup.find_all('p')
for tag in tags:
tag.clear()
print(soup)
输出
每个 <p> .. </p> 的内容将被删除,标签将被保留。
<html> <body> <p></p> <p></p> <p></p> <p></p> </body> </html>
示例 3
这里我们清除 <body> 标签的内容,并将 `decompose` 参数设置为 Tue。
html = '''
<html>
<body>
<p>The quick, brown fox jumps over a lazy dog.</p>
<p>DJs flock by when MTV ax quiz prog.</p>
<p>Junk MTV quiz graced by fox whelps.</p>
<p>Bawds jog, flick quartz, vex nymphs.</p>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
tags = soup.find('body')
ret = tags.clear(decompose=True)
print(soup)
输出
<html> <body></body> </html>
Beautiful Soup - extract() 方法
方法描述
Beautiful Soup 库中的 `extract()` 方法用于从文档树中删除标签或字符串。`extract()` 方法返回已删除的对象。它类似于 Python 列表中 `pop()` 方法的工作方式。
语法
extract(index)
参数
Index − 要删除的元素的位置。默认为 None。
返回值类型
`extract()` 方法返回已从文档树中删除的元素。
示例1
html = '''
<div>
<p>Hello Python</p>
</div>
'''
from bs4 import BeautifulSoup
soup=BeautifulSoup(html, 'html.parser')
tag1 = soup.find("div")
tag2 = tag1.find("p")
ret = tag2.extract()
print ('Extracted:',ret)
print ('original:',soup)
输出
Extracted: <p>Hello Python</p> original: <div> </div>
示例2
考虑以下 HTML 标记 -
<html>
<body>
<p> The quick, brown fox jumps over a lazy dog.</p>
<p> DJs flock by when MTV ax quiz prog.</p>
<p> Junk MTV quiz graced by fox whelps.</p>
<p> Bawds jog, flick quartz, vex nymphs./p>
</body>
</html>
这是代码 -
from bs4 import BeautifulSoup
fp = open('index.html')
soup = BeautifulSoup(fp, 'html.parser')
tags = soup.find_all()
for tag in tags:
obj = tag.extract()
print ("Extracted:",obj)
print (soup)
输出
Extracted: <html> <body> <p> The quick, brown fox jumps over a lazy dog.</p> <p> DJs flock by when MTV ax quiz prog.</p> <p> Junk MTV quiz graced by fox whelps.</p> <p> Bawds jog, flick quartz, vex nymphs.</p> </body> </html> Extracted: <body> <p> The quick, brown fox jumps over a lazy dog.</p> <p> DJs flock by when MTV ax quiz prog.</p> <p> Junk MTV quiz graced by fox whelps.</p> <p> Bawds jog, flick quartz, vex nymphs.</p> </body> Extracted: <p> The quick, brown fox jumps over a lazy dog.</p> Extracted: <p> DJs flock by when MTV ax quiz prog.</p> Extracted: <p> Junk MTV quiz graced by fox whelps.</p> Extracted: <p> Bawds jog, flick quartz, vex nymphs.</p>
示例 3
您还可以将 `extract()` 方法与 `find_next()`、`find_previous()` 方法以及 `next_element`、`previous_element` 属性一起使用。
html = '''
<div>
<p><b>Hello</b><b>Python</b></p>
</div>
'''
from bs4 import BeautifulSoup
soup=BeautifulSoup(html, 'html.parser')
tag1 = soup.find("b")
ret = tag1.next_element.extract()
print ('Extracted:',ret)
print ('original:',soup)
输出
Extracted: Hello original: <div> <p><b></b><b>Python</b></p> </div>
Beautiful Soup - decompose() 方法
方法描述
`decompose()` 方法会销毁当前元素及其子元素,因此该元素将从树中删除,将其及下面的所有内容都清除。可以通过 `decomposed` 属性检查元素是否已被分解。如果已销毁,则返回 True,否则返回 false。
语法
decompose()
参数
此方法未定义任何参数。
返回值类型
该方法不会返回任何对象。
示例1
当我们在 BeautifulSoup 对象本身调用 `descompose()` 方法时,整个内容将被销毁。
html = '''
<html>
<body>
<p>The quick, brown fox jumps over a lazy dog.</p>
<p>DJs flock by when MTV ax quiz prog.</p>
<p>Junk MTV quiz graced by fox whelps.</p>
