- Mahout 有用资源
- Mahout 快速指南
- Mahout - 资源
- Mahout - 讨论
Mahout 快速指南
Mahout - 简介
我们生活在一个信息充裕的时代。信息过载已经达到了如此的高度,以至于有时难以管理我们小小的邮箱!想象一下,一些流行的网站(如 Facebook、Twitter 和 Youtube)每天必须收集和管理的数据和记录量。即使是鲜为人知的网站,接收大量信息也是很常见的。
通常,我们依靠数据挖掘算法来分析海量数据,以识别趋势并得出结论。但是,除非计算任务在云端分布在多台机器上运行,否则没有数据挖掘算法能够高效地处理非常大的数据集并在短时间内提供结果。
现在我们有了新的框架,允许我们将计算任务分解成多个片段,并在不同的机器上运行每个片段。Mahout 就是这样一个数据挖掘框架,它通常在其后台与 Hadoop 基础架构耦合运行,以管理海量数据。
什么是 Apache Mahout?
Mahout 指的是驾驭大象的驯象人。这个名字来源于它与 Apache Hadoop 的密切关联,后者使用大象作为其标志。
Hadoop 是 Apache 的一个开源框架,它允许使用简单的编程模型在计算机集群的分布式环境中存储和处理大数据。
Apache Mahout 是一个开源项目,主要用于创建可扩展的机器学习算法。它实现了流行的机器学习技术,例如:
- 推荐系统
- 分类
- 聚类
Apache Mahout 于 2008 年作为 Apache Lucene 的子项目启动。2010 年,Mahout 成为 Apache 的顶级项目。
Mahout 的特点
下面列出了 Apache Mahout 的主要特点。
Mahout 的算法构建在 Hadoop 之上,因此它在分布式环境中运行良好。Mahout 使用 Apache Hadoop 库在云中有效地进行扩展。
Mahout 为程序员提供了一个现成的框架,用于对海量数据执行数据挖掘任务。
Mahout 允许应用程序有效且快速地分析大型数据集。
包含多个支持 MapReduce 的聚类实现,例如 k-means、模糊 k-means、Canopy、Dirichlet 和 Mean-Shift。
支持分布式朴素贝叶斯和互补朴素贝叶斯分类实现。
具有用于进化编程的分布式适应度函数功能。
包含矩阵和向量库。
Mahout 的应用
Adobe、Facebook、LinkedIn、Foursquare、Twitter 和 Yahoo 等公司都在内部使用 Mahout。
Foursquare 帮助你找到特定区域可用的场所、食物和娱乐。它使用 Mahout 的推荐引擎。
Twitter 使用 Mahout 进行用户兴趣建模。
雅虎!使用 Mahout 进行模式挖掘。
Mahout - 机器学习
Apache Mahout 是一个高度可扩展的机器学习库,它使开发人员能够使用优化的算法。Mahout 实现了流行的机器学习技术,例如推荐、分类和聚类。因此,在我们进一步讲解之前,最好简要介绍一下机器学习。
什么是机器学习?
机器学习是科学的一个分支,它处理以这样的方式对系统进行编程:它们会根据经验自动学习和改进。在这里,学习意味着识别和理解输入数据,并根据提供的数据做出明智的决策。
根据所有可能的输入来满足所有决策是非常困难的。为了解决这个问题,开发了算法。这些算法根据统计学、概率论、逻辑、组合优化、搜索、强化学习和控制理论的原理,从特定数据和过去的经验中构建知识。
开发的算法构成了各种应用程序的基础,例如:
- 视觉处理
- 语言处理
- 预测(例如,股市趋势)
- 模式识别
- 游戏
- 数据挖掘
- 专家系统
- 机器人技术
机器学习是一个广阔的领域,本教程无法涵盖其所有功能。有多种方法可以实现机器学习技术,但是最常用的方法是监督学习和无监督学习。
监督学习
监督学习处理从可用的训练数据中学习函数。监督学习算法分析训练数据并生成一个推断函数,该函数可用于映射新示例。监督学习的常见示例包括:
- 将电子邮件分类为垃圾邮件;
- 根据其内容标记网页;以及
- 语音识别。
有很多监督学习算法,例如神经网络、支持向量机 (SVM) 和朴素贝叶斯分类器。Mahout 实现了朴素贝叶斯分类器。
无监督学习
无监督学习无需任何预定义的训练数据集即可理解未标记的数据。无监督学习是分析可用数据并查找模式和趋势的极其强大的工具。它最常用于将相似的输入聚类到逻辑组中。无监督学习的常见方法包括:
- k-means
- 自组织映射;以及
- 层次聚类
推荐系统
推荐是一种流行的技术,它根据用户信息(例如之前的购买、点击和评分)提供相似的推荐。
亚马逊使用此技术来显示您可能感兴趣的推荐商品列表,这些信息来自您的过去行为。亚马逊背后有推荐引擎来捕捉用户行为,并根据您之前的行为推荐选择的商品。
Facebook 使用推荐技术来识别和推荐“你可能认识的人”列表。

分类
分类,也称为分类,是一种机器学习技术,它使用已知数据来确定如何将新数据分类到一组现有类别中。分类是一种监督学习形式。
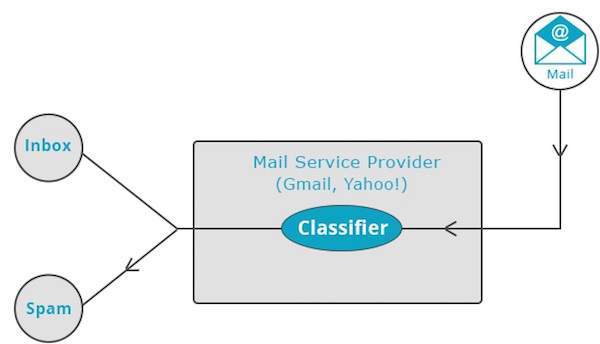
雅虎!和 Gmail 等邮件服务提供商使用此技术来确定是否应将新邮件分类为垃圾邮件。分类算法通过分析用户将某些邮件标记为垃圾邮件的习惯来自我训练。基于此,分类器会决定是否应将未来的邮件存放到您的收件箱中或垃圾邮件文件夹中。
