
 数据结构
数据结构 网络
网络 关系数据库管理系统 (RDBMS)
关系数据库管理系统 (RDBMS) 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C语言编程
C语言编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHPApache Spark 组件
Apache Spark 是一个复杂的计算系统。它提供用 Python、Scala 和 Java 等编程语言编写的更高级别的 API。在 Spark 中编写并行作业很容易。它提供对数据的通用且更快的处理。它是用 Scala 编写的,比其他系统更快。它用于处理大量数据集。它现在是最受关注的 Apache 项目。其关键特性是内存中复杂计算,这提高了数据处理速度。它的一些主要特性包括:多语言支持、平台独立性、高速、现代分析和通用性。
现在,我们了解了 Apache Spark 的一些重要特性,让我们更深入地了解其组件。
Apache Spark 如何工作?
Hadoop 编程范例 MapReduce 使用分布式并行方法来处理大量数据。开发人员在创建大规模并行运算符时无需担心容错性。MapReduce 是运行作业所需的一系列多个步骤。它在每个步骤中读取数据,执行操作,然后将结果写回 HDFS。由于此原因,其作业速度较慢。
Apache Spark 的开发是为了解决 MapReduce 的限制。通过使用它,将数据读入内存、执行操作和写入结果的过程只需一步即可完成。这导致执行速度更快。
Apache Spark 组件
Apache Spark 包含六个组件。这些组件如下所述:
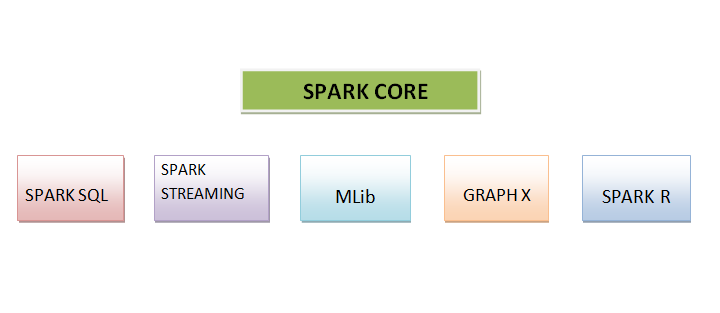
SPARK CORE
它被认为是平台的基础。它负责内存管理、作业调度、作业分发、故障恢复和作业监控以及与存储系统的通信。为 Python、Java、Scala 和 R 创建的 API 使其易于访问。这些 API 涵盖了分布式处理的复杂性和更高级别的运算符。
SPARK SQL
它可以被认为是一个分布式查询引擎,它提供低延迟查询,并且比 MapReduce 更快地提供交互式查询。它包含数千个节点、基于成本的优化器和用于快速查询的代码生成。它预装了对多种数据源的支持。从 Spark 包生态系统中,我们可以访问 Amazon S3、Amazon Redshift、CouchBase 等知名存储。
SPARK STREAMING
这是一种用于流分析的实时方法,它利用了 Spark Core 的快速调度能力。Spark Streaming 支持 Spark 包生态系统中许多知名来源,例如 Twitter、Flume 和 HDFS。它可以运行不同的算法。它使用微批处理进行实时流式传输。
MLib
MLib 是算法库,是 Spark 的重要组成部分。它支持在机器学习上进行大规模数据处理。使用它可以快速进行机器学习。它被开发用于在存储中运行的快速交互式计算。它包含各种算法实现。
GRAPH X
Graph X 是基于 Spark 的分布式图处理平台。它带有各种图算法和通用的 API。开发人员使用它来处理图形数据和探索性分析等等。它帮助用户使用图形数据创建应用程序。
SPARK R
由于其简单性和运行复杂算法的能力,它是科学家常用的编程语言。它最大的缺点是只有一个节点用于计算能力,因此它对于处理海量数据毫无用处。
Apache Spark 的优势
Apache Spark 具有许多功能,其中一些如下所述:
快速 - 它可以对大型数据运行快速查询。
用户友好 - 它支持多种编程语言,如 Java、Python 等。
多工作负载 - 它可以无缝支持多工作负载。
平台独立 - 它可以在任何平台上运行,无需太多麻烦。
结论
Apache Spark 是一个集群计算系统。它是平台独立的,用于处理海量数据集。它提供用 Python、Java 和 Scala 编写的更高级别的 API。它包含六个主要组件,即 Spark Core、Spark SQL、Spark Streaming、MLib、Graph X 和 Spark R。所有这些组件可以单独使用,也可以一起使用。它可以运行多个工作负载,并且可以对大量数据运行快速查询。它使编写并行作业变得容易。它以其简单性和运行复杂算法的能力而闻名。

浏览量 1K+
