- 并行算法有用资源
- 并行算法 - 快速指南
- 并行算法 - 有用资源
- 并行算法 - 讨论
并行随机存取机
并行随机存取机 (PRAM)是一种模型,它被认为适用于大多数并行算法。在这里,多个处理器连接到单个内存块。PRAM模型包含:
一组类似类型的处理器。
所有处理器共享一个公共内存单元。处理器只能通过共享内存相互通信。
一个内存访问单元 (MAU) 将处理器与单个共享内存连接起来。
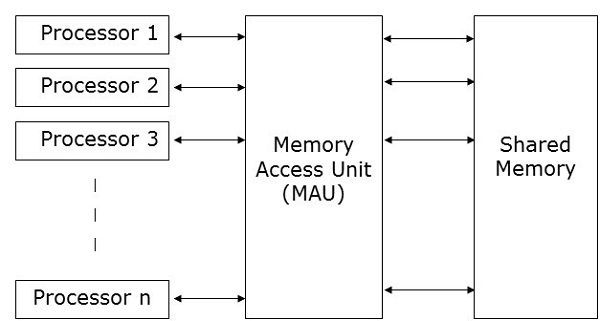
在这里,n个处理器可以在特定时间单位内对n个数据执行独立操作。这可能会导致不同的处理器同时访问相同的内存位置。
为了解决这个问题,在PRAM模型上施加了以下约束:
独占读独占写 (EREW) - 在这里,不允许两个处理器同时从同一内存位置读取或写入。
独占读并发写 (ERCW) - 在这里,不允许两个处理器同时从同一内存位置读取,但允许同时写入同一内存位置。
并发读独占写 (CREW) - 在这里,允许所有处理器同时从同一内存位置读取,但不允许同时写入同一内存位置。
并发读并发写 (CRCW) - 允许所有处理器同时从同一内存位置读取或写入。
有许多方法可以实现PRAM模型,但最突出的方法是:
- 共享内存模型
- 消息传递模型
- 数据并行模型
共享内存模型
共享内存强调控制并行性而不是数据并行性。在共享内存模型中,多个进程在不同的处理器上独立执行,但它们共享一个公共内存空间。由于任何处理器的活动,如果任何内存位置发生任何更改,则其他处理器都可以看到。
由于多个处理器访问同一内存位置,因此在任何特定时间点,可能有多个处理器访问同一内存位置。假设一个正在读取该位置,而另一个正在写入该位置。这可能会造成混淆。为了避免这种情况,实现了一些控制机制,例如锁/信号量,以确保互斥。
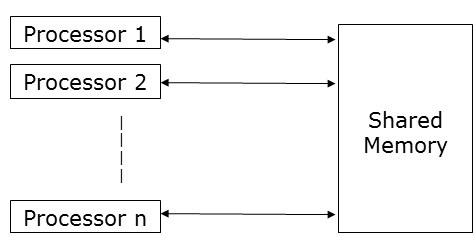
共享内存编程已在以下方面实现:
线程库 - 线程库允许多个控制线程在同一内存位置并发运行。线程库提供了一个接口,通过子程序库支持多线程。它包含用于以下方面的子程序:
- 创建和销毁线程
- 调度线程执行
- 在线程之间传递数据和消息
- 保存和恢复线程上下文
线程库的示例包括:SolarisTM线程(用于Solaris),POSIX线程(在Linux中实现),Win32线程(在Windows NT和Windows 2000中可用)以及作为标准JavaTM开发工具包 (JDK)一部分的JavaTM线程。
分布式共享内存 (DSM) 系统 - DSM系统在松散耦合架构上创建共享内存的抽象,以便在没有硬件支持的情况下实现共享内存编程。它们实现标准库并使用现代操作系统中存在的先进用户级内存管理功能。示例包括Tread Marks系统、Munin、IVY、Shasta、Brazos和Cashmere。
程序注释包 - 这是在具有统一内存访问特性的架构上实现的。程序注释包最著名的示例是OpenMP。OpenMP实现函数式并行性。它主要关注循环的并行化。
共享内存的概念提供了对共享内存系统的低级控制,但它往往很繁琐且容易出错。它更适用于系统编程而不是应用程序编程。
共享内存编程的优点
全局地址空间为用户提供了友好的内存编程方法。
由于内存与CPU的接近性,进程间的数据共享速度快且一致。
无需明确指定进程间的数据通信。
进程通信开销可忽略不计。
它很容易学习。
共享内存编程的缺点
- 它不可移植。
- 管理数据局部性非常困难。
消息传递模型
消息传递是分布式内存系统中最常用的并行编程方法。在这里,程序员必须确定并行性。在这个模型中,所有处理器都有自己的本地内存单元,它们通过通信网络交换数据。
