- Scala 集合教程
- Scala 集合 - 首页
- Scala 集合 - 概述
- Scala 集合 - 环境设置
- Scala 集合 - 数组
- Scala 集合 - 数组
- Scala 集合 - 多维数组
- Scala 集合 - 使用 Range 创建数组
- Scala 集合 - ArrayBuffer
- Scala 集合 - 列表
- Scala 集合 - 列表
- Scala 集合 - ListBuffer
- Scala 集合 - ListSet
- Scala 集合 - 向量
- Scala 集合 - 集合
- Scala 集合 - 集合
- Scala 集合 - BitSet
- Scala 集合 - HashSet
- Scala 集合 - TreeSet
- Scala 集合 - 映射
- Scala 集合 - 映射
- Scala 集合 - HashMap
- Scala 集合 - ListMap
- Scala 集合 - 其他
- Scala 集合 - 迭代器
- Scala 集合 - Option
- Scala 集合 - 队列
- Scala 集合 - 元组
- Scala 集合 - Seq
- Scala 集合 - 堆栈
- Scala 集合 - 流
- Scala 集合组合器方法
- Scala 集合 - drop
- Scala 集合 - dropWhile
- Scala 集合 - filter
- Scala 集合 - find
- Scala 集合 - flatMap
- Scala 集合 - flatten
- Scala 集合 - fold
- Scala 集合 - foldLeft
- Scala 集合 - foldRight
- Scala 集合 - map
- Scala 集合 - partition
- Scala 集合 - reduce
- Scala 集合 - scan
- Scala 集合 - zip
- Scala 集合有用资源
- Scala 集合 - 快速指南
- Scala 集合 - 有用资源
- Scala 集合 - 讨论
Scala 集合 - 快速指南
Scala 集合 - 概述
Scala 拥有丰富的集合库。集合是事物的容器。这些容器可以是有序的,例如 List、Tuple、Option、Map 等线性项目集。集合可以包含任意数量的元素,也可以限制为零个或一个元素(例如,Option)。
集合可以是**严格的**或**惰性的**。惰性集合的元素可能不会在访问之前占用内存,例如**Ranges**。此外,集合可以是**可变的**(引用的内容可以更改)或**不可变的**(引用指向的事物永远不会更改)。请注意,不可变集合可能包含可变项。
对于某些问题,可变集合效果更好,而对于其他问题,不可变集合效果更好。如有疑问,最好从不可变集合开始,如果需要可变集合,则稍后再更改。
本章阐述了最常用的集合类型和对这些集合最常用的操作。
| 序号 | 集合及描述 |
|---|---|
| 1 | Scala 列表 Scala 的 List[T] 是类型 T 的链表。 |
| 2 | Scala 集合 集合是相同类型元素的成对不同元素的集合。 |
| 3 |
Scala 映射 映射是键/值对的集合。任何值都可以根据其键检索。 |
| 4 | Scala 元组 与数组或列表不同,元组可以容纳不同类型的对象。 |
| 5 | Scala Option Option[T] 为给定类型的零个或一个元素提供容器。 |
| 6 | Scala 迭代器 迭代器不是集合,而是一种逐一访问集合元素的方法。 |
Scala 集合 - 环境设置
Scala 可以安装在任何类 Unix 或基于 Windows 的系统上。在开始在您的计算机上安装 Scala 之前,您必须在计算机上安装 Java 1.8 或更高版本。
请按照以下步骤安装 Scala。
步骤 1:验证您的 Java 安装
首先,您需要在系统上安装 Java 软件开发工具包 (SDK)。要验证这一点,请根据您正在使用的平台执行以下两个命令中的任何一个。
如果 Java 安装已正确完成,则它将显示当前版本和 Java 安装的规范。示例输出在以下表格中给出。
| 平台 | 命令 | 示例输出 |
|---|---|---|
| Windows |
打开命令控制台并键入: >java -version |
Java 版本 "1.8.0_31" Java(TM) SE 运行时环境 (build 1.8.0_31-b31) Java Hotspot(TM) 64 位服务器 VM (build 25.31-b07, mixed mode) |
| Linux |
打开命令终端并键入: $java -version |
Java 版本 "1.8.0_31" Open JDK 运行时环境 (rhel-2.8.10.4.el6_4-x86_64) Open JDK 64 位服务器 VM (build 25.31-b07, mixed mode) |
我们假设本教程的读者在其系统上安装了 Java SDK 版本 1.8.0_31。
如果您没有 Java SDK,请从https://www.oracle.com/technetwork/java/javase/downloads/index.html下载其当前版本并安装它。
步骤 2:设置您的 Java 环境
设置环境变量 JAVA_HOME 以指向 Java 安装在您机器上的基本目录位置。例如:
| 序号 | 平台和描述 |
|---|---|
| 1 |
Windows 将 JAVA_HOME 设置为 C:\ProgramFiles\java\jdk1.8.0_31 |
| 2 |
Linux Export JAVA_HOME=/usr/local/java-current |
将 Java 编译器位置的完整路径附加到系统路径。
| 序号 | 平台和描述 |
|---|---|
| 1 |
Windows 将字符串 "C:\Program Files\Java\jdk1.8.0_31\bin" 附加到系统变量 PATH 的末尾。 |
| 2 |
Linux Export PATH=$PATH:$JAVA_HOME/bin/ |
如上所述,从命令提示符执行命令**java -version**。
步骤 3:安装 Scala
您可以从www.scala-lang.org/downloads下载 Scala。在撰写本教程时,我下载了“scala-2.13.1-installer.jar”。确保您拥有管理员权限才能继续。现在,在命令提示符下执行以下命令:
| 平台 | 命令和输出 | 描述 |
|---|---|---|
| Windows | >java -jar scala-2.13.1-installer.jar> |
此命令将显示安装向导,该向导将指导您在 Windows 机器上安装 Scala。在安装过程中,它将询问许可协议,只需接受它,然后它将询问安装 Scala 的路径。我选择了默认路径 _“C:\Program Files\Scala”_,您可以根据自己的方便选择合适的路径。 |
| Linux |
**命令**: $java -jar scala-2.13.1-installer.jar **输出**: 欢迎安装 Scala 2.13.1! 主页位于:https://scala-lang.org.cn/ 按 1 继续,按 2 退出,按 3 重新显示 1................................................ [ 开始解压 ] [ 处理软件包:软件包安装 (1/1) ] [ 解压完成 ] [ 控制台安装完成 ] |
在安装过程中,它将询问许可协议,要接受它,请输入 1,它将询问安装 Scala 的路径。我输入了 _/usr/local/share_,您可以根据自己的方便选择合适的路径。 |
最后,打开一个新的命令提示符并键入**Scala -version** 并按 Enter 键。您应该看到以下内容:
| 平台 | 命令 | 输出 |
|---|---|---|
| Windows | >scala -version |
Scala 代码运行器版本 2.13.1 -- 版权所有 2002-2019,LAMP/EPFL 和 Lightbend, Inc. |
| Linux | $scala -version |
Scala 代码运行器版本 2.13.1 -- 版权所有 2002-2019,LAMP/EPFL 和 Lightbend, Inc.tut |
Scala 集合 - 数组
Scala 提供了一种数据结构**数组**,它存储相同类型元素的固定大小的顺序集合。数组用于存储数据集合,但通常将数组视为相同类型变量的集合更有用。
您可以声明一个数组变量(例如 numbers),并使用 numbers[0]、numbers[1] 和 ... numbers[99] 来表示各个变量,而不是声明单独的变量,例如 number0、number1、... 和 number99。本教程介绍如何声明数组变量、创建数组以及使用索引变量处理数组。数组第一个元素的索引为零,最后一个元素的索引为元素总数减一。
声明数组变量
要在程序中使用数组,必须声明一个变量来引用数组,并且必须指定变量可以引用的数组类型。
以下是声明数组变量的语法。
语法
var z:Array[String] = new Array[String](3) or var z = new Array[String](3)
这里,z 被声明为一个最多可以容纳三个元素的字符串数组。可以使用以下命令为各个元素赋值或访问各个元素:
命令
z(0) = "Zara"; z(1) = "Nuha"; z(4/2) = "Ayan"
这里,最后一个示例表明,通常索引可以是任何产生整数的表达式。还有一种定义数组的方法:
var z = Array("Zara", "Nuha", "Ayan")
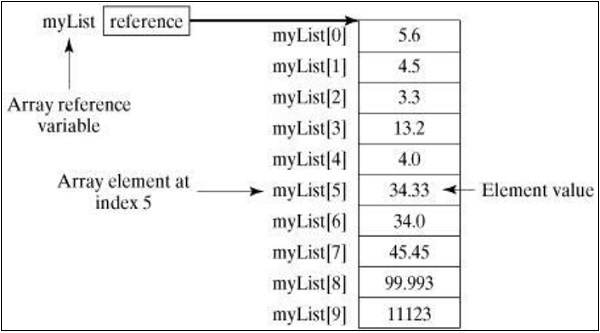
下图表示数组**myList**。这里,**myList** 包含十个双精度值,索引从 0 到 9。
处理数组
处理数组元素时,我们经常使用循环控制结构,因为数组中的所有元素都是相同类型,并且数组的大小是已知的。
以下是一个示例程序,演示如何创建、初始化和处理数组:
示例
object Demo {
def main(args: Array[String]) {
var myList = Array(1.9, 2.9, 3.4, 3.5)
// Print all the array elements
for ( x <- myList ) {
println( x )
}
// Summing all elements
var total = 0.0;
for ( i <- 0 to (myList.length - 1)) {
total += myList(i);
}
println("Total is " + total);
// Finding the largest element
var max = myList(0);
for ( i <- 1 to (myList.length - 1) ) {
if (myList(i) > max) max = myList(i);
}
println("Max is " + max);
}
}
