
 数据结构
数据结构 网络
网络 关系型数据库管理系统
关系型数据库管理系统 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 编程
C 编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP如何在 Python 中使用 Seaborn 可视化具有多个变量的数据?
Seaborn 是一个有助于数据可视化的库。它带有自定义主题和高级接口。在实时情况下,数据集包含许多变量。有时,可能需要分析数据集中每个变量与其他每个变量的关系。在这种情况下,双变量分布可能花费太多时间,并且也可能变得复杂。
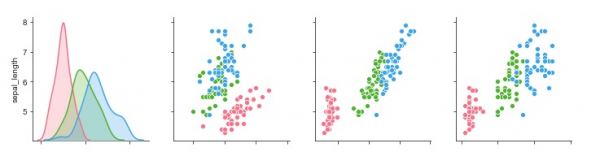
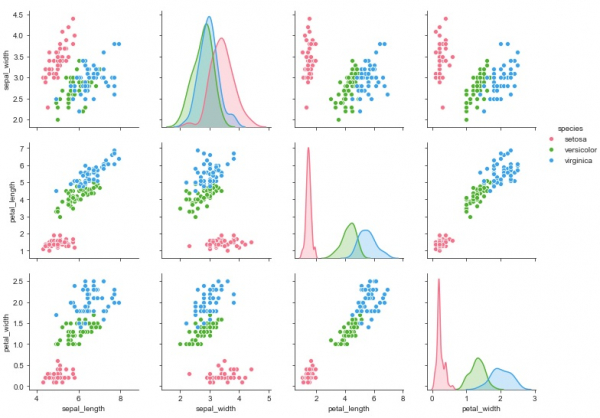
这就是多对多双变量分布发挥作用的地方。可以使用“pairplot”函数获取数据框中变量组合之间的关系。输出将是单变量图。
pairplot 函数的语法
seaborn.pairplot(data,…)
现在让我们了解如何在图形上绘制它 -
示例
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
my_df = sb.load_dataset('iris')
sb.set_style("ticks")
sb.pairplot(my_df,hue = 'species',diag_kind = "kde",kind = "scatter",palette = "husl")
plt.show()输出
解释
- 导入所需的包。
- 输入数据为“iris_data”,它从 scikit learn 库加载。
- 此数据存储在数据框中。
- “load_dataset”函数用于加载鸢尾花数据。
- 使用“pairplot”函数可视化此数据。
- 这里,数据框作为参数提供。
- 这里,“kind”参数指定为“kde”,以便绘图理解打印核密度估计。
- 图的类型被提及为散点图。
- 此数据显示在控制台上。

更新于:2020-12-11
248 次查看

广告