- H2O 教程
- H2O - 首页
- H2O - 简介
- H2O - 安装
- H2O - 流程
- H2O - 运行示例应用程序
- H2O - AutoML
- H2O 有用资源
- H2O 快速指南
- H2O - 有用资源
- H2O - 讨论
H2O 快速指南
H2O - 简介
您是否曾被要求在一个巨大的数据库上开发机器学习模型?通常,客户会提供数据库并要求您进行某些预测,例如谁可能是潜在买家;是否可以提前发现欺诈案件等。为了回答这些问题,您的任务是开发一个机器学习算法来回答客户的查询。从零开始开发机器学习算法并非易事,而且当市场上有多个现成的机器学习库可用时,为什么要这样做呢?
如今,您更倾向于使用这些库,从这些库中应用经过良好测试的算法并查看其性能。如果性能未达到可接受的限制,则可以尝试微调当前算法或尝试完全不同的算法。
同样,您可以在同一数据集上尝试多种算法,然后选择最能满足客户需求的算法。这就是 H2O 派上用场的地方。它是一个开源机器学习框架,包含对几种广泛接受的 ML 算法的全面测试实现。您只需从其庞大的存储库中选择算法并将其应用于您的数据集即可。它包含最常用的统计和 ML 算法。
这里仅举几例,它包括梯度提升机 (GBM)、广义线性模型 (GLM)、深度学习等等。不仅如此,它还支持 AutoML 功能,该功能将对您数据集上不同算法的性能进行排名,从而减少您查找最佳性能模型的工作量。H2O 被全球超过 18000 个组织使用,并与 R 和 Python 良好地交互,方便您进行开发。它是一个内存平台,提供卓越的性能。
在本教程中,您将首先学习使用 Python 和 R 选项在您的机器上安装 H2O。我们将了解如何在命令行中使用它,以便您逐行理解其工作原理。如果您是 Python 爱好者,您可以使用 Jupyter 或任何其他您选择的 IDE 来开发 H2O 应用程序。如果您更喜欢 R,则可以使用 RStudio 进行开发。
在本教程中,我们将考虑一个示例来了解如何使用 H2O。我们还将学习如何在程序代码中更改算法并将其性能与之前的算法进行比较。H2O 还提供了一个基于 Web 的工具来测试数据集上的不同算法。这称为 Flow。
本教程将向您介绍 Flow 的使用方法。同时,我们将讨论 AutoML 的使用,它将识别您数据集上性能最佳的算法。您是不是很兴奋地学习 H2O?继续阅读!
H2O - 安装
H2O 可以使用以下五个不同的选项进行配置和使用:
在 Python 中安装
在 R 中安装
基于 Web 的 Flow GUI
Hadoop
Anaconda Cloud
在接下来的章节中,您将看到基于可用选项的 H2O 安装说明。您可能会使用其中一个选项。
在 Python 中安装
要使用 Python 运行 H2O,安装需要多个依赖项。因此,让我们开始安装运行 H2O 的最小依赖项集。
安装依赖项
要安装依赖项,请执行以下 pip 命令:
$ pip install requests
打开您的控制台窗口并键入上述命令以安装 requests 包。以下屏幕截图显示了在我们的 Mac 机器上执行上述命令的情况:
安装 requests 后,您需要安装另外三个包,如下所示:
$ pip install tabulate $ pip install "colorama >= 0.3.8" $ pip install future
H2O GitHub 页面上提供了最新的依赖项列表。在撰写本文时,页面上列出了以下依赖项。
python 2. H2O — Installation pip >= 9.0.1 setuptools colorama >= 0.3.7 future >= 0.15.2
删除旧版本
安装上述依赖项后,您需要删除任何现有的 H2O 安装。为此,请运行以下命令:
$ pip uninstall h2o
安装最新版本
现在,让我们使用以下命令安装最新版本的 H2O:
$ pip install -f http://h2o-release.s3.amazonaws.com/h2o/latest_stable_Py.html h2o
安装成功后,您应该会看到屏幕上显示以下消息:
Installing collected packages: h2o Successfully installed h2o-3.26.0.1
测试安装
