- Mahout 有用资源
- Mahout - 快速指南
- Mahout - 资源
- Mahout - 讨论
Mahout - 聚类
聚类是根据项目之间的相似性,将给定集合中的元素或项目组织成组的过程。例如,与在线新闻发布相关的应用程序使用聚类对其新闻文章进行分组。
聚类的应用
聚类广泛应用于许多应用中,例如市场研究、模式识别、数据分析和图像处理。
聚类可以帮助营销人员在其客户群中发现不同的群体。他们可以根据购买模式来描述其客户群体。
在生物学领域,它可以用于推导植物和动物分类法,对具有相似功能的基因进行分类,并深入了解群体中固有的结构。
聚类有助于识别地球观测数据库中相似土地利用区域。
聚类还有助于对网络上的文档进行分类以进行信息发现。
聚类用于异常值检测应用程序,例如信用卡欺诈检测。
作为一种数据挖掘功能,聚类分析可作为一种工具来深入了解数据的分布,以观察每个聚类的特征。
使用 Mahout,我们可以对给定的数据集进行聚类。所需的步骤如下:
算法 您需要选择合适的聚类算法来对聚类的元素进行分组。
相似性和相异性 您需要制定规则来验证新遇到的元素与组中元素之间的相似性。
停止条件 需要一个停止条件来定义不需要聚类的点。
聚类过程
要对给定数据进行聚类,您需要:
启动 Hadoop 服务器。创建在 Hadoop 文件系统中存储文件的所需目录。(为输入文件、序列文件和(在 canopy 情况下)聚类输出创建目录)。
将输入文件从 Unix 文件系统复制到 Hadoop 文件系统。
根据输入数据准备序列文件。
运行任何可用的聚类算法。
获取聚类数据。
启动 Hadoop
Mahout 与 Hadoop 一起工作,因此请确保 Hadoop 服务器已启动并正在运行。
$ cd HADOOP_HOME/bin $ start-all.sh
准备输入文件目录
使用以下命令在 Hadoop 文件系统中创建目录以存储输入文件、序列文件和聚类数据
$ hadoop fs -p mkdir /mahout_data $ hadoop fs -p mkdir /clustered_data $ hadoop fs -p mkdir /mahout_seq
您可以使用以下 URL 中的 Hadoop Web 界面验证目录是否已创建:https://:50070/
它会给出如下所示的输出
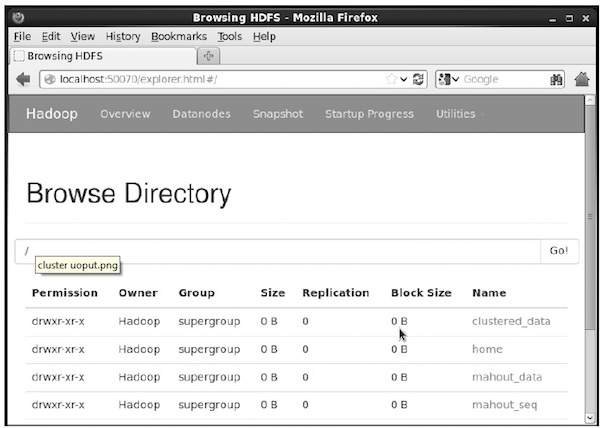
将输入文件复制到 HDFS
现在,将输入数据文件从 Linux 文件系统复制到 Hadoop 文件系统中的 mahout_data 目录,如下所示。假设您的输入文件是 mydata.txt,它位于 /home/Hadoop/data/ 目录中。
$ hadoop fs -put /home/Hadoop/data/mydata.txt /mahout_data/
准备序列文件
Mahout 提供了一个实用程序,用于将给定的输入文件转换为序列文件格式。此实用程序需要两个参数。
- 包含原始数据所在的输入文件目录。
- 要存储聚类数据的输出文件目录。
以下是 mahout seqdirectory 实用程序的帮助提示。
步骤 1: 浏览到 Mahout 主目录。您可以获得如下所示的实用程序帮助
[Hadoop@localhost bin]$ ./mahout seqdirectory --help Job-Specific Options: --input (-i) input Path to job input directory. --output (-o) output The directory pathname for output. --overwrite (-ow) If present, overwrite the output directory
使用以下语法使用实用程序生成序列文件
mahout seqdirectory -i <input file path> -o <output directory>
示例
mahout seqdirectory -i hdfs://:9000/mahout_seq/ -o hdfs://:9000/clustered_data/
聚类算法
Mahout 支持两种主要的聚类算法,即
- Canopy 聚类
- K 均值聚类
Canopy 聚类
Canopy 聚类是一种简单快速的 Mahout 聚类技术。对象将被视为平面空间中的点。此技术通常用作其他聚类技术(如 k 均值聚类)的初始步骤。您可以使用以下语法运行 Canopy 作业
mahout canopy -i <input vectors directory> -o <output directory> -t1 <threshold value 1> -t2 <threshold value 2>
Canopy 作业需要一个包含序列文件的输入文件目录和一个要存储聚类数据的输出目录。
示例
mahout canopy -i hdfs://:9000/mahout_seq/mydata.seq -o hdfs://:9000/clustered_data -t1 20 -t2 30
您将在给定的输出目录中获得生成的聚类数据。
K 均值聚类
K 均值聚类是一种重要的聚类算法。k 均值聚类算法中的 k 表示数据将被划分成的聚类数。例如,如果为此算法指定的 k 值选择为 3,则该算法将数据划分为 3 个聚类。
每个对象都将表示为空间中的向量。最初,算法将随机选择 k 个点并将其视为中心,每个最接近每个中心的物体都会被聚类。有几种距离度量算法,用户应该选择所需的算法。
创建向量文件
与 Canopy 算法不同,k 均值算法需要向量文件作为输入,因此您必须创建向量文件。
为了从序列文件格式生成向量文件,Mahout 提供了 seq2parse 实用程序。
以下是 seq2parse 实用程序的一些选项。使用这些选项创建向量文件。
$MAHOUT_HOME/bin/mahout seq2sparse --analyzerName (-a) analyzerName The class name of the analyzer --chunkSize (-chunk) chunkSize The chunkSize in MegaBytes. --output (-o) output The directory pathname for o/p --input (-i) input Path to job input directory.
创建向量后,继续进行 k 均值算法。运行 k 均值作业的语法如下:
mahout kmeans -i <input vectors directory> -c <input clusters directory> -o <output working directory> -dm <Distance Measure technique> -x <maximum number of iterations> -k <number of initial clusters>
K 均值聚类作业需要输入向量目录、输出聚类目录、距离度量、要执行的最大迭代次数以及一个表示输入数据将被划分为的聚类数的整数值。