- LISP 教程
- LISP - 首页
- LISP - 概述
- LISP - 环境
- LISP - 程序结构
- LISP - 基本语法
- LISP - 数据类型
- LISP - 宏
- LISP - 变量
- LISP - 常量
- LISP - 运算符
- LISP - 决策
- LISP - 循环
- LISP - 函数
- LISP - 谓词
- LISP - 数字
- LISP - 字符
- LISP - 数组
- LISP - 字符串
- LISP - 序列
- LISP - 列表
- LISP - 符号
- LISP - 向量
- LISP - 集合
- LISP - 树
- LISP - 哈希表
- LISP - 输入与输出
- LISP - 文件 I/O
- LISP - 结构体
- LISP - 包
- LISP - 错误处理
- LISP - CLOS
- LISP 有用资源
- Lisp - 快速指南
- Lisp - 有用资源
- Lisp - 讨论
LISP 快速指南
LISP - 概述
John McCarthy 在 1958 年发明了 LISP,这紧随 FORTRAN 的开发之后。它最初由 Steve Russell 在 IBM 704 计算机上实现。
它特别适用于人工智能程序,因为它可以有效地处理符号信息。
Common Lisp 起源于 20 世纪 80 年代和 90 年代,试图统一几个实现组的工作,这些组是 Maclisp 的继任者,如 ZetaLisp 和 NIL(Lisp 的新实现)等。
它作为一种通用语言,可以轻松地扩展到特定实现。
用 Common LISP 编写的程序不依赖于特定于机器的特性,例如字长等。
Common LISP 的特性
它是机器无关的
它使用迭代设计方法,并且易于扩展。
它允许动态更新程序。
它提供高级调试。
它提供高级面向对象编程。
它提供了一个方便的宏系统。
它提供了广泛的数据类型,例如对象、结构体、列表、向量、可调整数组、哈希表和符号。
它是基于表达式的。
它提供了一个面向对象的条件系统。
它提供了一个完整的 I/O 库。
它提供了广泛的控制结构。
用 LISP 构建的应用程序
用 Lisp 构建的大型成功应用程序。
Emacs
G2
AutoCad
Igor Engraver
Yahoo Store
LISP - 环境设置
本地环境设置
如果您仍然希望为 Lisp 编程语言设置您的环境,则需要您的计算机上有以下两个软件:(a) 文本编辑器和 (b) Lisp 执行器。
文本编辑器
这将用于键入您的程序。一些编辑器的示例包括 Windows 记事本、OS Edit 命令、Brief、Epsilon、EMACS 和 vim 或 vi。
文本编辑器的名称和版本在不同的操作系统上可能有所不同。例如,Notepad 将在 Windows 上使用,而 vim 或 vi 可以在 Windows 以及 Linux 或 UNIX 上使用。
您使用编辑器创建的文件称为源文件,其中包含程序源代码。Lisp 程序的源文件通常以扩展名“.lisp”命名。
在开始编程之前,请确保您已准备好一个文本编辑器,并且您有足够的经验编写计算机程序,将其保存在文件中,最后执行它。
Lisp 执行器
源文件中编写的源代码是程序的人类可读源代码。它需要“执行”,才能转换为机器语言,以便您的 CPU 能够根据给定的指令实际执行程序。
此 Lisp 编程语言将用于将您的源代码执行为最终的可执行程序。我假设您具备编程语言的基本知识。
CLISP 是 GNU Common LISP 的多架构编译器,用于在 Windows 中设置 LISP。Windows 版本在 Windows 下使用 MingW 模拟 unix 环境。安装程序会处理此问题并自动将 clisp 添加到 Windows PATH 变量中。
您可以从此处获取适用于 Windows 的最新 CLISP - https://sourceforge.net/projects/clisp/files/latest/download

默认情况下,它会在“开始”菜单中创建一个快捷方式,用于逐行解释器。
如何使用 CLISP
在安装过程中,如果您选择选项(推荐),则clisp会自动添加到您的 PATH 变量中。这意味着您可以简单地打开一个新的命令提示符窗口并键入“clisp”以启动编译器。
要运行 *.lisp 或 *.lsp 文件,只需使用 −
clisp hello.lisp
LISP - 程序结构
LISP 表达式称为符号表达式或 s 表达式。s 表达式由三个有效对象组成,原子、列表和字符串。
任何 s 表达式都是一个有效的程序。
LISP 程序要么在解释器上运行,要么作为编译代码运行。
解释器在重复循环中检查源代码,该循环也称为读取-求值-打印循环 (REPL)。它读取程序代码,对其进行求值,并打印程序返回的值。
一个简单的程序
让我们编写一个 s 表达式来找到三个数字 7、9 和 11 的总和。为此,我们可以在解释器提示符下键入。
(+ 7 9 11)
LISP 返回结果 −
27
如果您想将同一个程序作为编译代码运行,则创建一个名为 myprog.lisp 的 LISP 源代码文件,并在其中键入以下代码。
(write (+ 7 9 11))
当您单击“执行”按钮或键入 Ctrl+E 时,LISP 会立即执行它,并返回的结果为 −
27
LISP 使用前缀表示法
您可能已经注意到 LISP 使用前缀表示法。
在上述程序中,+ 符号作为求和过程的函数名称。
在前缀表示法中,运算符写在其操作数之前。例如,表达式,
a * ( b + c ) / d
将写成 −
(/ (* a (+ b c) ) d)
让我们再举一个例子,让我们编写将 60o F 的华氏温度转换为摄氏温度的代码 −
此转换的数学表达式将为 −
(60 * 9 / 5) + 32
创建一个名为 main.lisp 的源代码文件,并在其中键入以下代码。
(write(+ (* (/ 9 5) 60) 32))
当您单击“执行”按钮或键入 Ctrl+E 时,LISP 会立即执行它,并返回的结果为 −
140
LISP 程序的求值
LISP 程序的求值有两个部分 −
由读取器程序将程序文本转换为 Lisp 对象
根据这些对象以评估器程序的形式实现语言的语义
求值过程采取以下步骤 −
读取器将字符字符串转换为 LISP 对象或s 表达式。
评估器定义 Lisp形式的语法,这些形式由 s 表达式构建而成。这第二级的求值定义了一个语法,该语法确定哪些s 表达式是 LISP 形式。
评估器充当一个函数,它以一个有效的 LISP 形式作为参数并返回一个值。这就是我们将 LISP 表达式放在括号中的原因,因为我们将整个表达式/形式作为参数发送给评估器。
“Hello World”程序
学习一门新的编程语言,直到你学会用这种语言问候全世界,才算真正开始,对吧!
所以,请创建一个名为 main.lisp 的新源代码文件,并在其中键入以下代码。
(write-line "Hello World") (write-line "I am at 'Tutorials Point'! Learning LISP")
当您单击“执行”按钮或键入 Ctrl+E 时,LISP 会立即执行它,并返回的结果为 −
Hello World I am at 'Tutorials Point'! Learning LISP
LISP - 基本语法
LISP 中的基本构建块
LISP 程序由三个基本构建块组成 −
- 原子
- 列表
- 字符串
原子是一个数字或连续字符的字符串。它包括数字和特殊字符。
以下是一些有效原子的示例 −
hello-from-tutorials-point name 123008907 *hello* Block#221 abc123
列表是括号中包含的原子和/或其他列表的序列。
以下是一些有效列表的示例 −
( i am a list) (a ( a b c) d e fgh) (father tom ( susan bill joe)) (sun mon tue wed thur fri sat) ( )
字符串是由双引号括起来的一组字符。
以下是一些有效字符串的示例 −
" I am a string" "a ba c d efg #$%^&!" "Please enter the following details :" "Hello from 'Tutorials Point'! "
添加注释
分号符号 (;) 用于指示注释行。
例如,
(write-line "Hello World") ; greet the world ; tell them your whereabouts (write-line "I am at 'Tutorials Point'! Learning LISP")
当您单击“执行”按钮或键入 Ctrl+E 时,LISP 会立即执行它,并返回的结果为 −
Hello World I am at 'Tutorials Point'! Learning LISP
在继续下一步之前的一些注意事项
以下是一些需要注意的重要事项 −
LISP 中的基本数值运算为 +、-、* 和 /
LISP 将函数调用 f(x) 表示为 (f x),例如 cos(45) 写成 cos 45
LISP 表达式不区分大小写,cos 45 或 COS 45 相同。
LISP 尝试对所有内容进行求值,包括函数的参数。只有三种类型的元素是常量,并且始终返回它们自己的值
数字
字母t,代表逻辑真。
值nil,代表逻辑假,以及空列表。
关于 LISP 形式的更多信息
在上一章中,我们提到 LISP 代码的求值过程采取以下步骤。
读取器将字符字符串转换为 LISP 对象或s 表达式。
评估器定义 Lisp形式的语法,这些形式由 s 表达式构建而成。这第二级的求值定义了一个语法,该语法确定哪些 s 表达式是 LISP 形式。
现在,LISP 形式可以是。
- 一个原子
- 一个空列表或非列表
- 任何以符号作为其第一个元素的列表
评估器充当一个函数,它以一个有效的 LISP 形式作为参数并返回一个值。这就是我们将LISP 表达式放在括号中的原因,因为我们将整个表达式/形式作为参数发送给评估器。
LISP 中的命名约定
名称或符号可以包含任意数量的字母数字字符,除了空格、开括号和闭括号、双引号和单引号、反斜杠、逗号、冒号、分号和竖线。要在名称中使用这些字符,您需要使用转义字符 (\)。
名称可以包含数字,但不能完全由数字组成,因为那样它将被读取为数字。类似地,名称可以包含句点,但不能完全由句点组成。
单引号的使用
LISP 会对所有内容进行求值,包括函数参数和列表成员。
有时,我们需要按字面意思获取原子或列表,并且不希望它们被求值或被视为函数调用。
为此,我们需要在原子或列表前面加上单引号。
以下示例演示了这一点。
创建一个名为 main.lisp 的文件,并将以下代码键入其中。
(write-line "single quote used, it inhibits evaluation") (write '(* 2 3)) (write-line " ") (write-line "single quote not used, so expression evaluated") (write (* 2 3))
当您单击“执行”按钮或键入 Ctrl+E 时,LISP 会立即执行它,并返回的结果为 −
single quote used, it inhibits evaluation (* 2 3) single quote not used, so expression evaluated 6
LISP - 数据类型
在 LISP 中,变量没有类型,但数据对象有。
LISP 数据类型可以分类为。
标量类型− 例如,数字类型、字符、符号等。
数据结构− 例如,列表、向量、位向量和字符串。
任何变量都可以将其值作为任何 LISP 对象,除非您已明确声明它。
虽然没有必要为 LISP 变量指定数据类型,但是,它有助于某些循环扩展、方法声明和其他我们将在后续章节中讨论的情况。
数据类型按层次结构排列。数据类型是一组 LISP 对象,许多对象可能属于这样一个集合。
typep谓词用于查找对象是否属于特定类型。
type-of函数返回给定对象的类型。
LISP 中的类型说明符
类型说明符是系统定义的数据类型的符号。
| 数组 | 定点整数 | 包 | 简单字符串 |
| 原子 | 浮点数 | 路径名 | 简单向量 |
| 大整数 | 函数 | 随机状态 | 单精度浮点数 |
| 比特 | 哈希表 | 有理数 | 标准字符 |
| 比特向量 | 整数 | 有理数 | 流 |
| 字符 | 关键字 | 读表 | 字符串 |
| [通用] | 列表 | 序列 | [字符串字符] |
| 编译后的函数 | 长浮点数 | 短浮点数 | 符号 |
| 复数 | 空 | 有符号字节 | 真 |
| cons单元 | 空 | 简单数组 | 无符号字节 |
| 双精度浮点数 | 数字 | 简单比特向量 | 向量 |
除了这些系统定义的类型外,您还可以创建自己的数据类型。当使用defstruct函数定义结构类型时,结构类型的名称成为有效的类型符号。
示例 1
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(setq x 10) (setq y 34.567) (setq ch nil) (setq n 123.78) (setq bg 11.0e+4) (setq r 124/2) (print x) (print y) (print n) (print ch) (print bg) (print r)
当您单击“执行”按钮或键入 Ctrl+E 时,LISP 会立即执行它,并返回的结果为 −
10 34.567 123.78 NIL 110000.0 62
示例 2
接下来,让我们检查前面示例中使用的变量的类型。创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(defvar x 10) (defvar y 34.567) (defvar ch nil) (defvar n 123.78) (defvar bg 11.0e+4) (defvar r 124/2) (print (type-of x)) (print (type-of y)) (print (type-of n)) (print (type-of ch)) (print (type-of bg)) (print (type-of r))
当您单击“执行”按钮或键入 Ctrl+E 时,LISP 会立即执行它,并返回的结果为 −
(INTEGER 0 281474976710655) SINGLE-FLOAT SINGLE-FLOAT NULL SINGLE-FLOAT (INTEGER 0 281474976710655)
LISP - 宏
宏允许您扩展标准LISP的语法。
从技术上讲,宏是一个函数,它以s表达式作为参数,并返回一个LISP形式,然后对该形式进行求值。
定义宏
在LISP中,命名宏是使用另一个名为defmacro的宏定义的。定义宏的语法如下:
(defmacro macro-name (parameter-list)) "Optional documentation string." body-form
宏定义包括宏的名称、参数列表、可选的文档字符串以及定义宏要执行的任务的Lisp表达式的代码体。
示例
让我们编写一个名为setTo10的简单宏,它将接收一个数字并将其值设置为10。
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(defmacro setTo10(num) (setq num 10)(print num)) (setq x 25) (print x) (setTo10 x)
当您单击“执行”按钮或键入 Ctrl+E 时,LISP 会立即执行它,并返回的结果为 −
25 10
LISP - 变量
在LISP中,每个变量都由一个符号表示。变量的名称是符号的名称,它存储在符号的存储单元中。
全局变量
全局变量在整个LISP系统中具有永久值,并且保持有效,直到指定新值。
全局变量通常使用defvar结构声明。
例如
(defvar x 234) (write x)
当您单击“执行”按钮或键入Ctrl+E时,LISP会立即执行它,并返回结果
234
由于LISP中没有变量的类型声明,因此您可以使用setq结构直接为符号指定值。
例如
->(setq x 10)
上述表达式将值10赋给变量x。您可以使用符号本身作为表达式来引用变量。
symbol-value函数允许您提取存储在符号存储位置的值。
例如
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(setq x 10) (setq y 20) (format t "x = ~2d y = ~2d ~%" x y) (setq x 100) (setq y 200) (format t "x = ~2d y = ~2d" x y)
当您单击“执行”按钮或键入Ctrl+E时,LISP会立即执行它,并返回结果。
x = 10 y = 20 x = 100 y = 200
局部变量
局部变量在给定的过程中定义。在函数定义中作为参数命名的参数也是局部变量。局部变量仅在相应的函数内可访问。
与全局变量一样,局部变量也可以使用setq结构创建。
还有另外两个结构 - let 和 prog 用于创建局部变量。
let结构具有以下语法。
(let ((var1 val1) (var2 val2).. (varn valn))<s-expressions>)
其中var1、var2、..varn是变量名,val1、val2、..valn是分配给相应变量的初始值。
当执行let时,每个变量都被分配相应的值,最后对s表达式进行求值。返回最后求值的表达式的值。
如果您不为变量包含初始值,则将其分配给nil。
示例
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(let ((x 'a) (y 'b)(z 'c)) (format t "x = ~a y = ~a z = ~a" x y z))
当您单击“执行”按钮或键入Ctrl+E时,LISP会立即执行它,并返回结果。
