- Apache Solr 教程
- Apache Solr - 首页
- Apache Solr - 概述
- Apache Solr - 搜索引擎基础
- Apache Solr - Windows环境
- Apache Solr - 在Hadoop上
- Apache Solr - 架构
- Apache Solr - 术语
- Apache Solr - 基本命令
- Apache Solr - Core
- Apache Solr - 索引数据
- Apache Solr - 添加文档 (XML)
- Apache Solr - 更新数据
- Apache Solr - 删除文档
- Apache Solr - 检索数据
- Apache Solr - 查询数据
- Apache Solr - 分面搜索
- Apache Solr 有用资源
- Apache Solr 快速指南
- Apache Solr - 有用资源
- Apache Solr - 讨论
Apache Solr 快速指南
Apache Solr - 概述
Solr是一个开源搜索平台,用于构建搜索应用程序。它构建在Lucene(全文搜索引擎)之上。Solr 具备企业级功能,快速且高度可扩展。使用Solr构建的应用程序功能强大,性能高。
Yonik Seely于2004年创建了Solr,目的是为CNET Networks的公司网站添加搜索功能。2006年1月,它成为Apache软件基金会下的一个开源项目。其最新版本Solr 6.0于2016年发布,支持并行SQL查询的执行。
Solr可以与Hadoop一起使用。由于Hadoop处理大量数据,Solr帮助我们从如此庞大的数据源中找到所需的信息。Solr不仅用于搜索,还可以用于存储。像其他NoSQL数据库一样,它是一种非关系型数据存储和处理技术。
简而言之,Solr是一个可扩展、随时部署的搜索/存储引擎,经过优化,可以搜索大量以文本为中心的数据。
Apache Solr 的特性
Solr是对Lucene的Java API的封装。因此,使用Solr,您可以利用Lucene的所有功能。让我们来看看Solr的一些最突出的功能:
RESTful API - 与Solr通信,不需要掌握Java编程技能。您可以使用RESTful服务与之通信。我们以XML、JSON和.CSV等文件格式将文档输入Solr,并以相同的格式获取结果。
全文搜索 - Solr提供全文搜索所需的所有功能,例如标记、短语、拼写检查、通配符和自动完成。
企业级 - 根据组织的需求,Solr可以部署在任何类型的系统(大型或小型)中,例如独立部署、分布式部署、云部署等。
灵活且可扩展 - 通过扩展Java类并进行相应配置,我们可以轻松定制Solr的组件。
NoSQL数据库 - Solr也可以用作大规模NoSQL数据库,我们可以在集群中分配搜索任务。
管理界面 - Solr提供了一个易于使用、用户友好、功能强大的用户界面,我们可以使用它来执行所有可能的任务,例如管理日志、添加、删除、更新和搜索文档。
高度可扩展 - 将Solr与Hadoop一起使用时,我们可以通过添加副本来扩展其容量。
以文本为中心并按相关性排序 - Solr主要用于搜索文本文档,结果按与用户查询的相关性顺序交付。
