- Biopython 教程
- Biopython - 首页
- Biopython - 简介
- Biopython - 安装
- 创建简单的应用程序
- Biopython - 序列
- 高级序列操作
- 序列 I/O 操作
- Biopython - 序列比对
- Biopython - BLAST 概述
- Biopython - Entrez 数据库
- Biopython - PDB 模块
- Biopython - 基序对象
- Biopython - BioSQL 模块
- Biopython - 群体遗传学
- Biopython - 基因组分析
- Biopython - 表型微阵列
- Biopython - 绘图
- Biopython - 聚类分析
- Biopython - 机器学习
- Biopython - 测试技术
- Biopython 资源
- Biopython 快速指南
- Biopython - 有用资源
- Biopython - 讨论
Biopython 快速指南
Biopython - 简介
Biopython 是 Python 最大的、最流行的生物信息学软件包。它包含许多用于常见生物信息学任务的不同子模块。它由 Chapman 和 Chang 开发,主要用 Python 编写。它还包含 C 代码来优化软件的复杂计算部分。它可以在 Windows、Linux、Mac OS X 等操作系统上运行。
基本上,Biopython 是一个 Python 模块的集合,提供处理 DNA、RNA 和蛋白质序列操作的功能,例如 DNA 字符串的反向互补、在蛋白质序列中查找基序等。它提供了许多解析器来读取所有主要的遗传数据库,如 GenBank、SwissPort、FASTA 等,以及运行其他流行的生物信息学软件/工具(如 NCBI BLASTN、Entrez 等)的包装器/接口,在 Python 环境中。它有类似的项目,如 BioPerl、BioJava 和 BioRuby。
特征
Biopython 可移植、清晰且易于学习语法。下面列出了一些主要功能:
解释型、交互式和面向对象。
支持 FASTA、PDB、GenBank、Blast、SCOP、PubMed/Medline、ExPASy 相关的格式。
处理序列格式的选项。
管理蛋白质结构的工具。
BioSQL - 用于存储序列以及特征和注释的标准 SQL 表集。
访问在线服务和数据库,包括 NCBI 服务(Blast、Entrez、PubMed)和 ExPASy 服务(SwissProt、Prosite)。
访问本地服务,包括 Blast、Clustalw、EMBOSS。
目标
Biopython 的目标是通过 Python 语言提供对生物信息学的简单、标准和广泛的访问。Biopython 的具体目标如下:
提供对生物信息学资源的标准化访问。
高质量、可重用的模块和脚本。
可在集群代码、PDB、朴素贝叶斯和马尔可夫模型中使用的快速数组操作。
基因组数据分析。
优势
Biopython 需要非常少的代码,并具有以下优点:
提供用于聚类的微阵列数据类型。
读取和写入 Tree-View 类型文件。
支持用于 PDB 解析、表示和分析的结构数据。
支持 Medline 应用程序中使用的期刊数据。
支持 BioSQL 数据库,它是所有生物信息学项目中广泛使用的标准数据库。
通过提供模块将生物信息学文件解析为特定格式的记录对象或序列加特征的通用类来支持解析器开发。
基于食谱风格的清晰文档。
案例研究
让我们检查一些用例(群体遗传学、RNA 结构等),并尝试了解 Biopython 在该领域如何发挥重要作用:
群体遗传学
群体遗传学是对群体中遗传变异的研究,包括检查和建模基因和等位基因频率在空间和时间上群体中的变化。
Biopython 提供 Bio.PopGen 模块用于群体遗传学。此模块包含收集经典群体遗传学信息所需的所有必要函数。
RNA 结构
对我们的生命至关重要的三种主要的生物大分子是 DNA、RNA 和蛋白质。蛋白质是细胞的“主力军”,在酶中发挥着重要作用。DNA(脱氧核糖核酸)被认为是细胞的“蓝图”。它携带细胞生长、吸收营养物质和繁殖所需的所有遗传信息。RNA(核糖核酸)在细胞中充当“DNA 影印本”。
Biopython 提供 Bio.Sequence 对象,表示核苷酸,即 DNA 和 RNA 的构建块。
Biopython - 安装
本节说明如何在您的机器上安装 Biopython。安装非常简单,不会超过五分钟。
步骤 1 - 验证 Python 安装
Biopython 旨在与 Python 2.5 或更高版本一起使用。因此,必须首先安装 python。在命令提示符中运行以下命令:
> python --version
定义如下:

如果正确安装,它将显示 python 的版本。否则,下载最新版本的 python,安装它,然后再次运行该命令。
步骤 2 - 使用 pip 安装 Biopython
在所有平台上,使用命令行通过 pip 安装 Biopython 很容易。键入以下命令:
> pip install biopython
您将在屏幕上看到以下响应:

更新旧版本的 Biopython:
> pip install biopython –-upgrade
您将在屏幕上看到以下响应:

执行此命令后,将在安装最新版本之前删除旧版本的 Biopython 和 NumPy(Biopython 依赖于它)。
步骤 3 - 验证 Biopython 安装
现在,您已成功在您的机器上安装了 Biopython。要验证 Biopython 是否已正确安装,请在 Python 控制台中键入以下命令:

它显示 Biopython 的版本。
备用方法 - 使用源代码安装 Biopython
要使用源代码安装 Biopython,请按照以下说明操作:
从以下链接下载 Biopython 的最新版本:https://biopython.org.cn/wiki/Download
截至目前,最新版本为biopython-1.72。
下载文件并解压缩压缩的存档文件,移动到源代码文件夹并键入以下命令:
> python setup.py build
这将根据以下说明从源代码构建 Biopython:
现在,使用以下命令测试代码:
> python setup.py test
最后,使用以下命令进行安装:
> python setup.py install

Biopython - 创建简单的应用程序
让我们创建一个简单的 Biopython 应用程序来解析生物信息学文件并打印内容。这将帮助我们理解 Biopython 的一般概念以及它如何在生物信息学领域提供帮助。
步骤 1 - 首先,创建一个样本序列文件“example.fasta”并将以下内容放入其中。
>sp|P25730|FMS1_ECOLI CS1 fimbrial subunit A precursor (CS1 pilin) MKLKKTIGAMALATLFATMGASAVEKTISVTASVDPTVDLLQSDGSALPNSVALTYSPAV NNFEAHTINTVVHTNDSDKGVVVKLSADPVLSNVLNPTLQIPVSVNFAGKPLSTTGITID SNDLNFASSGVNKVSSTQKLSIHADATRVTGGALTAGQYQGLVSIILTKSTTTTTTTKGT >sp|P15488|FMS3_ECOLI CS3 fimbrial subunit A precursor (CS3 pilin) MLKIKYLLIGLSLSAMSSYSLAAAGPTLTKELALNVLSPAALDATWAPQDNLTLSNTGVS NTLVGVLTLSNTSIDTVSIASTNVSDTSKNGTVTFAHETNNSASFATTISTDNANITLDK NAGNTIVKTTNGSQLPTNLPLKFITTEGNEHLVSGNYRANITITSTIKGGGTKKGTTDKK
扩展名fasta指的是序列文件的格式。FASTA 源自生物信息学软件 FASTA,因此得名。FASTA 格式有多个序列一个接一个地排列,每个序列都有自己的 ID、名称、描述和实际序列数据。
步骤 2 - 创建一个新的 Python 脚本“simple_example.py”,输入以下代码并保存。
from Bio.SeqIO import parse
from Bio.SeqRecord import SeqRecord
from Bio.Seq import Seq
file = open("example.fasta")
records = parse(file, "fasta") for record in records:
print("Id: %s" % record.id)
print("Name: %s" % record.name)
print("Description: %s" % record.description)
print("Annotations: %s" % record.annotations)
print("Sequence Data: %s" % record.seq)
print("Sequence Alphabet: %s" % record.seq.alphabet)
让我们更深入地了解一下代码:
第 1 行导入 Bio.SeqIO 模块中可用的 parse 类。Bio.SeqIO 模块用于以不同的格式读取和写入序列文件,而 `parse` 类用于解析序列文件的内容。
第 2 行导入 Bio.SeqRecord 模块中可用的 SeqRecord 类。此模块用于操作序列记录,而 SeqRecord 类用于表示序列文件中可用的特定序列。
“第 3 行”导入 Bio.Seq 模块中可用的 Seq 类。此模块用于操作序列数据,而 Seq 类用于表示序列文件中可用的特定序列记录的序列数据。
第 5 行使用常规 Python 函数 open 打开“example.fasta”文件。
第 7 行解析序列文件的内容,并将内容作为 SeqRecord 对象列表返回。
第 9-15 行使用 Python for 循环遍历记录,并打印序列记录(SqlRecord)的属性,例如 ID、名称、描述、序列数据等。
第 15 行使用 Alphabet 类打印序列的类型。
步骤 3 - 打开命令提示符并转到包含序列文件“example.fasta”的文件夹,然后运行以下命令:
> python simple_example.py
步骤 4 - Python 运行脚本并打印样本文件“example.fasta”中可用的所有序列数据。输出将类似于以下内容。
Id: sp|P25730|FMS1_ECOLI
Name: sp|P25730|FMS1_ECOLI
Decription: sp|P25730|FMS1_ECOLI CS1 fimbrial subunit A precursor (CS1 pilin)
Annotations: {}
Sequence Data: MKLKKTIGAMALATLFATMGASAVEKTISVTASVDPTVDLLQSDGSALPNSVALTYSPAVNNFEAHTINTVVHTNDSD
KGVVVKLSADPVLSNVLNPTLQIPVSVNFAGKPLSTTGITIDSNDLNFASSGVNKVSSTQKLSIHADATRVTGGALTA
GQYQGLVSIILTKSTTTTTTTKGT
Sequence Alphabet: SingleLetterAlphabet()
Id: sp|P15488|FMS3_ECOLI
Name: sp|P15488|FMS3_ECOLI
Decription: sp|P15488|FMS3_ECOLI CS3 fimbrial subunit A precursor (CS3 pilin)
Annotations: {}
Sequence Data: MLKIKYLLIGLSLSAMSSYSLAAAGPTLTKELALNVLSPAALDATWAPQDNLTLSNTGVSNTLVGVLTLSNTSIDTVS
IASTNVSDTSKNGTVTFAHETNNSASFATTISTDNANITLDKNAGNTIVKTTNGSQLPTNLPLKFITTEGNEHLVSGN
YRANITITSTIKGGGTKKGTTDKK
Sequence Alphabet: SingleLetterAlphabet()
在这个例子中,我们看到了三个类,parse、SeqRecord 和 Seq。这三个类提供了大部分功能,我们将在接下来的章节中学习这些类。
Biopython - 序列
序列是一系列字母,用于表示生物体的蛋白质、DNA 或 RNA。它由 Seq 类表示。Seq 类定义在 Bio.Seq 模块中。
让我们在 Biopython 中创建一个简单的序列,如下所示:
>>> from Bio.Seq import Seq
>>> seq = Seq("AGCT")
>>> seq
Seq('AGCT')
>>> print(seq)
AGCT
在这里,我们创建了一个简单的蛋白质序列AGCT,每个字母分别代表A赖氨酸、G甘氨酸、C半胱氨酸和T苏氨酸。
每个 Seq 对象有两个重要的属性:
data - 实际序列字符串 (AGCT)
alphabet - 用于表示序列类型。例如 DNA 序列、RNA 序列等。默认情况下,它不表示任何序列,并且本质上是通用的。
Alphabet 模块
Seq 对象包含 Alphabet 属性以指定序列类型、字母和可能的运算。它定义在 Bio.Alphabet 模块中。Alphabet 可以定义如下:
>>> from Bio.Seq import Seq
>>> myseq = Seq("AGCT")
>>> myseq
Seq('AGCT')
>>> myseq.alphabet
Alphabet()
Alphabet 模块提供以下类来表示不同类型的序列。Alphabet - 所有类型字母的基类。
SingleLetterAlphabet - 长度为 1 的字母的通用字母表。它派生自 Alphabet,所有其他字母类型都派生自它。
>>> from Bio.Seq import Seq
>>> from Bio.Alphabet import single_letter_alphabet
>>> test_seq = Seq('AGTACACTGGT', single_letter_alphabet)
>>> test_seq
Seq('AGTACACTGGT', SingleLetterAlphabet())
ProteinAlphabet - 通用单字母蛋白质字母表。
>>> from Bio.Seq import Seq
>>> from Bio.Alphabet import generic_protein
>>> test_seq = Seq('AGTACACTGGT', generic_protein)
>>> test_seq
Seq('AGTACACTGGT', ProteinAlphabet())
NucleotideAlphabet - 通用单字母核苷酸字母表。
>>> from Bio.Seq import Seq
>>> from Bio.Alphabet import generic_nucleotide
>>> test_seq = Seq('AGTACACTGGT', generic_nucleotide) >>> test_seq
Seq('AGTACACTGGT', NucleotideAlphabet())
DNAAlphabet - 通用单字母 DNA 字母表。
>>> from Bio.Seq import Seq
>>> from Bio.Alphabet import generic_dna
>>> test_seq = Seq('AGTACACTGGT', generic_dna)
>>> test_seq
Seq('AGTACACTGGT', DNAAlphabet())
RNAAlphabet - 通用单字母 RNA 字母表。
>>> from Bio.Seq import Seq
>>> from Bio.Alphabet import generic_rna
>>> test_seq = Seq('AGTACACTGGT', generic_rna)
>>> test_seq
Seq('AGTACACTGGT', RNAAlphabet())
Biopython 模块 Bio.Alphabet.IUPAC 提供了由 IUPAC 社区定义的基本序列类型。它包含以下类:
IUPACProtein (protein) - 20 种标准氨基酸的 IUPAC 蛋白质字母表。
ExtendedIUPACProtein (extended_protein) - 包括 X 的扩展大写 IUPAC 蛋白质单字母字母表。
IUPACAmbiguousDNA (ambiguous_dna) - 大写 IUPAC 模糊 DNA。
IUPACUnambiguousDNA (unambiguous_dna) - 大写 IUPAC 明确 DNA (GATC)。
ExtendedIUPACDNA (extended_dna) - 扩展 IUPAC DNA 字母表。
IUPACAmbiguousRNA (ambiguous_rna) − IUPAC模糊RNA大写字母。
IUPACUnambiguousRNA (unambiguous_rna) − IUPAC明确RNA大写字母 (GAUC)。
考虑以下所示的IUPACProtein类的简单示例:
>>> from Bio.Alphabet import IUPAC
>>> protein_seq = Seq("AGCT", IUPAC.protein)
>>> protein_seq
Seq('AGCT', IUPACProtein())
>>> protein_seq.alphabet
此外,Biopython通过Bio.Data模块公开了所有与生物信息学相关的配置数据。例如,IUPACData.protein_letters包含IUPACProtein字母表中可能的字母。
>>> from Bio.Data import IUPACData >>> IUPACData.protein_letters 'ACDEFGHIKLMNPQRSTVWY'
基本操作
本节简要介绍了Seq类中可用的所有基本操作。序列类似于Python字符串。我们可以在序列中执行Python字符串操作,如切片、计数、连接、查找、分割和去除首尾空格。
使用以下代码获取各种输出。
获取序列中的第一个值。
>>> seq_string = Seq("AGCTAGCT")
>>> seq_string[0]
'A'
打印前两个值。
>>> seq_string[0:2]
Seq('AG')
打印所有值。
>>> seq_string[ : ]
Seq('AGCTAGCT')
执行长度和计数操作。
>>> len(seq_string)
8
>>> seq_string.count('A')
2
添加两个序列。
>>> from Bio.Alphabet import generic_dna, generic_protein
>>> seq1 = Seq("AGCT", generic_dna)
>>> seq2 = Seq("TCGA", generic_dna)
>>> seq1+seq2
Seq('AGCTTCGA', DNAAlphabet())
这里,上面两个序列对象seq1、seq2是通用DNA序列,因此您可以将它们添加并生成新的序列。您不能添加具有不兼容字母的序列,例如如下所示的蛋白质序列和DNA序列:
>>> dna_seq = Seq('AGTACACTGGT', generic_dna)
>>> protein_seq = Seq('AGUACACUGGU', generic_protein)
>>> dna_seq + protein_seq
.....