将上述程序保存为**Demo.scala**。使用以下命令编译和执行此程序。
命令
\>scalac Demo.scala \>scala Demo
输出
1.9 2.9 3.4 3.5 Total is 11.7 Max is 3.5
Scala 不直接支持各种数组操作,并提供各种方法来处理任何维度的数组。如果要使用不同的方法,则需要导入**Array._** 包。
Scala 集合 - 多维数组
在许多情况下,您需要定义和使用多维数组(即元素为数组的数组)。例如,矩阵和表是可以实现为二维数组的结构示例。
以下是定义二维数组的示例:
var myMatrix = ofDim[Int](3,3)
这是一个数组,它有三个元素,每个元素都是一个包含三个元素的整数数组。
尝试以下示例程序来处理多维数组:
示例
import Array._
object Demo {
def main(args: Array[String]) {
var myMatrix = ofDim[Int](3,3)
// build a matrix
for (i <- 0 to 2) {
for ( j <- 0 to 2) {
myMatrix(i)(j) = j;
}
}
// Print two dimensional array
for (i <- 0 to 2) {
for ( j <- 0 to 2) {
print(" " + myMatrix(i)(j));
}
println();
}
}
}
将上述程序保存为**Demo.scala**。使用以下命令编译和执行此程序。
命令
\>scalac Demo.scala \>scala Demo
输出
0 1 2 0 1 2 0 1 2
Scala 集合 - 使用 Range 创建数组
使用 range() 方法生成一个包含给定范围内递增整数序列的数组。您可以使用最终参数作为步长来创建序列;如果您不使用最终参数,则步长将假定为 1。
让我们以创建范围 (10, 20, 2) 的数组为例:这意味着创建一个包含 10 到 20 之间的元素且范围差为 2 的数组。数组中的元素为 10、12、14、16 和 18。
另一个示例:range (10, 20)。这里没有给出范围差,因此默认情况下它假定为 1 个元素。它创建一个包含 10 到 20 之间的元素且范围差为 1 的数组。数组中的元素为 10、11、12、13、…和 19。
以下示例程序演示如何使用范围创建数组。
示例
import Array._
object Demo {
def main(args: Array[String]) {
var myList1 = range(10, 20, 2)
var myList2 = range(10,20)
// Print all the array elements
for ( x <- myList1 ) {
print( " " + x )
}
println()
for ( x <- myList2 ) {
print( " " + x )
}
}
}
将上述程序保存为**Demo.scala**。使用以下命令编译和执行此程序。
命令
\>scalac Demo.scala \>scala Demo
输出
10 12 14 16 18 10 11 12 13 14 15 16 17 18 19
Scala 集合 - ArrayBuffer
Scala 提供了一种数据结构**ArrayBuffer**,当初始大小不足时,它可以更改大小。由于数组大小固定,无法在数组中占用更多元素,因此 ArrayBuffer 是数组的替代方案,其大小是灵活的。
ArrayBuffer 在内部维护一个当前大小的数组来存储元素。添加新元素时,将检查大小。如果底层数组已满,则将创建一个新的更大数组,并将所有元素复制到更大的数组。
声明 ArrayBuffer 变量
以下是声明 ArrayBuffer 变量的语法。
语法
var z = ArrayBuffer[String]()
这里,z 被声明为一个最初为空的字符串数组缓冲区。可以使用以下命令添加值:
命令
z += "Zara"; z += "Nuha"; z += "Ayan";
处理 ArrayBuffer
下面是一个关于如何创建、初始化和处理ArrayBuffer的示例程序。
示例
import scala.collection.mutable.ArrayBuffer
object Demo {
def main(args: Array[String]) = {
var myList = ArrayBuffer("Zara","Nuha","Ayan")
println(myList);
// Add an element
myList += "Welcome";
// Add two element
myList += ("To", "Tutorialspoint");
println(myList);
// Remove an element
myList -= "Welcome";
// print second element
println(myList(1));
}
}
将上述程序保存为**Demo.scala**。使用以下命令编译和执行此程序。
命令
\>scalac Demo.scala \>scala Demo
输出
ArrayBuffer(Zara, Nuha, Ayan) ArrayBuffer(Zara, Nuha, Ayan, Welcome, To, Tutorialspoint) Nuha
Scala 集合 - 列表
Scala列表与数组非常相似,这意味着列表的所有元素都具有相同的类型,但是有两个重要的区别。首先,列表是不可变的,这意味着列表的元素不能通过赋值来更改。其次,列表表示一个链表,而数组是扁平的。
具有类型为T的元素的列表的类型写为List[T]。
尝试以下示例,这里定义了几个不同数据类型的列表。
// List of Strings
val fruit: List[String] = List("apples", "oranges", "pears")
// List of Integers
val nums: List[Int] = List(1, 2, 3, 4)
// Empty List.
val empty: List[Nothing] = List()
// Two dimensional list
val dim: List[List[Int]] = List(
List(1, 0, 0),
List(0, 1, 0),
List(0, 0, 1)
)
所有列表都可以使用两个基本构建块来定义:尾部Nil和::(发音为cons)。Nil也表示空列表。以上所有列表都可以如下定义。
// List of Strings
val fruit = "apples" :: ("oranges" :: ("pears" :: Nil))
// List of Integers
val nums = 1 :: (2 :: (3 :: (4 :: Nil)))
// Empty List.
val empty = Nil
// Two dimensional list
val dim = (1 :: (0 :: (0 :: Nil))) ::
(0 :: (1 :: (0 :: Nil))) ::
(0 :: (0 :: (1 :: Nil))) :: Nil
列表的基本操作
所有列表操作都可以用以下三种方法来表达。
| 序号 | 方法和描述 |
|---|---|
| 1 |
head 此方法返回列表的第一个元素。 |
| 2 |
tail 此方法返回一个列表,该列表包含除第一个元素之外的所有元素。 |
| 3 |
isEmpty 如果列表为空,此方法返回true,否则返回false。 |
以下示例演示了如何使用上述方法。
示例
object Demo {
def main(args: Array[String]) {
val fruit = "apples" :: ("oranges" :: ("pears" :: Nil))
val nums = Nil
println( "Head of fruit : " + fruit.head )
println( "Tail of fruit : " + fruit.tail )
println( "Check if fruit is empty : " + fruit.isEmpty )
println( "Check if nums is empty : " + nums.isEmpty )
}
}
将上述程序保存为**Demo.scala**。使用以下命令编译和执行此程序。
命令
\>scalac Demo.scala \>scala Demo
输出
Head of fruit : apples Tail of fruit : List(oranges, pears) Check if fruit is empty : false Check if nums is empty : true
连接列表
您可以使用:::运算符或List.:::()方法或List.concat()方法来添加两个或多个列表。请参见下面的示例。
示例
object Demo {
def main(args: Array[String]) {
val fruit1 = "apples" :: ("oranges" :: ("pears" :: Nil))
val fruit2 = "mangoes" :: ("banana" :: Nil)
// use two or more lists with ::: operator
var fruit = fruit1 ::: fruit2
println( "fruit1 ::: fruit2 : " + fruit )
// use two lists with Set.:::() method
fruit = fruit1.:::(fruit2)
println( "fruit1.:::(fruit2) : " + fruit )
// pass two or more lists as arguments
fruit = List.concat(fruit1, fruit2)
println( "List.concat(fruit1, fruit2) : " + fruit )
}
}
将上述程序保存为**Demo.scala**。使用以下命令编译和执行此程序。
命令
\>scalac Demo.scala \>scala Demo
输出
fruit1 ::: fruit2 : List(apples, oranges, pears, mangoes, banana) fruit1.:::(fruit2) : List(mangoes, banana, apples, oranges, pears) List.concat(fruit1, fruit2) : List(apples, oranges, pears, mangoes, banana)
创建统一列表
您可以使用List.fill()方法创建一个包含零个或多个相同元素副本的列表。尝试以下示例程序。
示例
object Demo {
def main(args: Array[String]) {
val fruit = List.fill(3)("apples") // Repeats apples three times.
