
 数据结构
数据结构 网络
网络 关系型数据库管理系统
关系型数据库管理系统 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C语言编程
C语言编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP星型模式设计组件及分析
星型模式设计是一种用于数据仓库的数据库模式类型,旨在提高对大型数据集的查询和分析效率。该模式包含一个中心的事实表,其中包含要分析的数据,以及一个或多个维度表,这些维度表提供有关事实表中数据的其他信息。
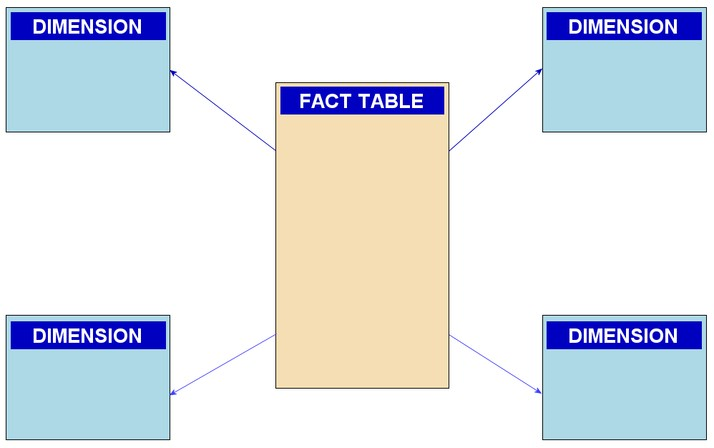
星型模式的组件
星型模式由四个主要组件组成。如下所示 -
事实表
维度表
属性
属性层次结构
让我们逐一了解它们 -
事实
这些是货币值。
表示业务活动的绩效指标。
例如,生产力、成本、销售额、利润、定价和数量。
事实也称为度量。它们保存在事实表中。
文本保存在维度表中,数值存储在事实表中。数值提供了公司绩效的统计度量。在书面描述销售时,销售统计数据更容易理解,而用文字描述则较为繁琐。事实有时也称为度量,因为它们用于衡量公司的成功。
事实表到底是什么?
事实表也称为详细表。
事实表是星型模式的中心点。
事实表提供主键以及事实或度量。
事实表由事实和键组成。这些是公司的最重要方面。事实表,也称为详细表,显示了公司绩效的概述。它始终位于星型模式的中心或中心位置。它周围环绕着度量表。它还包含事实表的主键。
示例
假设我们有一家零售店向客户销售产品,并且我们希望在数据仓库中跟踪销售数据。我们可以创建一个星型模式,其中包含一个名为“销售”的事实表,用于跟踪每次销售的信息 -
销售事实表
列名 |
数据类型 |
描述 |
|---|---|---|
sale_id |
整数 |
每次销售的唯一标识符 |
customer_id |
整数 |
引用客户维度表的外键 |
product_id |
整数 |
引用产品维度表的外键 |
store_id |
整数 |
引用商店维度表的外键 |
sale_date |
日期 |
销售日期 |
quantity |
整数 |
销售数量 |
total_price |
十进制 |
销售总价 |
在此示例中,“销售”事实表包含每次销售的唯一标识符,以及引用客户、产品和商店维度表的外键。事实表还包含有关销售日期、销售产品数量和销售总价的信息。此表可用于按客户、产品、商店和日期分析销售数据,以及跨不同维度汇总销售数据。
事实表特征
事实表定期通过插入来自运营数据库的聚合数据来刷新。
度量是在查询执行期间计算的事实。
每个事实表都包含维度表。
事实表有助于数据汇总。
至少包含一个事实或度量。
主键 - 所有维度表主键的并集。
维度表从不处于BCNF,但事实表处于。
事实表中的一行至少包含一个事实以及其维度表的主键。
度量有三种类型:可加性、半可加性和不可加性。
具有少量列和大量行,这些行相对较长且窄。
事实表中单个条目中信息的量称为事实表的粒度。
最有价值的事实是数值的、持续评估的和可加的。
事实表最常见的特征之一是销售额。因此,此值必须定期更新,例如每月或每季度更新一次。在星型模式中,维度表围绕核心事实表。事实表必须始终至少包含一个事实;否则,它就不存在。它不包含代理键;而是由所有维度表的主键的并集形成事实表的主键。事实表始终处于规范化的BCNF形式。由于事实表包含主键并且只有少量事实,因此它具有较少的属性但大量的行。如果销售额每天更新一次,则事实表的粒度为一天。
维度表到底是什么?
