自然语言处理 - 快速指南
自然语言处理 - 简介
语言是一种借助于说话、阅读和写作进行交流的方法。例如,我们思考、做决定、制定计划等等,都是用自然语言,准确地说,是用词语进行的。然而,在这个人工智能时代摆在我们面前的一个重大问题是:我们能否以类似的方式与计算机进行交流?换句话说,人类能否用他们的自然语言与计算机交流?为计算机开发 NLP 应用是一项挑战,因为计算机需要结构化数据,而人类语言是非结构化的,通常具有歧义性。
从这个意义上说,我们可以说自然语言处理 (NLP) 是计算机科学,特别是人工智能 (AI) 的一个子领域,它关注的是使计算机能够理解和处理人类语言。从技术上讲,NLP 的主要任务是为计算机编写程序,用于分析和处理海量的自然语言数据。
NLP 的历史
我们将 NLP 的历史划分为四个阶段。这些阶段具有不同的关注点和风格。
第一阶段(机器翻译阶段) - 20 世纪 40 年代后期至 60 年代后期
此阶段的工作主要集中在机器翻译 (MT) 上。这个阶段是一个充满热情和乐观主义的时期。
让我们来看看第一阶段包含的内容:
在 Booth & Richens 于 1949 年对机器翻译进行调查和 Weaver 的备忘录之后,NLP 的研究始于 20 世纪 50 年代初。
1954 年,乔治城-IBM 实验展示了从俄语到英语的有限自动翻译实验。
同年,《机器翻译》(MT) 期刊开始出版。
第一次国际机器翻译 (MT) 会议于 1952 年举行,第二次于 1956 年举行。
1961 年,特丁顿国际机器翻译语言和应用语言分析会议上发表的作品是这一阶段的最高点。
第二阶段(人工智能影响阶段)– 20 世纪 60 年代后期至 70 年代后期
在这个阶段,所做的工作主要与世界知识及其在构建和操纵意义表示中的作用相关。因此,这个阶段也称为人工智能风味阶段。
此阶段包括以下内容:
1961 年初,开始研究解决和构建数据库或知识库的问题。这项工作受到了人工智能的影响。
同年,还开发了一个棒球问答系统。该系统的输入是有限的,所涉及的语言处理很简单。
Minsky (1968) 描述了一个更先进的系统。与棒球问答系统相比,该系统得到了认可,并提供了在解释和响应语言输入时对知识库进行推理的需要。
第三阶段(语法逻辑阶段)– 20 世纪 70 年代后期至 80 年代后期
这个阶段可以被描述为语法逻辑阶段。由于上一阶段实际系统构建的失败,研究人员转向使用逻辑进行人工智能中的知识表示和推理。
第三阶段包括以下内容:
在本世纪末,语法逻辑方法帮助我们获得了强大的通用句法处理器,例如 SRI 的核心语言引擎和语篇表示理论,它们提供了一种解决更长篇语篇的方法。
在这个阶段,我们获得了一些实用的资源和工具,例如解析器,例如 Alvey 自然语言工具,以及更多可操作的和商业系统,例如用于数据库查询。
20 世纪 80 年代关于词典的工作也指向了语法逻辑方法的方向。
第四阶段(词汇和语料库阶段)– 20 世纪 90 年代
我们可以将其描述为词汇和语料库阶段。该阶段采用了在 20 世纪 80 年代后期出现并日益产生影响的词汇化语法方法。随着用于语言处理的机器学习算法的引入,本十年自然语言处理发生了革命。
人类语言的研究
语言是人类生活中至关重要的组成部分,也是我们行为中最根本的方面。我们可以主要以两种形式体验它——书面形式和口语形式。在书面形式中,它是将我们的知识一代一代传承下去的一种方式。在口语形式中,它是人类在日常行为中相互协调的主要媒介。语言在各个学术学科中都有研究。每个学科都有自己的一套问题和解决这些问题的一套解决方案。
请参考下表以了解这一点:
| 学科 | 问题 | 工具 |
|---|---|---|
语言学家 |
如何用词语构成短语和句子? 什么限制了句子的可能含义? |
关于形式良好性和含义的直觉。 结构的数学模型。例如,模型论语义学、形式语言理论。 |
心理语言学家 |
人类如何识别句子的结构? 如何识别词语的含义? 理解何时发生? |
主要用于测量人类绩效的实验技术。 对观测结果进行统计分析。 |
哲学家 |
词语和句子如何获得含义? 词语如何识别物体? 什么是含义? |
使用直觉进行自然语言论证。 逻辑和模型论等数学模型。 |
计算语言学家 |
我们如何识别句子的结构? 如何对知识和推理进行建模? 我们如何使用语言来完成特定任务? |
算法 数据结构 表示和推理的形式模型。 人工智能技术,如搜索和表示方法。 |
语言中的歧义和不确定性
通常在自然语言处理中使用的歧义可以指能够以多种方式理解的能力。简单来说,我们可以说歧义是能够以多种方式理解的能力。自然语言非常含糊不清。NLP 具有以下几种类型的歧义:
词汇歧义
单个词的歧义称为词汇歧义。例如,将单词“silver”视为名词、形容词或动词。
句法歧义
当句子以不同的方式解析时,就会出现这种歧义。例如,句子“The man saw the girl with the telescope”。不清楚是男人看到拿着望远镜的女孩,还是他通过望远镜看到她。
语义歧义
当词语本身的含义可能被误解时,就会出现这种歧义。换句话说,当句子包含歧义词或短语时,就会发生语义歧义。例如,句子“The car hit the pole while it was moving”存在语义歧义,因为解释可以是“正在移动的汽车撞到了杆子”和“汽车撞到了正在移动的杆子”。
指代歧义
由于在语篇中使用指代实体而导致这种歧义。例如,马跑上了山。山很陡峭。它很快累了。在这里,“它”在两种情况下指代不明确导致歧义。
语用歧义
这种歧义是指短语的上下文赋予其多种解释的情况。简单来说,我们可以说语用歧义是在陈述不明确的情况下产生的。例如,句子“我也喜欢你”可以有多种解释,例如我喜欢你(就像你喜欢我一样),我喜欢你(就像其他人一样)。
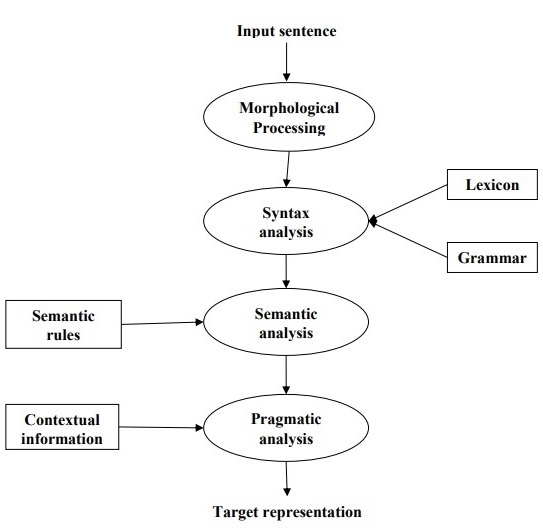
NLP 阶段
下图显示了自然语言处理中的阶段或逻辑步骤:
形态学处理
这是 NLP 的第一阶段。此阶段的目的是将语言输入块分解为对应于段落、句子和单词的标记集。例如,像“uneasy”这样的词可以分解成两个子词标记,如“un-easy”。
句法分析
这是 NLP 的第二阶段。此阶段的目的是双重的:检查句子是否格式良好,并将其分解成一个显示不同单词之间句法关系的结构。例如,像“The school goes to the boy”这样的句子会被句法分析器或解析器拒绝。
语义分析
这是 NLP 的第三阶段。此阶段的目的是从文本中提取确切的含义,或者你可以说是词典含义。检查文本是否有意义。例如,语义分析器会拒绝像“Hot ice-cream”这样的句子。
语用分析
这是 NLP 的第四阶段。语用分析只是将存在于给定上下文中的实际对象/事件与在上一阶段(语义分析)中获得的对象引用相匹配。例如,句子“Put the banana in the basket on the shelf”可以有两种语义解释,语用分析器将在这两种可能性之间进行选择。
NLP - 语言资源
在本节中,我们将学习自然语言处理中的语言资源。
语料库
语料库是一组大型且结构化的机器可读文本,这些文本是在自然的交流环境中产生的。它的复数是 corpora。它们可以通过不同的方式获得,例如最初是电子的文本、口语的记录和光学字符识别等。
语料库设计的要素
语言是无限的,但语料库的大小必须是有限的。为了使语料库的大小有限,我们需要对文本类型进行抽样并按比例包含广泛的文本类型,以确保良好的语料库设计。
现在让我们学习一些语料库设计的重要要素:
语料库的代表性
代表性是语料库设计的决定性特征。两位伟大的研究者——李奇和比伯的定义将帮助我们理解语料库的代表性:
根据李奇 (1991) 的说法,“如果基于语料库内容的发现可以推广到所要代表的语言变体,则认为该语料库代表了该语言变体”。
根据比伯 (1993) 的说法,“代表性是指样本包含总体中全部变异范围的程度”。
这样,我们可以得出结论:语料库的代表性取决于以下两个因素:
均衡性——语料库中包含的体裁范围
抽样——为每种体裁选择的文本片段的方式。
语料库均衡性
语料库设计的另一个非常重要的因素是语料库的均衡性——语料库中包含的体裁范围。我们已经学习过,一般语料库的代表性取决于语料库的均衡程度。均衡的语料库涵盖广泛的文本类别,这些类别应该能够代表该语言。我们没有任何可靠的科学衡量标准来衡量均衡性,但最好的方法是依靠估计和直觉。换句话说,我们可以说,可接受的均衡性仅由其预期用途决定。
抽样
语料库设计的另一个重要因素是抽样。语料库的代表性和均衡性与抽样密切相关。这就是为什么我们可以说抽样在语料库构建中是不可避免的。
根据比伯 (1993) 的说法,“构建语料库时首先要考虑的一些问题与整体设计有关:例如,包含的文本类型、文本数量、特定文本的选择、文本中文本样本的选择以及文本样本的长度。每一个都涉及一个抽样决策,无论是有意识的还是无意识的。”
在获取代表性样本时,我们需要考虑以下几点:
抽样单位——指需要抽样的单位。例如,对于书面文本,抽样单位可以是报纸、期刊或书籍。
抽样框——所有抽样单位的列表称为抽样框。
总体——可以指所有抽样单位的集合。它根据语言的产生、语言的接收或语言作为一种产物来定义。
语料库规模
语料库设计的另一个重要因素是其规模。语料库应该有多大?这个问题没有具体的答案。语料库的规模取决于其预期用途以及以下一些实际考虑因素:
用户预期的查询类型。
用户研究数据的方法。
数据来源的可获得性。
随着技术的进步,语料库的规模也在不断扩大。下表将帮助您了解语料库规模是如何变化的:
| 年份 | 语料库名称 | 规模(以词计) |
|---|---|---|
| 20世纪60年代-70年代 | Brown 和 LOB 语料库 | 100万词 |
| 20世纪80年代 | 伯明翰语料库 | 2000万词 |
| 20世纪90年代 | 英国国家语料库 | 1亿词 |
| 21世纪初 | 英语银行语料库 | 6.5亿词 |
在接下来的章节中,我们将看几个语料库的例子。
TreeBank 语料库
它可以定义为经过语言学解析的文本语料库,它注释句子的句法或语义结构。Geoffrey Leech创造了“treebank”这个术语,它表示表示语法分析的最常见方法是通过树状结构。通常,Treebank是在已经标注了词性标签的语料库的基础上创建的。
TreeBank 语料库的类型
语义 Treebank 和句法 Treebank 是语言学中最常见的两种 Treebank 类型。现在让我们进一步了解这些类型:
语义 Treebanks
这些 Treebanks 使用句子语义结构的形式化表示。它们在语义表示的深度上有所不同。机器人指令 Treebank、Geoquery、格罗宁根语义银行、RoboCup 语料库是一些语义 Treebanks 的例子。
句法 Treebanks
与语义 Treebanks 相反,句法 Treebank 系统的输入是从解析的 Treebank 数据转换而来的形式语言表达式。此类系统的输出是基于谓词逻辑的意义表示。迄今为止,已经创建了各种不同语言的句法 Treebanks。例如,宾夕法尼亚阿拉伯语 Treebank、哥伦比亚阿拉伯语 Treebank 是用阿拉伯语创建的句法 Treebanks。Sininca 句法 Treebank是用中文创建的。Lucy、Susane 和BLLIP WSJ 句法语料库是用英语创建的。
TreeBank 语料库的应用
以下是 Treebanks 的一些应用:
在计算语言学中
如果我们谈论计算语言学,那么 Treebanks 最好的用途是构建最先进的自然语言处理系统,例如词性标注器、解析器、语义分析器和机器翻译系统。
在语料库语言学中
在语料库语言学中,Treebanks 最好的用途是研究句法现象。
在理论语言学和心理语言学中
Treebanks 在理论语言学和心理语言学中的最佳用途是交互证据。
PropBank 语料库
PropBank,更确切地说叫“命题库”,是一个用动词命题及其论元进行注释的语料库。该语料库是面向动词的资源;这里的注释与句法层面更密切相关。科罗拉多大学博尔德分校语言学系的 Martha Palmer 等人开发了它。我们可以使用 PropBank 这个术语作为普通名词,指任何用命题及其论元进行注释的语料库。
在自然语言处理 (NLP) 中,PropBank 项目发挥了非常重要的作用。它有助于语义角色标注。
VerbNet (VN)
VerbNet (VN) 是英语中最大的、与领域无关的层次化词汇资源,它包含其内容的语义和句法信息。VN 是一个覆盖范围广泛的动词词典,它与其他词汇资源(如 WordNet、Xtag 和 FrameNet)具有映射关系。它被组织成动词类别,通过细化和添加子类来扩展 Levin 类别,以实现类成员之间的句法和语义一致性。
每个 VerbNet (VN) 类包含:
一组句法描述或句法框架
用于描述诸如及物、不及物、介词短语、结果状语以及大量倾注交替等结构的论元结构的可能表面实现。
一组语义描述,例如 animate、human、organization
用于约束论元允许的主题角色类型,并且可以施加进一步的限制。这将有助于指示可能与主题角色相关的成分的句法性质。
WordNet
WordNet 由普林斯顿大学创建,是一个英语词汇数据库。它是 NLTK 语料库的一部分。在 WordNet 中,名词、动词、形容词和副词被分组为称为同义词集 (Synsets) 的认知同义词集。所有同义词集都借助概念语义和词汇关系连接起来。其结构使其对自然语言处理 (NLP) 非常有用。
在信息系统中,WordNet 用于各种目的,例如词义消歧、信息检索、自动文本分类和机器翻译。WordNet 最重要的用途之一是找出单词之间的相似性。对于这项任务,各种算法已在各种软件包中实现,例如 Perl 中的 Similarity、Python 中的 NLTK 和 Java 中的 ADW。
NLP - 词法分析
在本章中,我们将了解自然语言处理中的词法分析。
正则表达式
正则表达式 (RE) 是一种用于指定文本搜索字符串的语言。RE 帮助我们使用模式中包含的特殊语法来匹配或查找其他字符串或字符串集。正则表达式用于在 UNIX 和 MS WORD 中以相同的方式搜索文本。我们有各种搜索引擎使用许多正则表达式功能。
正则表达式的性质
以下是正则表达式的一些重要性质:
美国数学家 Stephen Cole Kleene 正式化了正则表达式语言。
RE 是用特殊语言编写的公式,可用于指定简单的字符串类,即符号序列。换句话说,我们可以说 RE 是一种代数符号,用于表征一组字符串。
正则表达式需要两件事,一是我们要搜索的模式,二是我们要从中搜索的文本语料库。
从数学上讲,正则表达式可以定义如下:
ε 是一个正则表达式,表示该语言包含空字符串。
φ 是一个正则表达式,表示它是一个空语言。
如果X 和Y 是正则表达式,则
X,Y
X.Y(XY 的连接)
X+Y(X 和 Y 的并集)
X*,Y*(X 和 Y 的 Kleene 闭包)
也是正则表达式。
如果一个字符串是从上述规则导出的,那么它也是一个正则表达式。
正则表达式的例子
下表显示了一些正则表达式的例子:
| 正则表达式 | 正则集 |
|---|---|
| (0 + 10*) | {0, 1, 10, 100, 1000, 10000, …} |
| (0*10*) | {1, 01, 10, 010, 0010, …} |
| (0 + ε)(1 + ε) | {ε, 0, 1, 01} |
| (a+b)* | 它将是一组任意长度的 a 和 b 字符串,也包括空字符串,即 {ε, a, b, aa, ab, bb, ba, aaa……}。 |
| (a+b)*abb | 它将是一组以字符串 abb 结尾的 a 和 b 字符串,即 {abb, aabb, babb, aaabb, ababb, …………}。 |
| (11)* | 它将是一组包含偶数个 1 的字符串,也包括空字符串,即 {ε, 11, 1111, 111111, ……}。 |
| (aa)*(bb)*b | 它将是一组包含偶数个 a 后跟奇数个 b 的字符串,即 {b, aab, aabbb, aabbbbb, aaaab, aaaabbb, …………}。 |
| (aa + ab + ba + bb)* | 它将是偶数长度的 a 和 b 字符串,可以通过连接 aa、ab、ba 和 bb 的任何组合(包括空字符串)来获得,即 {aa, ab, ba, bb, aaab, aaba, …………}。 |
正则集及其性质
它可以定义为表示正则表达式的值的集合,并具有特定的性质。
正则集的性质
如果我们对两个正则集进行并集运算,则结果集也将是正则的。
如果我们对两个正则集进行交集运算,则结果集也将是正则的。
如果我们对正则集进行补集运算,则结果集也将是正则的。
如果我们对两个正则集进行差集运算,则结果集也将是正则的。
如果对正则集合进行逆序操作,则结果集合也仍然是正则的。
如果对正则集合进行闭包运算,则结果集合也仍然是正则的。
如果对两个正则集合进行连接运算,则结果集合也仍然是正则的。
有限状态自动机
“自动机”一词源于希腊语“αὐτόματα”,意为“自动的”。自动机的复数是自动机,可以定义为一种抽象的自动运行的计算设备,它会自动按照预定的操作序列运行。
具有有限状态的自动机称为有限自动机 (FA) 或有限状态自动机 (FSA)。
数学上,自动机可以用一个 5 元组 (Q, Σ, δ, q0, F) 来表示,其中:
Q 是一个有限的状态集。
Σ 是一个有限的符号集,称为自动机的字母表。
δ 是状态转移函数。
q0 是初始状态,任何输入都从该状态开始处理 (q0 ∈ Q)。
F 是一个或多个最终状态的集合 (F ⊆ Q)。
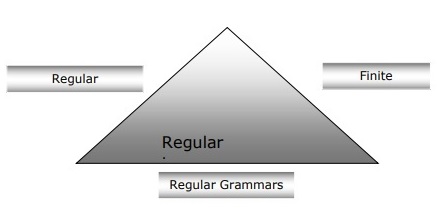
有限自动机、正则文法和正则表达式之间的关系
以下几点将使我们更清晰地了解有限自动机、正则文法和正则表达式之间的关系:
众所周知,有限状态自动机是计算工作的理论基础,而正则表达式是描述它们的一种方式。
可以说,任何正则表达式都可以实现为 FSA,任何 FSA 都可以用正则表达式来描述。
另一方面,正则表达式是表征一种称为正则语言的语言的方式。因此,可以说正则语言可以用 FSA 和正则表达式来描述。
正则文法是一种可以是右正则或左正则的形式文法,它是表征正则语言的另一种方式。
下图显示了有限自动机、正则表达式和正则文法是描述正则语言的等效方式。
有限状态自动机 (FSA) 的类型
有限状态自动机分为两种类型。让我们看看这些类型是什么。
确定性有限自动机 (DFA)
可以定义为一种有限自动机,对于每个输入符号,我们都可以确定机器将转移到的状态。它具有有限数量的状态,这就是为什么该机器被称为确定性有限自动机 (DFA) 的原因。
数学上,DFA可以用一个 5 元组 (Q, Σ, δ, q0, F) 来表示,其中:
Q 是一个有限的状态集。
Σ 是一个有限的符号集,称为自动机的字母表。
δ 是状态转移函数,其中 δ: Q × Σ → Q。
q0 是初始状态,任何输入都从该状态开始处理 (q0 ∈ Q)。
F 是一个或多个最终状态的集合 (F ⊆ Q)。
而在图形上,DFA可以用称为状态图的有向图来表示,其中:
状态由**顶点**表示。
转移由带标签的**弧**表示。
初始状态由**空入弧**表示。
最终状态由**双圈**表示。
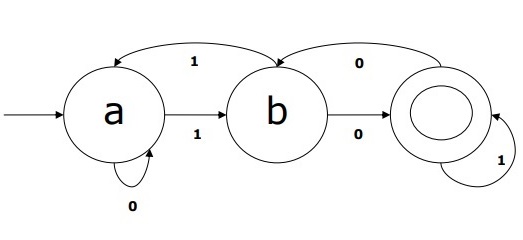
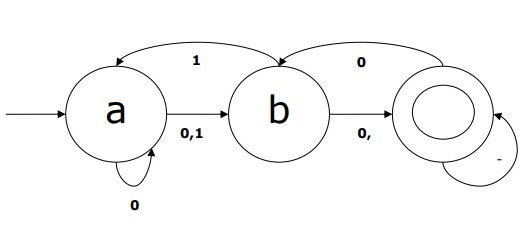
DFA示例
假设一个 DFA 为
Q = {a, b, c},
Σ = {0, 1},
q0 = {a},
F = {c},
状态转移函数 δ 如表所示:
| 当前状态 | 输入为 0 时的下一状态 | 输入为 1 时的下一状态 |
|---|---|---|
| A | a | B |
| B | b | A |
| C | c | C |
此 DFA 的图形表示如下:
非确定性有限自动机 (NDFA)
可以定义为一种有限自动机,对于每个输入符号,我们无法确定机器将转移到的状态,即机器可以转移到任何状态组合。它具有有限数量的状态,这就是为什么该机器被称为非确定性有限自动机 (NDFA) 的原因。
数学上,NDFA可以用一个 5 元组 (Q, Σ, δ, q0, F) 来表示,其中:
Q 是一个有限的状态集。
Σ 是一个有限的符号集,称为自动机的字母表。
δ:是状态转移函数,其中 δ: Q × Σ → 2Q。
q0:是初始状态,任何输入都从该状态开始处理 (q0 ∈ Q)。
F:是一个或多个最终状态的集合 (F ⊆ Q)。
而在图形上(与 DFA 相同),NDFA可以用称为状态图的有向图来表示,其中:
状态由**顶点**表示。
转移由带标签的**弧**表示。