为了测试安装,我们将运行 H2O 安装中提供的示例应用程序之一。首先通过键入以下命令启动 Python 提示符:
$ Python3
Python 解释器启动后,在 Python 命令提示符下键入以下 Python 语句:
>>>import h2o
上述命令将 H2O 包导入您的程序。接下来,使用以下命令初始化 H2O 系统:
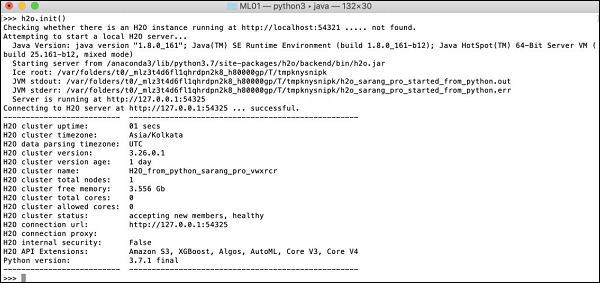
>>>h2o.init()
您的屏幕将显示集群信息,在此阶段应如下所示:
现在,您可以运行示例代码了。在 Python 提示符下键入以下命令并执行它。
>>>h2o.demo("glm")
该演示包含一个 Python 笔记本,其中包含一系列命令。执行每个命令后,其输出会立即显示在屏幕上,系统会要求您按键盘上的键以继续下一步。此处显示执行笔记本中最后一条语句时的部分屏幕截图:
在此阶段,您的 Python 安装已完成,您可以开始自己的实验了。
在 R 中安装
安装 H2O 用于 R 开发与安装它用于 Python 非常相似,只是您将使用 R 提示符进行安装。
启动 R 控制台
通过单击机器上的 R 应用程序图标启动 R 控制台。控制台屏幕将如下图所示:
您的 H2O 安装将在上述 R 提示符下完成。如果您更喜欢使用 RStudio,请在 R 控制台子窗口中键入命令。
删除旧版本
首先,使用以下命令在 R 提示符下删除旧版本:
> if ("package:h2o" %in% search()) { detach("package:h2o", unload=TRUE) }
> if ("h2o" %in% rownames(installed.packages())) { remove.packages("h2o") }
下载依赖项
使用以下代码下载 H2O 的依赖项:
> pkgs <- c("RCurl","jsonlite")
for (pkg in pkgs) {
if (! (pkg %in% rownames(installed.packages()))) { install.packages(pkg) }
}
安装 H2O
在 R 提示符下键入以下命令安装 H2O:
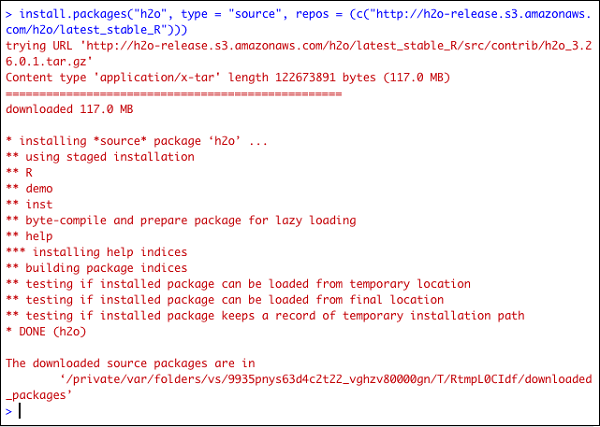
> install.packages("h2o", type = "source", repos = (c("http://h2o-release.s3.amazonaws.com/h2o/latest_stable_R")))
以下屏幕截图显示了预期的输出:
还有另一种在 R 中安装 H2O 的方法。
从 CRAN 安装 R
要从 CRAN 安装 R,请在 R 提示符下使用以下命令:
> install.packages("h2o")
系统会要求您选择镜像:
--- Please select a CRAN mirror for use in this session ---
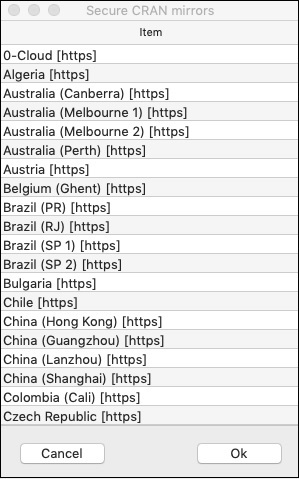
屏幕上将显示一个显示镜像站点列表的对话框。选择最近的位置或您选择的镜像。
测试安装
在 R 提示符下,键入并运行以下代码:
> library(h2o) > localH2O = h2o.init() > demo(h2o.kmeans)
生成的输出将如下图所示:
您在 R 中的 H2O 安装现已完成。
安装 Web GUI Flow
要安装 GUI Flow,请从 H20 站点下载安装文件。将下载的文件解压缩到您首选的文件夹中。请注意安装中存在 h2o.jar 文件。使用以下命令在命令窗口中运行此文件:
$ java -jar h2o.jar
一段时间后,您的控制台窗口中将出现以下内容。
07-24 16:06:37.304 192.168.1.18:54321 3294 main INFO: H2O started in 7725ms 07-24 16:06:37.304 192.168.1.18:54321 3294 main INFO: 07-24 16:06:37.305 192.168.1.18:54321 3294 main INFO: Open H2O Flow in your web browser: http://192.168.1.18:54321 07-24 16:06:37.305 192.168.1.18:54321 3294 main INFO:
