
 数据结构
数据结构 网络
网络 关系数据库管理系统(RDBMS)
关系数据库管理系统(RDBMS) 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C语言编程
C语言编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP如何在Selenium中使用XPath查找元素?
我们可以使用Selenium webdriver和xpath定位器来查找元素。
要使用xpath识别元素,表达式应为`//tagname[@attribute='value']`。
要使用xpath识别元素,表达式应为`//tagname[@class='value']`。xpath有两种类型:相对路径和绝对路径。绝对路径以`/`符号开头,从根节点开始到我们要识别的元素。
例如:
/html/body/div[1]/div/div[1]/a
相对xpath以`//`符号开头,不从根节点开始。例如:
//img[@alt='tutorialspoint']
让我们看看从根节点开始的高亮显示元素的html代码。
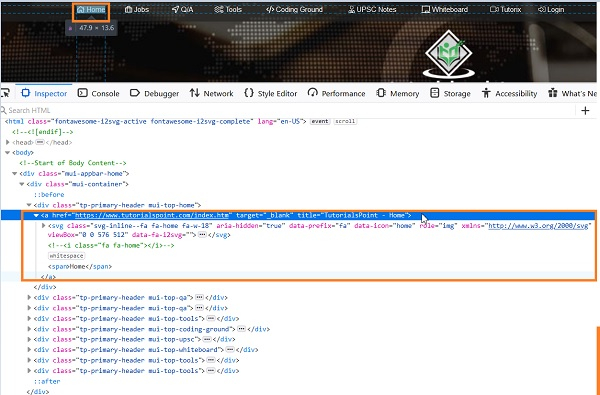
元素“Home”的绝对xpath是`/html/body/div[1]/div/div[1]/a`。
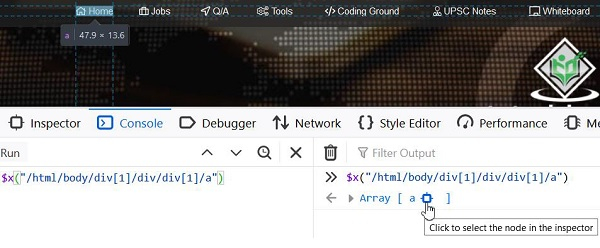
元素“Home”的相对xpath是`//a[@title='TutorialsPoint - Home']`。
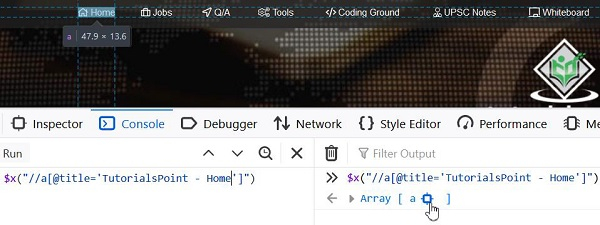
还有一些可用的函数可以帮助构建相对xpath表达式:
`text()` – 用于根据页面上可见的文本识别元素。xpath表达式为`//*[text()='Home']`。
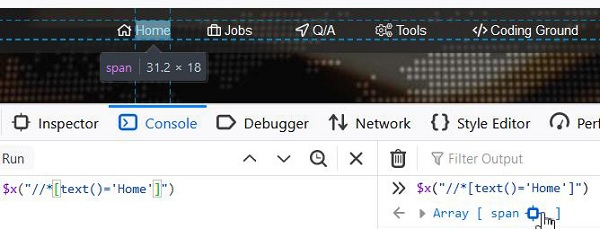
`starts-with()` – 用于识别其属性值以特定文本开头的元素。此函数通常用于属性值在每次页面加载时都会更改的情况。
让我们看看元素“Q/A”的html:
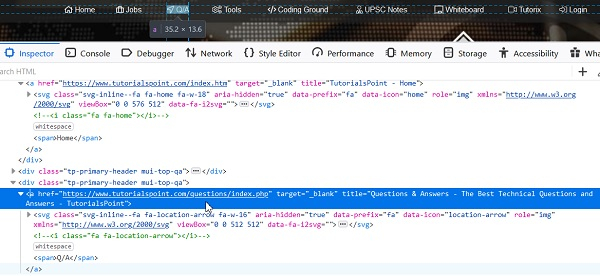
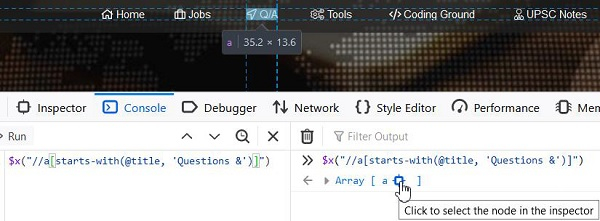
xpath表达式应为`//a[starts-with(@title, 'Questions &')]`。
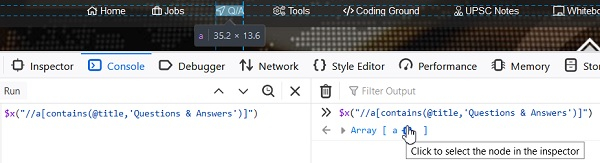
`contains()` - 它识别其属性值包含实际属性值子文本的元素。此函数通常用于属性值在每次页面加载时都会更改的情况。
xpath表达式为:`//a[contains(@title, 'Questions & Answers')]`。
语法
WebElement m = driver.findElement(By.xpath("//span[@class = 'cat-title']"));示例
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.firefox.FirefoxDriver;
import java.util.concurrent.TimeUnit;
public class LocatorXpath{
public static void main(String[] args) {
System.setProperty("webdriver.gecko.driver",
"C:\Users\ghs6kor\Desktop\Java\geckodriver.exe");
WebDriver driver = new FirefoxDriver();
//implicit wait
driver.manage().timeouts().implicitlyWait(5, TimeUnit.SECONDS);
//URL launch
driver.get("https://tutorialspoint.com/online_dev_tools.htm");
// identify element with xpath
WebElement n=driver.
findElement(By.xpath("//span[@class = 'cat-title']"));
String str = n.getText();
System.out.println("Text is : " + str);
driver.close();
}
}输出


更新于:2021年4月6日
7K+ 次浏览

广告