iTunes 应用程序使用分类来准备播放列表。
聚类
聚类用于根据共同特征形成相似数据的组或聚类。聚类是一种无监督学习形式。
谷歌和雅虎!等搜索引擎使用聚类技术对具有相似特征的数据进行分组。
新闻组使用聚类技术根据相关主题对各种文章进行分组。
聚类引擎会完全遍历输入数据,并根据数据的特征决定应将其分组到哪个聚类中。请看下面的例子。
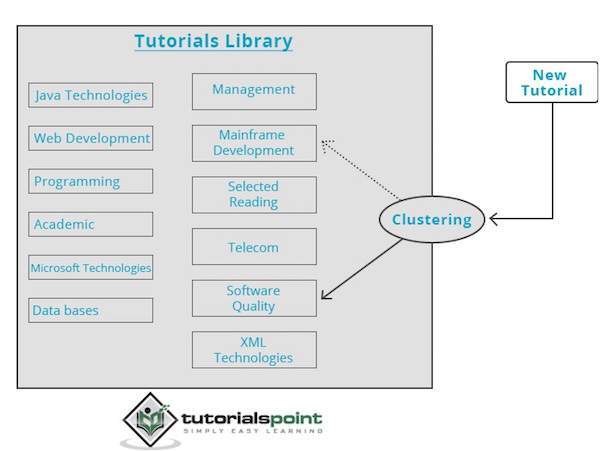
我们的教程库包含关于各种主题的主题。当我们在 TutorialsPoint 收到新的教程时,它会由聚类引擎处理,该引擎会根据其内容决定将其分组到哪里。
Mahout - 环境配置
本章将教你如何设置 Mahout。Java 和 Hadoop 是 Mahout 的先决条件。下面是下载和安装 Java、Hadoop 和 Mahout 的步骤。
预安装设置
在将 Hadoop 安装到 Linux 环境之前,我们需要使用ssh(安全外壳)设置 Linux。请按照以下步骤设置 Linux 环境。
创建用户
建议为 Hadoop 创建一个单独的用户,以将 Hadoop 文件系统与 Unix 文件系统隔离。请按照以下步骤创建用户
使用命令“su”打开 root。
- 使用命令“useradd 用户名”从 root 帐户创建用户。
现在,您可以使用命令“su 用户名”打开现有的用户帐户。
打开 Linux 终端,并键入以下命令以创建用户。
$ su password: # useradd hadoop # passwd hadoop New passwd: Retype new passwd
SSH 设置和密钥生成
SSH 设置是执行集群上不同操作(例如启动、停止和分布式守护进程 shell 操作)所必需的。为了验证 Hadoop 的不同用户,需要为 Hadoop 用户提供公钥/私钥对,并与不同的用户共享。
以下命令用于使用 SSH 生成密钥值对,将公钥从 id_rsa.pub 复制到 authorized_keys,并分别为 authorized_keys 文件提供所有者、读和写权限。
$ ssh-keygen -t rsa $ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys $ chmod 0600 ~/.ssh/authorized_keys
验证 ssh
ssh localhost
安装 Java
Java 是 Hadoop 和 HBase 的主要先决条件。首先,你应该使用“java -version”验证系统中 Java 的存在。Java 版本命令的语法如下所示。
$ java -version
它应该产生以下输出。
java version "1.7.0_71" Java(TM) SE Runtime Environment (build 1.7.0_71-b13) Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)
如果你的系统中没有安装 Java,那么请按照以下步骤安装 Java。
步骤 1
访问以下链接下载 java(JDK <最新版本> - X64.tar.gz):Oracle
然后jdk-7u71-linux-x64.tar.gz 下载到你的系统上。
步骤 2
通常,你会在“下载”文件夹中找到下载的 Java 文件。验证它并使用以下命令解压jdk-7u71-linux-x64.gz文件。
$ cd Downloads/ $ ls jdk-7u71-linux-x64.gz $ tar zxf jdk-7u71-linux-x64.gz $ ls jdk1.7.0_71 jdk-7u71-linux-x64.gz
步骤 3
为了使 Java 可供所有用户使用,你需要将其移动到“/usr/local/”位置。打开 root,并键入以下命令。
$ su password: # mv jdk1.7.0_71 /usr/local/ # exit
步骤 4
为了设置PATH和JAVA_HOME变量,请将以下命令添加到~/.bashrc 文件中。
export JAVA_HOME=/usr/local/jdk1.7.0_71 export PATH= $PATH:$JAVA_HOME/bin
现在,如上所述,从终端验证java -version命令。
下载 Hadoop
安装 Java 后,你需要先安装 Hadoop。使用以下所示的“Hadoop version”命令验证 Hadoop 的存在。
hadoop version
它应该产生以下输出
Hadoop 2.6.0 Compiled by jenkins on 2014-11-13T21:10Z Compiled with protoc 2.5.0 From source with checksum 18e43357c8f927c0695f1e9522859d6a This command was run using /home/hadoop/hadoop/share/hadoop/common/hadoopcommon-2.6.0.jar
如果你的系统无法找到 Hadoop,那么请下载 Hadoop 并将其安装到你的系统上。请按照以下命令操作。
