
- SAP HANA 教程
- SAP HANA - 首页
- SAP HANA 简介
- SAP HANA - 概述
- 内存计算引擎 (In-Memory Computing Engine)
- SAP HANA - Studio
- Studio 管理视图
- SAP HANA - 系统监控
- SAP HANA - 信息建模器
- SAP HANA - 核心架构
- SAP HANA 建模
- SAP HANA - 建模
- SAP HANA - 数据仓库
- SAP HANA - 表
- SAP HANA - 包
- SAP HANA - 属性视图
- SAP HANA - 分析视图
- SAP HANA - 计算视图
- SAP HANA - 分析权限
- SAP HANA - 信息组合器
- SAP HANA - 导出和导入
- SAP HANA 安全性
- SAP HANA - 安全性概述
- 用户管理与维护
- SAP HANA - 身份验证
- SAP HANA - 授权方法
- SAP HANA - 许可证管理
- SAP HANA - 审计
- SAP HANA 数据复制
- SAP HANA - 数据复制概述
- SAP HANA - 基于 ETL 的复制
- SAP HANA - 基于日志的复制
- SAP HANA - DXC 方法
- SAP HANA - CTL 方法
- SAP HANA - MDX 提供程序
- SAP HANA SQL
- SAP HANA - SQL 概述
- SAP HANA - 数据类型
- SAP HANA - SQL 运算符
- SAP HANA - SQL 函数
- SAP HANA - SQL 表达式
- SAP HANA - SQL 存储过程
- SAP HANA - SQL 序列
- SAP HANA - SQL 触发器
- SAP HANA - SQL 同义词
- SAP HANA - SQL 执行计划
- SAP HANA - SQL 数据分析
- SAP HANA - SQL 脚本
- SAP HANA 有用资源
- SAP HANA - 问答
- SAP HANA 快速指南
- SAP HANA - 有用资源
- SAP HANA - 讨论
SAP HANA 快速指南
SAP HANA - 概述
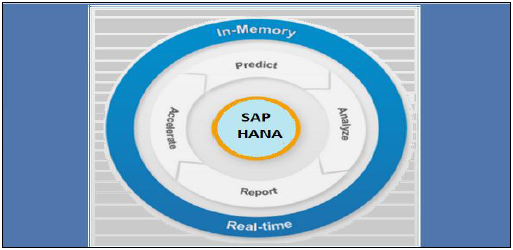
SAP HANA 集成了 HANA 数据库、数据建模、HANA 管理和数据供应在一个单一的套件中。在 SAP HANA 中,HANA 代表高性能分析设备 (High-Performance Analytic Appliance)。
据前 SAP 高管 Vishal Sikka 博士介绍,HANA 代表 Hasso 的新架构 (Hasso’s New Architecture)。HANA 在 2011 年中期引起了人们的兴趣,此后,许多财富 500 强公司开始将其视为满足业务仓库需求的一种选择。
SAP HANA 的特性
SAP HANA 的主要特性如下:
SAP HANA 结合了软件和硬件创新,可以处理海量实时数据。
基于分布式系统环境中的多核架构。
基于数据库中行和列类型的数据存储。
广泛应用于内存计算引擎 (IMCE) 中,用于处理和分析海量实时数据。
它降低了拥有成本,提高了应用程序性能,使以前不可能在实时环境中运行的新应用程序得以运行。
它是用 C++ 编写的,仅支持并在 Suse Linux Enterprise Server 11 SP1/2 操作系统上运行。
SAP HANA 的需求
如今,大多数成功的公司都能快速响应市场变化和新机遇。关键在于分析师和管理人员有效且高效地利用数据和信息。
HANA 克服了以下限制:
由于“数据量”的增加,公司难以提供对实时数据进行分析和业务使用的访问。
对于 IT 公司来说,存储和维护大量数据会产生高昂的维护成本。
由于实时数据不可用,分析和处理结果会延迟。
SAP HANA 供应商
SAP 已与 IBM、Dell、Cisco 等领先的 IT 硬件供应商建立了合作伙伴关系,并将 SAP 许可服务和技术与之结合,以销售 SAP HANA 平台。
共有 11 家供应商生产 HANA 设备,并提供 HANA 系统安装和配置的现场支持。
主要的几家供应商包括:
- IBM
- Dell
- HP
- Cisco
- 富士通
- 联想(中国)
- NEC
- 华为
根据 SAP 提供的统计数据,IBM 是 SAP HANA 硬件设备的主要供应商之一,市场份额为 50-52%,但根据 HANA 客户进行的另一项市场调查,IBM 的市场占有率高达 70%。
SAP HANA 安装
HANA 硬件供应商提供预配置的硬件、操作系统和 SAP 软件产品设备。
供应商通过 HANA 组件的现场设置和配置完成安装。现场访问包括在数据中心部署 HANA 系统、连接到组织网络、SAP 系统 ID 适配、来自 Solution Manager 的更新、SAP 路由器连接、SSL 启用和其他系统配置。
客户开始连接数据源系统和 BI 客户端。HANA Studio 安装在本地系统上完成,并添加 HANA 系统以执行数据建模和管理。
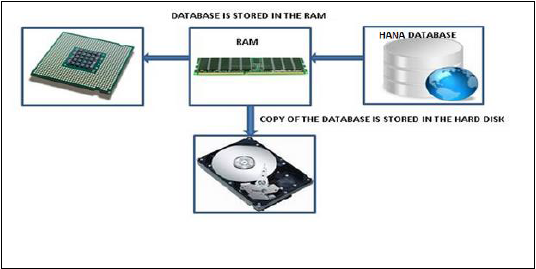
SAP HANA - 内存计算引擎 (In-Memory Computing Engine)
内存数据库意味着来自源系统的所有数据都存储在 RAM 内存中。在传统的数据库系统中,所有数据都存储在硬盘中。SAP HANA 内存数据库无需花费时间将数据从硬盘加载到 RAM。它为多核 CPU 提供更快的数据访问,用于信息处理和分析。
内存数据库的特性
SAP HANA 内存数据库的主要特性:
SAP HANA 是混合内存数据库。
它结合了基于行、基于列和基于对象的技术。
它使用多核 CPU 架构进行并行处理。
传统数据库读取内存数据需要 5 毫秒。SAP HANA 内存数据库读取数据需要 5 纳秒。
这意味着 HANA 数据库中的内存读取速度比传统数据库硬盘内存读取速度快 100 万倍。
分析师希望立即实时查看当前数据,而不希望等到数据加载到 SAP BW 系统后再查看。SAP HANA 内存处理允许使用各种数据供应技术加载实时数据。
内存数据库的优势
HANA 数据库利用内存处理来提供最快的数据检索速度,这对于难以处理大规模在线交易或及时预测和规划的公司来说非常诱人。
基于磁盘的存储仍然是企业标准,RAM 的价格一直在稳步下降,因此内存密集型架构最终将取代缓慢的机械旋转磁盘,并将降低数据存储成本。
基于列的内存存储可将数据压缩高达 11 倍,从而减少大量数据的存储空间。
RAM 存储系统提供的速度优势通过在分布式环境中使用多核 CPU、每个节点的多个 CPU 和每个服务器的多个节点得到进一步增强。
SAP HANA - Studio
SAP HANA Studio 是一个基于 Eclipse 的工具。SAP HANA Studio 既是 HANA 系统的中央开发环境,也是主要的管理工具。其他功能包括:
它是一个客户端工具,可用于访问本地或远程 HANA 系统。
它为 HANA 管理、HANA 信息建模和 HANA 数据库中的数据供应提供了一个环境。
SAP HANA Studio 可在以下平台上使用:
Microsoft Windows 32 位和 64 位版本:Windows XP、Windows Vista、Windows 7
SUSE Linux Enterprise Server SLES11:x86 64 位
Mac OS,HANA Studio 客户端不可用
根据 HANA Studio 的安装情况,并非所有功能都可用。在 Studio 安装时,请根据角色指定要安装的功能。要使用最新版本的 HANA Studio,可以使用软件生命周期管理器更新客户端。
SAP HANA Studio 透视图/功能
SAP HANA Studio 提供了用于处理以下 HANA 功能的透视图。您可以从以下选项中选择 HANA Studio 中的透视图:
Sap Hana Studio → 窗口 → 打开透视图 → 其他
SAP HANA Studio 管理
用于各种管理任务的工具集,不包括可传输的设计时存储库对象。还包括诸如跟踪、目录浏览器和 SQL 控制台之类的常规故障排除工具。
SAP HANA Studio 数据库开发
它提供内容开发工具集。它尤其解决了 DataMarts 和 ABAP on SAP HANA 场景,其中不包括 SAP HANA 原生应用程序开发 (XS)。
SAP HANA Studio 应用程序开发
SAP HANA 系统包含一个小型 Web 服务器,可用于托管小型应用程序。它提供用于开发 SAP HANA 原生应用程序的工具集,例如用 Java 和 HTML 编写的应用程序代码。
默认情况下,所有功能都已安装。
SAP HANA - Studio 管理视图
要执行 HANA 数据库管理和监控功能,可以使用 SAP HANA 管理控制台透视图。
管理员编辑器可以通过多种方式访问:
从系统视图工具栏 - 选择“打开管理”默认按钮
在系统视图中 - 双击 HANA 系统或打开透视图
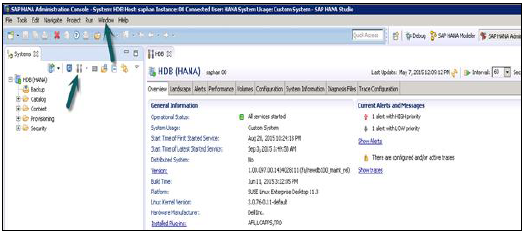
HANA Studio:管理员编辑器
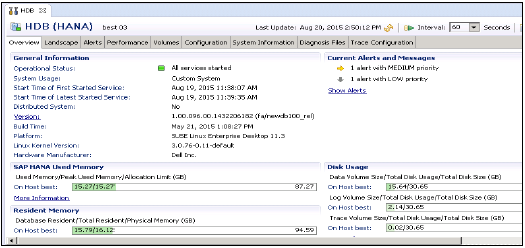
在管理视图中:HANA Studio 提供多个选项卡来检查 HANA 系统的配置和运行状况。概述选项卡显示常规信息,例如操作状态、第一次和最后一次启动服务的启动时间、版本、构建日期和时间、平台、硬件制造商等。
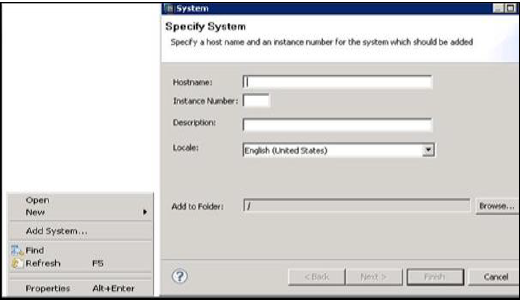
将 HANA 系统添加到 Studio
可以将一个或多个系统添加到 HANA Studio 以进行管理和信息建模。要添加新的 HANA 系统,需要主机名、实例号以及数据库用户名和密码。
- 应打开端口 3615 以连接到数据库
- 端口 31015 实例号 10
- 端口 30015 实例号 00
- 还应打开 SSh 端口
将系统添加到 Hana Studio
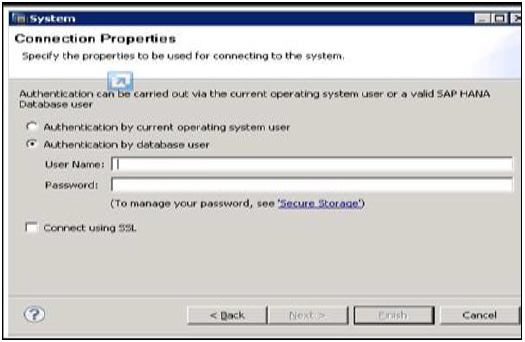
要将系统添加到 HANA Studio,请按照以下步骤操作。
右键单击导航器空间,然后单击“添加系统”。输入 HANA 系统详细信息,即主机名和实例号,然后单击下一步。
输入数据库用户名和密码以连接到 SAP HANA 数据库。单击下一步,然后单击完成。
单击完成后,HANA 系统将添加到系统视图中,用于管理和建模。每个 HANA 系统都有两个主要的子节点,即目录和内容。
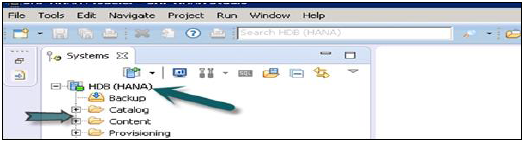
目录和内容
目录
它包含所有可用的模式,即所有数据结构、表和数据、列视图、可在内容选项卡中使用的过程。
内容
内容选项卡包含设计时存储库,其中包含使用 HANA Modeler 创建的所有数据模型的信息。这些模型按包组织。内容节点提供对相同物理数据的不同视图。
SAP HANA - 系统监控
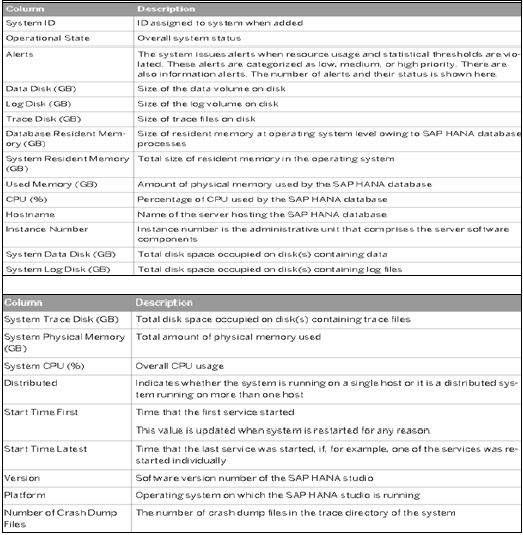
HANA Studio 中的系统监控器提供所有 HANA 系统的概览。从系统监控器中,您可以深入了解管理编辑器中单个系统的详细信息。它显示有关数据磁盘、日志磁盘、跟踪磁盘以及资源使用情况(按优先级排序)的警报。
系统监控器中提供以下信息:
SAP HANA - 信息建模器
SAP HANA 信息建模器;也称为 HANA 数据建模器是 HANA 系统的核心。它能够在数据库表之上创建建模视图,并实现业务逻辑以创建有意义的分析报告。
信息建模器的功能
提供存储在 HANA 数据库物理表中的事务数据的多种视图,用于分析和业务逻辑目的。
信息建模器仅适用于基于列的存储表。
信息建模视图由基于 Java 或 HTML 的应用程序或 SAP 工具(如 SAP Lumira 或 Analysis Office)用于报告目的。
也可以使用第三方工具(如 MS Excel)连接到 HANA 并创建报表。
SAP HANA 建模视图充分利用了 SAP HANA 的强大功能。
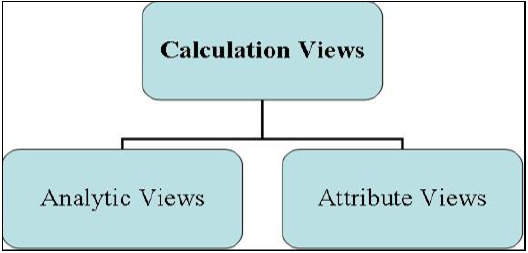
信息视图有三种类型,定义如下:
- 属性视图
- 分析视图
- 计算视图
行存储与列存储
SAP HANA 建模视图只能在基于列的表之上创建。将数据存储在列表中并非什么新鲜事。早些时候,人们认为将数据存储在基于列的结构中会占用更多内存,并且性能未经优化。
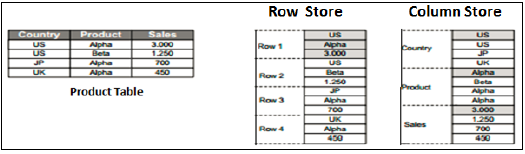
随着 SAP HANA 的发展,HANA 在信息视图中使用了基于列的数据存储,并展示了列表相对于行表的真正优势。
列存储
在列存储表中,数据垂直存储。因此,类似的数据类型组合在一起,如上例所示。它借助内存计算引擎提供更快的内存读写操作。
在传统的数据库中,数据以基于行的结构(即水平)存储。SAP HANA 以基于行和基于列的结构存储数据。这在 HANA 数据库中提供了性能优化、灵活性和数据压缩。
在基于列的表中存储数据具有以下优点:
数据压缩
与传统的基于行的存储相比,表读写访问速度更快
灵活性和并行处理
以更高的速度执行聚合和计算
有多种方法和算法可以将数据存储在基于列的结构中——字典压缩、游程长度压缩等等。
在字典压缩中,单元格以数字的形式存储在表中,数字单元格始终比字符具有更好的性能。
在游程长度压缩中,它以数字格式保存单元格值的乘数,乘数显示表中重复的值。
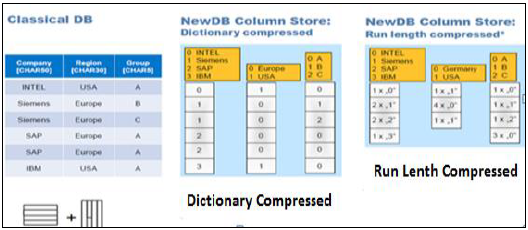
功能差异 - 行存储与列存储
如果 SQL 语句需要执行聚合函数和计算,则始终建议使用基于列的存储。在运行 Sum、Count、Max、Min 等聚合函数时,基于列的表始终表现更好。
如果输出必须返回完整行,则首选基于行存储。以下示例使理解变得更容易。
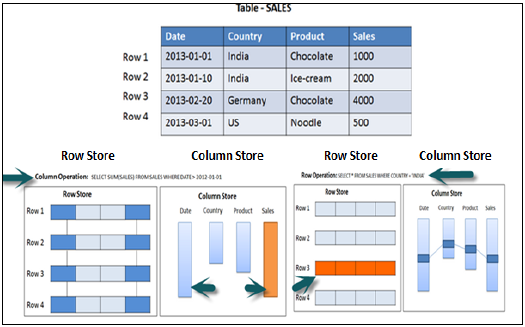
在上面的示例中,在使用 Where 子句运行 sales 列中的聚合函数 (Sum) 时,它只使用 Date 和 Sales 列运行 SQL 查询,因此,如果它是基于列的存储表,则它将是性能优化的,速度更快,因为只需要来自两列的数据。
在运行简单的 Select 查询时,必须在输出中打印完整行,因此在这种情况下建议将表存储为基于行的表。
信息建模视图
属性视图
属性是数据库表中不可度量的元素。它们表示主数据,类似于 BW 的特征。属性视图是数据库中的维度,或者用于在建模中连接维度或其他属性视图。
重要功能包括:
- 属性视图用于分析视图和计算视图。
- 属性视图表示主数据。
- 用于过滤分析视图和计算视图中维度表的大小。
分析视图
分析视图利用 SAP HANA 的强大功能对数据库中的表执行计算和聚合函数。它至少有一个包含度量和维度表主键的事实表,并且周围的维度表包含主数据。
重要功能包括:
分析视图旨在执行星型模式查询。
分析视图至少包含一个事实表和多个包含主数据的维度表,并执行计算和聚合。
它们类似于 SAP BW 中的 InfoCube 和 Info 对象。
分析视图可以创建在属性视图和事实表之上,并执行计算,例如销售数量、总价格等。
计算视图
计算视图用于在分析视图和属性视图之上执行复杂的计算,这些计算是分析视图无法实现的。计算视图是基本列表、属性视图和分析视图的组合,用于提供业务逻辑。
重要功能包括:
计算视图可以使用 HANA 建模功能以图形方式定义,也可以使用 SQL 编写脚本。
它的创建是为了执行复杂的计算,而这些计算是 SAP HANA 建模器的其他视图(属性视图和分析视图)无法实现的。
借助内置函数(如 Projects、Union、Join、Rank),计算视图会使用一个或多个属性视图和分析视图。
SAP HANA - 核心架构
SAP HANA 最初是用 Java 和 C++ 开发的,并且设计为仅运行 Suse Linux Enterprise Server 11 操作系统。SAP HANA 系统包含多个组件,这些组件负责强调 HANA 系统的计算能力。
SAP HANA 系统最重要的组件是索引服务器,它包含 SQL/MDX 处理器,用于处理数据库的查询语句。
HANA 系统包含名称服务器、预处理器服务器、统计服务器和 XS 引擎,用于通信和托管小型 Web 应用程序以及各种其他组件。
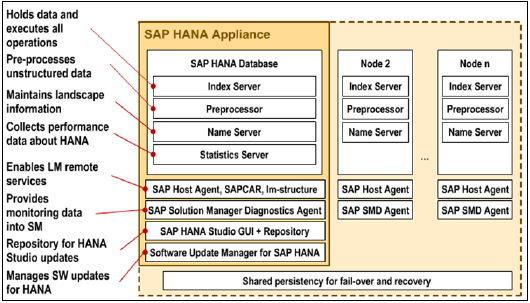
索引服务器
索引服务器是 SAP HANA 数据库系统的核心。它包含实际数据和处理该数据的引擎。当为 SAP HANA 系统触发 SQL 或 MDX 时,索引服务器会处理所有这些请求并对其进行处理。所有 HANA 处理都在索引服务器中进行。
索引服务器包含数据引擎,用于处理进入 HANA 数据库系统的所有 SQL/MDX 语句。它还具有持久性层,负责 HANA 系统的持久性,并确保在系统故障或重新启动时将 HANA 系统恢复到最新状态。
索引服务器还具有会话和事务管理器,用于管理事务并跟踪所有正在运行和已关闭的事务。
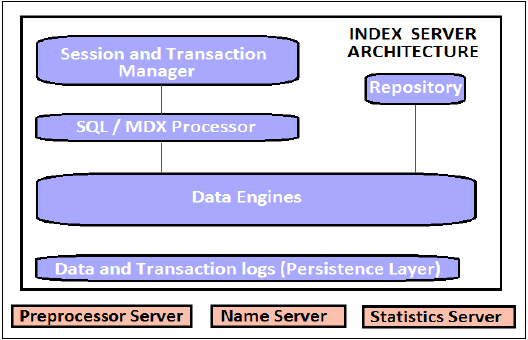
索引服务器 - 架构
SQL/MDX 处理器
它负责使用负责运行查询的数据引擎处理 SQL/MDX 事务。它分割所有查询请求并将它们定向到正确的引擎以进行性能优化。