.....
TypeError: Incompatible alphabets DNAAlphabet() and ProteinAlphabet()
>>>
要添加两个或多个序列,首先将其存储在Python列表中,然后使用“for循环”检索它,最后将其加在一起,如下所示:
>>> from Bio.Alphabet import generic_dna
>>> list = [Seq("AGCT",generic_dna),Seq("TCGA",generic_dna),Seq("AAA",generic_dna)]
>>> for s in list:
... print(s)
...
AGCT
TCGA
AAA
>>> final_seq = Seq(" ",generic_dna)
>>> for s in list:
... final_seq = final_seq + s
...
>>> final_seq
Seq('AGCTTCGAAAA', DNAAlphabet())
在以下部分,提供了各种代码以根据需求获取输出。
更改序列的大小写。
>>> from Bio.Alphabet import generic_rna
>>> rna = Seq("agct", generic_rna)
>>> rna.upper()
Seq('AGCT', RNAAlphabet())
检查Python成员资格和身份运算符。
>>> rna = Seq("agct", generic_rna)
>>> 'a' in rna
True
>>> 'A' in rna
False
>>> rna1 = Seq("AGCT", generic_dna)
>>> rna is rna1
False
在给定序列中查找单个字母或字母序列。
>>> protein_seq = Seq('AGUACACUGGU', generic_protein)
>>> protein_seq.find('G')
1
>>> protein_seq.find('GG')
8
执行分割操作。
>>> protein_seq = Seq('AGUACACUGGU', generic_protein)
>>> protein_seq.split('A')
[Seq('', ProteinAlphabet()), Seq('GU', ProteinAlphabet()),
Seq('C', ProteinAlphabet()), Seq('CUGGU', ProteinAlphabet())]
在序列中执行去除首尾空格操作。
>>> strip_seq = Seq(" AGCT ")
>>> strip_seq
Seq(' AGCT ')
>>> strip_seq.strip()
Seq('AGCT')
Biopython - 高级序列操作
在本章中,我们将讨论Biopython提供的一些高级序列功能。
互补序列和反向互补序列
核苷酸序列可以反向互补以获得新的序列。此外,互补序列可以反向互补以获得原始序列。Biopython提供了两种方法来实现此功能:complement和reverse_complement。代码如下所示:
>>> from Bio.Alphabet import IUPAC
>>> nucleotide = Seq('TCGAAGTCAGTC', IUPAC.ambiguous_dna)
>>> nucleotide.complement()
Seq('AGCTTCAGTCAG', IUPACAmbiguousDNA())
>>>
这里,complement()方法允许互补DNA或RNA序列。reverse_complement()方法对从左到右的结果序列进行互补和反转。如下所示:
>>> nucleotide.reverse_complement()
Seq('GACTGACTTCGA', IUPACAmbiguousDNA())
Biopython使用Bio.Data.IUPACData提供的ambiguous_dna_complement变量来执行互补操作。
>>> from Bio.Data import IUPACData
>>> import pprint
>>> pprint.pprint(IUPACData.ambiguous_dna_complement) {
'A': 'T',
'B': 'V',
'C': 'G',
'D': 'H',
'G': 'C',
'H': 'D',
'K': 'M',
'M': 'K',
'N': 'N',
'R': 'Y',
'S': 'S',
'T': 'A',
'V': 'B',
'W': 'W',
'X': 'X',
'Y': 'R'}
>>>
GC含量
基因组DNA碱基组成(GC含量)预计会显着影响基因组功能和物种生态。GC含量是GC核苷酸数量除以总核苷酸数量。
要获取GC核苷酸含量,请导入以下模块并执行以下步骤:
>>> from Bio.SeqUtils import GC
>>> nucleotide = Seq("GACTGACTTCGA",IUPAC.unambiguous_dna)
>>> GC(nucleotide)
50.0
转录
转录是将DNA序列转换为RNA序列的过程。实际的生物转录过程是执行反向互补(TCAG → CUGA)以获得mRNA,将DNA视为模板链。但是,在生物信息学以及在Biopython中,我们通常直接使用编码链,并且可以通过将字母T更改为U来获取mRNA序列。
以上的一个简单示例如下所示:
>>> from Bio.Seq import Seq
>>> from Bio.Seq import transcribe
>>> from Bio.Alphabet import IUPAC
>>> dna_seq = Seq("ATGCCGATCGTAT",IUPAC.unambiguous_dna) >>> transcribe(dna_seq)
Seq('AUGCCGAUCGUAU', IUPACUnambiguousRNA())
>>>
要反转转录,将T更改为U,如下面的代码所示:
>>> rna_seq = transcribe(dna_seq)
>>> rna_seq.back_transcribe()
Seq('ATGCCGATCGTAT', IUPACUnambiguousDNA())
要获取DNA模板链,请反向互补反转录的RNA,如下所示:
>>> rna_seq.back_transcribe().reverse_complement()
Seq('ATACGATCGGCAT', IUPACUnambiguousDNA())
翻译
翻译是将RNA序列翻译成蛋白质序列的过程。考虑以下所示的RNA序列:
>>> rna_seq = Seq("AUGGCCAUUGUAAU",IUPAC.unambiguous_rna)
>>> rna_seq
Seq('AUGGCCAUUGUAAUGGGCCGCUGAAAGGGUGCCCGAUAG', IUPACUnambiguousRNA())
现在,将translate()函数应用于上面的代码:
>>> rna_seq.translate()
Seq('MAIV', IUPACProtein())
上述RNA序列很简单。考虑RNA序列AUGGCCAUUGUAAUGGGCCGCUGAAAGGGUGCCCGA并应用translate():
>>> rna = Seq('AUGGCCAUUGUAAUGGGCCGCUGAAAGGGUGCCCGA', IUPAC.unambiguous_rna)
>>> rna.translate()
Seq('MAIVMGR*KGAR', HasStopCodon(IUPACProtein(), '*'))
这里,终止密码子用星号“*”表示。
在translate()方法中,可以停止在第一个终止密码子处。要执行此操作,您可以在translate()中分配to_stop=True,如下所示:
>>> rna.translate(to_stop = True)
Seq('MAIVMGR', IUPACProtein())
这里,终止密码子不包含在结果序列中,因为它不包含一个。
翻译表
NCBI的遗传密码页面提供了Biopython使用的翻译表的完整列表。让我们看一个标准表的示例以可视化代码:
>>> from Bio.Data import CodonTable >>> table = CodonTable.unambiguous_dna_by_name["Standard"] >>> print(table) Table 1 Standard, SGC0 | T | C | A | G | --+---------+---------+---------+---------+-- T | TTT F | TCT S | TAT Y | TGT C | T T | TTC F | TCC S | TAC Y | TGC C | C T | TTA L | TCA S | TAA Stop| TGA Stop| A T | TTG L(s)| TCG S | TAG Stop| TGG W | G --+---------+---------+---------+---------+-- C | CTT L | CCT P | CAT H | CGT R | T C | CTC L | CCC P | CAC H | CGC R | C C | CTA L | CCA P | CAA Q | CGA R | A C | CTG L(s)| CCG P | CAG Q | CGG R | G --+---------+---------+---------+---------+-- A | ATT I | ACT T | AAT N | AGT S | T A | ATC I | ACC T | AAC N | AGC S | C A | ATA I | ACA T | AAA K | AGA R | A A | ATG M(s)| ACG T | AAG K | AGG R | G --+---------+---------+---------+---------+-- G | GTT V | GCT A | GAT D | GGT G | T G | GTC V | GCC A | GAC D | GGC G | C G | GTA V | GCA A | GAA E | GGA G | A G | GTG V | GCG A | GAG E | GGG G | G --+---------+---------+---------+---------+-- >>>
Biopython使用此表将DNA翻译成蛋白质以及查找终止密码子。
Biopython - 序列I/O操作
Biopython提供了一个模块Bio.SeqIO,分别用于从文件(任何流)读取和写入序列。它支持生物信息学中几乎所有可用的文件格式。大多数软件为不同的文件格式提供了不同的方法。但是,Biopython有意识地遵循单一方法,通过其SeqRecord对象向用户呈现解析的序列数据。
让我们在下一节中进一步了解SeqRecord。
SeqRecord
Bio.SeqRecord模块提供SeqRecord来保存序列的元信息以及序列数据本身,如下所示:
seq − 它是实际的序列。
id − 它是给定序列的主要标识符。默认类型为字符串。
name − 它是序列的名称。默认类型为字符串。
description − 它显示有关序列的人类可读信息。
annotations − 它是有关序列的其他信息的字典。
SeqRecord可以按以下方式导入
from Bio.SeqRecord import SeqRecord
让我们在接下来的部分中了解使用真实序列文件解析序列文件的细微差别。
解析序列文件格式
本节说明如何解析两种最流行的序列文件格式:FASTA和GenBank。
FASTA
FASTA是用于存储序列数据的最基本的文件格式。最初,FASTA是一个用于DNA和蛋白质序列比对的软件包,开发于生物信息学的早期发展阶段,主要用于搜索序列相似性。
Biopython提供了一个示例FASTA文件,可以在以下位置访问:https://github.com/biopython/biopython/blob/master/Doc/examples/ls_orchid.fasta.
将此文件下载并保存到您的Biopython示例目录中,命名为“orchid.fasta”。
Bio.SeqIO模块提供parse()方法来处理序列文件,可以按如下方式导入:
from Bio.SeqIO import parse
parse()方法包含两个参数,第一个是文件句柄,第二个是文件格式。
>>> file = open('path/to/biopython/sample/orchid.fasta')
>>> for record in parse(file, "fasta"):
... print(record.id)
...
gi|2765658|emb|Z78533.1|CIZ78533
gi|2765657|emb|Z78532.1|CCZ78532
..........
..........
gi|2765565|emb|Z78440.1|PPZ78440
gi|2765564|emb|Z78439.1|PBZ78439
>>>
这里,parse()方法返回一个可迭代对象,该对象在每次迭代时返回SeqRecord。作为可迭代对象,它提供了许多复杂且易用的方法,让我们看看其中的一些功能。
next()
next()方法返回可迭代对象中可用的下一个项目,我们可以使用它来获取第一个序列,如下所示:
>>> first_seq_record = next(SeqIO.parse(open('path/to/biopython/sample/orchid.fasta'),'fasta'))
>>> first_seq_record.id 'gi|2765658|emb|Z78533.1|CIZ78533'
>>> first_seq_record.name 'gi|2765658|emb|Z78533.1|CIZ78533'
>>> first_seq_record.seq Seq('CGTAACAAGGTTTCCGTAGGTGAACCTGCGGAAGGATCATTGATGAGACCGTGG...CGC', SingleLetterAlphabet())
>>> first_seq_record.description 'gi|2765658|emb|Z78533.1|CIZ78533 C.irapeanum 5.8S rRNA gene and ITS1 and ITS2 DNA'
>>> first_seq_record.annotations
{}
>>>
这里,seq_record.annotations为空,因为FASTA格式不支持序列注释。
列表推导式
我们可以使用列表推导式将可迭代对象转换为列表,如下所示
>>> seq_iter = SeqIO.parse(open('path/to/biopython/sample/orchid.fasta'),'fasta')
>>> all_seq = [seq_record for seq_record in seq_iter] >>> len(all_seq)
94
>>>
这里,我们使用了len方法来获取总数。我们可以获取长度最大的序列,如下所示:
>>> seq_iter = SeqIO.parse(open('path/to/biopython/sample/orchid.fasta'),'fasta')
>>> max_seq = max(len(seq_record.seq) for seq_record in seq_iter)
>>> max_seq
789
>>>
我们也可以使用以下代码过滤序列:
>>> seq_iter = SeqIO.parse(open('path/to/biopython/sample/orchid.fasta'),'fasta')
>>> seq_under_600 = [seq_record for seq_record in seq_iter if len(seq_record.seq) < 600]
>>> for seq in seq_under_600:
... print(seq.id)
...
gi|2765606|emb|Z78481.1|PIZ78481
gi|2765605|emb|Z78480.1|PGZ78480
gi|2765601|emb|Z78476.1|PGZ78476
gi|2765595|emb|Z78470.1|PPZ78470
gi|2765594|emb|Z78469.1|PHZ78469
gi|2765564|emb|Z78439.1|PBZ78439
>>>
将SqlRecord对象(解析数据)的集合写入文件就像调用SeqIO.write方法一样简单,如下所示:
file = open("converted.fasta", "w)
SeqIO.write(seq_record, file, "fasta")
此方法可以有效地用于转换格式,如下所示:
file = open("converted.gbk", "w)
SeqIO.write(seq_record, file, "genbank")
GenBank
它是一种更丰富的基因序列格式,包括用于各种注释的字段。Biopython提供了一个示例GenBank文件,可以在以下位置访问:https://github.com/biopython/biopython/blob/master/Doc/examples/ls_orchid.fasta.
将文件下载并保存到您的Biopython示例目录中,命名为“orchid.gbk”
由于Biopython提供了一个单一函数parse来解析所有生物信息学格式,因此解析GenBank格式就像在parse方法中更改格式选项一样简单。
相同的代码如下所示:
>>> from Bio import SeqIO
>>> from Bio.SeqIO import parse
>>> seq_record = next(parse(open('path/to/biopython/sample/orchid.gbk'),'genbank'))
>>> seq_record.id
'Z78533.1'
>>> seq_record.name
'Z78533'
>>> seq_record.seq Seq('CGTAACAAGGTTTCCGTAGGTGAACCTGCGGAAGGATCATTGATGAGACCGTGG...CGC', IUPACAmbiguousDNA())
>>> seq_record.description
'C.irapeanum 5.8S rRNA gene and ITS1 and ITS2 DNA'
>>> seq_record.annotations {
'molecule_type': 'DNA',
'topology': 'linear',
'data_file_division': 'PLN',
'date': '30-NOV-2006',
'accessions': ['Z78533'],
'sequence_version': 1,
'gi': '2765658',
'keywords': ['5.8S ribosomal RNA', '5.8S rRNA gene', 'internal transcribed spacer', 'ITS1', 'ITS2'],
'source': 'Cypripedium irapeanum',
'organism': 'Cypripedium irapeanum',
'taxonomy': [
'Eukaryota',
'Viridiplantae',
'Streptophyta',
'Embryophyta',
'Tracheophyta',
'Spermatophyta',
'Magnoliophyta',
'Liliopsida',
'Asparagales',
'Orchidaceae',
'Cypripedioideae',
'Cypripedium'],
'references': [
Reference(title = 'Phylogenetics of the slipper orchids (Cypripedioideae:
Orchidaceae): nuclear rDNA ITS sequences', ...),
Reference(title = 'Direct Submission', ...)