与Lucene不同,在使用Apache Solr时,您不需要具备Java编程技能。它提供了一种很棒的随时可部署的服务来构建具有自动完成功能的搜索框,而Lucene则不提供此功能。使用Solr,我们可以扩展、分发和管理索引,以用于大型(大数据)应用程序。
Lucene 在搜索应用程序中的应用
Lucene是一个简单而强大的基于Java的搜索库。它可以用于任何应用程序以添加搜索功能。Lucene是一个可扩展且高性能的库,用于索引和搜索几乎任何类型的文本。Lucene库提供了任何搜索应用程序所需的核心操作,例如索引和搜索。
如果我们有一个包含大量数据的数据门户,那么我们很可能需要在我们的门户中使用搜索引擎来从庞大的数据池中提取相关信息。Lucene作为任何搜索应用程序的核心,并提供与索引和搜索相关的关键操作。
Apache Solr - 搜索引擎基础
搜索引擎是指互联网资源(如网页、新闻组、程序、图像等)的巨大数据库。它有助于在万维网上查找信息。
用户可以通过以关键字或短语的形式将查询传递到搜索引擎来搜索信息。然后,搜索引擎在其数据库中搜索并向用户返回相关链接。
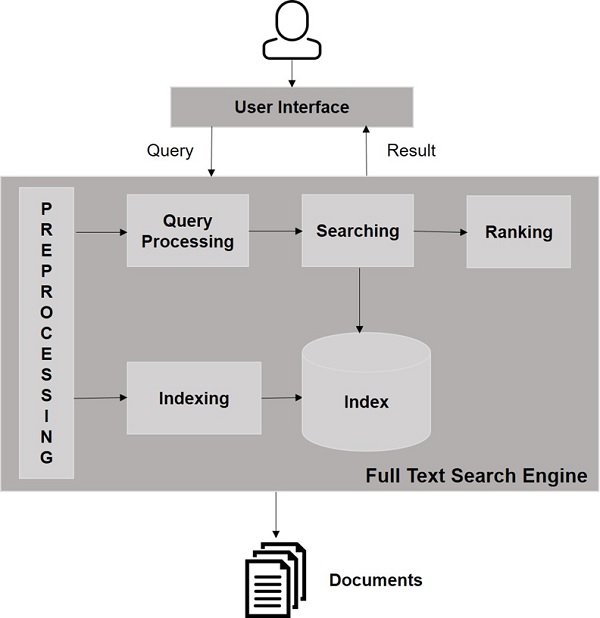
搜索引擎组件
通常,搜索引擎有三个基本组件,如下所示:
网络爬虫 - 网络爬虫也称为蜘蛛或机器人。它是一个遍历网络以收集信息的软件组件。
数据库 - 网络上的所有信息都存储在数据库中。它们包含大量的网络资源。
搜索接口 - 此组件是用户和数据库之间的接口。它帮助用户搜索数据库。
搜索引擎的工作原理?
任何搜索应用程序都需要执行以下部分或全部操作。
| 步骤 | 标题 | 描述 |
|---|---|---|
1 |
获取原始内容 |
任何搜索应用程序的第一步都是收集要进行搜索的目标内容。 |
2 |
构建文档 |
下一步是从原始内容构建文档,以便搜索应用程序可以轻松理解和解释。 |
3 |
分析文档 |
在索引开始之前,需要分析文档。 |
4 |
索引文档 |
一旦文档被构建和分析,下一步就是对其进行索引,以便可以基于某些键检索此文档,而不是文档的全部内容。 索引类似于我们在书末尾的索引,其中显示了常用词及其页码,以便可以快速跟踪这些词,而不是搜索整本书。 |
5 |
搜索的用户界面 |
一旦索引数据库准备就绪,应用程序就可以执行搜索操作。为了帮助用户进行搜索,应用程序必须提供一个用户界面,用户可以在其中输入文本并启动搜索过程。 |
6 |
构建查询 |
一旦用户请求搜索文本,应用程序应该使用该文本准备一个查询对象,然后可以使用该对象查询索引数据库以获取相关详细信息。 |
7 |
搜索查询 |
使用查询对象,检查索引数据库以获取相关详细信息和内容文档。 |
8 |
呈现结果 |
一旦收到所需的结果,应用程序应该决定如何使用其用户界面向用户显示结果。 |
请看下图。它显示了搜索引擎功能的整体视图。
除了这些基本操作外,搜索应用程序还可以提供管理用户界面,以帮助管理员根据用户配置文件控制搜索级别。搜索结果分析是任何搜索应用程序的另一个重要且高级方面。
Apache Solr - 在 Windows 环境中
本章将讨论如何在Windows环境中设置Solr。要在Windows系统上安装Solr,您需要按照以下步骤操作:
访问Apache Solr的主页,然后单击下载按钮。
选择一个镜像以获取Apache Solr的索引。从那里下载名为Solr-6.2.0.zip的文件。