println( "fruit : " + fruit )
val num = List.fill(10)(2) // Repeats 2, 10 times.
println( "num : " + num )
}
}
将上述程序保存为**Demo.scala**。使用以下命令编译和执行此程序。
命令
\>scalac Demo.scala \>scala Demo
输出
fruit : List(apples, apples, apples) num : List(2, 2, 2, 2, 2, 2, 2, 2, 2, 2)
制表函数
您可以将函数与List.tabulate()方法一起使用,以在制表列表之前将其应用于列表的所有元素。其参数与List.fill的参数类似:第一个参数列表给出要创建的列表的维度,第二个参数描述列表的元素。唯一的区别是,元素不是固定的,而是由函数计算的。
尝试以下示例程序。
示例
object Demo {
def main(args: Array[String]) {
// Creates 5 elements using the given function.
val squares = List.tabulate(6)(n => n * n)
println( "squares : " + squares )
val mul = List.tabulate( 4,5 )( _ * _ )
println( "mul : " + mul )
}
}
将上述程序保存为**Demo.scala**。使用以下命令编译和执行此程序。
命令
\>scalac Demo.scala \>scala Demo
输出
squares : List(0, 1, 4, 9, 16, 25) mul : List(List(0, 0, 0, 0, 0), List(0, 1, 2, 3, 4), List(0, 2, 4, 6, 8), List(0, 3, 6, 9, 12))
反转列表顺序
您可以使用List.reverse方法反转列表的所有元素。以下示例演示了用法。
示例
object Demo {
def main(args: Array[String]) {
val fruit = "apples" :: ("oranges" :: ("pears" :: Nil))
println( "Before reverse fruit : " + fruit )
println( "After reverse fruit : " + fruit.reverse )
}
}
将上述程序保存为**Demo.scala**。使用以下命令编译和执行此程序。
命令
\>scalac Demo.scala \>scala Demo
输出
Before reverse fruit : List(apples, oranges, pears) After reverse fruit : List(pears, oranges, apples)
Scala 集合 - ListBuffer
Scala提供了一种数据结构ListBuffer,它在添加/删除列表中的元素时比List更高效。它提供了在列表中添加元素的方法。
声明ListBuffer变量
以下是声明ListBuffer变量的语法。
语法
var z = ListBuffer[String]()
这里,z声明为一个最初为空的字符串ListBuffer。可以使用以下命令添加值:
命令
z += "Zara"; z += "Nuha"; z += "Ayan";
处理ListBuffer
下面是一个关于如何创建、初始化和处理ListBuffer的示例程序。
示例
import scala.collection.mutable.ListBuffer
object Demo {
def main(args: Array[String]) = {
var myList = ListBuffer("Zara","Nuha","Ayan")
println(myList);
// Add an element
myList += "Welcome";
// Add two element
myList += ("To", "Tutorialspoint");
println(myList);
// Remove an element
myList -= "Welcome";
// print second element
println(myList(1));
}
}
将上述程序保存为**Demo.scala**。使用以下命令编译和执行此程序。
命令
\>scalac Demo.scala \>scala Demo
输出
ListBuffer(Zara, Nuha, Ayan) ListBuffer(Zara, Nuha, Ayan, Welcome, To, Tutorialspoint) Nuha
Scala 集合 - ListSet
Scala Set是一个包含相同类型成对不同元素的集合。换句话说,Set是一个不包含重复元素的集合。ListSet实现不可变集合并使用列表结构。存储元素时会保留元素的插入顺序。
声明ListSet变量
以下是声明ListSet变量的语法。
语法
var z : ListSet[String] = ListSet("Zara","Nuha","Ayan")
这里,z声明为一个包含三个成员的字符串ListSet。可以使用以下命令添加值:
命令
var myList1: ListSet[String] = myList + "Naira";
处理ListSet
下面是一个关于如何创建、初始化和处理ListSet的示例程序。
示例
import scala.collection.immutable.ListSet
object Demo {
def main(args: Array[String]) = {
var myList: ListSet[String] = ListSet("Zara","Nuha","Ayan");
// Add an element
var myList1: ListSet[String] = myList + "Naira";
// Remove an element
var myList2: ListSet[String] = myList - "Nuha";
// Create empty set
var myList3: ListSet[String] = ListSet.empty[String];
println(myList);
println(myList1);
println(myList2);
println(myList3);
}
}
将上述程序保存为**Demo.scala**。使用以下命令编译和执行此程序。
命令
\>scalac Demo.scala \>scala Demo
输出
ListSet(Zara, Nuha, Ayan) ListSet(Zara, Nuha, Ayan, Naira) ListSet(Zara, Ayan) ListSet()
Scala 集合 - 向量
Scala Vector是一个通用的不可变数据结构,其中元素可以随机访问。它通常用于大型数据集合。
声明Vector变量
以下是声明Vector变量的语法。
语法
var z : Vector[String] = Vector("Zara","Nuha","Ayan")
这里,z声明为一个包含三个成员的字符串Vector。可以使用以下命令添加值:
命令
var vector1: Vector[String] = z + "Naira";
处理Vector
下面是一个关于如何创建、初始化和处理Vector的示例程序。
示例
import scala.collection.immutable.Vector
object Demo {
def main(args: Array[String]) = {
var vector: Vector[String] = Vector("Zara","Nuha","Ayan");
// Add an element
var vector1: Vector[String] = vector :+ "Naira";
// Reverse an element
var vector2: Vector[String] = vector.reverse;
// sort a vector
var vector3: Vector[String] = vector1.sorted;
println(vector);
println(vector1);
println(vector2);
println(vector3);
}
}
将上述程序保存为**Demo.scala**。使用以下命令编译和执行此程序。
命令
\>scalac Demo.scala \>scala Demo
输出
Vector(Zara, Nuha, Ayan) Vector(Zara, Nuha, Ayan, Naira) Vector(Ayan, Nuha, Zara) Vector(Ayan, Naira, Nuha, Zara)
Scala 集合 - 集合
Scala Set是一个包含相同类型成对不同元素的集合。换句话说,Set是一个不包含重复元素的集合。Set有两种类型:**不可变**和**可变**。可变对象和不可变对象的区别在于,当一个对象是不可变的时,对象本身不能被改变。
默认情况下,Scala使用不可变Set。如果要使用可变Set,则必须显式导入scala.collection.mutable.Set类。如果要在同一个集合中同时使用可变和不可变集合,则可以继续将不可变Set称为Set,但可变Set可以称为mutable.Set。
以下是如何声明不可变Set:
语法
// Empty set of integer type var s : Set[Int] = Set() // Set of integer type var s : Set[Int] = Set(1,3,5,7) or var s = Set(1,3,5,7)
定义空集合时,类型注释是必要的,因为系统需要为变量分配具体的类型。
集合的基本操作
所有集合操作都可以用以下三种方法来表达:
| 序号 | 方法和描述 |
|---|---|
| 1 |
head 此方法返回集合的第一个元素。 |
| 2 |
tail 此方法返回一个集合,该集合包含除第一个元素之外的所有元素。 |
| 3 |
isEmpty 此方法如果集合为空则返回true,否则返回false。 |
尝试以下示例,该示例显示了基本操作方法的用法:
示例
object Demo {
def main(args: Array[String]) {
val fruit = Set("apples", "oranges", "pears")
val nums: Set[Int] = Set()
println( "Head of fruit : " + fruit.head )
println( "Tail of fruit : " + fruit.tail )
println( "Check if fruit is empty : " + fruit.isEmpty )
