
 数据结构
数据结构 网络
网络 关系数据库管理系统
关系数据库管理系统 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 编程
C 编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP符号表中定长数组和变长数组的表示方法是什么?
符号表是一种数据结构,它支持一种有效且高效的方式来存储源代码中出现的各种名称的相关数据。这些名称在源代码中用于标识不同的程序元素,例如变量、常量、过程和语句的标签。
每次在源文本中遇到名称时,都会搜索符号表。当找到新名称或有关现有名称的新数据时,符号表的内容会修改。因此,符号表应该具有有效的结构,以便创建表中保存的数据,以及将新条目插入符号表。
在符号表中表示名称的方法有很多,例如定长数组表示和变长数组表示。
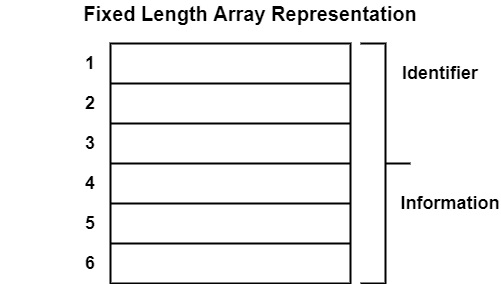
定长数组表示
这是在连续数组记录中表示名称的最简单方法之一。
符号表的名称字段大小固定。
类似地,可以存储的特定名称信息的量的大小也是固定的。
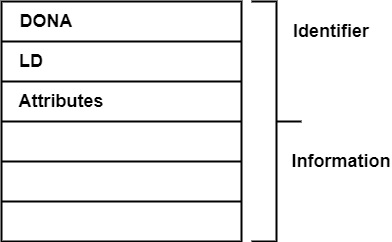
考虑 IBM 370 表示
- 标识符长度 = 8 个字符
- 信息量 = 16 个字符
假设每个块只能存储 4 个字符。因此,我们需要 2 个块来存储标识符,4 个块来存储其信息。
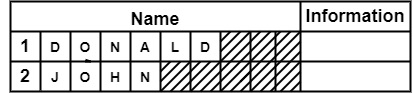
让我们考虑名称 **DONALD**。
可以看出,分配给名称的空间被浪费了,因为只占用了 1.5 个块。但是,名称使用了 2 个块。让我们考虑另一个例子。

这里浪费了一个完整的块。我们使用下图总结了这一点。符号表中的阴影框表示内存浪费。
优点
- 易于理解。
- 易于实现和访问。
缺点
- 浪费大量内存。
- 顺序访问
- 记录的插入和删除速度相对较慢。
- 需要大量的处理和内存需求。
变长数组表示
它不会将名称直接存储在符号表中,而是将所有名称存储在一个独立的字符数组中,并且只保留名称的起始索引和长度。这将克服定长名称的缺点。现在它可以具有超过 8 个字符的可变长度,因为在以前的方法中它是固定的。类似地,我们可以将前面的示例表示为
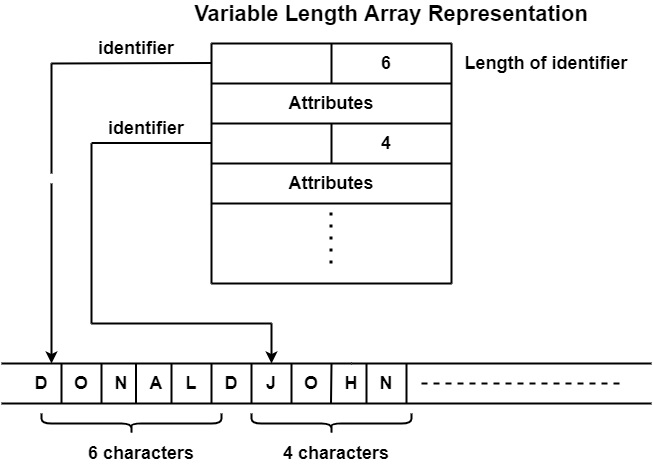
优点
- 变量名可以是任意长度。
- 易于访问。
- 符号表中没有浪费内存。
- 符号表现在更有条理。
- 它可以促进更快的编辑。
缺点
- 间接维护问题。
- 需要额外的数组记录来存储变量名。

更新于: 2021-11-08
1K+ 浏览量

广告