
 数据结构
数据结构 网络
网络 关系型数据库管理系统 (RDBMS)
关系型数据库管理系统 (RDBMS) 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 编程
C 编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP机器学习分类中使用的交叉熵代价函数
在机器学习中,回归任务的目的是确定一个能够可靠地预测数据模式的函数值。另一方面,分类任务则需要确定一个能够正确识别不同数据类别的函数值。模型的准确性取决于模型在给定输入值的情况下预测输出值的有效性。代价函数就是这样一种度量标准,它用于迭代地校准模型的准确性,我们将在下面探讨这一点。
什么是代价函数?
在训练阶段,模型尝试在训练数据上生成预测,同时随机选择初始权重。但是模型如何学习其预测“偏差”有多大呢?它毫无疑问需要此知识,以便在后续训练数据迭代中使用梯度下降并相应地调整权重。
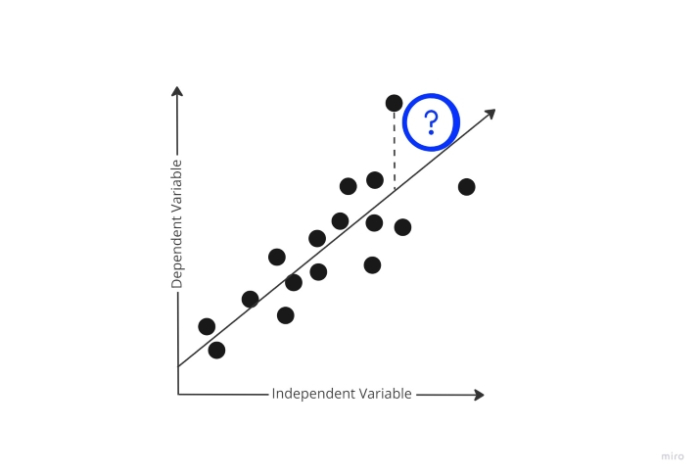
此时,代价函数登场。为了确定模型预测的错误程度,代价函数会比较模型的预测输出和实际输出。
利用代价函数提供的这些可量化的数据,模型现在正尝试更改其参数的权重,以便在后续的训练数据迭代中进一步最小化代价函数报告的误差。训练阶段的目标是迭代地创建最小化此误差的权重,直到无法再最小化为止。这本质上是一个优化问题。
分类中使用的代价函数
交叉熵损失度量用于衡量机器学习分类模型的性能。损失用 0 到 1 之间的数字表示,其中 0 表示完美模型(或无错误)。主要目标是使模型尽可能接近 0。交叉熵损失有时会与逻辑损失(或对数损失,有时称为二元交叉熵损失)混淆,但这并非总是如此。
交叉熵损失衡量机器学习分类模型的发现概率分布与预期概率分布之间的差距。它会保存所有可能的预测,因此,如果你正在寻找抛硬币的概率,它会将其保存为 0.5 和 0.5。(正面和反面)。相反,二元交叉熵损失仅存储一个值。也就是说,它只会存储 0.5,而在另一种情况下则假设另一个为 0.5(例如,如果第一个概率为 0.7,它会假设第二个为 0.3)。它还使用对数(因此称为“对数损失”)。
虽然很明显,当有三个或更多结果时它会失败,但当只有两个结果时,二元交叉熵损失(也称为对数损失)用于此目的。交叉熵损失广泛用于包含三个或更多分类选项的模型。当仅考虑单个训练样本中的误差时,代价函数可以类似地称为“损失函数”。
梯度下降
梯度下降是一种用于最小化模型或代价函数中误差的方法。它用于找到模型中哪怕是最微小的错误。你可以将梯度下降视为必须遵循的路径,以使错误最小化。你的模型的准确性在不同位置可能会有所不同,因此你必须确定最快的减少错误的方法,以避免浪费资源。
梯度下降是一种技术,用于找出给定不同输入变量值时模型的错误程度。你可以观察到,随着这种操作的重复进行,随着时间的推移,错误会越来越少。代价函数将被优化,并且你将很快达到具有最小误差的变量值。
分类中使用的代价函数类型
1. 二元交叉熵代价函数
当只有一个输出并且它只取 0 或 1 的二元值分别表示负类和正类时,二元交叉熵是分类交叉熵的一个特例。例如,对狗和猫进行分类。
假设 y 表示实际输出,则给定数据集 D 的交叉熵可以简化为:
交叉熵(D) = – y*log(p) 当 y = 1 时
交叉熵(D) = – (1-y)*log(1-p) 当 y = 0 时
所有 N 个训练数据的交叉熵的平均值,也称为二元交叉熵,决定了整个模型在二元分类中的误差。
二元交叉熵 = (N 个数据的交叉熵之和)/N
2. 多类别分类交叉熵代价函数
当有多个类别并且输入数据只属于一个类别时,此代价函数用于解决分类问题。让我们现在检查一下交叉熵的计算。假设模型为“n”个类别和特定输入数据集 D 输出以下所示的概率分布。
然后,特定数据 D 的交叉熵计算如下:
交叉熵损失(y,p) = – yT log(p)
= -(y1 log(p1) + y2 log(p2) + ……yn log(pn) )
结论
最后一点,我可以说代价函数作为各种算法和模型的监控工具,因为它突出了预期结果和实际结果之间的差异,并有助于改进模型。

453 次浏览