它还确保所有 SQL/MDX 请求都已授权,并提供错误处理以有效处理这些语句。它包含用于查询执行的多个引擎和处理器:
MDX(多维表达式)是 OLAP 系统的查询语言,就像 SQL 用于关系数据库一样。MDX 引擎负责处理查询并操作存储在 OLAP 多维数据集中多维数据。
规划引擎负责在 SAP HANA 数据库中运行规划操作。
计算引擎将数据转换为计算模型,以创建逻辑执行计划以支持语句的并行处理。
存储过程处理器执行过程调用以进行优化的处理;它将 OLAP 多维数据集转换为 HANA 优化的多维数据集。
事务和会话管理
它负责协调所有数据库事务并跟踪所有正在运行和已关闭的事务。
当事务执行或失败时,事务管理器会通知相关数据引擎采取必要的措施。
会话管理组件负责使用预定义的会话参数初始化和管理 SAP HANA 系统的会话和连接。
持久性层
它负责 HANA 系统中事务的持久性和原子性。持久性层为 HANA 数据库提供内置的灾难恢复系统。
它确保数据库恢复到最新状态,并确保在系统故障或重新启动时完成或撤消所有事务。
它还负责管理数据和事务日志,还包含 HANA 系统的数据备份、日志备份和配置备份。备份作为保存点存储在数据卷中,通过保存点协调器,通常设置为每 5-10 分钟保存一次备份。
预处理器服务器
SAP HANA 系统中的预处理器服务器用于文本数据分析。
当使用文本搜索功能时,索引服务器使用预处理器服务器分析文本数据并从文本数据中提取信息。
名称服务器
名称服务器包含 HANA 系统的系统环境信息。在分布式环境中,有多个节点,每个节点有多个 CPU,名称服务器保存 HANA 系统的拓扑结构,并包含有关所有正在运行的组件的信息,这些信息分布在所有组件上。
这里记录了 SAP HANA 系统的拓扑结构。
它减少了重新索引的时间,因为它保存了分布式环境中哪些数据位于哪个服务器上。
统计服务器
此服务器检查并分析 HANA 系统中所有组件的运行状况。统计服务器负责收集与系统资源、资源分配和使用以及 HANA 系统整体性能相关的数据。
它还提供与系统性能相关的历史数据,用于分析目的,以检查和修复 HANA 系统中的性能相关问题。
XS 引擎
XS 引擎帮助外部基于 Java 和 HTML 的应用程序通过 XS 客户端访问 HANA 系统。由于 SAP HANA 系统包含一个 Web 服务器,该服务器可用于托管小型基于 JAVA/HTML 的应用程序。
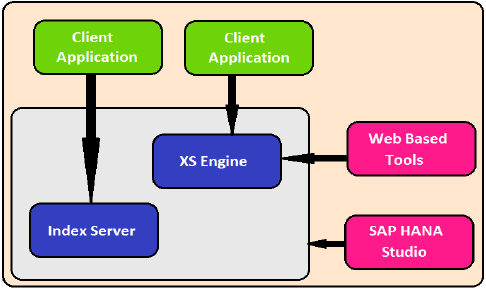
XS 引擎将存储在数据库中的持久性模型转换为通过 HTTP/HTTPS 公开的客户端的消费模型。
SAP 主机代理
应在属于 SAP HANA 系统环境的所有计算机上安装 SAP 主机代理。软件更新管理器 SUM 使用 SAP 主机代理在分布式环境中将自动更新安装到 HANA 系统的所有组件。
LM 结构
SAP HANA 系统的 LM 结构包含有关当前安装详细信息的信息。软件更新管理器使用此信息在 HANA 系统组件上安装自动更新。
SAP Solution Manager (SAP SOLMAN) 诊断代理
此诊断代理向 SAP Solution Manager 提供所有数据以监控 SAP HANA 系统。此代理提供有关 HANA 数据库的所有信息,包括数据库当前状态和常规信息。
当 SAP SOLMAN 与 SAP HANA 系统集成时,它提供 HANA 系统的配置详细信息。
SAP HANA Studio 资源库
SAP HANA Studio 仓库帮助 HANA 开发人员将当前版本的 HANA Studio 更新到最新版本。Studio 仓库保存执行此更新的代码。
SAP HANA 软件更新管理器
SAP Market Place 用于安装 SAP 系统的更新。HANA 系统的软件更新管理器有助于从 SAP Market Place 更新 HANA 系统。
它用于软件下载、客户消息、SAP Notes 和请求 HANA 系统的许可证密钥。它还用于将 HANA Studio 分发到最终用户的系统。
SAP HANA - 建模
SAP HANA Modeler 选项用于在 HANA 数据库的模式 → 表之上创建信息视图。这些视图由基于 JAVA/HTML 的应用程序或 SAP 应用程序(如 SAP Lumira、Office Analysis)或第三方软件(如 MS Excel)用于报告目的,以满足业务逻辑并执行分析和信息提取。
HANA 建模是在 HANA Studio 中“模式”下的“目录”选项卡中提供的表之上完成的,所有视图都保存在“包”下的“内容”表中。
您可以在 HANA Studio 的“内容”选项卡下,右键单击“内容”并选择“新建”来创建新的包。
在一个包内创建的所有建模视图都位于 HANA Studio 中的同一个包下,并按视图类型进行分类。
每个视图对于维度表和事实表都有不同的结构。维度表定义了主数据,事实表包含维度表的主键和度量,例如销售单位数量、平均延迟时间、总价等。
事实表和维度表
事实表包含维度表的主键和度量。它们在 HANA 视图中与维度表连接以满足业务逻辑。
度量示例 - 销售单位数量、总价、平均延迟时间等。
维度表包含主数据,并与一个或多个事实表连接以实现某些业务逻辑。维度表用于创建具有事实表的模式,并且可以被规范化。
维度表示例 - 客户、产品等。
假设一家公司向客户销售产品。每次销售都是公司内发生的事实,事实表用于记录这些事实。
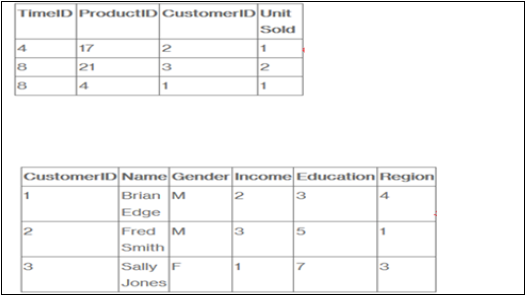
例如,事实表中的第 3 行记录了客户 1(Brian)在第 4 天购买了一件商品的事实。在一个完整的示例中,我们还将拥有产品表和时间表,以便我们知道她购买了什么以及确切的时间。
事实表列出了我们公司中发生的事情(或至少是我们想要分析的事件——销售单位数量、利润率和销售收入)。维度表列出了我们想要据此分析数据的因素(客户、时间和产品)。
SAP HANA - 数据仓库中的模式
模式是对数据仓库中表的逻辑描述。模式是通过连接多个事实表和维度表来满足某些业务逻辑而创建的。
数据库使用关系模型来存储数据。但是,数据仓库使用连接维度表和事实表以满足业务逻辑的模式。数据仓库中使用三种类型的模式:
- 星型模式
- 雪花模式
- 星系模式
星型模式
在星型模式中,每个维度都连接到一个事实表。每个维度仅由一个维度表示,并且不会进一步规范化。
维度表包含用于分析数据的属性集。
示例 - 在下面的示例中,我们有一个事实表 FactSales,它包含所有维度表的主键以及度量 units_sold 和 dollars_sold 用于分析。
我们有四个维度表:DimTime、DimItem、DimBranch、DimLocation。
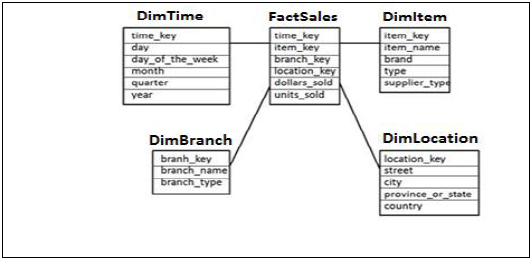
每个维度表都连接到事实表,因为事实表包含每个维度表的主键,用于连接两个表。
事实表中的事实/度量与维度表中的属性一起用于分析目的。
雪花模式
在雪花模式中,某些维度表被进一步规范化,并且维度表连接到单个事实表。规范化用于组织数据库的属性和表,以最大限度地减少数据冗余。
规范化包括将表分解成冗余较少的较小表,而不会丢失任何信息,并且较小表连接到维度表。
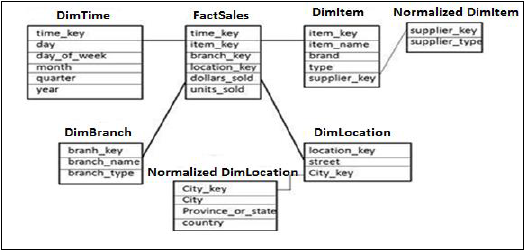
在上面的示例中,DimItem 和 DimLocation 维度表在不丢失任何信息的情况下被规范化。这称为雪花模式,其中维度表被进一步规范化为较小表。
星系模式
在星系模式中,存在多个事实表和维度表。每个事实表存储一些维度表的主键以及度量/事实以进行分析。
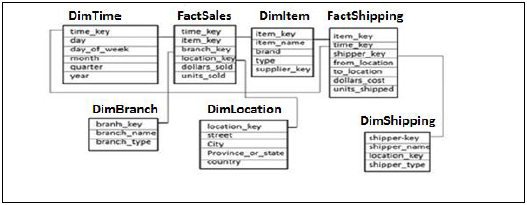
在上面的示例中,有两个事实表 FactSales、FactShipping 和多个连接到事实表的维度表。每个事实表都包含连接的维度表的主键以及度量/事实以执行分析。
SAP HANA - 表
可以从 HANA Studio 中“模式”下的“目录”选项卡访问 HANA 数据库中的表。可以使用以下两种方法创建新表:
- 使用 SQL 编辑器
- 使用 GUI 选项
HANA Studio 中的 SQL 编辑器
可以通过选择要使用系统视图 SQL 编辑器选项创建新表的模式名称,或右键单击模式名称(如下所示)来打开 SQL 控制台:
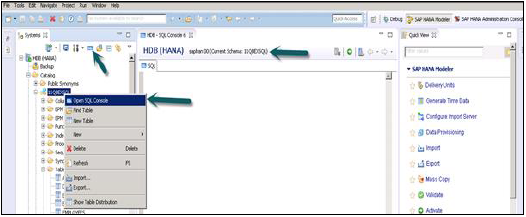
打开 SQL 编辑器后,可以从 SQL 编辑器顶部显示的名称确认模式名称。可以使用 SQL Create Table 语句创建新表:
Create column Table Test1 ( ID INTEGER, NAME VARCHAR(10), PRIMARY KEY (ID) );
在此 SQL 语句中,我们创建了一个列表“Test1”,定义了表的数据库类型和主键。
编写 Create table SQL 查询后,单击 SQL 编辑器右侧顶部的“执行”选项。语句执行后,我们将收到如下快照所示的确认消息:
语句“Create column Table Test1 (ID INTEGER,NAME VARCHAR(10), PRIMARY KEY (ID))”
已在 13 毫秒 761 微秒内成功执行(服务器处理时间:12 毫秒 979 微秒) - 受影响的行数:0
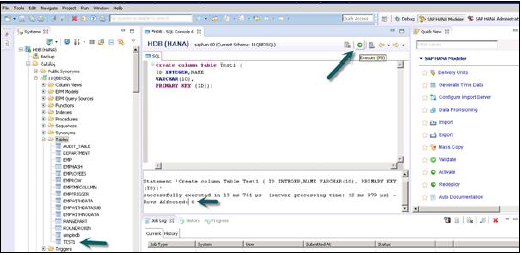
执行语句还说明了执行语句所花费的时间。语句成功执行后,右键单击系统视图中模式名称下的“表”选项卡并刷新。新表将反映在模式名称下的表列表中。
Insert 语句用于使用 SQL 编辑器将数据输入表中。
Insert into TEST1 Values (1,'ABCD') Insert into TEST1 Values (2,'EFGH');
单击“执行”。
您可以右键单击表名并使用“打开数据定义”查看表的数据库类型。使用“打开数据预览/打开内容”查看表内容。
使用 GUI 选项创建表
在 HANA 数据库中创建表的另一种方法是使用 HANA Studio 中的 GUI 选项。
右键单击模式下的“表”选项卡 → 选择“新建表”选项,如下面的快照所示。
单击“新建表”后,将打开一个窗口以输入表名,从下拉列表中选择模式名称,从下拉列表中定义表类型:列存储或行存储。
定义如下所示的数据库类型。可以通过单击“+”号添加列,可以通过单击列名前主键单元格选择主键,“非空”默认情况下处于活动状态。
添加列后,单击“执行”。
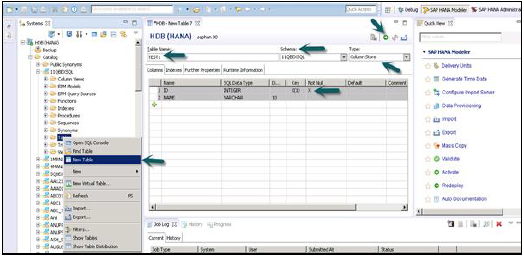
执行 (F8) 后,右键单击“表”选项卡 → 刷新。新表将反映在所选模式下的表列表中。下面的“插入”选项可用于将数据插入表中。“选择”语句用于查看表的内容。
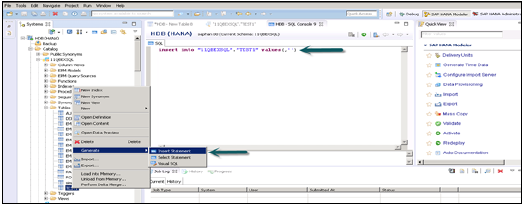
在 HANA Studio 中使用 GUI 将数据插入表中
您可以右键单击表名并使用“打开数据定义”查看表的数据库类型。使用“打开数据预览/打开内容”查看表内容。
要使用一个模式中的表创建视图,我们应该向在 HANA 建模中运行所有视图的默认用户提供对该模式的访问权限。这可以通过转到 SQL 编辑器并运行以下查询来完成:
GRANT SELECT ON SCHEMA "<SCHEMA_NAME>" TO _SYS_REPO WITH GRANT OPTION
SAP HANA - 包
SAP HANA 包显示在 HANA Studio 的“内容”选项卡下。所有 HANA 建模都保存在包中。
您可以通过右键单击“内容”选项卡 → 新建 → 包来创建新包。
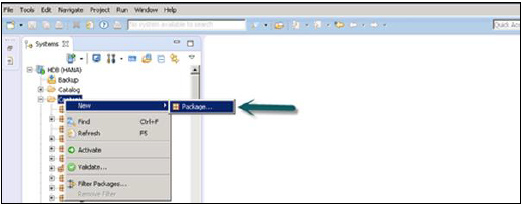
您还可以通过右键单击包名称在包下创建子包。当我们右键单击包时,我们会得到 7 个选项:我们可以在包下创建 HANA 视图属性视图、分析视图和计算视图。
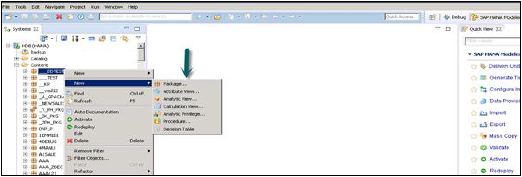
您还可以创建决策表、定义分析权限并在包中创建过程。
右键单击包并单击“新建”时,您还可以创建包中的子包。创建包时,您必须输入包名称和描述。
SAP HANA - 属性视图
SAP HANA 建模中的属性视图是在维度表之上创建的。它们用于连接维度表或其他属性视图。您还可以从其他包中已存在的属性视图复制新的属性视图,但这不允许您更改视图属性。
属性视图的特性
HANA 中的属性视图用于连接维度表或其他属性视图。
属性视图用于分析视图和计算视图中进行分析以传递主数据。
它们类似于 BM 中的特征,并包含主数据。
属性视图用于大型维度表的性能优化,您可以限制属性视图中进一步用于报告和分析目的的属性数量。
属性视图用于建模主数据以提供一些上下文。
如何创建属性视图?
选择要在其下创建属性视图的包名称。右键单击包 → 转到新建 → 属性视图
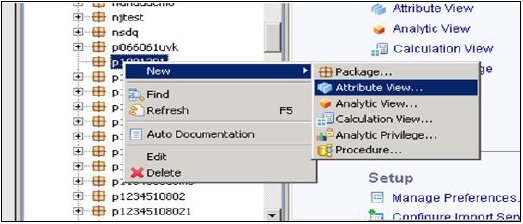
单击“属性视图”后,将打开一个新窗口。输入属性视图名称和描述。从下拉列表中选择视图类型和子类型。在子类型中,有三种类型的属性视图:标准、时间和派生。
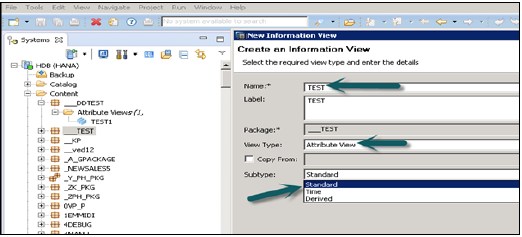
时间子类型属性视图是一种特殊类型的属性视图,它向数据基础添加时间维度。输入属性名称、类型和子类型并单击“完成”后,它将打开三个工作窗格:
具有数据基础和语义层的场景窗格。
详细信息窗格显示添加到数据基础的所有表的属性以及它们之间的连接。
输出面板,我们可以在这里添加来自详细信息面板的属性来过滤报表。
您可以通过点击数据基础旁边的“+”号来向数据基础添加对象。您可以在方案面板中添加多个维度表和属性视图,并使用主键将它们连接起来。
当您点击数据基础中的“添加对象”时,将会出现一个搜索栏,您可以从中将维度表和属性视图添加到方案面板。一旦表或属性视图添加到数据基础,就可以在详细信息面板中使用主键将它们连接起来,如下所示。
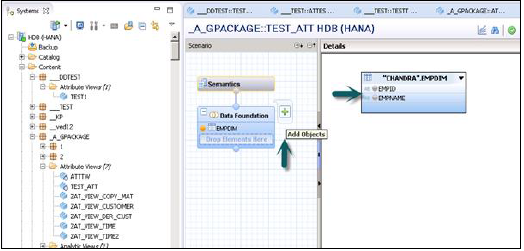
连接完成后,在详细信息面板中选择多个属性,右键单击并选择“添加到输出”。所有列都将添加到输出面板。现在点击“激活”选项,您将在作业日志中收到确认消息。
现在您可以右键单击属性视图并进行数据预览。
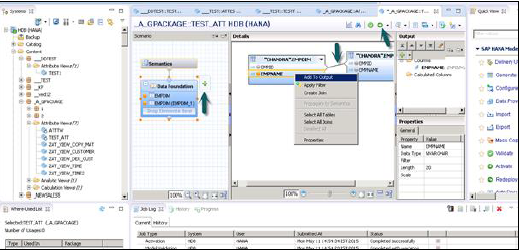
注意 - 当视图未激活时,上面会有菱形标记。但是,一旦您激活它,菱形标记就会消失,这确认视图已成功激活。
单击“数据预览”后,它将显示已添加到输出面板的“可用对象”下的所有属性。
这些对象可以通过右键单击并添加或通过拖动对象添加到标签和值轴,如下所示:
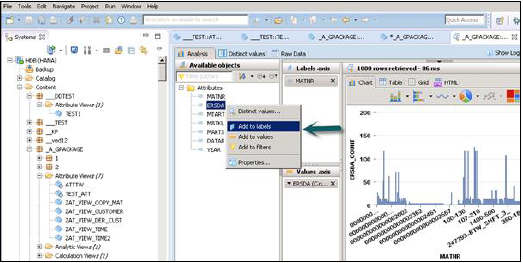
SAP HANA - 分析视图
分析视图采用星型模式,其中我们将一个事实表连接到多个维度表。分析视图利用SAP HANA的强大功能,通过以星型模式连接表并执行星型模式查询来执行复杂的计算和聚合函数。
分析视图的特点
以下是SAP HANA分析视图的属性:
分析视图用于执行复杂的计算和聚合函数,例如Sum、Count、Min、Max等。
分析视图设计用于运行星型模式查询。
每个分析视图都有一个事实表,周围环绕着多个维度表。事实表包含每个维度表的primaryKey和度量。
分析视图类似于SAP BW的信息对象和信息集。
如何创建分析视图?
选择要在其下创建分析视图的包名称。右键单击包→转到新建→分析视图。当您单击分析视图时,将打开一个新窗口。输入视图名称和描述,然后从下拉列表中选择视图类型并单击“完成”。
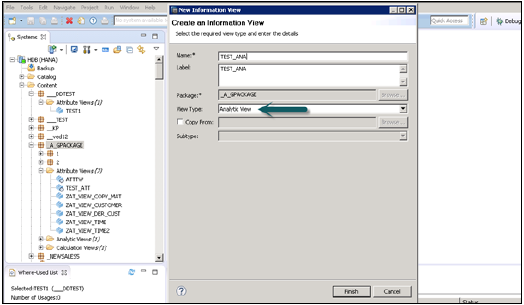
单击“完成”后,您可以看到一个带有数据基础和星型连接选项的分析视图。
单击“数据基础”以添加维度表和事实表。单击“星型连接”以添加属性视图。
使用“+”号将维度表和事实表添加到数据基础。在下面给出的示例中,已添加3个维度表:DIM_CUSTOMER、DIM_PRODUCT、DIM_REGION和1个事实表FCT_SALES到详细信息面板。使用存储在事实表中的主键将维度表连接到事实表。
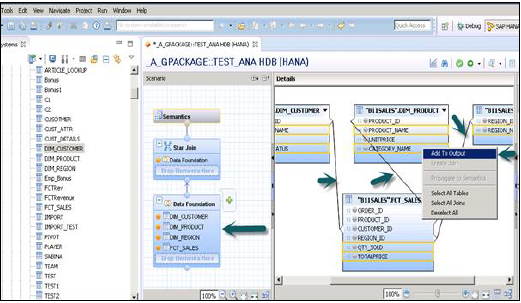
选择要添加到输出面板的维度表和事实表的属性,如上图所示。现在将事实表的数据类型从事实表更改为度量。
单击语义层,选择事实,然后单击如下所示的度量符号以将数据类型更改为度量并激活视图。
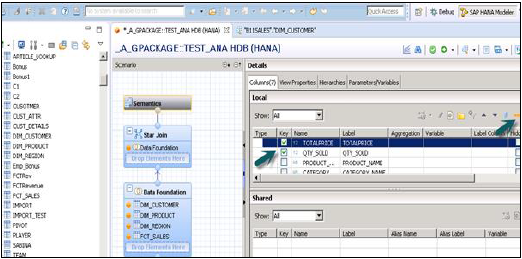
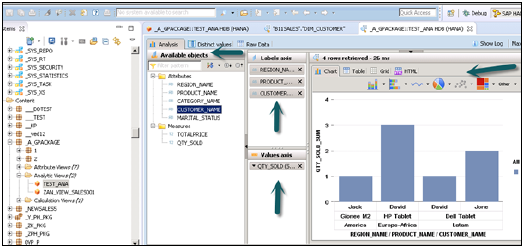
激活视图并单击“数据预览”后,所有属性和度量都将添加到“可用对象”列表中。将属性添加到标签轴,将度量添加到值轴以进行分析。
可以选择不同类型的图表。
SAP HANA - 计算视图
计算视图用于使用其他分析视图、属性视图和其他计算视图以及基本列表。它们用于执行其他类型的视图无法执行的复杂计算。
计算视图的特点
以下是计算视图的一些特点:
计算视图用于使用分析视图、属性视图和其他计算视图。
它们用于执行其他视图无法执行的复杂计算。
创建计算视图有两种方法:SQL编辑器或图形编辑器。
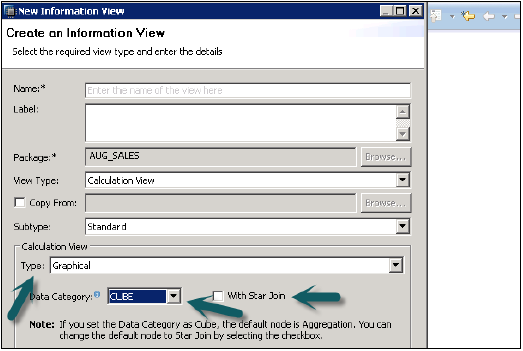
内置的Union、Join、Projection和Aggregation节点。
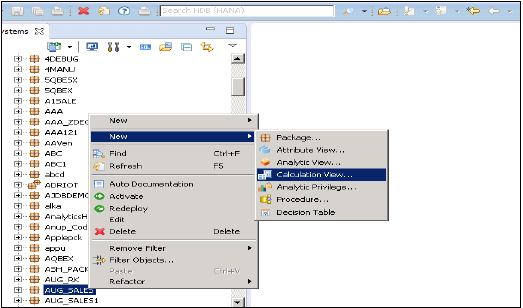
如何创建一个计算视图?