println( "Check if nums is empty : " + nums.isEmpty )
}
}
将上述程序保存为**Demo.scala**。使用以下命令编译和执行此程序。
命令
\>scalac Demo.scala \>scala Demo
输出
Head of fruit : apples Tail of fruit : Set(oranges, pears) Check if fruit is empty : false Check if nums is empty : true
连接集合
您可以使用++运算符或Set.++()方法连接两个或多个集合,但在添加集合时,它会删除重复的元素。
以下是连接两个集合的示例。
示例
object Demo {
def main(args: Array[String]) {
val fruit1 = Set("apples", "oranges", "pears")
val fruit2 = Set("mangoes", "banana")
// use two or more sets with ++ as operator
var fruit = fruit1 ++ fruit2
println( "fruit1 ++ fruit2 : " + fruit )
// use two sets with ++ as method
fruit = fruit1.++(fruit2)
println( "fruit1.++(fruit2) : " + fruit )
}
}
将上述程序保存为**Demo.scala**。使用以下命令编译和执行此程序。
命令
\>scalac Demo.scala \>scala Demo
输出
fruit1 ++ fruit2 : Set(banana, apples, mangoes, pears, oranges) fruit1.++(fruit2) : Set(banana, apples, mangoes, pears, oranges)
查找集合中的最大值和最小值元素
您可以使用Set.min方法找出集合中可用的元素的最小值,并使用Set.max方法找出最大值。以下是显示程序的示例。
示例
object Demo {
def main(args: Array[String]) {
val num = Set(5,6,9,20,30,45)
// find min and max of the elements
println( "Min element in Set(5,6,9,20,30,45) : " + num.min )
println( "Max element in Set(5,6,9,20,30,45) : " + num.max )
}
}
将上述程序保存为**Demo.scala**。使用以下命令编译和执行此程序。
命令
\>scalac Demo.scala \>scala Demo
输出
Min element in Set(5,6,9,20,30,45) : 5 Max element in Set(5,6,9,20,30,45) : 45
查找集合中的公共值
您可以使用Set.&方法或Set.intersect方法找出两个集合之间的公共值。尝试以下示例以显示用法。
示例
object Demo {
def main(args: Array[String]) {
val num1 = Set(5,6,9,20,30,45)
val num2 = Set(50,60,9,20,35,55)
// find common elements between two sets
println( "num1.&(num2) : " + num1.&(num2) )
println( "num1.intersect(num2) : " + num1.intersect(num2) )
}
}
将上述程序保存为**Demo.scala**。使用以下命令编译和执行此程序。
命令
\>scalac Demo.scala \>scala Demo
输出
num1.&(num2) : Set(20, 9) num1.intersect(num2) : Set(20, 9)
Scala 集合 - BitSet
Bitset是可变和不可变位集的公共基类。位集是非负整数的集合,表示为打包到64位字中的可变大小的位数组。位集的内存占用量由其中存储的最大数字表示。
声明BitSet变量
以下是声明BitSet变量的语法。
语法
var z : BitSet = BitSet(0,1,2)
这里,z声明为一个包含三个成员的非负整数位集。可以使用以下命令添加值:
命令
var myList1: BitSet = myList + 3;
处理BitSet
下面是一个关于如何创建、初始化和处理BitSet的示例程序。
示例
import scala.collection.immutable.BitSet
object Demo {
def main(args: Array[String]) = {
var mySet: BitSet = BitSet(0, 1, 2);
// Add an element
var mySet1: BitSet = mySet + 3;
// Remove an element
var mySet2: BitSet = mySet - 2;
var mySet3: BitSet = BitSet(4, 5);
// Adding sets
var mySet4: BitSet = mySet1 ++ mySet3;
println(mySet);
println(mySet1);
println(mySet2);
println(mySet4);
}
}
将上述程序保存为**Demo.scala**。使用以下命令编译和执行此程序。
命令
\>scalac Demo.scala \>scala Demo
输出
BitSet(0, 1, 2) BitSet(0, 1, 2, 3) BitSet(0, 1) BitSet(0, 1, 2, 3, 4, 5)
Scala 集合 - HashSet
Scala Set是一个包含相同类型成对不同元素的集合。换句话说,Set是一个不包含重复元素的集合。HashSet实现不可变集合并使用哈希表。不保留元素的插入顺序。
声明HashSet变量
以下是声明HashSet变量的语法。
语法
var z : HashSet[String] = HashSet("Zara","Nuha","Ayan")
这里,z声明为一个包含三个成员的字符串HashSet。可以使用以下命令添加值:
命令
var myList1: HashSet[String] = myList + "Naira";
处理HashSet
下面是一个关于如何创建、初始化和处理HashSet的示例程序。
示例
import scala.collection.immutable.HashSet
object Demo {
def main(args: Array[String]) = {
var mySet: HashSet[String] = HashSet("Zara","Nuha","Ayan");
// Add an element
var mySet1: HashSet[String] = mySet + "Naira";
// Remove an element
var mySet2: HashSet[String] = mySet - "Nuha";
// Create empty set
var mySet3: HashSet[String] = HashSet.empty[String];
println(mySet);
println(mySet1);
println(mySet2);
println(mySet3);
}
}
将上述程序保存为**Demo.scala**。使用以下命令编译和执行此程序。
命令
\>scalac Demo.scala \>scala Demo
输出
HashSet(Zara, Nuha, Ayan) HashSet(Zara, Nuha, Ayan, Naira) HashSet(Zara, Ayan) HashSet()
Scala 集合 - TreeSet
Scala Set是一个包含相同类型成对不同元素的集合。换句话说,Set是一个不包含重复元素的集合。TreeSet实现不可变集合并按排序顺序保存元素。
声明TreeSet变量
以下是声明TreeSet变量的语法。
语法
var z : TreeSet[String] = TreeSet("Zara","Nuha","Ayan")
这里,z声明为一个包含三个成员的字符串TreeSet。可以使用以下命令添加值:
命令
var myList1: TreeSet[String] = myList + "Naira";
处理TreeSet
下面是一个关于如何创建、初始化和处理TreeSet的示例程序。
示例
import scala.collection.immutable.TreeSet
object Demo {
def main(args: Array[String]) = {
var mySet: TreeSet[String] = TreeSet("Zara","Nuha","Ayan");
// Add an element
var mySet1: TreeSet[String] = mySet + "Naira";
// Remove an element
var mySet2: TreeSet[String] = mySet - "Nuha";
// Create empty set
var mySet3: TreeSet[String] = TreeSet.empty[String];
println(mySet);
println(mySet1);
println(mySet2);
println(mySet3);
}
}
将上述程序保存为**Demo.scala**。使用以下命令编译和执行此程序。
命令
\>scalac Demo.scala \>scala Demo
输出
TreeSet(Ayan, Nuha, Zara) TreeSet(Ayan, Naira, Nuha, Zara) TreeSet(Ayan, Zara) TreeSet()
Scala 集合 - 映射
Scala Map是键/值对的集合。任何值都可以根据其键检索。Map中的键是唯一的,但值不必唯一。Map也称为哈希表。Map有两种类型:**不可变**和**可变**。可变对象和不可变对象的区别在于,当一个对象是不可变的时,对象本身不能被改变。
默认情况下,Scala使用不可变Map。如果要使用可变Map,则必须显式导入scala.collection.mutable.Map类。如果要在同一个集合中同时使用可变和不可变Map,则可以继续将不可变Map称为Map,但可变Map可以称为mutable.Map。
以下是声明不可变Map的示例语句:
// Empty hash table whose keys are strings and values are integers:
var A:Map[Char,Int] = Map()
// A map with keys and values.