x = A y = B z = C
prog结构也将其第一个参数作为局部变量列表,后面跟着prog的主体,以及任意数量的s表达式。
prog函数按顺序执行s表达式的列表,并返回nil,除非它遇到名为return的函数调用。然后对return函数的参数进行求值并返回。
示例
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(prog ((x '(a b c))(y '(1 2 3))(z '(p q 10))) (format t "x = ~a y = ~a z = ~a" x y z))
当您单击“执行”按钮或键入Ctrl+E时,LISP会立即执行它,并返回结果。
x = (A B C) y = (1 2 3) z = (P Q 10)
LISP - 常量
在LISP中,常量是程序执行期间其值永远不会改变的变量。常量使用defconstant结构声明。
示例
以下示例显示了声明全局常量PI,以及随后在名为area-circle的函数中使用此值来计算圆的面积。
defun结构用于定义函数,我们将在函数章节中详细介绍它。
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(defconstant PI 3.141592) (defun area-circle(rad) (terpri) (format t "Radius: ~5f" rad) (format t "~%Area: ~10f" (* PI rad rad))) (area-circle 10)
当您单击“执行”按钮或键入Ctrl+E时,LISP会立即执行它,并返回结果。
Radius: 10.0 Area: 314.1592
LISP - 运算符
运算符是一个符号,它告诉编译器执行特定的数学或逻辑操作。LISP允许对数据进行大量操作,这些操作由各种函数、宏和其他结构支持。
允许对数据执行的操作可以分类为:
- 算术运算
- 比较运算
- 逻辑运算
- 按位运算
算术运算
下表显示了LISP支持的所有算术运算符。假设变量A持有10,变量B持有20,则:
| 运算符 | 描述 | 示例 |
|---|---|---|
| + | 将两个操作数相加 | (+A B)将得到30 |
| - | 从第一个操作数中减去第二个操作数 | (- A B)将得到-10 |
| * | 将两个操作数相乘 | (* A B)将得到200 |
| / | 将分子除以分母 | (/ B A)将得到2 |
| mod,rem | 模运算符和整数除法后的余数 | (mod B A )将得到0 |
| incf | 增量运算符将整数的值增加指定的第二个参数 | (incf A 3)将得到13 |
| decf | 减量运算符将整数的值减少指定的第二个参数 | (decf A 4)将得到9 |
比较运算
下表显示了LISP支持的所有关系运算符,这些运算符用于比较数字之间的大小。但是,与其他语言中的关系运算符不同,LISP比较运算符可以接受两个以上的操作数,并且它们仅对数字起作用。
假设变量A持有10,变量B持有20,则:
| 运算符 | 描述 | 示例 |
|---|---|---|
| = | 检查操作数的值是否都相等,如果是,则条件变为真。 | (= A B)不为真。 |
| /= | 检查操作数的值是否都不同,如果值不相等,则条件变为真。 | (/= A B)为真。 |
| > | 检查操作数的值是否单调递减。 | (> A B)不为真。 |
| < | 检查操作数的值是否单调递增。 | (< A B)为真。 |
| >= | 检查任何左侧操作数的值是否大于或等于其右侧下一个操作数的值,如果是,则条件变为真。 | (>= A B)不为真。 |
| <= | 检查任何左侧操作数的值是否小于或等于其右侧操作数的值,如果是,则条件变为真。 | (<= A B)为真。 |
| max | 它比较两个或多个参数并返回最大值。 | (max A B)返回20 |
| min | 它比较两个或多个参数并返回最小值。 | (min A B)返回10 |
布尔值的逻辑运算
Common LISP提供了三个逻辑运算符:and、or和not,它们对布尔值进行操作。假设A的值为nil,B的值为5,则:
| 运算符 | 描述 | 示例 |
|---|---|---|
| and | 它接受任意数量的参数。参数从左到右求值。如果所有参数都求值为非nil,则返回最后一个参数的值。否则返回nil。 | (and A B)将返回NIL。 |
| or | 它接受任意数量的参数。参数从左到右求值,直到一个参数求值为非nil,在这种情况下,返回该参数的值,否则返回nil。 | (or A B)将返回5。 |
| not | 它接受一个参数,如果参数求值为nil,则返回t。 | (not A)将返回T。 |
数字的按位运算
按位运算符对位进行操作,并执行逐位运算。按位与、或和异或运算的真值表如下:
| p | q | p and q | p or q | p xor q |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 1 | 1 |
| 1 | 1 | 1 | 1 | 0 |
| 1 | 0 | 0 | 1 | 1 |
Assume if A = 60; and B = 13; now in binary format they will be as follows: A = 0011 1100 B = 0000 1101 ----------------- A and B = 0000 1100 A or B = 0011 1101 A xor B = 0011 0001 not A = 1100 0011
LISP支持的按位运算符列在下表中。假设变量A持有60,变量B持有13,则:
| 运算符 | 描述 | 示例 |
|---|---|---|
| logand | 这将返回其参数的按位逻辑与。如果没有给出参数,则结果为-1,这是此操作的恒等式。 | (logand a b))将得到12 |
| logior | 这将返回其参数的按位逻辑或。如果没有给出参数,则结果为零,这是此操作的恒等式。 | (logior a b)将得到61 |
| logxor | 这将返回其参数的按位逻辑异或。如果没有给出参数,则结果为零,这是此操作的恒等式。 | (logxor a b)将得到49 |
| lognor | 这将返回其参数的按位非。如果没有给出参数,则结果为-1,这是此操作的恒等式。 | (lognor a b)将得到-62, |
| logeqv | 这将返回其参数的按位逻辑等价(也称为异或非)。如果没有给出参数,则结果为-1,这是此操作的恒等式。 | (logeqv a b)将得到-50 |
LISP - 决策
决策结构要求程序员指定一个或多个要由程序评估或测试的条件,以及如果确定条件为真则要执行的语句或语句,以及可选地,如果确定条件为假则要执行的其他语句。
以下是大多数编程语言中发现的典型决策结构的一般形式:
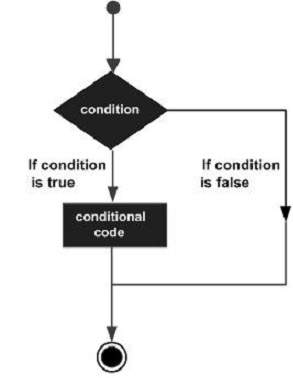
LISP提供了以下类型的决策结构。点击以下链接查看其详细信息。
| 序号 | 结构及描述 |
|---|---|
| 1 | cond
此结构用于用于检查多个测试-动作子句。它可以与其他编程语言中的嵌套if语句进行比较。 |
| 2 | if
if结构有多种形式。在最简单的形式中,它后面跟着一个测试子句、一个测试动作和一些其他后续动作。如果测试子句求值为真,则执行测试动作,否则求值后续子句。 |
| 3 | when
在最简单的形式中,它后面跟着一个测试子句和一个测试动作。如果测试子句求值为真,则执行测试动作,否则求值后续子句。 |
| 4 | case
此结构类似于 cond 结构,实现了多个测试-动作子句。但是,它会评估一个关键表单,并根据该关键表单的评估结果允许多个动作子句。 |
LISP - 循环
在某些情况下,您可能需要多次执行一段代码。循环语句允许我们多次执行一个语句或一组语句,以下是大多数编程语言中循环语句的一般形式。
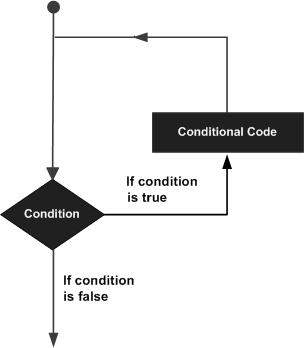
LISP 提供以下几种类型的结构来处理循环需求。点击以下链接查看其详细信息。
| 序号 | 结构及描述 |
|---|---|
| 1 | loop
loop 结构是 LISP 提供的最简单的迭代形式。在其最简单的形式中,它允许您重复执行某些语句,直到找到一个 return 语句。 |
| 2 | loop for
loop for 结构允许您实现类似于 for 循环的迭代,这在其他语言中最常见。 |
| 3 | do
do 结构也用于使用 LISP 执行迭代。它提供了一种结构化的迭代形式。 |
| 4 | dotimes
dotimes 结构允许循环执行固定次数的迭代。 |
| 5 | dolist
dolist 结构允许遍历列表的每个元素。 |
优雅地退出代码块
block 和 return-from 允许您在发生任何错误时优雅地退出任何嵌套的代码块。
block 函数允许您创建一个命名块,其主体由零个或多个语句组成。语法如下:
(block block-name( ... ... ))
return-from 函数接受一个块名称和一个可选的返回值(默认为 nil)。
以下示例演示了这一点:
示例
创建一个名为 main.lisp 的新源代码文件,并在其中键入以下代码:
(defun demo-function (flag)
(print 'entering-outer-block)
(block outer-block
(print 'entering-inner-block)
(print (block inner-block
(if flag
(return-from outer-block 3)
(return-from inner-block 5)
)
(print 'This-wil--not-be-printed))
)
(print 'left-inner-block)
(print 'leaving-outer-block)
t)
)
(demo-function t)
(terpri)
(demo-function nil)
当您单击“执行”按钮或键入 Ctrl+E 时,LISP 会立即执行它,并返回的结果为 −
ENTERING-OUTER-BLOCK ENTERING-INNER-BLOCK ENTERING-OUTER-BLOCK ENTERING-INNER-BLOCK 5 LEFT-INNER-BLOCK LEAVING-OUTER-BLOCK
LISP - 函数
函数是一组共同执行一项任务的语句。
您可以将代码分成不同的函数。如何将代码划分为不同的函数取决于您,但通常在逻辑上划分是为了使每个函数执行特定的任务。
在 LISP 中定义函数
名为 defun 的宏用于定义函数。defun 宏需要三个参数:
- 函数名称
- 函数的参数
- 函数体
defun 的语法如下:
(defun name (parameter-list) "Optional documentation string." body)
让我们用简单的例子来说明这个概念。
示例 1
让我们编写一个名为 averagenum 的函数,该函数将打印四个数字的平均值。我们将把这些数字作为参数发送。
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(defun averagenum (n1 n2 n3 n4) (/ ( + n1 n2 n3 n4) 4) ) (write(averagenum 10 20 30 40))
执行代码后,它将返回以下结果:
25
示例 2
让我们定义并调用一个函数,该函数将在给定圆的半径作为参数时计算圆的面积。
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(defun area-circle(rad) "Calculates area of a circle with given radius" (terpri) (format t "Radius: ~5f" rad) (format t "~%Area: ~10f" (* 3.141592 rad rad)) ) (area-circle 10)
执行代码后,它将返回以下结果:
Radius: 10.0 Area: 314.1592
请注意:
您可以提供一个空列表作为参数,这意味着函数不接受任何参数,列表为空,写成 ()。
LISP 还允许可选参数、多个参数和关键字参数。
文档字符串描述了函数的目的。它与函数名称相关联,可以使用 documentation 函数获取。
函数体可以包含任意数量的 Lisp 表达式。
主体中最后一个表达式的值作为函数的值返回。
您还可以使用 return-from 特殊运算符从函数中返回值。
让我们简要讨论上述概念。点击以下链接查找详细信息:
LISP - 谓词
谓词是测试其参数是否满足某些特定条件的函数,如果条件为假则返回 nil,如果条件为真则返回某个非 nil 值。
下表显示了一些最常用的谓词:
| 序号 | 谓词和描述 |
|---|---|
| 1 | 原子 它接受一个参数,如果参数是原子则返回 t,否则返回 nil。 |
| 2 | equal 它接受两个参数,如果它们在结构上相等则返回 t,否则返回 nil。 |
| 3 | eq 它接受两个参数,如果它们是相同的对象,共享相同的内存位置则返回 t,否则返回 nil。 |
| 4 | eql 它接受两个参数,如果参数是 eq,或者如果它们是相同类型且具有相同值的数字,或者如果它们是表示相同字符的字符对象,则返回 t,否则返回 nil。 |
| 5 | evenp 它接受一个数字参数,如果参数是偶数则返回 t,否则返回 nil。 |
| 6 | oddp 它接受一个数字参数,如果参数是奇数则返回 t,否则返回 nil。 |
| 7 | zerop 它接受一个数字参数,如果参数为零则返回 t,否则返回 nil。 |
| 8 | 空 它接受一个参数,如果参数计算结果为 nil 则返回 t,否则返回 nil。 |
| 9 | listp 它接受一个参数,如果参数计算结果为列表则返回 t,否则返回 nil。 |
| 10 | greaterp 它接受一个或多个参数,如果只有一个参数或参数从左到右依次变大,则返回 t,否则返回 nil。 |
| 11 | lessp 它接受一个或多个参数,如果只有一个参数或参数从左到右依次变小,则返回 t,否则返回 nil。 |
| 12 | numberp 它接受一个参数,如果参数是数字则返回 t,否则返回 nil。 |
| 13 | symbolp 它接受一个参数,如果参数是符号则返回 t,否则返回 nil。 |
| 14 | integerp 它接受一个参数,如果参数是整数则返回 t,否则返回 nil。 |
| 15 | rationalp 它接受一个参数,如果参数是有理数(比率或数字)则返回 t,否则返回 nil。 |
| 16 | floatp 它接受一个参数,如果参数是浮点数则返回 t,否则返回 nil。 |
| 17 | realp 它接受一个参数,如果参数是实数则返回 t,否则返回 nil。 |
| 18 | complexp 它接受一个参数,如果参数是复数则返回 t,否则返回 nil。 |
| 19 | characterp 它接受一个参数,如果参数是字符则返回 t,否则返回 nil。 |
| 20 | stringp 它接受一个参数,如果参数是字符串对象则返回 t,否则返回 nil。 |
| 21 | arrayp 它接受一个参数,如果参数是数组对象则返回 t,否则返回 nil。 |
| 22 | packagep 它接受一个参数,如果参数是包则返回 t,否则返回 nil。 |
示例 1
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(write (atom 'abcd)) (terpri) (write (equal 'a 'b)) (terpri) (write (evenp 10)) (terpri) (write (evenp 7 )) (terpri) (write (oddp 7 )) (terpri) (write (zerop 0.0000000001)) (terpri) (write (eq 3 3.0 )) (terpri) (write (equal 3 3.0 )) (terpri) (write (null nil ))
执行代码后,它将返回以下结果:
T NIL T NIL T NIL NIL NIL T
示例 2
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(defun factorial (num)
(cond ((zerop num) 1)
(t ( * num (factorial (- num 1))))
)
)
(setq n 6)
(format t "~% Factorial ~d is: ~d" n (factorial n))
执行代码后,它将返回以下结果:
Factorial 6 is: 720
LISP - 数字
Common Lisp 定义了几种类型的数字。number 数据类型包含 LISP 支持的各种类型的数字。
LISP 支持的数字类型有:
- 整数
- 比率
- 浮点数
- 复数
下图显示了数字层次结构和 LISP 中可用的各种数值数据类型:
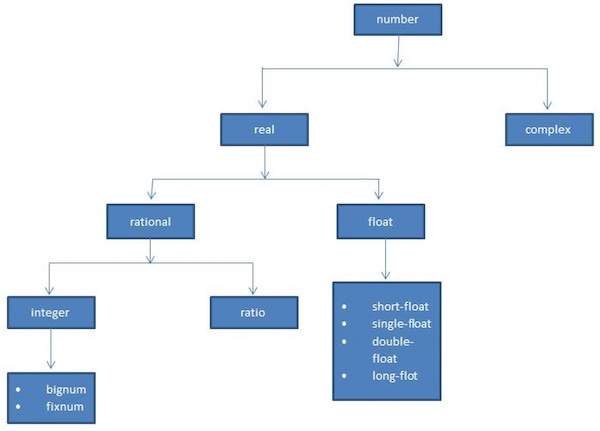
LISP 中的各种数值类型
下表描述了 LISP 中可用的各种数字类型数据:
| 序号 | 数据类型和描述 |
|---|---|
| 1 | 定点整数 此数据类型表示整数,这些整数不太大,并且大多在 -215 到 215-1 的范围内(取决于机器)。 |
| 2 | 大整数 这些是非常大的数字,大小受分配给 LISP 的内存量限制,它们不是 fixnum 数字。 |
| 3 | 有理数 表示分子/分母形式的两个数字的比率。当参数为整数时,/ 函数始终产生比率结果。 |
| 4 | 浮点数 它表示非整数。有四种浮点数据类型,精度逐渐提高。 |
