
 数据结构
数据结构 网络
网络 关系数据库管理系统
关系数据库管理系统 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C语言编程
C语言编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHPCNN图像分类入门指南(Python实现)
卷积神经网络(CNN)是一种专门设计用于处理具有网格拓扑结构的数据(例如图像)的神经网络。CNN由多个卷积层和池化层组成,这些层旨在从输入数据中提取特征,以及一个全连接层,用于对特征进行分类。
CNN的主要优势在于,它们能够自动学习与手头任务最相关的特征,而不是依赖于手动特征工程。这使得它们特别适合于图像分类任务,在这些任务中,用于分类的重要特征可能事先未知。
在本文中,我们将详细概述CNN,包括其架构和背后的关键概念。然后,我们将演示如何使用流行的Keras库在Python中实现用于图像分类的CNN。
CNN架构
CNN由许多不同的层组成,每层执行特定的功能。CNN中最常见的层类型是卷积层、池化层和全连接层。
卷积层
卷积层是CNN的主要构建块。它们将卷积运算应用于输入数据,这涉及到在输入数据上滑动一个小矩阵(称为核或过滤器)并计算核中的条目与输入数据之间的点积。这会产生一个新的、转换后的特征图,该特征图捕获输入数据中条目之间的关系。
卷积层的参数包括核的大小、步长(即核每次移动的像素数)和填充(即添加到输入数据边界处的像素数,以确保核可以应用于输入数据的每个部分)。
池化层
池化层用于通过对卷积层产生的特征图应用池化操作来对输入数据进行下采样。最常见的池化类型是最大池化和平均池化,它们分别获取一组输入的最大值和平均值。
池化层通常用于减少输入数据的空间维度(即宽度和高度),这可以减少模型中的参数数量并提高其泛化性能。
全连接层
全连接层用于对卷积层和池化层提取的特征进行分类。它们由多个神经元组成,每个神经元都连接到前一层中的每个神经元。全连接层的输出是一组类别分数,可用于预测输入数据的类别标签。
卷积神经网络(CNN)的典型架构如下所示:
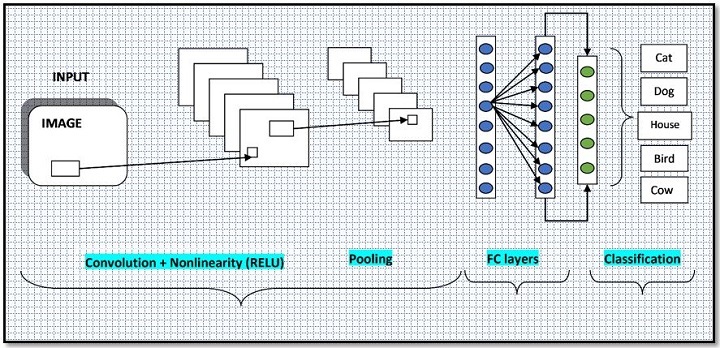
使用CNN进行图像分类
为了有效地使用CNN进行图像分类,有一些关键概念需要理解。
过滤器和内核
如上所述,卷积层将内核或过滤器应用于输入数据以生成转换后的特征图。内核的大小决定了在卷积运算的每个步骤中考虑的输入数据区域的大小。例如,3x3内核在每个步骤中考虑输入数据的3x3区域。
内核的权重在训练过程中学习,并用于从输入数据中提取特征。不同的内核可用于提取不同类型的特征,例如边缘、角点或纹理。
步长
步长决定了内核应用于输入数据的步长。较大的步长会导致较小的输出特征图,因为内核应用于输入数据中的较少位置。另一方面,较小的步长会导致较大的输出特征图,因为内核应用于输入数据中的更多位置。
填充
填充是在应用卷积运算之前添加到输入数据边界处的像素数。填充通常用于确保输出特征图与输入数据具有相同的空间维度,这对于某些类型的下游处理非常有用。
池化
池化是对卷积层的输出应用的下采样操作。它减少了数据的空间维度,通常用于减少模型中的参数数量并提高其泛化性能。
在Python中实现用于图像分类的CNN
现在我们已经对CNN有了基本的了解,让我们看看如何使用流行的Keras库在Python中实现用于图像分类的CNN。
首先,我们需要安装所需的库。我们将使用以下库:
NumPy - 用于处理数组和矩阵的库
Matplotlib - 用于创建绘图和图表
Keras - 用于构建和训练神经网络的高级库
您可以使用pip安装这些库:
pip install numpy matplotlib keras
接下来,我们需要导入我们将要使用的库:
import numpy as np import matplotlib.pyplot as plt from tensorflow import keras from tensorflow.keras.datasets import mnist from tensorflow.keras.utils import to_categorical from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
我们将在此示例中使用MNIST数据集,该数据集包含60,000个训练图像和10,000个手写数字的测试图像。这些图像为28×28像素,每个像素由0到255之间的灰度值表示。任务的目标是将图像分类为10个类别之一(即数字0-9)。
首先,我们需要加载数据集并预处理数据。我们可以使用以下代码:
# Load the dataset (X_train, y_train), (X_test, y_test) = mnist.load_data() # Pre-process the data X_train = X_train.astype(np.float32) / 255.0 X_test = X_test.astype(np.float32) / 255.0 # Reshape the data to add a channel dimension X_train = np.expand_dims(X_train, axis=-1) X_test = np.expand_dims(X_test, axis=-1) # One-hot encode the labels y_train = to_categorical(y_train, num_classes=10) y_test = to_categorical(y_test, num_classes=10)
接下来,我们需要定义模型。我们将使用Sequential模型,它允许我们将模型定义为一系列层。我们将首先添加一个具有32个大小为3x3的过滤器的卷积层,然后添加一个池大小为2×2的最大池化层。然后,我们将添加一个丢弃率为0.25的丢弃层,这将在训练期间随机丢弃25%的单元,以防止过拟合。
然后,我们将添加一个具有64个大小为3×3的过滤器的第二个卷积层,然后添加另一个池大小为2×2的最大池化层。我们还将添加一个丢弃率为0.25的丢弃层。
最后,我们将展平第二个池化层的输出,并添加一个具有128个单元的全连接层,然后添加一个具有10个单元的输出层(每个类别一个)。
我们可以使用以下代码定义模型:
# Define the model model = Sequential() model.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=(28, 28, 1))) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.25)) model.add(Conv2D(64, kernel_size=(3, 3), activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(128, activation='relu')) model.add(Dense(10, activation='softmax'))
接下来,我们需要通过指定要使用的损失函数、优化器和指标来编译模型。对于此示例,我们将使用分类交叉熵损失、Adam优化器和准确率指标。