使用以下命令从 Apache 软件基金会下载并解压 hadoop-2.6.0。
$ su password: # cd /usr/local # wget http://mirrors.advancedhosters.com/apache/hadoop/common/hadoop- 2.6.0/hadoop-2.6.0-src.tar.gz # tar xzf hadoop-2.6.0-src.tar.gz # mv hadoop-2.6.0/* hadoop/ # exit
安装 Hadoop
以任何所需模式安装 Hadoop。在这里,我们演示了伪分布式模式下的 HBase 功能,因此请以伪分布式模式安装 Hadoop。
请按照以下步骤在你的系统上安装Hadoop 2.4.1。
步骤 1:设置 Hadoop
你可以通过将以下命令添加到~/.bashrc文件中来设置 Hadoop 环境变量。
export HADOOP_HOME=/usr/local/hadoop export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin export HADOOP_INSTALL=$HADOOP_HOME
现在,将所有更改应用到当前正在运行的系统。
$ source ~/.bashrc
步骤 2:Hadoop 配置
你可以在“$HADOOP_HOME/etc/hadoop”位置找到所有 Hadoop 配置文件。需要根据你的 Hadoop 基础架构更改这些配置文件。
$ cd $HADOOP_HOME/etc/hadoop
为了用 Java 开发 Hadoop 程序,你需要通过用系统中 Java 的位置替换JAVA_HOME值来重置hadoop-env.sh文件中的 Java 环境变量。
export JAVA_HOME=/usr/local/jdk1.7.0_71
下面列出了你需要编辑以配置 Hadoop 的文件列表。
core-site.xml
core-site.xml文件包含诸如 Hadoop 实例使用的端口号、为文件系统分配的内存、存储数据的内存限制以及读/写缓冲区的大小等信息。
打开 core-site.xml 文件,在 `
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://:9000</value>
</property>
</configuration>
hdfs-site.xml
hdfs-site.xml 文件包含诸如复制数据值、namenode 路径和本地文件系统的 datanode 路径等信息。这意味着您希望存储 Hadoop 基础架构的位置。
让我们假设以下数据
dfs.replication (data replication value) = 1 (In the below given path /hadoop/ is the user name. hadoopinfra/hdfs/namenode is the directory created by hdfs file system.) namenode path = //home/hadoop/hadoopinfra/hdfs/namenode (hadoopinfra/hdfs/datanode is the directory created by hdfs file system.) datanode path = //home/hadoop/hadoopinfra/hdfs/datanode
打开此文件,在此文件的 `
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode</value>
</property>
</configuration>
注意:在上文中,所有属性值都是用户定义的。您可以根据您的 Hadoop 基础架构进行更改。
mapred-site.xml
此文件用于将 yarn 配置到 Hadoop 中。打开 mapred-site.xml 文件,在此文件的 `
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
mapred-site.xml
此文件用于指定我们正在使用哪个 MapReduce 框架。默认情况下,Hadoop 包含 mapred-site.xml 的模板。首先,需要使用以下命令将文件从 mapred-site.xml.template 复制到 mapred-site.xml 文件。
$ cp mapred-site.xml.template mapred-site.xml
打开 mapred-site.xml 文件,在此文件的 `
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
验证 Hadoop 安装
以下步骤用于验证 Hadoop 安装。
步骤 1:Name Node 设置
使用命令“hdfs namenode -format”设置 namenode,如下所示
$ cd ~ $ hdfs namenode -format
预期结果如下所示
