- H2O 教程
- H2O - 首页
- H2O - 简介
- H2O - 安装
- H2O - 流程
- H2O - 运行示例应用程序
- H2O - 自动机器学习 (AutoML)
- H2O 有用资源
- H2O - 快速指南
- H2O - 有用资源
- H2O - 讨论
H2O - 安装
H2O 可以通过以下五个选项进行配置和使用:
在 Python 中安装
在 R 中安装
基于 Web 的 Flow GUI
Hadoop
Anaconda Cloud
在接下来的章节中,您将看到基于可用选项的 H2O 安装说明。您可能会使用其中一个选项。
在 Python 中安装
要使用 Python 运行 H2O,安装需要几个依赖项。因此,让我们开始安装运行 H2O 的最小依赖项集。
安装依赖项
要安装依赖项,请执行以下 pip 命令:
$ pip install requests
打开您的控制台窗口并输入上述命令以安装 requests 包。以下屏幕截图显示了在我们的 Mac 机器上执行上述命令的情况:
安装 requests 后,您需要安装另外三个包,如下所示:
$ pip install tabulate $ pip install "colorama >= 0.3.8" $ pip install future
H2O GitHub 页面上提供了最新的依赖项列表。在撰写本文时,页面上列出了以下依赖项。
python 2. H2O — Installation pip >= 9.0.1 setuptools colorama >= 0.3.7 future >= 0.15.2
删除旧版本
安装上述依赖项后,您需要删除任何现有的 H2O 安装。为此,请运行以下命令:
$ pip uninstall h2o
安装最新版本
现在,让我们使用以下命令安装最新版本的 H2O:
$ pip install -f http://h2o-release.s3.amazonaws.com/h2o/latest_stable_Py.html h2o
安装成功后,您应该会看到以下消息显示在屏幕上:
Installing collected packages: h2o Successfully installed h2o-3.26.0.1
测试安装
为了测试安装,我们将运行 H2O 安装中提供的示例应用程序之一。首先通过键入以下命令启动 Python 提示符:
$ Python3
启动 Python 解释器后,在 Python 命令提示符下键入以下 Python 语句:
>>>import h2o
上述命令将 H2O 包导入您的程序。接下来,使用以下命令初始化 H2O 系统:
>>>h2o.init()
您的屏幕将显示集群信息,在此阶段应如下所示:
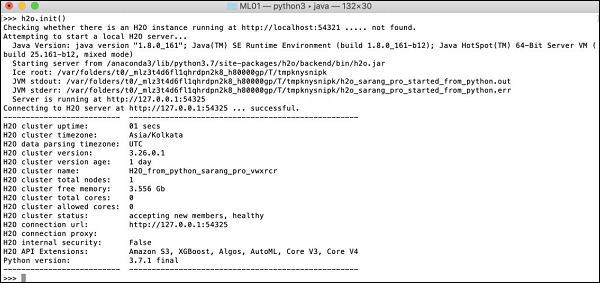
现在,您可以运行示例代码了。在 Python 提示符下键入以下命令并执行它。
>>>h2o.demo("glm")
该演示包含一个包含一系列命令的 Python 笔记本。执行每个命令后,其输出会立即显示在屏幕上,并且系统会提示您按回车键继续执行下一步。此处显示执行笔记本中最后一条语句时的部分屏幕截图:
在此阶段,您的 Python 安装已完成,您可以进行自己的实验了。
在 R 中安装
安装用于 R 开发的 H2O 与为 Python 安装它非常相似,只是您将使用 R 提示符进行安装。
启动 R 控制台
通过点击您机器上的 R 应用程序图标来启动 R 控制台。控制台屏幕将如下面的屏幕截图所示:
您的 H2O 安装将在上述 R 提示符下完成。如果您更喜欢使用 RStudio,请在 R 控制台子窗口中键入命令。