<p>Bawds jog, flick quartz, vex nymphs.</p>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
soup.decompose()
print ("decomposed:",soup.decomposed)
print (soup)
输出
decomposed: True
document: Traceback (most recent call last):
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~^~~~~~~~~~~
TypeError: can only concatenate str (not "NoneType") to str
由于 soup 对象已被分解,因此它返回 True,但是,您会得到如上所示的 TypeError。
示例2
以下代码使用 `decompose()` 方法删除在使用的 HTML 字符串中所有 <p> 标签的出现。
html = '''
<html>
<body>
<p>The quick, brown fox jumps over a lazy dog.</p>
<p>DJs flock by when MTV ax quiz prog.</p>
<p>Junk MTV quiz graced by fox whelps.</p>
<p>Bawds jog, flick quartz, vex nymphs.</p>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
p_all = soup.find_all('p')
[p.decompose() for p in p_all]
print ("document:",soup)
输出
删除所有 <p> 标签后的其余 HTML 文档将被打印。
document: <html> <body> </body> </html>
示例 3
这里,我们从 HTML 文档树中找到 <body> 标签,并分解其前面的元素,该元素恰好是 <title> 标签。生成的文档树省略了 <title> 标签。
html = '''
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
Hello World
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
tag = soup.body
tag.find_previous().decompose()
print ("document:",soup)
输出
document: <html> <head> </head> <body> Hello World </body> </html>
Beautiful Soup - replace_with() 方法
方法描述
Beautiful Soup 的 `replace_with()` 方法用提供的标签或字符串替换元素中的标签或字符串。
语法
replace_with(tag/string)
参数
该方法接受标签对象或字符串作为参数。
返回值类型
`replace_method` 不会返回新对象。
示例1
在此示例中,<p> 标签使用 `replace_with()` 方法替换为 <b>。
html = '''
<html>
<body>
<p>The quick, brown fox jumps over a lazy dog.</p>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
tag1 = soup.find('p')
txt = tag1.string
tag2 = soup.new_tag('b')
tag2.string = txt
tag1.replace_with(tag2)
print (soup)
输出
<html> <body> <b>The quick, brown fox jumps over a lazy dog.</b> </body> </html>
示例2
您可以简单地通过在 `tag.string` 对象上调用 `replace_with()` 方法来用另一个字符串替换标签的内部文本。
html = '''
<html>
<body>
<p>The quick, brown fox jumps over a lazy dog.</p>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
tag1 = soup.find('p')
tag1.string.replace_with("DJs flock by when MTV ax quiz prog.")
print (soup)
输出
<html> <body> <p>DJs flock by when MTV ax quiz prog.</p> </body> </html>
示例 3
用于替换的标签对象可以通过任何 `find()` 方法获得。这里,我们替换 <p> 标签旁边的标签的文本。
html = '''
<html>
<body>
<p>The quick, <b>brown</b> fox jumps over a lazy dog.</p>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
tag1 = soup.find('p')
tag1.find_next('b').string.replace_with('black')
print (soup)
输出
<html> <body> <p>The quick, <b>black</b> fox jumps over a lazy dog.</p> </body> </html>
Beautiful Soup - wrap() 方法
方法描述
Beautiful Soup 中的 `wrap()` 方法将元素包含在另一个元素内。您可以将现有的标签元素用另一个元素包装,或者将标签的字符串用标签包装。
语法
wrap(tag)
参数
要包装的标签。
返回值类型
该方法返回一个带有给定标签的新包装器。
示例1
在此示例中,<b> 标签被包装在 <div> 标签中。
html = '''
<html>
<body>
<p>The quick, <b>brown</b> fox jumps over a lazy dog.</p>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
tag1 = soup.find('b')
newtag = soup.new_tag('div')
tag1.wrap(newtag)
print (soup)
输出
<html> <body> <p>The quick, <div><b>brown</b></div> fox jumps over a lazy dog.</p> </body> </html>