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = localhost/192.168.1.11 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.4.1 ... ... 10/24/14 21:30:56 INFO common.Storage: Storage directory /home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted. 10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0 10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11 ************************************************************/
步骤 2:验证 Hadoop dfs
以下命令用于启动 dfs。此命令启动您的 Hadoop 文件系统。
$ start-dfs.sh
预期输出如下所示
10/24/14 21:37:56 Starting namenodes on [localhost] localhost: starting namenode, logging to /home/hadoop/hadoop- 2.4.1/logs/hadoop-hadoop-namenode-localhost.out localhost: starting datanode, logging to /home/hadoop/hadoop- 2.4.1/logs/hadoop-hadoop-datanode-localhost.out Starting secondary namenodes [0.0.0.0]
步骤 3:验证 Yarn 脚本
以下命令用于启动 yarn 脚本。执行此命令将启动您的 yarn 守护进程。
$ start-yarn.sh
预期输出如下所示
starting yarn daemons starting resource manager, logging to /home/hadoop/hadoop-2.4.1/logs/yarn- hadoop-resourcemanager-localhost.out localhost: starting node manager, logging to /home/hadoop/hadoop- 2.4.1/logs/yarn-hadoop-nodemanager-localhost.out
步骤 4:在浏览器上访问 Hadoop
访问 hadoop 的默认端口号为 50070。使用以下 URL 在浏览器上获取 Hadoop 服务。
https://:50070/
步骤 5:验证集群的所有应用程序
访问集群所有应用程序的默认端口号为 8088。使用以下 URL 访问此服务。
https://:8088/
下载 Mahout
Mahout 可在网站 Mahout 上获得。从网站提供的链接下载 Mahout。以下是网站的屏幕截图。
步骤 1
使用以下命令从链接 https://mahout.apache.org/general/downloads 下载 Apache mahout。
[Hadoop@localhost ~]$ wget http://mirror.nexcess.net/apache/mahout/0.9/mahout-distribution-0.9.tar.gz
然后 mahout-distribution-0.9.tar.gz 将下载到您的系统中。
步骤 2
浏览存储 mahout-distribution-0.9.tar.gz 的文件夹,并解压下载的 jar 文件,如下所示。
[Hadoop@localhost ~]$ tar zxvf mahout-distribution-0.9.tar.gz
Maven 仓库
以下是使用 Eclipse 构建 Apache Mahout 的 pom.xml。
<dependency>
<groupId>org.apache.mahout</groupId>
<artifactId>mahout-core</artifactId>
<version>0.9</version>
</dependency>
<dependency>
<groupId>org.apache.mahout</groupId>
<artifactId>mahout-math</artifactId>
<version>${mahout.version}</version>
</dependency>
<dependency>
<groupId>org.apache.mahout</groupId>
<artifactId>mahout-integration</artifactId>
<version>${mahout.version}</version>
</dependency>
Mahout - 推荐系统
本章介绍流行的机器学习技术——推荐,其机制以及如何编写实现 Mahout 推荐的应用程序。
推荐系统
您是否曾经想过亚马逊是如何提出推荐商品列表,来吸引您注意您可能感兴趣的特定产品的!