选择要在其下创建计算视图的包名称。右键单击包→转到新建→计算视图。当您单击计算视图时,将打开一个新窗口。
输入视图名称、描述并选择视图类型为计算视图,子类型为标准或时间(这是一种特殊的视图,它添加时间维度)。您可以使用两种类型的计算视图:图形和SQL脚本。
图形计算视图
它具有默认节点,如聚合、投影、连接和联合。它用于使用其他属性视图、分析视图和其他计算视图。
基于SQL脚本的计算视图
它使用基于SQL命令或HANA定义函数的SQL脚本编写。
数据类别
Cube,在此默认节点中为聚合。您可以选择具有Cube维度的星型连接。
Dimension,在此默认节点中为投影。
具有星型连接的计算视图
它不允许在数据基础中添加基本列表、属性视图或分析视图。所有维度表都必须更改为维度计算视图才能在星型连接中使用。所有事实表都可以添加,并且可以使用计算视图中的默认节点。
示例
以下示例显示了如何使用具有星型连接的计算视图:
您有四个表,两个维度表和两个事实表。您需要查找所有员工及其入职日期、员工姓名、员工ID、工资和奖金的列表。
将下面的脚本复制并粘贴到SQL编辑器中并执行。
维度表 - Empdim和Empdate
Create column table Empdim (empId nvarchar(3),Empname nvarchar(100));
Insert into Empdim values('AA1','John');
Insert into Empdim values('BB1','Anand');
Insert into Empdim values('CC1','Jason');
Create column table Empdate (caldate date, CALMONTH nvarchar(4) ,CALYEAR nvarchar(4));
Insert into Empdate values('20100101','04','2010');
Insert into Empdate values('20110101','05','2011');
Insert into Empdate values('20120101','06','2012');
事实表 - Empfact1、Empfact2
Create column table Empfact1 (empId nvarchar(3), Empdate date, Sal integer );
Insert into Empfact1 values('AA1','20100101',5000);
Insert into Empfact1 values('BB1','20110101',10000);
Insert into Empfact1 values('CC1','20120101',12000);
Create column table Empfact2 (empId nvarchar(3), deptName nvarchar(20), Bonus integer );
Insert into Empfact2 values ('AA1','SAP', 2000);
Insert into Empfact2 values ('BB1','Oracle', 2500);
Insert into Empfact2 values ('CC1','JAVA', 1500);
现在我们必须实现具有星型连接的计算视图。首先将两个维度表都更改为维度计算视图。
创建一个具有星型连接的计算视图。在图形面板中,为两个事实表添加2个投影。将两个事实表都添加到两个投影中,并将这些投影的属性添加到输出面板。
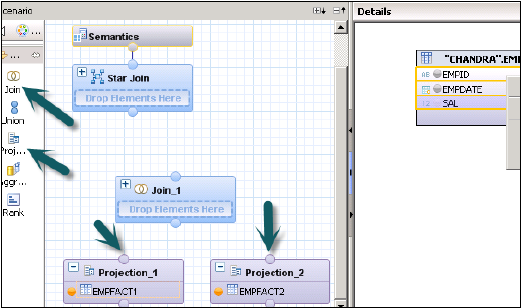
从默认节点添加一个连接,并将两个事实表连接起来。将事实连接的参数添加到输出面板。
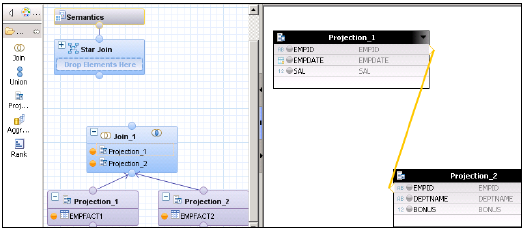
在星型连接中,添加两个维度计算视图,并将事实连接添加到星型连接,如下所示。选择输出面板中的参数并激活视图。
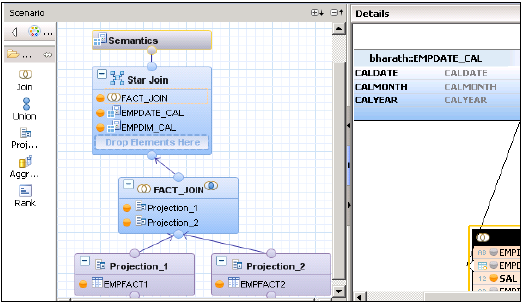
SAP HANA计算视图 - 星型连接
成功激活视图后,右键单击视图名称并单击“数据预览”。将属性和度量添加到值轴和标签轴并进行分析。
使用星型连接的优点
它简化了设计过程。您无需创建分析视图和属性视图,可以直接将事实表用作投影。
星型连接允许3NF。
没有星型连接的计算视图
在两个维度表上创建2个属性视图 - 添加输出并激活这两个视图。
在事实表上创建2个分析视图→在分析视图的数据基础中添加两个属性视图和Fact1/Fact2。
现在创建一个计算视图→维度(投影)。创建两个分析视图的投影并连接它们。将此连接的属性添加到输出面板。现在连接到投影并再次添加输出。
成功激活视图并转到数据预览进行分析。
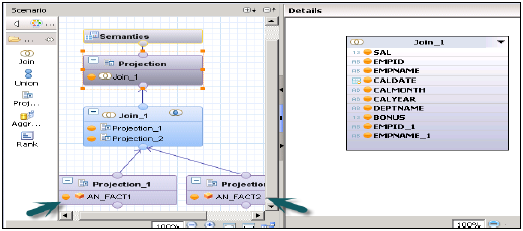
SAP HANA - 分析权限
分析权限用于限制对HANA信息视图的访问。您可以在分析权限中为不同用户的视图的不同组件分配不同类型的权限。
有时,需要将同一视图中的数据对没有相关需求的其他用户不可访问。
示例
假设您有一个包含公司员工详细信息的分析视图EmpDetails:员工姓名、员工ID、部门、工资、入职日期、员工登录名等。如果您不想让报表开发人员查看所有员工的工资详细信息或员工登录详细信息,您可以使用分析权限选项将其隐藏。
分析权限仅应用于信息视图中的属性。我们不能添加度量来限制分析权限中的访问。
分析权限用于控制对SAP HANA信息视图的读取访问。
因此,我们可以按员工姓名、员工ID、员工登录名或部门来限制数据,而不能按数值(如工资、奖金)来限制。
创建分析权限
右键单击包名称,然后转到新建分析权限,或者您可以使用HANA建模器快速启动打开。
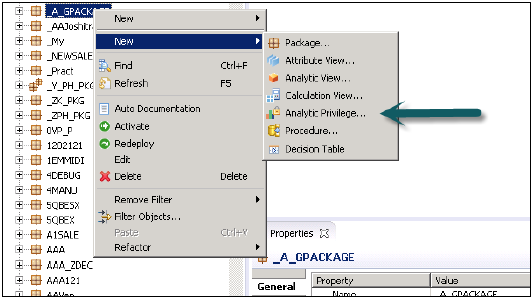
输入分析权限的名称和描述→完成。将打开一个新窗口。
您可以在单击“完成”之前单击“下一步”按钮,在此窗口中添加建模视图。还有一个选项可以复制现有的分析权限包。
单击“添加”按钮后,它将显示“内容”选项卡下的所有视图。
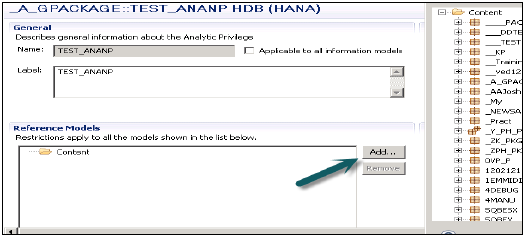
选择要添加到分析权限包的视图,然后单击“确定”。选定的视图将添加到引用模型下。
现在要添加选定视图下的属性到分析权限,请单击带有关联属性限制窗口的“添加”按钮。
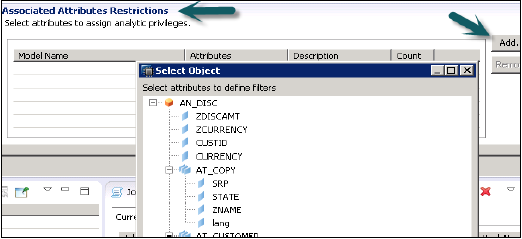
从选择对象选项中添加要添加到分析权限的对象,然后单击“确定”。
在“分配限制”选项中,它允许您添加要从特定用户处隐藏的建模视图中的值。您可以添加在建模视图的数据预览中不会反映的对象值。
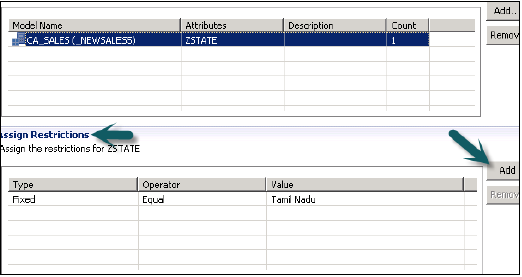
我们现在必须通过单击顶部的绿色圆形图标来激活分析权限。状态消息 - 成功完成确认成功激活,然后我们现在可以通过添加到角色来使用此视图。
现在要将此角色添加到用户,请转到安全选项卡→用户→选择要应用这些分析权限的用户。
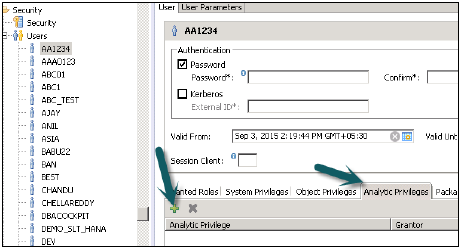
搜索要应用的分析权限(使用名称),然后单击“确定”。该视图将添加到分析权限下的用户角色中。
要从特定用户中删除分析权限,请选择选项卡下的视图,然后使用红色的删除选项。使用部署(顶部的箭头标记或F8)将其应用于用户配置文件。
SAP HANA - 信息组合器
SAP HANA信息组合器是一个自助建模环境,供最终用户分析数据集。它允许您将数据从工作簿格式(.xls、.csv)导入到HANA数据库中,并创建用于分析的建模视图。
信息组合器与HANA建模器非常不同,两者都旨在面向不同的用户组。技术娴熟且在数据建模方面拥有丰富经验的人员使用HANA建模器。没有技术知识的业务用户使用信息组合器。它提供简单易用的功能和界面。
信息组合器的功能
数据提取 - 信息组合器有助于提取数据、清理数据、预览数据并自动化在HANA数据库中创建物理表的过程。
数据操作 - 它帮助我们将两个对象(物理表、分析视图、属性视图和计算视图)组合起来,并创建一个信息视图,该视图可以被SAP BO工具(如SAP Business Objects Analysis、SAP Business Objects Explorer)和其他工具(如MS Excel)使用。
它以URL的形式提供集中的IT服务,可以从任何地方访问。
如何使用信息组合器上传数据?
它允许我们上传大量数据(最多500万个单元格)。访问信息组合器的链接:
http://<server>:<port>/IC
登录SAP HANA信息组合器。您可以使用此工具执行数据加载或操作。
上传数据可以通过两种方式完成:
- 直接将.xls、.csv文件上传到HANA数据库
- 另一种方法是将数据复制到剪贴板,然后从剪贴板复制到HANA数据库。
- 它允许加载包含标题的数据。
在信息组合器的左侧,您有三个选项:
选择数据源 → 分类数据 → 发布
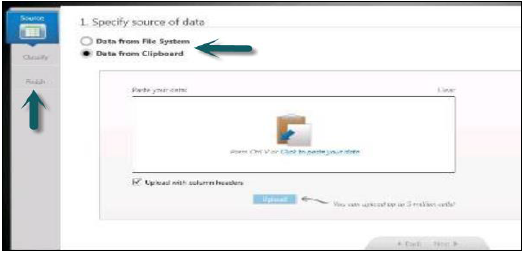
一旦数据发布到HANA数据库,就不能重命名表。在这种情况下,您必须从HANA数据库的模式中删除该表。
“SAP_IC”模式,其中存在IC_MODELS、IC_SPREADSHEETS等表。可以在这些表下找到使用IC创建的表的详细信息。
使用剪贴板
在IC中上传数据的另一种方法是使用剪贴板。将数据复制到剪贴板,并借助信息组合器将其上传。信息组合器还允许您查看数据的预览,甚至在临时存储中提供数据的摘要。它具有内置的数据清洗功能,用于消除数据中的任何不一致性。
数据清洗完成后,需要对数据进行分类,判断其是否为属性数据。IC具有内置功能来检查上传数据的类型。
最后一步是将数据发布到HANA数据库中的物理表。提供表的技术名称和描述,这将加载到IC_Tables模式中。
使用信息组合器发布的数据的用户角色
可以定义两组用户来使用从IC发布的数据。
IC_MODELER用于创建物理表、上传数据和创建信息视图。
IC_PUBLIC允许用户查看其他用户创建的信息视图。此角色不允许用户使用IC上传或创建任何信息视图。
信息组合器的系统要求
服务器要求:
至少需要2GB可用RAM。
必须在服务器上安装Java 6(64位)。
信息组合器服务器必须物理地位于HANA服务器旁边。
客户端要求:
- 已安装Silverlight 4的Internet Explorer。
SAP HANA - 导出和导入
HANA导出和导入选项允许将表、信息模型和环境移动到不同的或现有的系统。您无需重新创建所有表和信息模型,因为您可以简单地将其导出到新系统或导入到现有的目标系统以减少工作量。
此选项可以通过顶部的“文件”菜单访问,也可以通过右键单击HANA Studio中的任何表或信息模型来访问。
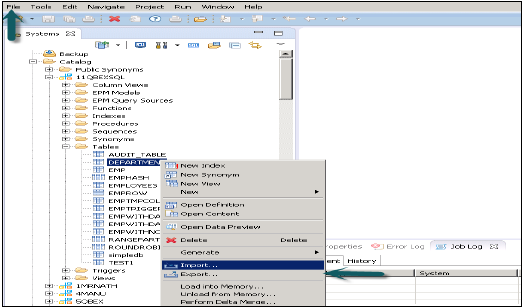
在HANA Studio中导出表/信息模型
转到文件菜单→导出→您将看到如下所示的选项:
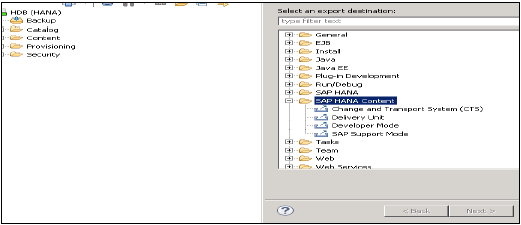
SAP HANA内容下的导出选项
交付单元
交付单元是一个单一单元,可以映射到多个包,并且可以作为一个单一实体导出,以便分配给交付单元的所有包都可以作为一个单元处理。
用户可以使用此选项将构成交付单元的所有包及其包含的相关对象导出到HANA服务器或本地客户端位置。
用户应在使用交付单元之前创建它。
这可以通过HANA建模器→交付单元→选择系统和下一步→创建→填写名称、版本等详细信息→确定→将包添加到交付单元→完成来实现。
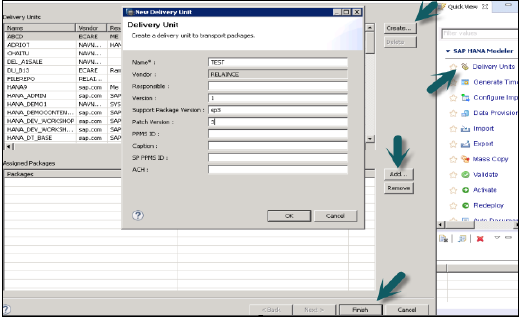
创建交付单元并将包分配给它后,用户可以使用导出选项查看包列表:
转到文件→导出→交付单元→选择交付单元。
您可以看到分配给交付单元的所有包的列表。它提供了一个选择导出位置的选项:
- 导出到服务器
- 导出到客户端
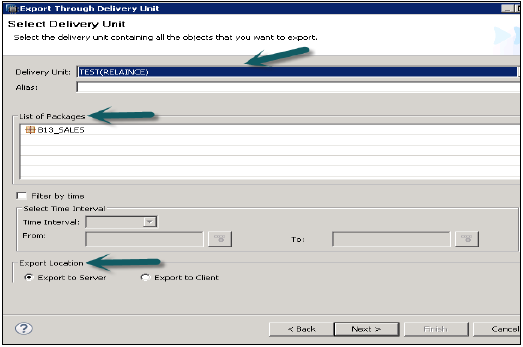
您可以将交付单元导出到HANA服务器位置或客户端位置,如图所示。
用户可以通过“按时间筛选”来限制导出,这意味着只有在指定时间间隔内更新的信息视图才会被导出。
选择交付单元和导出位置,然后单击下一步→完成。这将把选定的交付单元导出到指定位置。
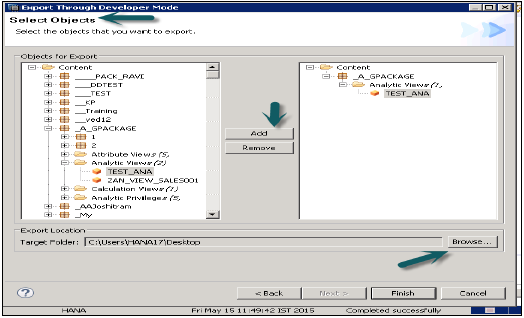
开发人员模式
此选项可用于将单个对象导出到本地系统中的位置。用户可以选择单个信息视图或视图和包组,并选择本地客户端位置进行导出并完成。
这在下面的快照中显示。
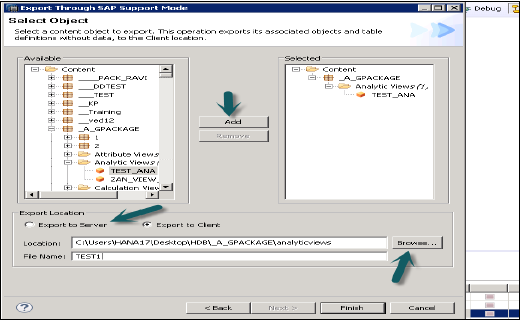
支持模式
这可用于将对象及其数据一起导出,用于SAP支持目的。仅在请求时使用。
示例:用户创建一个信息视图,该视图引发错误,并且他无法解决。在这种情况下,他可以使用此选项导出视图及其数据,并将其与SAP共享以进行调试。
SAP HANA Studio下的导出选项:
环境:将环境从一个系统导出到另一个系统。
表:此选项可用于导出表及其内容。
SAP HANA内容下的导入选项
转到文件→导入,您将在导入下看到如下所示的所有选项。
来自本地文件的数据
这用于从平面文件(如.xls或.csv文件)导入数据。
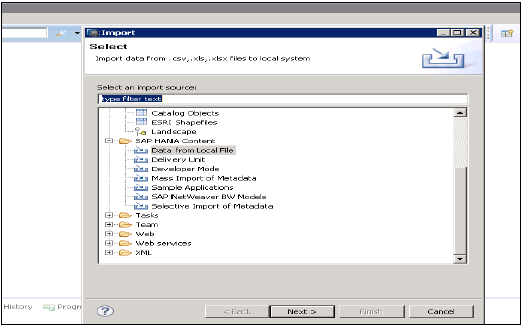
单击下一步→选择目标系统→定义导入属性
通过浏览本地系统选择源文件。如果您想保留标题行,它也会提供一个选项。它还提供了一个选项,即您是否要在现有模式下创建新表,或者您是否要将数据从文件导入到现有表。
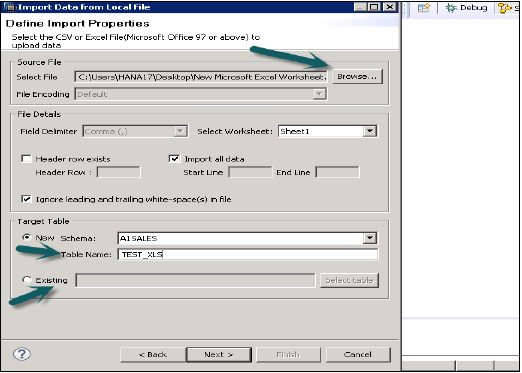
单击下一步时,它提供了一个选项来定义主键、更改列的数据类型、定义表的存储类型,并且还允许您更改表的建议结构。
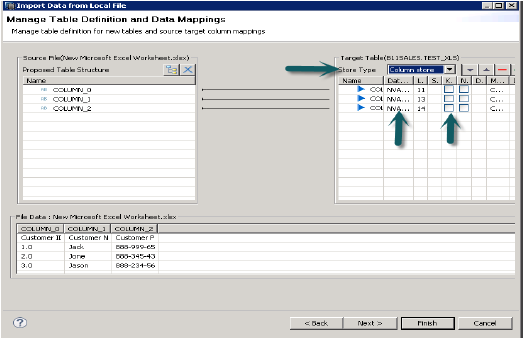
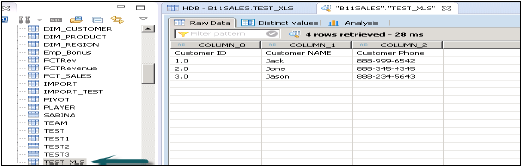
单击完成时,该表将在所述模式的表列表下填充。您可以进行数据预览并检查表的数据定义,它将与.xls文件相同。
交付单元
转到文件→导入→交付单元选择交付单元。您可以从服务器或本地客户端选择。
您可以选择“覆盖非活动版本”,这允许您覆盖存在的任何非活动版本的对象。如果用户选择“激活对象”,则导入后,所有导入的对象都将默认激活。用户无需手动触发导入视图的激活。
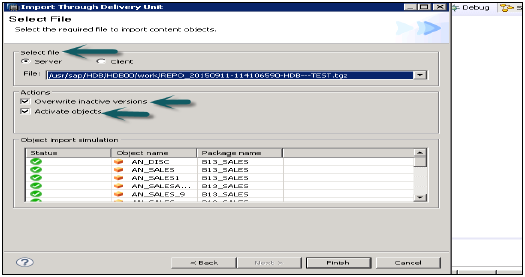
单击完成,一旦成功完成,它将填充到目标系统。
开发人员模式
浏览导出视图的本地客户端位置并选择要导入的视图,用户可以选择单个视图或视图和包组,然后单击完成。
元数据的批量导入
转到文件→导入→元数据的批量导入→下一步并选择源系统和目标系统。
配置用于批量导入的系统,然后单击完成。
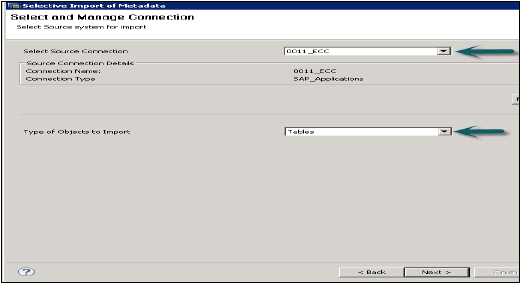
元数据的选择性导入
它允许您选择表和目标模式以从SAP应用程序导入元数据。
转到文件→导入→元数据的选择性导入→下一步
选择类型为“SAP应用程序”的源连接。请记住,类型为SAP应用程序的数据存储应该已经创建→单击下一步
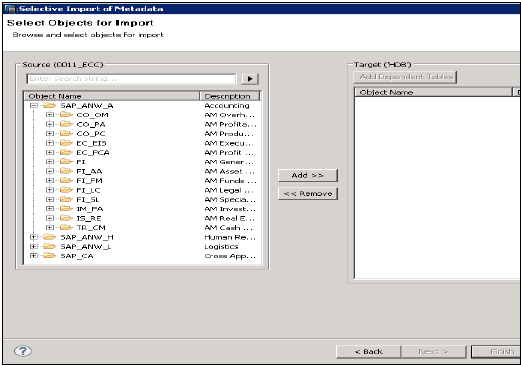
选择要导入的表,并在需要时验证数据。之后单击完成。
