
 数据结构
数据结构 网络
网络 关系数据库管理系统 (RDBMS)
关系数据库管理系统 (RDBMS) 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C语言编程
C语言编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP如何处理机器学习中的类别不平衡问题
在本教程中,我们将学习如何在 ML 中处理类别不平衡问题。
介绍
一般来说,机器学习中的类别不平衡是指一种类型或观测值的类别数量高于另一种类型的情况。这是机器学习中的一个常见问题,涉及诸如欺诈检测、广告点击率预测、垃圾邮件检测、客户流失等任务。它对模型的准确性有很大影响。
类别不平衡的影响
在这种问题中,多数类在训练模型时会掩盖少数类。由于在这种情况下,与其他类别相比,一种类别的数量非常高(通常< 0.05%),因此训练出的模型大多会预测多数类。这会对准确性产生不利影响,结果容易出错。
那么,我们如何解决这个问题呢?让我们深入了解一些已被证明有效的技术。
如何处理类别不平衡
有 5 种方法可以用来处理类别不平衡问题。
1. 随机欠采样
在信用卡欺诈检测系统中,我们经常面临类别不平衡的问题,因为欺诈交易的数量非常低(有时不到 1%)。随机欠采样是一种简单的处理此问题的技术。在这种方法中,从多数类中删除大量数据点,以便平衡少数类。多数类和少数类的比例相当。
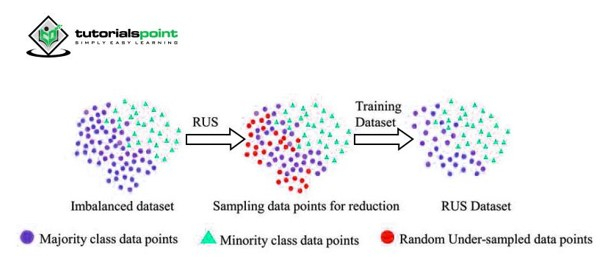
当我们有大量数据时,此方法非常有用。
此方法的一个缺点是它可能导致大量信息丢失,并可能产生不太准确的模型。
2. 随机过采样
在这种方法中,少数类被复制多次(以固定的整数比例),以便平衡多数类。我们应该记住在过采样之前使用 K 折交叉验证,以便在数据中引入适当的随机性以防止过拟合。
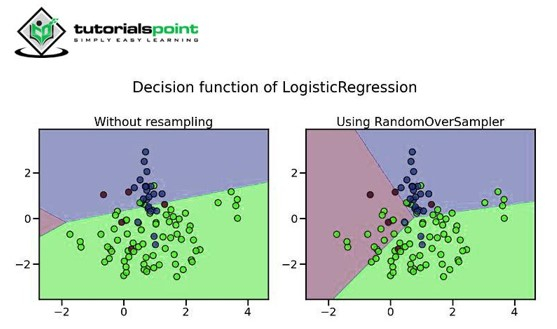
当我们只有少量数据时,此方法非常有用。
此方法的缺点是它可能导致过拟合,并且生成的模型不会很好地泛化。
3. 合成少数类过采样技术 (SMOTE)
SMOTE 是一种统计技术,可以以平衡的方式增加少数类中的样本。它从现有的少数类中生成新实例。它不会影响多数类。该算法从目标类及其 k 个最近邻中获取样本。然后,它通过结合目标类及其邻居的特征来创建样本。
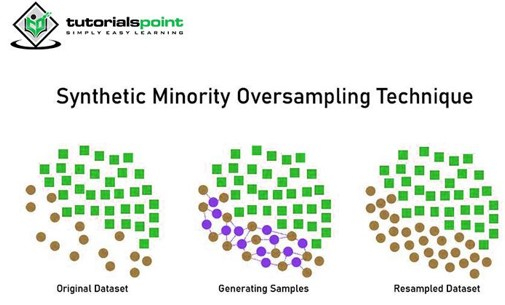
SMOTE 的优点是我们不仅仅是复制少数类,而是创建与原始样本不同的合成数据点。
SMOTE 有几个缺点:
很难确定最近邻的数量,并且最近邻的选择并不准确。
它可能会对噪声样本进行过采样。
4. 集成学习
在这种方法中,我们使用多个学习器或组合多个分类器的结果来产生所需的结果。事实证明,很多时候多个学习器比单个学习器产生更好的结果。
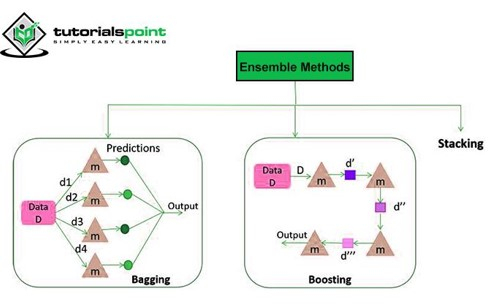
涉及的两种方法是 Bagging 和 Boosting。
Bagging
Bagging 方法被称为 Bootstrap 聚合。Bootstrap 是从总体中创建数据样本以估计总体参数的方法。在 Bagging 中,小型分类器是在从具有替换的数据集中获取的数据样本上进行训练的。然后聚合这些分类器的预测以产生最终结果。
Boosting
这是一种通过根据最近的分类调整观测值的权重来减少预测误差的方法。它倾向于增加错误分类观测值的权重。此模型根据先前模型产生的错误进行训练。这种迭代方法是高度并行的。
Bagging 的一个优点是它减少了模型的方差误差。
Boosting 的一个优点是它减少了模型的偏差误差。
选择正确的评估指标。
对于类别不平衡的数据集,选择准确性作为评估参数可能会适得其反。更好的指标是精确率或召回率或组合指标,如 F1 分数。虽然准确性指标似乎由于类别比例不当而受到不利影响,但精确率/召回率/F1 分数似乎能够很好地处理这个问题,如下面的关系式所示:
$$\mathrm{精确率 \:=\: \frac{真阳性}{真阳性\:+\:假阳性}}$$ $$\mathrm{召回率 \:=\: \frac{真阳性}{真阳性\:+\:假阴性}}$$F1 分数考虑了进行了多少正确的分类。
$$\mathrm{F1\:分数 \:=\: \frac{2\:*\:精确率\:*\:召回率}{精确率\:+\:召回率}}$$结论
因此,我们看到了类别不平衡如何严重影响基于模型性能的预测。处理此类问题有时可能会很繁琐,但正如我们在本文中所看到的,正确的技术结合适当的评估指标可以解决这个问题,从而提高模型预测的质量。

367 次查看