要启动 Flow,请在浏览器中打开给定的 URL **https://:54321**。将出现以下屏幕:
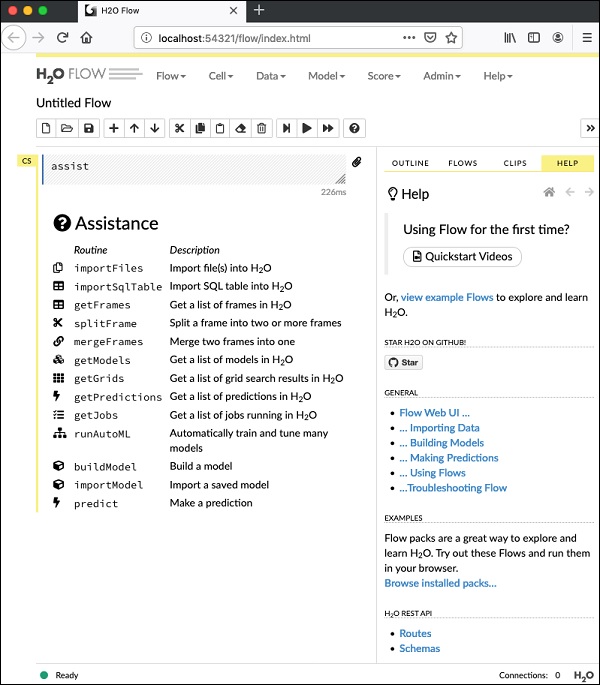
在此阶段,您的 Flow 安装已完成。
在 Hadoop/Anaconda Cloud 上安装
除非您是经验丰富的开发者,否则您不会考虑在 Big Data 上使用 H2O。在这里,足以说明 H2O 模型在数 TB 的大型数据库上高效运行。如果您的数据位于您的 Hadoop 安装或云中,请按照 H2O 站点上给出的步骤为您的数据库安装它。
现在您已成功在您的机器上安装和测试 H2O,您可以进行真正的开发了。首先,我们将看到从命令提示符开始的开发。在我们接下来的课程中,我们将学习如何在 H2O Flow 中进行模型测试。
在命令提示符下进行开发
现在让我们考虑使用 H2O 对众所周知的 iris 数据集的植物进行分类,该数据集可免费用于开发机器学习应用程序。
通过在 shell 窗口中键入以下命令启动 Python 解释器:
$ Python3
这将启动 Python 解释器。使用以下命令导入 h2o 平台:
>>> import h2o
我们将使用 Random Forest 算法进行分类。这在 H2ORandomForestEstimator 包中提供。我们使用 import 语句导入此包,如下所示:
>>> from h2o.estimators import H2ORandomForestEstimator
我们通过调用其 init 方法来初始化 H2o 环境。
>>> h2o.init()
初始化成功后,您应该会在控制台上看到以下消息以及集群信息。
Checking whether there is an H2O instance running at https://:54321 . connected.
现在,我们将使用 H2O 中的 import_file 方法导入 iris 数据。
>>> data = h2o.import_file('iris.csv')
进度将如下图所示:

将文件加载到内存后,您可以通过显示加载表的前面 10 行来验证这一点。您可以使用 **head** 方法来做到这一点:
>>> data.head()
您将在表格格式中看到以下输出。
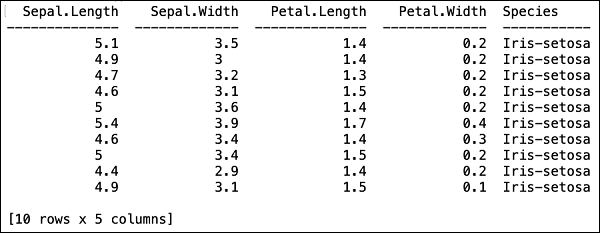
该表还显示列名。我们将使用前四列作为我们 ML 算法的特征,并将最后一列 class 作为预测输出。我们首先创建以下两个变量,在对 ML 算法的调用中指定这一点。
>>> features = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width'] >>> output = 'class'
接下来,我们通过调用 split_frame 方法将数据分成训练集和测试集。
>>> train, test = data.split_frame(ratios = [0.8])
数据以 80:20 的比例分割。我们使用 80% 的数据进行训练,20% 的数据进行测试。
现在,我们将内置的 Random Forest 模型加载到系统中。
>>> model = H2ORandomForestEstimator(ntrees = 50, max_depth = 20, nfolds = 10)
在上面的调用中,我们将树的数量设置为 50,树的最大深度设置为 20,交叉验证的折叠数设置为 10。我们现在需要训练模型。我们通过调用 train 方法来做到这一点,如下所示:
>>> model.train(x = features, y = output, training_frame = train)
train 方法接收我们之前创建的特征和输出作为前两个参数。训练数据集设置为 train,这是我们完整数据集的 80%。在训练期间,您将看到如下所示的进度:
现在,模型构建过程完成后,是时候测试模型了。我们通过对经过训练的模型对象调用 model_performance 方法来做到这一点。
