
 数据结构
数据结构 网络
网络 关系数据库管理系统 (RDBMS)
关系数据库管理系统 (RDBMS) 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C语言编程
C语言编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHPHive动态分区概述
Hive是由Facebook开发的,用于分析和MapReduce作业。它可以读取、写入和管理大型数据集。Hive可以替代传统的数据库操作。Hive使用索引来提高查询效率,并且可以处理存储在Hadoop生态系统中的压缩数据。
在本文中,我们将讨论Hive中的动态分区及其操作。
Apache Hive
Apache Hive是一个数据仓库系统,用于对结构化数据执行操作。它广泛用于分析和MapReduce作业。Apache Hive提供读取、写入和管理大型数据集的功能。Hive的关键特性之一是其对数据进行分区的能力。在本文中,我们将概述Hive中的动态分区。
Hive中的分区
分区是将大型数据集划分为更小、更易于管理的部分的过程。Hive中有两种分区类型:静态分区和动态分区。
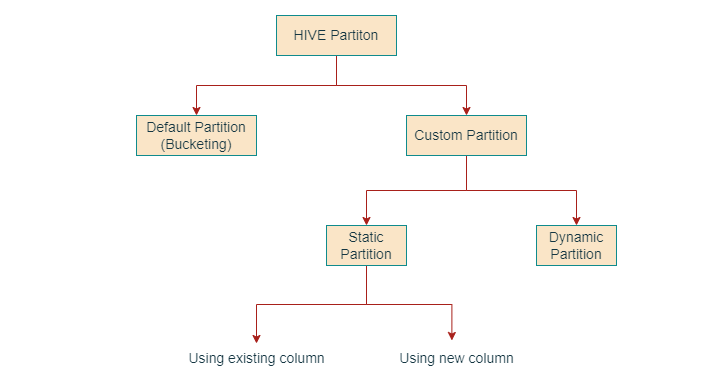
静态分区
在将数据插入分区表时,它会指定每个记录的分区键和值。这种方法用于分区数量较少的情况。
动态分区
它具有更灵活的方法。它根据插入的数据确定分区键和值。对于具有大量分区的大型数据集,它是更好的选择。
动态分区的特性
它有很多特性,这些特性使其成为处理存储在分布式存储中的大量数据的理想选择。以下是动态分区的一些特性:
能够处理大型数据集
动态分区是从非分区表加载数据的策略方法。它处理存储在分布式存储中的大型数据集。
支持外部表和管理表
可以在Hive的外部表和管理表上执行动态分区。
不需要WHERE子句
与静态分区不同,动态分区不需要WHERE子句来指定分区键和值。
能够处理结构未知的表
动态分区可以用于对表进行分区,而无需预先知道列的数量。
动态分区的操作
以下是执行Hive动态分区操作的步骤:
步骤1 - 创建要执行操作的数据库并选择它。
步骤2 - 使用以下命令启用动态分区
hive> set hive.exec.dynamic.partition=true; hive> set hive.exec.dynamic.partition.mode=nonstrict;
步骤3 - 创建一个表来存储数据。
步骤4 - 将数据加载到表中。
步骤5 - 使用`partitioned by`子句创建一个分区表。
步骤6 - 将数据加载到分区表中。
步骤7 - 执行查询操作。
步骤8 - 要删除动态分区列,请使用以下命令
hive> alter table partitioned_table drop partition (partition_col = 'value');
请务必将`partition_col`和`value`替换为相应的列名和值。
结论
动态分区是Hive的一个特性,它高效且灵活地处理存储在分布式存储中的大型数据集。它可以成为分析和MapReduce作业的绝佳选择。执行动态分区操作的步骤相对简单易懂。用户可以充分利用Hive中的动态分区,从而提高数据管理和分析能力。Hive是大数据工具,凭借动态分区等特性,它变得更加多功能和宝贵。

523 次浏览