初始状态由**空入弧**表示。
最终状态由双**圈**表示。
NDFA示例
假设一个 NDFA 为
Q = {a, b, c},
Σ = {0, 1},
q0 = {a},
F = {c},
状态转移函数 δ 如表所示:
| 当前状态 | 输入为 0 时的下一状态 | 输入为 1 时的下一状态 |
|---|---|---|
| A | a, b | B |
| B | C | a, c |
| C | b, c | C |
此 NDFA 的图形表示如下:
形态分析
形态分析是指对词素进行分析。我们可以将形态分析定义为识别单词分解成较小的有意义单元(称为词素)并为其生成某种语言结构的问题。例如,我们可以将单词 *foxes* 分解成两个部分,*fox* 和 *-es*。我们可以看到,单词 *foxes* 由两个词素组成,一个是 *fox*,另一个是 *-es*。
换句话说,形态学是研究:
词的构成。
词的起源。
词的语法形式。
在词的构成中使用前缀和后缀。
语言的词性是如何构成的。
词素的类型
词素是最小的意义单元,可以分为两种类型:
词干
词序
词干
它是单词的核心意义单元。我们也可以说它是单词的词根。例如,在单词 foxes 中,词干是 fox。
**词缀**——顾名思义,它们为单词添加了一些额外的意义和语法功能。例如,在单词 foxes 中,词缀是 -es。
此外,词缀还可以分为以下四种类型:
**前缀**——顾名思义,前缀位于词干之前。例如,在单词 unbuckle 中,un 是前缀。
**后缀**——顾名思义,后缀位于词干之后。例如,在单词 cats 中,-s 是后缀。
**中缀**——顾名思义,中缀插入词干内部。例如,单词 cupful 可以通过使用 -s 作为中缀将其复数化,变成 cupsful。
**环缀**——它们位于词干之前和之后。英语中环缀的例子很少。一个很常见的例子是“A-ing”,我们可以使用 -A 位于词干之前,-ing 位于词干之后。
词序
词序将由形态分析决定。现在让我们看看构建形态分析器所需的内容:
词典
构建形态分析器的首要要求是词典,其中包括词干和词缀的列表以及关于它们的详细信息。例如,词干是名词词干还是动词词干等信息。
形态句法
它基本上是词素排序的模型。换句话说,该模型解释了哪些词素类可以在单词中跟随其他词素类。例如,形态句法事实是,英语复数词素总是跟在名词之后,而不是在名词之前。
拼写规则
这些拼写规则用于模拟单词中发生的更改。例如,将 y 转换为 ie 的规则,例如 city+s = cities 而不是 citys。
自然语言处理 - 语法分析
语法分析或解析或句法分析是自然语言处理的第三阶段。此阶段的目的是从文本中提取确切的含义,或者可以说从词典中提取含义。语法分析检查文本的含义是否符合形式语法的规则。例如,诸如“热的冰淇淋”之类的句子将被语义分析器拒绝。
从这个意义上说,语法分析或解析可以定义为分析自然语言中符合形式语法规则的符号串的过程。“解析”一词源于拉丁语“pars”,意思是“部分”。
解析器的概念
它用于实现解析任务。可以将其定义为设计用于接收输入数据(文本)并在根据形式语法检查语法正确性后给出输入的结构化表示的软件组件。它还构建一个数据结构,通常以解析树或抽象语法树或其他层次结构的形式存在。
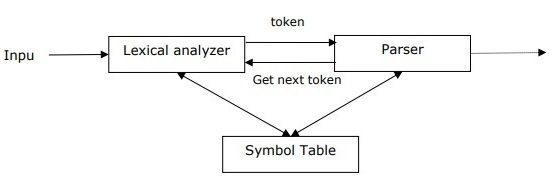
解析器的主要作用包括:
报告任何语法错误。
从常见错误中恢复,以便可以继续处理程序的其余部分。
创建解析树。
创建符号表。
生成中间表示 (IR)。
解析的类型
推导将解析分为以下两种类型:
自顶向下解析
自底向上解析
自顶向下解析
在这种解析中,解析器从起始符号开始构建解析树,然后尝试将起始符号转换为输入。最常见的自顶向下解析形式使用递归过程来处理输入。递归下降解析的主要缺点是回溯。
自底向上解析
在这种解析中,解析器从输入符号开始,尝试构建解析树直至到达起始符号。
推导的概念
为了获得输入字符串,我们需要一系列产生式规则。推导是一组产生式规则。在解析过程中,我们需要确定要替换的非终结符,以及要使用哪个产生式规则来替换非终结符。
推导的类型
在本节中,我们将学习两种类型的推导,它们可以用来确定哪个非终结符要使用产生式规则替换:
最左推导
在最左推导中,输入的句型从左到右进行扫描和替换。在这种情况下,句型称为左句型。
最右推导
在最右推导中,输入的句型从右到左进行扫描和替换。在这种情况下,句型称为右句型。
语法树的概念
语法树可以定义为推导的图形表示。推导的起始符号作为语法树的根节点。在每棵语法树中,叶子节点是终结符,内部节点是非终结符。语法树的一个特性是,中序遍历将产生原始输入字符串。
语法的概念
语法对于描述结构良好的程序的句法结构至关重要。从文学意义上讲,它们表示自然语言对话的句法规则。自从英语、印地语等自然语言出现以来,语言学家就一直在试图定义语法。
形式语言理论也适用于计算机科学领域,主要体现在编程语言和数据结构中。例如,在C语言中,精确的语法规则规定了如何从列表和语句中构成函数。
1956年,**诺姆·乔姆斯基**给出了语法的数学模型,该模型有效地用于编写计算机语言。
数学上,语法G可以形式化地写成一个4元组(N, T, S, P),其中:
N 或 VN = 非终结符集,即变量。
T 或 ∑ = 终结符集。
S = 起始符号,其中S ∈ N
P 表示终结符和非终结符的产生式规则。它具有α → β的形式,其中α和β是VN ∪ ∑上的字符串,并且α至少有一个符号属于VN
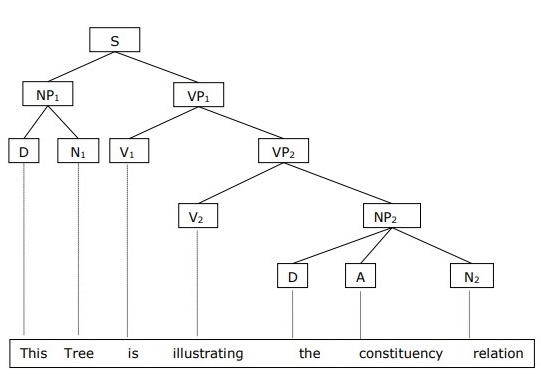
短语结构语法或成分语法
短语结构语法由诺姆·乔姆斯基提出,基于成分关系。这就是为什么它也称为成分语法。它与依存语法相反。
示例
在给出成分语法的示例之前,我们需要了解关于成分语法和成分关系的基本要点。
所有相关的框架都根据成分关系来看待句子结构。
成分关系源于拉丁语和希腊语语法的主谓划分。
基本从句结构是用名词短语NP和动词短语VP来理解的。
我们可以将句子“这棵树正在说明成分关系”写成如下:
依存语法
它与成分语法相反,基于依存关系。它由吕西安·特斯尼尔提出。依存语法(DG)与成分语法相反,因为它缺乏短语节点。
示例
在给出依存语法的示例之前,我们需要了解关于依存语法和依存关系的基本要点。
在依存语法中,语言单位,即单词,通过有向链接相互连接。
动词成为从句结构的中心。
其他句法单元都通过有向链接连接到动词。这些句法单元称为依存关系。
我们可以将句子“这棵树正在说明依存关系”写成如下:
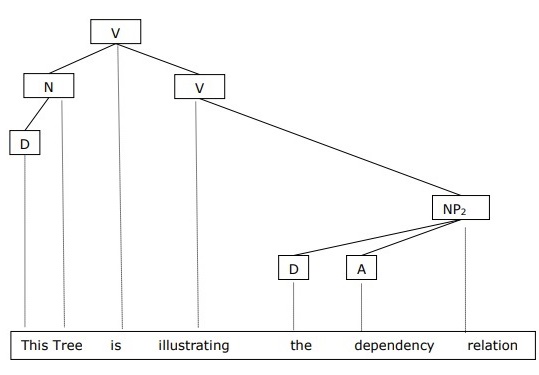
使用成分语法的语法树称为基于成分的语法树;使用依存语法的语法树称为基于依存的语法树。
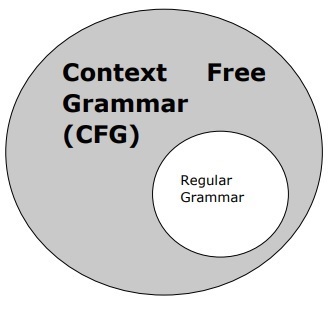
上下文无关文法
上下文无关文法,也称为CFG,是一种描述语言的表示法,也是正则文法的超集。它可以在下图中看到:
CFG的定义
CFG由一组有限的语法规则组成,这些规则具有以下四个组成部分:
非终结符集
它用V表示。非终结符是句法变量,表示字符串集,这些字符串集进一步有助于定义由语法生成的语言。
终结符集
它也称为标记,由Σ定义。字符串是由终结符的基本符号构成的。
产生式集
它用P表示。该集合定义了如何组合终结符和非终结符。每个产生式(P)都由非终结符、箭头和终结符(终结符的序列)组成。非终结符称为产生式的左部,终结符称为产生式的右部。
起始符号
产生式从起始符号开始。它用符号S表示。非终结符总是被指定为起始符号。
自然语言处理 - 语义分析
语义分析的目的是从文本中提取确切的含义,或者可以说字典含义。语义分析器的作用是检查文本的意义。
我们已经知道词法分析也处理单词的含义,那么语义分析与词法分析有何不同呢?词法分析基于较小的标记,而语义分析则关注较大的块。这就是为什么语义分析可以分为以下两部分:
研究单个词的含义
这是语义分析的第一部分,其中进行对单个词含义的研究。这部分称为词汇语义。
研究单个词的组合
在第二部分中,将组合单个单词以在句子中提供含义。
语义分析最重要的任务是获得句子的正确含义。例如,分析句子“ राम महान है。”在这个句子中,说话者谈论的是 राम神,还是一个名叫 राम的人。这就是为什么语义分析器获得句子正确含义的工作很重要。
语义分析的要素
以下是语义分析的一些重要要素:
下义词
它可以定义为泛指词及其泛指词实例之间的关系。这里的泛指词称为上位词,其实例称为下义词。例如,“颜色”这个词是上位词,“蓝色”、“黄色”等是下义词。
同音异义词
它可以定义为拼写相同或形式相同但含义不同且无关的词。例如,“Bat”(蝙蝠)是一个同音异义词,因为bat可以是击球的工具,也可以是夜行动物。
多义词
多义词是一个希腊词,意思是“许多符号”。它是一个具有不同但相关含义的词或短语。换句话说,我们可以说多义词具有相同的拼写,但含义不同且相关。例如,“bank”(银行)是一个多义词,具有以下含义:
金融机构。
此类机构所在的建筑物。
“依靠”的同义词。
多义词和同音异义词的区别
多义词和同音异义词都具有相同的句法或拼写。它们的主要区别在于,在多义词中,词的含义是相关的,但在同音异义词中,词的含义是不相关的。例如,如果我们谈论同一个词“Bank”,我们可以写出“金融机构”或“河岸”的含义。在这种情况下,它将是同音异义词的例子,因为这些含义彼此不相关。
同义词
它是两个词汇项之间的关系,它们的形式不同,但表达相同或相近的含义。例如,“作者/作家”、“命运/天命”。
反义词
它是两个词汇项之间的关系,它们的语义成分相对于一个轴具有对称性。反义词的范围如下:
属性的应用与否 - 例如“生/死”、“确定性/不确定性”
可扩展属性的应用 - 例如“富/穷”、“热/冷”
用法的应用 - 例如“父亲/儿子”、“月亮/太阳”。
意义表示
语义分析创建句子含义的表示。但在深入了解与意义表示相关的概念和方法之前,我们需要理解语义系统的构建块。
语义系统的构建块
在单词表示或单词含义表示中,以下构建块起着重要作用:
实体 - 它代表个人,例如特定的人、地点等。例如,哈里亚纳邦、印度、 राम都是实体。
概念 - 它代表个人的一般类别,例如人、城市等。
关系 - 它表示实体和概念之间的关系。例如, राम是一个人。
谓词 - 它表示动词结构。例如,语义角色和格语法是谓词的例子。