示例2
我们将 <p> 标签内的字符串用包装标签包装。
from bs4 import BeautifulSoup
soup = BeautifulSoup("<p>tutorialspoint.com</p>", 'html.parser')
soup.p.string.wrap(soup.new_tag("b"))
print (soup)
输出
<p><b>tutorialspoint.com</b></p>
Beautiful Soup - unwrap() 方法
方法描述
`unwrap()` 方法与 `wrap()` 方法相反。它用标签内的任何内容替换标签。它从元素中删除标签并将其返回。
语法
unwrap()
参数
该方法不需要任何参数。
返回值类型
`unwrap()` 方法返回已删除的标签。
示例1
在以下示例中,删除了 html 字符串中的 <b> 标签。
html = '''
<p>The quick, <b>brown</b> fox jumps over a lazy dog.</p>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
tag1 = soup.find('b')
newtag = tag1.unwrap()
print (soup)
输出
<p>The quick, brown fox jumps over a lazy dog.</p>
示例2
以下代码打印 `unwrap()` 方法的返回值。
html = '''
<p>The quick, <b>brown</b> fox jumps over a lazy dog.</p>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
tag1 = soup.find('b')
newtag = tag1.unwrap()
print (newtag)
输出
<b></b>
示例 3
`unwrap()` 方法对于去除标记很有用,如下面的代码所示 -
html = '''
<html>
<body>
<p>The quick, brown fox jumps over a lazy dog.</p>
<p>DJs flock by when MTV ax quiz prog.</p>
<p>Junk MTV quiz graced by fox whelps.</p>
<p>Bawds jog, flick quartz, vex nymphs.</p>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
#print (soup.unwrap())
for tag in soup.find_all():
tag.unwrap()
print (soup)
输出
The quick, brown fox jumps over a lazy dog. DJs flock by when MTV ax quiz prog. Junk MTV quiz graced by fox whelps. Bawds jog, flick quartz, vex nymphs.
Beautiful Soup - smooth() 方法
方法描述
在调用大量修改解析树的方法后,您最终可能会得到两个或多个彼此相邻的 NavigableString 对象。`smooth()` 方法通过合并连续的字符串来平滑此元素的子元素。这使得在大量修改树的操作之后,格式化输出看起来更自然。
语法
smooth()
参数
此方法没有参数。
返回值类型
此方法在平滑后返回给定的标签。
示例1
html ='''<html>
<head>
<title>TutorislsPoint/title>
</head>
<body>
Some Text
<div></div>
<p></p>
<div>Some more text</div>
<b></b>
<i></i> # COMMENT
</body>
</html>'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
soup.find('body').sm
for item in soup.find_all():
if not item.get_text(strip=True):
p = item.parent
item.replace_with('')
p.smooth()
print (soup.prettify())
输出
<html>
<head>
<title>
TutorislsPoint/title>
</title>
</head>
<body>
Some Text
<div>
Some more text
</div>
# COMMENT
</body>
</html>
示例2
from bs4 import BeautifulSoup
soup = BeautifulSoup("<p>Hello</p>", 'html.parser')
soup.p.append(", World")
soup.smooth()
print (soup.p.contents)
print(soup.p.prettify())
输出
['Hello, World'] <p> Hello, World </p>
Beautiful Soup - prettify() 方法
方法描述
要获得格式良好的 Unicode 字符串,请使用 Beautiful Soup 的 prettify() 方法。它格式化 Beautiful Soup 解析树,以便每个标签都位于自己的单独行并带有缩进。它允许您轻松地可视化 Beautiful Soup 解析树的结构。
语法
prettify(encoding, formatter)
参数
encoding − 字符串的最终编码。如果为 None,则将返回 Unicode 字符串。
一个 Formatter 对象,或一个命名标准格式化程序之一的字符串。
返回值类型
`prettify()` 方法返回一个 Unicode 字符串(如果 `encoding==None`)或一个字节字符串(否则)。
示例1
考虑以下 HTML 字符串。
<p>The quick, <b>brown fox</b> jumps over a lazy dog.</p>
使用 prettify() 方法,我们可以更好地理解其结构:
html = ''' <p>The quick, <b>brown fox</b> jumps over a lazy dog.</p> ''' from bs4 import BeautifulSoup soup = BeautifulSoup(html, "lxml") print (soup.prettify())
输出
<html>
<body>
<p>
The quick,
<b>
brown fox
</b>
jumps over a lazy dog.