| 5 | 复数 它表示复数,用 #c 表示。实部和虚部都可以是有理数或浮点数。 |
示例
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(write (/ 1 2)) (terpri) (write ( + (/ 1 2) (/ 3 4))) (terpri) (write ( + #c( 1 2) #c( 3 -4)))
执行代码后,它将返回以下结果:
1/2 5/4 #C(4 -2)
数字函数
下表描述了一些常用的数值函数:
| 序号 | 函数和描述 |
|---|---|
| 1 | +, -, *, / 相应的算术运算 |
| 2 | sin, cos, tan, acos, asin, atan 相应的三角函数。 |
| 3 | sinh, cosh, tanh, acosh, asinh, atanh 相应的双曲函数。 |
| 4 | exp 指数函数。计算 ex |
| 5 | expt 指数函数,同时接受底数和指数。 |
| 6 | sqrt 它计算数字的平方根。 |
| 7 | log 对数函数。如果给出一个参数,则计算其自然对数,否则第二个参数用作底数。 |
| 8 | conjugate 它计算数字的复共轭。对于实数,它返回数字本身。 |
| 9 | abs 它返回数字的绝对值(或大小)。 |
| 10 | gcd 它计算给定数字的最大公约数。 |
| 11 | lcm 它计算给定数字的最小公倍数。 |
| 12 | isqrt 它给出小于或等于给定自然数的精确平方根的最大整数。 |
| 13 | floor, ceiling, truncate, round 所有这些函数都接受两个参数作为数字并返回商;floor 返回不大于比率的最大整数,ceiling 选择大于比率的较小整数,truncate 选择与比率符号相同的整数,其绝对值小于比率的绝对值,round 选择最接近比率的整数。 |
| 14 | ffloor, fceiling, ftruncate, fround 执行与上述相同的操作,但将商返回为浮点数。 |
| 15 | mod, rem 返回除法运算中的余数。 |
| 16 | 浮点数 将实数转换为浮点数。 |
| 17 | rational, rationalize 将实数转换为有理数。 |
| 18 | numerator, denominator 返回有理数的相应部分。 |
| 19 | realpart, imagpart 返回复数的实部和虚部。 |
示例
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(write (/ 45 78)) (terpri) (write (floor 45 78)) (terpri) (write (/ 3456 75)) (terpri) (write (floor 3456 75)) (terpri) (write (ceiling 3456 75)) (terpri) (write (truncate 3456 75)) (terpri) (write (round 3456 75)) (terpri) (write (ffloor 3456 75)) (terpri) (write (fceiling 3456 75)) (terpri) (write (ftruncate 3456 75)) (terpri) (write (fround 3456 75)) (terpri) (write (mod 3456 75)) (terpri) (setq c (complex 6 7)) (write c) (terpri) (write (complex 5 -9)) (terpri) (write (realpart c)) (terpri) (write (imagpart c))
执行代码后,它将返回以下结果:
15/26 0 1152/25 46 47 46 46 46.0 47.0 46.0 46.0 6 #C(6 7) #C(5 -9) 6 7
LISP - 字符
在 LISP 中,字符表示为类型为 character 的数据对象。
您可以表示在字符本身之前用 #\ 前缀的字符对象。例如,#\a 表示字符 a。
空格和其他特殊字符可以通过在字符名称前加上 #\ 来表示。例如,#\SPACE 表示空格字符。
以下示例演示了这一点:
示例
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(write 'a) (terpri) (write #\a) (terpri) (write-char #\a) (terpri) (write-char 'a)
执行代码后,它将返回以下结果:
A #\a a *** - WRITE-CHAR: argument A is not a character
特殊字符
Common LISP 允许在代码中使用以下特殊字符。它们被称为半标准字符。
- #\Backspace
- #\Tab
- #\Linefeed
- #\Page
- #\Return
- #\Rubout
字符比较函数
数值比较函数和运算符(如 < 和 >)不适用于字符。Common LISP 提供了另外两组函数用于在代码中比较字符。
一组区分大小写,另一组不区分大小写。
下表提供了这些函数 -
| 区分大小写函数 | 不区分大小写函数 | 描述 |
|---|---|---|
| char= | char-equal | 检查操作数的值是否都相等,如果是,则条件变为真。 |
| char/= | char-not-equal | 检查操作数的值是否都不同,如果值不相等,则条件变为真。 |
| char< | char-lessp | 检查操作数的值是否单调递减。 |
| char> | char-greaterp | 检查操作数的值是否单调递增。 |
| char<= | char-not-greaterp | 检查任何左侧操作数的值是否大于或等于其右侧下一个操作数的值,如果是,则条件变为真。 |
| char>= | char-not-lessp | 检查任何左侧操作数的值是否小于或等于其右侧操作数的值,如果是,则条件变为真。 |
示例
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
; case-sensitive comparison (write (char= #\a #\b)) (terpri) (write (char= #\a #\a)) (terpri) (write (char= #\a #\A)) (terpri) ;case-insensitive comparision (write (char-equal #\a #\A)) (terpri) (write (char-equal #\a #\b)) (terpri) (write (char-lessp #\a #\b #\c)) (terpri) (write (char-greaterp #\a #\b #\c))
执行代码后,它将返回以下结果:
NIL T NIL T NIL T NIL
LISP - 数组
LISP 允许您使用 **make-array** 函数定义一维或多维数组。数组可以存储任何 LISP 对象作为其元素。
所有数组都由连续的内存位置组成。最低地址对应于第一个元素,最高地址对应于最后一个元素。
数组的维度数称为其秩。
在 LISP 中,数组元素由一系列非负整数索引指定。序列的长度必须等于数组的秩。索引从零开始。
例如,要创建一个包含 10 个单元格的数组,命名为 my-array,我们可以编写 -
(setf my-array (make-array '(10)))
aref 函数允许访问单元格的内容。它接受两个参数,数组的名称和索引值。
例如,要访问第十个单元格的内容,我们编写 -
(aref my-array 9)
示例 1
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(write (setf my-array (make-array '(10)))) (terpri) (setf (aref my-array 0) 25) (setf (aref my-array 1) 23) (setf (aref my-array 2) 45) (setf (aref my-array 3) 10) (setf (aref my-array 4) 20) (setf (aref my-array 5) 17) (setf (aref my-array 6) 25) (setf (aref my-array 7) 19) (setf (aref my-array 8) 67) (setf (aref my-array 9) 30) (write my-array)
执行代码后,它将返回以下结果:
#(NIL NIL NIL NIL NIL NIL NIL NIL NIL NIL) #(25 23 45 10 20 17 25 19 67 30)
示例 2
让我们创建一个 3x3 的数组。
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(setf x (make-array '(3 3) :initial-contents '((0 1 2 ) (3 4 5) (6 7 8))) ) (write x)
执行代码后,它将返回以下结果:
#2A((0 1 2) (3 4 5) (6 7 8))
示例 3
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(setq a (make-array '(4 3)))
(dotimes (i 4)
(dotimes (j 3)
(setf (aref a i j) (list i 'x j '= (* i j)))
)
)
(dotimes (i 4)
(dotimes (j 3)
(print (aref a i j))
)
)
执行代码后,它将返回以下结果:
(0 X 0 = 0) (0 X 1 = 0) (0 X 2 = 0) (1 X 0 = 0) (1 X 1 = 1) (1 X 2 = 2) (2 X 0 = 0) (2 X 1 = 2) (2 X 2 = 4) (3 X 0 = 0) (3 X 1 = 3) (3 X 2 = 6)
make-array 函数的完整语法
make-array 函数接受许多其他参数。让我们看一下此函数的完整语法 -
make-array dimensions :element-type :initial-element :initial-contents :adjustable :fill-pointer :displaced-to :displaced-index-offset
除了 *dimensions* 参数之外,所有其他参数都是关键字。下表提供了参数的简要说明。
| 序号 | 参数 & 描述 |
|---|---|
| 1 | dimensions 它给出数组的维度。对于一维数组,它是一个数字;对于多维数组,它是一个列表。 |
| 2 | :element-type 它是类型说明符,默认值为 T,即任何类型 |
| 3 | :initial-element 初始元素值。它将创建一个数组,所有元素都初始化为特定值。 |
| 4 | :initial-content 作为对象的初始内容。 |
| 5 | :adjustable 它有助于创建可调整大小(或可调整)的向量,其底层内存可以调整大小。该参数是一个布尔值,指示数组是否可调整,默认值为 NIL。 |
| 6 | :fill-pointer 它跟踪可调整大小向量中实际存储的元素数量。 |
| 7 | :displaced-to 它有助于创建与指定数组共享其内容的置换数组或共享数组。这两个数组应具有相同的元素类型。:displaced-to 选项不能与 :initial-element 或 :initial-contents 选项一起使用。此参数默认为 nil。 |
| 8 | :displaced-index-offset 它给出创建的共享数组的索引偏移量。 |
示例 4
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(setq myarray (make-array '(3 2 3)
:initial-contents
'(((a b c) (1 2 3))
((d e f) (4 5 6))
((g h i) (7 8 9))
))
)
(setq array2 (make-array 4 :displaced-to myarray :displaced-index-offset 2))
(write myarray)
(terpri)
(write array2)
执行代码后,它将返回以下结果:
#3A(((A B C) (1 2 3)) ((D E F) (4 5 6)) ((G H I) (7 8 9))) #(C 1 2 3)
如果置换数组是二维的 -
(setq myarray (make-array '(3 2 3)
:initial-contents
'(((a b c) (1 2 3))
((d e f) (4 5 6))
((g h i) (7 8 9))
))
)
(setq array2 (make-array '(3 2) :displaced-to myarray :displaced-index-offset 2))
(write myarray)
(terpri)
(write array2)
执行代码后,它将返回以下结果:
#3A(((A B C) (1 2 3)) ((D E F) (4 5 6)) ((G H I) (7 8 9))) #2A((C 1) (2 3) (D E))
让我们将置换索引偏移量更改为 5 -
(setq myarray (make-array '(3 2 3)
:initial-contents
'(((a b c) (1 2 3))
((d e f) (4 5 6))
((g h i) (7 8 9))
))
)
(setq array2 (make-array '(3 2) :displaced-to myarray :displaced-index-offset 5))
(write myarray)
(terpri)
(write array2)
执行代码后,它将返回以下结果:
#3A(((A B C) (1 2 3)) ((D E F) (4 5 6)) ((G H I) (7 8 9))) #2A((3 D) (E F) (4 5))
示例 5
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
;a one dimensional array with 5 elements, ;initail value 5 (write (make-array 5 :initial-element 5)) (terpri) ;two dimensional array, with initial element a (write (make-array '(2 3) :initial-element 'a)) (terpri) ;an array of capacity 14, but fill pointer 5, is 5 (write(length (make-array 14 :fill-pointer 5))) (terpri) ;however its length is 14 (write (array-dimensions (make-array 14 :fill-pointer 5))) (terpri) ; a bit array with all initial elements set to 1 (write(make-array 10 :element-type 'bit :initial-element 1)) (terpri) ; a character array with all initial elements set to a ; is a string actually (write(make-array 10 :element-type 'character :initial-element #\a)) (terpri) ; a two dimensional array with initial values a (setq myarray (make-array '(2 2) :initial-element 'a :adjustable t)) (write myarray) (terpri) ;readjusting the array (adjust-array myarray '(1 3) :initial-element 'b) (write myarray)
执行代码后,它将返回以下结果:
#(5 5 5 5 5) #2A((A A A) (A A A)) 5 (14) #*1111111111 "aaaaaaaaaa" #2A((A A) (A A)) #2A((A A B))
LISP - 字符串
Common Lisp 中的字符串是向量,即字符的一维数组。
字符串文字用双引号括起来。字符集中支持的任何字符都可以用双引号括起来以构成字符串,除了双引号字符 (") 和转义字符 (\)。但是,您可以通过使用反斜杠 (\) 对它们进行转义来包含它们。
示例
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(write-line "Hello World") (write-line "Welcome to Tutorials Point") ;escaping the double quote character (write-line "Welcome to \"Tutorials Point\"")
执行代码后,它将返回以下结果:
Hello World Welcome to Tutorials Point Welcome to "Tutorials Point"
字符串比较函数