假设您想从亚马逊购买“Mahout in Action”这本书
除了所选产品外,亚马逊还会显示相关的推荐商品列表,如下所示。
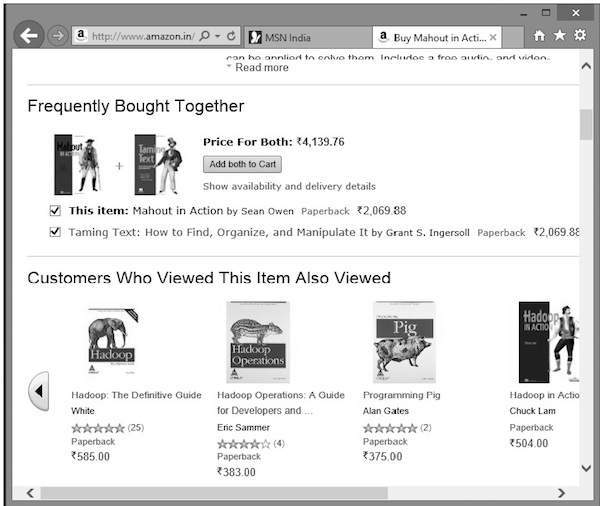
此类推荐列表是在 推荐引擎 的帮助下生成的。Mahout 提供了几种类型的推荐引擎,例如
- 基于用户的推荐器,
- 基于项目的推荐器,以及
- 其他几种算法。
Mahout 推荐引擎
Mahout 有一个非分布式、非基于 Hadoop 的推荐引擎。您应该传递一个包含用户对商品偏好的文本文档。该引擎的输出将是特定用户对其他商品的估计偏好。
示例
考虑一个销售消费品(如手机、小工具及其配件)的网站。如果我们想在此类网站中实现 Mahout 的功能,那么我们可以构建一个推荐引擎。该引擎分析用户的过去购买数据,并据此推荐新产品。
Mahout 提供的用于构建推荐引擎的组件如下
- 数据模型 (DataModel)
- 用户相似度 (UserSimilarity)
- 项目相似度 (ItemSimilarity)
- 用户邻域 (UserNeighborhood)
- 推荐器 (Recommender)
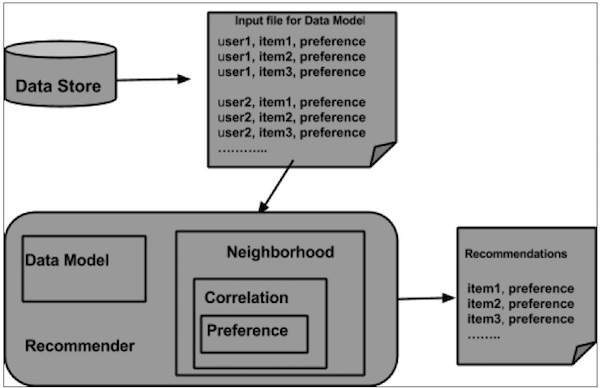
从数据存储中准备数据模型,并将其作为输入传递给推荐引擎。推荐引擎会为特定用户生成推荐。以下是推荐引擎的架构。
推荐引擎架构
使用 Mahout 构建推荐器
以下是开发简单推荐器的步骤
步骤 1:创建 DataModel 对象
PearsonCorrelationSimilarity 类的构造函数需要一个数据模型对象,该对象保存包含用户、商品和产品偏好详细信息的文件。以下是示例数据模型文件
1,00,1.0 1,01,2.0 1,02,5.0 1,03,5.0 1,04,5.0 2,00,1.0 2,01,2.0 2,05,5.0 2,06,4.5 2,02,5.0 3,01,2.5 3,02,5.0 3,03,4.0 3,04,3.0 4,00,5.0 4,01,5.0 4,02,5.0 4,03,0.0
DataModel 对象需要文件对象,其中包含输入文件的路径。如下所示创建 DataModel 对象。
DataModel datamodel = new FileDataModel(new File("input file"));
步骤 2:创建 UserSimilarity 对象
如下所示,使用 PearsonCorrelationSimilarity 类创建 UserSimilarity 对象
UserSimilarity similarity = new PearsonCorrelationSimilarity(datamodel);
步骤 3:创建 UserNeighborhood 对象
此对象计算与给定用户相似的用户“邻域”。邻域有两种类型
NearestNUserNeighborhood - 此类计算一个邻域,该邻域包含与给定用户最近的 *n* 个用户。“最近”由给定的 UserSimilarity 定义。
ThresholdUserNeighborhood - 此类计算一个邻域,该邻域包含所有与给定用户的相似度达到或超过某个阈值的用户的相似度。相似度由给定的 UserSimilarity 定义。
这里我们使用 ThresholdUserNeighborhood 并将偏好限制设置为 3.0。
UserNeighborhood neighborhood = new ThresholdUserNeighborhood(3.0, similarity, model);
步骤 4:创建 Recommender 对象
创建 UserbasedRecomender 对象。将所有上述创建的对象传递给其构造函数,如下所示。
UserBasedRecommender recommender = new GenericUserBasedRecommender(model, neighborhood, similarity);
步骤 5:向用户推荐商品
使用 Recommender 接口的 recommend() 方法向用户推荐产品。此方法需要两个参数。第一个表示需要向其发送推荐的用户 ID,第二个表示要发送的推荐数量。以下是 recommender() 方法的用法
List<RecommendedItem> recommendations = recommender.recommend(2, 3);
for (RecommendedItem recommendation : recommendations) {
System.out.println(recommendation);
}
示例程序
以下是设置推荐的示例程序。为用户 ID 为 2 的用户准备推荐。
import java.io.File;
import java.util.List;
import org.apache.mahout.cf.taste.impl.model.file.FileDataModel;
import org.apache.mahout.cf.taste.impl.neighborhood.ThresholdUserNeighborhood;