</p>
</body>
</html>
示例2
您可以在文档中的任何 Tag 对象上调用 prettify()。
print (soup.b.prettify())
输出
<b> brown fox </b>
prettify() 方法用于理解文档的结构。但是,它不应用于重新格式化它,因为它添加了空格(以换行符的形式),并更改了 HTML 文档的含义。
He prettify() 方法可以选择提供 formatter 参数来指定要使用的格式。
格式化程序有以下可能的值。
formatter="minimal" − 这是默认值。字符串将仅被处理到足以确保 Beautiful Soup 生成有效的 HTML/XML。
formatter="html" - Beautiful Soup 将尽可能地将 Unicode 字符转换为 HTML 实体。
formatter="html5" − 它类似于 `formatter="html"`,但 Beautiful Soup 将省略 HTML 空标签(如 "br")中的结束斜杠。
formatter=None − Beautiful Soup 根本不会修改输出中的字符串。这是最快的选项,但它可能导致 Beautiful Soup 生成无效的 HTML/XML。
示例 3
from bs4 import BeautifulSoup
french = "<p>Il a dit <<Sacré bleu!>></p>"
soup = BeautifulSoup(french, 'html.parser')
print ("minimal: ")
print(soup.prettify(formatter="minimal"))
print ("html: ")
print(soup.prettify(formatter="html"))
print ("None: ")
print(soup.prettify(formatter=None))
输出
minimal: <p> Il a dit < <sacré bleu!=""> > </sacré> </p> html: <p> Il a dit < <sacré bleu!=""> > </sacré> </p> None: <p> Il a dit < <sacré bleu!=""> > </sacré> </p>
Beautiful Soup - encode() 方法
方法描述
Beautiful Soup 中的 `encode()` 方法呈现给定 PageElement 及其内容的字节字符串表示形式。
`prettify()` 方法允许您轻松可视化 Beautiful Soup 解析树的结构,它具有 `encoding` 参数。`encode()` 方法的作用与 `prettify()` 方法中的 `encoding` 参数相同。
语法
encode(encoding, indent_level, formatter, errors)
参数
encoding − 目标编码。
indent_level − 渲染的每一行将
缩进这么多级。在漂亮打印时,在递归调用中内部使用。
formatter − 一个 Formatter 对象,或一个命名标准格式化程序之一的字符串。
errors − 错误处理策略。
返回值
`encode()` 方法返回标签及其内容的字节字符串表示形式。
示例1
`encoding` 参数默认为 utf-8。以下代码显示了 soup 对象的编码字节字符串表示形式。
from bs4 import BeautifulSoup
soup = BeautifulSoup("Hello “World!”", 'html.parser')
print (soup.encode('utf-8'))
输出
b'Hello \xe2\x80\x9cWorld!\xe2\x80\x9d'
示例2
格式化程序对象具有以下预定义值 -
formatter="minimal" − 这是默认值。字符串将仅被处理到足以确保 Beautiful Soup 生成有效的 HTML/XML。
formatter="html" - Beautiful Soup 将尽可能地将 Unicode 字符转换为 HTML 实体。
formatter="html5" − 它类似于 `formatter="html"`,但 Beautiful Soup 将省略 HTML 空标签(如 "br")中的结束斜杠。
formatter=None − Beautiful Soup 根本不会修改输出中的字符串。这是最快的选项,但它可能导致 Beautiful Soup 生成无效的 HTML/XML。
在以下示例中,不同的格式化程序值用作 `encode()` 方法的参数。
from bs4 import BeautifulSoup
french = "<p>Il a dit <<Sacré bleu!>></p>"
soup = BeautifulSoup(french, 'html.parser')
print ("minimal: ")
print(soup.p.encode(formatter="minimal"))
print ("html: ")
print(soup.p.encode(formatter="html"))
print ("None: ")
print(soup.p.encode(formatter=None))
输出
minimal: b'<p>Il a dit <<Sacr\xc3\xa9 bleu!>></p>' html: b'<p>Il a dit <<Sacré bleu!>></p>' None: b'<p>Il a dit <<Sacr\xc3\xa9 bleu!>></p>'
示例 3
以下示例使用 Latin-1 作为 `encoding` 参数。
markup = '''
<html>
<head>
<meta content="text/html; charset=ISO-Latin-1" http-equiv="Content-type" />
</head>
<body>
<p>Sacr`e bleu!</p>
</body>
</html>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(markup, 'lxml')
print(soup.p.encode("latin-1"))
输出
b'<p>Sacr`e bleu!</p>'
Beautiful Soup - decode() 方法
方法描述
Beautiful Soup 中的 `decode()` 方法将解析树作为 HTML 或 XML 文档返回字符串或 Unicode 表示形式。该方法使用为编码注册的编解码器解码字节。其功能与 `encode()` 方法相反。调用 `encode()` 获取字节字符串,调用 `decode()` 获取 Unicode。让我们通过一些示例来学习 `decode()` 方法。
语法
decode(pretty_print, encoding, formatter, errors)
参数
pretty_print − 如果此值为 True,则将使用缩进使文档更易读。
encoding − 最终文档的编码。如果此值为 None,则文档将为 Unicode 字符串。
formatter − 一个 Formatter 对象,或一个命名标准格式化程序之一的字符串。
errors − 用于处理解码错误的错误处理方案。值为 'strict'、'ignore' 和 'replace'。
返回值
decode() 方法返回一个 Unicode 字符串。
示例
from bs4 import BeautifulSoup
soup = BeautifulSoup("Hello “World!”", 'html.parser')
enc = soup.encode('utf-8')
print (enc)
dec = enc.decode()
print (dec)
输出
b'Hello \xe2\x80\x9cWorld!\xe2\x80\x9d' Hello "World!"