现在,我们可以理解,意义表示展示了如何将语义系统的构建块组合在一起。换句话说,它展示了如何将实体、概念、关系和谓词组合在一起以描述一种情况。它还可以对语义世界进行推理。
意义表示的方法
语义分析使用以下方法来表示含义:
一阶谓词逻辑(FOPL)
语义网络
框架
概念依赖(CD)
基于规则的架构
格语法
概念图
意义表示的必要性
这里出现了一个问题,为什么我们需要意义表示?以下是同样的原因:
将语言要素与非语言要素联系起来
第一个原因是,借助意义表示,可以将语言要素与非语言要素联系起来。
表示词汇层面的多样性
借助意义表示,可以在词汇层面表示明确的规范形式。
可用于推理
意义表示可用于推理,以验证世界上什么是真实的,以及从语义表示中推断知识。
词汇语义
语义分析的第一部分,研究单个词的含义,称为词汇语义。它还包括单词、子词、词缀(子单元)、复合词和短语。所有单词、子词等统称为词汇项。换句话说,我们可以说词汇语义是词汇项、句子含义和句子句法之间的关系。
以下是词汇语义中涉及的步骤:
在词汇语义中进行单词、子词、词缀等的词汇项分类。
在词汇语义中对单词、子词、词缀等词汇项进行分解。
还分析了各种词汇语义结构之间的差异和相似之处。
NLP - 词义消歧
我们理解,单词根据其在句子中的使用语境具有不同的含义。如果我们谈论人类语言,那么它们也是模棱两可的,因为许多单词可以根据其出现的语境以多种方式解释。
在自然语言处理(NLP)中,词义消歧可以定义为确定在特定语境中单词的使用激活了单词的哪个含义的能力。词法歧义、句法歧义或语义歧义是任何NLP系统面临的第一个问题之一。具有高精度水平的词性(POS)标记器可以解决单词的句法歧义。另一方面,解决语义歧义的问题称为WSD(词义消歧)。解决语义歧义比解决句法歧义更难。
例如,考虑单词“bass”(低音/鲈鱼)的两个不同含义:
我能听到低音。
他喜欢吃烤鲈鱼。
单词“bass”的出现清楚地表明了不同的含义。在第一句中,它指的是频率,在第二句中,它指的是鱼。因此,如果通过WSD消除歧义,则可以为上述句子分配正确的含义如下:
我能听到低音/频率的声音。
他喜欢吃烤鱼。
WSD的评估
WSD的评估需要以下两个输入:
词典
WSD评估的第一个输入是词典,它用于指定要消除歧义的词义。
测试语料库
WSD所需的另一个输入是高度标注的测试语料库,其中包含目标或正确的词义。测试语料库可以分为两种类型:
词汇样本 - 这种语料库用于需要消除少量单词歧义的系统。
全部单词 - 这种语料库用于需要消除一段连续文本中所有单词歧义的系统。
词义消歧 (WSD) 的方法和途径
WSD的方法和途径根据词义消歧中使用的知识来源进行分类。
现在让我们看看WSD的四种常用方法:
基于词典或知识的方法
顾名思义,这些方法主要依赖于词典、宝库和词汇知识库来进行消歧。它们不使用语料库证据进行消歧。Lesk方法是由Michael Lesk在1986年提出的开创性基于词典的方法。Lesk算法所基于的Lesk定义是“衡量上下文所有单词的词义定义之间的重叠”。然而,在2000年,Kilgarriff和Rosensweig将简化的Lesk定义定义为“衡量单词词义定义与当前上下文之间的重叠”,这进一步意味着一次识别一个单词的正确词义。这里的当前上下文是指周围句子或段落中的词集。
监督方法
对于消歧,机器学习方法利用语义标注语料库进行训练。这些方法假设上下文本身可以提供足够的证据来消除歧义。在这些方法中,词语知识和推理被认为是不必要的。上下文被表示为单词的一组“特征”。它还包括有关周围单词的信息。支持向量机和基于记忆的学习是WSD最成功的监督学习方法。这些方法依赖于大量的以人工方式标注词义的语料库,创建这种语料库的成本非常高。
半监督方法
由于缺乏训练语料库,大多数词义消歧算法使用半监督学习方法。这是因为半监督方法同时使用标记数据和未标记数据。这些方法只需要少量标注文本和大量普通未标注文本。半监督方法使用的一种技术是从种子数据中进行自举。
无监督方法
这些方法假设相似的词义出现在相似的上下文中。这就是为什么可以通过使用某种上下文相似性度量来对词语出现进行聚类,从而从文本中推导出词义。这项任务被称为词义归纳或辨别。无监督方法由于不依赖人工努力,因此具有克服知识获取瓶颈的巨大潜力。
词义消歧 (WSD) 的应用
词义消歧 (WSD) 应用于几乎所有语言技术应用中。
现在让我们看看WSD的范围:
机器翻译
机器翻译或MT是WSD最明显的应用。在MT中,WSD完成对具有不同词义的不同翻译的单词的词汇选择。MT中的词义以目标语言中的单词表示。大多数机器翻译系统不使用显式的WSD模块。
信息检索 (IR)
信息检索 (IR) 可以定义为一种软件程序,它处理从文档存储库(特别是文本信息)中组织、存储、检索和评估信息。该系统基本上帮助用户找到他们需要的信息,但它不会明确地返回问题的答案。WSD用于解决提供给IR系统的查询的歧义。与MT一样,当前的IR系统也不显式地使用WSD模块,它们依赖于用户会在查询中输入足够的上下文以仅检索相关文档的概念。
文本挖掘和信息提取 (IE)
在大多数应用中,WSD对于进行准确的文本分析是必要的。例如,WSD帮助智能收集系统标记正确的单词。例如,医疗智能系统可能需要标记“非法药物”而不是“医疗药物”。
词典编纂学
WSD和词典编纂学可以循环协同工作,因为现代词典编纂学是基于语料库的。通过词典编纂学,WSD提供了粗略的经验意义分组以及统计上显著的上下文意义指标。
词义消歧 (WSD) 中的困难
以下是词义消歧 (WSD) 面临的一些困难:
词典之间的差异
WSD的主要问题是确定单词的词义,因为不同的词义可能非常密切相关。即使是不同的词典和同义词词典也可能提供不同的单词词义划分。
不同应用的不同算法
WSD的另一个问题是,对于不同的应用可能需要完全不同的算法。例如,在机器翻译中,它采用目标词选择的形式;在信息检索中,不需要词义清单。
评判者间差异
WSD的另一个问题是,WSD系统通常通过将其在任务上的结果与人类的任务进行比较来进行测试。这就是所谓的评判者间差异问题。
词义离散性
WSD中的另一个困难是,单词不能轻易地划分为离散的子义。
自然语言话语处理
人工智能最困难的问题是让计算机处理自然语言,或者换句话说,自然语言处理是人工智能最困难的问题。如果我们谈论NLP中的主要问题,那么NLP中的一个主要问题是话语处理——建立关于语句如何组合在一起形成连贯话语的理论和模型。实际上,语言总是由并置的、结构化的和连贯的句子群组成,而不是像电影一样孤立且无关的句子。这些连贯的句子群被称为话语。
连贯性概念
连贯性和话语结构在许多方面是相互关联的。连贯性连同良好文本的属性一起用于评估自然语言生成系统的输出质量。这里出现的问题是,文本连贯意味着什么?假设我们从报纸的每一页收集一个句子,那它会是一个话语吗?当然不是。这是因为这些句子没有表现出连贯性。连贯的话语必须具备以下特性:
话语之间存在的连贯关系
如果话语在其话语之间存在有意义的联系,则该话语将是连贯的。此属性称为连贯关系。例如,必须存在某种解释来证明话语之间的联系。
实体之间的关系
使话语连贯的另一个属性是,实体之间必须存在某种关系。这种连贯性称为基于实体的连贯性。
话语结构
关于话语的一个重要问题是话语必须具有什么样的结构。这个问题的答案取决于我们对话语进行的分割。话语分割可以定义为确定大型话语的结构类型。话语分割非常难以实现,但对于信息检索、文本摘要和信息提取等应用非常重要。
话语分割算法
在本节中,我们将学习关于话语分割的算法。这些算法描述如下:
无监督话语分割
无监督话语分割通常表示为线性分割。我们可以借助示例来理解线性分割的任务。例如,有一项任务是将文本分割成多段单元;这些单元代表原文的段落。这些算法依赖于内聚力,内聚力可以定义为使用某些语言手段将文本单元联系在一起。另一方面,词汇内聚力是指由两个或多个单词在两个单元之间的关系所指示的内聚力,例如同义词的使用。
监督话语分割
早期方法没有任何手工标记的段落边界。另一方面,监督话语分割需要具有边界标记的训练数据。获取相同的数据非常容易。在监督话语分割中,话语标记或提示词起着重要作用。话语标记或提示词是指用于指示话语结构的单词或短语。这些话语标记是特定于领域的。
文本连贯性
词汇重复是查找话语中结构的一种方法,但它不能满足连贯话语的要求。为了实现连贯的话语,我们必须特别关注连贯关系。正如我们所知,连贯关系定义了话语中话语之间可能的联系。Hebb提出了以下几种关系:
我们使用两个术语S0和S1来表示两个相关句子的含义:
结果
它推断出术语S0所断言的状态可能导致S1所断言的状态。例如,两句话显示了结果关系: राम आग में फंस गया था। उसकी खाल जल गई। (Ram was caught in the fire. His skin burned.)
解释
它推断出S1所断言的状态可能导致S0所断言的状态。例如,两句话显示了关系: राम ने श्याम के दोस्त से लड़ाई की। वह नशे में था। (Ram fought with Shyam’s friend. He was drunk.)
平行
它从S0的断言中推断出p(a1,a2,…),从S1的断言中推断出p(b1,b2,…)。这里对于所有i,ai和bi都是相似的。例如,两句话是平行的: राम कार चाहता था। श्याम पैसे चाहता था。(Ram wanted a car. Shyam wanted money.)
详述
它从两个断言——S0和S1中推断出相同的命题P。例如,两句话显示了详述关系: राम चंडीगढ़ से था। श्याम केरल से था。(Ram was from Chandigarh. Shyam was from Kerala.)
场合
当可以从S0的断言中推断出状态变化时,其最终状态可以从S1中推断出来,反之亦然。例如,两句话显示了场合关系: राम ने किताब उठाई। उसने उसे श्याम को दे दिया।(Ram picked up the book. He gave it to Shyam.)
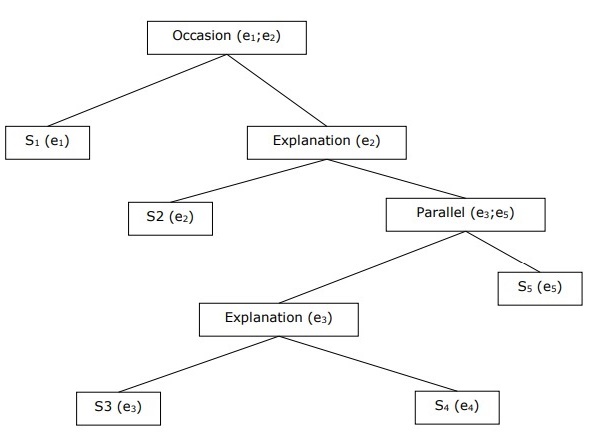
构建分层话语结构
整个话语的连贯性也可以通过连贯关系之间的分层结构来考虑。例如,以下段落可以表示为分层结构:
S1 - राम बैंक गया पैसे जमा करने के लिए। (Ram went to the bank to deposit money.)