import org.apache.mahout.cf.taste.impl.recommender.GenericUserBasedRecommender;
import org.apache.mahout.cf.taste.impl.similarity.PearsonCorrelationSimilarity;
import org.apache.mahout.cf.taste.model.DataModel;
import org.apache.mahout.cf.taste.neighborhood.UserNeighborhood;
import org.apache.mahout.cf.taste.recommender.RecommendedItem;
import org.apache.mahout.cf.taste.recommender.UserBasedRecommender;
import org.apache.mahout.cf.taste.similarity.UserSimilarity;
public class Recommender {
public static void main(String args[]){
try{
//Creating data model
DataModel datamodel = new FileDataModel(new File("data")); //data
//Creating UserSimilarity object.
UserSimilarity usersimilarity = new PearsonCorrelationSimilarity(datamodel);
//Creating UserNeighbourHHood object.
UserNeighborhood userneighborhood = new ThresholdUserNeighborhood(3.0, usersimilarity, datamodel);
//Create UserRecomender
UserBasedRecommender recommender = new GenericUserBasedRecommender(datamodel, userneighborhood, usersimilarity);
List<RecommendedItem> recommendations = recommender.recommend(2, 3);
for (RecommendedItem recommendation : recommendations) {
System.out.println(recommendation);
}
}catch(Exception e){}
}
}
使用以下命令编译程序
javac Recommender.java java Recommender
它应该产生以下输出
RecommendedItem [item:3, value:4.5] RecommendedItem [item:4, value:4.0]
Mahout - 聚类
聚类是根据项目之间的相似性将给定集合的元素或项目组织成组的过程。例如,与在线新闻发布相关的应用程序使用聚类对其新闻文章进行分组。
聚类的应用
聚类广泛应用于许多应用程序中,例如市场研究、模式识别、数据分析和图像处理。
聚类可以帮助营销人员在其客户群中发现不同的群体。他们可以根据购买模式来描述其客户群体。
在生物学领域,它可用于推导植物和动物分类法、对具有相似功能的基因进行分类以及深入了解群体中固有的结构。
聚类有助于识别地球观测数据库中具有相似土地利用面积的区域。
聚类还有助于对网络上的文档进行分类以进行信息发现。
聚类用于异常值检测应用程序,例如信用卡欺诈检测。
作为一种数据挖掘功能,聚类分析可作为一种工具来深入了解数据的分布,从而观察每个聚类的特征。
使用 Mahout,我们可以对给定的一组数据进行聚类。所需的步骤如下
算法您需要选择合适的聚类算法来对聚类的元素进行分组。
相似性和相异性您需要制定规则来验证新遇到的元素与组中元素之间的相似性。
停止条件需要停止条件来定义不需要聚类的点。
聚类过程
要对给定数据进行聚类,您需要:
启动 Hadoop 服务器。创建在 Hadoop 文件系统中存储文件的所需目录。(为输入文件、序列文件和(在 canopy 的情况下)聚类输出创建目录)。
将输入文件从 Unix 文件系统复制到 Hadoop 文件系统。
从输入数据准备序列文件。
运行任何可用的聚类算法。
获取聚类数据。
启动 Hadoop
Mahout 与 Hadoop 一起工作,因此请确保 Hadoop 服务器已启动并正在运行。
$ cd HADOOP_HOME/bin $ start-all.sh
准备输入文件目录
使用以下命令在 Hadoop 文件系统中创建目录以存储输入文件、序列文件和聚类数据
$ hadoop fs -p mkdir /mahout_data $ hadoop fs -p mkdir /clustered_data $ hadoop fs -p mkdir /mahout_seq