删除旧版本
首先,使用以下命令在 R 提示符下删除旧版本:
> if ("package:h2o" %in% search()) { detach("package:h2o", unload=TRUE) }
> if ("h2o" %in% rownames(installed.packages())) { remove.packages("h2o") }
下载依赖项
使用以下代码下载 H2O 的依赖项:
> pkgs <- c("RCurl","jsonlite")
for (pkg in pkgs) {
if (! (pkg %in% rownames(installed.packages()))) { install.packages(pkg) }
}
安装 H2O
在 R 提示符下键入以下命令安装 H2O:
> install.packages("h2o", type = "source", repos = (c("http://h2o-release.s3.amazonaws.com/h2o/latest_stable_R")))
以下屏幕截图显示了预期的输出:
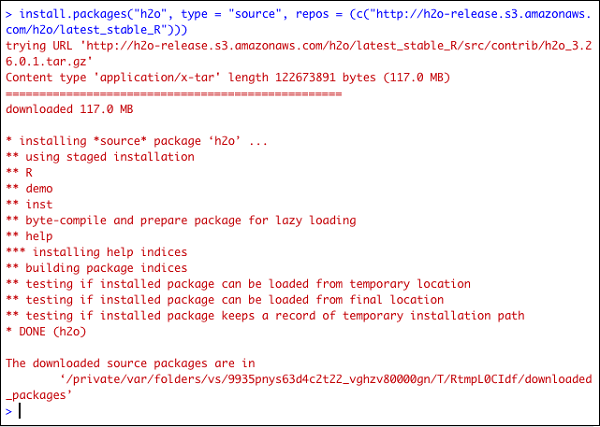
还有另一种在 R 中安装 H2O 的方法。
从 CRAN 安装 R
要从 CRAN 安装 R,请在 R 提示符下使用以下命令:
> install.packages("h2o")
系统将要求您选择镜像:
--- Please select a CRAN mirror for use in this session ---
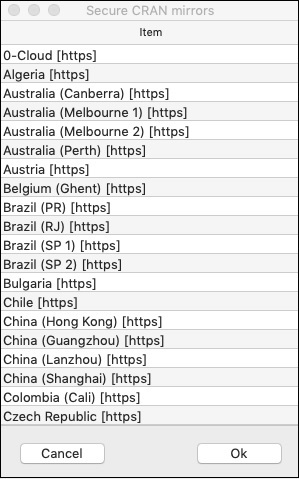
屏幕上将显示一个显示镜像站点列表的对话框。选择最近的位置或您选择的镜像。
测试安装
在 R 提示符下,键入并运行以下代码:
> library(h2o) > localH2O = h2o.init() > demo(h2o.kmeans)
生成的输出将如下面的屏幕截图所示:
您在 R 中的 H2O 安装现已完成。
安装 Web GUI Flow
要安装 GUI Flow,请从 H20 网站下载安装文件。将下载的文件解压缩到您首选的文件夹中。请注意安装中存在 h2o.jar 文件。使用以下命令在命令窗口中运行此文件:
$ java -jar h2o.jar
一段时间后,您的控制台窗口将显示以下内容。
07-24 16:06:37.304 192.168.1.18:54321 3294 main INFO: H2O started in 7725ms 07-24 16:06:37.304 192.168.1.18:54321 3294 main INFO: 07-24 16:06:37.305 192.168.1.18:54321 3294 main INFO: Open H2O Flow in your web browser: http://192.168.1.18:54321 07-24 16:06:37.305 192.168.1.18:54321 3294 main INFO:
要启动 Flow,请在您的浏览器中打开给定的 URL **https://:54321**。将出现以下屏幕:
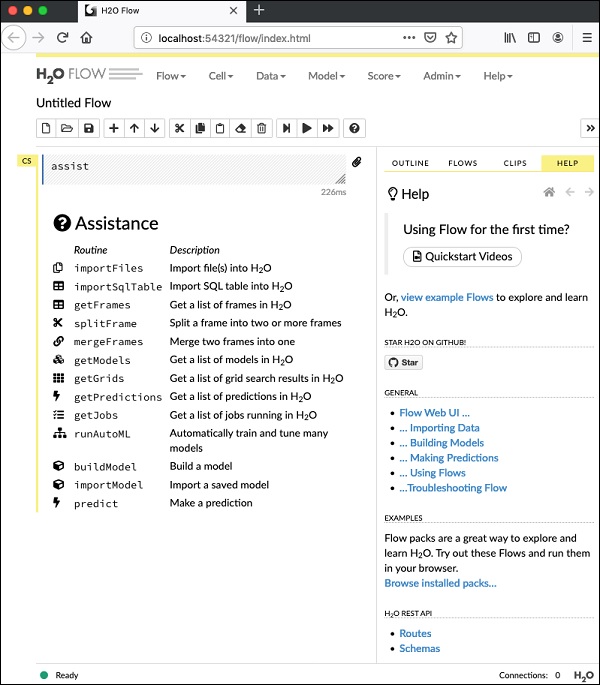
在此阶段,您的 Flow 安装已完成。
在 Hadoop/Anaconda Cloud 上安装
除非您是经验丰富的开发者,否则您不会考虑在大型数据上使用 H2O。在此只需说明,H2O 模型可以在数 TB 的大型数据库上高效运行。如果您的数据位于您的 Hadoop 安装或云中,请按照 H2O 网站上提供的步骤为您的数据库安装它。
