NLP - 信息检索
信息检索 (IR) 可以定义为一种软件程序,它处理从文档存储库(特别是文本信息)中组织、存储、检索和评估信息。该系统帮助用户找到他们需要的信息,但它不会明确地返回问题的答案。它告知可能包含所需信息文档的存在和位置。满足用户需求的文档称为相关文档。完美的 IR 系统只会检索相关文档。
借助下图,我们可以了解信息检索 (IR) 的过程:
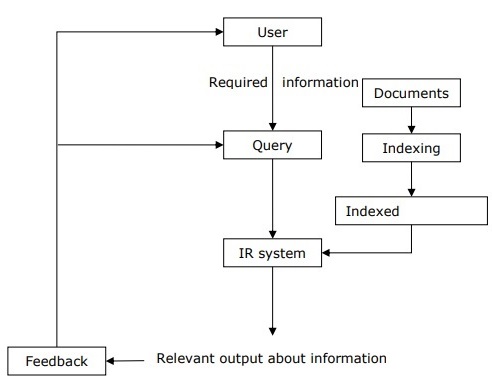
从上图可以清楚地看出,需要信息的使用者必须以自然语言查询的形式提出请求。然后,IR 系统将通过以文档形式检索相关输出,来响应所需信息。
信息检索 (IR) 系统中的经典问题
IR 研究的主要目标是开发一个从文档存储库中检索信息的模型。在这里,我们将讨论一个与 IR 系统相关的经典问题,称为 **临时检索问题**。
在临时检索中,用户必须输入一个用自然语言描述所需信息的查询。然后,IR 系统将返回与所需信息相关的所需文档。例如,假设我们在互联网上搜索某些内容,它会提供一些根据我们的需求相关的精确页面,但也可能有一些不相关的页面。这是由于临时检索问题造成的。
临时检索的方面
以下是 IR 研究中解决的一些临时检索方面:
用户如何借助相关反馈改进查询的原始表述?
如何实现数据库合并,即如何将来自不同文本数据库的结果合并到一个结果集中?
如何处理部分损坏的数据?哪些模型适用于此?
信息检索 (IR) 模型
在数学上,模型被用于许多科学领域,其目标是理解现实世界中的一些现象。信息检索模型预测并解释用户在与给定查询相关的方面会发现什么。IR 模型基本上是一个模式,它定义了上述检索过程的各个方面,并包括以下内容:
文档模型。
查询模型。
将查询与文档进行比较的匹配函数。
在数学上,检索模型包括:
**D** - 文档表示。
**R** - 查询表示。
**F** - D、Q 的建模框架以及它们之间关系。
**R (q,di)** - 一个相似度函数,根据查询对文档进行排序。它也称为排序。
信息检索 (IR) 模型的类型
信息模型 (IR) 模型可以分为以下三种模型:
经典 IR 模型
这是最简单且易于实现的 IR 模型。该模型基于数学知识,易于识别和理解。布尔、向量和概率是三种经典的 IR 模型。
非经典 IR 模型
它与经典 IR 模型完全相反。此类 IR 模型基于相似性、概率、布尔运算以外的原理。信息逻辑模型、情境理论模型和交互模型是非经典 IR 模型的示例。
替代 IR 模型
它是经典 IR 模型的增强,利用了来自其他领域的一些特定技术。聚类模型、模糊模型和潜在语义索引 (LSI) 模型是替代 IR 模型的示例。
信息检索 (IR) 系统的设计特征
现在让我们学习一下 IR 系统的设计特征:
倒排索引
大多数 IR 系统的主要数据结构采用倒排索引的形式。我们可以将倒排索引定义为一种数据结构,它列出每个单词包含它的所有文档以及在文档中出现的频率。它可以轻松搜索查询词的“命中”。
停用词消除
停用词是指那些频率很高的词,被认为不太可能用于搜索。它们的语义权重较低。所有此类单词都位于一个称为停用词列表的列表中。例如,冠词“a”、“an”、“the”和介词如“in”、“of”、“for”、“at”等是停用词的示例。停用词列表可以显着减少倒排索引的大小。根据齐夫定律,包含几十个单词的停用词列表将倒排索引的大小减少了近一半。另一方面,有时停用词的消除可能会导致用于搜索的有用术语的消除。例如,如果我们从“维生素 A”中消除字母“A”,则它将没有任何意义。
词干提取
词干提取,形态分析的简化形式,是通过截取单词结尾来提取单词基本形式的启发式过程。例如,单词 laughing、laughs、laughed 将被词干提取为根词 laugh。
在我们接下来的章节中,我们将讨论一些重要且有用的 IR 模型。
布尔模型
这是最古老的信息检索 (IR) 模型。该模型基于集合论和布尔代数,其中文档是术语的集合,查询是术语上的布尔表达式。布尔模型可以定义为:
**D** - 一组词,即文档中存在的索引词。这里,每个词要么存在 (1),要么不存在 (0)。
**Q** - 一个布尔表达式,其中术语是索引词,运算符是逻辑积 - AND、逻辑和 - OR 和逻辑差 - NOT
**F** - 布尔代数,作用于术语集以及文档集
如果我们谈论相关反馈,那么在布尔 IR 模型中,相关预测可以定义如下:
**R** - 当且仅当文档满足查询表达式时,才预测文档与查询表达式相关,如下所示:
((𝑡𝑒𝑥𝑡 ˅ 𝑖𝑛𝑓𝑜𝑟𝑚𝑎𝑡𝑖𝑜𝑛) ˄ 𝑟𝑒𝑟𝑖𝑒𝑣𝑎𝑙 ˄ ˜ 𝑡ℎ𝑒𝑜𝑟𝑦)
我们可以通过将查询词解释为文档集的明确定义来解释此模型。
例如,查询词 **“经济”** 定义了用术语 **“经济”** 索引的文档集。
现在,使用布尔 AND 运算符组合术语后的结果是什么?它将定义一个文档集,该文档集小于或等于任何单个术语的文档集。例如,带有术语 **“社会”** 和 **“经济”** 的查询将生成用这两个术语索引的文档集。换句话说,这两个集合的交集的文档集。
现在,使用布尔 OR 运算符组合术语后的结果是什么?它将定义一个文档集,该文档集大于或等于任何单个术语的文档集。例如,带有术语 **“社会”** 或 **“经济”** 的查询将生成用术语 **“社会”** 或 **“经济”** 索引的文档集。换句话说,这两个集合的并集的文档集。
布尔模型的优点
布尔模型的优点如下:
最简单的模型,基于集合。
易于理解和实现。
它只检索完全匹配。
它让用户对系统有一种控制感。
布尔模型的缺点
布尔模型的缺点如下:
该模型的相似度函数是布尔函数。因此,不会有任何部分匹配。这可能会让用户感到烦恼。
在此模型中,布尔运算符的使用比关键词的影响更大。
查询语言具有表现力,但也过于复杂。
检索到的文档没有排名。
向量空间模型
由于布尔模型的上述缺点,Gerard Salton 和他的同事提出了一种基于 Luhn 相似性准则的模型。Luhn 制定的相似性准则指出,“两个表示在给定元素及其分布方面越一致,则它们表示相似信息的概率就越高。”
请考虑以下要点,以更深入地了解向量空间模型:
索引表示(文档)和查询被视为嵌入在高维欧几里得空间中的向量。
文档向量与查询向量的相似度度量通常是它们之间角度的余弦。
余弦相似度度量公式
余弦是归一化的点积,可以使用以下公式计算:
$$Score \lgroup \vec{d} \vec{q} \rgroup= \frac{\sum_{k=1}^m d_{k}\:.q_{k}}{\sqrt{\sum_{k=1}^m\lgroup d_{k}\rgroup^2}\:.\sqrt{\sum_{k=1}^m}m\lgroup q_{k}\rgroup^2 }$$
$$Score \lgroup \vec{d} \vec{q}\rgroup =1\:when\:d =q $$
$$Score \lgroup \vec{d} \vec{q}\rgroup =0\:when\:d\:and\:q\:share\:no\:items$$
带查询和文档的向量空间表示
查询和文档由二维向量空间表示。术语为 **“汽车”** 和 **“保险”**。向量空间中有一个查询和三个文档。
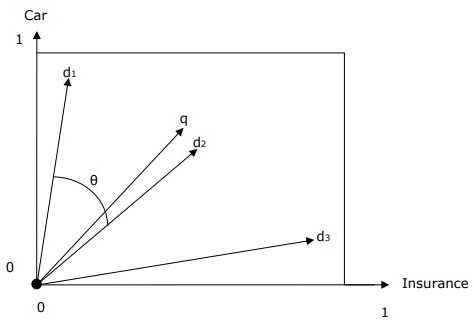
针对术语“汽车”和“保险”的排名最高的文档将是文档 **d2**,因为 **q** 和 **d2** 之间的角度最小。其背后的原因是,“汽车”和“保险”这两个概念在 d2 中都很突出,因此权重很高。另一方面,**d1** 和 **d3** 也提到了这两个术语,但在每种情况下,其中一个都不是文档中的核心重要术语。
术语权重
词项权重指的是向量空间中词项的权重。词项权重越高,该词项对余弦相似度的影响就越大。模型中应该为更重要的词项分配更大的权重。现在的问题是,我们如何对词项权重进行建模。
一种方法是将文档中词项出现的次数作为其词项权重。但是,你认为这是一种有效的方法吗?