您可以使用以下 URL 中的 hadoop Web 界面验证是否创建了目录:https://:50070/
它会给你如下所示的输出
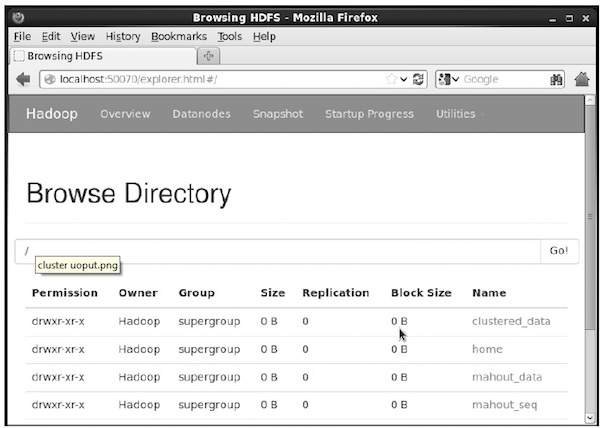
将输入文件复制到 HDFS
现在,将输入数据文件从 Linux 文件系统复制到 Hadoop 文件系统中的 mahout_data 目录,如下所示。假设您的输入文件是 mydata.txt,并且它位于 /home/Hadoop/data/ 目录中。
$ hadoop fs -put /home/Hadoop/data/mydata.txt /mahout_data/
准备序列文件
Mahout 为您提供了一个实用程序,用于将给定的输入文件转换为序列文件格式。此实用程序需要两个参数。
- 包含原始数据所在的输入文件目录。
- 要存储聚类数据所在的输出文件目录。
以下是 mahout seqdirectory 实用程序的帮助提示。
步骤 1:浏览到 Mahout 主目录。您可以获得如下所示的实用程序帮助
[Hadoop@localhost bin]$ ./mahout seqdirectory --help Job-Specific Options: --input (-i) input Path to job input directory. --output (-o) output The directory pathname for output. --overwrite (-ow) If present, overwrite the output directory
使用以下语法使用实用程序生成序列文件
mahout seqdirectory -i <input file path> -o <output directory>
示例
mahout seqdirectory -i hdfs://:9000/mahout_seq/ -o hdfs://:9000/clustered_data/
聚类算法
Mahout 支持两种主要的聚类算法,即
- Canopy 聚类
- K 均值聚类
Canopy 聚类
Canopy 聚类是 Mahout 用于聚类目的的一种简单而快速的技法。对象将被视为平面空间中的点。此技术通常用作其他聚类技术(例如 k 均值聚类)的初始步骤。您可以使用以下语法运行 Canopy 作业
mahout canopy -i <input vectors directory> -o <output directory> -t1 <threshold value 1> -t2 <threshold value 2>
Canopy 作业需要一个包含序列文件的输入文件目录和一个要存储聚类数据的输出目录。
示例
mahout canopy -i hdfs://:9000/mahout_seq/mydata.seq -o hdfs://:9000/clustered_data -t1 20 -t2 30
您将在给定的输出目录中获得生成的聚类数据。
K 均值聚类
K 均值聚类是一种重要的聚类算法。k 均值聚类算法中的 k 表示要将数据划分为的聚类数量。例如,如果为此算法指定的 k 值选择为 3,则该算法将数据分为 3 个聚类。
每个对象都将被表示为空间中的向量。初始时,算法将随机选择k个点作为中心,每个最接近每个中心的物体都被聚类。距离度量有几种算法,用户应该选择所需的算法。
创建向量文件
与Canopy算法不同,k-means算法需要向量文件作为输入,因此您必须创建向量文件。
要从序列文件格式生成向量文件,Mahout 提供了seq2parse实用程序。
下面列出了一些seq2parse实用程序的选项。使用这些选项创建向量文件。
$MAHOUT_HOME/bin/mahout seq2sparse --analyzerName (-a) analyzerName The class name of the analyzer --chunkSize (-chunk) chunkSize The chunkSize in MegaBytes. --output (-o) output The directory pathname for o/p --input (-i) input Path to job input directory.
创建向量后,继续进行k-means算法。运行k-means作业的语法如下
mahout kmeans -i <input vectors directory> -c <input clusters directory> -o <output working directory> -dm <Distance Measure technique> -x <maximum number of iterations> -k <number of initial clusters>
K-means聚类作业需要输入向量目录、输出聚类目录、距离度量、要执行的最大迭代次数以及表示输入数据要划分成的聚类数量的整数值。
Mahout - 分类
什么是分类?