]
}
Biopython - 序列比对
序列比对是将两个或多个序列(DNA、RNA或蛋白质序列)按特定顺序排列以识别它们之间相似区域的过程。
识别相似区域使我们能够推断出许多信息,例如不同物种之间哪些性状是保守的、不同物种在遗传上有多接近、物种如何进化等等。Biopython为序列比对提供了广泛的支持。
让我们在本节中学习Biopython提供的一些重要功能:
解析序列比对
Biopython提供了一个模块Bio.AlignIO来读取和写入序列比对。在生物信息学中,有很多格式可用于指定序列比对数据,类似于前面学习的序列数据。Bio.AlignIO提供类似于Bio.SeqIO的API,不同之处在于Bio.SeqIO处理序列数据,而Bio.AlignIO处理序列比对数据。
在开始学习之前,让我们从互联网下载一个示例序列比对文件。
要下载示例文件,请按照以下步骤操作:
步骤1 − 打开您喜欢的浏览器并访问http://pfam.xfam.org/family/browse网站。它将按字母顺序显示所有Pfam家族。
步骤2 − 选择任何一个种子值较少的家族。它包含最少的数据,使我们能够轻松地处理比对。这里,我们选择了/点击了PF18225,它会打开http://pfam.xfam.org/family/PF18225并显示有关它的完整详细信息,包括序列比对。
步骤3 − 转到比对部分,并以Stockholm格式(PF18225_seed.txt)下载序列比对文件。
让我们尝试使用Bio.AlignIO读取下载的序列比对文件,如下所示:
导入Bio.AlignIO模块
>>> from Bio import AlignIO
使用read方法读取比对。read方法用于读取给定文件中可用的单个比对数据。如果给定文件包含多个比对,我们可以使用parse方法。parse方法返回可迭代的比对对象,类似于Bio.SeqIO模块中的parse方法。
>>> alignment = AlignIO.read(open("PF18225_seed.txt"), "stockholm")
打印比对对象。
>>> print(alignment) SingleLetterAlphabet() alignment with 6 rows and 65 columns MQNTPAERLPAIIEKAKSKHDINVWLLDRQGRDLLEQRVPAKVA...EGP B7RZ31_9GAMM/59-123 AKQRGIAGLEEWLHRLDHSEAIPIFLIDEAGKDLLEREVPADIT...KKP A0A0C3NPG9_9PROT/58-119 ARRHGQEYFQQWLERQPKKVKEQVFAVDQFGRELLGRPLPEDMA...KKP A0A143HL37_9GAMM/57-121 TRRHGPESFRFWLERQPVEARDRIYAIDRSGAEILDRPIPRGMA...NKP A0A0X3UC67_9GAMM/57-121 AINRNTQQLTQDLRAMPNWSLRFVYIVDRNNQDLLKRPLPPGIM...NRK B3PFT7_CELJU/62-126 AVNATEREFTERIRTLPHWARRNVFVLDSQGFEIFDRELPSPVA...NRT K4KEM7_SIMAS/61-125 >>>
我们还可以检查比对中可用的序列(SeqRecord),如下所示:
>>> for align in alignment: ... print(align.seq) ... MQNTPAERLPAIIEKAKSKHDINVWLLDRQGRDLLEQRVPAKVATVANQLRGRKRRAFARHREGP AKQRGIAGLEEWLHRLDHSEAIPIFLIDEAGKDLLEREVPADITA---RLDRRREHGEHGVRKKP ARRHGQEYFQQWLERQPKKVKEQVFAVDQFGRELLGRPLPEDMAPMLIALNYRNRESHAQVDKKP TRRHGPESFRFWLERQPVEARDRIYAIDRSGAEILDRPIPRGMAPLFKVLSFRNREDQGLVNNKP AINRNTQQLTQDLRAMPNWSLRFVYIVDRNNQDLLKRPLPPGIMVLAPRLTAKHPYDKVQDRNRK AVNATEREFTERIRTLPHWARRNVFVLDSQGFEIFDRELPSPVADLMRKLDLDRPFKKLERKNRT >>>
多序列比对
通常,大多数序列比对文件包含单个比对数据,使用read方法解析就足够了。在多序列比对的概念中,两个或多个序列被比较以找到它们之间最佳的子序列匹配,并最终将结果以多序列比对的形式存储在一个文件中。
如果输入序列比对格式包含多个序列比对,那么我们需要使用parse方法而不是read方法,如下所示:
>>> from Bio import AlignIO
>>> alignments = AlignIO.parse(open("PF18225_seed.txt"), "stockholm")
>>> print(alignments)
<generator object parse at 0x000001CD1C7E0360>
>>> for alignment in alignments:
... print(alignment)
...
SingleLetterAlphabet() alignment with 6 rows and 65 columns
MQNTPAERLPAIIEKAKSKHDINVWLLDRQGRDLLEQRVPAKVA...EGP B7RZ31_9GAMM/59-123
AKQRGIAGLEEWLHRLDHSEAIPIFLIDEAGKDLLEREVPADIT...KKP A0A0C3NPG9_9PROT/58-119
ARRHGQEYFQQWLERQPKKVKEQVFAVDQFGRELLGRPLPEDMA...KKP A0A143HL37_9GAMM/57-121
TRRHGPESFRFWLERQPVEARDRIYAIDRSGAEILDRPIPRGMA...NKP A0A0X3UC67_9GAMM/57-121
AINRNTQQLTQDLRAMPNWSLRFVYIVDRNNQDLLKRPLPPGIM...NRK B3PFT7_CELJU/62-126
AVNATEREFTERIRTLPHWARRNVFVLDSQGFEIFDRELPSPVA...NRT K4KEM7_SIMAS/61-125
>>>
在这里,parse方法返回可迭代的比对对象,并且可以对其进行迭代以获取实际的比对。
成对序列比对
成对序列比对一次只比较两个序列,并提供最佳可能的序列比对。成对比对易于理解,并且从所得的序列比对结果中推断出信息也十分便捷。
Biopython提供了一个特殊的模块Bio.pairwise2,用于使用成对方法识别比对序列。Biopython应用最佳算法来查找比对序列,其性能与其他软件相当。
让我们编写一个示例,使用成对模块查找两个简单且假设的序列的序列比对。这将帮助我们理解序列比对的概念以及如何使用Biopython对其进行编程。
步骤 1
使用以下命令导入模块pairwise2:
>>> from Bio import pairwise2
步骤 2
创建两个序列,seq1和seq2:
>>> from Bio.Seq import Seq
>>> seq1 = Seq("ACCGGT")
>>> seq2 = Seq("ACGT")
步骤 3
使用以下代码行调用pairwise2.align.globalxx方法,并传入seq1和seq2以查找比对:
>>> alignments = pairwise2.align.globalxx(seq1, seq2)
在这里,globalxx方法执行实际工作,并找到给定序列中所有可能的最佳比对。实际上,Bio.pairwise2提供了相当一组方法,这些方法遵循以下约定在不同情况下查找比对。
<sequence alignment type>XY
这里,序列比对类型指的是比对类型,可以是全局或局部。全局类型通过考虑整个序列来查找序列比对。局部类型通过查看给定序列的子集来查找序列比对。这将比较繁琐,但提供了关于给定序列之间相似性的更佳理解。
X指的是匹配得分。可能的值有x(完全匹配)、m(基于相同字符的得分)、d(用户提供的包含字符和匹配得分的字典)以及c(用户自定义函数,用于提供自定义评分算法)。
Y指的是间隔罚分。可能的值有x(无间隔罚分)、s(两个序列的罚分相同)、d(每个序列的罚分不同)以及c(用户自定义函数,用于提供自定义间隔罚分)。
因此,localds也是一个有效的方法,它使用局部比对技术、用户提供的匹配字典和用户提供的两个序列的间隔罚分来查找序列比对。
>>> test_alignments = pairwise2.align.localds(seq1, seq2, blosum62, -10, -1)
这里,blosum62指的是pairwise2模块中提供匹配得分的字典。-10指的是间隔打开罚分,-1指的是间隔扩展罚分。
步骤 4
遍历可迭代的比对对象,获取每个单独的比对对象并打印它。
>>> for alignment in alignments:
... print(alignment)
...
('ACCGGT', 'A-C-GT', 4.0, 0, 6)
('ACCGGT', 'AC--GT', 4.0, 0, 6)
('ACCGGT', 'A-CG-T', 4.0, 0, 6)
('ACCGGT', 'AC-G-T', 4.0, 0, 6)
步骤 5
Bio.pairwise2模块提供了一个格式化方法format_alignment,可以更好地可视化结果:
>>> from Bio.pairwise2 import format_alignment >>> alignments = pairwise2.align.globalxx(seq1, seq2) >>> for alignment in alignments: ... print(format_alignment(*alignment)) ... ACCGGT | | || A-C-GT Score=4 ACCGGT || || AC--GT Score=4 ACCGGT | || | A-CG-T Score=4 ACCGGT || | | AC-G-T Score=4 >>>
Biopython还提供另一个模块来进行序列比对,即Align。此模块提供了一组不同的API来简化参数的设置,例如算法、模式、匹配得分、间隔罚分等。对Align对象的简单了解如下:
>>> from Bio import Align >>> aligner = Align.PairwiseAligner() >>> print(aligner) Pairwise sequence aligner with parameters match score: 1.000000 mismatch score: 0.000000 target open gap score: 0.000000 target extend gap score: 0.000000 target left open gap score: 0.000000 target left extend gap score: 0.000000 target right open gap score: 0.000000 target right extend gap score: 0.000000 query open gap score: 0.000000 query extend gap score: 0.000000 query left open gap score: 0.000000 query left extend gap score: 0.000000 query right open gap score: 0.000000 query right extend gap score: 0.000000 mode: global >>>
对序列比对工具的支持
Biopython通过Bio.Align.Applications模块为许多序列比对工具提供了接口。一些工具列在下面:
- ClustalW
- MUSCLE
- EMBOSS needle和water
让我们在Biopython中编写一个简单的示例,通过最流行的比对工具ClustalW创建序列比对。
步骤 1 - 从http://www.clustal.org/download/current/下载Clustalw程序并安装它。此外,使用“clustal”安装路径更新系统PATH。
步骤 2 - 从模块Bio.Align.Applications导入ClustalwCommanLine。
>>> from Bio.Align.Applications import ClustalwCommandline
步骤 3 - 通过调用ClustalwCommanLine并传入输入文件opuntia.fasta(位于Biopython包中)来设置cmd。https://raw.githubusercontent.com/biopython/biopython/master/Doc/examples/opuntia.fasta
>>> cmd = ClustalwCommandline("clustalw2",
infile="/path/to/biopython/sample/opuntia.fasta")
>>> print(cmd)
clustalw2 -infile=fasta/opuntia.fasta
步骤 4 - 调用cmd()将运行clustalw命令,并输出结果比对文件opuntia.aln。
>>> stdout, stderr = cmd()
步骤 5 - 读取并打印比对文件,如下所示:
>>> from Bio import AlignIO
>>> align = AlignIO.read("/path/to/biopython/sample/opuntia.aln", "clustal")
>>> print(align)
SingleLetterAlphabet() alignment with 7 rows and 906 columns
TATACATTAAAGAAGGGGGATGCGGATAAATGGAAAGGCGAAAG...AGA
gi|6273285|gb|AF191659.1|AF191
TATACATTAAAGAAGGGGGATGCGGATAAATGGAAAGGCGAAAG...AGA
gi|6273284|gb|AF191658.1|AF191
TATACATTAAAGAAGGGGGATGCGGATAAATGGAAAGGCGAAAG...AGA
gi|6273287|gb|AF191661.1|AF191
TATACATAAAAGAAGGGGGATGCGGATAAATGGAAAGGCGAAAG...AGA
gi|6273286|gb|AF191660.1|AF191
TATACATTAAAGGAGGGGGATGCGGATAAATGGAAAGGCGAAAG...AGA
gi|6273290|gb|AF191664.1|AF191
TATACATTAAAGGAGGGGGATGCGGATAAATGGAAAGGCGAAAG...AGA
gi|6273289|gb|AF191663.1|AF191
TATACATTAAAGGAGGGGGATGCGGATAAATGGAAAGGCGAAAG...AGA
gi|6273291|gb|AF191665.1|AF191
>>>
Biopython - BLAST 概述
BLAST代表Basic Local Alignment Search Tool(基本局部比对搜索工具)。它查找生物序列之间相似性区域。Biopython提供Bio.Blast模块来处理NCBI BLAST操作。您可以在本地连接或通过Internet连接运行BLAST。
让我们在下一节中简要了解这两种连接:
通过Internet运行
Biopython提供Bio.Blast.NCBIWWW模块来调用BLAST的在线版本。为此,我们需要导入以下模块:
>>> from Bio.Blast import NCBIWWW
NCBIWW模块提供qblast函数来查询BLAST在线版本,https://blast.ncbi.nlm.nih.gov/Blast.cgi。qblast支持在线版本支持的所有参数。
要获取有关此模块的任何帮助,请使用以下命令并了解其功能:
>>> help(NCBIWWW.qblast) Help on function qblast in module Bio.Blast.NCBIWWW: qblast( program, database, sequence, url_base = 'https://blast.ncbi.nlm.nih.gov/Blast.cgi', auto_format = None, composition_based_statistics = None, db_genetic_code = None, endpoints = None, entrez_query = '(none)', expect = 10.0, filter = None, gapcosts = None, genetic_code = None, hitlist_size = 50, i_thresh = None, layout = None, lcase_mask = None, matrix_name = None, nucl_penalty = None, nucl_reward = None, other_advanced = None, perc_ident = None, phi_pattern = None, query_file = None, query_believe_defline = None, query_from = None, query_to = None, searchsp_eff = None, service = None, threshold = None, ungapped_alignment = None, word_size = None, alignments = 500, alignment_view = None, descriptions = 500, entrez_links_new_window = None, expect_low = None, expect_high = None, format_entrez_query = None, format_object = None, format_type = 'XML', ncbi_gi = None, results_file = None, show_overview = None, megablast = None, template_type = None, template_length = None ) BLAST search using NCBI's QBLAST server or a cloud service provider. Supports all parameters of the qblast API for Put and Get. Please note that BLAST on the cloud supports the NCBI-BLAST Common URL API (http://ncbi.github.io/blast-cloud/dev/api.html). To use this feature, please set url_base to 'http://host.my.cloud.service.provider.com/cgi-bin/blast.cgi' and format_object = 'Alignment'. For more details, please see 8. Biopython – Overview of BLAST https://blast.ncbi.nlm.nih.gov/Blast.cgi?PAGE_TYPE = BlastDocs&DOC_TYPE = CloudBlast Some useful parameters: - program blastn, blastp, blastx, tblastn, or tblastx (lower case) - database Which database to search against (e.g. "nr"). - sequence The sequence to search. - ncbi_gi TRUE/FALSE whether to give 'gi' identifier. - descriptions Number of descriptions to show. Def 500. - alignments Number of alignments to show. Def 500. - expect An expect value cutoff. Def 10.0. - matrix_name Specify an alt. matrix (PAM30, PAM70, BLOSUM80, BLOSUM45). - filter "none" turns off filtering. Default no filtering - format_type "HTML", "Text", "ASN.1", or "XML". Def. "XML". - entrez_query Entrez query to limit Blast search - hitlist_size Number of hits to return. Default 50 - megablast TRUE/FALSE whether to use MEga BLAST algorithm (blastn only) - service plain, psi, phi, rpsblast, megablast (lower case) This function does no checking of the validity of the parameters and passes the values to the server as is. More help is available at: https://ncbi.github.io/blast-cloud/dev/api.html
通常,qblast函数的参数基本上类似于您可以在BLAST网页上设置的不同参数。这使得qblast函数易于理解,并减少了使用它的学习曲线。
连接和搜索
为了理解连接和搜索BLAST在线版本的流程,让我们通过Biopython对在线BLAST服务器进行一个简单的序列搜索(在我们本地的序列文件中可用)。
步骤 1 - 在Biopython目录中创建一个名为blast_example.fasta的文件,并将以下序列信息作为输入。
Example of a single sequence in FASTA/Pearson format: >sequence A ggtaagtcctctagtacaaacacccccaatattgtgatataattaaaattatattcatat tctgttgccagaaaaaacacttttaggctatattagagccatcttctttgaagcgttgtc >sequence B ggtaagtcctctagtacaaacacccccaatattgtgatataattaaaattatattca tattctgttgccagaaaaaacacttttaggctatattagagccatcttctttgaagcgttgtc
步骤 2 - 导入NCBIWWW模块。
>>> from Bio.Blast import NCBIWWW
步骤 3 - 使用python IO模块打开序列文件blast_example.fasta。
>>> sequence_data = open("blast_example.fasta").read()
>>> sequence_data
'Example of a single sequence in FASTA/Pearson format:\n\n\n> sequence
A\nggtaagtcctctagtacaaacacccccaatattgtgatataattaaaatt
atattcatat\ntctgttgccagaaaaaacacttttaggctatattagagccatcttctttg aagcgttgtc\n\n'
步骤 4 - 现在,调用qblast函数,并将序列数据作为主要参数传递。其他参数表示数据库(nt)和内部程序(blastn)。
>>> result_handle = NCBIWWW.qblast("blastn", "nt", sequence_data)
>>> result_handle
<_io.StringIO object at 0x000001EC9FAA4558>
blast_results保存我们搜索的结果。它可以保存到文件中以供以后使用,也可以解析以获取详细信息。我们将在下一节中学习如何执行此操作。
步骤 5 - 同样的功能也可以使用Seq对象来完成,而不是使用整个fasta文件,如下所示:
>>> from Bio import SeqIO
>>> seq_record = next(SeqIO.parse(open('blast_example.fasta'),'fasta'))
>>> seq_record.id
'sequence'
>>> seq_record.seq
Seq('ggtaagtcctctagtacaaacacccccaatattgtgatataattaaaattatat...gtc',
SingleLetterAlphabet())
现在,调用qblast函数,并将Seq对象record.seq作为主要参数传递。
>>> result_handle = NCBIWWW.qblast("blastn", "nt", seq_record.seq)
>>> print(result_handle)
<_io.StringIO object at 0x000001EC9FAA4558>
BLAST将自动为您的序列分配一个标识符。
步骤 6 - result_handle对象将包含整个结果,并可以保存到文件中以供以后使用。
>>> with open('results.xml', 'w') as save_file:
>>> blast_results = result_handle.read()
>>> save_file.write(blast_results)
我们将在后面的章节中了解如何解析结果文件。
运行独立的BLAST
本节介绍如何在本地系统中运行BLAST。如果您在本地系统中运行BLAST,它可能会更快,并且允许您创建自己的数据库来搜索序列。
连接BLAST
通常,由于BLAST体积庞大、运行软件需要额外工作以及成本问题,不建议在本地运行。对于基本和高级用途,在线BLAST已足够。当然,有时您可能需要在本地安装它。
假设您正在进行频繁的在线搜索,这可能需要大量时间和网络流量,并且如果您有专有的序列数据或与IP相关的隐私问题,那么建议在本地安装它。
为此,我们需要遵循以下步骤:
步骤 1 - 使用给定的链接下载并安装最新的blast二进制文件:ftp://ftp.ncbi.nlm.nih.gov/blast/executables/blast+/LATEST/
步骤 2 - 使用以下链接下载并解压缩最新的必要数据库:ftp://ftp.ncbi.nlm.nih.gov/blast/db/
BLAST软件在其网站上提供了许多数据库。让我们从blast数据库站点下载alu.n.gz文件并将其解压缩到alu文件夹中。此文件为FASTA格式。要在我们的blast应用程序中使用此文件,我们需要先将文件从FASTA格式转换为blast数据库格式。BLAST提供makeblastdb应用程序来执行此转换。
使用以下代码片段:
cd /path/to/alu makeblastdb -in alu.n -parse_seqids -dbtype nucl -out alun
运行以上代码将解析输入文件alu.n并创建BLAST数据库,如多个文件alun.nsq、alun.nsi等。现在,我们可以查询此数据库以查找序列。
我们已在本地服务器上安装了BLAST,并且还拥有示例BLAST数据库alun,可以对其进行查询。
步骤 3 - 让我们创建一个示例序列文件来查询数据库。创建一个名为search.fsa的文件,并将以下数据放入其中。
>gnl|alu|Z15030_HSAL001056 (Alu-J) AGGCTGGCACTGTGGCTCATGCTGAAATCCCAGCACGGCGGAGGACGGCGGAAGATTGCT TGAGCCTAGGAGTTTGCGACCAGCCTGGGTGACATAGGGAGATGCCTGTCTCTACGCAAA AGAAAAAAAAAATAGCTCTGCTGGTGGTGCATGCCTATAGTCTCAGCTATCAGGAGGCTG GGACAGGAGGATCACTTGGGCCCGGGAGTTGAGGCTGTGGTGAGCCACGATCACACCACT GCACTCCAGCCTGGGTGACAGAGCAAGACCCTGTCTCAAAACAAACAAATAA >gnl|alu|D00596_HSAL003180 (Alu-Sx) AGCCAGGTGTGGTGGCTCACGCCTGTAATCCCACCGCTTTGGGAGGCTGAGTCAGATCAC CTGAGGTTAGGAATTTGGGACCAGCCTGGCCAACATGGCGACACCCCAGTCTCTACTAAT AACACAAAAAATTAGCCAGGTGTGCTGGTGCATGTCTGTAATCCCAGCTACTCAGGAGGC TGAGGCATGAGAATTGCTCACGAGGCGGAGGTTGTAGTGAGCTGAGATCGTGGCACTGTA CTCCAGCCTGGCGACAGAGGGAGAACCCATGTCAAAAACAAAAAAAGACACCACCAAAGG TCAAAGCATA >gnl|alu|X55502_HSAL000745 (Alu-J) TGCCTTCCCCATCTGTAATTCTGGCACTTGGGGAGTCCAAGGCAGGATGATCACTTATGC CCAAGGAATTTGAGTACCAAGCCTGGGCAATATAACAAGGCCCTGTTTCTACAAAAACTT TAAACAATTAGCCAGGTGTGGTGGTGCGTGCCTGTGTCCAGCTACTCAGGAAGCTGAGGC AAGAGCTTGAGGCTACAGTGAGCTGTGTTCCACCATGGTGCTCCAGCCTGGGTGACAGGG CAAGACCCTGTCAAAAGAAAGGAAGAAAGAACGGAAGGAAAGAAGGAAAGAAACAAGGAG AG
序列数据是从alu.n文件中收集的;因此,它与我们的数据库匹配。
步骤 4 - BLAST软件提供了许多应用程序来搜索数据库,我们使用blastn。blastn应用程序至少需要三个参数:db、query和out。db指的是要搜索的数据库;query是要匹配的序列;out是要存储结果的文件。现在,运行以下命令执行此简单查询:
blastn -db alun -query search.fsa -out results.xml -outfmt 5
运行以上命令将在results.xml文件中搜索并输出结果,如下所示(部分数据):
<?xml version = "1.0"?>
<!DOCTYPE BlastOutput PUBLIC "-//NCBI//NCBI BlastOutput/EN"
"http://www.ncbi.nlm.nih.gov/dtd/NCBI_BlastOutput.dtd">
<BlastOutput>
<BlastOutput_program>blastn</BlastOutput_program>
<BlastOutput_version>BLASTN 2.7.1+</BlastOutput_version>
<BlastOutput_reference>Zheng Zhang, Scott Schwartz, Lukas Wagner, and Webb
Miller (2000), "A greedy algorithm for aligning DNA sequences", J
Comput Biol 2000; 7(1-2):203-14.
</BlastOutput_reference>
<BlastOutput_db>alun</BlastOutput_db>
<BlastOutput_query-ID>Query_1</BlastOutput_query-ID>
<BlastOutput_query-def>gnl|alu|Z15030_HSAL001056 (Alu-J)</BlastOutput_query-def>
<BlastOutput_query-len>292</BlastOutput_query-len>
<BlastOutput_param>
<Parameters>
<Parameters_expect>10</Parameters_expect>
<Parameters_sc-match>1</Parameters_sc-match>
<Parameters_sc-mismatch>-2</Parameters_sc-mismatch>
<Parameters_gap-open>0</Parameters_gap-open>
<Parameters_gap-extend>0</Parameters_gap-extend>
<Parameters_filter>L;m;</Parameters_filter>
</Parameters>
</BlastOutput_param>
<BlastOutput_iterations>
<Iteration>
<Iteration_iter-num>1</Iteration_iter-num><Iteration_query-ID>Query_1</Iteration_query-ID>
<Iteration_query-def>gnl|alu|Z15030_HSAL001056 (Alu-J)</Iteration_query-def>
<Iteration_query-len>292</Iteration_query-len>
<Iteration_hits>
<Hit>
<Hit_num>1</Hit_num>
<Hit_id>gnl|alu|Z15030_HSAL001056</Hit_id>
<Hit_def>(Alu-J)</Hit_def>
<Hit_accession>Z15030_HSAL001056</Hit_accession>
<Hit_len>292</Hit_len>
<Hit_hsps>
<Hsp>
<Hsp_num>1</Hsp_num>
<Hsp_bit-score>540.342</Hsp_bit-score>
<Hsp_score>292</Hsp_score>
<Hsp_evalue>4.55414e-156</Hsp_evalue>
<Hsp_query-from>1</Hsp_query-from>
<Hsp_query-to>292</Hsp_query-to>
<Hsp_hit-from>1</Hsp_hit-from>
<Hsp_hit-to>292</Hsp_hit-to>
<Hsp_query-frame>1</Hsp_query-frame>
<Hsp_hit-frame>1</Hsp_hit-frame>
<Hsp_identity>292</Hsp_identity>
<Hsp_positive>292</Hsp_positive>
<Hsp_gaps>0</Hsp_gaps>
<Hsp_align-len>292</Hsp_align-len>
<Hsp_qseq>
AGGCTGGCACTGTGGCTCATGCTGAAATCCCAGCACGGCGGAGGACGGCGGAAGATTGCTTGAGCCTAGGAGTTTG
CGACCAGCCTGGGTGACATAGGGAGATGCCTGTCTCTACGCAAAAGAAAAAAAAAATAGCTCTGCTGGTGGTGCATG
CCTATAGTCTCAGCTATCAGGAGGCTGGGACAGGAGGATCACTTGGGCCCGGGAGTTGAGGCTGTGGTGAGCC
ACGATCACACCACTGCACTCCAGCCTGGGTGACAGAGCAAGACCCTGTCTCAAAACAAACAAATAA
</Hsp_qseq>
<Hsp_hseq>
AGGCTGGCACTGTGGCTCATGCTGAAATCCCAGCACGGCGGAGGACGGCGGAAGATTGCTTGAGCCTAGGA
GTTTGCGACCAGCCTGGGTGACATAGGGAGATGCCTGTCTCTACGCAAAAGAAAAAAAAAATAGCTCTGCT
GGTGGTGCATGCCTATAGTCTCAGCTATCAGGAGGCTGGGACAGGAGGATCACTTGGGCCCGGGAGTTGAGG
CTGTGGTGAGCCACGATCACACCACTGCACTCCAGCCTGGGTGACAGAGCAAGACCCTGTCTCAAAACAAAC
AAATAA
</Hsp_hseq>
<Hsp_midline>
|||||||||||||||||||||||||||||||||||||||||||||||||||||
|||||||||||||||||||||||||||||||||||||||||||||||||||||
|||||||||||||||||||||||||||||||||||||||||||||||||||||
|||||||||||||||||||||||||||||||||||||||||||||||||||||
|||||||||||||||||||||||||||||||||||||||||||||||||||||
|||||||||||||||||||||||||||
</Hsp_midline>
</Hsp>
</Hit_hsps>
</Hit>
.........................
.........................
.........................