SAP HANA - 报表视图
我们知道,通过使用SAP HANA中的信息建模功能,我们可以创建不同的信息视图、属性视图、分析视图和计算视图。这些视图可以被不同的报表工具使用,例如SAP Business Object、SAP Lumira、Design Studio、Office Analysis,甚至第三方工具,如MS Excel。
这些报表工具使业务经理、分析师、销售经理和高级管理人员能够分析历史信息,以创建业务场景并决定公司的业务战略。
这就需要不同的报表工具使用HANA建模视图,并生成最终用户易于理解的报表和仪表板。
在大多数已实施SAP的公司中,HANA上的报表是使用BI平台工具完成的,这些工具借助关系和OLAP连接使用SQL和MDX查询。有各种各样的BI工具,例如:Web Intelligence、Crystal Reports、Dashboard、Explorer、Office Analysis等等。
BI 4.0连接到Hana视图
报表工具
Web Intelligence和Crystal Reports是最常用的报表工具。WebI使用称为Universe的语义层来连接到数据源,这些Universe用于在工具中进行报表。这些Universe是借助Universe设计工具UDT或信息设计工具IDT设计的。IDT支持多源启用数据源。但是,UDT仅支持单一数据源。
用于设计交互式仪表板的主要工具是Design Studio和Dashboard Designer。Design Studio是用于设计仪表板的未来工具,它通过BI消费者服务BICS连接使用HANA视图。仪表板设计(xcelsius)使用IDT通过关系或OLAP连接使用HANA数据库中的模式。
SAP Lumira具有直接连接或从HANA数据库加载数据的内置功能。HANA视图可以直接在Lumira中使用,用于可视化和创建故事。
Office Analysis使用OLAP连接连接到HANA信息视图。此OLAP连接可以在CMC或IDT中创建。
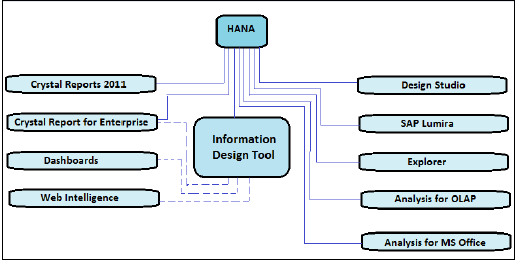
上图显示了所有BI工具,它们可以使用实线直接连接和集成到SAP HANA中,并使用OLAP连接。它还描述了需要使用IDT建立关系连接到HANA的工具,这些工具用虚线表示。
关系连接与OLAP连接
基本思想是,如果您需要访问表或传统数据库中的数据,则您的连接应该是关系连接;但如果您的源是应用程序,并且数据存储在多维数据存储区(例如Info cubes、信息模型)中,则应使用OLAP连接。
- 关系连接只能在IDT/UDT中创建。
- OLAP连接可以在IDT和CMC中创建。
需要注意的另一点是,关系连接总是产生要从报表中触发的SQL语句,而OLAP连接通常会创建MDX语句。
信息设计工具
在信息设计工具(IDT)中,您可以使用JDBC或ODBC驱动程序创建到SAP HANA视图或表的连接,并使用此连接构建Universe,以便为客户端工具(如仪表板和Web Intelligence)提供访问权限,如上图所示。
您可以使用JDBC或ODBC驱动程序创建到SAP HANA的直接连接。
SAP HANA - Crystal Reports
企业版Crystal Reports
在企业版Crystal Reports中,您可以使用信息设计工具创建的现有关系连接访问SAP HANA数据。
您还可以使用信息设计工具或CMC创建的OLAP连接连接到SAP HANA。
Design Studio
Design Studio可以使用信息设计工具或CMC中创建的现有OLAP连接访问SAP HANA数据,这与Office Analysis类似。
仪表板
仪表板只能通过关系Universe连接到SAP HANA。在SAP HANA之上使用仪表板的客户应认真考虑使用Design Studio构建新的仪表板。
Web Intelligence
Web Intelligence只能通过关系Universe连接到SAP HANA。
SAP Lumira
Lumira可以直连SAP HANA分析和计算视图。它也可以通过SAP BI平台使用关系型Universe连接SAP HANA。
Office Analysis OLAP版
在Office Analysis OLAP版中,您可以使用在中央管理控制台 (CMC) 或信息设计工具中定义的OLAP连接来连接SAP HANA。
Explorer
您可以使用JDBC驱动程序基于SAP HANA视图创建信息空间。
在CMC中创建OLAP连接
我们可以为所有想要在HANA视图之上使用的BI工具创建OLAP连接,例如用于分析的OLAP、用于企业的Crystal Reports和Design Studio。通过IDT的关系连接用于将Web Intelligence和Dashboard连接到HANA数据库。
这些连接可以使用IDT和CMC创建,并且两个连接都保存在BO Repository中。
使用用户名和密码登录CMC。
从连接的下拉列表中,选择一个OLAP连接。它还会显示在CMC中已创建的连接。要创建新连接,请点击绿色图标。
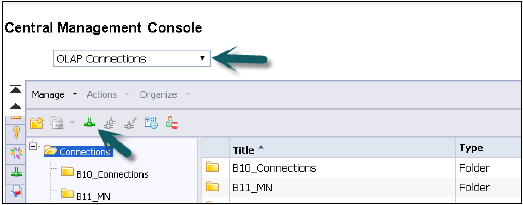
输入OLAP连接的名称和描述。多人可以使用此连接在不同的BI平台工具中连接到HANA视图。
提供程序 - SAP HANA
服务器 - 输入HANA服务器名称
实例 - 实例编号
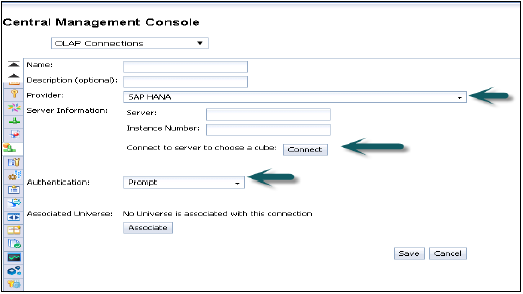
它还提供连接到单个多维数据集(您也可以选择连接到单个分析或计算视图)或连接到完整HANA系统的选项。
单击“连接”并通过输入用户名和密码选择建模视图。
身份验证类型 - 在CMC中创建OLAP连接时,可以使用三种身份验证类型。
预定义 - 使用此连接时,不会再次询问用户名和密码。
提示 - 每次都会询问用户名和密码
SSO - 用户特定
输入用户 - 输入HANA系统的用户名和密码,保存后,新的连接将添加到现有的连接列表中。
现在打开BI Launchpad以打开所有用于报告的BI平台工具,例如Office Analysis for OLAP,它将要求选择连接。默认情况下,如果在创建此连接时指定了信息视图,它将显示信息视图;否则,单击“下一步”,然后转到文件夹→选择视图(分析视图或计算视图)。
SAP Lumira与HANA系统的连接
从“开始”程序打开SAP Lumira,单击文件菜单→新建→添加新数据集→连接到SAP HANA→下一步
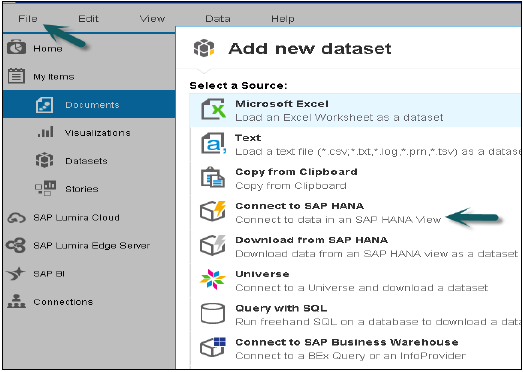
连接到SAP HANA和从SAP HANA下载之间的区别在于,它会将数据从HANA系统下载到BO Repository,并且数据刷新不会随着HANA系统中的更改而发生。输入HANA服务器名称和实例编号。输入用户名和密码→单击“连接”。
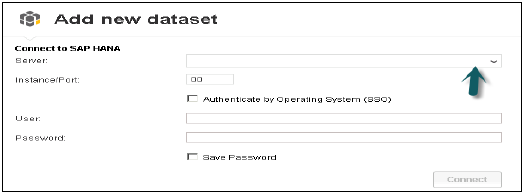
它将显示所有视图。您可以使用视图名称进行搜索→选择视图→下一步。它将显示所有度量和维度。您可以根据需要从这些属性中选择→单击创建选项。
SAP Lumira内部有四个选项卡:
准备 - 您可以查看数据并进行任何自定义计算。
可视化 - 您可以添加图表。单击X轴和Y轴的加号以添加属性。
组合 - 此选项可用于创建可视化序列(故事)→单击“面板”以添加多个面板→创建→它将在左侧显示所有可视化效果。拖动第一个可视化效果,然后添加页面,再添加第二个可视化效果。
共享 - 如果它构建在SAP HANA上,我们只能发布到SAP Lumira服务器。否则,您还可以将故事从SAP Lumira发布到SAP社区网络SCN或BI平台。
保存文件以便以后使用→转到文件-保存→选择本地→保存
在IDT中创建关系连接以在WebI和Dashboard中使用HANA视图 -
打开信息设计工具→转到BI平台客户端工具。单击“新建”→“项目”输入项目名称→“完成”。
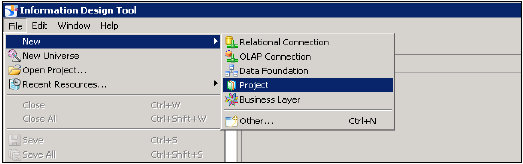
右键单击项目名称→转到“新建”→选择“关系连接”→输入连接/资源名称→下一步→从列表中选择SAP以连接到HANA系统→SAP HANA→选择JDBC/ODBC驱动程序→单击下一步→输入HANA系统详细信息→单击下一步和完成。
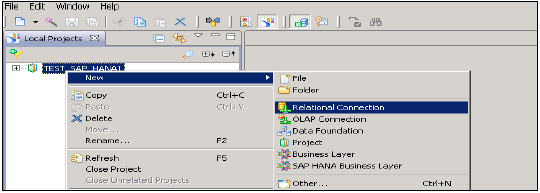
您还可以通过单击“测试连接”选项来测试此连接。
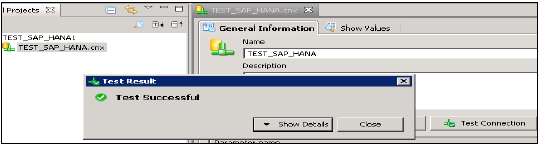
测试连接→成功。下一步是将此连接发布到Repository,使其可供使用。
右键单击连接名称→单击“将连接发布到Repository”→输入BO Repository名称和密码→单击“连接”→下一步→完成→是。
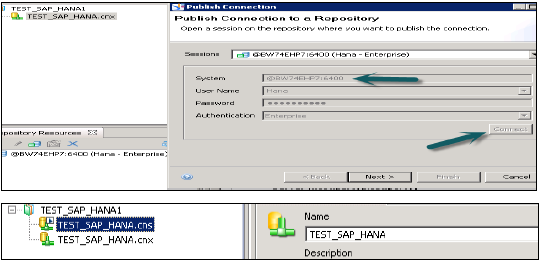
它将创建一个具有.cns扩展名的新的关系连接。
.cns - 连接类型表示安全的Repository连接,应将其用于创建数据基础。
.cnx - 表示本地非安全连接。如果在创建和发布Universe时使用此连接,则不允许您将其发布到Repository。
选择.cns连接类型→右键单击此连接→单击“新建数据基础”→输入数据基础的名称→下一步→单一源/多源→单击下一步→完成。

它将在中间窗格中显示HANA数据库中的所有表以及模式名称。
将HANA数据库中的所有表导入到主窗格以创建Universe。使用Dim表中的主键连接Dim表和Fact表以创建模式。
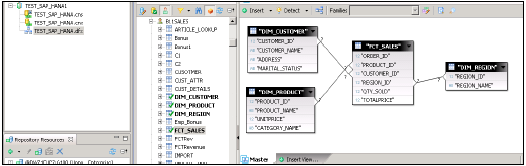
双击连接并检测基数→检测→确定→保存顶部所有内容。现在,我们必须在数据基础上创建一个新的业务层,该层将由BI应用程序工具使用。
右键单击.dfx并选择“新建业务层”→输入名称→完成→。它将自动显示主窗格下所有对象→。将维度更改为度量(根据需要更改类型-度量投影)→全部保存。
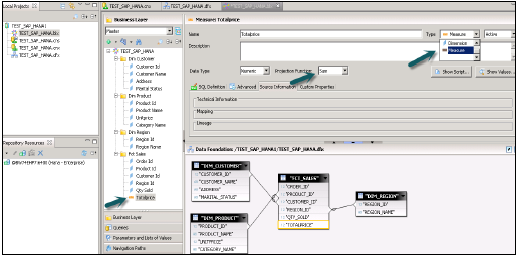
右键单击.bfx文件→单击“发布”→到Repository→单击“下一步”→“完成”→Universe发布成功。
现在从BI Launchpad打开WebI报表或从BI平台客户端工具打开Webi富客户端→新建→选择Universe→TEST_SAP_HANA→确定。
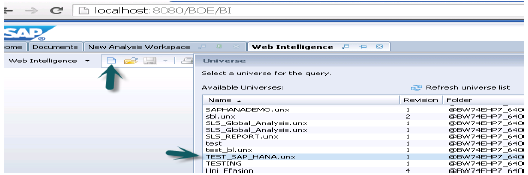
所有对象都将添加到查询面板。您可以从左窗格中选择属性和度量,并将它们添加到结果对象。“运行查询”将运行SQL查询,并在WebI中以报表形式生成输出,如下所示。
SAP HANA - Excel 集成
许多组织认为Microsoft Excel是最常见的BI报表和分析工具。业务经理和分析师可以将其连接到HANA数据库,以绘制用于分析的透视表和图表。
将MS Excel连接到HANA
打开Excel,然后转到“数据”选项卡→从其他来源→单击“数据连接向导”→其他/高级,然后单击“下一步”→将打开“数据链接属性”。
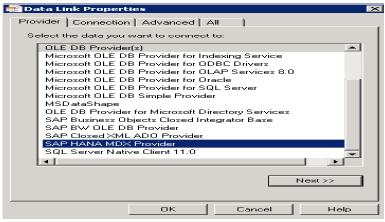
从列表中选择SAP HANA MDX提供程序以连接到任何MDX数据源→输入HANA系统详细信息(服务器名称、实例、用户名和密码)→单击“测试连接”→连接成功→确定。
它将在下拉列表中为您提供HANA系统中可用的所有包的列表。您可以选择一个信息视图→单击“下一步”→选择透视表/其他→确定。
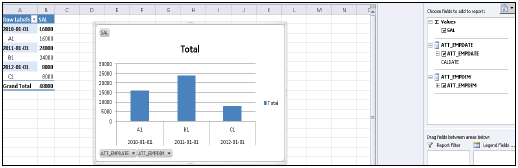
信息视图中的所有属性都将添加到MS Excel。您可以选择不同的属性和度量进行报告,如所示,您可以从顶部的设计选项中选择不同的图表,如饼图和条形图。
SAP HANA - 安全性概述
安全意味着保护公司关键数据免受未经授权的访问和使用,并确保根据公司政策满足合规性和标准。SAP HANA使客户能够实施不同的安全策略和程序,并满足公司的合规性要求。
SAP HANA在一个HANA系统中支持多个数据库,这称为多租户数据库容器。HANA系统还可以包含多个多租户数据库容器。多容器系统始终只有一个系统数据库和任意数量的多租户数据库容器。在此环境中安装的SAP HANA系统由单个系统ID (SID) 标识。HANA系统中的数据库容器由SID和数据库名称标识。称为HANA Studio的SAP HANA客户端连接到特定的数据库。
SAP HANA提供所有与安全相关的功能,例如身份验证、授权、加密和审计,以及一些其他多租户数据库不支持的附加功能。
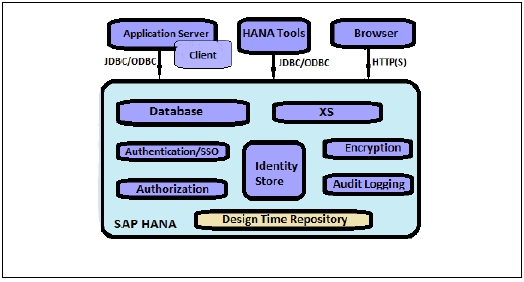
以下是SAP HANA提供的与安全相关的功能列表:
- 用户和角色管理
- 身份验证和SSO
- 授权
- 网络中数据通信的加密
- 持久层中数据的加密
多租户HANA数据库中的附加功能:
数据库隔离 - 它涉及通过操作系统机制防止跨租户攻击
配置更改黑名单 - 它涉及阻止租户数据库管理员更改某些系统属性
受限功能 - 它涉及禁用某些数据库功能,这些功能提供对文件系统、网络或其他资源的直接访问。
SAP HANA用户和角色管理
SAP HANA用户和角色管理配置取决于HANA系统的架构。
如果SAP HANA与BI平台工具集成并充当报表数据库,则最终用户和角色在应用程序服务器中管理。
如果最终用户直接连接到SAP HANA数据库,则HANA系统数据库层中的用户和角色对于最终用户和管理员都是必需的。
每个想要使用HANA数据库的用户都必须具有具有必要权限的数据库用户。访问HANA系统的用户可以是技术用户或最终用户,具体取决于访问要求。成功登录系统后,将验证用户执行所需操作的授权。执行该操作取决于已授予用户的权限。可以使用HANA Security中的角色授予这些权限。HANA Studio是管理HANA数据库系统用户和角色的强大工具之一。
用户类型
用户类型根据安全策略和分配给用户配置文件的不同权限而有所不同。用户类型可以是技术数据库用户,也可以是最终用户,他们需要访问HANA系统以进行报告或数据处理。
标准用户
标准用户可以在自己的模式中创建对象,并具有系统信息模型的读取权限。读取权限由 PUBLIC 角色提供,该角色分配给每个标准用户。
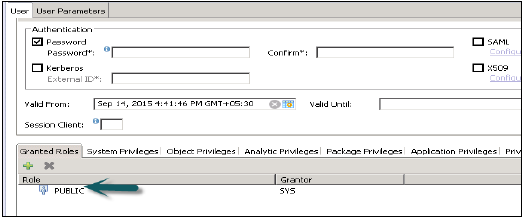
受限用户
受限用户是指使用某些应用程序访问 HANA 系统且不具有 HANA 系统 SQL 权限的用户。创建这些用户时,他们最初没有任何访问权限。
如果我们将受限用户与标准用户进行比较:
受限用户无法在 HANA 数据库或其自己的模式中创建对象。
他们无法查看数据库中的任何数据,因为他们没有像标准用户那样在配置文件中添加通用的 PUBLIC 角色。
他们只能使用 HTTP/HTTPS 连接到 HANA 数据库。
用户管理和角色管理
技术数据库用户仅用于管理目的,例如在数据库中创建新对象、向其他用户分配权限、以及对包和应用程序等进行操作。
SAP HANA 用户管理活动
根据业务需求和 HANA 系统的配置,可以使用用户管理工具(如 HANA Studio)执行不同的用户活动。
最常见的活动包括:
- 创建用户
- 向用户授予角色
- 定义和创建角色
- 删除用户
- 重置用户密码
- 在多次登录失败后重新激活用户
- 在需要时停用用户
如何在 HANA Studio 中创建用户?