S2 - फिर वह श्याम की कपड़े की दुकान के लिए ट्रेन में चढ़ गया। (He then took a train to Shyam’s cloth shop.)
S3 - वह कुछ कपड़े खरीदना चाहता था। (He wanted to buy some clothes.)
S4 - पार्टी के लिए उसके पास नए कपड़े नहीं थे। (He didn't have new clothes for the party.)
S5 - वह श्याम से उसके स्वास्थ्य के बारे में बात करना भी चाहता था। (He also wanted to talk to Shyam regarding his health.)
指代消解
从任何语篇中解释句子是另一项重要的任务,为了实现这一点,我们需要知道谈论的是谁或什么实体。这里,解释参考是关键要素。指称可以定义为用来表示实体或个体的语言表达。例如,在文章中,Ram,ABC银行的经理,在一家商店看到了他的朋友Shyam。他去见他,像Ram、His、He这样的语言表达就是指称。
同样地,指称消解可以定义为确定哪些语言表达指的是哪些实体的任务。
指称消解中使用的术语
我们在指称消解中使用以下术语:
指称表达式 - 用于进行指称的自然语言表达称为指称表达式。例如,上面使用的文章就是一个指称表达式。
指称项 - 指的是被指称的实体。例如,在最后一个例子中,Ram是一个指称项。
共指 - 当两个表达式用于指称同一个实体时,它们被称为共指。例如,Ram和he是共指的。
先行词 - 该术语有权使用另一个术语。例如,Ram是he这个指称的先行词。
回指 & 回指的 - 它可以定义为对先前已引入句子的实体的指称。而指称表达式被称为回指的。
语篇模型 - 包含对语篇中已提及的实体及其所参与关系的表示的模型。
指称表达式的类型
现在让我们看看不同类型的指称表达式。下面描述了五种类型的指称表达式:
不定名词短语
这种类型的指称代表对听者来说是新的,引入语篇语境中的实体。例如,在句子“Ram有一天四处走动给他带些食物”中,“some”是不定指称。
定名词短语
与上述相反,这种类型的指称代表对听者来说不是新的或可识别的,引入语篇语境中的实体。例如,在句子“我过去常读《印度时报》”中,“《印度时报》”是定指称。
代词
它是定指称的一种形式。例如,“Ram笑得像他能笑得一样大声”。单词he代表代词指称表达式。
指示词
这些指示词的行为与简单的定代词不同。例如,“this”和“that”是指示代词。
专有名词
这是最简单的指称表达式类型。它也可以是人、组织和地点的名称。例如,在上面的例子中,Ram是专有名词指称表达式。
指称消解任务
下面描述了两个指称消解任务。
共指消解
它是查找文本中指称同一实体的指称表达式的任务。简单来说,它是查找共指表达式的任务。一组共指表达式称为共指链。例如,He、Chief Manager和His——这些是第一个例子中给出的文章中的指称表达式。
共指消解的约束
在英语中,共指消解的主要问题是代词it。其背后的原因是代词it有多种用法。例如,它可以像he和she一样指称。代词it也指称那些不指称特定事物的事物。例如,“It’s raining.”,“It is really good.”
代词回指消解
与共指消解不同,代词回指消解可以定义为为单个代词查找先行词的任务。例如,代词是his,代词回指消解的任务是找到单词Ram,因为Ram是先行词。
词性标注 (PoS)
标注是一种分类,可以定义为自动为词元分配描述符的任务。这里的描述符称为标签,它可以表示词性、语义信息等等。
现在,如果我们谈论词性标注 (PoS),那么它可以定义为为给定单词分配词性之一的过程。它通常被称为POS标注。简单来说,我们可以说POS标注是为句子中的每个单词贴上其适当词性的任务。我们已经知道,词性包括名词、动词、副词、形容词、代词、连词及其子类别。
大多数POS标注属于基于规则的POS标注、随机POS标注和基于转换的标注。
基于规则的POS标注
最古老的标注技术之一是基于规则的POS标注。基于规则的标注器使用词典或词库来获取对每个单词进行标注的可能标签。如果一个单词有多个可能的标签,那么基于规则的标注器将使用手工编写的规则来识别正确的标签。通过分析单词的语言特征及其前面和后面的单词,也可以在基于规则的标注中执行消歧。例如,假设一个单词的前面单词是冠词,那么这个单词必须是名词。
顾名思义,基于规则的POS标注中所有此类信息都以规则的形式编码。这些规则可以是:
上下文模式规则
或者,作为编译成有限状态自动机的正则表达式,与词汇上模棱两可的句子表示相交。
我们也可以通过其两阶段架构来理解基于规则的POS标注:
第一阶段 - 在第一阶段,它使用词典为每个单词分配一系列潜在的词性。
第二阶段 - 在第二阶段,它使用大量手工编写的消歧规则来将列表缩减为每个单词的单个词性。
基于规则的POS标注的特性
基于规则的POS标注器具有以下特性:
这些标注器是知识驱动的标注器。
基于规则的POS标注中的规则是手动构建的。
信息以规则的形式编码。
我们有一些有限数量的规则,大约1000条左右。
平滑和语言建模在基于规则的标注器中是明确定义的。
随机POS标注
另一种标注技术是随机POS标注。现在,这里出现的问题是哪个模型可以是随机的。包含频率或概率(统计)的模型可以称为随机模型。任何数量的不同方法都可以应用于词性标注问题,这些方法都可以被称为随机标注器。
最简单的随机标注器应用以下方法进行POS标注:
词频方法
在这种方法中,随机标注器根据单词与特定标签一起出现的概率来消歧单词。我们也可以说,在训练集中与单词一起出现频率最高的标签是分配给该单词模棱两可实例的标签。这种方法的主要问题是它可能产生不可接受的标签序列。
标签序列概率
这是随机标注的另一种方法,其中标注器计算给定标签序列出现的概率。它也称为n-gram方法。之所以这样称呼,是因为给定单词的最佳标签是由它与前n个标签一起出现的概率决定的。
随机POS标注的特性
随机POS标注器具有以下特性:
这种POS标注基于标签出现的概率。
它需要训练语料库。
对于语料库中不存在的单词,将没有概率。
它使用不同的测试语料库(不同于训练语料库)。
这是最简单的POS标注,因为它选择训练语料库中与单词相关的最频繁的标签。
基于转换的标注
基于转换的标注也称为Brill标注。它是基于转换学习 (TBL) 的一个实例,这是一种用于将POS自动标注到给定文本的基于规则的算法。TBL允许我们以易于阅读的形式拥有语言知识,通过使用转换规则将一种状态转换为另一种状态。
它从前面解释的两种标注器——基于规则的和随机的——中汲取灵感。如果我们看到基于规则的和基于转换的标注器之间的相似之处,那么就像基于规则的一样,它也基于指定哪些标签需要分配给哪些单词的规则。另一方面,如果我们看到随机的和基于转换的标注器之间的相似之处,那么就像随机的一样,它是一种机器学习技术,其中规则是从数据中自动归纳的。
基于转换学习 (TBL) 的工作原理
为了理解基于转换的标注器的工作原理和概念,我们需要理解基于转换学习的工作原理。考虑以下步骤以理解TBL的工作原理:
从解决方案开始 - TBL通常从问题的某个解决方案开始,并循环工作。
选择最有利的转换 - 在每个循环中,TBL将选择最有利的转换。
应用于问题 - 上一步中选择的转换将应用于问题。
当步骤2中选择的转换不再增加更多价值或没有更多转换可供选择时,算法将停止。这种学习最适合分类任务。
基于转换学习 (TBL) 的优势
TBL的优势如下:
我们学习少量简单的规则,这些规则足以进行标注。
TBL中的开发和调试非常容易,因为学习的规则易于理解。
标注的复杂性降低了,因为在TBL中,机器学习规则和人工生成的规则交织在一起。
基于转换的标注器比马尔可夫模型标注器快得多。
基于转换学习 (TBL) 的缺点
TBL的缺点如下:
基于转换学习 (TBL) 不提供标签概率。
在TBL中,训练时间非常长,尤其是在大型语料库上。
隐马尔可夫模型 (HMM) POS标注
在深入研究HMM POS标注之前,我们必须理解隐马尔可夫模型 (HMM) 的概念。
隐马尔可夫模型
HMM模型可以定义为双重嵌入的随机模型,其中底层随机过程是隐藏的。这个隐藏的随机过程只能通过另一组产生观测序列的随机过程来观察。
示例
例如,进行了一系列隐藏的抛硬币实验,我们只看到由正面和反面组成的观察序列。这个过程的实际细节——使用了多少枚硬币,选择的顺序——对我们来说是隐藏的。通过观察这一系列的正面和反面,我们可以构建几个隐马尔可夫模型 (HMM) 来解释这个序列。以下是针对此问题的一种隐马尔可夫模型形式:
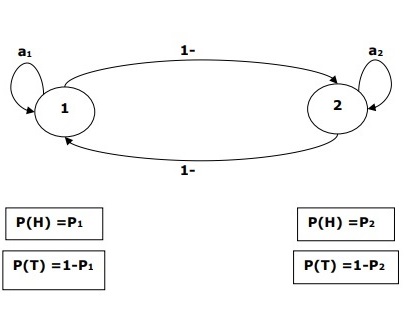
我们假设HMM中有两个状态,每个状态对应于选择不同的有偏差的硬币。以下矩阵给出状态转移概率:
$$A = \begin{bmatrix}a11 & a12 \\a21 & a22 \end{bmatrix}$$
这里:
aij = 从一个状态转移到另一个状态的概率,从i到j。
a11 + a12 = 1 且 a21 + a22 =1
P1 = 第一枚硬币出现正面的概率,即第一枚硬币的偏差。
P2 = 第二枚硬币出现正面的概率,即第二枚硬币的偏差。
我们也可以创建一个假设有3枚或更多硬币的HMM模型。
这样,我们可以通过以下元素来描述HMM:
N,模型中状态的数量(在上面的例子中N=2,只有两个状态)。
M,每个状态下可能出现的不同观察结果的数量(在上面的例子中M=2,即H或T)。
A,状态转移概率分布——上面例子中的矩阵A。
P,每个状态下可观察符号的概率分布(在我们的例子中是P1和P2)。
I,初始状态分布。
HMM在词性标注中的应用
词性标注过程是找到最有可能生成给定词序列的标签序列的过程。我们可以使用隐马尔可夫模型 (HMM) 对此词性过程进行建模,其中标签是产生可观察输出(即词语)的隐藏状态。
在数学上,在词性标注中,我们总是感兴趣的是找到最大化以下值的标签序列 (C):
P (C|W)
其中:
C = C1, C2, C3... CT
W = W1, W2, W3, WT
另一方面,事实是我们需要大量的统计数据才能合理地估计这种序列。然而,为了简化问题,我们可以应用一些数学变换以及一些假设。
使用HMM进行词性标注是贝叶斯推理的一个特例。因此,我们将首先使用贝叶斯规则重新表述这个问题,该规则指出上述条件概率等于:
(PROB (C1,..., CT) * PROB (W1,..., WT | C1,..., CT)) / PROB (W1,..., WT)
在所有这些情况下,我们可以消除分母,因为我们感兴趣的是找到最大化上述值的序列C。这不会影响我们的答案。现在,我们的问题简化为找到最大化以下序列C:
PROB (C1,..., CT) * PROB (W1,..., WT | C1,..., CT) (1)
即使将问题简化为上述表达式,也需要大量的数据。我们可以对上述表达式中的两个概率做出合理的独立性假设来克服这个问题。
第一个假设
一个标签的概率取决于之前的标签(二元模型)或之前的两个标签(三元模型)或之前的n个标签(n元模型),这可以用以下数学公式解释:
PROB (C1,..., CT) = Πi=1..T PROB (Ci|Ci-n+1…Ci-1) (n元模型)
PROB (C1,..., CT) = Πi=1..T PROB (Ci|Ci-1) (二元模型)
句子的开头可以通过假设每个标签的初始概率来解释。
PROB (C1|C0) = PROB initial (C1)
第二个假设
上述公式(1)中的第二个概率可以通过假设一个词出现在一个类别中的概率与前面或后面类别中的词无关来近似,这可以用以下数学公式解释:
PROB (W1,..., WT | C1,..., CT) = Πi=1..T PROB (Wi|Ci)
现在,根据上述两个假设,我们的目标简化为找到一个最大化以下序列C:
Πi=1...T PROB(Ci|Ci-1) * PROB(Wi|Ci)
现在这里出现的问题是,将问题转换成上述形式是否真的帮助了我们。答案是肯定的。如果我们有一个大型标注语料库,那么上述公式中的两个概率可以计算如下:
PROB (Ci=VERB|Ci-1=NOUN) = (动词出现在名词后面的实例数)/(名词出现的实例数) (2)
PROB (Wi|Ci) = (Wi出现在Ci中的实例数)/(Ci出现的实例数) (3)
自然语言处理 - 开篇
本章,我们将讨论自然语言处理中的自然语言入门。首先,让我们先了解什么是自然语言语法。
自然语言语法
对于语言学家来说,语言是一组任意的语音符号。我们可以说语言是创造性的,受规则支配的,同时也是先天性和普遍性的。另一方面,它也是人性的。不同人的语言性质不同。关于语言的性质有很多误解。这就是为什么理解模棱两可的术语“语法”的含义非常重要的原因。在语言学中,语法可以定义为语言运作所遵循的规则或原则。广义上,我们可以将语法分为两类:
描写语法
语言学家和语法学家用来描述说话者语法的规则集合称为描写语法。
规范语法
这是语法的另一种意义,它试图维持语言的正确性标准。这一类别与语言的实际运作关系不大。
语言的组成部分
语言研究被划分为相互关联的组成部分,这些组成部分是语言学研究的约定俗成且任意的划分。这些组成部分的解释如下:
音系学
语言的第一个组成部分是音系学。它是对特定语言语音的研究。这个词的起源可以追溯到希腊语,其中“phone”的意思是声音或语音。音韵学的一个分支——语音学,是从语音的产生、感知或物理属性的角度研究人类语言的语音。国际音标 (IPA) 是一种以规范的方式表示人类语音的工具,用于音系学的研究。在IPA中,每个书写符号都代表一个且只有一个语音,反之亦然。
音位
它可以定义为一种声音单位,它使一种语言中的一个词与另一个词区分开来。在语言学中,音位用斜线括起来。例如,音位/k/出现在诸如kit、skit等词中。
形态学
它是语言的第二个组成部分。它是对特定语言中词的结构和分类的研究。这个词的起源来自希腊语,其中“morphe”的意思是“形式”。形态学考虑的是一种语言中词的构成原则。换句话说,声音如何组合成有意义的单位,如前缀、后缀和词根。它还考虑了如何将单词分组到词类中。
词素
在语言学中,形态学分析的抽象单位,对应于单个词的一组形式,称为词素。词素在句中的使用方式由其语法类别决定。词素可以是单个词或多个词。例如,单词“talk”就是一个单个词词素的例子,它可能有许多语法变体,如talks、talked和talking。多词词素可以由多个拼写词组成。例如,speak up、pull through等是多词词素的例子。
句法
它是语言的第三个组成部分。它是对将单词组合成更大单位的顺序和排列的研究。这个词可以追溯到希腊语,其中suntassein的意思是“按顺序排列”。它研究句子类型及其结构、从句和短语。
语义学
它是语言的第四个组成部分。它是研究如何表达意义的学科。意义可以与外部世界相关,也可以与句子的语法相关。这个词可以追溯到希腊语,其中semainein的意思是“表示”、“显示”、“信号”。
语用学
它是语言的第五个组成部分。它是研究语言的功能及其在语境中的使用的学科。这个词的起源可以追溯到希腊语,其中“pragma”的意思是“行为”、“事件”。
语法范畴
语法范畴可以定义为语言语法中的一类单位或特征。这些单位是语言的构成要素,并共享一组共同的特征。语法范畴也称为语法特征。
语法范畴的清单如下:
数
这是最简单的语法范畴。我们有两个与这个范畴相关的术语:单数和复数。单数是“一”的概念,而复数是“多于一”的概念。例如,dog/dogs,this/these。
性
语法性由人称代词和第三人称的变化来表达。语法性的例子是单数:he、she、it;第一和第二人称形式:I、we和you;第三人称复数形式they,是普通性或中性。
人称
另一个简单的语法范畴是人称。在此之下,识别出以下三个术语:
第一人称 - 说话者被识别为第一人称。
第二人称 - 听者或被谈话者被识别为第二人称。
第三人称 - 我们谈论的人或物被识别为第三人称。
格
这是最困难的语法范畴之一。它可以定义为名词短语 (NP) 功能的指示,或名词短语与动词或句子中其他名词短语的关系。我们在人称代词和疑问代词中表达了以下三种格:
主格 − 它是主语的功能。例如,I、we、you、he、she、it、they和who都是主格。
属格 − 它是所有格的功能。例如,my/mine、our/ours、his、her/hers、its、their/theirs、whose都是属格。
宾格 − 它是宾语的功能。例如,me、us、you、him、her、them、whom都是宾格。
程度
这个语法范畴与形容词和副词有关。它包含以下三个等级 −
原级 − 它表达一种性质。例如,big、fast、beautiful都是原级。
比较级 − 它表达两种事物中一种性质的更高程度或强度。例如,bigger、faster、more beautiful都是比较级。
最高级 − 它表达三种或更多事物中一种性质的最高程度或强度。例如,biggest、fastest、most beautiful都是最高级。
限定和非限定
这两个概念都很简单。限定性,正如我们所知,指的是说话者或听者已知、熟悉或可识别的指称。另一方面,非限定性指的是未知或不熟悉的指称。这个概念可以在冠词与名词的共现中理解 −
定冠词 − the
不定冠词 − a/an
时态
这个语法范畴与动词有关,可以定义为对动作时间的语言表达。时态建立了一种关系,因为它表示事件相对于说话时刻的时间。大体上,它有以下三种类型 −
现在时 − 表示动作在现在发生的。例如,Ram works hard。( राम मेहनत करता है)
过去时 − 表示动作发生在现在时刻之前。例如,it rained。(雨下了)
将来时 − 表示动作发生在现在时刻之后。例如,it will rain。(雨会下)
体
这个语法范畴可以定义为对事件的视角。它可以是以下类型 −
完成体 − 从这个角度来看,事件是完整和完整的。例如,英语中的简单过去时,如yesterday I met my friend,就是完成体,因为它将事件视为完整和整体的。
未完成体 − 从这个角度来看,事件是正在进行的和不完整的。例如,英语中的现在分词时态,如I am working on this problem,就是未完成体,因为它将事件视为不完整和正在进行的。
语气
这个语法范畴有点难以定义,但简单地说,它是说话者对所说内容的态度的表达。它也是动词的语法特征。它不同于语法时态和语法体。语气的例子有陈述语气、疑问语气、祈使语气、命令语气、虚拟语气、可能语气、愿望语气、动名词和分词。
一致
它也称为一致性。当一个词根据它所关联的其他词而发生变化时,就会发生这种情况。换句话说,它涉及使某些语法范畴的值在不同的词或词性之间保持一致。以下是基于其他语法范畴的一致性 −
基于人称的一致 − 它是主语和谓语动词之间的一致。例如,我们总是用“I am”和“He is”,但决不用“He am”和“I is”。
基于数的一致 − 这种一致性发生在主语和谓语动词之间。在这种情况下,第一人称单数、第二人称复数等有特定的动词形式。例如,第一人称单数:I really am,第二人称复数:We really are,第三人称单数:The boy sings,第三人称复数:The boys sing。
基于性别的的一致 − 在英语中,代词和先行词在性别上保持一致。例如,He reached his destination. The ship reached her destination.
基于格的一致 − 这种一致性不是英语的重要特征。例如,谁先来——他还是他的妹妹?
口语语法
书面英语和口语英语语法有很多共同点,但与此同时,它们在许多方面也存在差异。以下特征区分了口语英语和书面英语语法 −
语流不畅和修复
这个显著特征使口语英语和书面英语语法彼此不同。它分别被称为语流不畅现象,统称为修复现象。语流不畅包括使用以下内容 −
填充词 − 有时在句子中间,我们会使用一些填充词。它们被称为填充词或填充停顿。此类词的例子是uh和um。
需修复部分和修复 − 句子中间重复的词段称为需修复部分。在同一词段中,更改的词称为修复。考虑以下例子以理解这一点 −
Does ABC airlines offer any one-way flights uh one-way fares for 5000 rupees?
在上面的句子中,“one-way flight”是需修复部分,“one-way fares”是修复。
重新开始
在填充停顿之后,会发生重新开始。例如,在上面的句子中,当说话者开始询问单程航班然后停顿,用填充停顿纠正自己,然后重新开始询问单程票价时,就会发生重新开始。
词语碎片
有时我们用较小的词语碎片来说话。例如,wwha-what is the time? 这里的词w-wha是词语碎片。
NLP - 信息检索
信息检索 (IR) 可以定义为一种软件程序,它处理从文档存储库(特别是文本信息)中组织、存储、检索和评估信息。该系统帮助用户找到他们需要的信息,但它不会明确地返回问题的答案。它告知可能包含所需信息的文档的存在和位置。满足用户需求的文档称为相关文档。完美的 IR 系统只会检索相关文档。
借助下图,我们可以理解信息检索 (IR) 的过程 −
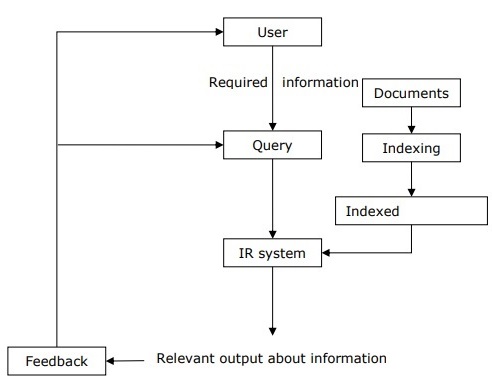
从上图可以清楚地看出,需要信息的使用者必须以自然语言查询的形式提出请求。然后,IR 系统将通过检索相关输出(以文档形式)来响应所需信息。
信息检索 (IR) 系统中的经典问题
IR 研究的主要目标是开发一个模型,用于从文档存储库中检索信息。在这里,我们将讨论一个经典问题,称为即席检索问题,它与 IR 系统有关。
在即席检索中,用户必须输入用自然语言描述所需信息的查询。然后,IR 系统将返回与所需信息相关的所需文档。例如,假设我们在互联网上搜索某些内容,它会提供一些根据我们的要求相关的精确页面,但也可能有一些不相关的页面。这是由于即席检索问题造成的。
即席检索的方面
以下是 IR 研究中解决的即席检索的一些方面 −
用户如何借助相关反馈来改进查询的原始表达?
如何实现数据库合并,即如何将来自不同文本数据库的结果合并到一个结果集中?
如何处理部分损坏的数据?哪些模型适合这种情况?