val colors = Map("red" -> "#FF0000", "azure" -> "#F0FFFF")
定义空Map时,类型注释是必要的,因为系统需要为变量分配具体的类型。如果要向Map添加键值对,可以使用+运算符,如下所示。
A + = ('I' -> 1)
A + = ('J' -> 5)
A + = ('K' -> 10)
A + = ('L' -> 100)
MAP的基本操作
所有Map操作都可以用以下三种方法来表达。
| 序号 | 方法和描述 |
|---|---|
| 1 |
keys 此方法返回一个包含Map中每个键的可迭代对象。 |
| 2 |
values 此方法返回一个包含Map中每个值的可迭代对象。 |
| 3 |
isEmpty 此方法如果Map为空则返回true,否则返回false。 |
尝试以下示例程序,该程序显示了Map方法的用法。
示例
object Demo {
def main(args: Array[String]) {
val colors = Map(
"red" -> "#FF0000", "azure" -> "#F0FFFF", "peru" -> "#CD853F"
)
val nums: Map[Int, Int] = Map()
println( "Keys in colors : " + colors.keys )
println( "Values in colors : " + colors.values )
println( "Check if colors is empty : " + colors.isEmpty )
println( "Check if nums is empty : " + nums.isEmpty )
}
}
将上述程序保存为**Demo.scala**。使用以下命令编译和执行此程序。
命令
\>scalac Demo.scala \>scala Demo
输出
Keys in colors : Set(red, azure, peru) Values in colors : MapLike(#FF0000, #F0FFFF, #CD853F) Check if colors is empty : false Check if nums is empty : true
连接Map
您可以使用++运算符或Map.++()方法连接两个或多个Map,但在添加Map时,它会删除重复的键。
尝试以下示例程序来连接两个Map。
示例
object Demo {
def main(args: Array[String]) {
val colors1 = Map(
"red" -> "#FF0000", "azure" -> "#F0FFFF", "peru" -> "#CD853F"
)
val colors2 = Map(
"blue" -> "#0033FF", "yellow" -> "#FFFF00", "red" -> "#FF0000"
)
// use two or more Maps with ++ as operator
var colors = colors1 ++ colors2
println( "colors1 ++ colors2 : " + colors )
// use two maps with ++ as method
colors = colors1.++(colors2)
println( "colors1.++(colors2)) : " + colors )
}
}
将上述程序保存为**Demo.scala**。使用以下命令编译和执行此程序。
命令
\>scalac Demo.scala \>scala Demo
输出
colors1 ++ colors2 : Map(blue -> #0033FF, azure -> #F0FFFF, peru -> #CD853F, yellow -> #FFFF00, red -> #FF0000) colors1.++(colors2)) : Map(blue -> #0033FF, azure -> #F0FFFF, peru -> #CD853F, yellow -> #FFFF00, red -> #FF0000)
打印Map中的键和值
您可以使用“foreach”循环遍历Map的键和值。在这里,我们使用了与迭代器关联的foreach方法来遍历键。以下是一个示例程序。
示例
object Demo {
def main(args: Array[String]) {
val colors = Map("red" -> "#FF0000", "azure" -> "#F0FFFF","peru" -> "#CD853F")
colors.keys.foreach{
i =>
print( "Key = " + i )
println(" Value = " + colors(i) )
}
}
}
将上述程序保存为**Demo.scala**。使用以下命令编译和执行此程序。
命令
\>scalac Demo.scala \>scala Demo
输出
Key = red Value = #FF0000 Key = azure Value = #F0FFFF Key = peru Value = #CD853F
检查Map中的键
您可以使用Map.contains方法来测试给定的键是否存在于Map中。尝试以下示例程序进行键检查。
示例
object Demo {
def main(args: Array[String]) {
val colors = Map(
"red" -> "#FF0000", "azure" -> "#F0FFFF", "peru" -> "#CD853F"
)
if( colors.contains( "red" )) {
println("Red key exists with value :" + colors("red"))
} else {
println("Red key does not exist")
}
if( colors.contains( "maroon" )) {
println("Maroon key exists with value :" + colors("maroon"))
} else {
println("Maroon key does not exist")
}
}
}
将上述程序保存为**Demo.scala**。使用以下命令编译和执行此程序。
命令
\>scalac Demo.scala \>scala Demo
输出
Red key exists with value :#FF0000 Maroon key does not exist
Scala 集合 - HashMap
Scala Map是键/值对的集合。任何值都可以根据其键检索。Map中的键是唯一的,但值不必唯一。HashMap实现不可变Map并使用哈希表来实现相同的功能。
声明HashMap变量
以下是声明HashMap变量的语法。
语法
val colors = HashMap("red" -> "#FF0000", "azure" -> "#F0FFFF", "peru" -> "#CD853F")
这里,colors声明为一个包含三个键值对的字符串、Int HashMap。可以使用以下命令添加值:
命令
var myMap1: HashMap[Char, Int] = colors + ("black" -> "#000000");
处理HashMap
下面是一个关于如何创建、初始化和处理HashMap的示例程序。
示例
import scala.collection.immutable.HashMap
object Demo {
def main(args: Array[String]) = {
var myMap: HashMap[String,String] = HashMap(
"red" -> "#FF0000", "azure" -> "#F0FFFF", "peru" -> "#CD853F"
);
// Add an element
var myMap1: HashMap[String,String] = myMap + ("white" -> "#FFFFFF");
// Print key values
myMap.keys.foreach{
i =>
print( "Key = " + i )
println(" Value = " + myMap(i) )
}
if( myMap.contains( "red" )) {
println("Red key exists with value :" + myMap("red"))
} else {
println("Red key does not exist")
}
if( myMap.contains( "maroon" )) {
println("Maroon key exists with value :" + myMap("maroon"))
} else {
println("Maroon key does not exist")
}
//removing element
var myMap2: HashMap[String,String] = myMap - ("white");
// Create empty map
var myMap3: HashMap[String,String] = HashMap.empty[String, String];
println(myMap1);
println(myMap2);
println(myMap3);
}
}
将上述程序保存为**Demo.scala**。使用以下命令编译和执行此程序。
命令
\>scalac Demo.scala \>scala Demo
输出
Key = azure Value = #F0FFFF Key = peru Value = #CD853F Key = red Value = #FF0000 Red key exists with value :#FF0000 Maroon key does not exist HashMap(azure -> #F0FFFF, peru -> #CD853F, white -> #FFFFFF, red -> #FF0000) HashMap(azure -> #F0FFFF, peru -> #CD853F, red -> #FF0000) HashMap()
Scala 集合 - ListMap
Scala Map是键/值对的集合。任何值都可以根据其键检索。Map中的键是唯一的,但值不必唯一。ListMap实现不可变Map并使用列表来实现相同的功能。它用于少量元素。
声明ListMap变量
以下是声明 ListMap 变量的语法。
语法
val colors = ListMap("red" -> "#FF0000", "azure" -> "#F0FFFF", "peru" -> "#CD853F")
这里,colors声明为一个包含三个键值对的字符串、Int HashMap。可以使用以下命令添加值:
命令
var myMap1: ListMap[Char, Int] = colors + ("black" -> "#000000");
处理 ListMap
下面是一个示例程序,演示如何创建、初始化和处理 ListMap:
示例
import scala.collection.immutable.ListMap
object Demo {
def main(args: Array[String]) = {
var myMap: ListMap[String,String] = ListMap(
"red" -> "#FF0000", "azure" -> "#F0FFFF", "peru" -> "#CD853F"
);
// Add an element
var myMap1: ListMap[String,String] = myMap + ("white" -> "#FFFFFF");
// Print key values
myMap.keys.foreach{
i =>
print( "Key = " + i )
println(" Value = " + myMap(i) )
}
if( myMap.contains( "red" )) {
println("Red key exists with value :" + myMap("red"))
} else {
println("Red key does not exist")
}
if( myMap.contains( "maroon" )) {
println("Maroon key exists with value :" + myMap("maroon"))
} else {
println("Maroon key does not exist")
}
//removing element
var myMap2: ListMap[String,String] = myMap - ("white");