</Iteration_hits>
<Iteration_stat>
<Statistics>
<Statistics_db-num>327</Statistics_db-num>
<Statistics_db-len>80506</Statistics_db-len>
<Statistics_hsp-lenv16</Statistics_hsp-len>
<Statistics_eff-space>21528364</Statistics_eff-space>
<Statistics_kappa>0.46</Statistics_kappa>
<Statistics_lambda>1.28</Statistics_lambda>
<Statistics_entropy>0.85</Statistics_entropy>
</Statistics>
</Iteration_stat>
</Iteration>
</BlastOutput_iterations>
</BlastOutput>
以上命令可以在python中使用以下代码运行:
>>> from Bio.Blast.Applications import NcbiblastnCommandline >>> blastn_cline = NcbiblastnCommandline(query = "search.fasta", db = "alun", outfmt = 5, out = "results.xml") >>> stdout, stderr = blastn_cline()
这里,第一个是blast输出的句柄,第二个是blast命令生成的可能的错误输出。
由于我们已将输出文件作为命令行参数提供(out = “results.xml”)并将输出格式设置为XML(outfmt = 5),因此输出文件将保存在当前工作目录中。
解析BLAST结果
通常,BLAST输出使用NCBIXML模块解析为XML格式。为此,我们需要导入以下模块:
>>> from Bio.Blast import NCBIXML
现在,使用python open方法直接打开文件并使用NCBIXML parse方法,如下所示:
>>> E_VALUE_THRESH = 1e-20
>>> for record in NCBIXML.parse(open("results.xml")):
>>> if record.alignments:
>>> print("\n")
>>> print("query: %s" % record.query[:100])
>>> for align in record.alignments:
>>> for hsp in align.hsps:
>>> if hsp.expect < E_VALUE_THRESH:
>>> print("match: %s " % align.title[:100])
这将产生如下输出:
query: gnl|alu|Z15030_HSAL001056 (Alu-J) match: gnl|alu|Z15030_HSAL001056 (Alu-J) match: gnl|alu|L12964_HSAL003860 (Alu-J) match: gnl|alu|L13042_HSAL003863 (Alu-FLA?) match: gnl|alu|M86249_HSAL001462 (Alu-FLA?) match: gnl|alu|M29484_HSAL002265 (Alu-J) query: gnl|alu|D00596_HSAL003180 (Alu-Sx) match: gnl|alu|D00596_HSAL003180 (Alu-Sx) match: gnl|alu|J03071_HSAL001860 (Alu-J) match: gnl|alu|X72409_HSAL005025 (Alu-Sx) query: gnl|alu|X55502_HSAL000745 (Alu-J) match: gnl|alu|X55502_HSAL000745 (Alu-J)
Biopython - Entrez 数据库
Entrez是NCBI提供的在线搜索系统。它提供对几乎所有已知的分子生物学数据库的访问,并集成了一个全局查询,支持布尔运算符和字段搜索。它从所有数据库返回结果,其中包含诸如每个数据库的命中次数、带有指向源数据库链接的记录等信息。
一些可以通过Entrez访问的流行数据库列在下面:
- PubMed
- PubMed Central
- 核苷酸(GenBank序列数据库)
- 蛋白质(序列数据库)
- 基因组(全基因组数据库)
- 结构(三维大分子结构)
- 分类(GenBank中的生物体)
- SNP(单核苷酸多态性)
- UniGene(转录序列的基因导向簇)
- CDD(保守蛋白结构域数据库)
- 3D结构域(来自Entrez结构的结构域)
除了上述数据库之外,Entrez 还提供了更多数据库来执行字段搜索。
Biopython 提供了一个 Entrez 特定的模块 Bio.Entrez 来访问 Entrez 数据库。让我们在本节中学习如何使用 Biopython 访问 Entrez -
数据库连接步骤
要添加 Entrez 的功能,请导入以下模块 -
>>> from Bio import Entrez
接下来设置您的电子邮件以识别谁连接到下面给出的代码 -
>>> Entrez.email = '<youremail>'
然后,设置 Entrez 工具参数,默认情况下为 Biopython。
>>> Entrez.tool = 'Demoscript'
现在,调用 einfo 函数以查找每个数据库的索引词计数、上次更新和可用链接,如下所示 -
>>> info = Entrez.einfo()
einfo 方法返回一个对象,该对象通过其 read 方法提供对信息的访问,如下所示 -
>>> data = info.read()
>>> print(data)
<?xml version = "1.0" encoding = "UTF-8" ?>
<!DOCTYPE eInfoResult PUBLIC "-//NLM//DTD einfo 20130322//EN"
"https://eutils.ncbi.nlm.nih.gov/eutils/dtd/20130322/einfo.dtd">
<eInfoResult>
<DbList>
<DbName>pubmed</DbName>
<DbName>protein</DbName>
<DbName>nuccore</DbName>
<DbName>ipg</DbName>
<DbName>nucleotide</DbName>
<DbName>nucgss</DbName>
<DbName>nucest</DbName>
<DbName>structure</DbName>
<DbName>sparcle</DbName>
<DbName>genome</DbName>
<DbName>annotinfo</DbName>
<DbName>assembly</DbName>
<DbName>bioproject</DbName>
<DbName>biosample</DbName>
<DbName>blastdbinfo</DbName>
<DbName>books</DbName>
<DbName>cdd</DbName>
<DbName>clinvar</DbName>
<DbName>clone</DbName>
<DbName>gap</DbName>
<DbName>gapplus</DbName>
<DbName>grasp</DbName>
<DbName>dbvar</DbName>
<DbName>gene</DbName>
<DbName>gds</DbName>
<DbName>geoprofiles</DbName>
<DbName>homologene</DbName>
<DbName>medgen</DbName>
<DbName>mesh</DbName>
<DbName>ncbisearch</DbName>
<DbName>nlmcatalog</DbName>
<DbName>omim</DbName>
<DbName>orgtrack</DbName>
<DbName>pmc</DbName>
<DbName>popset</DbName>
<DbName>probe</DbName>
<DbName>proteinclusters</DbName>
<DbName>pcassay</DbName>
<DbName>biosystems</DbName>
<DbName>pccompound</DbName>
<DbName>pcsubstance</DbName>
<DbName>pubmedhealth</DbName>
<DbName>seqannot</DbName>
<DbName>snp</DbName>
<DbName>sra</DbName>
<DbName>taxonomy</DbName>
<DbName>biocollections</DbName>
<DbName>unigene</DbName>
<DbName>gencoll</DbName>
<DbName>gtr</DbName>
</DbList>
</eInfoResult>
数据采用 XML 格式,要将数据作为 python 对象获取,请在调用Entrez.einfo()方法后立即使用Entrez.read方法 -
>>> info = Entrez.einfo() >>> record = Entrez.read(info)
这里,record 是一个字典,它有一个键 DbList,如下所示 -
>>> record.keys() [u'DbList']
访问 DbList 键将返回数据库名称列表,如下所示 -
>>> record[u'DbList'] ['pubmed', 'protein', 'nuccore', 'ipg', 'nucleotide', 'nucgss', 'nucest', 'structure', 'sparcle', 'genome', 'annotinfo', 'assembly', 'bioproject', 'biosample', 'blastdbinfo', 'books', 'cdd', 'clinvar', 'clone', 'gap', 'gapplus', 'grasp', 'dbvar', 'gene', 'gds', 'geoprofiles', 'homologene', 'medgen', 'mesh', 'ncbisearch', 'nlmcatalog', 'omim', 'orgtrack', 'pmc', 'popset', 'probe', 'proteinclusters', 'pcassay', 'biosystems', 'pccompound', 'pcsubstance', 'pubmedhealth', 'seqannot', 'snp', 'sra', 'taxonomy', 'biocollections', 'unigene', 'gencoll', 'gtr'] >>>
基本上,Entrez 模块解析 Entrez 搜索系统返回的 XML 并将其作为 python 字典和列表提供。
搜索数据库
要搜索任何一个 Entrez 数据库,我们可以使用 Bio.Entrez.esearch() 模块。它定义如下 -
>>> info = Entrez.einfo()
>>> info = Entrez.esearch(db = "pubmed",term = "genome")
>>> record = Entrez.read(info)
>>>print(record)
DictElement({u'Count': '1146113', u'RetMax': '20', u'IdList':
['30347444', '30347404', '30347317', '30347292',
'30347286', '30347249', '30347194', '30347187',
'30347172', '30347088', '30347075', '30346992',
'30346990', '30346982', '30346980', '30346969',
'30346962', '30346954', '30346941', '30346939'],
u'TranslationStack': [DictElement({u'Count':
'927819', u'Field': 'MeSH Terms', u'Term': '"genome"[MeSH Terms]',
u'Explode': 'Y'}, attributes = {})
, DictElement({u'Count': '422712', u'Field':
'All Fields', u'Term': '"genome"[All Fields]', u'Explode': 'N'}, attributes = {}),
'OR', 'GROUP'], u'TranslationSet': [DictElement({u'To': '"genome"[MeSH Terms]
OR "genome"[All Fields]', u'From': 'genome'}, attributes = {})], u'RetStart': '0',
u'QueryTranslation': '"genome"[MeSH Terms] OR "genome"[All Fields]'},
attributes = {})
>>>
如果您分配了不正确的数据库,则它将返回
>>> info = Entrez.esearch(db = "blastdbinfo",term = "books")
>>> record = Entrez.read(info)
>>> print(record)
DictElement({u'Count': '0', u'RetMax': '0', u'IdList': [],
u'WarningList': DictElement({u'OutputMessage': ['No items found.'],
u'PhraseIgnored': [], u'QuotedPhraseNotFound': []}, attributes = {}),
u'ErrorList': DictElement({u'FieldNotFound': [], u'PhraseNotFound':
['books']}, attributes = {}), u'TranslationSet': [], u'RetStart': '0',
u'QueryTranslation': '(books[All Fields])'}, attributes = {})
如果要跨数据库搜索,则可以使用Entrez.egquery。这类似于Entrez.esearch,只是它只需指定关键字并跳过数据库参数即可。
>>>info = Entrez.egquery(term = "entrez") >>> record = Entrez.read(info) >>> for row in record["eGQueryResult"]: ... print(row["DbName"], row["Count"]) ... pubmed 458 pmc 12779 mesh 1 ... ... ... biosample 7 biocollections 0
获取记录
Enterz 提供了一个特殊的方法 efetch 来搜索和下载 Entrez 中记录的完整详细信息。考虑以下简单示例 -
>>> handle = Entrez.efetch( db = "nucleotide", id = "EU490707", rettype = "fasta")
现在,我们可以简单地使用 SeqIO 对象读取记录
>>> record = SeqIO.read( handle, "fasta" )
>>> record
SeqRecord(seq = Seq('ATTTTTTACGAACCTGTGGAAATTTTTGGTTATGACAATAAATCTAGTTTAGTA...GAA',
SingleLetterAlphabet()), id = 'EU490707.1', name = 'EU490707.1',
description = 'EU490707.1
Selenipedium aequinoctiale maturase K (matK) gene, partial cds; chloroplast',
dbxrefs = [])
Biopython - PDB 模块
Biopython 提供 Bio.PDB 模块来处理多肽结构。PDB(蛋白质数据库)是可在线获取的最大蛋白质结构资源。它承载了许多不同的蛋白质结构,包括蛋白质-蛋白质、蛋白质-DNA、蛋白质-RNA 复合物。
为了加载 PDB,请键入以下命令 -
from Bio.PDB import *
蛋白质结构文件格式
PDB 以三种不同的格式分发蛋白质结构 -
- 基于 XML 的文件格式,Biopython 不支持该格式
- pdb 文件格式,这是一种特殊格式的文本文件
- PDBx/mmCIF 文件格式
蛋白质数据库分发的 PDB 文件可能包含格式错误,这些错误会使它们变得模棱两可或难以解析。Bio.PDB 模块尝试自动处理这些错误。
Bio.PDB 模块实现了两个不同的解析器,一个是 mmCIF 格式,另一个是 pdb 格式。
让我们详细了解如何解析每种格式 -
mmCIF 解析器
让我们使用以下命令从 pdb 服务器下载 mmCIF 格式的示例数据库 -
>>> pdbl = PDBList()
>>> pdbl.retrieve_pdb_file('2FAT', pdir = '.', file_format = 'mmCif')
这将从服务器下载指定的文件 (2fat.cif) 并将其存储在当前工作目录中。
这里,PDBList 提供了列出和下载来自在线 PDB FTP 服务器的文件的选项。retrieve_pdb_file 方法需要要下载的文件的名称,不带扩展名。retrieve_pdb_file 还可以选择指定下载目录 pdir 和文件格式 file_format。文件格式的可能值为:-
- “mmCif”(默认,PDBx/mmCif 文件)
- “pdb”(格式 PDB)
- “xml”(PMDML/XML 格式)
- “mmtf”(高度压缩)
- “bundle”(用于大型结构的 PDB 格式存档)
要加载 cif 文件,请使用 Bio.MMCIF.MMCIFParser,如下所示 -
>>> parser = MMCIFParser(QUIET = True)
>>> data = parser.get_structure("2FAT", "2FAT.cif")
这里,QUIET 在解析文件期间抑制警告。get_structure 将解析文件并返回结构,其 ID 为 2FAT(第一个参数)。
运行上述命令后,它将解析文件并打印可能的警告(如果可用)。
现在,使用以下命令检查结构 -
>>> data <Structure id = 2FAT> To get the type, use type method as specified below, >>> print(type(data)) <class 'Bio.PDB.Structure.Structure'>
我们已成功解析文件并获得了蛋白质的结构。我们将在后面的章节中学习蛋白质结构的详细信息以及如何获取它。
PDB 解析器
让我们使用以下命令从 pdb 服务器下载 PDB 格式的示例数据库 -
>>> pdbl = PDBList()
>>> pdbl.retrieve_pdb_file('2FAT', pdir = '.', file_format = 'pdb')
这将从服务器下载指定的文件 (pdb2fat.ent) 并将其存储在当前工作目录中。
要加载 pdb 文件,请使用 Bio.PDB.PDBParser,如下所示 -
>>> parser = PDBParser(PERMISSIVE = True, QUIET = True)
>>> data = parser.get_structure("2fat","pdb2fat.ent")
这里,get_structure 类似于 MMCIFParser。PERMISSIVE 选项尝试尽可能灵活地解析蛋白质数据。
现在,使用下面给出的代码片段检查结构及其类型 -
>>> data <Structure id = 2fat> >>> print(type(data)) <class 'Bio.PDB.Structure.Structure'>
好吧,标题结构存储字典信息。为此,请键入以下命令 -
>>> print(data.header.keys()) dict_keys([ 'name', 'head', 'deposition_date', 'release_date', 'structure_method', 'resolution', 'structure_reference', 'journal_reference', 'author', 'compound', 'source', 'keywords', 'journal']) >>>
要获取名称,请使用以下代码 -
>>> print(data.header["name"]) an anti-urokinase plasminogen activator receptor (upar) antibody: crystal structure and binding epitope >>>
您还可以使用以下代码检查日期和分辨率 -
>>> print(data.header["release_date"]) 2006-11-14 >>> print(data.header["resolution"]) 1.77
PDB 结构
PDB 结构由单个模型组成,包含两条链。
- 链 L,包含多个残基
- 链 H,包含多个残基
每个残基由多个原子组成,每个原子都有一个 3D 位置,由 (x、y、z) 坐标表示。
让我们在下一节中详细了解如何获取原子的结构 -
模型
Structure.get_models() 方法返回模型的迭代器。它定义如下 -
>>> model = data.get_models() >>> model <generator object get_models at 0x103fa1c80> >>> models = list(model) >>> models [<Model id = 0>] >>> type(models[0]) <class 'Bio.PDB.Model.Model'>
这里,Model 精确描述了一种 3D 构象。它包含一个或多个链。
链
Model.get_chain() 方法返回链的迭代器。它定义如下 -
>>> chains = list(models[0].get_chains()) >>> chains [<Chain id = L>, <Chain id = H>] >>> type(chains[0]) <class 'Bio.PDB.Chain.Chain'>
这里,Chain 描述了一个正确的多肽结构,即一系列连续结合的残基。
残基
Chain.get_residues() 方法返回残基的迭代器。它定义如下 -
>>> residue = list(chains[0].get_residues()) >>> len(residue) 293 >>> residue1 = list(chains[1].get_residues()) >>> len(residue1) 311
好吧,Residue 保存属于氨基酸的原子。
原子
Residue.get_atom() 返回原子的迭代器,定义如下 -
>>> atoms = list(residue[0].get_atoms()) >>> atoms [<Atom N>, <Atom CA>, <Atom C>, <Atom Ov, <Atom CB>, <Atom CG>, <Atom OD1>, <Atom OD2>]
原子保存原子的 3D 坐标,称为向量。它定义如下
>>> atoms[0].get_vector() <Vector 18.49, 73.26, 44.16>
它表示 x、y 和 z 坐标值。
Biopython - 基序对象
序列基序是核苷酸或氨基酸序列模式。序列基序由可能不相邻的氨基酸的三维排列形成。Biopython 提供了一个单独的模块 Bio.motifs 来访问序列基序的功能,如下所示 -
from Bio import motifs
创建简单的 DNA 基序
让我们使用以下命令创建一个简单的 DNA 基序序列 -
>>> from Bio import motifs
>>> from Bio.Seq import Seq
>>> DNA_motif = [ Seq("AGCT"),
... Seq("TCGA"),
... Seq("AACT"),
... ]
>>> seq = motifs.create(DNA_motif)
>>> print(seq) AGCT TCGA AACT
要计算序列值,请使用以下命令 -
>>> print(seq.counts)
0 1 2 3
A: 2.00 1.00 0.00 1.00
C: 0.00 1.00 2.00 0.00
G: 0.00 1.00 1.00 0.00
T: 1.00 0.00 0.00 2.00
使用以下代码计算序列中的“A” -
>>> seq.counts["A", :] (2, 1, 0, 1)
如果要访问计数列,请使用以下命令 -
>>> seq.counts[:, 3]
{'A': 1, 'C': 0, 'T': 2, 'G': 0}
创建序列标识
我们现在将讨论如何创建序列标识。
考虑以下序列 -
AGCTTACG ATCGTACC TTCCGAAT GGTACGTA AAGCTTGG
您可以使用以下链接创建自己的标识:http://weblogo.berkeley.edu/
添加上述序列并创建一个新的标识,并将名为 seq.png 的图像保存到您的 biopython 文件夹中。
seq.png
创建图像后,现在运行以下命令 -
>>> seq.weblogo("seq.png")
此 DNA 序列基序表示为 LexA 结合基序的序列标识。
JASPAR 数据库
JASPAR 是最流行的数据库之一。它为任何基序格式提供读取、写入和扫描序列的功能。它存储每个基序的元信息。Bio.motifs 模块包含一个专门的类 jaspar.Motif 来表示元信息属性。
它具有以下值得注意的属性类型 -
- matrix_id - 唯一的 JASPAR 基序 ID
- name - 基序的名称
- tf_family - 基序的家族,例如“螺旋-环-螺旋”
- data_type - 基序中使用的数据类型。
让我们在 biopython 文件夹中创建一个名为 sample.sites 的 JASPAR 站点格式。它定义如下 -
sample.sites >MA0001 ARNT 1 AACGTGatgtccta >MA0001 ARNT 2 CAGGTGggatgtac >MA0001 ARNT 3 TACGTAgctcatgc >MA0001 ARNT 4 AACGTGacagcgct >MA0001 ARNT 5 CACGTGcacgtcgt >MA0001 ARNT 6 cggcctCGCGTGc
在上面的文件中,我们创建了基序实例。现在,让我们从上述实例创建一个基序对象 -
>>> from Bio import motifs
>>> with open("sample.sites") as handle:
... data = motifs.read(handle,"sites")
...