维度表提供主键以及仅在决策过程中使用的特征。
例如,产品维度、位置维度和时间维度。
主键到外键连接将维度表连接到事实表。
维度表提供过滤和分组。
维度通常是限定为事实的描述性数据。
顾名思义,维度表包含业务实体的支持特征。每个维度表都具有主键和必需的属性。客户表是一种维度表。外键连接将每个维度表连接到事实表。
示例
假设我们有一家零售店向客户销售产品,并且我们希望在数据仓库中跟踪有关产品的信息。我们可以创建一个星型模式,其中包含一个名为“产品”的维度表,其中包含有关每个产品的信息 -
产品维度表
列名 |
数据类型 |
描述 |
|---|---|---|
product_id |
整数 |
每个产品的唯一标识符 |
product_name |
可变字符 |
产品名称 |
category |
可变字符 |
产品所属的类别 |
price |
十进制 |
产品价格 |
supplier_id |
整数 |
引用供应商维度表的外键 |
brand_id |
整数 |
引用品牌维度表的外键 |
在此示例中,“产品”维度表包含每个产品的唯一标识符,以及有关产品名称、类别、价格以及引用供应商和品牌维度表的外键的信息。此表可用于按类别、价格范围、供应商和品牌分析产品信息,以及跨不同维度汇总产品信息。
维度表特征包括
维度表通常称为查找表或参考表。
维度表未被规范化。
包含一个主键,它是事实表主键的一部分。
维度不会随着时间的推移而改变或变化非常缓慢。
它们具有少量行和大量列。
大多数星型模式都包含一个时间维度。
维度表不会相互连接;而是每个维度表都通过 PK-FK 联接连接到事实表。
代理键通常是主键。
这些被称为参考表,因为它们支持事实表中提供的信息。事实表显示了公司实体的摘要,而维度表则为事实表提供支持。维度表未被规范化,因为这样做会导致维度表被拆分为多个表。这将增加模式中联接的数量,使星型查询变得更加困难,并且执行时间更长。维度表连接到事实表,但不会相互连接,因为这是不必要的。为每个维度表引入了代理键以唯一标识每个条目。
属性是什么?
这些是维度表的列。
客户维度表示例包括客户姓名、年龄、性别、婚姻状况等。
这些大多是描述性值。
列名称为属性。在客户表中,客户特征是将恰当定义客户的详细信息。客户特征包括其姓名、性别、年龄和婚姻状况。通常,它们是描述性数据,例如姓名和地址。
假设我们有一家零售店向客户销售产品,并且我们希望在数据仓库中跟踪有关客户的信息。我们可以创建一个星型模式,其中包含一个名为“客户”的维度表,其中包含有关每个客户的属性 -
客户维度表 -
列名 |
数据类型 |
描述 |
|---|---|---|
customer_id |
整数 |
每个客户的唯一标识符 |
first_name |
可变字符 |
客户名 |
last_name |
可变字符 |
客户姓 |
gender |
可变字符 |
客户性别 |
date_of_birth |
日期 |
客户出生日期 |
可变字符 |
客户电子邮件地址 |
|
address |
可变字符 |
客户街道地址 |
city |
可变字符 |
客户居住的城市 |
state |
可变字符 |
客户居住的州 |
country |
可变字符 |
客户居住的国家 |
在此示例中,“客户”维度表包含每个客户的唯一标识符,以及客户姓名、性别、出生日期、电子邮件地址和地址信息等属性。此表可用于按人口统计特征、位置和购买历史分析客户信息,以及跨不同维度汇总客户信息。
属性层次结构到底是什么?
属性可以组织成层次结构。
层次结构级别具有 N:1 关系。
确定功能依赖序列。
示例 - 产品->产品类型,产品类型->行业
时间维度的层次结构 - 日期->周->月->季度->年。
位置的层次结构 - 城市->地区->州->国家->商店
属性层次结构用于在多个聚合级别分析数据,通常从最高级别开始。
某些维度表列仅用于维度描述,并未用于属性层次结构。
当我们需要更细粒度或更粗粒度的信息时,属性层次结构就派上用场了。我们可以找到特定季度的总销售额。如果存在时间层次结构,我们可以检索同一季度特定月份发生的销售额。如果我们进一步深入层次结构,我们可以确定该月在特定一周的总销售额。同样,我们可以向上遍历结构。并非所有维度表都需要属性层次结构。
数据聚合的多种方法有哪些?
数据层次结构由属性层次结构定义。
向上汇总 - 获取更粗粒度或层次结构中更高级别的数据。
向下钻取 - 获取更细粒度的数据。
星型查询到底是什么?
星型查询是事实表和多个维度表之间的连接。
这些问题确实很难。
完成需要很长时间。
星型查询是在星型模式上运行的 SQL 查询。星型查询的名称来源于我们是在星型模式上运行查询的事实。因为星型模式在事实和维度列之间有多个连接,所以星型查询很困难。由于多个连接关系,星型查询的执行需要数小时。
结论
总之,星型模式设计是为数据仓库中的分析建模数据的一种有效方法。该模式包含一个中心事实表,其中包含要分析的定量数据,以及一个或多个维度表,这些表提供有关事实表中数据的其他上下文和描述性数据。事实表使用外键链接到维度表,从而能够跨不同维度和属性执行查询和分析。星型模式设计的分析涉及通过维度表中各种维度和属性聚合和查询事实表中的数据,以生成提供数据洞察的报表和可视化。使用星型模式设计的优势包括更快的查询性能、简化的数据建模以及易于最终用户使用。

203 次查看