// Create empty map
var myMap3: ListMap[String,String] = ListMap.empty[String, String];
println(myMap1);
println(myMap2);
println(myMap3);
}
}
将上述程序保存为**Demo.scala**。使用以下命令编译和执行此程序。
命令
\>scalac Demo.scala \>scala Demo
输出
Key = red Value = #FF0000 Key = azure Value = #F0FFFF Key = peru Value = #CD853F Red key exists with value :#FF0000 Maroon key does not exist ListMap(red -> #FF0000, azure -> #F0FFFF, peru -> #CD853F, white -> #FFFFFF) ListMap(red -> #FF0000, azure -> #F0FFFF, peru -> #CD853F) ListMap()
Scala 集合 - 迭代器
迭代器不是集合,而是一种逐一访问集合元素的方法。迭代器 it 的两个基本操作是next 和 hasNext。调用it.next() 将返回迭代器的下一个元素并推进迭代器的状态。您可以使用迭代器的it.hasNext 方法来确定是否还有更多元素可以返回。
遍历迭代器返回的所有元素最直接的方法是使用 while 循环。让我们来看下面的示例程序。
示例
object Demo {
def main(args: Array[String]) {
val it = Iterator("a", "number", "of", "words")
while (it.hasNext){
println(it.next())
}
}
}
将上述程序保存为**Demo.scala**。使用以下命令编译和执行此程序。
命令
\>scalac Demo.scala \>scala Demo
输出
a number of words
查找最小和最大值元素
您可以使用it.min 和it.max 方法来查找迭代器中的最小和最大值元素。这里,我们使用ita 和itb 执行两个不同的操作,因为迭代器只能遍历一次。下面是示例程序。
示例
object Demo {
def main(args: Array[String]) {
val ita = Iterator(20,40,2,50,69, 90)
val itb = Iterator(20,40,2,50,69, 90)
println("Maximum valued element " + ita.max )
println("Minimum valued element " + itb.min )
}
}
将上述程序保存为**Demo.scala**。使用以下命令编译和执行此程序。
命令
\>scalac Demo.scala \>scala Demo
输出
Maximum valued element 90 Minimum valued element 2
查找迭代器的长度
您可以使用it.size 或it.length 方法来查找迭代器中可用元素的数量。这里,我们使用 ita 和 itb 执行两个不同的操作,因为迭代器只能遍历一次。下面是示例程序。
示例
object Demo {
def main(args: Array[String]) {
val ita = Iterator(20,40,2,50,69, 90)
val itb = Iterator(20,40,2,50,69, 90)
println("Value of ita.size : " + ita.size )
println("Value of itb.length : " + itb.length )
}
}
将上述程序保存为**Demo.scala**。使用以下命令编译和执行此程序。
命令
\>scalac Demo.scala \>scala Demo
输出
Value of ita.size : 6 Value of itb.length : 6
Scala 集合 - Option
Scala Option[T] 是一个容器,包含给定类型的一个或零个元素。Option[T] 可以是Some[T] 或None 对象,后者表示缺失的值。例如,Scala 的 Map 的 get 方法如果找到与给定键对应的值,则会产生 Some(value),如果给定键在 Map 中未定义,则会产生None。
Option 类型在 Scala 程序中经常使用,您可以将其与 Java 中的null 值进行比较,后者表示没有值。例如,java.util.HashMap 的 get 方法要么返回存储在 HashMap 中的值,要么如果未找到值则返回 null。
假设我们有一个方法,它根据主键从数据库中检索记录。
def findPerson(key: Int): Option[Person]
如果找到记录,该方法将返回 Some[Person],如果未找到记录,则返回 None。让我们来看下面的程序。
示例
object Demo {
def main(args: Array[String]) {
val capitals = Map("France" -> "Paris", "Japan" -> "Tokyo")
println("capitals.get( \"France\" ) : " + capitals.get( "France" ))
println("capitals.get( \"India\" ) : " + capitals.get( "India" ))
}
}
将上述程序保存为**Demo.scala**。使用以下命令编译和执行此程序。
命令
\>scalac Demo.scala \>scala Demo
输出
capitals.get( "France" ) : Some(Paris) capitals.get( "India" ) : None
分解可选值最常用的方法是模式匹配。例如,尝试以下程序。
示例
object Demo {
def main(args: Array[String]) {
val capitals = Map("France" -> "Paris", "Japan" -> "Tokyo")
println("show(capitals.get( \"Japan\")) : " + show(capitals.get( "Japan")) )
println("show(capitals.get( \"India\")) : " + show(capitals.get( "India")) )
}
def show(x: Option[String]) = x match {
case Some(s) => s
case None => "?"
}
}
将上述程序保存为**Demo.scala**。使用以下命令编译和执行此程序。
命令
\>scalac Demo.scala \>scala Demo
输出
show(capitals.get( "Japan")) : Tokyo show(capitals.get( "India")) : ?
使用 getOrElse() 方法
以下示例程序演示如何使用 getOrElse() 方法访问值或在没有值时使用默认值。
示例
object Demo {
def main(args: Array[String]) {
val a:Option[Int] = Some(5)
val b:Option[Int] = None
println("a.getOrElse(0): " + a.getOrElse(0) )
println("b.getOrElse(10): " + b.getOrElse(10) )
}
}
将上述程序保存为**Demo.scala**。使用以下命令编译和执行此程序。
命令
\>scalac Demo.scala \>scala Demo
输出
a.getOrElse(0): 5 b.getOrElse(10): 10
使用 isEmpty() 方法
以下示例程序演示如何使用 isEmpty() 方法检查选项是否为 None。
示例
object Demo {
def main(args: Array[String]) {
val a:Option[Int] = Some(5)
val b:Option[Int] = None
println("a.isEmpty: " + a.isEmpty )
println("b.isEmpty: " + b.isEmpty )
}
}
将上述程序保存为**Demo.scala**。使用以下命令编译和执行此程序。
命令
\>scalac Demo.scala \>scala Demo
示例
a.isEmpty: false b.isEmpty: true
Scala 集合 - 队列
队列是先进先出 (FIFO) 数据结构,允许以 FIFO 方式插入和检索元素。
声明队列变量
以下是声明队列变量的语法。
语法
val queue = Queue(1, 2, 3, 4, 5)
这里,queue 被声明为一个数字队列。可以使用以下命令在队首添加值:
命令
queue.enqueue(6)
可以使用以下命令从队首检索值:
命令
queue.dequeue()
处理队列
下面是一个示例程序,演示如何创建、初始化和处理队列:
示例
import scala.collection.mutable.Queue
object Demo {
def main(args: Array[String]) = {
var queue = Queue(1, 2, 3, 4, 5);
// Print queue elements
queue.foreach{(element:Int) => print(element + " ")}
println();
// Print first element
println("First Element: " + queue.front)
// Add an element
queue.enqueue(6);
// Print queue elements
queue.foreach{(element:Int) => print(element+ " ")}
println();
// Remove an element
var dq = queue.dequeue;
// Print dequeued element
println("Dequeued Element: " + dq)
// Print queue elements
queue.foreach{(element:Int) => print(element+ " ")}
}
}
将上述程序保存为**Demo.scala**。使用以下命令编译和执行此程序。
命令
\>scalac Demo.scala \>scala Demo
输出
1 2 3 4 5 First Element: 1 1 2 3 4 5 6 Dequeued Element: 1 2 3 4 5 6
Scala 集合 - 元组
Scala 元组将固定数量的项组合在一起,以便可以将其作为一个整体传递。与数组或列表不同,元组可以保存不同类型的对象,但它们也是不可变的。
以下是一个包含整数、字符串和控制台的元组示例。
val t = (1, "hello", Console)
这是以下内容的语法糖(快捷方式):
val t = new Tuple3(1, "hello", Console)
元组的实际类型取决于它包含的元素数量和这些元素的类型。因此,(99, "Luftballons") 的类型是 Tuple2[Int, String]。('u', 'r', "the", 1, 4, "me") 的类型是 Tuple6[Char, Char, String, Int, Int, String]
元组的类型为 Tuple1、Tuple2、Tuple3 等。Scala 中目前上限为 22,如果您需要更多,则可以使用集合,而不是元组。对于每个 TupleN 类型(其中 1 <= N <= 22),Scala 定义了许多元素访问方法。给定以下定义:
val t = (4,3,2,1)
要访问元组 t 的元素,可以使用方法 t._1 访问第一个元素,t._2 访问第二个元素,依此类推。例如,以下表达式计算 t 所有元素的总和。
val sum = t._1 + t._2 + t._3 + t._4
您可以使用元组编写一个方法,该方法接受 List[Double] 并返回一个包含三个元素的元组 Tuple3[Int, Double, Double] 中的计数、总和以及平方和。它们也可用于在并发编程中将数据值列表作为消息传递给参与者之间。
尝试以下示例程序。它演示了如何使用元组。
示例
object Demo {
