- H2O 教程
- H2O - 首页
- H2O - 简介
- H2O - 安装
- H2O - Flow
- H2O - 运行示例应用程序
- H2O - 自动机器学习
- H2O 有用资源
- H2O - 快速指南
- H2O - 有用资源
- H2O - 讨论
H2O - 自动机器学习
要使用 AutoML,请启动一个新的 Jupyter notebook 并按照以下步骤操作。
导入 AutoML
首先使用以下两个语句将 H2O 和 AutoML 包导入项目中:
import h2o from h2o.automl import H2OAutoML
初始化 H2O
使用以下语句初始化 h2o:
h2o.init()
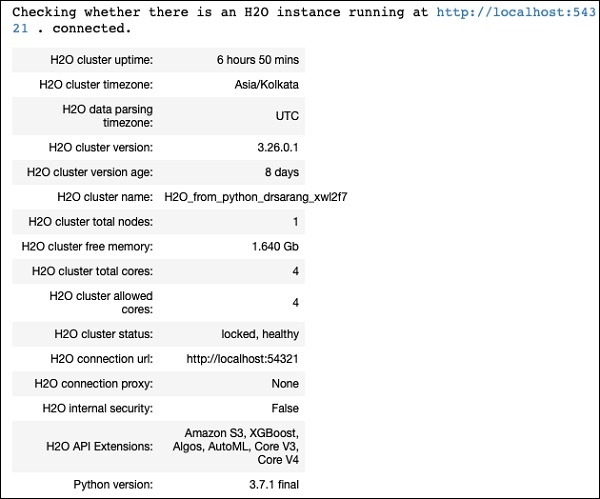
您应该在屏幕上看到集群信息,如下面的屏幕截图所示:
加载数据
我们将使用本教程前面使用过的相同 iris.csv 数据集。使用以下语句加载数据:
data = h2o.import_file('iris.csv')
准备数据集
我们需要确定特征和预测列。我们使用与之前案例相同的特征和预测列。使用以下两个语句设置特征和输出列:
features = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width'] output = 'class'
将数据以 80:20 的比例拆分为训练集和测试集:
train, test = data.split_frame(ratios=[0.8])
应用 AutoML
现在,我们已准备好将 AutoML 应用于我们的数据集。AutoML 将运行我们设置的固定时间,并为我们提供优化的模型。我们使用以下语句设置 AutoML:
aml = H2OAutoML(max_models = 30, max_runtime_secs=300, seed = 1)
第一个参数指定我们要评估和比较的模型数量。
第二个参数指定算法运行的时间。
现在,我们像这里所示一样在 AutoML 对象上调用 train 方法:
aml.train(x = features, y = output, training_frame = train)
我们将 x 指定为我们之前创建的特征数组,将 y 指定为输出变量以指示预测值,并将数据框指定为**训练**数据集。
运行代码,您需要等待 5 分钟(我们将 max_runtime_secs 设置为 300),直到您获得以下输出:

打印排行榜
当 AutoML 处理完成后,它会创建一个排行榜,对它评估的所有 30 种算法进行排名。要查看排行榜的前 10 条记录,请使用以下代码:
lb = aml.leaderboard lb.head()
执行后,以上代码将生成以下输出:
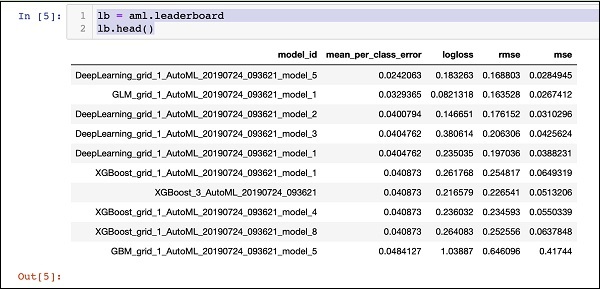
显然,DeepLearning 算法获得了最高分。
在测试数据上进行预测
现在,您已经对模型进行了排名,您可以查看评分最高的模型在测试数据上的性能。为此,请运行以下代码语句:
preds = aml.predict(test)
处理会继续一段时间,完成后您将看到以下输出。

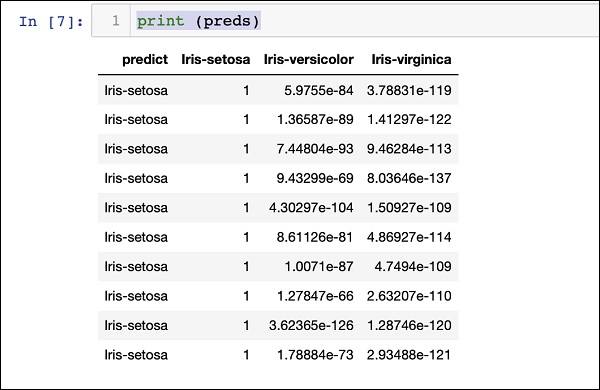
打印结果
使用以下语句打印预测结果:
print (preds)
执行上述语句后,您将看到以下结果:
打印所有算法的排名
如果要查看所有测试算法的排名,请运行以下代码语句:
lb.head(rows = lb.nrows)
执行上述语句后,将生成以下输出(部分显示):
结论
H2O 提供了一个易于使用的开源平台,用于在给定数据集上应用不同的机器学习算法。它提供了多种统计和机器学习算法,包括深度学习。在测试过程中,您可以微调这些算法的参数。您可以使用命令行或提供的基于 Web 的界面(称为 Flow)来执行此操作。H2O 还支持 AutoML,它根据算法的性能提供算法之间的排名。H2O 在大数据上也表现良好。这绝对是数据科学家的福音,可以将不同的机器学习模型应用于他们的数据集,并选择最适合他们需求的模型。