
 数据结构
数据结构 网络
网络 关系数据库管理系统 (RDBMS)
关系数据库管理系统 (RDBMS) 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C语言编程
C语言编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP如何用Python检查时间序列数据是否平稳?
时间序列是一组数据点,这些数据点以固定的时间间隔记录。它用于研究模式趋势,以及在定义的时间内变量之间的关系。时间序列的常见例子包括股票价格、天气模式和经济指标。
它通过统计和数学技术分析时间序列数据。时间序列的主要目的是识别先前数据的模式和趋势,以预测未来的值。
如果数据不随时间变化,则称数据为平稳的。有必要检查数据是否平稳。有多种方法可以检查时间序列数据是否平稳,让我们一一来看。
增强型Dickey-Fuller检验(ADF)
增强型Dickey-Fuller检验(ADF)是一种统计检验,用于检查时间序列数据中是否存在单位根。单位根是非平稳的数据。它返回检验统计量和p值作为输出。
在输出中,如果p值低于0.05,则表示时间序列数据不平稳。以下是ADF平稳数据的示例。我们在python中有一个名为adfuller()的函数,它在statsmodel包中可用,用于检查时间序列数据是否平稳。
示例
在这个例子中,我们使用python的statsmodel包中的adfuller()函数来查找增强型Dickey-Fuller检验的ADF统计量和p值。
from statsmodels.tsa.stattools import adfuller
import pandas as pd
data = pd.read_csv('https://raw.githubusercontent.com/selva86/datasets/master/a10.csv',parse_dates=['date'], index_col='date')
t_data = data.loc[:, 'value'].values
result = adfuller(t_data)
print("The result of adfuller function:",result)
print('ADF Statistic:', result[0])
print('p-value:', result[1])
输出
以下是执行上述程序后生成的输出:
The result of adfuller function: (3.145185689306744, 1.0, 15, 188, {'1%': -3.465620397124192, '5%': -2.8770397560752436, '10%': -2.5750324547306476}, 549.6705685364172)
ADF Statistic: 3.145185689306744
p-value: 1.0
KPSS检验
另一个检查单位根的检验是KPSS检验。它的缩写是Kwiatkowski-Phillips-Schmidt-Shin。我们在statsmodels包中有一个名为kpss()的函数,用于检查时间序列数据中的单位根。
示例
以下是查找时间序列数据中单位根的示例。
from statsmodels.tsa.stattools import kpss
import pandas as pd
data = pd.read_csv('https://raw.githubusercontent.com/selva86/datasets/master/a10.csv',parse_dates=['date'], index_col='date')
t_data = data.loc[:, 'value'].values
from statsmodels.tsa.stattools import kpss
result = kpss(data)
print("The result of kpss function:",result)
print('KPSS Statistic:', result[0])
print('p-value:', result[1])
输出
以下是statsmodels包中kpss()函数的输出。
The result of kpss function: (2.0131256386303322, 0.01, 9, {'10%': 0.347, '5%': 0.463, '2.5%': 0.574, '1%': 0.739})
KPSS Statistic: 2.0131256386303322
p-value: 0.01
滚动统计
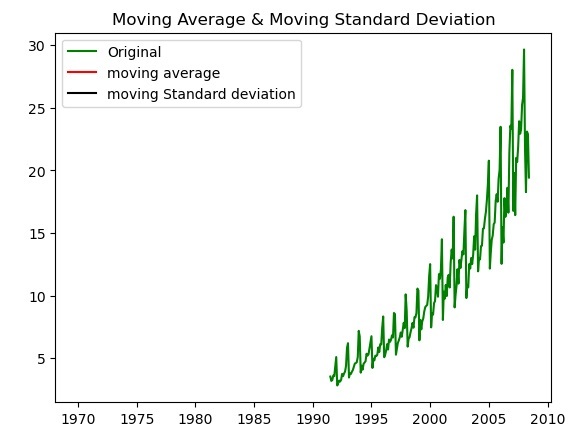
检查时间序列数据平稳性的另一种方法是绘制给定时间序列数据的移动平均数和移动标准差,并检查数据是否保持不变。如果图中的数据随时间变化,则时间序列数据是非平稳的。
示例
以下是如何使用matplotlib库的plot()函数绘制移动平均数和移动标准差来检查数据变化的示例。
import pandas as pd
import matplotlib.pyplot as plt
data = pd.read_csv('https://raw.githubusercontent.com/selva86/datasets/master/a10.csv',parse_dates=['date'], index_col='date')
t_data = data.loc[:, 'value'].values
moving_avg = t_data.mean()
moving_std = t_data.std()
plt.plot(data, color='green', label='Original')
plt.plot(moving_avg, color='red', label='moving average')
plt.plot(moving_std, color='black', label='moving Standard deviation')
plt.legend(loc='best')
plt.title('Moving Average & Moving Standard Deviation')
plt.show()
输出
以下是通过绘制移动平均数和移动标准差来标准化时间序列数据的输出。

300 次浏览