# Compile the model model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
最后,我们可以通过调用fit方法并指定训练数据、时期数(即模型将看到数据的次数)和批大小(即每个梯度更新的样本数)来训练模型。
# Train the model history = model.fit(X_train, y_train, epochs=10, batch_size=32, validation_data=(X_test, y_test))
运行以上代码片段后,输出如下:
Epoch 1/10 1875/1875 [==============================] - 38s 20ms/step - loss: 0.1680 - accuracy: 0.9481 - val_loss: 0.0556 - val_accuracy: 0.9823 Epoch 2/10 1875/1875 [==============================] - 42s 22ms/step - loss: 0.0608 - accuracy: 0.9811 - val_loss: 0.0374 - val_accuracy: 0.9880 Epoch 3/10 1875/1875 [==============================] - 42s 22ms/step - loss: 0.0470 - accuracy: 0.9854 - val_loss: 0.0292 - val_accuracy: 0.9903 Epoch 4/10 1875/1875 [==============================] - 44s 24ms/step - loss: 0.0370 - accuracy: 0.9889 - val_loss: 0.0260 - val_accuracy: 0.9908 Epoch 5/10 1875/1875 [==============================] - 43s 23ms/step - loss: 0.0311 - accuracy: 0.9903 - val_loss: 0.0246 - val_accuracy: 0.9913 Epoch 6/10 1875/1875 [==============================] - 43s 23ms/step - loss: 0.0267 - accuracy: 0.9911 - val_loss: 0.0278 - val_accuracy: 0.9910 Epoch 7/10 1875/1875 [==============================] - 40s 21ms/step - loss: 0.0233 - accuracy: 0.9923 - val_loss: 0.0261 - val_accuracy: 0.9926 Epoch 8/10 1875/1875 [==============================] - 41s 22ms/step - loss: 0.0193 - accuracy: 0.9939 - val_loss: 0.0268 - val_accuracy: 0.9917 Epoch 9/10 1875/1875 [==============================] - 41s 22ms/step - loss: 0.0188 - accuracy: 0.9941 - val_loss: 0.0252 - val_accuracy: 0.9916 Epoch 10/10 1875/1875 [==============================] - 41s 22ms/step - loss: 0.0169 - accuracy: 0.9945 - val_loss: 0.0314 - val_accuracy: 0.9909
训练完成后,我们可以通过调用evaluate方法在测试数据上评估模型:
# Evaluate the model
loss, accuracy = model.evaluate(X_test, y_test)
print("Loss: ", loss)
print("Accuracy: ", accuracy)
运行以上代码片段后,输出如下:
313/313 [==============================] - 1s 5ms/step - loss: 0.0314 - accuracy: 0.9909 Loss: 0.031392790377140045 Accuracy: 0.9908999800682068
我们还可以通过从history对象中提取准确率历史记录来绘制训练和验证准确率随训练过程的变化图:
# Extract the accuracy history
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
# Plot the accuracy history
plt.plot(acc)
plt.plot(val_acc)
plt.title('Model Accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
它将绘制训练和验证准确率如下所示:

提高性能
为了进一步提高CNN的性能,您可以考虑以下提示:
微调架构 - 有许多不同的方法来设计CNN,最适合您的任务的架构将取决于数据的特定特征。您可以尝试使用不同的层数、内核大小、步长等,以查看什么最适合您的任务。
使用数据增强 - 数据增强是一种通过对现有数据应用转换来生成额外训练数据的技术。这对于提高泛化性能很有用,尤其是在训练数据有限的情况下。
使用预训练模型 - 预训练模型是在大型数据集(如ImageNet)上训练的CNN,可以作为您自己任务的起点。迁移学习,即在您自己的数据集上微调预训练模型,是一种强大的技术,可以大大加快训练速度并提高性能。
优化超参数 - CNN的性能还可以通过优化超参数来提高,例如学习率、批大小等。您可以使用网格搜索或随机搜索等技术来找到最适合您任务的一组超参数。
通过遵循这些提示并将其应用于您自己的CNN,您应该能够在各种图像分类任务中获得良好的性能。
结论
本文详细概述了卷积神经网络(CNN),并演示了如何使用Keras库在Python中实现CNN进行图像分类。我们讨论了CNN背后的关键概念,包括过滤器和内核、步长、填充和池化,并解释了如何利用这些概念从输入数据中提取特征并对其进行分类。
我们还展示了如何微调CNN的架构和超参数,使用数据增强来提高泛化能力,以及使用预训练模型来加快训练速度和提高性能。
通过遵循本文中概述的技术,您应该能够在各种图像分类任务中取得良好的性能。总的来说,CNN是分析和分类图像数据的强大工具,通过正确的方法,它们可以用来解决计算机视觉和机器学习中的各种问题。

1K+ 浏览量