>>> print(data)
TF name None
Matrix ID None
Matrix:
0 1 2 3 4 5
A: 2.00 5.00 0.00 0.00 0.00 1.00
C: 3.00 0.00 5.00 0.00 0.00 0.00
G: 0.00 1.00 1.00 6.00 0.00 5.00
T: 1.00 0.00 0.00 0.00 6.00 0.00
这里,data 从 sample.sites 文件读取所有基序实例。
要打印 data 中的所有实例,请使用以下命令 -
>>> for instance in data.instances: ... print(instance) ... AACGTG CAGGTG TACGTA AACGTG CACGTG CGCGTG
使用以下命令计算所有值 -
>>> print(data.counts)
0 1 2 3 4 5
A: 2.00 5.00 0.00 0.00 0.00 1.00
C: 3.00 0.00 5.00 0.00 0.00 0.00
G: 0.00 1.00 1.00 6.00 0.00 5.00
T: 1.00 0.00 0.00 0.00 6.00 0.00
>>>
Biopython - BioSQL 模块
BioSQL 是一种通用数据库模式,主要设计用于存储序列及其所有 RDBMS 引擎的相关数据。它的设计方式使其能够保存来自所有流行的生物信息学数据库(如 GenBank、Swissport 等)的数据。它也可以用于存储内部数据。
BioSQL 目前为以下数据库提供特定的模式 -
- MySQL (biosqldb-mysql.sql)
- PostgreSQL (biosqldb-pg.sql)
- Oracle (biosqldb-ora/*.sql)
- SQLite (biosqldb-sqlite.sql)
它还为基于 Java 的 HSQLDB 和 Derby 数据库提供最少的支持。
BioPython 提供非常简单、易用和高级的 ORM 功能来处理基于 BioSQL 的数据库。BioPython 提供了一个模块 BioSQL 来执行以下功能 -
- 创建/删除 BioSQL 数据库
- 连接到 BioSQL 数据库
- 解析序列数据库(如 GenBank、Swisport、BLAST 结果、Entrez 结果等),并将其直接加载到 BioSQL 数据库中
- 从 BioSQL 数据库中获取序列数据
- 从 NCBI BLAST 中获取分类数据并将其存储到 BioSQL 数据库中
- 对 BioSQL 数据库运行任何 SQL 查询
BioSQL 数据库模式概述
在深入了解 BioSQL 之前,让我们了解 BioSQL 模式的基础知识。BioSQL 模式提供 25 个以上的表来保存序列数据、序列特征、序列类别/本体和分类信息。一些重要的表如下 -
- biodatabase
- bioentry
- biosequence
- seqfeature
- taxon
- taxon_name
- antology
- term
- dxref
创建 BioSQL 数据库
在本节中,让我们使用 BioSQL 团队提供的模式创建一个示例 BioSQL 数据库 biosql。我们将使用 SQLite 数据库,因为它非常易于上手并且没有复杂的设置。
这里,我们将使用以下步骤创建一个基于 SQLite 的 BioSQL 数据库。
步骤 1 - 下载 SQLite 数据库引擎并安装它。
步骤 2 - 从 GitHub URL 下载 BioSQL 项目。https://github.com/biosql/biosql
步骤 3 - 打开控制台并使用 mkdir 创建一个目录并进入该目录。
cd /path/to/your/biopython/sample mkdir sqlite-biosql cd sqlite-biosql
步骤 4 - 运行以下命令以创建一个新的 SQLite 数据库。
> sqlite3.exe mybiosql.db SQLite version 3.25.2 2018-09-25 19:08:10 Enter ".help" for usage hints. sqlite>
步骤 5 - 从 BioSQL 项目复制 biosqldb-sqlite.sql 文件(/sql/biosqldb-sqlite.sql`)并将其存储在当前目录中。
步骤 6 - 运行以下命令以创建所有表。
sqlite> .read biosqldb-sqlite.sql
现在,所有表都已创建到我们的新数据库中。
步骤 7 - 运行以下命令以查看数据库中的所有新表。
sqlite> .headers on sqlite> .mode column sqlite> .separator ROW "\n" sqlite> SELECT name FROM sqlite_master WHERE type = 'table'; biodatabase taxon taxon_name ontology term term_synonym term_dbxref term_relationship term_relationship_term term_path bioentry bioentry_relationship bioentry_path biosequence dbxref dbxref_qualifier_value bioentry_dbxref reference bioentry_reference comment bioentry_qualifier_value seqfeature seqfeature_relationship seqfeature_path seqfeature_qualifier_value seqfeature_dbxref location location_qualifier_value sqlite>
前三个命令是配置命令,用于配置 SQLite 以格式化的方式显示结果。
步骤 8 - 将 BioPython 团队提供的示例 GenBank 文件 ls_orchid.gbk 复制到当前目录https://raw.githubusercontent.com/biopython/biopython/master/Doc/examples/ls_orchid.gbk并将其另存为 orchid.gbk。
步骤 9 - 使用以下代码创建一个 python 脚本 load_orchid.py 并执行它。
from Bio import SeqIO
from BioSQL import BioSeqDatabase
import os
server = BioSeqDatabase.open_database(driver = 'sqlite3', db = "orchid.db")
db = server.new_database("orchid")
count = db.load(SeqIO.parse("orchid.gbk", "gb"), True) server.commit()
server.close()
以上代码解析文件中的记录并将其转换为 python 对象,然后将其插入到 BioSQL 数据库中。我们将在后面的章节中分析代码。
最后,我们创建了一个新的 BioSQL 数据库并将一些示例数据加载到其中。我们将在下一章讨论重要的表。
简单的 ER 图
biodatabase 表位于层次结构的顶部,其主要目的是将一组序列数据组织到单个组/虚拟数据库中。biodatabase 中的每个条目都指的是一个单独的数据库,并且不会与其他数据库混合。BioSQL 数据库中的所有相关表都引用 biodatabase 条目。
bioentry 表保存序列的所有详细信息,但序列数据除外。特定bioentry的序列数据将存储在biosequence表中。
taxon 和 taxon_name 是分类详细信息,每个条目都引用此表以指定其分类信息。
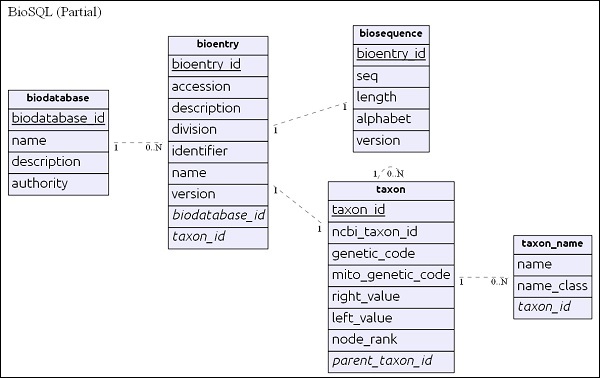
在了解了模式后,让我们在下一节中查看一些查询。
BioSQL 查询
让我们深入研究一些SQL查询,以便更好地理解数据是如何组织的以及表是如何相互关联的。在继续之前,让我们使用以下命令打开数据库并设置一些格式化命令:
> sqlite3 orchid.db SQLite version 3.25.2 2018-09-25 19:08:10 Enter ".help" for usage hints. sqlite> .header on sqlite> .mode columns
.header 和 .mode 是格式化选项,可以更好地可视化数据。您也可以使用任何SQLite编辑器来运行查询。
列出系统中可用的虚拟序列数据库,如下所示:
select * from biodatabase; *** Result *** sqlite> .width 15 15 15 15 sqlite> select * from biodatabase; biodatabase_id name authority description --------------- --------------- --------------- --------------- 1 orchid sqlite>
这里,我们只有一个数据库,orchid。
列出数据库orchid中可用的条目(前3个),使用以下代码
select
be.*,
bd.name
from
bioentry be
inner join
biodatabase bd
on bd.biodatabase_id = be.biodatabase_id
where
bd.name = 'orchid' Limit 1,
3;
*** Result ***
sqlite> .width 15 15 10 10 10 10 10 50 10 10
sqlite> select be.*, bd.name from bioentry be inner join biodatabase bd on
bd.biodatabase_id = be.biodatabase_id where bd.name = 'orchid' Limit 1,3;
bioentry_id biodatabase_id taxon_id name accession identifier division description version name
--------------- --------------- ---------- ---------- ---------- ---------- ----------
---------- ---------- ----------- ---------- --------- ---------- ----------
2 1 19 Z78532 Z78532 2765657 PLN
C.californicum 5.8S rRNA gene and ITS1 and ITS2 DN 1
orchid
3 1 20 Z78531 Z78531 2765656 PLN
C.fasciculatum 5.8S rRNA gene and ITS1 and ITS2 DN 1
orchid
4 1 21 Z78530 Z78530 2765655 PLN
C.margaritaceum 5.8S rRNA gene and ITS1 and ITS2 D 1
orchid
sqlite>
列出与一个条目(登录号 - Z78530,名称 - C. fasciculatum 5.8S rRNA基因和ITS1和ITS2 DNA)关联的序列详细信息,使用以下代码:
select
substr(cast(bs.seq as varchar), 0, 10) || '...' as seq,
bs.length,
be.accession,
be.description,
bd.name
from
biosequence bs
inner join
bioentry be
on be.bioentry_id = bs.bioentry_id
inner join
biodatabase bd
on bd.biodatabase_id = be.biodatabase_id
where
bd.name = 'orchid'
and be.accession = 'Z78532';
*** Result ***
sqlite> .width 15 5 10 50 10
sqlite> select substr(cast(bs.seq as varchar), 0, 10) || '...' as seq,
bs.length, be.accession, be.description, bd.name from biosequence bs inner
join bioentry be on be.bioentry_id = bs.bioentry_id inner join biodatabase bd
on bd.biodatabase_id = be.biodatabase_id where bd.name = 'orchid' and
be.accession = 'Z78532';
seq length accession description name
------------ ---------- ---------- ------------ ------------ ---------- ---------- -----------------
CGTAACAAG... 753 Z78532 C.californicum 5.8S rRNA gene and ITS1 and ITS2 DNA orchid
sqlite>
使用以下代码获取与一个条目(登录号 - Z78530,名称 - C. fasciculatum 5.8S rRNA基因和ITS1和ITS2 DNA)关联的完整序列:
select
bs.seq
from
biosequence bs
inner join
bioentry be
on be.bioentry_id = bs.bioentry_id
inner join
biodatabase bd
on bd.biodatabase_id = be.biodatabase_id
where
bd.name = 'orchid'
and be.accession = 'Z78532';
*** Result ***
sqlite> .width 1000
sqlite> select bs.seq from biosequence bs inner join bioentry be on
be.bioentry_id = bs.bioentry_id inner join biodatabase bd on bd.biodatabase_id =
be.biodatabase_id where bd.name = 'orchid' and be.accession = 'Z78532';
seq
----------------------------------------------------------------------------------------
----------------------------
CGTAACAAGGTTTCCGTAGGTGAACCTGCGGAAGGATCATTGTTGAGACAACAGAATATATGATCGAGTGAATCT
GGAGGACCTGTGGTAACTCAGCTCGTCGTGGCACTGCTTTTGTCGTGACCCTGCTTTGTTGTTGGGCCTCC
TCAAGAGCTTTCATGGCAGGTTTGAACTTTAGTACGGTGCAGTTTGCGCCAAGTCATATAAAGCATCACTGATGAATGACATTATTGT
CAGAAAAAATCAGAGGGGCAGTATGCTACTGAGCATGCCAGTGAATTTTTATGACTCTCGCAACGGATATCTTGGCTC
TAACATCGATGAAGAACGCAG
sqlite>
列出与生物数据库orchid相关的分类群
select distinct
tn.name
from
biodatabase d
inner join
bioentry e
on e.biodatabase_id = d.biodatabase_id
inner join
taxon t
on t.taxon_id = e.taxon_id
inner join
taxon_name tn
on tn.taxon_id = t.taxon_id
where
d.name = 'orchid' limit 10;
*** Result ***
sqlite> select distinct tn.name from biodatabase d inner join bioentry e on
e.biodatabase_id = d.biodatabase_id inner join taxon t on t.taxon_id =
e.taxon_id inner join taxon_name tn on tn.taxon_id = t.taxon_id where d.name =
'orchid' limit 10;
name
------------------------------
Cypripedium irapeanum
Cypripedium californicum
Cypripedium fasciculatum
Cypripedium margaritaceum
Cypripedium lichiangense
Cypripedium yatabeanum
Cypripedium guttatum
Cypripedium acaule
pink lady's slipper
Cypripedium formosanum
sqlite>
将数据加载到BioSQL数据库中
让我们在本节中学习如何将序列数据加载到BioSQL数据库中。我们已经在上一节中提供了将数据加载到数据库中的代码,代码如下:
from Bio import SeqIO
from BioSQL import BioSeqDatabase
import os
server = BioSeqDatabase.open_database(driver = 'sqlite3', db = "orchid.db")
DBSCHEMA = "biosqldb-sqlite.sql"
SQL_FILE = os.path.join(os.getcwd(), DBSCHEMA)
server.load_database_sql(SQL_FILE)
server.commit()
db = server.new_database("orchid")
count = db.load(SeqIO.parse("orchid.gbk", "gb"), True) server.commit()
server.close()
我们将深入了解代码的每一行及其用途:
第1行 - 加载SeqIO模块。
第2行 - 加载BioSeqDatabase模块。此模块提供与BioSQL数据库交互的所有功能。
第3行 - 加载os模块。
第5行 - open_database打开指定数据库(db),使用配置的驱动程序(driver),并返回到BioSQL数据库(server)的句柄。Biopython支持sqlite、mysql、postgresql和oracle数据库。
第6-10行 - load_database_sql方法加载外部文件中的sql并执行它。commit方法提交事务。我们可以跳过此步骤,因为我们已经创建了具有模式的数据库。
第12行 - new_database方法创建新的虚拟数据库orchid,并返回一个句柄db以针对orchid数据库执行命令。
第13行 - load方法将序列条目(可迭代的SeqRecord)加载到orchid数据库中。SqlIO.parse解析GenBank数据库,并将其中的所有序列作为可迭代的SeqRecord返回。load方法的第二个参数(True)指示它从NCBI blast网站获取序列数据的分类学详细信息,如果系统中尚不存在。
第14行 - commit提交事务。
第15行 - close关闭数据库连接并销毁服务器句柄。
获取序列数据
让我们从orchid数据库中获取标识符为2765658的序列,如下所示:
from BioSQL import BioSeqDatabase
server = BioSeqDatabase.open_database(driver = 'sqlite3', db = "orchid.db")
db = server["orchid"]
seq_record = db.lookup(gi = 2765658)
print(seq_record.id, seq_record.description[:50] + "...")