数值比较函数和运算符(如 < 和 >)不适用于字符串。Common LISP 提供了另外两组函数用于在代码中比较字符串。一组区分大小写,另一组不区分大小写。
下表提供了这些函数 -
| 区分大小写函数 | 不区分大小写函数 | 描述 |
|---|---|---|
| string= | string-equal | 检查操作数的值是否都相等,如果是,则条件变为真。 |
| string/= | string-not-equal | 检查操作数的值是否都不同,如果值不相等,则条件变为真。 |
| string< | string-lessp | 检查操作数的值是否单调递减。 |
| string> | string-greaterp | 检查操作数的值是否单调递增。 |
| string<= | string-not-greaterp | 检查任何左侧操作数的值是否大于或等于其右侧下一个操作数的值,如果是,则条件变为真。 |
| string>= | string-not-lessp | 检查任何左侧操作数的值是否小于或等于其右侧操作数的值,如果是,则条件变为真。 |
示例
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
; case-sensitive comparison (write (string= "this is test" "This is test")) (terpri) (write (string> "this is test" "This is test")) (terpri) (write (string< "this is test" "This is test")) (terpri) ;case-insensitive comparision (write (string-equal "this is test" "This is test")) (terpri) (write (string-greaterp "this is test" "This is test")) (terpri) (write (string-lessp "this is test" "This is test")) (terpri) ;checking non-equal (write (string/= "this is test" "this is Test")) (terpri) (write (string-not-equal "this is test" "This is test")) (terpri) (write (string/= "lisp" "lisping")) (terpri) (write (string/= "decent" "decency"))
执行代码后,它将返回以下结果:
NIL 0 NIL T NIL NIL 8 NIL 4 5
大小写控制函数
下表描述了大小写控制函数 -
| 序号 | 函数和描述 |
|---|---|
| 1 | string-upcase 将字符串转换为大写 |
| 2 | string-downcase 将字符串转换为小写 |
| 3 | string-capitalize 将字符串中每个单词的首字母大写 |
示例
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(write-line (string-upcase "a big hello from tutorials point")) (write-line (string-capitalize "a big hello from tutorials point"))
执行代码后,它将返回以下结果:
A BIG HELLO FROM TUTORIALS POINT A Big Hello From Tutorials Point
修剪字符串
下表描述了字符串修剪函数 -
| 序号 | 函数和描述 |
|---|---|
| 1 | string-trim 它以字符字符串作为第一个参数,以字符串作为第二个参数,并返回一个子字符串,其中第一个参数中的所有字符都从参数字符串中删除。 |
| 2 | String-left-trim 它以字符字符串作为第一个参数,以字符串作为第二个参数,并返回一个子字符串,其中第一个参数中的所有字符都从参数字符串的开头删除。 |
| 3 | String-right-trim 它以字符字符串作为第一个参数,以字符串作为第二个参数,并返回一个子字符串,其中第一个参数中的所有字符都从参数字符串的末尾删除。 |
示例
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(write-line (string-trim " " " a big hello from tutorials point ")) (write-line (string-left-trim " " " a big hello from tutorials point ")) (write-line (string-right-trim " " " a big hello from tutorials point ")) (write-line (string-trim " a" " a big hello from tutorials point "))
执行代码后,它将返回以下结果:
a big hello from tutorials point a big hello from tutorials point a big hello from tutorials point big hello from tutorials point
其他字符串函数
LISP 中的字符串是数组,因此也是序列。我们将在后续教程中介绍这些数据类型。所有适用于数组和序列的函数也适用于字符串。但是,我们将通过各种示例演示一些常用的函数。
计算长度
**length** 函数计算字符串的长度。
提取子字符串
**subseq** 函数返回一个子字符串(因为字符串也是一个序列),该子字符串从特定索引开始,一直持续到特定结束索引或字符串的末尾。
访问字符串中的字符
**char** 函数允许访问字符串的单个字符。
示例
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(write (length "Hello World")) (terpri) (write-line (subseq "Hello World" 6)) (write (char "Hello World" 6))
执行代码后,它将返回以下结果:
11 World #\W
字符串的排序和合并
**sort** 函数允许对字符串进行排序。它接受一个序列(向量或字符串)和一个双参数谓词,并返回该序列的排序版本。
**merge** 函数接受两个序列和一个谓词,并返回一个序列,该序列是根据谓词合并这两个序列生成的。
示例
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
;sorting the strings (write (sort (vector "Amal" "Akbar" "Anthony") #'string<)) (terpri) ;merging the strings (write (merge 'vector (vector "Rishi" "Zara" "Priyanka") (vector "Anju" "Anuj" "Avni") #'string<))
执行代码后,它将返回以下结果:
#("Akbar" "Amal" "Anthony")
#("Anju" "Anuj" "Avni" "Rishi" "Zara" "Priyanka")
反转字符串
**reverse** 函数反转字符串。
例如,创建一个名为 main.lisp 的新源代码文件,并在其中键入以下代码。
(write-line (reverse "Are we not drawn onward, we few, drawn onward to new era"))
执行代码后,它将返回以下结果:
are wen ot drawno nward ,wef ew ,drawno nward ton ew erA
连接字符串
concatenate 函数连接两个字符串。这是一个通用的序列函数,您必须提供结果类型作为第一个参数。
例如,创建一个名为 main.lisp 的新源代码文件,并在其中键入以下代码。
(write-line (concatenate 'string "Are we not drawn onward, " "we few, drawn onward to new era"))
执行代码后,它将返回以下结果:
Are we not drawn onward, we few, drawn onward to new era
LISP - 序列
序列是 LISP 中的一种抽象数据类型。向量和列表是这种数据类型的两个具体子类型。在序列数据类型上定义的所有功能实际上都应用于所有向量和列表类型。
在本节中,我们将讨论序列上最常用的函数。
在开始以各种方式操作序列(即向量和列表)之前,让我们先看一下所有可用函数的列表。
创建序列
make-sequence 函数允许您创建任何类型的序列。此函数的语法为 -
make-sequence sqtype sqsize &key :initial-element
它创建一个类型为 *sqtype* 且长度为 *sqsize* 的序列。
您可以选择使用 *:initial-element* 参数指定一些值,然后每个元素都将初始化为该值。
例如,创建一个名为 main.lisp 的新源代码文件,并在其中键入以下代码。
(write (make-sequence '(vector float) 10 :initial-element 1.0))
执行代码后,它将返回以下结果:
#(1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0)
序列上的通用函数
| 序号 | 函数和描述 |
|---|---|
| 1 | elt 它允许通过整数索引访问单个元素。 |
| 2 | length 它返回序列的长度。 |
| 3 | subseq 它通过提取从特定索引开始并持续到特定结束索引或序列末尾的子序列来返回一个子序列。 |
| 4 | copy-seq 它返回一个序列,该序列包含与其参数相同的元素。 |
| 5 | fill 它用于将序列的多个元素设置为单个值。 |
| 6 | replace 它接受两个序列,第一个参数序列通过从第二个参数序列中复制连续元素到其中来进行破坏性修改。 |
| 7 | count 它接受一个项目和一个序列,并返回该项目在序列中出现的次数。 |
| 8 | reverse 它返回一个序列,该序列包含与参数相同的元素,但顺序相反。 |
| 9 | nreverse 它返回与序列相同的序列,包含与序列相同的元素,但顺序相反。 |
| 10 | concatenate 它创建一个新的序列,包含任意数量序列的连接。 |
| 11 | position 它接受一个项目和一个序列,并返回该项目在序列中的索引或 nil。 |
| 12 | find 它接受一个项目和一个序列。它在序列中查找该项目并返回它,如果未找到,则返回 nil。 |
| 13 | sort 它接受一个序列和一个双参数谓词,并返回该序列的排序版本。 |
| 14 | merge 它接受两个序列和一个谓词,并返回一个序列,该序列是根据谓词合并这两个序列生成的。 |
| 15 | map 它接受一个 n 参数函数和 n 个序列,并返回一个新序列,其中包含将该函数应用于序列后续元素的结果。 |
| 16 | some 它接受一个谓词作为参数,并遍历参数序列,并返回谓词返回的第一个非 NIL 值,或者如果谓词从未满足,则返回 false。 |
| 17 | every 它接受一个谓词作为参数,并遍历参数序列,一旦谓词失败,它就会终止并返回 false。如果谓词始终满足,则返回 true。 |
| 18 | notany 它接受一个谓词作为参数,并遍历参数序列,一旦谓词满足就返回 false,或者如果从未满足就返回 true。 |
| 19 | notevery 它接受一个谓词作为参数,并遍历参数序列,一旦谓词失败就返回 true,或者如果谓词始终满足就返回 false。 |
| 20 | reduce 它映射到单个序列,首先将双参数函数应用于序列的前两个元素,然后将函数返回的值和序列的后续元素应用于该值。 |
| 21 | search 它搜索序列以定位一个或多个满足某些测试的元素。 |
| 22 | remove 它接受一个项目和一个序列,并返回删除了项目实例的序列。 |
| 23 | delete 它也接受一个项目和一个序列,并返回一个与参数序列类型相同的序列,该序列具有相同的元素,除了该项目。 |
| 24 | substitute 它接受一个新项目、一个现有项目和一个序列,并返回一个序列,其中现有项目的实例被新项目替换。 |
| 25 | nsubstitute 它接受一个新项目、一个现有项目和一个序列,并返回与该序列相同的序列,其中现有项目的实例被新项目替换。 |
| 26 | mismatch 它接受两个序列,并返回第一个不匹配元素对的索引。 |
标准序列函数关键字参数
| 参数 | 含义 | 默认值 |
|---|---|---|
| :test | 它是一个双参数函数,用于将项目(或 :key 函数提取的值)与元素进行比较。 | EQL |
| :键(:key) | 一个参数函数,用于从实际序列元素中提取键值。NIL 表示按原样使用元素。 | NIL |
| :开始(:start) | 子序列的起始索引(包含)。 | 0 |
| :结束(:end) | 子序列的结束索引(不包含)。NIL 表示序列的末尾。 | NIL |
| :从末尾(:from-end) | 如果为真,则序列将以相反的顺序遍历,从末尾到开头。 | NIL |
| :计数(:count) | 指示要删除或替换的元素数量,或 NIL 表示全部(仅限 REMOVE 和 SUBSTITUTE)。 | NIL |
我们刚刚讨论了各种用作这些函数参数的函数和关键字,这些函数作用于序列。在接下来的章节中,我们将通过示例了解如何使用这些函数。
查找长度和元素
length 函数返回序列的长度,elt 函数允许您使用整数索引访问单个元素。
示例
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(setq x (vector 'a 'b 'c 'd 'e)) (write (length x)) (terpri) (write (elt x 3))
执行代码后,它将返回以下结果:
5 D
修改序列
一些序列函数允许遍历序列并执行某些操作,例如搜索、删除、计数或过滤特定元素,而无需编写显式循环。
以下示例演示了这一点:
示例 1
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(write (count 7 '(1 5 6 7 8 9 2 7 3 4 5))) (terpri) (write (remove 5 '(1 5 6 7 8 9 2 7 3 4 5))) (terpri) (write (delete 5 '(1 5 6 7 8 9 2 7 3 4 5))) (terpri) (write (substitute 10 7 '(1 5 6 7 8 9 2 7 3 4 5))) (terpri) (write (find 7 '(1 5 6 7 8 9 2 7 3 4 5))) (terpri) (write (position 5 '(1 5 6 7 8 9 2 7 3 4 5)))
执行代码后,它将返回以下结果:
2 (1 6 7 8 9 2 7 3 4) (1 6 7 8 9 2 7 3 4) (1 5 6 10 8 9 2 10 3 4 5) 7 1
示例 2
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(write (delete-if #'oddp '(1 5 6 7 8 9 2 7 3 4 5))) (terpri) (write (delete-if #'evenp '(1 5 6 7 8 9 2 7 3 4 5))) (terpri) (write (remove-if #'evenp '(1 5 6 7 8 9 2 7 3 4 5) :count 1 :from-end t)) (terpri) (setq x (vector 'a 'b 'c 'd 'e 'f 'g)) (fill x 'p :start 1 :end 4) (write x)
执行代码后,它将返回以下结果:
(6 8 2 4) (1 5 7 9 7 3 5) (1 5 6 7 8 9 2 7 3 5) #(A P P P E F G)
排序和合并序列
排序函数接受一个序列和一个双参数谓词,并返回该序列的排序版本。
示例 1
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(write (sort '(2 4 7 3 9 1 5 4 6 3 8) #'<)) (terpri) (write (sort '(2 4 7 3 9 1 5 4 6 3 8) #'>)) (terpri)
执行代码后,它将返回以下结果:
(1 2 3 3 4 4 5 6 7 8 9) (9 8 7 6 5 4 4 3 3 2 1)
示例 2
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(write (merge 'vector #(1 3 5) #(2 4 6) #'<)) (terpri) (write (merge 'list #(1 3 5) #(2 4 6) #'<)) (terpri)
执行代码后,它将返回以下结果:
#(1 2 3 4 5 6) (1 2 3 4 5 6)
序列谓词
every、some、notany 和 notevery 函数称为序列谓词。
这些函数迭代序列并测试布尔谓词。
所有这些函数都将谓词作为第一个参数,其余参数是序列。
示例