>>> performance = model.model_performance(test_data=test)
在上述方法调用中,我们将测试数据作为参数发送。
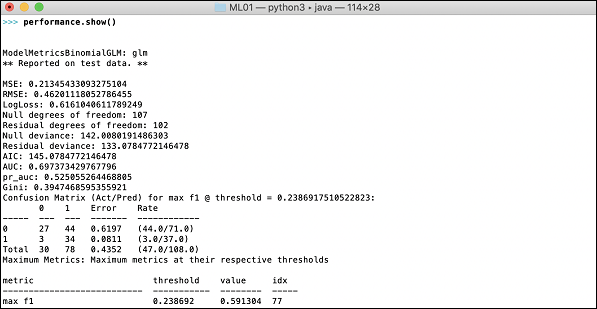
现在是查看输出的时候了,输出就是我们模型的性能。你可以通过简单地打印性能来实现。
>>> print (performance)
这将给你以下输出:
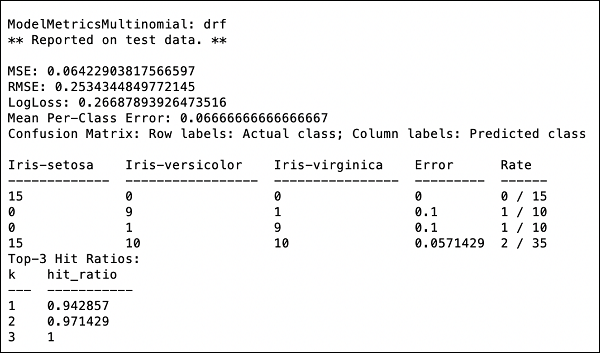
输出显示均方误差 (MSE)、均方根误差 (RMSE)、LogLoss 甚至混淆矩阵。
在 Jupyter 中运行
我们已经看到了命令行中的执行过程,也理解了每一行代码的目的。你可以在 Jupyter 环境中运行整个代码,可以一行一行地运行,也可以一次运行整个程序。完整的代码清单如下:
import h2o
from h2o.estimators import H2ORandomForestEstimator
h2o.init()
data = h2o.import_file('iris.csv')
features = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
output = 'class'
train, test = data.split_frame(ratios=[0.8])
model = H2ORandomForestEstimator(ntrees = 50, max_depth = 20, nfolds = 10)
model.train(x = features, y = output, training_frame = train)
performance = model.model_performance(test_data=test)
print (performance)
运行代码并观察输出。现在你可以体会到在你的数据集上应用和测试随机森林算法是多么容易。H2O 的功能远不止于此。如果你想在相同的数据集上尝试另一个模型以查看是否可以获得更好的性能,该怎么办?这将在我们后面的章节中解释。
应用不同的算法
现在,我们将学习如何将梯度提升算法应用于我们之前的数据集,以查看它的性能。在上文的完整代码清单中,你只需要进行如下代码中突出显示的两个小改动:
import h2o
from h2o.estimators import H2OGradientBoostingEstimator
h2o.init()
data = h2o.import_file('iris.csv')
features = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
output = 'class'
train, test = data.split_frame(ratios = [0.8])
model = H2OGradientBoostingEstimator
(ntrees = 50, max_depth = 20, nfolds = 10)
model.train(x = features, y = output, training_frame = train)
performance = model.model_performance(test_data = test)
print (performance)
运行代码,你将得到以下输出:
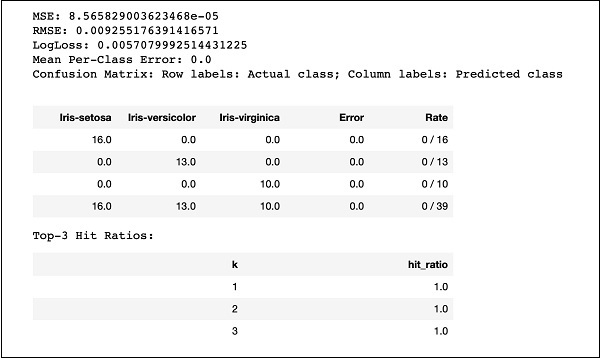
只需将 MSE、RMSE、混淆矩阵等结果与之前的输出进行比较,然后决定使用哪个模型进行生产部署。事实上,你可以应用多种不同的算法来决定最符合你目的的算法。
H2O - 流程
在上一课中,你学习了如何使用命令行界面创建基于 H2O 的机器学习模型。H2O Flow 具有相同的功能,但它使用的是基于 Web 的界面。
在接下来的课程中,我将向你展示如何启动 H2O Flow 并运行一个示例应用程序。
启动 H2O Flow
你之前下载的 H2O 安装包包含 h2o.jar 文件。要启动 H2O Flow,首先从命令提示符运行此 jar 文件:
$ java -jar h2o.jar
jar 文件成功运行后,你将在控制台上看到以下消息:
Open H2O Flow in your web browser: http://192.168.1.10:54321