print("Sequence length %i," % len(seq_record.seq))
这里,server["orchid"]返回句柄以从虚拟数据库orchid中获取数据。lookup方法提供了一个根据条件选择序列的选项,我们选择了标识符为2765658的序列。lookup将序列信息作为SeqRecord对象返回。由于我们已经知道如何使用SeqRecord,因此很容易从中获取数据。
删除数据库
删除数据库就像使用正确的数据库名称调用remove_database方法然后提交它一样简单,如下所示:
from BioSQL import BioSeqDatabase
server = BioSeqDatabase.open_database(driver = 'sqlite3', db = "orchid.db")
server.remove_database("orchids")
server.commit()
Biopython - 群体遗传学
群体遗传学在进化理论中发挥着重要作用。它分析物种之间以及同一物种内两个或多个个体之间的遗传差异。
Biopython为群体遗传学提供了Bio.PopGen模块,主要支持`GenePop,这是Michel Raymond和Francois Rousset开发的一个流行的遗传学软件包。
一个简单的解析器
让我们编写一个简单的应用程序来解析GenePop格式并理解其概念。
下载Biopython团队在以下链接中提供的genePop文件:
https://raw.githubusercontent.com/biopython/biopython/master/Tests/PopGen/c3line.gen使用以下代码片段加载GenePop模块:
from Bio.PopGen import GenePop
使用GenePop.read方法解析文件,如下所示:
record = GenePop.read(open("c3line.gen"))
显示基因座和种群信息,如下所示:
>>> record.loci_list
['136255903', '136257048', '136257636']
>>> record.pop_list
['4', 'b3', '5']
>>> record.populations
[[('1', [(3, 3), (4, 4), (2, 2)]), ('2', [(3, 3), (3, 4), (2, 2)]),
('3', [(3, 3), (4, 4), (2, 2)]), ('4', [(3, 3), (4, 3), (None, None)])],
[('b1', [(None, None), (4, 4), (2, 2)]), ('b2', [(None, None), (4, 4), (2, 2)]),
('b3', [(None, None), (4, 4), (2, 2)])],
[('1', [(3, 3), (4, 4), (2, 2)]), ('2', [(3, 3), (1, 4), (2, 2)]),
('3', [(3, 2), (1, 1), (2, 2)]), ('4',
[(None, None), (4, 4), (2, 2)]), ('5', [(3, 3), (4, 4), (2, 2)])]]
>>>
这里,文件中存在三个基因座和三组种群:第一组种群有4条记录,第二组种群有3条记录,第三组种群有5条记录。record.populations显示所有种群集,每个基因座的等位基因数据。
操作GenePop文件
Biopython提供删除基因座和种群数据的选项。
按位置删除种群集,
>>> record.remove_population(0)
>>> record.populations
[[('b1', [(None, None), (4, 4), (2, 2)]),
('b2', [(None, None), (4, 4), (2, 2)]),
('b3', [(None, None), (4, 4), (2, 2)])],
[('1', [(3, 3), (4, 4), (2, 2)]),
('2', [(3, 3), (1, 4), (2, 2)]),
('3', [(3, 2), (1, 1), (2, 2)]),
('4', [(None, None), (4, 4), (2, 2)]),
('5', [(3, 3), (4, 4), (2, 2)])]]
>>>
按位置删除基因座,
>>> record.remove_locus_by_position(0)
>>> record.loci_list
['136257048', '136257636']
>>> record.populations
[[('b1', [(4, 4), (2, 2)]), ('b2', [(4, 4), (2, 2)]), ('b3', [(4, 4), (2, 2)])],
[('1', [(4, 4), (2, 2)]), ('2', [(1, 4), (2, 2)]),
('3', [(1, 1), (2, 2)]), ('4', [(4, 4), (2, 2)]), ('5', [(4, 4), (2, 2)])]]
>>>
按名称删除基因座,
>>> record.remove_locus_by_name('136257636') >>> record.loci_list
['136257048']
>>> record.populations
[[('b1', [(4, 4)]), ('b2', [(4, 4)]), ('b3', [(4, 4)])],
[('1', [(4, 4)]), ('2', [(1, 4)]),
('3', [(1, 1)]), ('4', [(4, 4)]), ('5', [(4, 4)])]]
>>>
与GenePop软件交互
Biopython提供与GenePop软件交互的接口,从而公开其中的许多功能。Bio.PopGen.GenePop模块用于此目的。一个易于使用的接口是EasyController。让我们检查如何解析GenePop文件并使用EasyController进行一些分析。
首先,安装GenePop软件并将安装文件夹放在系统路径中。要获取有关GenePop文件的基本信息,请创建一个EasyController对象,然后调用get_basic_info方法,如下所示:
>>> from Bio.PopGen.GenePop.EasyController import EasyController
>>> ec = EasyController('c3line.gen')
>>> print(ec.get_basic_info())
(['4', 'b3', '5'], ['136255903', '136257048', '136257636'])
>>>
这里,第一项是种群列表,第二项是基因座列表。
要获取特定基因座的所有等位基因列表,请通过传递基因座名称来调用get_alleles_all_pops方法,如下所示:
>>> allele_list = ec.get_alleles_all_pops("136255903")
>>> print(allele_list)
[2, 3]
要获取特定种群和基因座的等位基因列表,请通过传递基因座名称和种群位置来调用get_alleles方法,如下所示:
>>> allele_list = ec.get_alleles(0, "136255903") >>> print(allele_list) [] >>> allele_list = ec.get_alleles(1, "136255903") >>> print(allele_list) [] >>> allele_list = ec.get_alleles(2, "136255903") >>> print(allele_list) [2, 3] >>>
类似地,EasyController公开了许多功能:等位基因频率、基因型频率、多基因座F统计量、Hardy-Weinberg平衡、连锁不平衡等。
Biopython - 基因组分析
基因组是完整的DNA集,包括其所有基因。基因组分析是指研究单个基因及其在遗传中的作用。
基因组图
基因组图将遗传信息表示为图表。Biopython使用Bio.Graphics.GenomeDiagram模块来表示GenomeDiagram。GenomeDiagram模块需要安装ReportLab。
创建图表的步骤
创建图表的流程通常遵循以下简单模式:
为要显示的每个单独的特征集创建一个FeatureSet,并将Bio.SeqFeature对象添加到其中。
为要显示的每个图形创建一个GraphSet,并将图形数据添加到其中。
为图表上的每个轨道创建一个Track,并将GraphSets和FeatureSets添加到所需的轨道中。
创建一个Diagram,并将Tracks添加到其中。
告诉Diagram绘制图像。
将图像写入文件。
让我们以一个输入GenBank文件为例:
https://raw.githubusercontent.com/biopython/biopython/master/Doc/examples/ls_orchid.gbk 并从SeqRecord对象中读取记录,然后最终绘制基因组图。解释如下:
我们将首先导入所有模块,如下所示:
>>> from reportlab.lib import colors >>> from reportlab.lib.units import cm >>> from Bio.Graphics import GenomeDiagram
现在,导入SeqIO模块以读取数据:
>>> from Bio import SeqIO
record = SeqIO.read("example.gb", "genbank")
这里,record从genbank文件中读取序列。
现在,创建一个空图表以添加轨道和特征集:
>>> diagram = GenomeDiagram.Diagram( "Yersinia pestis biovar Microtus plasmid pPCP1") >>> track = diagram.new_track(1, name="Annotated Features") >>> feature = track.new_set()
现在,我们可以使用从绿色到灰色的备用颜色(如下定义)应用颜色主题更改:
>>> for feature in record.features: >>> if feature.type != "gene": >>> continue >>> if len(feature) % 2 == 0: >>> color = colors.blue >>> else: >>> color = colors.red >>> >>> feature.add_feature(feature, color=color, label=True)
现在您可以在屏幕上看到以下响应:
<Bio.Graphics.GenomeDiagram._Feature.Feature object at 0x105d3dc90> <Bio.Graphics.GenomeDiagram._Feature.Feature object at 0x105d3dfd0> <Bio.Graphics.GenomeDiagram._Feature.Feature object at 0x1007627d0> <Bio.Graphics.GenomeDiagram._Feature.Feature object at 0x105d57290> <Bio.Graphics.GenomeDiagram._Feature.Feature object at 0x105d57050> <Bio.Graphics.GenomeDiagram._Feature.Feature object at 0x105d57390> <Bio.Graphics.GenomeDiagram._Feature.Feature object at 0x105d57590> <Bio.Graphics.GenomeDiagram._Feature.Feature object at 0x105d57410> <Bio.Graphics.GenomeDiagram._Feature.Feature object at 0x105d57490> <Bio.Graphics.GenomeDiagram._Feature.Feature object at 0x105d574d0>
让我们为上述输入记录绘制一个图:
>>> diagram.draw(
format = "linear", orientation = "landscape", pagesize = 'A4',
... fragments = 4, start = 0, end = len(record))
>>> diagram.write("orchid.pdf", "PDF")
>>> diagram.write("orchid.eps", "EPS")
>>> diagram.write("orchid.svg", "SVG")
>>> diagram.write("orchid.png", "PNG")
执行上述命令后,您可以在Biopython目录中看到保存的以下图像。
** Result ** genome.png
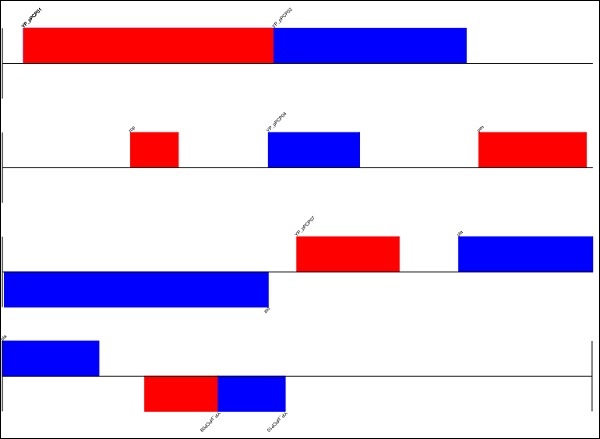
您还可以通过进行以下更改以圆形格式绘制图像:
>>> diagram.draw(
format = "circular", circular = True, pagesize = (20*cm,20*cm),
... start = 0, end = len(record), circle_core = 0.7)
>>> diagram.write("circular.pdf", "PDF")
染色体概述
DNA分子被包装成称为染色体的线状结构。每条染色体都由DNA组成,DNA紧密缠绕在称为组蛋白的蛋白质周围多次,这些蛋白质支撑着它的结构。
当细胞不分裂时,染色体在细胞核中不可见——甚至在显微镜下也看不到。但是,构成染色体的DNA在细胞分裂过程中会变得更加紧密地包装,然后可以在显微镜下看到。
在人类中,每个细胞通常包含23对染色体,总共46条。其中22对称为常染色体,在男性和女性中看起来相同。第23对,性染色体,在男性和女性之间有所不同。女性有两条X染色体的拷贝,而男性有一条X染色体和一条Y染色体。
Biopython - 表型微阵列
表型被定义为生物体针对特定化学物质或环境表现出的可观察特征或性状。表型微阵列同时测量生物体对大量化学物质和环境的反应,并分析数据以了解基因突变、基因特征等。
Biopython提供了一个优秀的模块Bio.Phenotype来分析表型数据。让我们在本节中学习如何解析、内插、提取和分析表型微阵列数据。
解析
表型微阵列数据可以采用两种格式:CSV和JSON。Biopython支持这两种格式。Biopython解析器解析表型微阵列数据并将其作为PlateRecord对象的集合返回。每个PlateRecord对象包含WellRecord对象的集合。每个WellRecord对象以8行12列的格式保存数据。八行由A到H表示,十二列由01到12表示。例如,第4行和第6列由D06表示。
让我们通过以下示例了解格式和解析的概念:
步骤1 - 下载Biopython团队提供的Plates.csv文件:https://raw.githubusercontent.com/biopython/biopython/master/Doc/examples/Plates.csv
步骤2 - 如下加载phenotpe模块:
>>> from Bio import phenotype
步骤3 - 调用phenotype.parse方法,传递数据文件和格式选项(“pm-csv”)。它返回可迭代的PlateRecord,如下所示:
>>> plates = list(phenotype.parse('Plates.csv', "pm-csv"))
>>> plates
[PlateRecord('WellRecord['A01'], WellRecord['A02'], WellRecord['A03'], ..., WellRecord['H12']'),
PlateRecord('WellRecord['A01'], WellRecord['A02'], WellRecord['A03'], ..., WellRecord['H12']'),
PlateRecord('WellRecord['A01'], WellRecord['A02'], WellRecord['A03'], ..., WellRecord['H12']'),
PlateRecord('WellRecord['A01'], WellRecord['A02'],WellRecord['A03'], ..., WellRecord['H12']')]
>>>
步骤4 - 从列表中访问第一个板,如下所示:
>>> plate = plates[0]
>>> plate
PlateRecord('WellRecord['A01'], WellRecord['A02'], WellRecord['A03'], ...,
WellRecord['H12']')
>>>
步骤5 - 如前所述,一个板包含8行,每行有12个项目。可以以两种方式访问WellRecord,如下所示:
>>> well = plate["A04"]
>>> well = plate[0, 4]
>>> well WellRecord('(0.0, 0.0), (0.25, 0.0), (0.5, 0.0), (0.75, 0.0),
(1.0, 0.0), ..., (71.75, 388.0)')
>>>
步骤6 - 每个孔将在不同的时间点具有一系列测量值,并且可以使用for循环访问,如下所示:
>>> for v1, v2 in well: ... print(v1, v2) ... 0.0 0.0 0.25 0.0 0.5 0.0 0.75 0.0 1.0 0.0 ... 71.25 388.0 71.5 388.0 71.75 388.0 >>>
插值
插值可以更深入地了解数据。Biopython提供方法来插值WellRecord数据,以获取中间时间点的信息。语法类似于列表索引,因此易于学习。
要获取20.1小时的数据,只需将索引值传递如下所示:
>>> well[20.10] 69.40000000000003 >>>
我们也可以传递开始时间点和结束时间点,如下所示:
>>> well[20:30] [67.0, 84.0, 102.0, 119.0, 135.0, 147.0, 158.0, 168.0, 179.0, 186.0] >>>
以上命令将数据从 20 小时插值到 30 小时,时间间隔为 1 小时。默认情况下,时间间隔为 1 小时,我们可以将其更改为任何值。例如,让我们指定如下所示的 15 分钟(0.25 小时)间隔:
>>> well[20:21:0.25] [67.0, 73.0, 75.0, 81.0] >>>
分析和提取
Biopython 提供了一种 fit 方法,可以使用 Gompertz、Logistic 和 Richards S 型函数分析 WellRecord 数据。默认情况下,fit 方法使用 Gompertz 函数。我们需要调用 WellRecord 对象的 fit 方法来完成此任务。代码如下:
>>> well.fit() Traceback (most recent call last): ... Bio.MissingPythonDependencyError: Install scipy to extract curve parameters. >>> well.model >>> getattr(well, 'min') 0.0 >>> getattr(well, 'max') 388.0 >>> getattr(well, 'average_height') 205.42708333333334 >>>