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(write (every #'evenp #(2 4 6 8 10))) (terpri) (write (some #'evenp #(2 4 6 8 10 13 14))) (terpri) (write (every #'evenp #(2 4 6 8 10 13 14))) (terpri) (write (notany #'evenp #(2 4 6 8 10))) (terpri) (write (notevery #'evenp #(2 4 6 8 10 13 14))) (terpri)
执行代码后,它将返回以下结果:
T T NIL NIL T
映射序列
我们已经讨论了映射函数。类似地,map 函数允许您将函数应用于一个或多个序列的后续元素。
map 函数接受一个 n 参数函数和 n 个序列,并在将函数应用于序列的后续元素后返回一个新序列。
示例
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(write (map 'vector #'* #(2 3 4 5) #(3 5 4 8)))
执行代码后,它将返回以下结果:
#(6 15 16 40)
LISP - 列表
在传统的 LISP 中,列表是最重要和最主要的复合数据结构。当今的 Common LISP 提供了其他数据结构,例如向量、哈希表、类或结构。
列表是单向链表。在 LISP 中,列表被构建为一个名为 cons 的简单记录结构的链,这些结构链接在一起。
cons 记录结构
cons 是一种记录结构,包含两个称为 car 和 cdr 的组件。
Cons 单元或 cons 是使用函数 cons 创建的值对对象。
cons 函数接受两个参数并返回一个新的 cons 单元,其中包含这两个值。这些值可以是任何类型对象的引用。
如果第二个值不是 nil 或另一个 cons 单元,则这些值将打印为括号括起来的一对点对。
cons 单元中的两个值分别称为 car 和 cdr。car 函数用于访问第一个值,cdr 函数用于访问第二个值。
示例
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(write (cons 1 2)) (terpri) (write (cons 'a 'b)) (terpri) (write (cons 1 nil)) (terpri) (write (cons 1 (cons 2 nil))) (terpri) (write (cons 1 (cons 2 (cons 3 nil)))) (terpri) (write (cons 'a (cons 'b (cons 'c nil)))) (terpri) (write ( car (cons 'a (cons 'b (cons 'c nil))))) (terpri) (write ( cdr (cons 'a (cons 'b (cons 'c nil)))))
执行代码后,它将返回以下结果:
(1 . 2) (A . B) (1) (1 2) (1 2 3) (A B C) A (B C)
上面的示例显示了如何使用 cons 结构创建单向链表,例如,列表 (A B C) 由三个 cons 单元组成,这些单元通过它们的 cdr 链接在一起。
图示如下:
LISP 中的列表
虽然 cons 单元可用于创建列表,但是,从嵌套的 cons 函数调用构建列表可能不是最佳解决方案。list 函数更常用于在 LISP 中创建列表。
list 函数可以接受任意数量的参数,并且由于它是一个函数,因此它会计算其参数。
first 和 rest 函数分别给出列表的第一个元素和其余部分。以下示例演示了这些概念。
示例 1
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(write (list 1 2)) (terpri) (write (list 'a 'b)) (terpri) (write (list 1 nil)) (terpri) (write (list 1 2 3)) (terpri) (write (list 'a 'b 'c)) (terpri) (write (list 3 4 'a (car '(b . c)) (* 4 -2))) (terpri) (write (list (list 'a 'b) (list 'c 'd 'e)))
执行代码后,它将返回以下结果:
(1 2) (A B) (1 NIL) (1 2 3) (A B C) (3 4 A B -8) ((A B) (C D E))
示例 2
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(defun my-library (title author rating availability) (list :title title :author author :rating rating :availabilty availability) ) (write (getf (my-library "Hunger Game" "Collins" 9 t) :title))
执行代码后,它将返回以下结果:
"Hunger Game"
列表操作函数
下表提供了一些常用的列表操作函数。
| 序号 | 函数和描述 |
|---|---|
| 1 | car 它将列表作为参数,并返回其第一个元素。 |
| 2 | cdr 它将列表作为参数,并返回一个没有第一个元素的列表。 |
| 3 | cons单元 它接受两个参数,一个元素和一个列表,并返回一个在第一个位置插入该元素的列表。 |
| 4 | 列表 它接受任意数量的参数,并返回一个以这些参数作为列表成员元素的列表。 |
| 5 | append 它将两个或多个列表合并为一个。 |
| 6 | last 它接受一个列表并返回一个包含最后一个元素的列表。 |
| 7 | member 它接受两个参数,其中第二个参数必须是一个列表,如果第一个参数是第二个参数的成员,则它返回从第一个参数开始的列表的其余部分。 |
| 8 | reverse 它接受一个列表并返回一个顶部元素按相反顺序排列的列表。 |
请注意,所有序列函数都适用于列表。
示例 3
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(write (car '(a b c d e f))) (terpri) (write (cdr '(a b c d e f))) (terpri) (write (cons 'a '(b c))) (terpri) (write (list 'a '(b c) '(e f))) (terpri) (write (append '(b c) '(e f) '(p q) '() '(g))) (terpri) (write (last '(a b c d (e f)))) (terpri) (write (reverse '(a b c d (e f))))
执行代码后,它将返回以下结果:
A (B C D E F) (A B C) (A (B C) (E F)) (B C E F P Q G) ((E F)) ((E F) D C B A)
car 和 cdr 函数的连接
car 和 cdr 函数及其组合允许提取列表的任何特定元素/成员。
但是,car 和 cdr 函数的序列可以通过在字母 c 和 r 内连接表示 car 的字母 a 和表示 cdr 的字母 d 来缩写。
例如,我们可以编写 cadadr 来缩写函数调用序列 - car cdr car cdr。
因此,(cadadr '(a (c d) (e f g))) 将返回 d
示例 4
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(write (cadadr '(a (c d) (e f g)))) (terpri) (write (caar (list (list 'a 'b) 'c))) (terpri) (write (cadr (list (list 1 2) (list 3 4)))) (terpri)
执行代码后,它将返回以下结果:
D A (3 4)
LISP - 符号
在 LISP 中,符号是表示数据对象的名称,有趣的是,它本身也是一个数据对象。
使符号特殊的是它们有一个称为 属性列表或 plist 的组件。
属性列表
LISP 允许您为符号分配属性。例如,让我们有一个“person”对象。我们希望此“person”对象具有名称、性别、身高、体重、地址、职业等属性。属性类似于属性名称。
属性列表实现为一个具有偶数(可能为零)个元素的列表。列表中的每一对元素构成一个条目;第一项是 指示符,第二项是 值。
创建符号时,其属性列表最初为空。属性是使用 setf 形式中的 get 创建的。
例如,以下语句允许我们将属性 title、author 和 publisher 以及相应的值分配给名为(符号)'book' 的对象。
示例 1
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(write (setf (get 'books'title) '(Gone with the Wind))) (terpri) (write (setf (get 'books 'author) '(Margaret Michel))) (terpri) (write (setf (get 'books 'publisher) '(Warner Books)))
执行代码后,它将返回以下结果:
(GONE WITH THE WIND) (MARGARET MICHEL) (WARNER BOOKS)
各种属性列表函数允许您分配属性以及检索、替换或删除符号的属性。
get 函数返回给定指示符的符号的属性列表。它具有以下语法:
get symbol indicator &optional default
get 函数在给定符号的属性列表中查找指定的指示符,如果找到,则返回相应的值;否则返回默认值(如果未指定默认值,则为 nil)。
示例 2
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(setf (get 'books 'title) '(Gone with the Wind)) (setf (get 'books 'author) '(Margaret Micheal)) (setf (get 'books 'publisher) '(Warner Books)) (write (get 'books 'title)) (terpri) (write (get 'books 'author)) (terpri) (write (get 'books 'publisher))
执行代码后,它将返回以下结果:
(GONE WITH THE WIND) (MARGARET MICHEAL) (WARNER BOOKS)
symbol-plist 函数允许您查看符号的所有属性。
示例 3
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(setf (get 'annie 'age) 43) (setf (get 'annie 'job) 'accountant) (setf (get 'annie 'sex) 'female) (setf (get 'annie 'children) 3) (terpri) (write (symbol-plist 'annie))
执行代码后,它将返回以下结果:
(CHILDREN 3 SEX FEMALE JOB ACCOUNTANT AGE 43)
remprop 函数从符号中删除指定的属性。
示例 4
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(setf (get 'annie 'age) 43) (setf (get 'annie 'job) 'accountant) (setf (get 'annie 'sex) 'female) (setf (get 'annie 'children) 3) (terpri) (write (symbol-plist 'annie)) (remprop 'annie 'age) (terpri) (write (symbol-plist 'annie))
执行代码后,它将返回以下结果:
(CHILDREN 3 SEX FEMALE JOB ACCOUNTANT AGE 43) (CHILDREN 3 SEX FEMALE JOB ACCOUNTANT)
LISP - 向量
向量是一维数组,因此是数组的子类型。向量和列表统称为序列。因此,我们迄今为止讨论的所有序列泛型函数和数组函数都适用于向量。
创建向量
vector 函数允许您使用特定值创建固定大小的向量。它接受任意数量的参数,并返回一个包含这些参数的向量。
示例 1
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(setf v1 (vector 1 2 3 4 5)) (setf v2 #(a b c d e)) (setf v3 (vector 'p 'q 'r 's 't)) (write v1) (terpri) (write v2) (terpri) (write v3)
执行代码后,它将返回以下结果:
#(1 2 3 4 5) #(A B C D E) #(P Q R S T)
请注意,LISP 使用 #(...) 语法作为向量的文字表示法。您可以使用此 #(... ) 语法在代码中创建和包含文字向量。
但是,这些是文字向量,因此在 LISP 中未定义对其进行修改。因此,对于编程,您应该始终使用 vector 函数或更通用的函数 make-array 来创建您计划修改的向量。
make-array 函数是创建向量的更通用的方法。您可以使用 aref 函数访问向量元素。
示例 2
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(setq a (make-array 5 :initial-element 0)) (setq b (make-array 5 :initial-element 2)) (dotimes (i 5) (setf (aref a i) i)) (write a) (terpri) (write b) (terpri)
执行代码后,它将返回以下结果:
#(0 1 2 3 4) #(2 2 2 2 2)
填充指针
make-array 函数允许您创建可调整大小的向量。
函数的 fill-pointer 参数跟踪实际存储在向量中的元素数量。当您向向量添加元素时,它是下一个要填充的位置的索引。
vector-push 函数允许您将元素添加到可调整大小向量的末尾。它将填充指针增加 1。
vector-pop 函数返回最近推送的项目并将填充指针减少 1。
示例
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(setq a (make-array 5 :fill-pointer 0)) (write a) (vector-push 'a a) (vector-push 'b a) (vector-push 'c a) (terpri) (write a) (terpri) (vector-push 'd a) (vector-push 'e a) ;this will not be entered as the vector limit is 5 (vector-push 'f a) (write a) (terpri) (vector-pop a) (vector-pop a) (vector-pop a) (write a)
执行代码后,它将返回以下结果:
#() #(A B C) #(A B C D E) #(A B)
向量是序列,所有序列函数都适用于向量。请参阅序列章节,了解向量函数。
LISP - 集合
Common Lisp 没有提供集合数据类型。但是,它提供了一些允许对列表执行集合操作的函数。
您可以根据各种条件添加、删除和搜索列表中的项目。您还可以执行各种集合操作,例如:并集、交集和集合差。
在 LISP 中实现集合
集合与列表一样,通常以 cons 单元的形式实现。但是,正因为如此,集合越大,集合操作的效率就越低。
adjoin 函数允许您构建集合。它接受一个项目和一个表示集合的列表,并返回一个表示包含该项目和原始集合中所有项目的集合的列表。
adjoin 函数首先在给定列表中查找该项目,如果找到,则返回原始列表;否则,它会创建一个新的 cons 单元,其 car 为该项目,cdr 指向原始列表,并返回此新列表。
adjoin 函数还接受 :key 和 :test 关键字参数。这些参数用于检查该项目是否在原始列表中。
由于 adjoin 函数不会修改原始列表,因此要对列表本身进行更改,您必须将 adjoin 返回的值分配给原始列表,或者,您可以使用宏 pushnew 将项目添加到集合中。
示例
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
; creating myset as an empty list (defparameter *myset* ()) (adjoin 1 *myset*) (adjoin 2 *myset*) ; adjoin did not change the original set ;so it remains same (write *myset*) (terpri) (setf *myset* (adjoin 1 *myset*)) (setf *myset* (adjoin 2 *myset*)) ;now the original set is changed (write *myset*) (terpri) ;adding an existing value (pushnew 2 *myset*) ;no duplicate allowed (write *myset*) (terpri) ;pushing a new value (pushnew 3 *myset*) (write *myset*) (terpri)