现在,打开你选择的浏览器,然后键入上述 URL。你将看到如下所示的 H2O 基于 Web 的桌面:
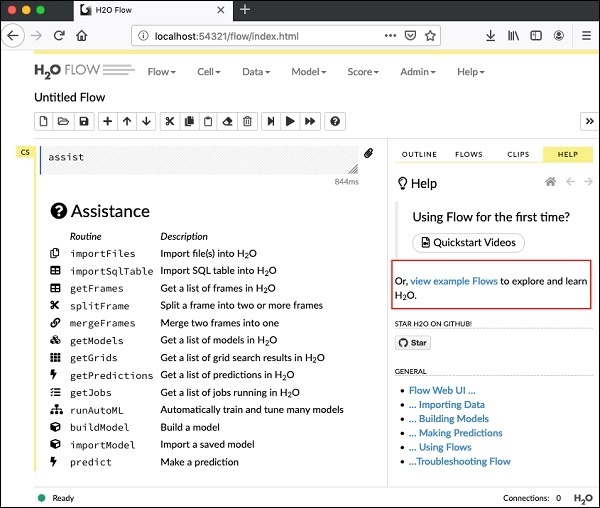
这基本上是一个类似于 Colab 或 Jupyter 的笔记本。我将向你展示如何在该笔记本中加载和运行示例应用程序,同时解释 Flow 中的各种功能。点击上述屏幕上的“查看示例 Flows”链接以查看提供的示例列表。
我将描述示例中的“航空公司延误 Flow”示例。
H2O - 运行示例应用程序
点击示例列表中的“航空公司延误 Flow”链接,如下图所示:
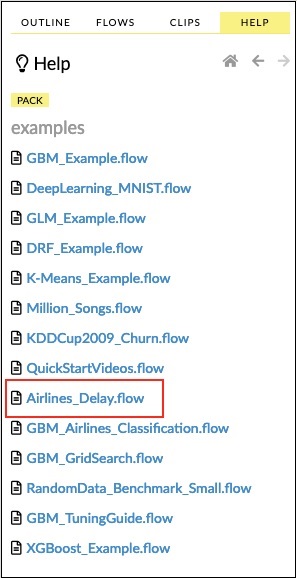
确认后,将加载新的笔记本。
清除所有输出
在我们解释笔记本中的代码语句之前,让我们清除所有输出,然后逐步运行笔记本。要清除所有输出,请选择以下菜单选项:
Flow / Clear All Cell Contents
如下图所示:
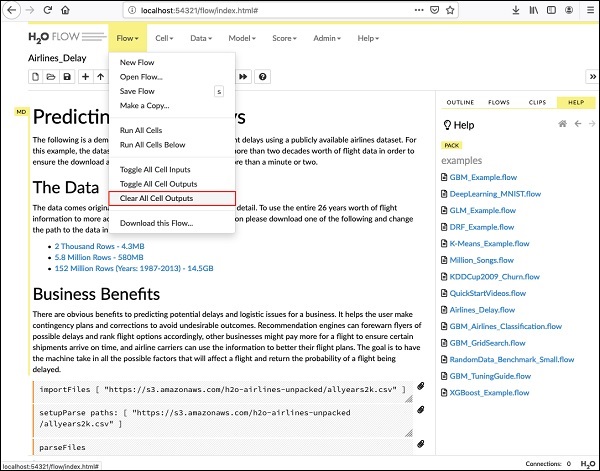
清除所有输出后,我们将分别运行笔记本中的每个单元格并检查其输出。
运行第一个单元格
点击第一个单元格。左侧会出现一个红色标记,表示该单元格已被选中。如下图所示:

此单元格的内容只是用 MarkDown (MD) 语言编写的程序注释。内容描述了已加载的应用程序的功能。要运行单元格,请点击“运行”图标,如下图所示:

你不会在单元格下方看到任何输出,因为当前单元格中没有可执行代码。光标现在会自动移动到下一个单元格,该单元格已准备好执行。
导入数据
下一个单元格包含以下 Python 语句:
importFiles ["https://s3.amazonaws.com/h2o-airlines-unpacked/allyears2k.csv"]
该语句将 allyears2k.csv 文件从 Amazon AWS 导入系统。运行单元格时,它会导入文件并给你以下输出。
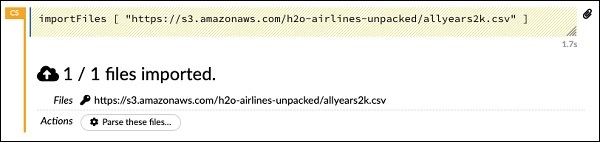
设置数据解析器
现在,我们需要解析数据并使其适合我们的机器学习算法。这可以使用以下命令完成:
setupParse paths: [ "https://s3.amazonaws.com/h2o-airlines-unpacked/allyears2k.csv" ]
执行上述语句后,将出现一个设置配置对话框。该对话框允许你进行多种文件解析设置。如下图所示:
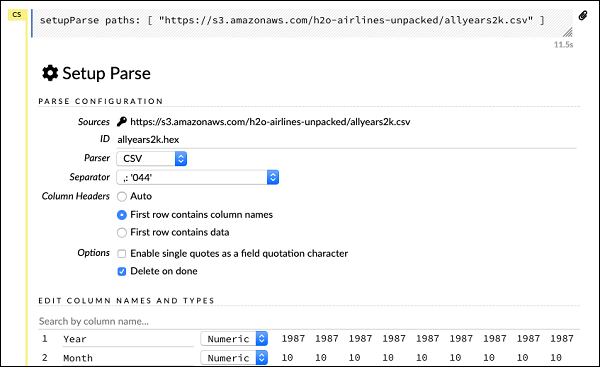
在此对话框中,你可以从给定的下拉列表中选择所需的解析器,并设置其他参数,例如字段分隔符等。
解析数据
实际上使用上述配置解析数据文件的下一个语句很长,如下所示:
parseFiles paths: ["https://s3.amazonaws.com/h2o-airlines-unpacked/allyears2k.csv"] destination_frame: "allyears2k.hex" parse_type: "CSV" separator: 44 number_columns: 31 single_quotes: false column_names: ["Year","Month","DayofMonth","DayOfWeek","DepTime","CRSDepTime", "ArrTime","CRSArrTime","UniqueCarrier","FlightNum","TailNum", "ActualElapsedTime","CRSElapsedTime","AirTime","ArrDelay","DepDelay", "Origin","Dest","Distance","TaxiIn","TaxiOut","Cancelled","CancellationCode", "Diverted","CarrierDelay","WeatherDelay","NASDelay","SecurityDelay", "LateAircraftDelay","IsArrDelayed","IsDepDelayed"] column_types: ["Enum","Enum","Enum","Enum","Numeric","Numeric","Numeric" ,"Numeric","Enum","Enum","Enum","Numeric","Numeric","Numeric","Numeric", "Numeric","Enum","Enum","Numeric","Numeric","Numeric","Enum","Enum", "Numeric","Numeric","Numeric","Numeric","Numeric","Numeric","Enum","Enum"] delete_on_done: true check_header: 1 chunk_size: 4194304
请注意,你在配置框中设置的参数已列在上述代码中。现在,运行此单元格。一段时间后,解析完成,你将看到以下输出:
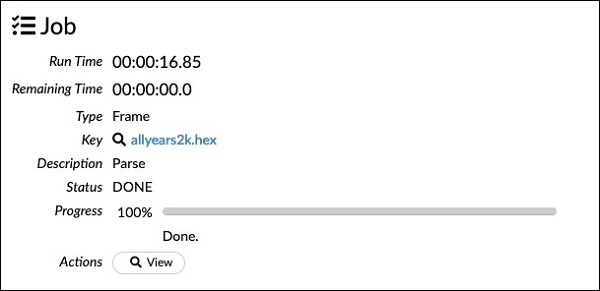
检查数据框
处理后,它会生成一个数据框,可以使用以下语句检查:
getFrameSummary "allyears2k.hex"
执行上述语句后,你将看到以下输出:
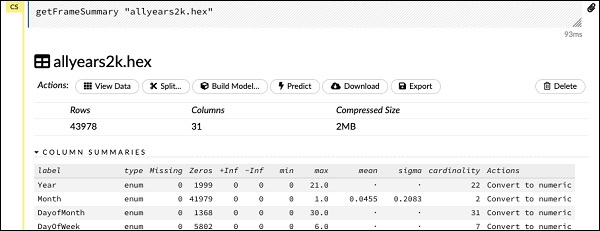
现在,你的数据已准备好输入机器学习算法。
下一个语句是一个程序注释,它说明我们将使用回归模型并指定预设正则化和 lambda 值。
构建模型
接下来是最重要的语句,即构建模型本身。这在以下语句中指定:
buildModel 'glm', {
"model_id":"glm_model","training_frame":"allyears2k.hex",
"ignored_columns":[
"DayofMonth","DepTime","CRSDepTime","ArrTime","CRSArrTime","TailNum",
"ActualElapsedTime","CRSElapsedTime","AirTime","ArrDelay","DepDelay",
"TaxiIn","TaxiOut","Cancelled","CancellationCode","Diverted","CarrierDelay",
"WeatherDelay","NASDelay","SecurityDelay","LateAircraftDelay","IsArrDelayed"],
"ignore_const_cols":true,"response_column":"IsDepDelayed","family":"binomial",
"solver":"IRLSM","alpha":[0.5],"lambda":[0.00001],"lambda_search":false,
"standardize":true,"non_negative":false,"score_each_iteration":false,
"max_iterations":-1,"link":"family_default","intercept":true,
"objective_epsilon":0.00001,"beta_epsilon":0.0001,"gradient_epsilon":0.0001,
"prior":-1,"max_active_predictors":-1
}
我们使用 glm,这是一个广义线性模型套件,其族类型设置为二项式。你可以在上述语句中看到这些高亮显示的部分。在我们的例子中,预期输出是二进制的,这就是我们使用二项式类型的原因。你可以自己检查其他参数;例如,查看我们之前指定的 alpha 和 lambda。请参考 GLM 模型文档以了解所有参数的解释。
现在,运行此语句。执行后,将生成以下输出:
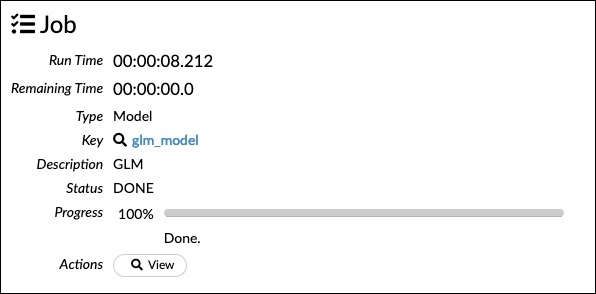
当然,你的机器上的执行时间会有所不同。现在,这是此示例代码中最有趣的部分。
检查输出
我们使用以下语句简单地输出我们构建的模型:
getModel "glm_model"
请注意,glm_model 是我们在前面语句中构建模型时作为 model_id 参数指定的模型 ID。这给了我们一个巨大的输出,详细说明了具有多个不同参数的结果。报告的部分输出如下图所示:
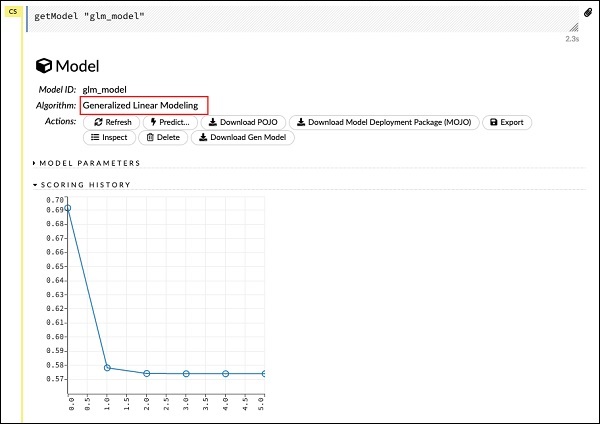