只有具有系统权限 ROLE ADMIN 的数据库用户才能在 HANA Studio 中创建用户和角色。要在 HANA Studio 中创建用户和角色,请转到 HANA 管理控制台。您将在“系统”视图中看到“安全”选项卡:
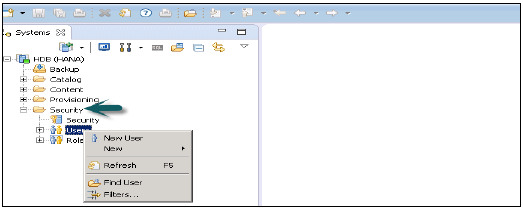
展开“安全”选项卡后,会显示“用户”和“角色”选项。要创建新用户,请右键单击“用户”,然后转到“新建用户”。将打开一个新窗口,您可以在其中定义用户和用户参数。
输入用户名(必填),并在“身份验证”字段中输入密码。保存新用户的密码时,密码将被应用。您也可以选择创建受限用户。
指定的用户名不能与现有用户或角色的名称相同。密码规则包括最短密码长度以及必须包含哪些字符类型(小写、大写、数字、特殊字符)的定义。
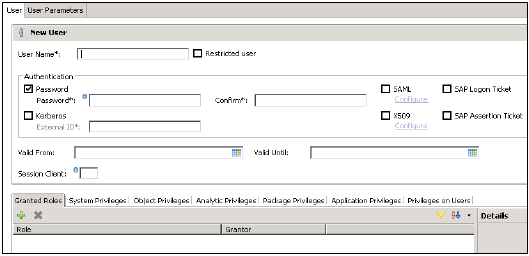
可以配置不同的授权方法,例如 SAML、X509 证书、SAP Logon ticket 等。数据库中的用户可以通过不同的机制进行身份验证:
使用密码的内部身份验证机制。
外部机制,例如 Kerberos、SAML、SAP Logon Ticket、SAP Assertion Ticket 或 X.509。
一个用户可以同时通过多种机制进行身份验证。但是,任何时候只能有一个密码和一个 Kerberos 主体名称有效。必须指定一种身份验证机制,才能允许用户连接并使用数据库实例。
它还提供定义用户有效性的选项,您可以通过选择日期来指定有效期。有效期规范是一个可选的用户参数。
SAP HANA 数据库默认情况下提供的一些用户包括:SYS、SYSTEM、_SYS_REPO、_SYS_STATISTICS。
完成此操作后,下一步是为用户配置文件定义权限。可以向用户配置文件添加不同类型的权限。
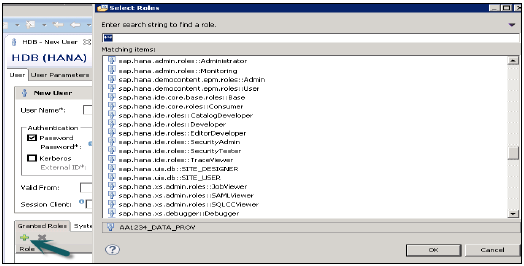
向用户授予角色
这用于向用户配置文件添加内置的 SAP HANA 角色或添加在“角色”选项卡下创建的自定义角色。自定义角色允许您根据访问需求定义角色,您可以直接将这些角色添加到用户配置文件。这样无需每次为不同的访问类型记住并向用户配置文件添加对象。
PUBLIC - 这是一个通用角色,默认情况下分配给所有数据库用户。此角色包含对系统视图的只读访问权限以及某些过程的执行权限。这些角色无法撤销。

建模
它包含在 SAP HANA Studio 中使用信息建模器所需的所有权限。
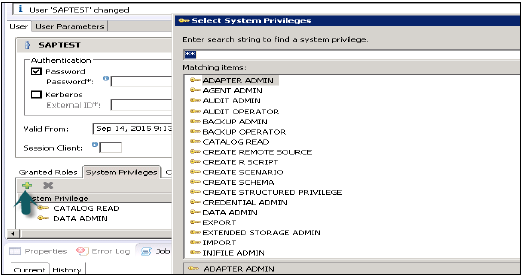
系统权限
可以向用户配置文件添加不同类型的系统权限。要向用户配置文件添加系统权限,请单击“+”号。
系统权限用于备份/还原、用户管理、实例启动和停止等。
内容管理员
它包含与 MODELING 角色中类似的权限,但除此之外,此角色还允许将这些权限授予其他用户。它还包含用于处理导入对象的存储库权限。
数据管理员
这是一种权限类型,需要将数据从对象添加到用户配置文件。
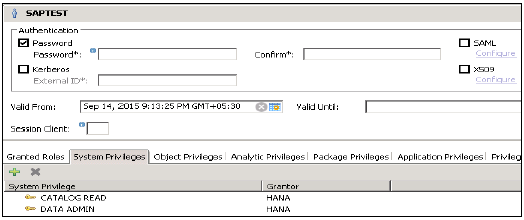
以下是常见的受支持系统权限:
附加调试器
它授权调试由不同用户调用的过程调用。此外,还需要对应过程的 DEBUG 权限。
审计管理员
控制以下与审计相关的命令的执行:CREATE AUDIT POLICY、DROP AUDIT POLICY 和 ALTER AUDIT POLICY 以及审计配置的更改。还允许访问 AUDIT_LOG 系统视图。
审计操作员
它授权执行以下命令:ALTER SYSTEM CLEAR AUDIT LOG。还允许访问 AUDIT_LOG 系统视图。
备份管理员
它授权 BACKUP 和 RECOVERY 命令,用于定义和启动备份和恢复过程。
备份操作员
它授权 BACKUP 命令启动备份过程。
目录读取
它授权用户对所有系统视图具有无过滤的只读访问权限。通常情况下,这些视图的内容会根据访问用户的权限进行过滤。
创建模式
它授权使用 CREATE SCHEMA 命令创建数据库模式。默认情况下,每个用户拥有一个模式,拥有此权限的用户可以创建其他模式。
创建结构化权限
它授权创建结构化权限(分析权限)。只有分析权限的所有者才能进一步向其他用户或角色授予或撤销该权限。
凭据管理员
它授权凭据命令:CREATE/ALTER/DROP CREDENTIAL。
数据管理员
它授权读取系统视图中的所有数据。它还能够在 SAP HANA 数据库中执行任何数据定义语言 (DDL) 命令。
拥有此权限的用户无法选择或更改他们没有访问权限的存储表中的数据,但他们可以删除表或修改表定义。
数据库管理员
它授权与多数据库中的数据库相关的所有命令,例如 CREATE、DROP、ALTER、RENAME、BACKUP、RECOVERY。
导出
它通过 EXPORT TABLE 命令授权数据库中的导出活动。
请注意,除了此权限之外,用户还需要对要导出的源表具有 SELECT 权限。
导入
它使用 IMPORT 命令授权数据库中的导入活动。
请注意,除了此权限之外,用户还需要对要导入的目标表具有 INSERT 权限。
Inifile 管理员
它授权更改系统设置。
许可证管理员
它授权 SET SYSTEM LICENSE 命令安装新许可证。
日志管理员
它授权 ALTER SYSTEM LOGGING [ON|OFF] 命令启用或禁用日志刷新机制。
监控管理员
它授权用于 EVENT 的 ALTER SYSTEM 命令。
优化器管理员
它授权与 SQL PLAN CACHE 相关的 ALTER SYSTEM 命令和 ALTER SYSTEM UPDATE STATISTICS 命令,这些命令会影响查询优化器的行为。
资源管理员
此权限授权与系统资源相关的命令。例如,ALTER SYSTEM RECLAIM DATAVOLUME 和 ALTER SYSTEM RESET MONITORING VIEW。它还授权管理控制台中可用的许多命令。
角色管理员
此权限授权使用 CREATE ROLE 和 DROP ROLE 命令创建和删除角色。它还授权使用 GRANT 和 REVOKE 命令授予和撤销角色。
已激活的角色(即创建者是预定义用户 _SYS_REPO 的角色)既不能授予其他角色或用户,也不能直接删除。即使拥有 ROLE ADMIN 权限的用户也无法这样做。请查看有关激活对象的文档。
保存点管理员
它授权使用 ALTER SYSTEM SAVEPOINT 命令执行保存点过程。
SAP HANA 数据库的组件可以创建新的系统权限。这些权限使用组件名称作为系统权限的第一个标识符,使用组件权限名称作为第二个标识符。
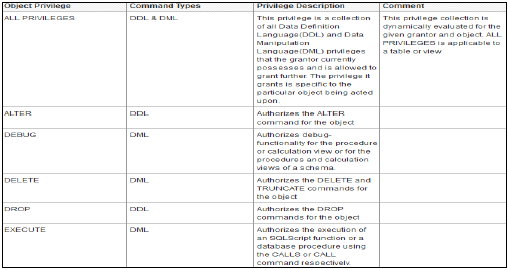
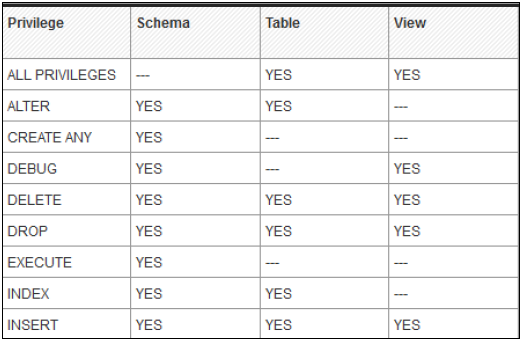
对象/SQL 权限
对象权限也称为 SQL 权限。这些权限用于允许访问对象,例如表、视图或模式的选择、插入、更新和删除。
以下是可能的 Object 权限类型:
仅在运行时存在的数据库对象的 Object 权限
在存储库中创建的激活对象(如计算视图)上的 Object 权限
包含在存储库中创建的激活对象的模式上的 Object 权限
Object/SQL 权限是数据库对象上所有 DDL 和 DML 权限的集合。
以下是常见的受支持对象权限:
HANA 数据库中有多个数据库对象,因此并非所有权限都适用于所有类型的数据库对象。
对象权限及其对数据库对象的适用性:
分析权限
有时,需要确保同一视图中的数据对于没有相关需求的其他用户不可访问。
分析权限用于限制对 HANA 信息视图的对象级访问。我们可以在分析权限中应用行级和列级安全性。
分析权限用于:
- 为特定值范围分配行级和列级安全性。
- 为建模视图分配行级和列级安全性。
包权限
在 SAP HANA 存储库中,您可以为特定用户或角色设置包授权。包权限用于允许访问数据模型(分析视图或计算视图)或存储库对象。分配给存储库包的所有权限也分配给所有子包。您还可以指定是否可以将分配的用户授权传递给其他用户。
将包权限添加到用户配置文件的步骤:
在 HANA Studio 的用户创建下单击“包权限”选项卡→ 选择“+”以添加一个或多个包。使用 Ctrl 键选择多个包。
在“选择存储库包”对话框中,使用包名称的全部或部分来查找要授权访问的存储库包。
选择一个或多个要授权访问的存储库包,选定的包将显示在“包权限”选项卡中。
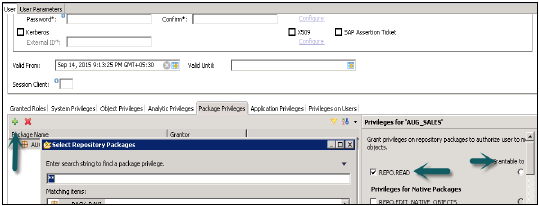
以下是用于授权用户修改对象的存储库包上的授予权限:
REPO.READ - 读取选定包和设计时对象(本地和导入的)的访问权限
REPO.EDIT_NATIVE_OBJECTS - 授权修改包中的对象。
可授予他人 - 如果为此选择“是”,则允许将分配的用户授权传递给其他用户。
应用程序权限
用户配置文件中的应用程序权限用于定义对 HANA XS 应用程序的访问授权。这可以分配给单个用户或用户组。应用程序权限还可以用于为同一应用程序提供不同级别的访问权限,例如为数据库管理员提供高级功能,为普通用户提供只读访问权限。
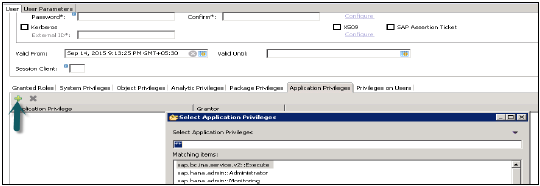
要在用户配置文件中定义特定于应用程序的权限或添加用户组,应使用以下权限:
- 应用程序权限文件 (.xsprivileges)
- 应用程序访问文件 (.xsaccess)
- 角色定义文件 (<RoleName>.hdbrole)
SAP HANA - 身份验证
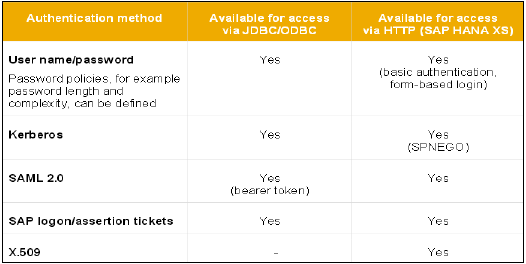
所有具有 HANA 数据库访问权限的 SAP HANA 用户都将通过不同的身份验证方法进行验证。SAP HANA 系统支持各种类型的身份验证方法,所有这些登录方法都在创建配置文件时进行配置。
以下是 SAP HANA 支持的身份验证方法列表:
- 用户名/密码
- Kerberos
- SAML 2.0
- SAP Logon Ticket
- X.509
用户名/密码
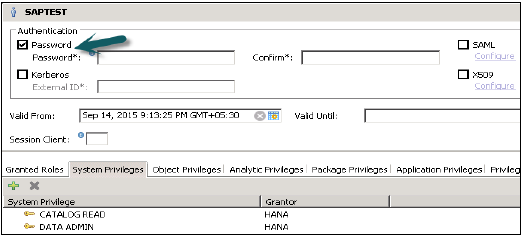
此方法需要HANA用户输入用户名和密码才能登录数据库。此用户配置文件是在HANA Studio中用户管理→安全选项卡下创建的。
密码应符合密码策略,即密码长度、复杂性、大小写字母等。
您可以根据组织的安全标准更改密码策略。请注意,密码策略无法停用。
Kerberos
所有使用外部身份验证方法连接到HANA数据库系统的用户也应该拥有一个数据库用户。需要将外部登录映射到内部数据库用户。
此方法允许用户通过网络或使用SAP Business Objects中的前端应用程序,使用JDBC/ODBC驱动程序直接对HANA系统进行身份验证。
它还允许在使用HANA XS引擎的HANA扩展服务中进行HTTP访问。它使用SPENGO机制进行Kerberos身份验证。
SAML
SAML代表安全断言标记语言,可用于对直接从ODBC/JDBC客户端访问HANA系统的用户进行身份验证。它也可用于通过HANA XS引擎通过HTTP访问HANA系统的用户身份验证。
SAML仅用于身份验证目的,不用于授权。
SAP Logon和断言Ticket
SAP Logon/断言Ticket可用于对HANA系统中的用户进行身份验证。这些Ticket在用户登录到配置为发出此类Ticket的SAP系统(例如SAP Portal等)时发放给用户。SAP Logon Ticket中指定的用户应在HANA系统中创建,因为它不支持用户映射。
X.509客户端证书
X.509证书也可用于通过HANA XS引擎的HTTP访问请求登录HANA系统。用户通过从受信任的证书颁发机构签名的证书进行身份验证,该证书存储在HANA XS系统中。
受信任证书中的用户应存在于HANA系统中,因为不支持用户映射。
HANA系统中的单点登录
可以在HANA系统中配置单点登录,允许用户在客户端进行初始身份验证后登录HANA系统。用户使用不同的身份验证方法在客户端应用程序中登录,而SSO允许用户直接访问HANA系统。
SSO可以在以下配置方法中配置:
- SAML
- Kerberos
- 来自HANA XS引擎的HTTP访问的X.509客户端证书
- SAP Logon/断言Ticket
SAP HANA - 授权方法
当用户尝试连接到HANA数据库并执行一些数据库操作时,将检查授权。当用户通过JDBC/ODBC或通过HTTP使用客户端工具连接到HANA数据库以对数据库对象执行某些操作时,相应的操作将由授予用户的访问权限确定。
授予用户的权限由分配给用户配置文件或已授予用户的角色的对象权限确定。授权是两种访问权限的组合。当用户尝试对HANA数据库执行某些操作时,系统将执行授权检查。当找到所有必需的权限时,系统将停止此检查并授予请求的访问权限。
SAP HANA中使用了不同类型的权限,如下面的用户角色和管理中所述:
系统权限
它们适用于用户的系统和数据库授权以及控制系统活动。它们用于管理任务,例如创建模式、数据备份、创建用户和角色等等。系统权限也用于执行存储库操作。
对象权限
它们适用于数据库操作,并应用于数据库对象,如表、模式等。它们用于管理数据库对象,如表和视图。可以根据数据库对象定义不同的操作,如选择、执行、更改、删除、删除。
它们还用于控制通过SMART数据访问连接到SAP HANA的远程数据对象。
分析权限
它们适用于HANA存储库中创建的所有包内部的数据。它们用于控制在包内创建的建模视图,如属性视图、分析视图和计算视图。它们将行和列级安全性应用于在HANA包中的建模视图中定义的属性。
包权限
它们适用于允许访问和使用在HANA数据库存储库中创建的包。包包含不同的建模视图,如属性视图、分析视图和计算视图,以及在HANA存储库数据库中定义的分析权限。
应用程序权限
它们适用于通过HTTP请求访问HANA数据库的HANA XS应用程序。它们用于控制对使用HANA XS引擎创建的应用程序的访问。
可以使用HANA Studio直接将应用程序权限应用于用户/角色,但最好是在设计时将它们应用于在存储库中创建的角色。
SAP HANA数据库中的存储库授权
_SYS_REPO用户拥有HANA存储库中的所有对象。此用户应在HANA系统中对建模存储库对象的外部对象进行授权。_SYS_REPO是所有对象的拥有者,因此它只能用于授予对这些对象的访问权限,其他用户无法以_SYS_REPO用户身份登录。
GRANT SELECT ON SCHEMA "<SCHEMA_NAME>" TO _SYS_REPO WITH GRANT OPTION
SAP HANA - 许可证管理
需要SAP HANA许可证管理和密钥才能使用HANA数据库。您可以使用HANA Studio安装或删除HANA许可证密钥。
许可证密钥类型
SAP HANA系统支持两种类型的许可证密钥:
临时许可证密钥 - 安装HANA数据库时会自动安装临时许可证密钥。这些密钥仅有效90天,您应在安装后90天期限到期前从SAP市场请求永久许可证密钥。
永久许可证密钥 - 永久许可证密钥仅在预定义的到期日期之前有效。许可证密钥指定许可给目标HANA安装的内存量。它们可以从SAP市场“密钥和请求”选项卡下安装。当永久许可证密钥过期时,将发放一个临时许可证密钥,该密钥仅有效28天。在此期间,您必须再次安装永久许可证密钥。
HANA系统有两种类型的永久许可证密钥:
非强制 - 如果安装了非强制许可证密钥,并且HANA系统的消耗超过许可的内存量,则在这种情况下,SAP HANA的操作不会受到影响。
强制 - 如果安装了强制许可证密钥,并且HANA系统的消耗超过许可的内存量,则HANA系统将被锁定。如果发生这种情况,则必须重新启动HANA系统或请求并安装新的许可证密钥。
HANA系统可以使用不同的许可证方案,具体取决于系统的环境(独立式、HANA Cloud、BW on HANA等),并非所有这些模型都基于HANA系统安装的内存。
如何检查HANA的许可证属性
右键单击HANA系统→属性→许可证
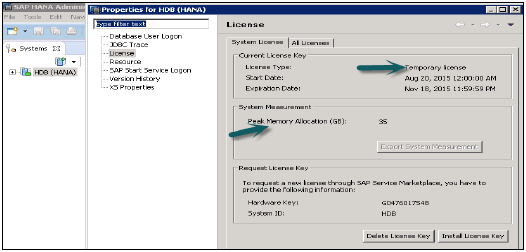
它说明了许可证类型、开始日期和到期日期、内存分配以及通过SAP市场请求新许可证所需的信息(硬件密钥、系统ID)。
安装许可证密钥→浏览→输入路径,用于安装新的许可证密钥,删除选项用于删除任何旧的过期密钥。
“许可证”下的“所有许可证”选项卡显示产品名称、说明、硬件密钥、首次安装时间等。
SAP HANA - 审计
SAP HANA审计策略说明了要审计的操作,以及必须执行操作才能与审计相关的条件。审计策略定义了在HANA系统中执行了哪些活动,以及谁在何时执行了这些活动。
SAP HANA数据库审计功能允许监控在HANA系统中执行的操作。必须在HANA系统上激活SAP HANA审计策略才能使用它。执行操作时,策略将触发审计事件以写入审计跟踪。您也可以删除审计跟踪中的审计条目。
在分布式环境中,如果您有多个数据库,则可以在每个单独的系统上启用审计策略。对于系统数据库,审计策略在nameserver.ini文件中定义,对于租户数据库,它在global.ini文件中定义。
激活审计策略
要在HANA系统中定义审计策略,您应该拥有系统权限 - 审计管理员。
转到HANA系统中的安全选项→审计
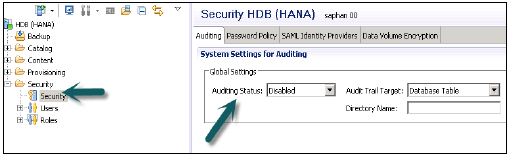
在全局设置下→将审计状态设置为启用。
您还可以选择审计跟踪目标。可能的审计跟踪目标如下:
Syslog(默认) - Linux操作系统的日志记录系统。
数据库表 - 内部数据库表,拥有审计管理员或审计操作员系统权限的用户只能对该表运行选择操作。
CSV文本 - 此类型的审计跟踪仅用于非生产环境中的测试目的。
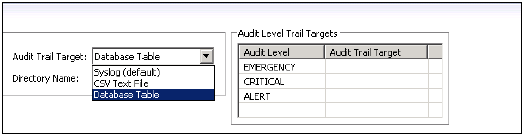
您还可以在审计策略区域创建新的审计策略→选择创建新策略。输入要审计的策略名称和操作。
使用部署按钮保存新策略。满足操作条件时,新策略会自动启用,审计条目将创建在审计跟踪表中。您可以通过将状态更改为禁用来禁用策略,也可以删除策略。
SAP HANA - 数据复制概述
SAP HANA复制允许将数据从源系统迁移到SAP HANA数据库。使用各种数据复制技术,将数据从现有SAP系统移动到HANA的一种简单方法。
可以通过命令行或使用HANA Studio在控制台上设置系统复制。在此过程中,主要的ECC或事务系统可以保持在线状态。HANA系统中有三种类型的数据复制方法:
- SAP LT复制方法
- ETL工具SAP Business Objects Data Services (BODS)方法
- 直接提取器连接方法 (DXC)
SAP LT复制方法
SAP Landscape Transformation复制是HANA系统中基于触发器的数据复制方法。它是从SAP和非SAP源复制实时数据或基于计划的复制的完美解决方案。它具有SAP LT复制服务器,负责处理所有触发器请求。复制服务器可以作为独立服务器安装,也可以在任何具有SAP NW 7.02或更高版本的SAP系统上运行。
HANA DB和ECC事务系统之间存在受信任的RFC连接,这使得HANA系统环境中基于触发器的复制成为可能。
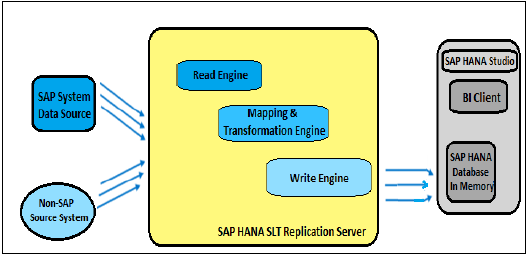
SLT复制的优势
SLT复制方法允许将数据从多个源系统复制到一个HANA系统,以及从一个源系统复制到多个HANA系统。
SAP LT采用触发器机制。它对源系统的性能没有可衡量的影响。
它还在加载到HANA数据库之前提供数据转换和过滤功能。
它允许实时数据复制,仅将相关数据从SAP和非SAP源系统复制到HANA。
它与HANA系统和HANA studio完全集成。
在ECC系统中创建受信任的RFC连接
在您的源SAP系统AA1上,您想设置一个指向目标系统BB1的受信任RFC。完成后,这意味着当您登录到AA1并且您的用户在BB1中拥有足够的授权时,您可以使用RFC连接并登录到BB1,而无需重新输入用户名和密码。
使用两个SAP系统之间的RFC信任/可信关系,来自受信任系统到可信系统的RFC,登录到可信系统不需要密码。
使用SAP登录打开SAP ECC系统。输入事务代码sm59 → 这是创建新的受信任RFC连接的事务代码 → 点击第3个图标打开新的连接向导 → 点击创建,将打开一个新窗口。
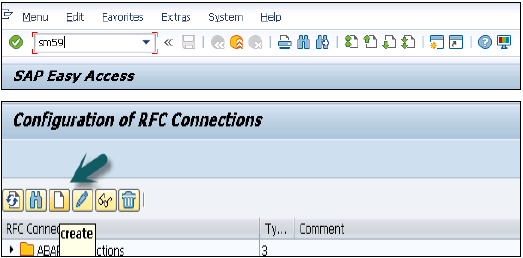
RFC目标ECCHANA(输入RFC目标的名称)连接类型 - 3(对于ABAP系统)
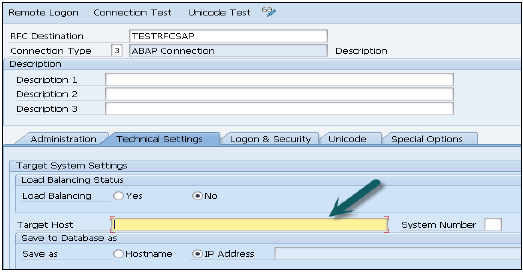
转到技术设置
输入目标主机 - ECC系统名称、IP并输入系统编号。
转到“登录和安全”选项卡,输入语言、客户端、ECC系统用户名和密码。
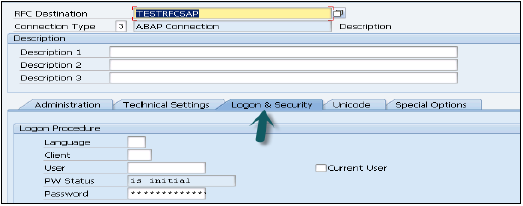
点击顶部的“保存”选项。

点击“测试连接”,它将成功测试连接。
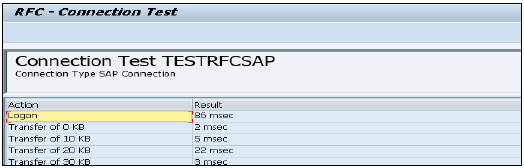
配置RFC连接
运行事务 - ltr(配置RFC连接)→ 将打开新的浏览器 → 输入ECC系统用户名和密码并登录。

点击“新建”→ 将打开新窗口 → 输入配置名称 → 点击“下一步” → 输入RFC目标(之前创建的连接名称),使用搜索选项,选择名称并点击“下一步”。
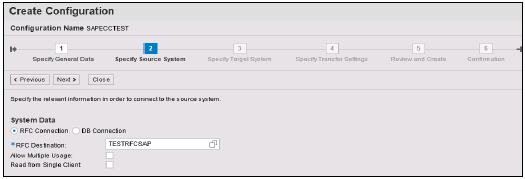
在“指定目标系统”中,输入HANA系统管理员用户名和密码、主机名、实例号并点击“下一步”。输入数据传输作业数,例如007(不能为000)→ 下一步 → 创建配置。
现在转到HANA Studio使用此连接 -
转到HANA Studio → 点击“数据供应”→ 选择HANA系统
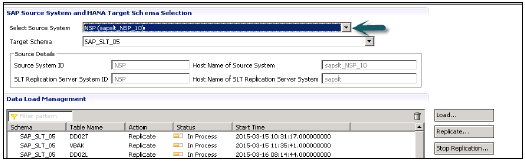
选择源系统(受信任RFC连接的名称)和要加载ECC系统表的目标模式名称。选择要移动到HANA数据库的表 → 添加 → 完成。

选定的表将移动到HANA数据库下的选定模式。
SAP HANA - 基于 ETL 的复制
基于SAP HANA ETL的复制使用SAP Data Services将数据从SAP或非SAP源系统迁移到目标HANA数据库。BODS系统是一个ETL工具,用于将数据从源系统提取、转换和加载到目标系统。
它能够在应用程序层读取业务数据。您需要在Data Services中定义数据流,安排复制作业并在Data Services设计器中的数据存储中定义源系统和目标系统。
如何使用基于SAP HANA Data Services ETL的复制?