Biopython 依赖于 scipy 模块进行高级分析。它将计算最小值、最大值和平均高度详细信息,而无需使用 scipy 模块。
Biopython - 绘图
本章介绍如何绘制序列图。在进入这个主题之前,让我们先了解绘图的基本知识。
绘图
Matplotlib 是一个 Python 绘图库,它可以生成各种格式的高质量图形。我们可以创建不同类型的绘图,例如折线图、直方图、条形图、饼图、散点图等。
pyLab 是属于 matplotlib 的一个模块,它将数值模块 numpy 与图形绘图模块 pyplot 相结合。Biopython 使用 pylab 模块绘制序列图。为此,我们需要导入以下代码:
import pylab
在导入之前,我们需要使用以下命令使用 pip 命令安装 matplotlib 包:
pip install matplotlib
示例输入文件
在您的 Biopython 目录中创建一个名为 plot.fasta 的示例文件,并添加以下更改:
>seq0 FQTWEEFSRAAEKLYLADPMKVRVVLKYRHVDGNLCIKVTDDLVCLVYRTDQAQDVKKIEKF >seq1 KYRTWEEFTRAAEKLYQADPMKVRVVLKYRHCDGNLCIKVTDDVVCLLYRTDQAQDVKKIEKFHSQLMRLME >seq2 EEYQTWEEFARAAEKLYLTDPMKVRVVLKYRHCDGNLCMKVTDDAVCLQYKTDQAQDVKKVEKLHGK >seq3 MYQVWEEFSRAVEKLYLTDPMKVRVVLKYRHCDGNLCIKVTDNSVCLQYKTDQAQDV >seq4 EEFSRAVEKLYLTDPMKVRVVLKYRHCDGNLCIKVTDNSVVSYEMRLFGVQKDNFALEHSLL >seq5 SWEEFAKAAEVLYLEDPMKCRMCTKYRHVDHKLVVKLTDNHTVLKYVTDMAQDVKKIEKLTTLLMR >seq6 FTNWEEFAKAAERLHSANPEKCRFVTKYNHTKGELVLKLTDDVVCLQYSTNQLQDVKKLEKLSSTLLRSI >seq7 SWEEFVERSVQLFRGDPNATRYVMKYRHCEGKLVLKVTDDRECLKFKTDQAQDAKKMEKLNNIFF >seq8 SWDEFVDRSVQLFRADPESTRYVMKYRHCDGKLVLKVTDNKECLKFKTDQAQEAKKMEKLNNIFFTLM >seq9 KNWEDFEIAAENMYMANPQNCRYTMKYVHSKGHILLKMSDNVKCVQYRAENMPDLKK >seq10 FDSWDEFVSKSVELFRNHPDTTRYVVKYRHCEGKLVLKVTDNHECLKFKTDQAQDAKKMEK
折线图
现在,让我们为上述 fasta 文件创建一个简单的折线图。
步骤 1 - 导入 SeqIO 模块以读取 fasta 文件。
>>> from Bio import SeqIO
步骤 2 - 解析输入文件。
>>> records = [len(rec) for rec in SeqIO.parse("plot.fasta", "fasta")]
>>> len(records)
11
>>> max(records)
72
>>> min(records)
57
步骤 3 - 让我们导入 pylab 模块。
>>> import pylab
步骤 4 - 通过分配 x 轴和 y 轴标签来配置折线图。
>>> pylab.xlabel("sequence length")
Text(0.5, 0, 'sequence length')
>>> pylab.ylabel("count")
Text(0, 0.5, 'count')
>>>
步骤 5 - 通过设置网格显示来配置折线图。
>>> pylab.grid()
步骤 6 - 通过调用 plot 方法并将记录作为输入来绘制简单的折线图。
>>> pylab.plot(records) [<matplotlib.lines.Line2D object at 0x10b6869d 0>]
步骤 7 - 最后使用以下命令保存图表。
>>> pylab.savefig("lines.png")
结果
执行上述命令后,您可以在Biopython目录中看到保存的以下图像。
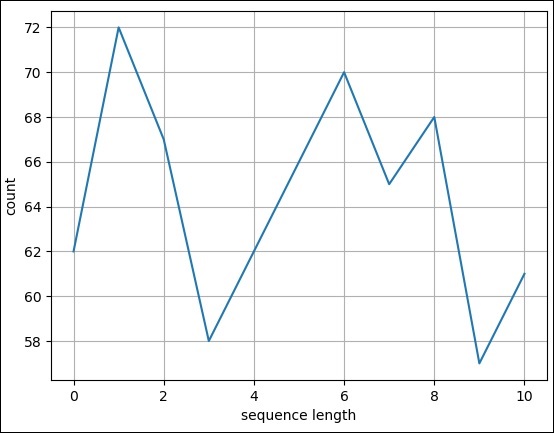
直方图
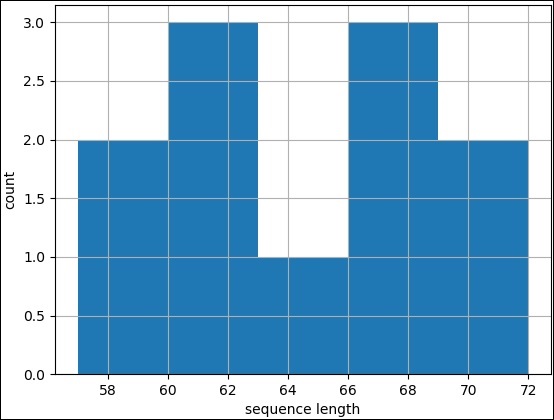
直方图用于连续数据,其中 bin 表示数据范围。绘制直方图与折线图相同,只是使用 pylab.hist 而不是 pylab.plot。改为调用 pylab 模块的 hist 方法,并使用记录和一些自定义 bin 值(5)。完整的代码如下:
步骤 1 - 导入 SeqIO 模块以读取 fasta 文件。
>>> from Bio import SeqIO
步骤 2 - 解析输入文件。
>>> records = [len(rec) for rec in SeqIO.parse("plot.fasta", "fasta")]
>>> len(records)
11
>>> max(records)
72
>>> min(records)
57
步骤 3 - 让我们导入 pylab 模块。
>>> import pylab
步骤 4 - 通过分配 x 轴和 y 轴标签来配置折线图。
>>> pylab.xlabel("sequence length")
Text(0.5, 0, 'sequence length')
>>> pylab.ylabel("count")
Text(0, 0.5, 'count')
>>>
步骤 5 - 通过设置网格显示来配置折线图。
>>> pylab.grid()
步骤 6 - 通过调用 plot 方法并将记录作为输入来绘制简单的折线图。
>>> pylab.hist(records,bins=5) (array([2., 3., 1., 3., 2.]), array([57., 60., 63., 66., 69., 72.]), <a list of 5 Patch objects>) >>>
步骤 7 - 最后使用以下命令保存图表。
>>> pylab.savefig("hist.png")
结果
执行上述命令后,您可以在Biopython目录中看到保存的以下图像。
序列中的 GC 百分比
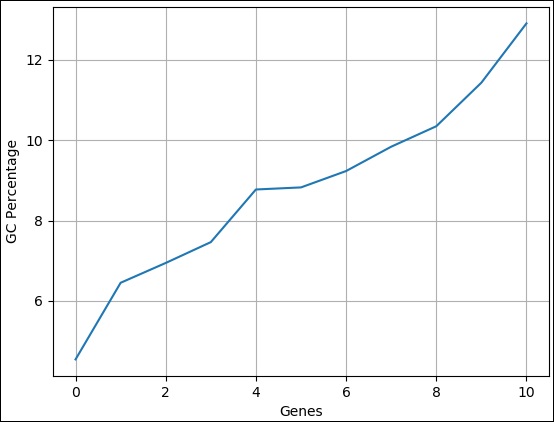
GC 百分比是用于比较不同序列的常用分析数据之一。我们可以使用一组序列的 GC 百分比创建一个简单的折线图,并立即进行比较。在这里,我们可以将数据从序列长度更改为 GC 百分比。完整的代码如下:
步骤 1 - 导入 SeqIO 模块以读取 fasta 文件。
>>> from Bio import SeqIO
步骤 2 - 解析输入文件。
>>> from Bio.SeqUtils import GC
>>> gc = sorted(GC(rec.seq) for rec in SeqIO.parse("plot.fasta", "fasta"))
步骤 3 - 让我们导入 pylab 模块。
>>> import pylab
步骤 4 - 通过分配 x 轴和 y 轴标签来配置折线图。
>>> pylab.xlabel("Genes")
Text(0.5, 0, 'Genes')
>>> pylab.ylabel("GC Percentage")
Text(0, 0.5, 'GC Percentage')
>>>
步骤 5 - 通过设置网格显示来配置折线图。
>>> pylab.grid()
步骤 6 - 通过调用 plot 方法并将记录作为输入来绘制简单的折线图。
>>> pylab.plot(gc) [<matplotlib.lines.Line2D object at 0x10b6869d 0>]
步骤 7 - 最后使用以下命令保存图表。
>>> pylab.savefig("gc.png")
结果
执行上述命令后,您可以在Biopython目录中看到保存的以下图像。
Biopython - 聚类分析
通常,聚类分析是将一组对象分组到同一组中。这个概念主要用于数据挖掘、统计数据分析、机器学习、模式识别、图像分析、生物信息学等。它可以通过各种算法来实现,以了解聚类在不同分析中的广泛应用。
根据生物信息学,聚类分析主要用于基因表达数据分析,以查找具有相似基因表达的基因组。
在本章中,我们将检查 Biopython 中重要的算法,以了解在真实数据集上进行聚类的基础知识。
Biopython 使用 Bio.Cluster 模块来实现所有算法。它支持以下算法:
- 层次聚类
- K 均值聚类
- 自组织映射
- 主成分分析
让我们简要介绍一下上述算法。
层次聚类
层次聚类用于通过距离度量将每个节点与其最近的邻居连接起来并创建一个聚类。Bio.Cluster 节点具有三个属性:left、right 和 distance。让我们创建一个简单的聚类,如下所示:
>>> from Bio.Cluster import Node >>> n = Node(1,10) >>> n.left = 11 >>> n.right = 0 >>> n.distance = 1 >>> print(n) (11, 0): 1
如果要构建基于树的聚类,请使用以下命令:
>>> n1 = [Node(1, 2, 0.2), Node(0, -1, 0.5)] >>> n1_tree = Tree(n1) >>> print(n1_tree) (1, 2): 0.2 (0, -1): 0.5 >>> print(n1_tree[0]) (1, 2): 0.2
让我们使用 Bio.Cluster 模块执行层次聚类。
假设距离是在一个数组中定义的。
>>> import numpy as np >>> distance = array([[1,2,3],[4,5,6],[3,5,7]])
现在将距离数组添加到树状聚类中。
>>> from Bio.Cluster import treecluster >>> cluster = treecluster(distance) >>> print(cluster) (2, 1): 0.666667 (-1, 0): 9.66667
上述函数返回一个 Tree 聚类对象。此对象包含节点,其中项目数被聚类为行或列。
K 均值聚类
这是一种分区算法,分为 k 均值、中位数和中心点聚类。让我们简要了解每种聚类。
K 均值聚类
这种方法在数据挖掘中很流行。该算法的目标是在数据中查找组,其中组数由变量 K 表示。
该算法迭代地将每个数据点分配到 K 个组中的一个,这基于提供的特征。数据点根据特征相似性进行聚类。
>>> from Bio.Cluster import kcluster >>> from numpy import array >>> data = array([[1, 2], [3, 4], [5, 6]]) >>> clusterid, error,found = kcluster(data) >>> print(clusterid) [0 0 1] >>> print(found) 1
K 中位数聚类
这是另一种聚类算法,它计算每个聚类的均值以确定其质心。
K 中心点聚类
这种方法基于给定的一组项目,使用用户传递的距离矩阵和聚类数。
假设距离矩阵定义如下:
>>> distance = array([[1,2,3],[4,5,6],[3,5,7]])
我们可以使用以下命令计算 k 中心点聚类:
>>> from Bio.Cluster import kmedoids >>> clusterid, error, found = kmedoids(distance)
让我们考虑一个例子。
kcluster 函数将数据矩阵作为输入,而不是 Seq 实例。您需要将序列转换为矩阵并将其提供给 kcluster 函数。
将数据转换为仅包含数值元素的矩阵的一种方法是使用 numpy.fromstring 函数。它基本上将序列中的每个字母转换为其 ASCII 对应项。
这将创建一个编码序列的二维数组,kcluster 函数识别该数组并使用它来对序列进行聚类。
>>> from Bio.Cluster import kcluster >>> import numpy as np >>> sequence = [ 'AGCT','CGTA','AAGT','TCCG'] >>> matrix = np.asarray([np.fromstring(s, dtype=np.uint8) for s in sequence]) >>> clusterid,error,found = kcluster(matrix) >>> print(clusterid) [1 0 0 1]
自组织映射
这种方法是一种人工神经网络。它由 Kohonen 开发,通常称为 Kohonen 映射。它根据矩形拓扑将项目组织成聚类。
让我们使用与以下相同的数组距离创建一个简单的聚类:
>>> from Bio.Cluster import somcluster >>> from numpy import array >>> data = array([[1, 2], [3, 4], [5, 6]]) >>> clusterid,map = somcluster(data) >>> print(map) [[[-1.36032469 0.38667395]] [[-0.41170578 1.35295911]]] >>> print(clusterid) [[1 0] [1 0] [1 0]]
这里,clusterid 是一个有两列的数组,其中行数等于聚类的项目数,而 data 是一个维度为行或列的数组。
主成分分析
主成分分析可用于可视化高维数据。这是一种使用来自线性代数和统计学的简单矩阵运算来计算原始数据投影到相同数量或更少维度的方法。
主成分分析返回一个元组 columnmean、coordinates、components 和 eigenvalues。让我们了解一下这个概念的基本知识。
>>> from numpy import array >>> from numpy import mean >>> from numpy import cov >>> from numpy.linalg import eig # define a matrix >>> A = array([[1, 2], [3, 4], [5, 6]]) >>> print(A) [[1 2] [3 4] [5 6]] # calculate the mean of each column >>> M = mean(A.T, axis = 1) >>> print(M) [ 3. 4.] # center columns by subtracting column means >>> C = A - M >>> print(C) [[-2. -2.] [ 0. 0.] [ 2. 2.]] # calculate covariance matrix of centered matrix >>> V = cov(C.T) >>> print(V) [[ 4. 4.] [ 4. 4.]] # eigendecomposition of covariance matrix >>> values, vectors = eig(V) >>> print(vectors) [[ 0.70710678 -0.70710678] [ 0.70710678 0.70710678]] >>> print(values) [ 8. 0.]
让我们将相同的矩形矩阵数据应用于 Bio.Cluster 模块,如下所示:
>>> from Bio.Cluster import pca >>> from numpy import array >>> data = array([[1, 2], [3, 4], [5, 6]]) >>> columnmean, coordinates, components, eigenvalues = pca(data) >>> print(columnmean) [ 3. 4.] >>> print(coordinates) [[-2.82842712 0. ] [ 0. 0. ] [ 2.82842712 0. ]] >>> print(components) [[ 0.70710678 0.70710678] [ 0.70710678 -0.70710678]] >>> print(eigenvalues) [ 4. 0.]
Biopython - 机器学习
生物信息学是应用机器学习算法的极佳领域。在这里,我们拥有大量生物体的遗传信息,不可能手动分析所有这些信息。如果使用合适的机器学习算法,我们可以从这些数据中提取大量有用的信息。Biopython 提供了一套有用的算法来进行监督式机器学习。
监督学习基于输入变量 (X) 和输出变量 (Y)。它使用一种算法来学习从输入到输出的映射函数。它定义如下:
Y = f(X)
这种方法的主要目标是近似映射函数,当您有新的输入数据 (x) 时,您可以预测该数据的输出变量 (Y)。
逻辑回归模型
逻辑回归是一种监督式机器学习算法。它用于使用预测变量的加权和找出 K 个类别之间的差异。它计算事件发生的概率,可用于癌症检测。
Biopython 提供 Bio.LogisticRegression 模块来根据逻辑回归算法预测变量。目前,Biopython 仅实现了用于两个类别的逻辑回归算法 (K = 2)。
K 近邻
K 近邻也是一种监督式机器学习算法。它通过根据最近邻对数据进行分类来工作。Biopython 提供 Bio.KNN 模块来根据 k 近邻算法预测变量。
朴素贝叶斯
朴素贝叶斯分类器是一组基于贝叶斯定理的分类算法。它不是单个算法,而是一系列算法,它们都共享一个共同的原则,即要分类的每对特征彼此独立。Biopython 提供 Bio.NaiveBayes 模块来使用朴素贝叶斯算法。
马尔可夫模型
马尔可夫模型是一个数学系统,定义为一组随机变量,根据某些概率规则经历从一个状态到另一个状态的转换。Biopython 提供 Bio.MarkovModel 和 Bio.HMM.MarkovModel 模块来使用马尔可夫模型。
Biopython - 测试技术
Biopython 拥有广泛的测试脚本,用于在不同条件下测试软件,以确保软件没有错误。要运行测试脚本,请下载 Biopython 的源代码,然后运行以下命令:
python run_tests.py
这将运行所有测试脚本并给出以下输出:
Python version: 2.7.12 (v2.7.12:d33e0cf91556, Jun 26 2016, 12:10:39) [GCC 4.2.1 (Apple Inc. build 5666) (dot 3)] Operating system: posix darwin test_Ace ... ok test_Affy ... ok test_AlignIO ... ok test_AlignIO_ClustalIO ... ok test_AlignIO_EmbossIO ... ok test_AlignIO_FastaIO ... ok test_AlignIO_MauveIO ... ok test_AlignIO_PhylipIO ... ok test_AlignIO_convert ... ok ........................................... ...........................................
我们还可以运行指定的单个测试脚本,如下所示:
python test_AlignIO.py
结论
正如我们所学到的,Biopython 是生物信息学领域的重要软件之一。它用 Python 编写(易于学习和编写),提供了广泛的功能来处理生物信息学领域中的任何计算和操作。它还为几乎所有流行的生物信息学软件提供了简单灵活的接口,以利用其功能。