def main(args: Array[String]) {
val t = (4,3,2,1)
val sum = t._1 + t._2 + t._3 + t._4
println( "Sum of elements: " + sum )
}
}
将上述程序保存为**Demo.scala**。使用以下命令编译和执行此程序。
命令
\>scalac Demo.scala \>scala Demo
输出
Sum of elements: 10
迭代元组
您可以使用Tuple.productIterator() 方法迭代元组的所有元素。
尝试以下示例程序来迭代元组。
示例
object Demo {
def main(args: Array[String]) {
val t = (4,3,2,1)
t.productIterator.foreach{ i =>println("Value = " + i )}
}
}
将上述程序保存为**Demo.scala**。使用以下命令编译和执行此程序。
命令
\>scalac Demo.scala \>scala Demo
输出
Value = 4 Value = 3 Value = 2 Value = 1
转换为字符串
您可以使用Tuple.toString() 方法将元组的所有元素连接成一个字符串。尝试以下示例程序以转换为字符串。
示例
object Demo {
def main(args: Array[String]) {
val t = new Tuple3(1, "hello", Console)
println("Concatenated String: " + t.toString() )
}
}
将上述程序保存为**Demo.scala**。使用以下命令编译和执行此程序。
命令
\>scalac Demo.scala \>scala Demo
输出
Concatenated String: (1,hello,scala.Console$@281acd47)
交换元素
您可以使用Tuple.swap 方法交换 Tuple2 的元素。
尝试以下示例程序来交换元素。
示例
object Demo {
def main(args: Array[String]) {
val t = new Tuple2("Scala", "hello")
println("Swapped Tuple: " + t.swap )
}
}
将上述程序保存为**Demo.scala**。使用以下命令编译和执行此程序。
命令
\>scalac Demo.scala \>scala Demo
输出
Swapped tuple: (hello,Scala)
Scala 集合 - Seq
Scala Seq 是一个代表不可变序列的特征。此结构提供基于索引的访问以及各种实用程序方法来查找元素、它们的出现和子序列。Seq 保持插入顺序。
声明 Seq 变量
以下是声明 Seq 变量的语法。
语法
val seq: Seq[Int] = Seq(1, 2, 3, 4, 5)
这里,seq 被声明为一个数字 Seq。Seq 提供以下命令:
命令
val isPresent = seq.contains(4); val contains = seq.endsWith(Seq(4,5)); var lastIndexOf = seq.lasIndexOf(5);
处理 Seq
下面是一个示例程序,演示如何创建、初始化和处理 Seq:
示例
import scala.collection.immutable.Seq
object Demo {
def main(args: Array[String]) = {
var seq = Seq(1, 2, 3, 4, 5, 3)
// Print seq elements
seq.foreach{(element:Int) => print(element + " ")}
println()
println("Seq ends with (5,3): " + seq.endsWith(Seq(5, 3)))
println("Seq contains 4: " + seq.contains(4))
println("Last index of 3: " + seq.lastIndexOf(3))
println("Reversed Seq" + seq.reverse)
}
}
将上述程序保存为**Demo.scala**。使用以下命令编译和执行此程序。
命令
\>scalac Demo.scala \>scala Demo
输出
1 2 3 4 5 3 Seq ends with (5,3): true Seq contains 4: true Last index of 3: 5 Reversed SeqList(3, 5, 4, 3, 2, 1)
Scala 集合 - 堆栈
栈是后进先出 (LIFO) 数据结构,允许以 LIFO 方式在顶部插入和检索元素。
声明栈变量
以下是声明栈变量的语法。
语法
val stack = Stack(1, 2, 3, 4, 5)
这里,stack 被声明为一个数字栈。可以使用以下命令在顶部添加值:
命令
stack.push(6)
可以使用以下命令从顶部检索值:
命令
stack.top
可以使用以下命令从顶部移除值:
命令
stack.pop
处理栈
下面是一个示例程序,演示如何创建、初始化和处理栈:
示例
import scala.collection.mutable.Stack
object Demo {
def main(args: Array[String]) = {
var stack: Stack[Int] = Stack();
// Add elements
stack.push(1);
stack.push(2);
// Print element at top
println("Top Element: " + stack.top)
// Print element
println("Removed Element: " + stack.pop())
// Print element
println("Top Element: " + stack.top)
}
}
将上述程序保存为**Demo.scala**。使用以下命令编译和执行此程序。
命令
\>scalac Demo.scala \>scala Demo
输出
Top Element: 2 Removed Element: 2 Top Element: 1
Scala 集合 - 流
Scala Stream 是一个具有惰性求值功能的特殊列表。在 Scala Stream 中,只有在需要时才求值元素。Stream 支持惰性计算,并且性能出色。
声明 Stream 变量
以下是声明 Stream 变量的语法。
语法
val stream = 1 #:: 2 #:: 3 #:: Stream.empty
这里,stream 被声明为一个数字流。这里 1 是流的头部,2、3 是流的尾部。Stream.empty 标记流的结尾。可以使用 take 命令检索值,如下所示:
命令
stream.take(2)
处理 Stream
下面是一个示例程序,演示如何创建、初始化和处理 Stream:
示例
import scala.collection.immutable.Stream
object Demo {
def main(args: Array[String]) = {
val stream = 1 #:: 2 #:: 3 #:: Stream.empty
// print stream
println(stream)
// Print first two elements
stream.take(2).print
println()
// Create an empty stream
val stream1: Stream[Int] = Stream.empty[Int]
// Print element
println(s"Stream: $stream1")
}
}
将上述程序保存为**Demo.scala**。使用以下命令编译和执行此程序。
命令
\>scalac Demo.scala \>scala Demo
输出
Stream(1, <not computed>) 1, 2 Stream: Stream()
Scala 集合 - Drop 方法
drop() 方法是 List 使用的方法,用于选择列表中除前 n 个元素之外的所有元素。
语法
以下是 drop 方法的语法。
def drop(n: Int): List[A]
这里,n 是要从列表中删除的元素数。此方法返回列表中除前 n 个元素之外的所有元素。
用法
下面是一个示例程序,演示如何使用 drop 方法:
示例
object Demo {
def main(args: Array[String]) = {
val list = List(1, 2, 3, 4, 5)
// print list
println(list)
//apply operation
val result = list.drop(3)
//print result
println(result)
}
}
将上述程序保存为**Demo.scala**。使用以下命令编译和执行此程序。
命令
\>scalac Demo.scala \>scala Demo
输出
List(1, 2, 3, 4, 5) List(4, 5)
Scala 集合 - DropWhile 方法
dropWhile() 方法是 List 使用的方法,用于删除满足给定条件的所有元素。
语法
以下是 dropWhile 方法的语法。
def dropWhile(p: (A) => Boolean): List[A]
这里,p: (A) => Boolean 是要应用于列表中每个元素的谓词或条件。此方法返回列表中除已删除元素之外的所有元素。
用法
下面是一个示例程序,演示如何使用 dropWhile 方法:
示例
object Demo {
def main(args: Array[String]) = {
val list = List(3, 6, 9, 4, 2)
// print list
println(list)
//apply operation
val result = list.dropWhile(x=>{x % 3 == 0})
//print result
println(result)
}
}
将上述程序保存为**Demo.scala**。使用以下命令编译和执行此程序。
命令
\>scalac Demo.scala \>scala Demo
输出
List(3, 6, 9, 4, 2) List(4, 2)
Scala 集合 - Filter 方法
filter() 方法是 List 使用的方法,用于选择满足给定谓词的所有元素。
语法
以下是 filter 方法的语法。
def filter(p: (A) => Boolean): List[A]
这里,p: (A) => Boolean 是要应用于列表中每个元素的谓词或条件。此方法返回满足给定条件的列表中的所有元素。
用法
下面是一个示例程序,演示如何使用 filter 方法:
示例
object Demo {
def main(args: Array[String]) = {
val list = List(3, 6, 9, 4, 2)
// print list
println(list)
//apply operation
val result = list.filter(x=>{x % 3 == 0})
//print result
println(result)
}
}
将上述程序保存为**Demo.scala**。使用以下命令编译和执行此程序。
命令
\>scalac Demo.scala \>scala Demo
输出
List(3, 6, 9, 4, 2) List(3, 6, 9)
Scala 集合 - Find 方法
find() 方法是迭代器使用的方法,用于查找满足给定谓词的元素。
语法
以下是 find 方法的语法。
def find(p: (A) => Boolean): Option[A]
这里,p: (A) => Boolean 是要应用于迭代器中每个元素的谓词或条件。此方法返回包含满足给定条件的迭代器的匹配元素的 Option 元素。
用法
下面是一个示例程序,演示如何使用 find 方法:
示例
object Demo {
def main(args: Array[String]) = {
val iterator = Iterator(3, 6, 9, 4, 2)
//apply operation
val result = iterator.find(x=>{x % 3 == 0})
//print result
println(result)
}
}
将上述程序保存为**Demo.scala**。使用以下命令编译和执行此程序。
命令