信息检索 (IR) 模型
在数学上,模型被用于许多科学领域,其目的是理解现实世界中的一些现象。信息检索模型预测并解释用户将找到什么与给定查询相关。IR 模型基本上是一个模式,它定义了上述检索过程的各个方面,并包含以下内容 −
文档模型。
查询模型。
比较查询和文档的匹配函数。
在数学上,检索模型包含 −
D − 文档的表示。
Q − 查询的表示。
F − D、Q 的建模框架以及它们之间关系。
R (q,di) − 一个相似度函数,它根据查询对文档进行排序。它也称为排序。
信息检索 (IR) 模型的类型
信息模型 (IR) 模型可以分为以下三种模型 −
经典 IR 模型
它是最简单、最易于实现的 IR 模型。该模型基于很容易识别和理解的数学知识。布尔型、向量型和概率型是三种经典的 IR 模型。
非经典 IR 模型
它与经典 IR 模型完全相反。这种 IR 模型基于相似性、概率、布尔运算以外的原理。信息逻辑模型、情境理论模型和交互模型是非经典 IR 模型的例子。
替代 IR 模型
它是经典 IR 模型的改进,它利用了其他领域的一些特定技术。聚类模型、模糊模型和潜在语义索引 (LSI) 模型是替代 IR 模型的例子。
信息检索 (IR) 系统的设计特征
现在让我们学习一下 IR 系统的设计特征 −
倒排索引
大多数 IR 系统的主要数据结构是倒排索引的形式。我们可以将倒排索引定义为一种数据结构,它列出每个单词的所有包含它的文档以及在文档中出现的频率。它使得搜索查询词的“命中”变得容易。
停用词消除
停用词是那些高频词,这些词被认为不太可能对搜索有用。它们的语义权重较低。所有此类词都位于称为停用词列表的列表中。例如,冠词“a”、“an”、“the”和介词如“in”、“of”、“for”、“at”等是停用词的例子。停用词列表可以显著减少倒排索引的大小。根据齐夫定律,包含几十个词的停用词列表可将倒排索引的大小减少近一半。另一方面,有时停用词的消除可能会导致对搜索有用的词的消除。例如,如果我们从“Vitamin A”中消除字母“A”,那么它将没有任何意义。
词干提取
词干提取是形态分析的简化形式,它是一个启发式过程,通过去除单词的词尾来提取单词的基本形式。例如,“laughing”、“laughs”、“laughed”这几个词会被词干提取成词根“laugh”。
在接下来的章节中,我们将讨论一些重要且有用的信息检索模型。
布尔模型
它是信息检索 (IR) 最古老的模型。该模型基于集合论和布尔代数,其中文档是术语的集合,查询是术语上的布尔表达式。布尔模型可以定义为:
D − 一组单词,即文档中存在的索引项。这里,每个术语要么存在 (1),要么不存在 (0)。
Q − 一个布尔表达式,其中术语是索引项,运算符是逻辑积 − AND,逻辑和 − OR 和逻辑差 − NOT
F − 基于术语集合和文档集合的布尔代数
如果我们谈论相关反馈,那么在布尔 IR 模型中,相关性预测可以定义如下:
R − 当且仅当文档满足查询表达式时,才预测该文档与查询表达式相关:
((𝑡𝑒𝑥𝑡 ˅ 𝑖𝑛𝑓𝑜𝑟𝑚𝑎𝑡𝑖𝑜𝑛) ˄ 𝑟𝑒𝑟𝑖𝑒𝑣𝑎𝑙 ˄ ˜ 𝑡ℎ𝑒𝑜𝑟𝑦)
我们可以将查询词解释为文档集合的明确定义。
例如,查询词“economic”定义了用术语“economic”索引的文档集合。
现在,使用布尔 AND 运算符组合术语后的结果是什么?它将定义一个文档集合,该集合小于或等于任何单个术语的文档集合。例如,包含术语“social”和“economic”的查询将产生用这两个术语都进行索引的文档集合。换句话说,是两个集合的交集。
现在,使用布尔 OR 运算符组合术语后的结果是什么?它将定义一个文档集合,该集合大于或等于任何单个术语的文档集合。例如,包含术语“social”或“economic”的查询将产生用术语“social”或“economic”进行索引的文档集合。换句话说,是两个集合的并集。
布尔模型的优点
布尔模型的优点如下:
基于集合的最简单模型。
易于理解和实现。
它只检索精确匹配。
它让用户对系统有掌控感。
布尔模型的缺点
布尔模型的缺点如下:
该模型的相似度函数是布尔函数。因此,不会有部分匹配。这可能会让用户感到恼火。
在这个模型中,布尔运算符的使用比关键词的影响更大。
查询语言表达能力强,但也比较复杂。
检索到的文档没有排名。
向量空间模型
由于布尔模型上述缺点,Gerard Salton 和他的同事提出了一种基于 Luhn 相似性准则的模型。Luhn 提出的相似性准则指出:“两种表示在给定元素及其分布上越一致,则它们代表相似信息的概率就越高。”
请考虑以下要点,以便更好地理解向量空间模型:
索引表示(文档)和查询被视为嵌入在高维欧几里得空间中的向量。
文档向量与查询向量的相似性度量通常是它们之间角度的余弦值。
余弦相似度度量公式
余弦是归一化点积,可以用以下公式计算:
$$Score \lgroup \vec{d} \vec{q} \rgroup= \frac{\sum_{k=1}^m d_{k}\:.q_{k}}{\sqrt{\sum_{k=1}^m\lgroup d_{k}\rgroup^2}\:.\sqrt{\sum_{k=1}^m}m\lgroup q_{k}\rgroup^2 }$$
$$Score \lgroup \vec{d} \vec{q}\rgroup =1\:when\:d =q $$
$$Score \lgroup \vec{d} \vec{q}\rgroup =0\:when\:d\:and\:q\:share\:no\:items$$
带有查询和文档的向量空间表示
查询和文档由二维向量空间表示。术语为“car”和“insurance”。向量空间中有一个查询和三个文档。
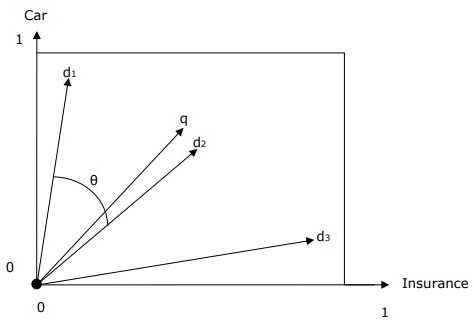
针对术语“car”和“insurance”的排名最高的文档将是文档d2,因为q和d2之间的角度最小。其原因是“car”和“insurance”这两个概念在d2中都很突出,因此权重较高。另一方面,d1和d3也提到了这两个术语,但在每种情况下,其中一个术语都不是文档中的核心重要术语。
词项权重
词项权重指的是向量空间中词项的权重。词项的权重越高,该词项对余弦值的影响就越大。模型应该为更重要的词项分配更高的权重。现在这里出现的问题是如何对它进行建模。
一种方法是将文档中的词数作为其词项权重。但是,您认为这是一种有效的方法吗?
另一种更有效的方法是使用词频 (tfij)、文档频率 (dfi) 和集合频率 (cfi)。
词频 (tfij)
它可以定义为wi在dj中出现的次数。词频捕捉到的信息是某个词在给定文档中的显著程度,换句话说,词频越高,该词就越能很好地描述该文档的内容。
文档频率 (dfi)
它可以定义为集合中包含wi的文档总数。它是信息量的一个指标。与语义不集中的词不同,语义集中的词会在文档中出现多次。
集合频率 (cfi)
它可以定义为wi在集合中出现的总次数。
数学上,$df_{i}\leq cf_{i}\:and\:\sum_{j}tf_{ij} = cf_{i}$
文档频率权重的形式
现在让我们学习文档频率权重的不同形式。这些形式描述如下:
词频因子
这也被归类为词频因子,这意味着如果术语t在一个文档中频繁出现,那么包含t的查询应该检索该文档。我们可以将单词的词频 (tfij)和文档频率 (dfi)组合成单个权重,如下所示:
$$weight \left ( i,j \right ) =\begin{cases}(1+log(tf_{ij}))log\frac{N}{df_{i}}\:if\:tf_{i,j}\:\geq1\\0 \:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\: if\:tf_{i,j}\:=0\end{cases}$$
这里 N 是文档总数。
逆文档频率 (idf)
这是文档频率权重的另一种形式,通常称为 idf 权重或逆文档频率权重。idf 权重的重点是术语在整个集合中的稀缺性是其重要性的衡量标准,并且重要性与出现频率成反比。
数学上,
$$idf_{t} = log\left(1+\frac{N}{n_{t}}\right)$$
$$idf_{t} = log\left(\frac{N-n_{t}}{n_{t}}\right)$$
这里:
N = 集合中的文档数
nt = 包含术语t的文档数
用户查询改进
任何信息检索系统的主要目标必须是准确性——根据用户的需求生成相关的文档。但是,这里出现的问题是如何通过改进用户的查询表达方式来改进输出。当然,任何 IR 系统的输出都取决于用户的查询,而格式良好的查询将产生更准确的结果。用户可以借助于相关反馈来改进其查询,这是任何 IR 模型的重要方面。
相关反馈
相关反馈采用从给定查询最初返回的输出。此初始输出可用于收集用户信息,并了解该输出是否相关以执行新查询。反馈可以分类如下:
显式反馈
它可以定义为从相关性评估者那里获得的反馈。这些评估者还将指示从查询检索到的文档的相关性。为了提高查询检索性能,需要将相关反馈信息与原始查询插值。
系统评估者或其他用户可以使用以下相关性系统明确指示相关性:
二元相关性系统 − 此相关反馈系统指示文档对于给定查询而言是相关 (1) 还是不相关 (0)。
等级相关性系统 − 等级相关反馈系统根据使用数字、字母或描述进行的评分来指示文档对于给定查询的相关性。描述可以像“不相关”、“有点相关”、“非常相关”或“相关”一样。
隐式反馈
它是从用户行为中推断出的反馈。行为包括用户查看文档所花费的时间、选择查看哪些文档以及哪些文档没有查看、页面浏览和滚动操作等。隐式反馈的最佳示例之一是停留时间,它衡量用户花费多少时间查看搜索结果中链接到的页面。
伪反馈
也称为盲反馈。它提供了一种自动局部分析的方法。借助伪相关反馈,可以使相关反馈的手动部分自动化,以便用户无需进行扩展交互即可获得改进的检索性能。此反馈系统的主要优点是它不需要像显式相关反馈系统那样的评估者。
请考虑以下步骤来实现此反馈:
步骤 1 − 首先,初始查询返回的结果必须作为相关结果。相关结果的范围必须在排名前 10-50 的结果中。
步骤 2 − 现在,例如使用词频 (tf)-逆文档频率 (idf) 权重从文档中选择前 20-30 个词语。
步骤 3 − 将这些词语添加到查询中并匹配返回的文档。然后返回最相关的文档。
自然语言处理 (NLP) 的应用
自然语言处理 (NLP) 是一项新兴技术,它衍生出我们现在看到的各种形式的人工智能,并且它用于创建人和机器之间无缝且交互式的接口将继续成为当今和未来越来越多的认知应用的首要任务。在这里,我们将讨论一些非常有用的 NLP 应用。
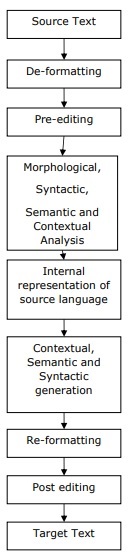
机器翻译
机器翻译 (MT),将一种源语言或文本翻译成另一种语言的过程,是 NLP 最重要的应用之一。我们可以借助以下流程图了解机器翻译的过程 −
机器翻译系统的类型
有不同类型的机器翻译系统。让我们看看有哪些不同类型。
双语 MT 系统
双语 MT 系统在两种特定语言之间进行翻译。
多语言 MT 系统
多语言 MT 系统可在任何一对语言之间进行翻译。它们在本质上可以是单向的或双向的。
机器翻译 (MT) 的方法
现在让我们学习机器翻译的重要方法。MT 的方法如下 −
直接 MT 方法
它不太流行,但却是 MT 最古老的方法。使用这种方法的系统能够将源语言 (SL) 直接翻译成目标语言 (TL)。此类系统本质上是双语和单向的。