现在您已成功在您的机器上安装并测试了 H2O,您可以进行实际开发了。首先,我们将看到从命令提示符进行的开发。在我们接下来的课程中,我们将学习如何在 H2O Flow 中进行模型测试。
在命令提示符下进行开发
现在让我们考虑使用 H2O 对众所周知的 iris 数据集的植物进行分类,该数据集可免费用于开发机器学习应用程序。
通过在 shell 窗口中键入以下命令来启动 Python 解释器:
$ Python3
这将启动 Python 解释器。使用以下命令导入 h2o 平台:
>>> import h2o
我们将使用随机森林算法进行分类。这在 H2ORandomForestEstimator 包中提供。我们使用 import 语句如下导入此包:
>>> from h2o.estimators import H2ORandomForestEstimator
我们通过调用其 init 方法来初始化 H2o 环境。
>>> h2o.init()
初始化成功后,您应该会在控制台上看到以下消息以及集群信息。
Checking whether there is an H2O instance running at https://:54321 . connected.
现在,我们将使用 H2O 中的 import_file 方法导入 iris 数据。
>>> data = h2o.import_file('iris.csv')
进度将如下面的屏幕截图所示:

将文件加载到内存后,您可以通过显示加载的表的前 10 行来验证这一点。您可以使用 **head** 方法来做到这一点:
>>> data.head()
您将在表格格式中看到以下输出。
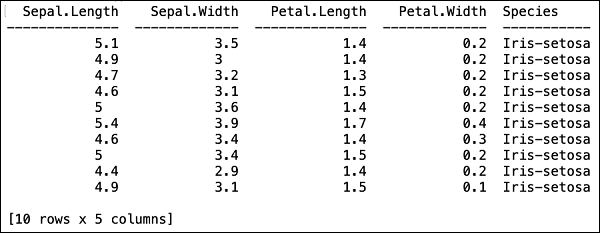
该表还显示列名。我们将使用前四列作为我们 ML 算法的特征,并将最后一列 class 作为预测输出。我们首先创建以下两个变量,在调用我们的 ML 算法时指定这一点。
>>> features = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width'] >>> output = 'class'
接下来,我们通过调用 split_frame 方法将数据分成训练集和测试集。
>>> train, test = data.split_frame(ratios = [0.8])
数据按 80:20 的比例分割。我们使用 80% 的数据进行训练,20% 的数据进行测试。
现在,我们将内置的随机森林模型加载到系统中。
>>> model = H2ORandomForestEstimator(ntrees = 50, max_depth = 20, nfolds = 10)
在上一次调用中,我们将树的数量设置为 50,树的最大深度设置为 20,交叉验证的折叠数设置为 10。现在我们需要训练模型。我们通过调用 train 方法如下进行:
>>> model.train(x = features, y = output, training_frame = train)
train 方法接收我们之前创建的特征和输出作为前两个参数。训练数据集设置为 train,这是我们完整数据集的 80%。在训练期间,您将看到如下所示的进度:
现在,模型构建过程完成后,是时候测试模型了。我们通过对训练好的模型对象调用 model_performance 方法来做到这一点。
>>> performance = model.model_performance(test_data=test)