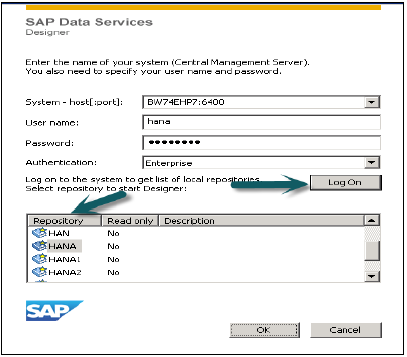
登录Data Services Designer(选择资源库)→ 创建数据存储
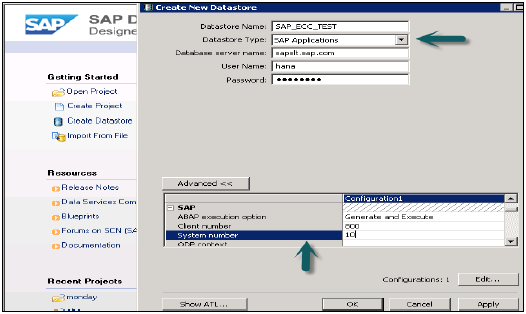
对于SAP ECC系统,选择数据库为SAP应用程序,输入ECC服务器名称、ECC系统的用户名和密码,“高级”选项卡选择详细信息,如实例号、客户端号等,然后应用。
此数据存储将位于本地对象库下,如果展开此库,则其中不包含任何表。
右键单击“表”→ “按名称导入”→ 输入要从ECC系统导入的ECC表(MARA是ECC系统中的默认表)→ “导入”→ 现在展开“表”→ MARA → 右键单击“查看数据”。如果显示数据,则数据存储连接正常。
现在,要选择目标系统为HANA数据库,请创建一个新的数据存储。创建数据存储 → 数据存储名称SAP_HANA_TEST → 数据存储类型(数据库)→ 数据库类型SAP HANA → 数据库版本HANA 1.x。
输入HANA服务器名称、HANA系统的用户名和密码,然后单击“确定”。
此数据存储将添加到本地对象库。如果要将数据从源表移动到HANA数据库中的特定表,则可以添加表。请注意,目标表的数据类型应与源表相似。
创建复制作业
创建一个新项目 → 输入项目名称 → 右键单击项目名称 → 新批处理作业 → 输入作业名称。
从右侧选项卡中,选择工作流 → 输入工作流名称 → 双击将其添加到批处理作业下 → 输入数据流 → 输入数据流名称 → 双击将其添加到项目区域中的批处理作业下,点击顶部的“保存全部”选项。

将表从第一个数据存储ECC(MARA)拖到工作区。选择它并右键单击 → 添加新 → 模板表,以在HANA DB中创建具有类似数据类型的新表 → 输入表名、数据存储ECC_HANA_TEST2 → 所有者名称(模式名称)→ 确定
将表拖到前面并连接两个表 → 保存全部。现在转到批处理作业 → 右键单击 → 执行 → 是 → 确定
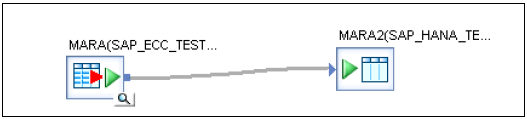
执行复制作业后,您将收到作业已成功完成的确认。
转到HANA studio → 展开模式 → 表 → 验证数据。这是批处理作业的手动执行。
批处理作业的调度
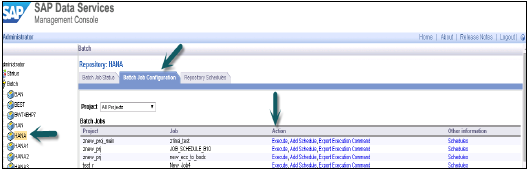
您还可以通过转到Data Services Management控制台来调度批处理作业。登录Data Services Management控制台。
从左侧选择资源库 → 导航到“批处理作业配置”选项卡,您将在其中看到作业列表 → 在要调度的作业上 → 点击“添加调度” → 输入“调度名称”并设置参数(时间、日期、重复等)适当,然后点击“应用”。
SAP HANA - 基于日志的复制
这在HANA系统中也称为Sybase复制。此复制方法的主要组件是Sybase复制代理(它是SAP源应用程序系统的一部分)、复制代理和要在SAP HANA系统中实现的Sybase复制服务器。
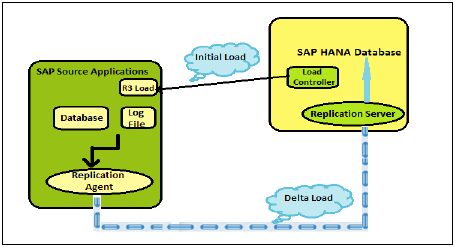
Sybase复制方法中的初始加载由加载控制器启动,并由SAP HANA中的管理员触发。它通知R3加载将初始加载传输到HANA数据库。源系统上的R3加载导出源系统中所选表的数,并将此数据传输到HANA系统中的R3加载组件。目标系统上的R3加载将数据导入SAP HANA数据库。
SAP主机代理管理源系统和目标系统之间的身份验证,它是源系统的一部分。Sybase复制代理在初始加载时检测任何数据更改,并确保完成每个更改。当源系统中表的条目发生更改、更新和删除时,会创建一个表日志。此表日志将数据从源系统移动到HANA数据库。
初始加载后的增量复制
一旦初始加载和复制完成,增量复制就会实时捕获源系统中的数据更改。使用上述方法,源系统中的所有进一步更改都将被捕获并从源系统复制到HANA数据库。
此方法是SAP HANA复制的初始产品的一部分,但由于许可问题和复杂性,不再定位/支持,SLT也提供相同的功能。
注意 - 此方法仅支持SAP ERP系统作为数据源和DB2作为数据库。
SAP HANA - DXC 方法
直接提取器连接数据复制通过与SAP HANA的简单HTTP(S)连接,重用通过SAP Business Suite系统内置的现有提取、转换和加载机制。它是一种批处理驱动的数据复制技术。它被认为是具有有限数据提取能力的提取、转换和加载方法。
DXC是一个批处理驱动的过程,在许多情况下,以特定间隔使用DXC进行数据提取就足够了。您可以设置批处理作业执行的间隔,例如:每20分钟,在大多数情况下,以特定时间间隔使用这些批处理作业提取数据就足够了。
DXC数据复制的优点
此方法不需要在SAP HANA系统环境中添加额外的服务器或应用程序。
DXC方法简化了SAP HANA中的数据建模,因为数据在应用源系统中的所有业务提取器逻辑后发送到HANA。
它加快了SAP HANA实施项目的时间表
它为SAP HANA提供了来自SAP Business Suite的语义丰富的的数据
它通过与SAP HANA的简单HTTP(S)连接,重用SAP Business Suite系统中内置的现有专有提取、转换和加载机制。
DXC数据复制的局限性
数据源必须具有预定义的提取、转换和加载机制,如果没有,我们需要定义一个。
它需要基于Net Weaver 7.0或更高版本的Business Suite系统,至少具有以下SP:Release 700 SAPKW70021(SP堆栈19,2008年11月起)。
配置DXC数据复制
在HANA Studio的“配置”选项卡中启用XS Engine服务 - 转到系统HANA studio的“管理员”选项卡。转到“配置”→ xsengine.ini并将实例值设置为1。
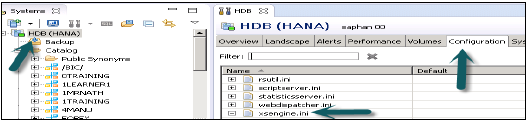
在HANA Studio中启用ICM Web Dispatcher服务 - 转到“配置”→ webdispatcher.ini并将实例值设置为1。
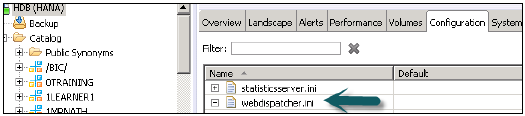
它在HANA系统中启用ICM Web Dispatcher服务。Web Dispatcher使用ICM方法在HANA系统中读取和加载数据。
设置SAP HANA直接提取器连接 - 将DXC交付单元下载到SAP HANA。您可以在/usr/sap/HDB/SYS/global/hdb/content位置导入单元。
使用SAP HANA内容节点中的“导入对话框”导入单元 → 配置XS应用程序服务器以利用DXC → 将application_container值更改为libxsdxc
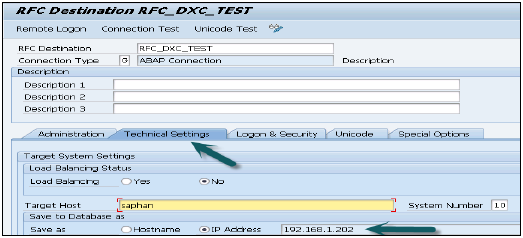
在SAP BW中创建HTTP连接 - 现在我们需要使用事务代码SM59在SAP BW中创建http连接。
输入参数 - 输入RFC连接的名称、HANA主机名和<实例号>
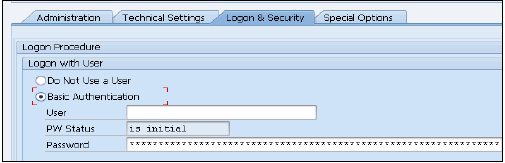
在“登录安全”选项卡中,使用基本身份验证方法输入在HANA studio中创建的DXC用户 -
设置HANA的BW参数 - 需要使用事务SE 38设置BW中的以下参数。参数列表 -
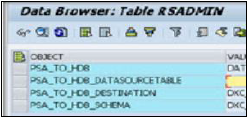
PSA_TO_HDB_DESTINATION - 我们需要提到我们需要将传入数据移动到哪里(使用SM 59创建的连接名称)
PSA_TO_HDB_SCHEMA - 将复制的数据需要分配到的模式
PSA_TO_HDB - GLOBAL将所有数据源复制到HANA。SYSTEM – 指定要使用DXC的客户端。DATASOURCE – 仅使用指定的Data Source
PSA_TO_HDB_DATASOURCETABLE - 需要提供包含用于DXC的数据源列表的表名。
数据源复制
使用RSA5在ECC中安装数据源。
使用指定的应用程序组件复制元数据(数据源版本需要为7.0,如果我们有3.5版本的数据源,我们需要迁移它。在SAP BW中激活数据源。一旦数据源在SAP BW中被激活,它将在定义的模式下创建以下表 -
/BIC/A<数据源>00 – IMDSO活动表
/BIC/A<数据源>40 –IMDSO激活队列
/BIC/A<数据源>70 – 记录模式处理表
/BIC/A<数据源>80 – 请求和数据包ID信息表
/BIC/A<数据源>A0 – 请求时间戳表
RSODSO_IMOLOG - 与IMDSO相关的表。存储与DXC相关的所有数据源的信息。
现在数据已成功加载到表/BIC/A0FI_AA_2000中(一旦激活)。
SAP HANA - CTL 方法
打开SAP HANA Studio → 在“目录”选项卡下创建模式。<从这里开始>
准备数据并将其保存为csv格式。现在创建一个扩展名为“ctl”的文件,语法如下:
--------------------------------------- import data into table Schema."Table name" from 'file.csv' records delimited by '\n' fields delimited by ',' Optionally enclosed by '"' error log 'table.err' -----------------------------------------
将此“ctl”文件传输到FTP并执行此文件以导入数据:
从 ‘table.ctl’ 导入
通过以下路径检查表中的数据:HANA Studio → 目录 → 模式 → 表格 → 查看内容
SAP HANA - MDX 提供程序
MDX Provider 用于连接 MS Excel 到 SAP HANA 数据库系统。它提供驱动程序以连接 HANA 系统到 Excel,并进一步用于数据建模。您可以使用 Microsoft Office Excel 2010/2013 来连接 32 位和 64 位 Windows 系统下的 HANA。
SAP HANA 支持两种查询语言:SQL 和 MDX。两种语言都可以使用:JDBC 和 ODBC 用于 SQL,ODBO 用于 MDX 处理。Excel 数据透视表使用 MDX 作为查询语言来读取 SAP HANA 系统中的数据。MDX 定义为 Microsoft 的 ODBO (OLE DB for OLAP) 规范的一部分,用于数据选择、计算和布局。MDX 支持多维数据模型,并支持报表和分析需求。
MDX 提供程序允许 SAP 和非 SAP 报表工具使用在 HANA studio 中定义的信息视图。现有的物理表和模式构成了信息模型的数据基础。
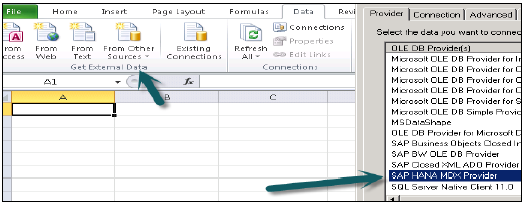
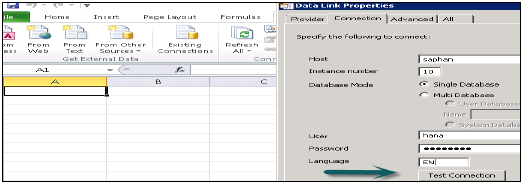
一旦您从要连接的数据源列表中选择 SAP HANA MDX 提供程序,请传入 HANA 系统详细信息,例如主机名、实例编号、用户名和密码。
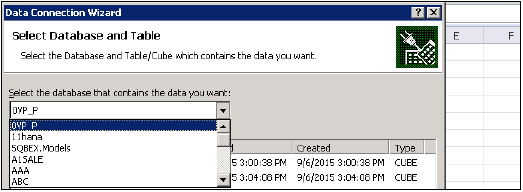
连接成功后,您可以选择包名称 → HANA 建模视图来生成数据透视表。
MDX 与 HANA 数据库紧密集成。HANA 数据库的连接和会话管理处理由 HANA 执行的语句。当执行这些语句时,它们由 MDX 接口解析,并为每个 MDX 语句生成一个计算模型。此计算模型创建一个执行计划,该计划生成 MDX 的标准结果。这些结果直接由 OLAP 客户端使用。
要与 HANA 数据库建立 MDX 连接,需要 HANA 客户端工具。您可以从 SAP 市场下载此客户端工具。安装 HANA 客户端后,您将在 MS Excel 的数据源列表中看到 SAP HANA MDX 提供程序选项。
SAP HANA - 监控与警报
SAP HANA 警报监控用于监控 HANA 系统中运行的系统资源和服务的运行状况。警报监控用于处理关键警报,例如 CPU 使用率、磁盘已满、文件系统达到阈值等。HANA 系统的监控组件持续收集有关 HANA 数据库所有组件的健康状况、使用情况和性能的信息。当任何组件超过设定的阈值时,它会发出警报。
HANA 系统中发出的警报优先级指示问题的严重性,它取决于对组件执行的检查。例如:如果 CPU 使用率为 80%,则会发出低优先级警报。但是,如果它达到 96%,系统将发出高优先级警报。
系统监控器是监控 HANA 系统和验证所有 SAP HANA 系统组件可用性的最常用方法。系统监控器用于检查 HANA 系统的所有关键组件和服务。
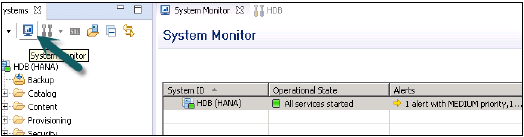
您还可以深入了解管理编辑器中单个系统的详细信息。它显示有关数据磁盘、日志磁盘、跟踪磁盘以及资源使用情况的警报(及其优先级)的信息。
管理员编辑器中的“警报”选项卡用于检查 HANA 系统中当前和所有警报。
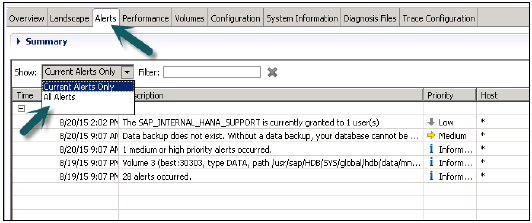
它还显示警报发出时间、警报描述、警报优先级等。
SAP HANA 监控仪表板显示系统健康状况和配置的关键方面:
- 高优先级和中优先级警报。
- 内存和 CPU 使用率
- 数据备份
SAP HANA - 持久层
SAP HANA 数据库持久层负责管理所有事务的日志,以提供标准数据备份和系统恢复功能。
它确保数据库可以在重新启动或系统崩溃后恢复到最近提交的状态,并且事务已完全执行或完全撤消。SAP HANA 持久层是索引服务器的一部分,它具有 HANA 系统的数据和事务日志卷,并且内存中的数据会定期保存到这些卷中。HANA 系统中有一些服务具有自己的持久性。它还为自上次保存点以来的所有数据库事务提供保存点和日志。
为什么 SAP HANA 数据库需要持久层?