另一种更有效的方法是使用**词频 (tfij)、文档频率 (dfi)** 和**集合频率 (cfi)**。
词频 (tfij)
它可以定义为**wi** 在**dj** 中出现的次数。词频捕捉的信息是某个词在给定文档中的显著程度,换句话说,词频越高,该词就越能很好地描述文档的内容。
文档频率 (dfi)
它可以定义为集合中包含**wi** 的文档总数。它是一个信息量指标。与语义不集中的词不同,语义集中的词会在文档中出现多次。
集合频率 (cfi)
它可以定义为**wi** 在整个集合中出现的总次数。
数学上,$df_{i}\leq cf_{i}\:and\:\sum_{j}tf_{ij} = cf_{i}$
文档频率权重的形式
现在让我们学习文档频率权重的不同形式。这些形式描述如下:
词频因子
这也被称为词频因子,这意味着如果某个词项**t** 在文档中经常出现,那么包含**t** 的查询应该检索该文档。我们可以将词项的**词频 (tfij)** 和**文档频率 (dfi)** 组合成一个权重,如下所示:
$$weight \left ( i,j \right ) =\begin{cases}(1+log(tf_{ij}))log\frac{N}{df_{i}}\:if\:tf_{i,j}\:\geq1\\0 \:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\: if\:tf_{i,j}\:=0\end{cases}$$
这里 N 是文档总数。
逆文档频率 (idf)
这是另一种文档频率权重形式,通常称为 idf 权重或逆文档频率权重。idf 权重的一个重要点是,词项在整个集合中的稀缺性是其重要性的衡量标准,而重要性与出现频率成反比。
数学上,
$$idf_{t} = log\left(1+\frac{N}{n_{t}}\right)$$
$$idf_{t} = log\left(\frac{N-n_{t}}{n_{t}}\right)$$
这里,
N = 集合中的文档数
nt = 包含词项 t 的文档数
用户查询改进
任何信息检索系统的首要目标必须是准确性——根据用户的需求生成相关的文档。但是,这里出现的问题是如何通过改进用户的查询形成风格来提高输出。当然,任何 IR 系统的输出都取决于用户的查询,而格式良好的查询将产生更准确的结果。用户可以通过相关反馈来改进其查询,这是任何 IR 模型的重要方面。
相关反馈
相关反馈采用给定查询最初返回的输出。此初始输出可用于收集用户信息,并了解该输出是否相关以执行新查询。反馈可以分类如下:
显式反馈
它可以定义为从相关性评估者那里获得的反馈。这些评估者还会指示从查询中检索到的文档的相关性。为了提高查询检索性能,需要将相关反馈信息与原始查询插值。
系统评估人员或其他用户可以通过以下相关性系统明确地指示相关性:
**二元相关性系统** - 此相关反馈系统指示文档对于给定查询要么相关 (1) 要么不相关 (0)。
**分级相关性系统** - 分级相关反馈系统根据使用数字、字母或描述进行分级来指示文档对于给定查询的相关性。描述可以是“不相关”、“有点相关”、“非常相关”或“相关”。
隐式反馈
它是从用户行为中推断出的反馈。行为包括用户查看文档花费的时间长短、选择查看哪些文档、页面浏览和滚动操作等。隐式反馈的最佳示例之一是**停留时间**,它衡量用户花费在查看搜索结果中链接到的页面上的时间。
伪反馈
它也称为盲反馈。它提供了一种自动本地分析的方法。伪相关反馈使相关反馈的手动部分自动化,以便用户无需扩展交互即可获得改进的检索性能。此反馈系统的主要优点是它不需要像显式相关反馈系统那样的评估人员。
考虑以下步骤来实现此反馈:
**步骤 1** - 首先,初始查询返回的结果必须作为相关结果。相关结果的范围必须在排名前 10-50 的结果中。
**步骤 2** - 现在,例如使用词频 (tf) - 逆文档频率 (idf) 权重从文档中选择前 20-30 个词项。
**步骤 3** - 将这些词项添加到查询中并匹配返回的文档。然后返回最相关的文档。