分类是一种机器学习技术,它使用已知数据来确定如何将新数据分类到一组现有类别中。例如:
iTunes 应用程序使用分类来准备播放列表。
雅虎!和 Gmail 等邮件服务提供商使用此技术来确定是否应将新邮件分类为垃圾邮件。分类算法通过分析用户将某些邮件标记为垃圾邮件的习惯来自我训练。基于此,分类器会决定是否应将未来的邮件存放到您的收件箱中或垃圾邮件文件夹中。
分类的工作原理
在对给定数据集进行分类时,分类器系统执行以下操作
- 首先,使用任何学习算法准备新的数据模型。
- 然后测试准备好的数据模型。
- 此后,使用此数据模型来评估新数据并确定其类别。
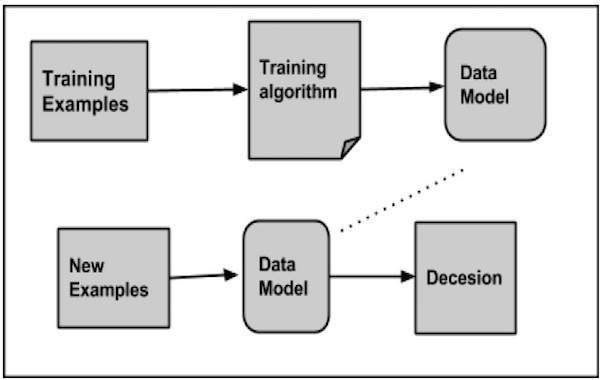
分类的应用
信用卡欺诈检测 - 分类机制用于预测信用卡欺诈。使用以前欺诈的历史信息,分类器可以预测哪些未来的交易可能变成欺诈。
垃圾邮件 - 根据以前垃圾邮件的特征,分类器确定是否应将新遇到的电子邮件发送到垃圾邮件文件夹。
朴素贝叶斯分类器
Mahout 使用朴素贝叶斯分类器算法。它使用两种实现
- 分布式朴素贝叶斯分类
- 互补朴素贝叶斯分类
朴素贝叶斯是一种构建分类器的简单技术。它不是用于训练此类分类器的单一算法,而是一系列算法。贝叶斯分类器构建模型来对问题实例进行分类。这些分类是使用可用数据进行的。
朴素贝叶斯的优势在于,它只需要少量训练数据即可估计分类所需的必要参数。
对于某些类型的概率模型,朴素贝叶斯分类器可以在监督学习环境中非常有效地进行训练。
尽管其假设过于简化,但朴素贝叶斯分类器在许多复杂的现实世界情况中都表现良好。
分类过程
要实现分类,需要遵循以下步骤
- 生成示例数据
- 从数据创建序列文件
- 将序列文件转换为向量
- 训练向量
- 测试向量
步骤1:生成示例数据
生成或下载要分类的数据。例如,您可以从以下链接获取20 个新闻组示例数据:http://people.csail.mit.edu/jrennie/20Newsgroups/20news-bydate.tar.gz
创建一个目录用于存储输入数据。如下所示下载示例。
$ mkdir classification_example $ cd classification_example $tar xzvf 20news-bydate.tar.gz wget http://people.csail.mit.edu/jrennie/20Newsgroups/20news-bydate.tar.gz
步骤2:创建序列文件
使用seqdirectory实用程序从示例创建序列文件。生成序列的语法如下所示
mahout seqdirectory -i <input file path> -o <output directory>
步骤3:将序列文件转换为向量
使用seq2parse实用程序从序列文件创建向量文件。seq2parse实用程序的选项如下所示
$MAHOUT_HOME/bin/mahout seq2sparse --analyzerName (-a) analyzerName The class name of the analyzer --chunkSize (-chunk) chunkSize The chunkSize in MegaBytes. --output (-o) output The directory pathname for o/p --input (-i) input Path to job input directory.
步骤4:训练向量
使用trainnb实用程序训练生成的向量。使用trainnb实用程序的选项如下所示
mahout trainnb
-i ${PATH_TO_TFIDF_VECTORS}
-el
-o ${PATH_TO_MODEL}/model
-li ${PATH_TO_MODEL}/labelindex
-ow
-c
步骤5:测试向量
使用testnb实用程序测试向量。使用testnb实用程序的选项如下所示
mahout testnb
-i ${PATH_TO_TFIDF_TEST_VECTORS}
-m ${PATH_TO_MODEL}/model
-l ${PATH_TO_MODEL}/labelindex
-ow
-o ${PATH_TO_OUTPUT}
-c
-seq