Beautiful Soup - get_text() 方法
方法描述
get_text() 方法仅返回整个 HTML 文档或给定标签中的人类可读文本。所有子字符串都由给定的分隔符连接,默认情况下为 null 字符串。
语法
get_text(separator, strip)
参数
separator − 子字符串将使用此参数连接。默认值为 ""。
strip − 在连接之前,字符串将被去除空格。
返回值类型
get_Text() 方法返回一个字符串。
示例1
在下面的示例中,get_text() 方法删除了所有 HTML 标签。
html = ''' <html> <body> <p> The quick, brown fox jumps over a lazy dog.</p> <p> DJs flock by when MTV ax quiz prog.</p> <p> Junk MTV quiz graced by fox whelps.</p> <p> Bawds jog, flick quartz, vex nymphs.</p> </body> </html> ''' from bs4 import BeautifulSoup soup = BeautifulSoup(html, "html.parser") text = soup.get_text() print(text)
输出
The quick, brown fox jumps over a lazy dog. DJs flock by when MTV ax quiz prog. Junk MTV quiz graced by fox whelps. Bawds jog, flick quartz, vex nymphs.
示例2
在以下示例中,我们将 get_text() 方法的分隔符参数指定为 '#'。
html = ''' <p>The quick, brown fox jumps over a lazy dog.</p> <p>DJs flock by when MTV ax quiz prog.</p> <p>Junk MTV quiz graced by fox whelps.</p> <p>Bawds jog, flick quartz, vex nymphs.</p> ''' from bs4 import BeautifulSoup soup = BeautifulSoup(html, "html.parser") text = soup.get_text(separator='#') print(text)
输出
#The quick, brown fox jumps over a lazy dog.# #DJs flock by when MTV ax quiz prog.# #Junk MTV quiz graced by fox whelps.# #Bawds jog, flick quartz, vex nymphs.#
示例 3
让我们检查当 strip 参数设置为 True 时产生的效果。默认值为 False。
html = ''' <p>The quick, brown fox jumps over a lazy dog.</p> <p>DJs flock by when MTV ax quiz prog.</p> <p>Junk MTV quiz graced by fox whelps.</p> <p>Bawds jog, flick quartz, vex nymphs.</p> ''' from bs4 import BeautifulSoup soup = BeautifulSoup(html, "html.parser") text = soup.get_text(strip=True) print(text)
输出
The quick, brown fox jumps over a lazy dog.DJs flock by when MTV ax quiz prog.Junk MTV quiz graced by fox whelps.Bawds jog, flick quartz, vex nymphs.