在上一次方法调用中,我们将测试数据作为参数发送。
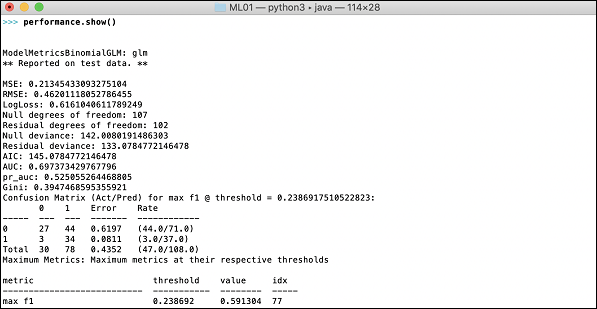
现在是时候查看输出了,这是我们模型的性能。您可以通过简单地打印性能来做到这一点。
>>> print (performance)
这将为您提供以下输出:
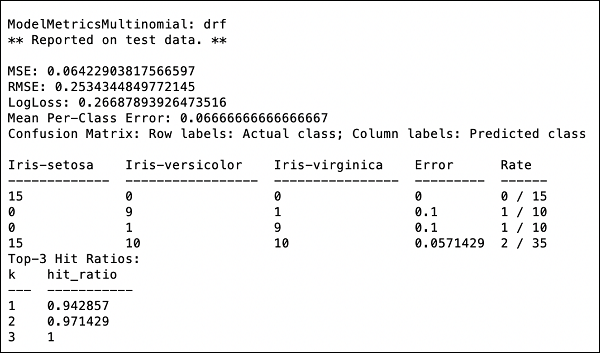
输出显示均方误差 (MSE)、均方根误差 (RMSE)、LogLoss,甚至混淆矩阵。
在 Jupyter 中运行
我们已经看到了从命令行执行的情况,也了解了每一行代码的目的。您可以在 Jupyter 环境中逐行或一次运行整个程序。完整的列表如下所示:
import h2o
from h2o.estimators import H2ORandomForestEstimator
h2o.init()
data = h2o.import_file('iris.csv')
features = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
output = 'class'
train, test = data.split_frame(ratios=[0.8])
model = H2ORandomForestEstimator(ntrees = 50, max_depth = 20, nfolds = 10)
model.train(x = features, y = output, training_frame = train)
performance = model.model_performance(test_data=test)
print (performance)
运行代码并观察输出。现在您可以欣赏到在您的数据集上应用和测试随机森林算法是多么容易了。H20 的强大功能远不止于此。如果您想在同一数据集上尝试另一个模型以查看是否可以获得更好的性能,该怎么办?这将在我们接下来的章节中解释。
应用不同的算法
现在,我们将学习如何将梯度提升算法应用于我们之前的 dataset,以查看它的性能如何。在上面的完整列表中,您只需要进行两个小的更改,如下面的代码中突出显示的那样:
import h2o
from h2o.estimators import H2OGradientBoostingEstimator
h2o.init()
data = h2o.import_file('iris.csv')
features = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
output = 'class'
train, test = data.split_frame(ratios = [0.8])
model = H2OGradientBoostingEstimator
(ntrees = 50, max_depth = 20, nfolds = 10)
model.train(x = features, y = output, training_frame = train)
performance = model.model_performance(test_data = test)
print (performance)
运行代码,您将获得以下输出:
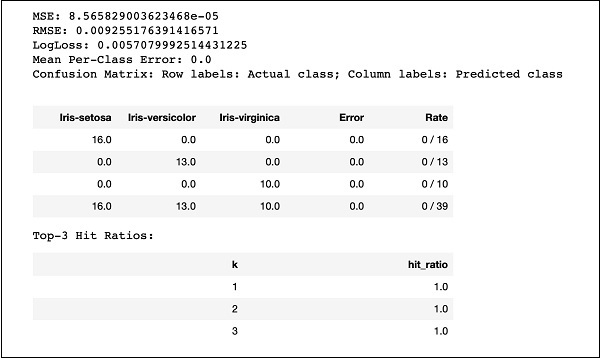
只需将 MSE、RMSE、混淆矩阵等结果与之前的输出进行比较,然后决定使用哪个结果进行生产部署。事实上,您可以应用几种不同的算法来决定最符合您目的的那个。