执行代码后,它将返回以下结果:
NIL (2 1) (2 1) (3 2 1)
检查成员资格
member 函数组允许您检查元素是否为集合的成员。
以下是这些函数的语法:
member item list &key :test :test-not :key member-if predicate list &key :key member-if-not predicate list &key :key
这些函数在给定列表中搜索满足测试的给定项目。如果未找到此类项目,则这些函数返回 nil。否则,将返回以该元素作为第一个元素的列表的尾部。
搜索仅在顶层进行。
这些函数可以用作谓词。
示例
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(write (member 'zara '(ayan abdul zara riyan nuha))) (terpri) (write (member-if #'evenp '(3 7 2 5/3 'a))) (terpri) (write (member-if-not #'numberp '(3 7 2 5/3 'a 'b 'c)))
执行代码后,它将返回以下结果:
(ZARA RIYAN NUHA)
(2 5/3 'A)
('A 'B 'C)
集合并集
并集函数组允许您根据测试对作为这些函数参数提供的两个列表执行集合并集。
以下是这些函数的语法:
union list1 list2 &key :test :test-not :key nunion list1 list2 &key :test :test-not :key
union 函数接受两个列表并返回一个新列表,其中包含这两个列表中存在的全部元素。如果存在重复项,则在返回的列表中仅保留一个成员的副本。
nunion 函数执行相同的操作,但可能会破坏参数列表。
示例
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(setq set1 (union '(a b c) '(c d e)))
(setq set2 (union '(#(a b) #(5 6 7) #(f h))
'(#(5 6 7) #(a b) #(g h)) :test-not #'mismatch)
)
(setq set3 (union '(#(a b) #(5 6 7) #(f h))
'(#(5 6 7) #(a b) #(g h)))
)
(write set1)
(terpri)
(write set2)
(terpri)
(write set3)
执行代码后,它将返回以下结果:
(A B C D E) (#(F H) #(5 6 7) #(A B) #(G H)) (#(A B) #(5 6 7) #(F H) #(5 6 7) #(A B) #(G H))
请注意
对于三个向量的列表,如果没有 :test-not #'mismatch 参数,则 union 函数无法按预期工作。这是因为列表由 cons 单元组成,尽管这些值对我们来说看起来相同,但单元的 cdr 部分并不匹配,因此它们对 LISP 解释器/编译器来说并不完全相同。这就是不建议使用列表实现大型集合的原因。但是,它适用于小型集合。
集合交集
交集函数组允许您根据测试对作为这些函数参数提供的两个列表执行交集。
以下是这些函数的语法:
intersection list1 list2 &key :test :test-not :key nintersection list1 list2 &key :test :test-not :key
这些函数接受两个列表并返回一个新列表,其中包含两个参数列表中存在的全部元素。如果任一列表具有重复项,则结果中可能会或可能不会出现冗余项。
示例
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(setq set1 (intersection '(a b c) '(c d e)))
(setq set2 (intersection '(#(a b) #(5 6 7) #(f h))
'(#(5 6 7) #(a b) #(g h)) :test-not #'mismatch)
)
(setq set3 (intersection '(#(a b) #(5 6 7) #(f h))
'(#(5 6 7) #(a b) #(g h)))
)
(write set1)
(terpri)
(write set2)
(terpri)
(write set3)
执行代码后,它将返回以下结果:
(C) (#(A B) #(5 6 7)) NIL
intersection 函数是 intersection 的破坏性版本,即它可能会破坏原始列表。
集合差
集合差函数组允许您根据测试对作为这些函数参数提供的两个列表执行集合差。
以下是这些函数的语法:
set-difference list1 list2 &key :test :test-not :key nset-difference list1 list2 &key :test :test-not :key
集合差函数返回第一个列表中未出现在第二个列表中的元素列表。
示例
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(setq set1 (set-difference '(a b c) '(c d e))) (setq set2 (set-difference '(#(a b) #(5 6 7) #(f h)) '(#(5 6 7) #(a b) #(g h)) :test-not #'mismatch) ) (setq set3 (set-difference '(#(a b) #(5 6 7) #(f h)) '(#(5 6 7) #(a b) #(g h))) ) (write set1) (terpri) (write set2) (terpri) (write set3)
执行代码后,它将返回以下结果:
(A B) (#(F H)) (#(A B) #(5 6 7) #(F H))
LISP - 树
您可以从 cons 单元格构建树形数据结构,作为列表的列表。
要实现树形结构,您必须设计能够以特定顺序遍历 cons 单元格的功能,例如二叉树的先序遍历、中序遍历和后序遍历。
列表表示的树
让我们考虑一个由 cons 单元格组成的树形结构,它形成了以下列表的列表:
((1 2) (3 4) (5 6)).
图示如下:
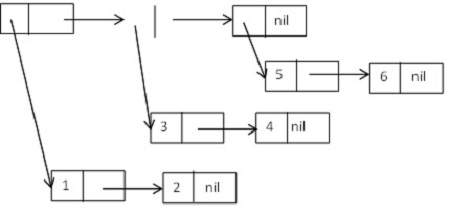
LISP 中的树函数
虽然大多数情况下您需要根据自己的具体需求编写自己的树功能,但 LISP 提供了一些可用的树函数。
除了所有列表函数之外,以下函数特别适用于树形结构:
| 序号 | 函数和描述 |
|---|---|
| 1 | copy-tree x & optional vecp 它返回 cons 单元格树 x 的副本。它递归地复制 car 和 cdr 方向。如果 x 不是 cons 单元格,则该函数只是返回未更改的 x。如果可选参数 vecp 为真,则此函数也会递归地复制向量以及 cons 单元格。 |
| 2 | tree-equal x y & key :test :test-not :key 它比较两个 cons 单元格树。如果 x 和 y 都是 cons 单元格,则它们的 car 和 cdr 会被递归比较。如果 x 和 y 都不是 cons 单元格,则它们通过 eql 进行比较,或者根据指定的测试进行比较。如果指定了 :key 函数,则将其应用于两棵树的元素。 |
| 3 | subst new old tree & key :test :test-not :key 它在 tree(一个 cons 单元格树)中用 new 项替换给定 old 项的出现。 |
| 4 | nsubst new old tree & key :test :test-not :key 它的作用与 subst 相同,但会破坏原始树。 |
| 5 | sublis alist tree & key :test :test-not :key 它的作用类似于 subst,不同之处在于它接受一个 alist,其中包含旧-新对的关联列表。树的每个元素(如果适用,则在应用 :key 函数后)都与 alist 的 car 进行比较;如果匹配,则将其替换为相应的 cdr。 |
| 6 | nsublis alist tree & key :test :test-not :key 它的作用类似于 sublis,但它是破坏性的版本。 |
示例 1
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(setq lst (list '(1 2) '(3 4) '(5 6))) (setq mylst (copy-list lst)) (setq tr (copy-tree lst)) (write lst) (terpri) (write mylst) (terpri) (write tr)
执行代码后,它将返回以下结果:
((1 2) (3 4) (5 6)) ((1 2) (3 4) (5 6)) ((1 2) (3 4) (5 6))
示例 2
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(setq tr '((1 2 (3 4 5) ((7 8) (7 8 9))))) (write tr) (setq trs (subst 7 1 tr)) (terpri) (write trs)
执行代码后,它将返回以下结果:
((1 2 (3 4 5) ((7 8) (7 8 9)))) ((7 2 (3 4 5) ((7 8) (7 8 9))))
构建您自己的树
让我们尝试使用 LISP 中可用的列表函数构建自己的树。
首先让我们创建一个包含一些数据的新节点
(defun make-tree (item) "it creates a new node with item." (cons (cons item nil) nil) )
接下来让我们向树中添加一个子节点 - 它将获取两个树节点并将第二个树作为第一个树的子节点添加。
(defun add-child (tree child) (setf (car tree) (append (car tree) child)) tree)
此函数将返回给定树的第一个子节点 - 它将获取一个树节点并返回该节点的第一个子节点,或者如果该节点没有任何子节点,则返回 nil。
(defun first-child (tree)
(if (null tree)
nil
(cdr (car tree))
)
)
此函数将返回给定节点的下一个兄弟节点 - 它以树节点作为参数,并返回对下一个兄弟节点的引用,或者如果该节点没有任何兄弟节点,则返回 nil。
(defun next-sibling (tree) (cdr tree) )
最后,我们需要一个函数来返回节点中的信息:
(defun data (tree) (car (car tree)) )
示例
此示例使用上述功能:
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(defun make-tree (item)
"it creates a new node with item."
(cons (cons item nil) nil)
)
(defun first-child (tree)
(if (null tree)
nil
(cdr (car tree))
)
)
(defun next-sibling (tree)
(cdr tree)
)
(defun data (tree)
(car (car tree))
)
(defun add-child (tree child)
(setf (car tree) (append (car tree) child))
tree
)
(setq tr '((1 2 (3 4 5) ((7 8) (7 8 9)))))
(setq mytree (make-tree 10))
(write (data mytree))
(terpri)
(write (first-child tr))
(terpri)
(setq newtree (add-child tr mytree))
(terpri)
(write newtree)
执行代码后,它将返回以下结果:
10 (2 (3 4 5) ((7 8) (7 8 9))) ((1 2 (3 4 5) ((7 8) (7 8 9)) (10)))
LISP - 哈希表
哈希表数据结构表示 键值对 的集合,这些键值对根据键的哈希码进行组织。它使用键来访问集合中的元素。
当您需要使用键访问元素,并且您可以识别有用的键值时,可以使用哈希表。哈希表中的每个项目都有一个键/值对。键用于访问集合中的项目。
在 LISP 中创建哈希表
在 Common LISP 中,哈希表是一个通用集合。您可以使用任意对象作为键或索引。
当您将值存储在哈希表中时,您会创建一个键值对,并将其存储在该键下。稍后,您可以使用相同的键从哈希表中检索该值。每个键映射到一个值,尽管您可以在键中存储新值。
根据键的比较方式,LISP 中的哈希表可以分为三种类型:eq、eql 或 equal。如果哈希表是根据 LISP 对象进行哈希的,则键将使用 eq 或 eql 进行比较。如果哈希表是根据树结构进行哈希的,则将使用 equal 进行比较。
make-hash-table 函数用于创建哈希表。此函数的语法如下:
make-hash-table &key :test :size :rehash-size :rehash-threshold
其中:
key 参数提供键。
:test 参数确定如何比较键 - 它应该具有三个值之一 #'eq、#'eql 或 #'equal,或者三个符号 eq、eql 或 equal 之一。如果未指定,则假定为 eql。
:size 参数设置哈希表的初始大小。这应该是一个大于零的整数。
:rehash-size 参数指定当哈希表变得满时,将其大小增加多少。这可以是一个大于零的整数,表示要添加的条目数,也可以是一个大于 1 的浮点数,表示新大小与旧大小的比率。此参数的默认值取决于实现。
:rehash-threshold 参数指定哈希表在必须增长之前可以达到多满。这可以是一个大于零且小于 :rehash-size 的整数(在这种情况下,它将在每次表增长时进行缩放),也可以是一个介于零和 1 之间的浮点数。此参数的默认值取决于实现。
您也可以在没有任何参数的情况下调用 make-hash-table 函数。
从哈希表中检索项目和向哈希表中添加项目
gethash 函数通过搜索其键来从哈希表中检索项目。如果找不到键,则返回 nil。
它具有以下语法:
gethash key hash-table &optional default
其中:
key:是关联的键
hash-table:是要搜索的哈希表
default:是如果未找到条目则要返回的值,如果未指定,则为 nil。
gethash 函数实际上返回两个值,第二个值是谓词值,如果找到条目则为真,如果未找到条目则为假。
要向哈希表中添加项目,您可以将 setf 函数与 gethash 函数一起使用。
示例
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(setq empList (make-hash-table)) (setf (gethash '001 empList) '(Charlie Brown)) (setf (gethash '002 empList) '(Freddie Seal)) (write (gethash '001 empList)) (terpri) (write (gethash '002 empList))
执行代码后,它将返回以下结果:
(CHARLIE BROWN) (FREDDIE SEAL)
删除条目
remhash 函数删除哈希表中特定键的任何条目。这是一个谓词,如果存在条目则为真,如果不存在则为假。
此函数的语法如下:
remhash key hash-table
示例
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(setq empList (make-hash-table)) (setf (gethash '001 empList) '(Charlie Brown)) (setf (gethash '002 empList) '(Freddie Seal)) (setf (gethash '003 empList) '(Mark Mongoose)) (write (gethash '001 empList)) (terpri) (write (gethash '002 empList)) (terpri) (write (gethash '003 empList)) (remhash '003 empList) (terpri) (write (gethash '003 empList))
执行代码后,它将返回以下结果:
(CHARLIE BROWN) (FREDDIE SEAL) (MARK MONGOOSE) NIL
maphash 函数
maphash 函数允许您对哈希表上的每个键值对应用指定的函数。
它接受两个参数 - 函数和哈希表,并在哈希表中的每个键/值对上调用一次该函数。
示例
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(setq empList (make-hash-table)) (setf (gethash '001 empList) '(Charlie Brown)) (setf (gethash '002 empList) '(Freddie Seal)) (setf (gethash '003 empList) '(Mark Mongoose)) (maphash #'(lambda (k v) (format t "~a => ~a~%" k v)) empList)