主内存是易失性的,因此在重新启动或断电期间数据会丢失。
数据需要存储在持久介质中。
提供备份和恢复功能。
它确保数据库在重新启动后恢复到最近提交的状态,并且事务要么完全执行,要么完全撤消。
数据和事务日志卷
数据库始终可以恢复到其最新状态,以确保定期将对数据库中数据的这些更改复制到磁盘。包含数据更改和某些事务事件的日志文件也定期保存到磁盘。系统的日志和数据存储在日志卷中。
数据卷存储 SQL 数据和撤消日志信息,以及 SAP HANA 信息建模数据。这些信息存储在数据页中,称为块。这些块会定期写入数据卷,这称为保存点。
日志卷存储有关数据更改的信息。在两个日志点之间进行的更改将写入日志卷,并称为日志条目。事务提交时,它们将保存到日志缓冲区。
保存点
在 SAP HANA 数据库中,更改的数据会自动从内存保存到磁盘。这些定期间隔称为保存点,默认情况下,它们设置为每五分钟发生一次。SAP HANA 数据库中的持久层定期执行这些保存点操作。在此操作期间,更改的数据将写入磁盘,重做日志也将保存到磁盘。
属于保存点的数据指示磁盘上数据的稳定状态,并且保留在那里,直到下一个保存点操作完成。重做日志条目将为对持久数据的全部更改写入日志卷。如果数据库重新启动,则可以从数据卷读取上次完成的保存点的数据,并从日志卷写入重做日志条目。
保存点的频率可以通过 global.ini 文件配置。保存点可以由其他操作启动,例如数据库关闭或系统重新启动。您还可以通过执行以下命令来运行保存点:
ALTER System SAVEPOINT
要将数据和重做日志保存到日志卷,您应确保有足够的磁盘空间来捕获这些数据,否则系统将发出磁盘已满事件,数据库将停止工作。
在 HANA 系统安装期间,以下默认目录将创建为数据和日志卷的存储位置:
- /usr/sap/
/SYS/global/hdb/data - /usr/sap/
/SYS/global/hdb/log
这些目录在 global.ini 文件中定义,可以在以后更改。
请注意,保存点不会影响在 HANA 系统中执行的事务的性能。在保存点操作期间,事务将继续正常运行。如果 HANA 系统在合适的硬件上运行,则保存点对系统性能的影响可以忽略不计。
SAP HANA - 备份与恢复
SAP HANA 备份和恢复用于执行 HANA 系统备份以及在任何数据库故障的情况下恢复系统。
概述选项卡
它显示当前正在运行的数据备份和上次成功的数据备份的状态。
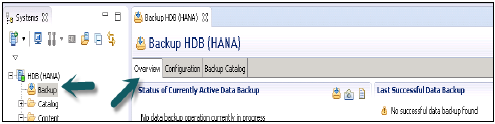
“立即备份”选项可用于运行数据备份向导。
配置选项卡
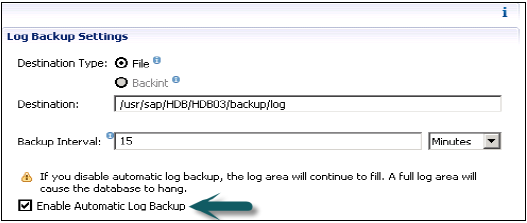
它显示备份间隔设置、基于文件的数据库备份设置和基于日志的数据库备份设置。

备份间隔设置
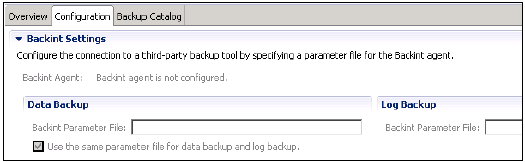
Backint 设置提供了一个选项,可以使用第三方工具进行数据和日志备份,并配置备份代理。
通过为 Backint 代理指定参数文件来配置与第三方备份工具的连接。
基于文件和日志的数据备份设置
基于文件的数据库备份设置显示要在 HANA 系统上保存数据备份的文件夹。您可以更改备份文件夹。
您还可以限制数据备份文件的大小。如果系统数据备份超过此设置的文件大小,它将拆分为多个文件。
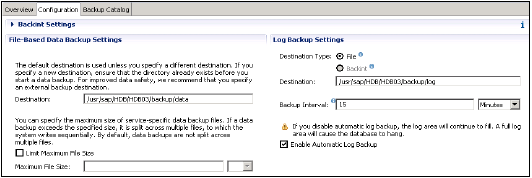
日志备份设置显示要在外部服务器上保存日志备份的目标文件夹。您可以为日志备份选择目标类型
文件 - 确保系统中有足够的存储空间来存储备份
Backint - 是文件系统上存在的特殊命名管道,但不需要磁盘空间。
您可以从下拉菜单中选择备份间隔。它表示在写入新的日志备份之前可以经过的最长时间。备份间隔:可以是秒、分钟或小时。
启用自动日志备份选项:这有助于保持日志区域为空。如果您禁用此功能,日志区域将继续填充,这可能导致数据库挂起。
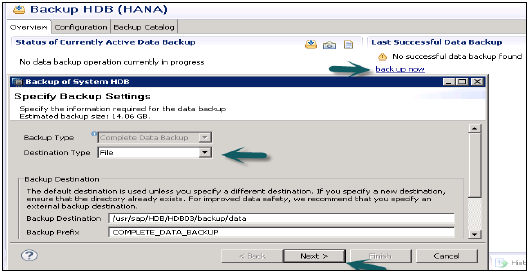
打开备份向导 - 以运行系统备份。
备份向导用于指定备份设置。它显示备份类型、目标类型、备份目标文件夹、备份前缀、备份大小等。
单击下一步 → 查看备份设置 → 完成
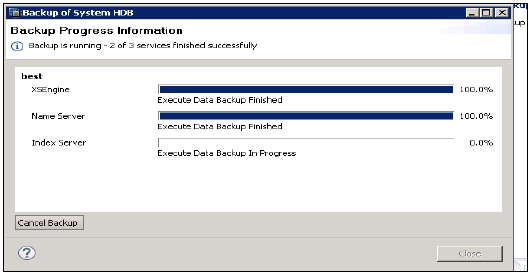
它运行系统备份,并显示每个服务器完成备份所需的时间。
HANA 系统恢复
要恢复 SAP HANA 数据库,需要关闭数据库。因此,在恢复期间,最终用户或 SAP 应用程序无法访问数据库。
在以下情况下需要恢复 SAP HANA 数据库:
数据区域中的磁盘不可用,或者日志区域中的磁盘不可用。
由于逻辑错误,需要将数据库重置到特定时间点上的状态。
您想要创建数据库的副本。
如何恢复 HANA 系统?
选择 HANA 系统 → 右键单击 → 备份和恢复 → 恢复系统
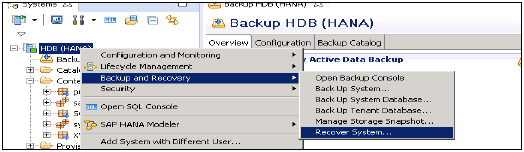
HANA 系统中的恢复类型
最新状态 - 用于将数据库恢复到尽可能接近当前时间的时刻。对于此恢复,自上次数据备份以来必须提供数据备份和日志备份,并且需要日志区域来执行上述类型的恢复。
特定时间点 - 用于将数据库恢复到特定时间点。对于此恢复,自上次数据备份以来必须提供数据备份和日志备份,并且需要日志区域来执行上述类型的恢复
特定数据备份 − 用于将数据库恢复到指定的数据备份。此类恢复选项需要特定数据备份。
特定日志位置 − 此恢复类型是高级选项,可在之前的恢复失败的特殊情况下使用。
注意 − 要运行恢复向导,您必须拥有 HANA 系统的管理员权限。
SAP HANA - 高可用性
SAP HANA 提供用于应对系统故障和软件错误的业务连续性和灾难恢复机制。HANA 系统中的高可用性定义了一套实践,有助于在灾难情况下(例如数据中心的电源故障、火灾、洪水等自然灾害或任何硬件故障)实现业务连续性。
SAP HANA 高可用性提供容错能力,使系统能够在中断后恢复系统操作,并将业务损失降至最低。
下图显示了 HANA 系统中高可用性的阶段 −
第一阶段是为故障做好准备。故障可以自动检测到,也可以通过管理操作检测到。数据备份完毕后,备用系统接管操作。恢复过程包括修复故障系统和将原始系统恢复到之前的配置。
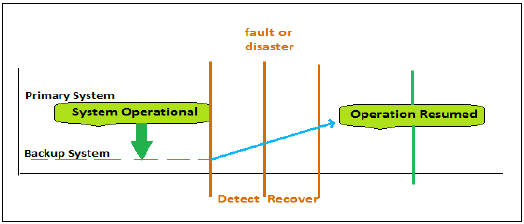
为了在 HANA 系统中实现高可用性,关键在于包含额外的组件,这些组件在其他组件发生故障时并非必需的功能和使用。它包括硬件冗余、网络冗余和数据中心冗余。SAP HANA 提供以下几个级别的硬件和软件冗余 −
HANA 系统硬件冗余
SAP HANA 设备供应商提供多层冗余硬件、软件和网络组件,例如冗余电源和风扇、纠错内存、完全冗余的网络交换机和路由器以及不间断电源 (UPS)。磁盘存储系统保证即使在电源故障的情况下也能写入数据,并使用条带化和镜像功能来提供冗余,以便从磁盘故障中自动恢复。
SAP HANA 软件冗余
SAP HANA 基于 SUSE Linux Enterprise 11 for SAP,并包含安全预配置。
SAP HANA 系统软件包括看门狗功能,该功能可在检测到停止(被终止或崩溃)的情况下自动重启已配置的服务(索引服务器、名称服务器等)。
SAP HANA 持久性冗余
SAP HANA 提供事务日志、保存点和快照的持久性,以支持系统重启和从故障中恢复,同时最大限度地减少延迟且不会丢失数据。
HANA 系统备用和故障转移
SAP HANA 系统包含单独的备用主机,用于在主系统发生故障时进行故障转移。这通过减少中断后的恢复时间来提高 HANA 系统的可用性。
SAP HANA - 日志配置
SAP HANA 系统将所有更改应用程序数据或数据库目录的事务记录到日志条目中,并将它们存储在日志区域中。它使用日志区域中的这些日志条目来回滚或重复 SQL 语句。日志文件位于 HANA 系统中,可以通过 HANA studio 在管理员编辑器下的“诊断文件”页面访问。
在日志备份过程中,只有日志段的实际数据才会从日志区域写入特定于服务的日志备份文件或第三方备份工具。
系统故障后,您可能需要从日志备份中重做日志条目,以将数据库恢复到所需状态。
如果具有持久性的数据库服务停止,务必确保将其重新启动,否则只能恢复到服务停止之前的某个点。
配置日志备份超时
如果在此间隔内发生了提交,则日志备份超时将确定备份日志段的间隔。您可以使用 SAP HANA studio 中的备份控制台配置日志备份超时 −
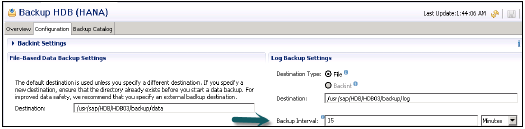
您也可以在 global.ini 配置文件中配置 log_backup_timeout_s 间隔。
安装 SAP HANA 系统后,“文件”日志备份和“NORMAL”备份模式是自动日志备份功能的默认设置。只有执行了至少一个完整的数据备份后,自动日志备份才有效。
执行第一次完整数据备份后,自动日志备份功能处于活动状态。可以使用 SAP HANA studio 启用/禁用自动日志备份功能。建议保持启用自动日志备份,否则日志区域将继续填充。日志区域已满会导致 HANA 系统数据库冻结。
您也可以更改 global.ini 配置文件 persistence 部分中的 enable_auto_log_backup 参数。
SAP HANA - SQL 概述
SQL 代表结构化查询语言。
它是一种与数据库通信的标准化语言。SQL 用于检索、存储或操作数据库中的数据。
SQL 语句执行以下功能 −
- 数据定义和操作
- 系统管理
- 会话管理
- 事务管理
- 模式定义和操作
允许开发人员将数据推入数据库的 SQL 扩展集称为SQL 脚本。
数据操纵语言 (DML)
DML 语句用于管理模式对象中的数据。一些示例 −
SELECT − 从数据库中检索数据
INSERT − 将数据插入表中
UPDATE − 更新表中现有数据
数据定义语言 (DDL)
DDL 语句用于定义数据库结构或模式。一些示例 −
CREATE − 在数据库中创建对象
ALTER − 更改数据库的结构
DROP − 从数据库中删除对象
数据控制语言 (DCL)
DCL 语句的一些示例是 −
GRANT − 向用户授予对数据库的访问权限
REVOKE − 撤销使用 GRANT 命令授予的访问权限
为什么我们需要 SQL?
当我们在 SAP HANA Modeler 中创建信息视图时,我们是在某些 OLTP 应用程序之上创建的。所有这些后端都在 SQL 上运行。数据库只理解这种语言。
要测试我们的报告是否满足业务需求,如果输出符合需求,我们必须在数据库中运行 SQL 语句。
HANA 计算视图可以通过两种方式创建 - 图形方式或使用 SQL 脚本。当我们创建更复杂的计算视图时,我们可能需要使用直接 SQL 脚本。
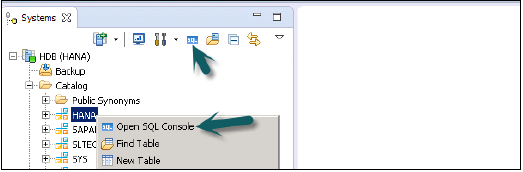
如何在 HANA Studio 中打开 SQL 控制台?
选择 HANA 系统,然后单击系统视图中的 SQL 控制台选项。您也可以通过右键单击“目录”选项卡或任何模式名称来打开 SQL 控制台。
SAP HANA 可以同时充当关系数据库和 OLAP 数据库。当我们在 HANA 上使用 BW 时,我们在 BW 和 HANA 中创建多维数据集,它们充当关系数据库并始终生成 SQL 语句。但是,当我们使用 OLAP 连接直接访问 HANA 视图时,它将充当 OLAP 数据库,并将生成 MDX。
SAP HANA - 数据类型
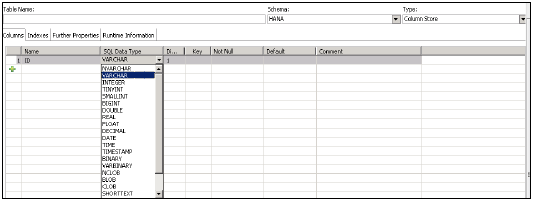
您可以使用 create table 选项在 SAP HANA 中创建行存储表或列存储表。可以通过执行数据定义 create table 语句或使用 HANA studio 中的图形选项来创建表。
创建表时,还需要在其中定义属性。
在 HANA Studio SQL 控制台中创建表的 SQL 语句 −
Create column Table TEST ( ID INTEGER, NAME VARCHAR(10), PRIMARY KEY (ID) );
使用 GUI 选项在 HANA studio 中创建表 −
创建表时,需要定义列的名称和 SQL 数据类型。“维度”字段指示值的长度,“键”选项用于将其定义为主键。
SAP HANA 支持表中的以下数据类型 −
SAP HANA 支持 7 类 SQL 数据类型,这取决于您必须在列中存储的数据类型。
- 数值型
- 字符/字符串
- 布尔型
- 日期时间型
- 二进制型
- 大型对象
- 多值型
下表列出了每类数据类型 −

日期时间型
这些数据类型用于在 HANA 数据库中的表中存储日期和时间。
DATE − 数据类型包含年份、月份和日期信息,用于表示列中的日期值。日期数据类型的默认格式为 YYYY-MM-DD。
TIME − 数据类型包含 HANA 数据库中表中的小时、分钟和秒值。时间数据类型的默认格式为 HH:MI:SS。
SECONDDATE − 数据类型包含 HANA 数据库中表中的年份、月份、日期、小时、分钟、秒值。SECONDDATE 数据类型的默认格式为 YYYY-MM-DD HH:MM:SS。
TIMESTAMP − 数据类型包含 HANA 数据库中表中的日期和时间信息。TIMESTAMP 数据类型的默认格式为 YYYY-MM-DD HH:MM:SS:FFn,其中 FFn 表示秒的分数。
数值型
TinyINT − 存储 8 位无符号整数。最小值:0,最大值:255
SMALLINT − 存储 16 位有符号整数。最小值:-32,768,最大值:32,767
Integer − 存储 32 位有符号整数。最小值:-2,147,483,648,最大值:2,147,483,648
BIGINT − 存储 64 位有符号整数。最小值:-9,223,372,036,854,775,808,最大值:9,223,372,036,854,775,808
SMALL − DECIMAL 和 DECIMAL:最小值:-10^38 +1,最大值:10^38 -1
REAL − 最小值:-3.40E + 38,最大值:3.40E + 38
DOUBLE − 存储 64 位浮点数。最小值:-1.7976931348623157E308,最大值:1.7976931348623157E308
布尔型
布尔数据类型存储布尔值,即 TRUE、FALSE
字符型
Varchar − 最大 8000 个字符。
Nvarchar − 最大长度为 4000 个字符
ALPHANUM − 存储字母数字字符。整数的值介于 1 到 127 之间。
SHORTTEXT − 存储可变长度的字符字符串,支持文本搜索功能和字符串搜索功能。
二进制型
二进制类型用于存储二进制数据的字节。
VARBINARY − 以字节为单位存储二进制数据。最大整数长度介于 1 和 5000 之间。
大型对象
LARGEOBJECTS 用于存储大量数据,例如文本文档和图像。
NCLOB − 存储大型 UNICODE 字符对象。
BLOB − 存储大量二进制数据。
CLOB − 存储大量 ASCII 字符数据。
TEXT − 它启用文本搜索功能。此数据类型只能为列表定义,不能为行存储表定义。
BINTEXT − 支持文本搜索功能,但也可以插入二进制数据。
多值
多值数据类型用于存储具有相同数据类型的多个值的集合。
数组
数组存储具有相同数据类型的多个值的集合。它们也可以包含空值。
SAP HANA - SQL 运算符
运算符是特殊字符,主要用于 SQL 语句的 WHERE 子句中执行操作,例如比较和算术运算。它们用于在 SQL 查询中传递条件。
HANA 中 SQL 语句可以使用以下运算符类型:
- 算术运算符
- 比较/关系运算符
- 逻辑运算符
- 集合运算符
算术运算符
算术运算符用于执行简单的计算函数,例如加法、减法、乘法、除法和百分比。
| 运算符 | 描述 |
|---|---|
| + | 加法 − 将运算符两侧的值相加 |
| - | 减法 − 从左操作数中减去右操作数 |
| * | 乘法 − 将运算符两侧的值相乘 |
| / | 除法 − 将左操作数除以右操作数 |
| % | 模数 − 将左操作数除以右操作数并返回余数 |
比较运算符
比较运算符用于比较 SQL 语句中的值。
| 运算符 | 描述 |
|---|---|
| = | 检查两个操作数的值是否相等,如果相等,则条件为真。 |
| != | 检查两个操作数的值是否不相等,如果不相等,则条件为真。 |
| <> | 检查两个操作数的值是否不相等,如果不相等,则条件为真。 |
| > | 检查左操作数的值是否大于右操作数的值,如果是,则条件为真。 |
| < | 检查左操作数的值是否小于右操作数的值,如果是,则条件为真。 |
| >= | 检查左操作数的值是否大于或等于右操作数的值,如果是,则条件为真。 |
| <= | 检查左操作数的值是否小于或等于右操作数的值,如果是,则条件为真。 |
| !< | 检查左操作数的值是否不小于右操作数的值,如果是,则条件为真。 |
| !> | 检查左操作数的值是否不大于右操作数的值,如果是,则条件为真。 |
逻辑运算符
逻辑运算符用于在 SQL 语句中传递多个条件,或用于操作条件的结果。
| 运算符 | 描述 |
|---|---|
| ALL | ALL 运算符用于将值与另一个值集中的所有值进行比较。 |
| AND | AND 运算符允许 SQL 语句的 WHERE 子句中存在多个条件。 |
| ANY | ANY 运算符用于根据条件将值与列表中任何适用的值进行比较。 |
| BETWEEN | BETWEEN 运算符用于搜索在给定最小值和最大值的一组值内的值。 |
| EXISTS | EXISTS 运算符用于搜索指定表中是否存在满足特定条件的行。 |
| IN | IN 运算符用于将值与已指定的文字值列表进行比较。 |
| LIKE | LIKE 运算符用于使用通配符运算符将值与类似的值进行比较。 |
| NOT | NOT 运算符反转与其一起使用的逻辑运算符的含义。例如:NOT EXISTS、NOT BETWEEN、NOT IN 等。这是一个否定运算符。 |
| OR | OR 运算符用于比较 SQL 语句 WHERE 子句中的多个条件。 |
| IS NULL | NULL 运算符用于将值与 NULL 值进行比较。 |
| UNIQUE | UNIQUE 运算符搜索指定表中每一行的唯一性(无重复)。 |
集合运算符
集合运算符用于将两个查询的结果组合成一个结果。两个表的的数据类型应该相同。
UNION − 它组合两个或多个 Select 语句的结果。但是它会消除重复的行。
UNION ALL − 此运算符类似于 Union,但它也显示重复的行。
INTERSECT − 交集运算用于组合两个 SELECT 语句,并返回两个 SELECT 语句中都存在的记录。对于 Intersect,两个表中的列数和数据类型必须相同。
MINUS − 减法运算组合两个 SELECT 语句的结果,并且只返回属于第一组结果的结果,并从第一个结果的输出中消除第二个语句中的行。
SAP HANA - SQL 函数
SAP HANA 数据库提供了各种 SQL 函数:
- 数值函数
- 字符串函数
- 全文函数
- 日期时间函数
- 聚合函数
- 数据类型转换函数
- 窗口函数
- 序列数据函数
- 杂项函数
数值函数
这些是 SQL 中的内置数值函数,用于脚本编写。它接受数值或包含数字字符的字符串,并返回数值。
ABS − 它返回数值参数的绝对值。
Example − SELECT ABS (-1) "abs" FROM TEST; abs 1
ACOS、ASIN、ATAN、ATAN2(这些函数返回参数的三角函数值)
BINTOHEX − 它将二进制值转换为十六进制值。
BITAND − 它对传入参数的位执行 AND 运算。
BITCOUNT − 它计算参数中已设置位的数量。
BITNOT − 它对参数的位执行按位 NOT 运算。
BITOR − 它对传入参数的位执行 OR 运算。
BITSET − 用于从 <start_bit> 位置设置 <target_num> 中的位为 1。
BITUNSET − 用于从 <start_bit> 位置设置 <target_num> 中的位为 0。
BITXOR − 它对传入参数的位执行 XOR 运算。
CEIL − 它返回大于或等于传入值的首个整数。
COS、COSH、COT(这些函数返回参数的三角函数值)
EXP − 它返回自然对数 e 的底数提升到传入值的幂的结果。
FLOOR − 它返回不大于数值参数的最大整数。
HEXTOBIN − 它将十六进制值转换为二进制值。
LN − 它返回参数的自然对数。
LOG − 它返回传入正值的算法值。底数和对数值都应为正数。
还可以使用各种其他数值函数:MOD、POWER、RAND、ROUND、SIGN、SIN、SINH、SQRT、TAN、TANH、UMINUS
字符串函数
HANA 中可以使用各种 SQL 字符串函数以及 SQL 脚本。最常见的字符串函数包括:
ASCII − 它返回传入字符串的整数 ASCII 值。
CHAR − 它返回与传入 ASCII 值关联的字符。
CONCAT − 它是连接运算符,返回组合的传入字符串。
LCASE − 它将字符串的所有字符转换为小写。
LEFT − 它根据提到的值返回传入字符串的第一个字符。
LENGTH − 它返回传入字符串中的字符数。
LOCATE − 它返回子字符串在传入字符串中的位置。
LOWER − 它将字符串中的所有字符转换为小写。
NCHAR − 它返回具有传入整数值的 Unicode 字符。
REPLACE − 它在传入的原始字符串中搜索搜索字符串的所有出现,并用替换字符串替换它们。
RIGHT − 它返回提到字符串的最右边的传入值字符。
UPPER − 它将传入字符串中的所有字符转换为大写。
UCASE − 它与 UPPER 函数相同。它将传入字符串中的所有字符转换为大写。
其他可使用的字符串函数包括:LPAD、LTRIM、RTRIM、STRTOBIN、SUBSTR_AFTER、SUBSTR_BEFORE、SUBSTRING、TRIM、UNICODE、RPAD、BINTOSTR
日期时间函数
HANA 中的 SQL 脚本可以使用各种日期时间函数。最常见的日期时间函数包括:
CURRENT_DATE − 它返回当前本地系统日期。