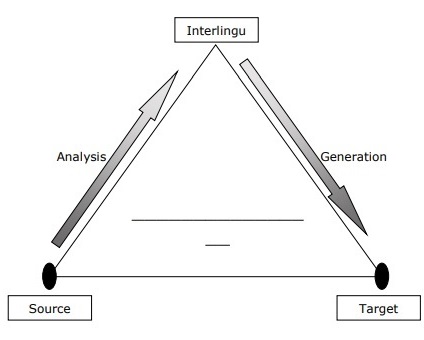
中间语言方法
使用中间语言方法的系统将 SL 翻译成一种称为中间语言 (IL) 的中间语言,然后将 IL 翻译成 TL。可以使用以下 MT 金字塔来理解中间语言方法 −
转换方法
此方法涉及三个阶段。
在第一阶段,源语言 (SL) 文本被转换为面向抽象 SL 的表示。
在第二阶段,面向 SL 的表示被转换为等效的目标语言 (TL) 面向的表示。
在第三阶段,生成最终文本。
经验 MT 方法
这是一种新兴的 MT 方法。基本上,它使用大量以平行语料库形式存在的原始数据。原始数据包含文本及其翻译。基于类比、基于示例、基于内存的机器翻译技术使用经验 MT 方法。
反垃圾邮件
如今最常见的问题之一是不需要的电子邮件。这使得垃圾邮件过滤器更加重要,因为它是在对抗此问题的防御的第一道防线。
通过考虑主要的误报和漏报问题,可以使用 NLP 功能开发垃圾邮件过滤系统。
现有的用于垃圾邮件过滤的 NLP 模型
以下是用于垃圾邮件过滤的一些现有 NLP 模型 −
N 元模型
N 元模型是较长字符串的 N 字符切片。在此模型中,不同长度的 N 元组同时用于处理和检测垃圾邮件。
词干提取
垃圾邮件发送者(垃圾邮件的生成者)通常会更改其垃圾邮件中攻击性词语的一个或多个字符,以便他们可以突破基于内容的垃圾邮件过滤器。这就是为什么我们可以说,如果基于内容的过滤器无法理解电子邮件中单词或短语的含义,它们就没有用。为了消除垃圾邮件过滤中的此类问题,开发了一种基于规则的词干提取技术,该技术可以匹配看起来和听起来相似的单词。
贝叶斯分类
这已成为一种广泛用于垃圾邮件过滤的技术。在一项统计技术中,电子邮件中单词的出现频率与未经请求的(垃圾邮件)和合法(非垃圾邮件)电子邮件消息数据库中其典型出现频率进行衡量。
自动摘要
在这个数字时代,最有价值的是数据,或者你可以说信息。但是,我们真的得到了有用以及所需数量的信息吗?答案是“否”,因为信息过载,我们获取知识和信息的途径远远超过了我们理解它的能力。我们迫切需要自动文本摘要和信息,因为互联网上的信息泛滥不会停止。
文本摘要可以定义为创建较长文本文档的简短、准确摘要的技术。自动文本摘要将帮助我们在更短的时间内获得相关信息。自然语言处理 (NLP) 在开发自动文本摘要方面发挥着重要作用。
问答
自然语言处理 (NLP) 的另一个主要应用是问答。搜索引擎将世界的信息掌握在我们的指尖,但当涉及到回答人类用自然语言提出的问题时,它们仍然存在不足。像谷歌这样的大型科技公司也在朝这个方向努力。
问答是人工智能和 NLP 领域内的一门计算机科学学科。它专注于构建能够自动回答人类用自然语言提出的问题的系统。一个理解自然语言的计算机系统具有程序系统的能力,可以将人类编写的句子翻译成内部表示,以便系统可以生成有效的答案。可以通过对问题的语法和语义分析来生成准确的答案。词汇差距、歧义和多语言性是 NLP 在构建良好的问答系统方面面临的一些挑战。
情感分析
自然语言处理 (NLP) 的另一个重要应用是情感分析。顾名思义,情感分析用于识别多个帖子中的情感。它也用于识别未明确表达情感的地方。公司正在使用情感分析(自然语言处理 (NLP) 的一种应用)来识别客户在线的意见和情感。这将帮助公司了解他们的客户对产品和服务的看法。公司可以借助情感分析来判断其来自客户帖子的整体声誉。这样,我们可以说,除了确定简单的极性之外,情感分析还会在上下文中理解情感,以帮助我们更好地理解表达意见背后的原因。
自然语言处理 - Python
在本章中,我们将学习使用 Python 进行语言处理。
以下特性使 Python 与其他语言有所不同 −
Python 是解释型语言 − 我们不需要在执行 Python 程序之前编译它,因为解释器在运行时处理 Python。
交互式 − 我们可以直接与解释器交互来编写 Python 程序。
面向对象 − Python 本质上是面向对象的,这使得编写程序更容易,因为借助这种编程技术,它可以将代码封装在对象中。
初学者易于学习 − Python 也被称为初学者语言,因为它非常容易理解,并且支持开发各种各样的应用程序。
先决条件
发布的最新 Python 3 版本是 Python 3.7.1,适用于 Windows、Mac OS 和大多数 Linux OS 版本。
对于 Windows,我们可以访问链接 www.python.org/downloads/windows/ 下载和安装 Python。
对于 MAC OS,我们可以使用链接 www.python.org/downloads/mac-osx/。
对于 Linux,不同版本的 Linux 使用不同的包管理器来安装新包。
例如,要在 Ubuntu Linux 上安装 Python 3,我们可以从终端使用以下命令 −
$sudo apt-get install python3-minimal
要了解更多关于 Python 编程的信息,请阅读 Python 3 基础教程 – Python 3
NLTK 入门
我们将使用 Python 库 NLTK(自然语言工具包)对英语文本进行文本分析。自然语言工具包 (NLTK) 是 Python 库的集合,专门用于识别和标记在自然语言(如英语)文本中发现的词性。
安装 NLTK
在开始使用 NLTK 之前,我们需要安装它。借助以下命令,我们可以在 Python 环境中安装它 −
pip install nltk
如果我们使用的是 Anaconda,则可以使用以下命令构建 NLTK 的 Conda 包 −
conda install -c anaconda nltk
下载 NLTK 的数据
安装 NLTK 后,另一个重要的任务是下载其预设文本存储库,以便可以轻松使用它。但是,在此之前,我们需要像导入任何其他 Python 模块一样导入 NLTK。以下命令将帮助我们导入 NLTK −
import nltk
现在,使用以下命令下载 NLTK 数据 −
nltk.download()
安装所有可用的 NLTK 包需要一些时间。
其他必要的包
其他一些 Python 包,如 gensim 和 pattern,对于文本分析以及使用 NLTK 构建自然语言处理应用程序也是非常必要的。这些包的安装方法如下所示 −
gensim
gensim 是一个强大的语义建模库,可用于许多应用程序。我们可以通过以下命令安装它 −
pip install gensim
pattern
它可以用来使 gensim 包正常工作。以下命令有助于安装 pattern −
pip install pattern
分词
分词可以定义为将给定文本分解成称为标记的较小单元的过程。单词、数字或标点符号可以是标记。它也可以称为单词分割。
示例
输入 − 床和椅子是家具的类型。

NLTK 提供了不同的分词包。我们可以根据我们的需求使用这些包。这些包及其安装细节如下 −
sent_tokenize 包
此包可用于将输入文本划分为句子。我们可以使用以下命令导入它 −
from nltk.tokenize import sent_tokenize
word_tokenize 包
此包可用于将输入文本划分为单词。我们可以使用以下命令导入它 −
from nltk.tokenize import word_tokenize
WordPunctTokenizer 包
此包可用于将输入文本划分为单词和标点符号。我们可以使用以下命令导入它 −
from nltk.tokenize import WordPuncttokenizer
词干提取
由于语法原因,语言包含许多变体。变体是指语言(英语以及其他语言)具有单词的不同形式。例如,诸如 democracy、democratic 和 democratization 之类的词。对于机器学习项目,机器理解这些不同的词(如上所述)具有相同的词干形式非常重要。这就是为什么在分析文本时提取单词的基本形式非常有用的原因。
词干提取是一个启发式过程,它有助于通过去除词尾来提取单词的基本形式。
NLTK 模块提供的不同词干提取包如下 −
PorterStemmer 包
此词干提取包使用 Porter 算法来提取单词的基本形式。借助以下命令,我们可以导入此包 −
from nltk.stem.porter import PorterStemmer
例如,将‘writing’作为输入提供给此词干提取器,其输出将是‘write’。
LancasterStemmer 包
此词干提取包使用 Lancaster 算法来提取单词的基本形式。借助以下命令,我们可以导入此包 −
from nltk.stem.lancaster import LancasterStemmer
例如,将‘writing’作为输入提供给此词干提取器,其输出将是‘writ’。
SnowballStemmer 包
此词干提取包使用 Snowball 算法来提取单词的基本形式。借助以下命令,我们可以导入此包 −
from nltk.stem.snowball import SnowballStemmer
例如,将‘writing’作为输入提供给此词干提取器,其输出将是‘write’。
词形还原
这是提取单词基本形式的另一种方法,通常旨在使用词汇和形态分析来去除屈折词尾。词形还原后,任何单词的基本形式都称为词形。
NLTK模块提供以下用于词形还原的包:
WordNetLemmatizer包
此包将根据单词用作名词还是动词提取单词的基本形式。可以使用以下命令导入此包:
from nltk.stem import WordNetLemmatizer
词性计数 – 组块分析
借助组块分析可以识别词性 (POS) 和短语。它是自然语言处理中的重要过程之一。我们知道分词过程用于创建标记,组块分析实际上是对这些标记进行标注。换句话说,我们可以说我们可以借助组块分析过程获得句子的结构。
示例
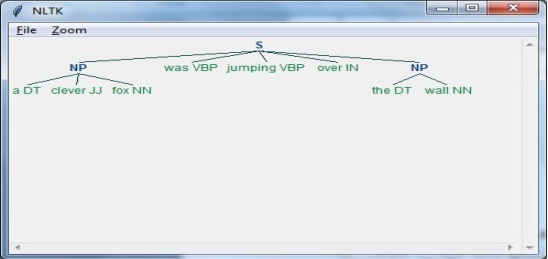
在下面的示例中,我们将使用 NLTK Python 模块实现名词短语组块分析,这是一种组块分析类别,它将查找句子中的名词短语组块。
考虑以下步骤来实现名词短语组块分析:
步骤 1:组块语法定义
在此步骤中,我们需要定义组块分析的语法。它将包含我们需要遵循的规则。
步骤 2:创建组块解析器
接下来,我们需要创建一个组块解析器。它将解析语法并给出输出。
步骤 3:输出
在此步骤中,我们将以树状格式获取输出。
运行 NLP 脚本
首先导入 NLTK 包:
import nltk
现在,我们需要定义句子。
这里:
DT 是限定词
VBP 是动词
JJ 是形容词
IN 是介词
NN 是名词
sentence = [("a", "DT"),("clever","JJ"),("fox","NN"),("was","VBP"),
("jumping","VBP"),("over","IN"),("the","DT"),("wall","NN")]
接下来,语法应以正则表达式的形式给出。
grammar = "NP:{<DT>?<JJ>*<NN>}"
现在,我们需要定义一个用于解析语法的解析器。
parser_chunking = nltk.RegexpParser(grammar)
现在,解析器将如下解析句子:
parser_chunking.parse(sentence)
接下来,输出将如下存储在变量中:
Output = parser_chunking.parse(sentence)
现在,以下代码将帮助您以树的形式绘制输出。
output.draw()