执行代码后,它将返回以下结果:
3 => (MARK MONGOOSE) 2 => (FREDDIE SEAL) 1 => (CHARLIE BROWN)
LISP - 输入与输出
Common LISP 提供了许多输入输出函数。我们已经使用 format 函数和 print 函数进行输出。在本节中,我们将探讨 LISP 提供的一些最常用的输入输出函数。
输入函数
下表提供了 LISP 最常用的输入函数:
| 序号 | 函数和描述 |
|---|---|
| 1 | read & optional input-stream eof-error-p eof-value recursive-p 它从 input-stream 读取 Lisp 对象的打印表示形式,构建相应的 Lisp 对象,并返回该对象。 |
| 2 | read-preserving-whitespace & optional in-stream eof-error-p eof-value recursive-p 它用于某些特殊情况,在这些情况下,需要精确确定哪个字符终止了扩展标记。 |
| 3 | read-line & optional input-stream eof-error-p eof-value recursive-p 它读取以换行符结尾的一行文本。 |
| 4 | read-char & optional input-stream eof-error-p eof-value recursive-p 它从 input-stream 获取一个字符,并将其作为字符对象返回。 |
| 5 | unread-char character & optional input-stream 它将最近从 input-stream 读取的字符放在 input-stream 的前面。 |
| 6 | peek-char & optional peek-type input-stream eof-error-p eof-value recursive-p 它返回 input-stream 中要读取的下一个字符,而无需实际将其从 input stream 中移除。 |
| 7 | listen & optional input-stream 谓词 listen 如果 input-stream 中立即有字符可用,则为真,否则为假。 |
| 8 | read-char-no-hang & optional input-stream eof-error-p eof-value recursive-p 它类似于 read-char,但如果它没有获取字符,则不会等待字符,而是立即返回 nil。 |
| 9 | clear-input & optional input-stream 它清除与 input-stream 关联的任何缓冲输入。 |
| 10 | read-from-string string & optional eof-error-p eof-value & key :start :end :preserve-whitespace 它依次获取字符串的字符并构建一个 LISP 对象,并返回该对象。它还返回字符串中未读取的第一个字符的索引,或者字符串的长度(或者,长度 +1),具体取决于情况。 |
| 11 | parse-integer string & key :start :end :radix :junk-allowed 它检查由 :start 和 :end 界定的字符串的子字符串(默认为字符串的开头和结尾)。它跳过空格字符,然后尝试解析整数。 |
| 12 | read-byte binary-input-stream & optional eof-error-p eof-value 它从 binary-input-stream 读取一个字节,并以整数的形式返回它。 |
从键盘读取输入
read 函数用于从键盘获取输入。它可能不接受任何参数。
例如,考虑以下代码片段:
(write ( + 15.0 (read)))
假设用户从 STDIN 输入中输入 10.2,它将返回:
25.2
read 函数从输入流中读取字符,并通过解析将其解释为 Lisp 对象的表示形式。
示例
创建一个名为 main.lisp 的新源代码文件,并在其中键入以下代码:
; the function AreaOfCircle ; calculates area of a circle ; when the radius is input from keyboard (defun AreaOfCircle() (terpri) (princ "Enter Radius: ") (setq radius (read)) (setq area (* 3.1416 radius radius)) (princ "Area: ") (write area)) (AreaOfCircle)
执行代码后,它将返回以下结果:
Enter Radius: 5 (STDIN Input) Area: 78.53999
示例
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(with-input-from-string (stream "Welcome to Tutorials Point!") (print (read-char stream)) (print (read-char stream)) (print (read-char stream)) (print (read-char stream)) (print (read-char stream)) (print (read-char stream)) (print (read-char stream)) (print (read-char stream)) (print (read-char stream)) (print (read-char stream)) (print (peek-char nil stream nil 'the-end)) (values) )
执行代码后,它将返回以下结果:
#\W #\e #\l #\c #\o #\m #\e #\Space #\t #\o #\Space
输出函数
LISP 中的所有输出函数都接受一个名为 output-stream 的可选参数,输出将发送到该参数。如果未提及或为 nil,则 output-stream 默认为变量 *standard-output* 的值。
下表提供了 LISP 最常用的输出函数:
| 序号 | 函数和描述 |
|---|---|
| 1 | write object & key :stream :escape :radix :base :circle :pretty :level :length :case :gensym :array write object & key :stream :escape :radix :base :circle :pretty :level :length :case :gensym :array :readably :right-margin :miser-width :lines :pprint-dispatch 两者都将对象写入由 :stream 指定的输出流,默认为 *standard-output* 的值。其他值默认为为打印设置的相应全局变量。 |
| 2 |
prin1 object & optional output-stream print object & optional output-stream pprint object & optional output-stream princ object & optional output-stream 所有这些函数都将对象的打印表示形式输出到 output-stream。但是,存在以下差异:
|
| 3 | write-to-string object & key :escape :radix :base :circle :pretty :level :length :case :gensym :array write-to-string object & key :escape :radix :base :circle :pretty :level :length :case :gensym :array :readably :right-margin :miser-width :lines :pprint-dispatch prin1-to-string object princ-to-string object 对象被有效地打印,输出字符被制成字符串,并返回该字符串。 |
| 4 | write-char character & optional output-stream 它将字符输出到output-stream,并返回该字符。 |
| 5 | write-string string & optional output-stream & key :start :end 它将指定string子字符串的字符写入output-stream。 |
| 6 | write-line string & optional output-stream & key :start :end 它的工作方式与write-string相同,但在之后输出一个换行符。 |
| 7 | terpri & optional output-stream 它将一个换行符输出到output-stream。 |
| 8 | fresh-line & optional output-stream 仅当流不在行的开头时,它才会输出一个换行符。 |
| 9 | finish-output & optional output-stream force-output & optional output-stream clear-output & optional output-stream
|
| 10 | write-byte integer binary-output-stream 它写入一个字节,即integer的值。 |
示例
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
; this program inputs a numbers and doubles it (defun DoubleNumber() (terpri) (princ "Enter Number : ") (setq n1 (read)) (setq doubled (* 2.0 n1)) (princ "The Number: ") (write n1) (terpri) (princ "The Number Doubled: ") (write doubled) ) (DoubleNumber)
执行代码后,它将返回以下结果:
Enter Number : 3456.78 (STDIN Input) The Number: 3456.78 The Number Doubled: 6913.56
格式化输出
函数format用于生成格式良好的文本。它具有以下语法:
format destination control-string &rest arguments
其中,
- destination是标准输出
- control-string包含要输出的字符和打印指令。
格式指令由一个波浪号(~)、可选的前缀参数(用逗号分隔)、可选的冒号(:)和at符号(@)修饰符以及一个指示此指令类型的单个字符组成。
前缀参数通常是整数,表示为带符号或无符号的十进制数。
下表简要描述了常用的指令:
| 序号 | 指令 & 描述 |
|---|---|
| 1 | ~A 后跟ASCII参数。 |
| 2 | ~S 后跟S表达式。 |
| 3 | ~D 用于十进制参数。 |
| 4 | ~B 用于二进制参数。 |
| 5 | ~O 用于八进制参数。 |
| 6 | ~X 用于十六进制参数。 |
| 7 | ~C 用于字符参数。 |
| 8 | ~F 用于定点格式浮点数参数。 |
| 9 | ~E 指数浮点数参数。 |
| 10 | ~$ 美元符号和浮点数参数。 |
| 11 | ~% 打印一个换行符。 |
| 12 | ~* 忽略下一个参数。 |
| 13 | ~? 间接寻址。下一个参数必须是一个字符串,再下一个参数必须是一个列表。 |
示例
让我们重写计算圆面积的程序:
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(defun AreaOfCircle() (terpri) (princ "Enter Radius: ") (setq radius (read)) (setq area (* 3.1416 radius radius)) (format t "Radius: = ~F~% Area = ~F" radius area) ) (AreaOfCircle)
执行代码后,它将返回以下结果:
Enter Radius: 10.234 (STDIN Input) Radius: = 10.234 Area = 329.03473
LISP - 文件 I/O
我们已经讨论了Common Lisp如何处理标准输入和输出。所有这些函数也适用于从文本和二进制文件读取以及写入文本和二进制文件。唯一的区别是,在这种情况下,我们使用的流不是标准输入或输出,而是为写入或读取文件而创建的流。
在本章中,我们将了解Lisp如何创建、打开、关闭文本或二进制文件以进行数据存储。
文件表示一系列字节,无论它是文本文件还是二进制文件。本章将引导您了解文件管理的重要函数/宏。
打开文件
您可以使用open函数创建新文件或打开现有文件。它是打开文件的最基本函数。但是,with-open-file通常更方便且更常用,我们将在本节后面看到。
打开文件时,会构造一个流对象以在Lisp环境中表示它。对流的所有操作基本上等同于对文件的操作。
open函数的语法如下:
open filename &key :direction :element-type :if-exists :if-does-not-exist :external-format
其中,
filename参数是要打开或创建的文件的名称。
keyword参数指定流的类型和错误处理方式。
:direction关键字指定流是否应处理输入、输出或两者,它采用以下值:
:input - 用于输入流(默认值)
:output - 用于输出流
:io - 用于双向流
:probe - 用于仅检查文件是否存在;流被打开然后关闭。
:element-type指定流的事务单元的类型。
:if-exists参数指定如果:direction为:output或:io并且指定名称的文件已存在,则应采取的操作。如果方向为:input或:probe,则忽略此参数。它采用以下值:
:error - 它发出错误信号。
:new-version - 它创建一个具有相同名称但版本号更大的新文件。
:rename - 它重命名现有文件。
:rename-and-delete - 它重命名现有文件,然后将其删除。
:append - 它追加到现有文件。
:supersede - 它取代现有文件。
nil - 它不创建文件甚至流,只是返回nil以指示失败。
:if-does-not-exist参数指定如果指定名称的文件不存在,则应采取的操作。它采用以下值:
:error - 它发出错误信号。
:create - 它创建一个具有指定名称的空文件,然后使用它。
nil - 它不创建文件甚至流,而是简单地返回nil以指示失败。
:external-format参数指定实现识别的用于在文件中表示字符的方案。
例如,您可以打开存储在/tmp文件夹中的名为myfile.txt的文件,如下所示:
(open "/tmp/myfile.txt")
写入和读取文件
with-open-file允许读取或写入文件,使用与读/写事务关联的流变量。工作完成后,它会自动关闭文件。使用它非常方便。
它具有以下语法:
with-open-file (stream filename {options}*)
{declaration}* {form}*
filename是要打开的文件的名称;它可以是字符串、路径名或流。
options与函数open的关键字参数相同。
示例 1
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(with-open-file (stream "/tmp/myfile.txt" :direction :output) (format stream "Welcome to Tutorials Point!") (terpri stream) (format stream "This is a tutorials database") (terpri stream) (format stream "Submit your Tutorials, White Papers and Articles into our Tutorials Directory.") )
请注意,上一章中讨论的所有输入输出函数,例如terpri和format,都适用于写入我们在此处创建的文件。
执行代码时,它不会返回任何内容;但是,我们的数据已写入文件。:direction :output关键字允许我们执行此操作。
但是,我们可以使用read-line函数从此文件中读取。
示例 2
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(let ((in (open "/tmp/myfile.txt" :if-does-not-exist nil)))
(when in
(loop for line = (read-line in nil)
while line do (format t "~a~%" line))
(close in)
)
)
执行代码后,它将返回以下结果:
Welcome to Tutorials Point! This is a tutorials database Submit your Tutorials, White Papers and Articles into our Tutorials Directory.