正如你在输出中看到的,它说明这是在你的数据集上运行广义线性建模算法的结果。
在“评分历史”上方,你会看到“模型参数”标签,展开它,你将看到构建模型时使用的所有参数列表。如下图所示。
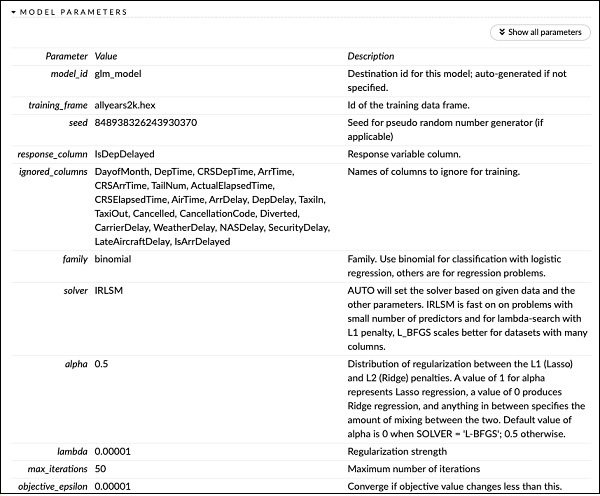
同样,每个标签都提供特定类型的详细输出。自己展开各个标签以研究不同类型的输出。
构建另一个模型
接下来,我们将基于我们的数据框构建一个深度学习模型。示例代码中的下一条语句只是一个程序注释。以下语句实际上是一个模型构建命令。如下所示:
buildModel 'deeplearning', {
"model_id":"deeplearning_model","training_frame":"allyear
s2k.hex","ignored_columns":[
"DepTime","CRSDepTime","ArrTime","CRSArrTime","FlightNum","TailNum",
"ActualElapsedTime","CRSElapsedTime","AirTime","ArrDelay","DepDelay",
"TaxiIn","TaxiOut","Cancelled","CancellationCode","Diverted",
"CarrierDelay","WeatherDelay","NASDelay","SecurityDelay",
"LateAircraftDelay","IsArrDelayed"],
"ignore_const_cols":true,"res ponse_column":"IsDepDelayed",
"activation":"Rectifier","hidden":[200,200],"epochs":"100",
"variable_importances":false,"balance_classes":false,
"checkpoint":"","use_all_factor_levels":true,
"train_samples_per_iteration":-2,"adaptive_rate":true,
"input_dropout_ratio":0,"l1":0,"l2":0,"loss":"Automatic","score_interval":5,
"score_training_samples":10000,"score_duty_cycle":0.1,"autoencoder":false,
"overwrite_with_best_model":true,"target_ratio_comm_to_comp":0.02,
"seed":6765686131094811000,"rho":0.99,"epsilon":1e-8,"max_w2":"Infinity",
"initial_weight_distribution":"UniformAdaptive","classification_stop":0,
"diagnostics":true,"fast_mode":true,"force_load_balance":true,
"single_node_mode":false,"shuffle_training_data":false,"missing_values_handling":
"MeanImputation","quiet_mode":false,"sparse":false,"col_major":false,
"average_activation":0,"sparsity_beta":0,"max_categorical_features":2147483647,
"reproducible":false,"export_weights_and_biases":false
}
正如你在上述代码中看到的,我们指定 deeplearning 来构建模型,并将多个参数设置为深度学习模型文档中指定的适当值。运行此语句时,它将比 GLM 模型构建花费更长时间。模型构建完成后,你将看到以下输出,尽管计时不同。
检查深度学习模型输出
这会生成一种输出,可以使用以下语句进行检查,就像之前的例子一样。
getModel "deeplearning_model"
我们将考虑如下图所示的 ROC 曲线输出以供快速参考。
