- 关系数据库设计
- DBMS - 数据库规范化
- DBMS - 数据库连接
- 存储和文件结构
- DBMS - 存储系统
- DBMS - 文件结构
- 事务和并发
- DBMS - 事务
- DBMS - 并发控制
- DBMS - 死锁
- 备份和恢复
- DBMS - 数据备份
- DBMS - 数据恢复
- DBMS 有用资源
- DBMS - 快速指南
- DBMS - 有用资源
- DBMS - 讨论
DBMS - 死锁
在多进程系统中,死锁是在共享资源环境中出现的一种不希望出现的情况,其中一个进程无限期地等待另一个进程持有的资源。
例如,假设一组事务 {T0, T1, T2, ...,Tn}。T0 需要资源 X 来完成其任务。资源 X 由 T1 持有,而 T1 正在等待资源 Y,该资源由 T2 持有。T2 正在等待资源 Z,该资源由 T0 持有。因此,所有进程都在等待彼此释放资源。在这种情况下,没有一个进程能够完成其任务。这种情况称为死锁。
死锁对系统不利。如果系统陷入死锁,则参与死锁的事务将回滚或重新启动。
死锁预防
为了防止系统中出现任何死锁情况,DBMS 会积极检查所有事务即将执行的操作。DBMS 检查这些操作并分析它们是否会造成死锁情况。如果发现可能会发生死锁情况,则该事务将不被允许执行。
有一些死锁预防方案使用事务的时间戳排序机制来预先确定死锁情况。
等待-死亡方案
在这种方案中,如果一个事务请求锁定另一个事务已经持有冲突锁的资源(数据项),则可能发生以下两种情况之一:
如果 TS(Ti) < TS(Tj) - 即请求冲突锁的 Ti 比 Tj 旧 - 则允许 Ti 等待,直到数据项可用。
如果 TS(Ti) > TS(tj) - 即 Ti 比 Tj 新 - 则 Ti 死亡。Ti 稍后会随机延迟后重新启动,但时间戳相同。
此方案允许较旧的事务等待,但会终止较新的事务。
等待-伤害方案
在这种方案中,如果一个事务请求锁定另一个事务已经持有冲突锁的资源(数据项),则可能发生以下两种情况之一:
如果 TS(Ti) < TS(Tj),则 Ti 强制 Tj 回滚 - 即 Ti 伤害 Tj。Tj 稍后会随机延迟后重新启动,但时间戳相同。
如果 TS(Ti) > TS(Tj),则 Ti 被迫等待,直到资源可用。
此方案允许较新的事务等待;但是,当较旧的事务请求较新事务持有的项时,较旧的事务会强制较新的事务中止并释放该项。
在这两种情况下,稍后进入系统的交易都会被中止。
死锁避免
中止事务并非总是可行的办法。相反,可以使用死锁避免机制来提前检测任何死锁情况。“等待图”之类的方案可用,但它们仅适用于事务轻量级且资源实例较少的系统。在庞大的系统中,死锁预防技术可能效果更好。
等待图
这是一种简单的可用方法,用于跟踪是否可能出现任何死锁情况。对于进入系统的每个事务,都会创建一个节点。当事务 Ti 请求对某个项(例如 X)的锁时,该项由另一个事务 Tj 保持,则会从 Ti 到 Tj 创建一条有向边。如果 Tj 释放项目 X,则它们之间的边将被删除,而 Ti 锁定数据项。
系统为每个等待其他事务持有的某些数据项的事务维护此等待图。系统会不断检查图中是否存在任何循环。
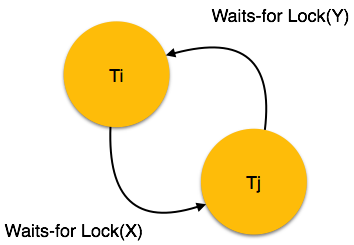
在这里,我们可以使用以下两种方法之一:
首先,不允许对另一个事务已锁定的项目进行任何请求。这并非总是可行的,并且可能导致饥饿,其中事务无限期地等待数据项且永远无法获取它。
第二个选项是回滚其中一个事务。回滚较新的事务并非总是可行的,因为它可能比较旧的事务更重要。借助某种相对算法,可以选择要中止的事务。此事务称为**受害者**,此过程称为**受害者选择**。