Beautiful Soup - diagnose() 方法
方法描述
Beautiful Soup 中的 diagnose() 方法是用于隔离常见问题的诊断套件。如果您难以理解 Beautiful Soup 对文档做了什么,请将文档作为参数传递给 diagnose() 函数。一个报告将向您展示不同的解析器如何处理文档,并告诉您是否缺少解析器。
语法
diagnose(data)
参数
data − 文档字符串。
返回值
diagnose() 方法根据所有可用的解析器打印解析给定文档的结果。
示例
让我们以这个简单的文档作为我们的练习示例 -
<h1>Hello World <b>Welcome</b> <P><b>Beautiful Soup</a> <i>Tutorial</i><p>
以下代码对上述 HTML 脚本运行诊断 -
markup = ''' <h1>Hello World <b>Welcome</b> <P><b>Beautiful Soup</a> <i>Tutorial</i><p> ''' from bs4.diagnose import diagnose diagnose(markup)
diagnose() 的输出以一条消息开头,显示所有可用的解析器 -
Diagnostic running on Beautiful Soup 4.12.2 Python version 3.11.2 (tags/v3.11.2:878ead1, Feb 7 2023, 16:38:35) [MSC v.1934 64 bit (AMD64)] Found lxml version 4.9.2.0 Found html5lib version 1.1
如果要诊断的文档是一个完美的 HTML 文档,则所有解析器的结果几乎相同。但是,在我们的示例中,有很多错误。
首先,内置的 html.parser 被使用。报告如下 -
Trying to parse your markup with html.parser
Here's what html.parser did with the markup:
<h1>
Hello World
<b>
Welcome
</b>
<p>
<b>
Beautiful Soup
<i>
Tutorial
</i>
<p>
</p>
</b>
</p>
</h1>
您可以看到 Python 的内置解析器不会插入 <html> 和 <body> 标签。未关闭的 <h1> 标签在末尾用匹配的 <h1> 提供。
html5lib 和 lxml 解析器都通过将其包装在 <html>、<head> 和 <body> 标签中来完成文档。
Trying to parse your markup with html5lib
Here's what html5lib did with the markup:
<html>
<head>
</head>
<body>
<h1>
Hello World
<b>
Welcome
</b>
<p>
<b>
Beautiful Soup
<i>
Tutorial
</i>
</b>
</p>
<p>
<b>
</b>
</p>
</h1>
</body>
</html>
使用 lxml 解析器,请注意插入 </h1> 的位置。此外,不完整的 <b> 标签已纠正,并且悬挂的 </a> 已删除。
Trying to parse your markup with lxml
Here's what lxml did with the markup:
<html>
<body>
<h1>
Hello World
<b>
Welcome
</b>
</h1>
<p>
<b>
Beautiful Soup
<i>
Tutorial
</i>
</b>
</p>
<p>
</p>
</body>
</html>
diagnose() 方法也以 XML 文档的形式解析文档,这在我们的例子中可能多余。
Trying to parse your markup with lxml-xml
Here's what lxml-xml did with the markup:
<?xml version="1.0" encoding="utf-8"?>
<h1>
Hello World
<b>
Welcome
</b>
<P>
<b>
Beautiful Soup
</b>
<i>
Tutorial
</i>
<p/>
</P>
</h1>
让我们为 diagnose() 方法提供一个 XML 文档而不是 HTML 文档。
<?xml version="1.0" ?>
<books>
<book>
<title>Python</title>
<author>TutorialsPoint</author>
<price>400</price>
</book>
</books>
现在,如果我们运行诊断,即使它是一个 XML,也会应用 html 解析器。
Trying to parse your markup with html.parser
Warning (from warnings module):
File "C:\Users\mlath\OneDrive\Documents\Feb23 onwards\BeautifulSoup\Lib\site-packages\bs4\builder\__init__.py", line 545
warnings.warn(
XMLParsedAsHTMLWarning: It looks like you're parsing an XML document using an HTML parser. If this really is an HTML document (maybe it's XHTML?), you can ignore or filter this warning. If it's XML, you should know that using an XML parser will be more reliable. To parse this document as XML, make sure you have the lxml package installed, and pass the keyword argument `features="xml"` into the BeautifulSoup constructor.
对于 html.parser,会显示一条警告消息。对于 html5lib,包含 XML 版本信息的第 1 行被注释掉,其余的文档被解析为 HTML 文档。
Trying to parse your markup with html5lib
Here's what html5lib did with the markup:
<!--?xml version="1.0" ?-->
<html>
<head>
</head>
<body>
<books>
<book>
<title>
Python
</title>
<author>
TutorialsPoint
</author>
<price>
400
</price>
</book>
</books>
</body>
</html>
lxml html 解析器不会插入注释,而是将其解析为 HTML。
Trying to parse your markup with lxml
Here's what lxml did with the markup:
<?xml version="1.0" ?>
<html>
<body>
<books>
<book>
<title>
Python
</title>
<author>
TutorialsPoint
</author>
<price>
400
</price>
</book>
</books>
</body>
</html>
lxml-xml 解析器将文档解析为 XML。
Trying to parse your markup with lxml-xml
Here's what lxml-xml did with the markup:
<?xml version="1.0" encoding="utf-8"?>
<?xml version="1.0" ?>
<books>
<book>
<title>
Python
</title>
<author>
TutorialsPoint
</author>
<price>
400
</price>
</book>
</books>
诊断报告可能有助于发现 HTML/XML 文档中的错误。