关闭文件
close函数关闭流。
LISP - 结构体
结构是用户定义的数据类型之一,它允许您组合不同类型的数据项。
结构用于表示记录。假设您想跟踪图书馆中的书籍。您可能希望跟踪每本书的以下属性:
- 标题
- 作者
- 主题
- 图书ID
定义结构
Lisp中的defstruct宏允许您定义抽象记录结构。defstruct语句定义了一种新的数据类型,为您的程序提供了多个成员。
为了讨论defstruct宏的格式,让我们编写Book结构的定义。我们可以将book结构定义为:
(defstruct book title author subject book-id )
请注意
上述声明创建了一个具有四个命名组件的book结构。因此,创建的每个book都将是此结构的对象。
它定义了四个名为book-title、book-author、book-subject和book-book-id的函数,这些函数将接受一个参数(一个book结构),并返回book对象的title、author、subject和book-id字段。这些函数称为访问函数。
符号book成为一种数据类型,您可以使用typep谓词来检查它。
还将有一个名为book-p的隐式函数,它是一个谓词,如果其参数是book则为真,否则为假。
将创建另一个名为make-book的隐式函数,它是一个构造函数,当被调用时,它将创建一个具有四个组件的数据结构,适合与访问函数一起使用。
#S语法指的是结构,您可以使用它来读取或打印book的实例。
还定义了一个名为copy-book的隐式函数,它只有一个参数。它接受一个book对象并创建一个另一个book对象,它是第一个对象的副本。此函数称为复制函数。
您可以使用setf来更改book的组件,例如
(setf (book-book-id book3) 100)
示例
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(defstruct book title author subject book-id ) ( setq book1 (make-book :title "C Programming" :author "Nuha Ali" :subject "C-Programming Tutorial" :book-id "478") ) ( setq book2 (make-book :title "Telecom Billing" :author "Zara Ali" :subject "C-Programming Tutorial" :book-id "501") ) (write book1) (terpri) (write book2) (setq book3( copy-book book1)) (setf (book-book-id book3) 100) (terpri) (write book3)
执行代码后,它将返回以下结果:
#S(BOOK :TITLE "C Programming" :AUTHOR "Nuha Ali" :SUBJECT "C-Programming Tutorial" :BOOK-ID "478") #S(BOOK :TITLE "Telecom Billing" :AUTHOR "Zara Ali" :SUBJECT "C-Programming Tutorial" :BOOK-ID "501") #S(BOOK :TITLE "C Programming" :AUTHOR "Nuha Ali" :SUBJECT "C-Programming Tutorial" :BOOK-ID 100)
LISP - 包
在编程语言的一般术语中,包旨在提供一种方法来将一组名称与另一组名称分开。在一个包中声明的符号不会与另一个包中声明的相同符号冲突。这样,包减少了独立代码模块之间的命名冲突。
Lisp读取器维护一个包含其找到的所有符号的表。当它找到一个新的字符序列时,它会创建一个新符号并将其存储在符号表中。此表称为包。
当前包由特殊变量*package*引用。
Lisp中有两个预定义的包:
common-lisp - 它包含所有定义的函数和变量的符号。
common-lisp-user - 它使用common-lisp包和所有其他包以及编辑和调试工具;简称cl-user
Lisp中的包函数
下表提供了用于创建、使用和操作包的最常用函数:
| 序号 | 函数和描述 |
|---|---|
| 1 | make-package package-name &key :nicknames :use 它创建并返回一个具有指定包名称的新包。 |
| 2 | in-package package-name &key :nicknames :use 使包成为当前包。 |
| 3 | in-package name 此宏导致*package*设置为名为name的包,name必须是符号或字符串。 |
| 4 |
find-package name 它搜索包。返回具有该名称或昵称的包;如果不存在此类包,则find-package返回nil。 |
| 5 |
rename-package package new-name &optional new-nicknames 它重命名包。 |
| 6 |
list-all-packages 此函数返回Lisp系统中当前存在的所有包的列表。 |
| 7 |
delete-package package 它删除包。 |
创建Lisp包
defpackage函数用于创建用户定义的包。它具有以下语法:
(defpackage :package-name (:use :common-lisp ...) (:export :symbol1 :symbol2 ...) )
其中,
package-name是包的名称。
:use关键字指定此包需要的包,即定义此包中的代码使用的函数的包。
:export关键字指定在此包中外部的符号。
make-package函数也用于创建包。此函数的语法如下:
make-package package-name &key :nicknames :use
参数和关键字与之前含义相同。
使用包
创建包后,您可以通过将其设为当前包来使用此包中的代码。in-package宏使包在环境中成为当前包。
示例
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(make-package :tom) (make-package :dick) (make-package :harry) (in-package tom) (defun hello () (write-line "Hello! This is Tom's Tutorials Point") ) (hello) (in-package dick) (defun hello () (write-line "Hello! This is Dick's Tutorials Point") ) (hello) (in-package harry) (defun hello () (write-line "Hello! This is Harry's Tutorials Point") ) (hello) (in-package tom) (hello) (in-package dick) (hello) (in-package harry) (hello)
执行代码后,它将返回以下结果:
Hello! This is Tom's Tutorials Point Hello! This is Dick's Tutorials Point Hello! This is Harry's Tutorials Point
删除包
delete-package宏允许您删除包。以下示例演示了这一点:
示例
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(make-package :tom) (make-package :dick) (make-package :harry) (in-package tom) (defun hello () (write-line "Hello! This is Tom's Tutorials Point") ) (in-package dick) (defun hello () (write-line "Hello! This is Dick's Tutorials Point") ) (in-package harry) (defun hello () (write-line "Hello! This is Harry's Tutorials Point") ) (in-package tom) (hello) (in-package dick) (hello) (in-package harry) (hello) (delete-package tom) (in-package tom) (hello)
执行代码后,它将返回以下结果:
Hello! This is Tom's Tutorials Point Hello! This is Dick's Tutorials Point Hello! This is Harry's Tutorials Point *** - EVAL: variable TOM has no value
LISP - 错误处理
在Common Lisp术语中,异常称为条件。
事实上,在传统的编程语言中,条件比异常更普遍,因为一个条件表示任何可能影响函数调用栈各个级别的事件、错误或非错误。
LISP 中的条件处理机制以这样一种方式处理此类情况:条件用于发出警告(例如打印警告),而调用栈上的上层代码可以继续其工作。
LISP 中的条件处理系统包含三个部分:
- 发出条件信号
- 处理条件
- 重新启动进程
处理条件
让我们以处理由除以零条件引起的条件的示例来解释这里的概念。
处理条件需要执行以下步骤:
定义条件 - “条件是一个对象,其类指示条件的总体性质,其实例数据携带有关导致发出条件的特定情况的详细信息。”
define-condition 宏用于定义条件,其语法如下:
(define-condition condition-name (error) ((text :initarg :text :reader text)) )
新的条件对象使用 MAKE-CONDITION 宏创建,该宏根据:initargs参数初始化新条件的槽。
在我们的示例中,以下代码定义了条件:
(define-condition on-division-by-zero (error) ((message :initarg :message :reader message)) )
编写处理程序 - 条件处理程序是用于处理发出信号的条件的代码。它通常编写在调用错误函数的较高层函数之一中。当发出条件信号时,发出信号机制根据条件的类搜索合适的处理程序。
每个处理程序包含:
- 类型说明符,指示它可以处理的条件类型
- 一个函数,它接受一个参数,即条件
当发出条件信号时,发出信号机制找到与条件类型兼容的最近建立的处理程序,并调用其函数。
handler-case 宏建立条件处理程序。handler-case 的基本形式:
(handler-case expression error-clause*)
其中,每个错误子句都具有以下形式:
condition-type ([var]) code)
重新启动阶段
这是实际从错误中恢复程序的代码,然后条件处理程序可以通过调用适当的重启来处理条件。重启代码通常放置在中间层或底层函数中,条件处理程序放置在应用程序的上层。
handler-bind 宏允许您提供一个重启函数,并允许您在底层函数中继续,而无需展开函数调用栈。换句话说,控制流仍然在底层函数中。
handler-bind 的基本形式如下:
(handler-bind (binding*) form*)
其中每个绑定都是以下内容的列表:
- 条件类型
- 一个带有一个参数的处理程序函数
invoke-restart 宏查找并调用最近绑定的重启函数,并使用指定的名称作为参数。
您可以有多个重启。
示例
在此示例中,我们通过编写一个名为 division-function 的函数来演示上述概念,如果除数参数为零,该函数将创建错误条件。我们有三个匿名函数,它们提供了三种退出方式 - 返回值 1、发送除数 2 并重新计算,或返回 1。
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(define-condition on-division-by-zero (error)
((message :initarg :message :reader message))
)
(defun handle-infinity ()
(restart-case
(let ((result 0))
(setf result (division-function 10 0))
(format t "Value: ~a~%" result)
)
(just-continue () nil)
)
)
(defun division-function (value1 value2)
(restart-case
(if (/= value2 0)
(/ value1 value2)
(error 'on-division-by-zero :message "denominator is zero")
)
(return-zero () 0)
(return-value (r) r)
(recalc-using (d) (division-function value1 d))
)
)
(defun high-level-code ()
(handler-bind
(
(on-division-by-zero
#'(lambda (c)
(format t "error signaled: ~a~%" (message c))
(invoke-restart 'return-zero)
)
)
(handle-infinity)
)
)
)
(handler-bind
(
(on-division-by-zero
#'(lambda (c)
(format t "error signaled: ~a~%" (message c))
(invoke-restart 'return-value 1)
)
)
)
(handle-infinity)
)
(handler-bind
(
(on-division-by-zero
#'(lambda (c)
(format t "error signaled: ~a~%" (message c))
(invoke-restart 'recalc-using 2)
)
)
)
(handle-infinity)
)
(handler-bind
(
(on-division-by-zero
#'(lambda (c)
(format t "error signaled: ~a~%" (message c))
(invoke-restart 'just-continue)
)
)
)
(handle-infinity)
)
(format t "Done."))
执行代码后,它将返回以下结果:
error signaled: denominator is zero Value: 1 error signaled: denominator is zero Value: 5 error signaled: denominator is zero Done.
除了上面讨论的“条件系统”之外,Common LISP 还提供了各种可以用于发出错误信号的函数。但是,发出信号后错误的处理方式取决于实现。
LISP 中的错误发出信号函数
下表提供了常用函数,用于发出警告、中断、非致命和致命错误的信号。
用户程序指定错误消息(字符串)。这些函数处理此消息,并且可能会或可能不会将其显示给用户。
错误消息应通过应用format函数来构造,在开头或结尾处不应包含换行符,并且不必指示错误,因为 LISP 系统将根据其首选样式处理这些错误。
| 序号 | 函数和描述 |
|---|---|
| 1 |
error format-string &rest args 它发出致命错误信号。无法从这种错误中继续;因此,error 永远不会返回到其调用方。 |
| 2 |
cerror continue-format-string error-format-string &rest args 它发出错误信号并进入调试器。但是,它允许程序在解决错误后从调试器中继续。 |
| 3 |
warn format-string &rest args 它打印错误消息,但通常不会进入调试器 |
| 4 |
break &optional format-string &rest args 它打印消息并直接进入调试器,而不允许任何程序错误处理设施拦截的可能性 |
示例
在此示例中,阶乘函数计算数字的阶乘;但是,如果参数为负数,则会引发错误条件。
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(defun factorial (x)
(cond ((or (not (typep x 'integer)) (minusp x))
(error "~S is a negative number." x))
((zerop x) 1)
(t (* x (factorial (- x 1))))
)
)
(write(factorial 5))
(terpri)
(write(factorial -1))
执行代码后,它将返回以下结果:
120 *** - -1 is a negative number.
LISP - CLOS
Common LISP 比面向对象编程的进步早了几十年。但是,面向对象在后期被整合到其中。
定义类
defclass 宏允许创建用户定义的类。它将类建立为数据类型。其语法如下:
(defclass class-name (superclass-name*) (slot-description*) class-option*))
槽是存储数据或字段的变量。
槽描述具有 (slot-name slot-option*) 的形式,其中每个选项都是一个关键字,后跟名称、表达式和其他选项。最常用的槽选项是:
:accessor function-name
:initform expression
:initarg symbol
例如,让我们定义一个 Box 类,它包含三个槽 length、breadth 和 height。
(defclass Box () (length breadth height) )
为槽提供访问和读/写控制
除非槽具有可以访问、读取或写入的值,否则类几乎没有用处。
您可以在定义类时为每个槽指定访问器。例如,以我们的 Box 类为例:
(defclass Box ()
((length :accessor length)
(breadth :accessor breadth)
(height :accessor height)
)
)
您还可以为读取和写入槽指定单独的访问器名称。
(defclass Box ()
((length :reader get-length :writer set-length)
(breadth :reader get-breadth :writer set-breadth)
(height :reader get-height :writer set-height)
)
)
创建类的实例
泛型函数make-instance创建并返回类的新的实例。
它具有以下语法:
(make-instance class {initarg value}*)
示例
让我们创建一个 Box 类,它包含三个槽 length、breadth 和 height。我们将使用三个槽访问器来设置这些字段中的值。
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(defclass box ()
((length :accessor box-length)
(breadth :accessor box-breadth)
(height :accessor box-height)
)
)
(setf item (make-instance 'box))
(setf (box-length item) 10)
(setf (box-breadth item) 10)
(setf (box-height item) 5)
(format t "Length of the Box is ~d~%" (box-length item))
(format t "Breadth of the Box is ~d~%" (box-breadth item))
(format t "Height of the Box is ~d~%" (box-height item))
执行代码后,它将返回以下结果:
Length of the Box is 10 Breadth of the Box is 10 Height of the Box is 5
定义类方法
defmethod 宏允许您在类中定义方法。以下示例扩展了我们的 Box 类以包含名为 volume 的方法。
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(defclass box ()
((length :accessor box-length)
(breadth :accessor box-breadth)
(height :accessor box-height)
(volume :reader volume)
)
)
; method calculating volume
(defmethod volume ((object box))
(* (box-length object) (box-breadth object)(box-height object))
)
;setting the values
(setf item (make-instance 'box))
(setf (box-length item) 10)
(setf (box-breadth item) 10)
(setf (box-height item) 5)
; displaying values
(format t "Length of the Box is ~d~%" (box-length item))
(format t "Breadth of the Box is ~d~%" (box-breadth item))
(format t "Height of the Box is ~d~%" (box-height item))
(format t "Volume of the Box is ~d~%" (volume item))
执行代码后,它将返回以下结果:
Length of the Box is 10 Breadth of the Box is 10 Height of the Box is 5 Volume of the Box is 500
继承
LISP 允许您根据另一个对象来定义对象。这称为继承。您可以通过添加新的或不同的功能来创建派生类。派生类继承父类的功能。
以下示例说明了这一点:
示例
创建一个名为main.lisp的新源代码文件,并在其中键入以下代码。
(defclass box ()
((length :accessor box-length)
(breadth :accessor box-breadth)
(height :accessor box-height)
(volume :reader volume)
)
)
; method calculating volume
(defmethod volume ((object box))
(* (box-length object) (box-breadth object)(box-height object))
)
;wooden-box class inherits the box class
(defclass wooden-box (box)
((price :accessor box-price)))
;setting the values
(setf item (make-instance 'wooden-box))
(setf (box-length item) 10)
(setf (box-breadth item) 10)
(setf (box-height item) 5)
(setf (box-price item) 1000)
; displaying values
(format t "Length of the Wooden Box is ~d~%" (box-length item))
(format t "Breadth of the Wooden Box is ~d~%" (box-breadth item))
(format t "Height of the Wooden Box is ~d~%" (box-height item))
(format t "Volume of the Wooden Box is ~d~%" (volume item))
(format t "Price of the Wooden Box is ~d~%" (box-price item))
执行代码后,它将返回以下结果:
Length of the Wooden Box is 10 Breadth of the Wooden Box is 10 Height of the Wooden Box is 5 Volume of the Wooden Box is 500 Price of the Wooden Box is 1000