\>scalac Demo.scala \>scala Demo
输出
Some(3)
Scala 集合 - FlatMap 方法
flatMap() 方法是 TraversableLike 特征的方法,它接受一个谓词,将其应用于集合的每个元素,并返回谓词返回的新元素集合。
语法
以下是 flatMap 方法的语法。
def flatMap[B](f: (A) ? GenTraversableOnce[B]): TraversableOnce[B]
这里,f: (A) => GenTraversableOnce[B] 是要应用于集合中每个元素的谓词或条件。此方法返回包含满足给定条件的迭代器的匹配元素的 Option 元素。
用法
下面是一个示例程序,演示如何使用 flatMap 方法:
示例
object Demo {
def main(args: Array[String]) = {
val list = List(1, 5, 10)
//apply operation
val result = list.flatMap{x => List(x,x+1)}
//print result
println(result)
}
}
将上述程序保存为**Demo.scala**。使用以下命令编译和执行此程序。
命令
\>scalac Demo.scala \>scala Demo
输出
List(1, 2, 5, 6, 10, 11)
Scala 集合 - Flatten 方法
flatten() 方法是 GenericTraversableTemplate 特征的成员,它通过合并子集合来返回单个元素集合。
语法
以下是 flatten 方法的语法。
def flatten[B]: Traversable[B]
这里,f: (A) => GenTraversableOnce[B] 是要应用于集合中每个元素的谓词或条件。此方法返回包含满足给定条件的迭代器的匹配元素的 Option 元素。
用法
下面是一个示例程序,演示如何使用 flatten 方法:
示例
object Demo {
def main(args: Array[String]) = {
val list = List(List(1,2), List(3,4))
//apply operation
val result = list.flatten
//print result
println(result)
}
}
将上述程序保存为**Demo.scala**。使用以下命令编译和执行此程序。
命令
\>scalac Demo.scala \>scala Demo
输出
List(1, 2, 3, 4)
Scala 集合 - Fold 方法
fold() 方法是 TraversableOnce 特征的成员,它用于折叠集合的元素。
语法
以下是 fold 方法的语法。
def fold[A1 >: A](z: A1)(op: (A1, A1) ? A1): A1
这里,fold 方法将关联二元运算符函数作为参数。此方法将结果作为值返回。它将第一个输入视为初始值,将第二个输入视为函数(它将累积值和当前项作为输入)。
用法
下面是一个示例程序,演示如何使用 fold 方法:
示例
object Demo {
def main(args: Array[String]) = {
val list = List(1, 2, 3 ,4)
//apply operation to get sum of all elements of the list
val result = list.fold(0)(_ + _)
//print result
println(result)
}
}
这里,我们将 0 作为初始值传递给 fold 函数,然后添加所有值。将上面的程序保存在Demo.scala中。以下命令用于编译和执行此程序。
命令
\>scalac Demo.scala \>scala Demo
输出
10
Scala 集合 - FoldLeft 方法
foldLeft() 方法是 TraversableOnce 特性(trait)的成员,用于折叠集合中的元素。它从左到右遍历元素。主要用于递归函数,可以防止堆栈溢出异常。
语法
以下是 fold 方法的语法。
def foldLeft[B](z: B)(op: (B, A) ? B): B
这里,foldLeft 方法接受一个关联二元运算符函数作为参数。此方法返回结果值。
用法
下面是一个演示如何使用 foldLeft 方法的示例程序:
示例
object Demo {
def main(args: Array[String]) = {
val list = List(1, 2, 3 ,4)
//apply operation to get sum of all elements of the list
val result = list.foldLeft(0)(_ + _)
//print result
println(result)
}
}
这里,我们将 0 作为初始值传递给 fold 函数,然后添加所有值。将上面的程序保存在Demo.scala中。以下命令用于编译和执行此程序。
命令
\>scalac Demo.scala \>scala Demo
输出
10
Scala 集合 - foldRight 方法
foldRight() 方法是 TraversableOnce 特性的成员,用于折叠集合中的元素。它从右到左遍历元素。
语法
以下是 foldRight 方法的语法。
def foldRight[B](z: B)(op: (B, A) ? B): B
这里,fold 方法接受一个关联二元运算符函数作为参数。此方法返回结果值。
用法
下面是一个演示如何使用 foldRight 方法的示例程序:
示例
object Demo {
def main(args: Array[String]) = {
val list = List(1, 2, 3 ,4)
//apply operation to get sum of all elements of the list
val result = list.foldRight(0)(_ + _)
//print result
println(result)
}
}
这里我们将 0 作为初始值传递给 foldRight 函数,然后将所有值相加。将上述程序保存为 **Demo.scala** 文件。使用以下命令编译并执行此程序。
命令
\>scalac Demo.scala \>scala Demo
输出
10
Scala 集合 - map 方法
map() 方法是 TraversableLike 特性的成员,用于对集合的每个元素运行一个谓词方法。它返回一个新的集合。
语法
以下是 map 方法的语法。
def map[B](f: (A) ? B): Traversable[B]
这里,map 方法接受一个谓词函数作为参数。此方法返回更新后的集合。
用法
下面是一个演示如何使用 map 方法的示例程序:
示例
object Demo {
def main(args: Array[String]) = {
val list = List(1, 2, 3 ,4)
//apply operation to get twice of each element.
val result = list.map(_ * 2)
//print result
println(result)
}
}
将上述程序保存为**Demo.scala**。使用以下命令编译和执行此程序。
命令
\>scalac Demo.scala \>scala Demo
输出
List(2, 4, 6, 8)
Scala 集合 - partition 方法
partition() 方法是 TraversableLike 特性的成员,用于对集合的每个元素运行一个谓词方法。它返回两个集合,一个集合包含满足给定谓词函数的元素,另一个集合包含不满足给定谓词函数的元素。
语法
以下是 map 方法的语法。
def partition(p: (A) ? Boolean): (Repr, Repr)
这里,partition 方法接受一个谓词函数作为参数。此方法返回这些集合。
用法
下面是一个演示如何使用 partition 方法的示例程序:
示例
object Demo {
def main(args: Array[String]) = {
val list = List(1, 2, 3, 4, 5, 6, 7)
//apply operation to get twice of each element.
val (result1, result2) = list.partition(x=>{x % 3 == 0})
//print result
println(result1)
println(result2)
}
}
将上述程序保存为**Demo.scala**。使用以下命令编译和执行此程序。
命令
\>scalac Demo.scala \>scala Demo
输出
List(3, 6) List(1, 2, 4, 5, 7)
Scala 集合 - reduce 方法
reduce() 方法是 TraversableOnce 特性的成员,用于折叠集合中的元素。它类似于 fold 方法,但它不接受初始值。
语法
以下是 reduce 方法的语法。
def reduce[A1 >: A](op: (A1, A1) ? A1): A1
这里,reduce 方法接受一个关联二元运算符函数作为参数。此方法返回结果值。
用法
下面是一个示例程序,演示如何使用 fold 方法:
示例
object Demo {
def main(args: Array[String]) = {
val list = List(1, 2, 3 ,4)
//apply operation to get sum of all elements of the list
val result = list.reduce(_ + _)
//print result
println(result)
}
}
将上述程序保存为**Demo.scala**。使用以下命令编译和执行此程序。
命令
\>scalac Demo.scala \>scala Demo
输出
10
Scala 集合 - scan 方法
scan() 方法是 TraversableLike 特性的成员,类似于 fold 方法,但用于对集合的每个元素应用一个操作并返回一个集合。
语法
以下是 fold 方法的语法。
def scan[B >: A, That](z: B)(op: (B, B) ? B)(implicit cbf: CanBuildFrom[Repr, B, That]): That
这里,scan 方法接受一个关联二元运算符函数作为参数。此方法返回更新后的集合作为结果。它将第一个输入作为初始值,第二个输入作为函数。
用法
下面是一个演示如何使用 scan 方法的示例程序:
示例
object Demo {
def main(args: Array[String]) = {
val list = List(1, 2, 3 ,4)
//apply operation to create a running total of all elements of the list
val list1 = list.scan(0)(_ + _)
//print list
println(list1)
}
}
这里我们将 0 作为初始值传递给 scan 函数,然后将所有值相加。将上述程序保存为 **Demo.scala** 文件。使用以下命令编译并执行此程序。
命令
\>scalac Demo.scala \>scala Demo
输出
List(0, 1, 3, 6, 10)
Scala 集合 - zip 方法
zip() 方法是 IterableLike 特性的成员,用于将一个集合与当前集合合并,结果是一个包含来自两个集合的成对元组元素的集合。
语法
以下是 zip 方法的语法。
def zip[B](that: GenIterable[B]): Iterable[(A, B)]
这里,zip 方法接受一个集合作为参数。此方法返回更新后的成对集合作为结果。
用法
下面是一个演示如何使用 zip 方法的示例程序:
示例
object Demo {
def main(args: Array[String]) = {
val list = List(1, 2, 3 ,4)
val list1 = List("A", "B", "C", "D")
//apply operation to create a zip of list
val list2 = list zip list1
//print list
println(list2)
}
}
将上述程序保存为**Demo.scala**。使用以下命令编译和执行此程序。
命令
\>scalac Demo.scala \>scala Demo
输出
List((1,A), (2,B), (3,C), (4,D))