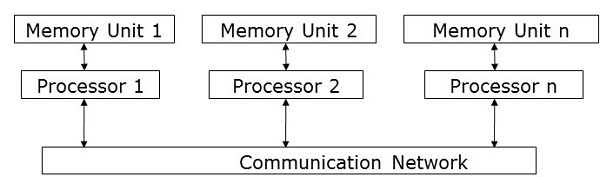
处理器使用消息传递库进行相互通信。除了发送的数据外,消息还包含以下组件:
发送消息的处理器的地址;
发送处理器中数据的内存位置的起始地址;
发送数据的类型;
发送数据的大小;
发送消息的处理器的地址;
接收处理器中数据的内存位置的起始地址。
处理器可以通过以下任何方法相互通信:
- 点对点通信
- 集体通信
- 消息传递接口
点对点通信
点对点通信是最简单的消息传递形式。在这里,消息可以通过以下任何传输模式从发送处理器发送到接收处理器:
同步模式 - 只有在收到确认其先前消息已送达后,才发送下一条消息,以保持消息的顺序。
异步模式 - 要发送下一条消息,不需要收到先前消息送达的确认。
集体通信
集体通信涉及多个处理器进行消息传递。以下模式允许集体通信:
屏障 - 如果通信中包含的所有处理器都运行特定块(称为屏障块)进行消息传递,则屏障模式是可能的。
广播 - 广播有两种类型:
一对多 - 在这里,一个处理器使用单个操作将相同的消息发送到所有其他处理器。
全对全 - 在这里,所有处理器都向所有其他处理器发送消息。
广播的消息可能有三种类型:
个性化 - 向所有其他目标处理器发送唯一的消息。
非个性化 - 所有目标处理器都收到相同的消息。
归约 - 在归约广播中,组中的一个处理器从组中的所有其他处理器收集所有消息,并将它们组合成一条单一消息,组中的所有其他处理器都可以访问该消息。
消息传递的优点
- 提供对并行性的低级控制;
- 它是可移植的;
- 错误更少;
- 并行同步和数据分布的开销较少。
消息传递的缺点
与并行共享内存代码相比,消息传递代码通常需要更多的软件开销。
消息传递库
有很多消息传递库。在这里,我们将讨论两个最常用的消息传递库:
- 消息传递接口 (MPI)
- 并行虚拟机 (PVM)
消息传递接口 (MPI)
这是一个通用标准,用于在分布式内存系统中的所有并发进程之间提供通信。大多数常用的并行计算平台至少提供了一种消息传递接口的实现。它已被实现为称为库的预定义函数的集合,并且可以从C、C++、Fortran等语言调用。与其他消息传递库相比,MPI速度快且可移植。
消息传递接口的优点
仅在共享内存架构或分布式内存架构上运行;
每个处理器都有自己的局部变量;
与大型共享内存计算机相比,分布式内存计算机成本更低。
消息传递接口的缺点
- 并行算法需要更多编程更改;
- 有时难以调试;并且
- 在节点之间的通信网络中性能不佳。
并行虚拟机 (PVM)
PVM是一个可移植的消息传递系统,旨在连接独立的异构主机机器以形成单个虚拟机。它是一个易于管理的并行计算资源。像超导性研究、分子动力学模拟和矩阵算法这样的大型计算问题可以通过使用许多计算机的内存和总功率来更经济有效地解决。它管理网络中不兼容计算机架构的所有消息路由、数据转换和任务调度。
PVM 的特点
- 非常易于安装和配置;
- 多个用户可以同时使用PVM;
- 一个用户可以执行多个应用程序;
- 它是一个小包;
- 支持C、C++、Fortran;
- 对于给定的PVM程序运行,用户可以选择机器组;
- 它是一个消息传递模型,
- 基于进程的计算;
- 支持异构架构。
数据并行编程
数据并行编程模型的主要重点是同时对数据集执行操作。数据集被组织成某种结构,例如数组、超立方体等。处理器对相同的数据结构进行集体操作。每个任务都在相同数据结构的不同分区上执行。
它是有限制的,因为并非所有算法都可以用数据并行性来指定。这就是数据并行性不是通用的原因。
数据并行语言有助于指定数据分解和映射到处理器。它还包括数据分布语句,允许程序员控制数据——例如,哪些数据将放在哪个处理器上——以减少处理器内部的通信量。