
 数据结构
数据结构 网络
网络 关系数据库管理系统 (RDBMS)
关系数据库管理系统 (RDBMS) 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 编程
C 编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP使用 Google 的 Teachable Machine 进行图像分类
在本文中,您将了解机器学习、图像分类以及如何使用 Google 的 Teachable Machine 来训练模型。
机器学习
机器学习是人工智能 (AI) 的一个子集,用于开发模型和算法,通过这些模型和算法,我们可以使我们的计算机学习并做出决策,而无需对其进行显式编程。这是一种有效的方法,可以教会机器从给定数据中学习并随着时间的推移提高性能。计算机可以通过显示场景的数据来学习任务并做出预测或找到任何模式,这些数据显示了我们下一步应该采取什么措施。
图像分类
图像分类是一种机器学习过程,通过该过程,我们将标签分配给图像。这在计算机视觉领域非常流行。通过对图像进行分类,我们可以使用模型来识别物体、活动、图像和场景。图像分类用于各种任务,例如人脸识别、物体检测。您可以在 Kaggle 平台上查看一些图像数据集。
Google 的 Teachable Machine
Google 的 Teachable Machine 为我们提供了一个基于 Web 的界面和工具,我们可以使用这些工具来训练用于图像分类的机器学习模型。
我们使用这些工具来识别物体、图像、场景和声音分类。此平台为我们提供了训练模型的功能,并将其导出到本地系统中,或者我们也可以免费将其发布到网上,以使用基于 URL 的服务器架构。
使用 Google Teachable Machine 创建图像分类项目的步骤
要使用 Teachable Machine,您首先需要创建一个项目。要创建项目,我们将访问 Google 的 Teachable Machine 网站并点击“开始”。

执行此步骤后,将打开一个新窗口,其中将显示三种项目类型:图像项目、音频项目和姿势项目。因此,我们想要创建图像分类模型,因此我们将选择“图像项目”选项。它会询问我们是否要使用标准图像模型或嵌入式图像模型,因此我们将选择“标准图像模型”。此处,标准图像模型将创建 TensorFlow 和移动机器学习模型,而嵌入式模型将创建嵌入式系统(如微控制器)的模型。

下一步,我们将创建与我们的分类相关的不同类别。我们将必须为类别添加名称并提供与该类别相关的图像。例如:我们想要创建“猫”类别,因此我们将提供猫的图像,类似地,对于“狗”类别,我们将提供与狗相关的图像。
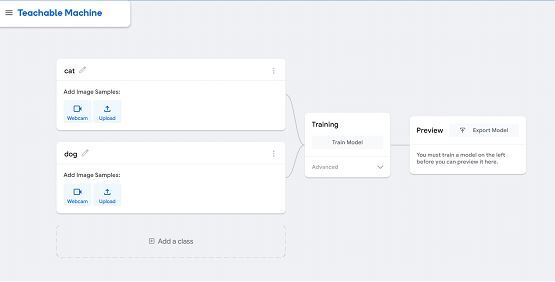
在这里,我们创建了“猫”和“狗”类别,您也可以根据需要添加更多类别。现在,我们将为此模型提供可训练的图像。对于此模型,我通过浏览网站保存了一些猫和狗的图像,并将其存储在我的本地计算机的不同文件夹中。

现在,我们将使用“上传”按钮并使用该选项从文件中选择图像并上传可用的猫和狗图像,我们将选择所有图像文件并上传该特定类别的所有图像。例如,对于“猫”,我们将仅上传与猫相关的图像,以便它能够正确地标记图像。

从下图中您可以看到,我们通过从文件中选择图像,将图像上传到这两个类别中。模型将标记在类名中给出的图像。
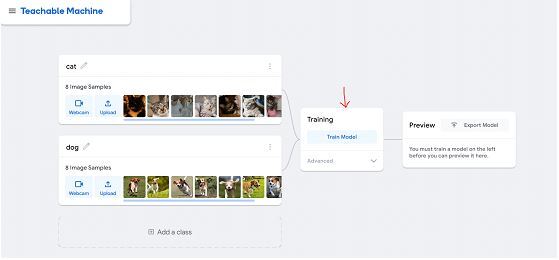
现在,我们将使用“训练模型”按钮开始基于提供的图像训练模型。Teachable Machine 将自动生成模型。当我们从训练选项中选择“高级”下拉菜单时,我们也可以单击并自定义训练要求,然后它将要求自定义“周期”、“批次大小”和“学习率”。
周期 - 一个周期意味着训练数据集中每个样本至少被输入一次。例如,如果周期为 20,则模型将通过整个数据集训练 20 次。因此,我们可以说更大的周期将更好地训练模型以预测图像。
批次大小 - 批次大小是在一次迭代/遍历中用于训练的一组样本图像。例如,我们有 50 张图像,我们的批次大小为 10,那么它将被分成 50/10=5 次迭代。这意味着在一次迭代中,它将使用 10 张图像来训练模型。所有 5 个批次完成后,将被视为 1 个周期的完成。
学习率 - 这是一个用于控制神经网络权重的超参数。
之后,我们将点击“训练模型”选项,它将需要一些时间来开始训练模型。

现在,它将提供通过将模型导出到本地文件来预览模型的选项。为了检查模型的工作原理,我们可以使用从文件中选择或使用相机选项的选项。因此,我选择了“文件”选项并选择了一张狗的图像,它将预测输出为“狗”。
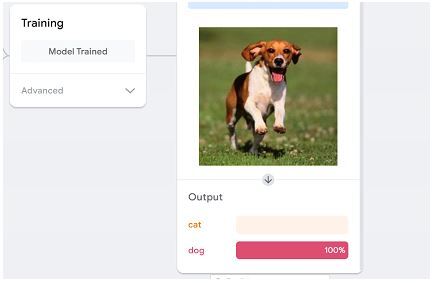
从上图中您可以看到,我们使用“从文件选择”选项选择了狗的图像,它预测输出为“狗”,置信度为 100%。
注意 - 如果我们对模型的性能不满意,则可以继续训练模型,直到它预测得更好。训练完成后,我们可以下载模型或使用链接。
以下是一些使用 Teachable Machine 的技巧 -
使用高质量的图像。我们应该为模型提供高质量的图像,图像质量越高,模型的性能就越好。
标记图像。我们应该使用正确的类别仔细标记我们的数据图像。
训练我们的模型更长时间。正如您所了解的,周期数越多,模型的性能就越好。
频繁测试我们的模型。我们应该执行模型测试以了解其性能如何,并且可以根据需要进行调整。
结论
因此,我们了解了使我们的计算机学习的机器学习,了解了我们可以使用图像分类训练模型以识别物体的知识,并学习了如何使用 Google 的 Teachable Machine。此平台使构建自定义图像分类的过程变得非常简单。即使没有广泛编码知识的人也可以创建自己的模型。我们可以标记图像、训练模型并在 Python 应用程序中使用它来创建非常有效的图像识别系统。我们通过遵循这些过程看到了所有过程。我们创建了我们的模型,并使用一个示例检查了模型的准确性。您也可以在此项目中添加更多类别,并提供与该特定类别相关的图像,这将作为其他标签。使用 Google 的 Teachable Machine,我们还可以创建其他模型,例如基于音频的模型,可用于构建语音识别应用程序,我们还可以创建基于姿势的模型,可用于识别瑜伽或身体运动等不同的身体姿势。因此,您学习了如何在没有繁琐的编码过程的情况下创建自己的模型。

389 次浏览
