
 数据结构
数据结构 网络
网络 关系数据库管理系统
关系数据库管理系统 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 编程
C 编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHPPython - 如何选择 Pandas DataFrame 的一个子集
假设 Microsoft Excel 中打开的 CSV 文件的内容如下 −
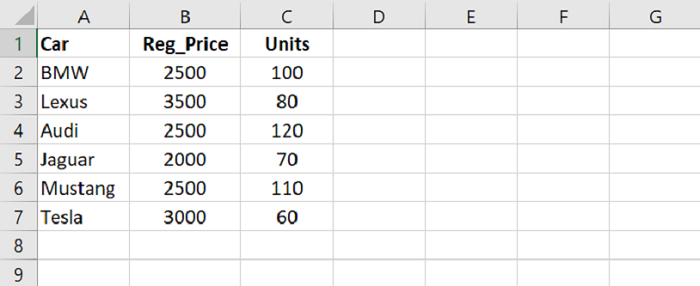
首先,将 CSV 文件中的数据加载到 Pandas DataFrame 中 −
dataFrame = pd.read_csv("C:\Users\amit_\Desktop\SalesData.csv")要选择一个子集,使用方括号。在括号中提及列并从整个数据集中提取单列 −
dataFrame['Car']
示例
以下是代码 −
import pandas as pd
# Load data from a CSV file into a Pandas DataFrame
dataFrame = pd.read_csv("C:\Users\amit_\Desktop\SalesData.csv")
print("\nReading the CSV file...\n",dataFrame)
# displaying only a single column
res1 = dataFrame['Car'];
# displaying only a subset
print("\nDisplaying only one column Car : \n",res1)
# displaying two columns
res2 = dataFrame[['Car','Units']];
# displaying another subset
print("\nDisplaying two columns : \n",res2)
输出
这将产生以下输出 −
Reading the CSV file... Car Reg_Price Units 0 BMW 2500 100 1 Lexus 3500 80 2 Audi 2500 120 3 Jaguar 2000 70 4 Mustang 2500 110 Displaying only one column Car : 0 BMW 1 Lexus 2 Audi 3 Jaguar 4 Mustang Name: Car, dtype: object Displaying two columns : Car Units 0 BMW 100 1 Lexus 80 2 Audi 120 3 Jaguar 70 4 Mustang 110

更新于: 29-Sep-2021
324 次浏览

广告