CURRENT_TIME − 它返回当前本地系统时间。
CURRENT_TIMESTAMP − 它返回当前本地系统时间戳详细信息 (YYYY-MM-DD HH:MM:SS:FF)。
CURRENT_UTCDATE − 它返回当前 UTC(格林威治平均日期)日期。
CURRENT_UTCTIME − 它返回当前 UTC(格林威治标准时间)时间。
CURRENT_UTCTIMESTAMP
DAYOFMONTH − 它返回参数中传入日期的月份中的整数天数。
HOUR − 它返回参数中传入时间的小时整数。
YEAR − 它返回传入日期的年份值。
其他日期时间函数包括:DAYOFYEAR、DAYNAME、DAYS_BETWEEN、EXTRACT、NANO100_BETWEEN、NEXT_DAY、NOW、QUARTER、SECOND、SECONDS_BETWEEN、UTCTOLOCAL、WEEK、WEEKDAY、WORKDAYS_BETWEEN、ISOWEEK、LAST_DAY、LOCALTOUTC、MINUTE、MONTH、MONTHNAME、ADD_DAYS、ADD_MONTHS、ADD_SECONDS、ADD_WORKDAYS
数据类型转换函数
这些函数用于将一种数据类型转换为另一种数据类型,或用于检查转换是否可行。
HANA 中 SQL 脚本中最常用的数据类型转换函数:
CAST − 它返回已转换为提供的 数据类型的表达式的值。
TO_ALPHANUM − 它将传入的值转换为 ALPHANUM 数据类型
TO_REAL − 它将值转换为 REAL 数据类型。
TO_TIME − 它将传入的时间字符串转换为 TIME 数据类型。
TO_CLOB − 它将值转换为 CLOB 数据类型。
其他类似的数据类型转换函数包括:TO_BIGINT、TO_BINARY、TO_BLOB、TO_DATE、TO_DATS、TO_DECIMAL、TO_DOUBLE、TO_FIXEDCHAR、TO_INT、TO_INTEGER、TO_NCLOB、TO_NVARCHAR、TO_TIMESTAMP、TO_TINYINT、TO_VARCHAR、TO_SECONDDATE、TO_SMALLDECIMAL、TO_SMALLINT
HANA SQL 脚本中还可以使用各种窗口和其他杂项函数。
Current_Schema − 它返回包含当前模式名称的字符串。
Session_User − 它返回当前会话的用户名
SAP HANA - SQL 表达式
表达式用于计算子句以返回值。HANA 中可以使用不同的 SQL 表达式:
- Case 表达式
- 函数表达式
- 聚合表达式
- 表达式中的子查询
Case 表达式
这用于在 SQL 表达式中传递多个条件。它允许在 SQL 语句中使用 IF-ELSE-THEN 逻辑而无需使用过程。
示例
SELECT COUNT( CASE WHEN sal < 2000 THEN 1 ELSE NULL END ) count1, COUNT( CASE WHEN sal BETWEEN 2001 AND 4000 THEN 1 ELSE NULL END ) count2, COUNT( CASE WHEN sal > 4000 THEN 1 ELSE NULL END ) count3 FROM emp;
此语句将根据传入的条件返回具有整数值的 count1、count2、count3。
函数表达式
函数表达式涉及在表达式中使用的 SQL 内置函数。
聚合表达式
聚合函数用于执行复杂的计算,例如求和、百分比、最小值、最大值、计数、众数、中位数等。聚合表达式使用聚合函数从多个值计算单个值。
聚合函数 − 求和、计数、最小值、最大值。这些应用于度量值(事实),并且始终与维度相关联。
常见的聚合函数包括:
- 平均值 ()
- 计数 ()
- 最大值 ()
- 中位数 ()
- 最小值 ()
- 众数 ()
- 求和 ()
表达式中的子查询
作为表达式的子查询是一个 Select 语句。当它用在表达式中时,它返回零个或单个值。
子查询用于返回将在主查询中用作条件的数据,以进一步限制要检索的数据。
子查询可与 SELECT、INSERT、UPDATE 和 DELETE 语句以及 =、<、>、>=、<=、IN、BETWEEN 等运算符一起使用。
子查询必须遵循一些规则:
子查询必须用括号括起来。
除非子查询的主查询有多个列用于比较子查询选择的列,否则子查询的SELECT语句中只能有一列。
子查询中不能使用ORDER BY,虽然主查询可以使用ORDER BY。可以使用GROUP BY 来实现子查询中ORDER BY的功能。
返回多行的子查询只能与多值运算符一起使用,例如IN运算符。
SELECT 列表中不能包含任何引用BLOB、ARRAY、CLOB或NCLOB值的表达式。
子查询不能直接包含在集合函数中。
BETWEEN运算符不能与子查询一起使用;但是,BETWEEN运算符可以在子查询中使用。
带有SELECT语句的子查询
子查询最常与SELECT语句一起使用。基本语法如下:
示例
SELECT * FROM CUSTOMERS WHERE ID IN (SELECT ID FROM CUSTOMERS WHERE SALARY > 4500) ;
+----+----------+-----+---------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+---------+----------+ | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+---------+----------+
SAP HANA - SQL 存储过程
过程允许您将SQL语句分组到单个块中。存储过程用于跨应用程序实现某些结果。用于执行某些特定任务的一组SQL语句和逻辑存储在SQL存储过程中。这些存储过程由应用程序执行以执行该任务。
存储过程可以以输出参数(整数或字符)或游标变量的形式返回数据。它还可以生成一组SELECT语句,这些语句由其他存储过程使用。
存储过程也用于性能优化,因为它包含一系列SQL语句,并且一组语句的结果决定了要执行的下一组语句。存储过程防止用户查看数据库中表的复杂性和细节。由于存储过程包含某些业务逻辑,因此用户需要执行或调用过程名称。
无需重复发出单个语句,而可以直接引用数据库过程。
创建过程的示例语句
Create procedure prc_name (in inp integer, out opt "EFASION"."ARTICLE_LOOKUP") as begin opt = select * from "EFASION"."ARTICLE_LOOKUP" where article_id = :inp ; end;
SAP HANA - SQL 序列
序列是一组按需生成的整数1、2、3…序列在数据库中经常使用,因为许多应用程序要求表中的每一行都包含唯一值,而序列提供了一种简单的方法来生成它们。
使用AUTO_INCREMENT列
在MySQL中使用序列最简单的方法是将列定义为AUTO_INCREMENT,并将其余的事情交给MySQL处理。
示例
尝试以下示例。这将创建表,然后在此表中插入几行,其中不需要提供记录ID,因为它由MySQL自动递增。
mysql> CREATE TABLE INSECT -> ( -> id INT UNSIGNED NOT NULL AUTO_INCREMENT, -> PRIMARY KEY (id), -> name VARCHAR(30) NOT NULL, # type of insect -> date DATE NOT NULL, # date collected -> origin VARCHAR(30) NOT NULL # where collected ); Query OK, 0 rows affected (0.02 sec) mysql> INSERT INTO INSECT (id,name,date,origin) VALUES -> (NULL,'housefly','2001-09-10','kitchen'), -> (NULL,'millipede','2001-09-10','driveway'), -> (NULL,'grasshopper','2001-09-10','front yard'); Query OK, 3 rows affected (0.02 sec) Records: 3 Duplicates: 0 Warnings: 0 mysql> SELECT * FROM INSECT ORDER BY id;
+----+-------------+------------+------------+ | id | name | date | origin | +----+-------------+------------+------------+ | 1 | housefly | 2001-09-10 | kitchen | | 2 | millipede | 2001-09-10 | driveway | | 3 | grasshopper | 2001-09-10 | front yard | +----+-------------+------------+------------+ 3 rows in set (0.00 sec)
获取AUTO_INCREMENT值
LAST_INSERT_ID()是一个SQL函数,因此您可以从任何了解如何发出SQL语句的客户端中使用它。否则,PERL和PHP脚本提供专用函数来检索最后一条记录的自动递增值。
PERL示例
使用mysql_insertid属性获取查询生成的AUTO_INCREMENT值。此属性可以通过数据库句柄或语句句柄访问,具体取决于您发出查询的方式。以下示例通过数据库句柄引用它:
$dbh->do ("INSERT INTO INSECT (name,date,origin)
VALUES('moth','2001-09-14','windowsill')");
my $seq = $dbh->{mysql_insertid};
PHP示例
发出生成AUTO_INCREMENT值的查询后,通过调用mysql_insert_id()检索该值:
mysql_query ("INSERT INTO INSECT (name,date,origin)
VALUES('moth','2001-09-14','windowsill')", $conn_id);
$seq = mysql_insert_id ($conn_id);
重新编号现有序列
可能有一种情况,您已从表中删除了许多记录,并且想要重新排序所有记录。这可以通过使用一个简单的技巧来完成,但是如果您的表与其他表具有连接,则应非常小心地执行此操作。
如果您确定必须重新排序AUTO_INCREMENT列,则执行此操作的方法是从表中删除该列,然后再次添加它。以下示例显示了如何使用此技术重新编号insect表中的id值:
mysql> ALTER TABLE INSECT DROP id; mysql> ALTER TABLE insect -> ADD id INT UNSIGNED NOT NULL AUTO_INCREMENT FIRST, -> ADD PRIMARY KEY (id);
从特定值开始序列
默认情况下,MySQL将从1开始序列,但您也可以在创建表时指定其他任何数字。以下是在MySQL中将序列从100开始的示例。
mysql> CREATE TABLE INSECT -> ( -> id INT UNSIGNED NOT NULL AUTO_INCREMENT = 100, -> PRIMARY KEY (id), -> name VARCHAR(30) NOT NULL, # type of insect -> date DATE NOT NULL, # date collected -> origin VARCHAR(30) NOT NULL # where collected );
或者,您可以创建表,然后使用ALTER TABLE设置初始序列值。
SAP HANA - SQL 触发器
触发器是存储程序,当某些事件发生时会自动执行或触发。实际上,触发器是编写为响应以下任何事件而执行的:
数据库操作(DML)语句(DELETE、INSERT或UPDATE)。
数据库定义(DDL)语句(CREATE、ALTER或DROP)。
数据库操作(SERVERERROR、LOGON、LOGOFF、STARTUP或SHUTDOWN)。
触发器可以在与事件关联的表、视图、模式或数据库上定义。
触发器的优点
触发器可以用于以下目的:
- 自动生成一些派生列值
- 强制参照完整性
- 事件日志记录和存储有关表访问的信息
- 审计
- 表的同步复制
- 强制安全授权
- 防止无效事务
SAP HANA - SQL 同义词
SQL同义词是数据库中表或模式对象的别名。它们用于保护客户端应用程序免受对对象名称或位置的更改的影响。
同义词允许应用程序独立于拥有该表的用户以及哪个数据库保存该表或对象而运行。
Create Synonym语句用于为表、视图、包、过程、对象等创建同义词。
示例
有一个位于Server1上的efashion的Customer表。要从Server2访问它,客户端应用程序必须使用Server1.efashion.Customer作为名称。现在我们更改Customer表的位置,客户端应用程序必须修改以反映此更改。
为了解决这些问题,我们可以在Server2上为Server1上的表创建Customer表的同义词Cust_Table。现在,客户端应用程序必须使用单部分名称Cust_Table来引用此表。现在,如果此表的位置发生更改,您必须修改同义词以指向该表的新位置。
由于没有ALTER SYNONYM语句,因此您必须删除同义词Cust_Table,然后使用相同的名称重新创建同义词,并将同义词指向Customer表的新位置。
公共同义词
公共同义词由数据库中的PUBLIC模式拥有。所有数据库用户都可以引用公共同义词。它们由应用程序所有者为表和其他对象(如过程和包)创建,以便应用程序用户可以看到这些对象。
语法
CREATE PUBLIC SYNONYM Cust_table for efashion.Customer;
要创建公共同义词,您必须使用关键字PUBLIC,如下所示。
私有同义词
私有同义词用于数据库模式中以隐藏表、过程、视图或任何其他数据库对象的真实名称。
只有拥有该表或对象的模式才能引用私有同义词。
语法
CREATE SYNONYM Cust_table FOR efashion.Customer;
删除同义词
可以使用DROP Synonym命令删除同义词。如果要删除公共同义词,则必须在drop语句中使用关键字public。
语法
DROP PUBLIC Synonym Cust_table; DROP Synonym Cust_table;
SAP HANA - SQL 执行计划
SQL解释计划用于生成SQL语句的详细解释。它们用于评估SAP HANA数据库为执行SQL语句而遵循的执行计划。
解释计划的结果存储在EXPLAIN_PLAN_TABLE中以进行评估。要使用解释计划,传入的SQL查询必须是数据操作语言(DML)。
常见的DML语句
SELECT - 从数据库中检索数据
INSERT − 将数据插入表中
UPDATE − 更新表中现有数据
SQL解释计划不能与DDL和DCL SQL语句一起使用。
数据库中的EXPLAIN PLAN TABLE
数据库中的EXPLAIN PLAN_TABLE包含多个列。一些常见的列名:OPERATOR_NAME、OPERATOR_ID、PARENT_OPERATOR_ID、LEVEL和POSITION等。
COLUMN SEARCH值指示列引擎运算符的起始位置。
ROW SEARCH值指示行引擎运算符的起始位置。
为SQL查询创建EXPLAIN PLAN语句
EXPLAIN PLAN SET STATEMENT_NAME = ‘statement_name’ FOR <SQL DML statement>
查看EXPLAIN PLAN TABLE中的值
SELECT Operator_Name, Operator_ID FROM explain_plan_table WHERE statement_name = 'statement_name';
删除EXPLAIN PLAN TABLE中的语句
DELETE FROM explain_plan_table WHERE statement_name = 'TPC-H Q10';
SAP HANA - SQL 数据分析
SQL数据分析任务用于理解和分析来自多个数据源的数据。它用于删除不正确、不完整的数据,并在将数据加载到数据仓库之前防止数据质量问题。
以下是SQL数据分析任务的优点:
它有助于更有效地分析源数据。
它有助于更好地理解源数据。
它删除不正确、不完整的数据,并在将其加载到数据仓库之前提高数据质量。
它与提取、转换和加载任务一起使用。
数据分析任务检查配置文件,这有助于理解数据源并识别数据中需要修复的问题。
您可以在Integration Services包中使用数据分析任务来分析存储在SQL Server中的数据,并识别数据质量的潜在问题。
注意 - 数据分析任务仅适用于SQL Server数据源,不支持任何其他基于文件或第三方的数据源。
访问要求
要运行包含数据分析任务的包,用户帐户必须对tempdb数据库具有读取/写入权限和CREATE TABLE权限。
数据分析器查看器
数据分析器查看器用于查看分析器输出。数据分析器查看器还支持钻取功能,可帮助您理解在分析输出中标识的数据质量问题。此钻取功能会向原始数据源发送实时查询。
数据分析任务设置和查看
设置数据分析任务
这涉及执行包含数据分析任务的包以计算概要文件。该任务将输出以XML格式保存到文件或包变量中。
查看概要文件
要查看数据概要文件,请将输出发送到文件,然后使用数据分析器查看器。此查看器是一个独立实用程序,可以以摘要和详细信息格式显示概要文件输出,并具有可选的钻取功能。
数据分析 - 配置选项
数据分析任务具有以下方便的配置选项:
通配符列
在配置概要请求时,任务接受使用“*”通配符来代替列名。这简化了配置,并使发现不熟悉数据的特性更容易。当任务运行时,任务会分析每个具有适当数据类型的列。
快速概要
您可以选择“快速概要”来快速配置任务。“快速概要”使用所有默认概要和设置来分析表或视图。
数据概要任务可以计算八种不同的数据概要。其中五种概要可以检查单个列,其余三种分析多个列或列之间的关系。
数据概要 - 任务输出
数据概要任务将选定的概要输出为类似于DataProfile.xsd模式的XML格式。
您可以保存模式的本地副本,并在Microsoft Visual Studio或其他模式编辑器、XML编辑器或文本编辑器(如记事本)中查看模式的本地副本。
SAP HANA - SQL 脚本
用于HANA数据库的一组SQL语句,允许开发者将复杂的逻辑传递到数据库中,称为SQL脚本。SQL脚本被称为SQL扩展的集合。这些扩展包括数据扩展、函数扩展和过程扩展。
SQL脚本支持存储的函数和过程,这允许将应用程序逻辑的复杂部分推送到数据库。
使用SQL脚本的主要好处是允许在SAP HANA数据库中执行复杂的计算。使用SQL脚本代替单个查询使函数能够返回多个值。复杂的SQL函数可以进一步分解成更小的函数。SQL脚本提供了单一SQL语句中不可用的控制逻辑。
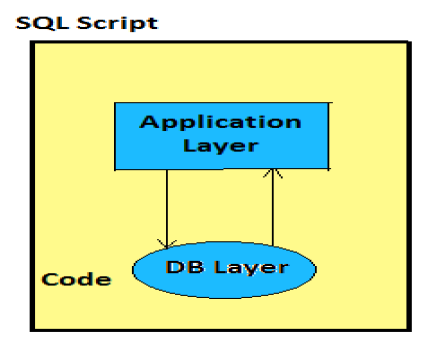
SQL脚本用于通过在数据库层执行脚本来实现HANA的性能优化:
通过在数据库层执行SQL脚本,消除了将大量数据从数据库传输到应用程序的需要。
计算在数据库层执行,以获得HANA数据库的优势,例如列操作、查询的并行处理等。
与信息建模器的集成
在信息建模器中使用SQL脚本时,以下内容应用于过程:
- 输入参数可以是标量类型或表类型。
- 输出参数必须是表类型。
- 签名所需的表类型会自动生成。
带有计算视图的SQL脚本
SQL脚本用于创建基于脚本的计算视图。针对现有的原始表或列存储编写SQL语句。定义输出结构,视图的激活会根据结构创建表类型。
如何使用SQL脚本创建计算视图?
**启动SAP HANA Studio**。展开内容节点→选择要创建新的计算视图的包。右键单击→新建计算视图 →提供名称和描述。
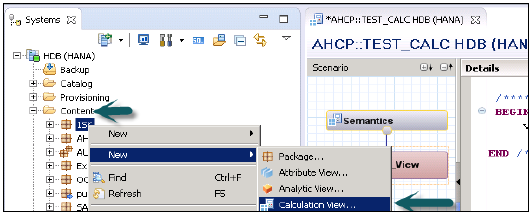
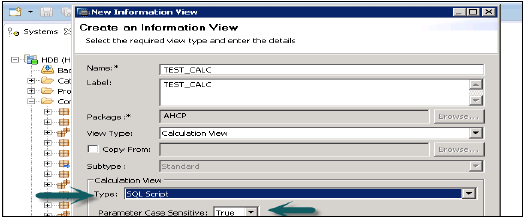
**选择计算视图类型**→从“类型”下拉列表中,选择“SQL脚本”→根据您需要的计算视图输出参数的命名约定,将“参数区分大小写”设置为“真”或“假”→选择“完成”。
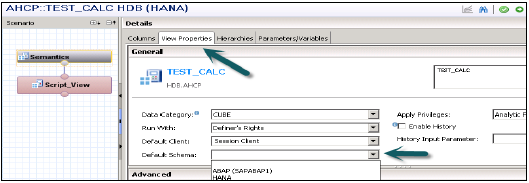
**选择默认模式** - 选择“语义”节点→选择“视图属性”选项卡→在“默认模式”下拉列表中,选择默认模式。
**在“语义”节点中选择“SQL脚本”节点**→定义输出结构。在输出窗格中,选择“创建目标”。添加所需的输出参数并指定其长度和类型。
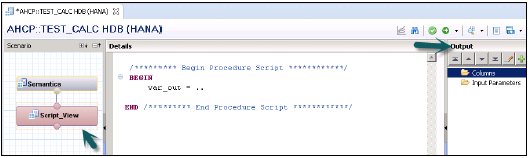
要将作为现有信息视图或目录表或表函数一部分的多个列添加到基于脚本的计算视图的输出结构中:
在输出窗格中,选择“开始导航路径 新建 下一步导航步骤 添加来自 结束导航路径”→包含要添加到输出的列的对象的名称→从下拉列表中选择一个或多个对象→选择“下一步”。
在“源”窗格中,选择要添加到输出的列→要将选择的列添加到输出,请选择这些列并选择“添加”。要将对象的所有列添加到输出,请选择该对象并选择“添加”→“完成”。
**激活基于脚本的计算视图** - 在SAP HANA建模器透视图中 - 保存并激活 - 激活当前视图,如果受影响对象的活动版本存在,则重新部署受影响的对象。否则,只激活当前视图。
**保存并激活所有** - 激活当前视图以及所需的和受影响的对象。
**在SAP HANA开发透视图中** - 在“项目资源管理器”视图中,选择所需的对象。在上下文菜单中,选择“开始导航路径 团队 下一步导航步骤 激活 结束导航路径”。
HANA信息建模器中的SQL脚本用于创建复杂的计算视图,这些视图无法使用GUI选项创建。