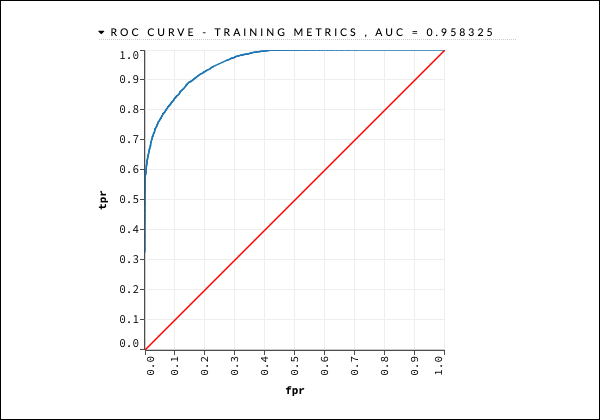
与之前的案例一样,展开各个选项卡并研究不同的输出。
保存模型
研究了不同模型的输出后,你决定在生产环境中使用其中一个模型。H20 允许你将此模型保存为 POJO(普通旧 Java 对象)。
展开输出中的最后一个标签“预览 POJO”,你将看到你微调模型的 Java 代码。在生产环境中使用它。
接下来,我们将学习 H2O 的一个非常令人兴奋的功能。我们将学习如何使用 AutoML 来测试和排名各种算法的性能。
H2O - AutoML
要使用 AutoML,请启动一个新的 Jupyter 笔记本并按照以下步骤操作。
导入 AutoML
首先使用以下两条语句将 H2O 和 AutoML 包导入项目:
import h2o from h2o.automl import H2OAutoML
初始化 H2O
使用以下语句初始化 h2o:
h2o.init()
你应该在屏幕上看到集群信息,如下图所示:
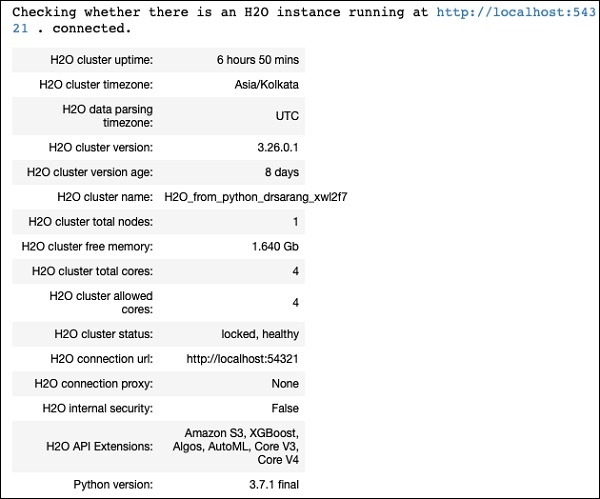
我们将使用你在本教程中前面使用过的相同 iris.csv 数据集。使用以下语句加载数据:
加载数据
data = h2o.import_file('iris.csv')
准备数据集
我们需要确定特征和预测列。我们使用与之前案例相同的特征和预测列。使用以下两条语句设置特征和输出列:
features = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width'] output = 'class'
将数据以 80:20 的比例拆分为训练集和测试集:
train, test = data.split_frame(ratios=[0.8])
应用 AutoML
现在,我们已经准备好将 AutoML 应用于我们的数据集。AutoML 将运行我们设置的固定时间,并提供优化的模型。我们使用以下语句设置 AutoML:
aml = H2OAutoML(max_models = 30, max_runtime_secs=300, seed = 1)
第一个参数指定我们要评估和比较的模型数量。
第二个参数指定算法运行的时间。
我们现在在 AutoML 对象上调用 train 方法,如下所示:
aml.train(x = features, y = output, training_frame = train)
我们将 x 指定为我们之前创建的特征数组,将 y 指定为输出变量以指示预测值,并将数据框指定为**训练**数据集。
运行代码,你必须等待 5 分钟(我们将 max_runtime_secs 设置为 300),直到你得到以下输出:

打印排行榜
AutoML 处理完成后,它会创建一个排行榜,对它评估的所有 30 种算法进行排名。要查看排行榜的前 10 条记录,请使用以下代码:
lb = aml.leaderboard lb.head()
执行后,上述代码将生成以下输出:
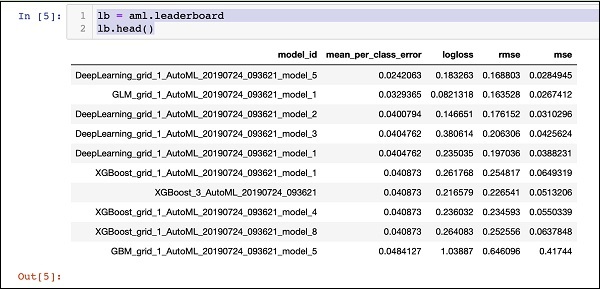
显然,深度学习算法获得了最高分。
在测试数据上进行预测
现在,您已经对模型进行了排名,您可以查看顶级模型在测试数据上的性能。为此,请运行以下代码语句:
preds = aml.predict(test)
处理过程将持续一段时间,完成后您将看到以下输出。

打印结果
使用以下语句打印预测结果:
print (preds)
执行上述语句后,您将看到以下结果:
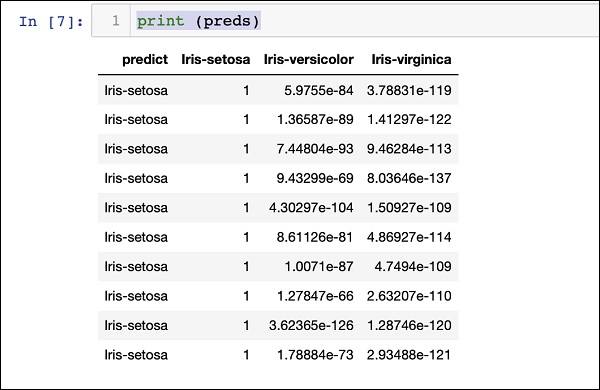
打印所有算法的排名
如果您想查看所有测试算法的排名,请运行以下代码语句:
lb.head(rows = lb.nrows)
执行上述语句后,将生成以下输出(部分显示):
结论
H2O 提供了一个易于使用的开源平台,用于在给定的数据集上应用不同的机器学习算法。它提供了多种统计和机器学习算法,包括深度学习。在测试过程中,您可以微调这些算法的参数。您可以使用命令行或提供的基于 Web 的界面 Flow 来实现这一点。H2O 还支持 AutoML,该功能可以根据算法的性能对其进行排名。H2O 在大数据上的性能也很好。这对于数据科学家在其数据集上应用不同的机器学习模型并选择最符合其需求的模型无疑是一个福音。