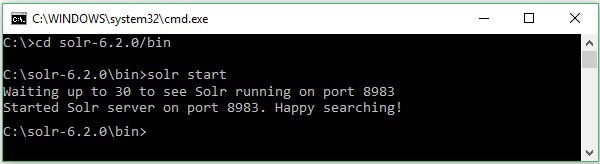
将文件从下载文件夹移动到所需目录并解压缩。
假设您下载了Solr文件并将其解压缩到C盘。在这种情况下,您可以像以下屏幕截图所示启动Solr。
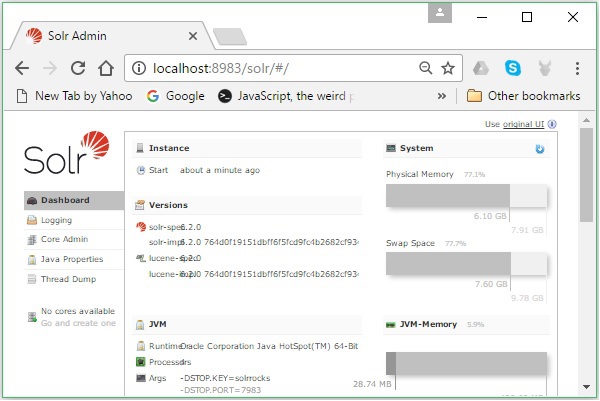
要验证安装,请在浏览器中使用以下URL。
https://:8983/
如果安装过程成功,您将看到Apache Solr用户界面的仪表板,如下所示。
设置Java环境
我们还可以使用Java库与Apache Solr通信;但在使用Java API访问Solr之前,您需要为这些库设置类路径。
设置类路径
在.bashrc文件中将类路径设置为Solr库。在任何编辑器中打开.bashrc,如下所示。
$ gedit ~/.bashrc
设置Solr库(HBase中的lib文件夹)的类路径,如下所示。
export CLASSPATH = $CLASSPATH://home/hadoop/Solr/lib/*
这是为了防止在使用Java API访问HBase时出现“找不到类”异常。
Apache Solr - 在Hadoop上
Solr可以与Hadoop一起使用。由于Hadoop处理大量数据,Solr帮助我们从如此庞大的数据源中找到所需的信息。在本节中,让我们了解如何在您的系统上安装Hadoop。
下载Hadoop
以下是下载Hadoop到您的系统的步骤。
步骤1 - 转到Hadoop的主页。您可以使用链接:www.hadoop.apache.org/。单击Releases链接,如下面的屏幕截图中突出显示的那样。
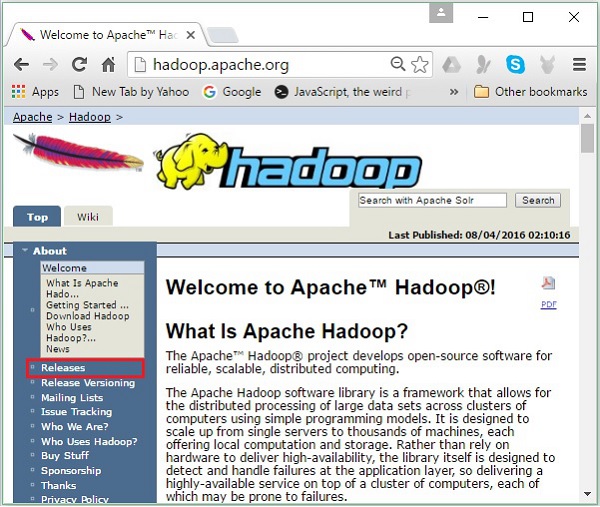
它将引导您进入Apache Hadoop Releases页面,其中包含各种版本的Hadoop的源文件和二进制文件的镜像链接,如下所示:
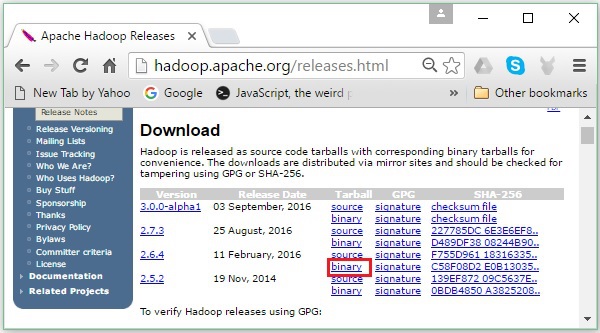
步骤2 - 选择最新版本的Hadoop(在本教程中为2.6.4),然后单击其二进制链接。它将带您到一个页面,其中提供Hadoop二进制文件的镜像。单击这些镜像之一以下载Hadoop。
从命令提示符下载Hadoop
打开Linux终端并以超级用户身份登录。
$ su password:
进入需要安装Hadoop的目录,使用之前复制的链接将文件保存到该目录,如下面的代码块所示。
# cd /usr/local # wget http://redrockdigimark.com/apachemirror/hadoop/common/hadoop- 2.6.4/hadoop-2.6.4.tar.gz
下载Hadoop后,使用以下命令解压。
# tar zxvf hadoop-2.6.4.tar.gz # mkdir hadoop # mv hadoop-2.6.4/* to hadoop/ # exit
安装Hadoop
按照以下步骤以伪分布式模式安装**Hadoop**。
步骤1:设置Hadoop
您可以通过将以下命令添加到**~/.bashrc**文件中来设置Hadoop环境变量。
export HADOOP_HOME = /usr/local/hadoop export HADOOP_MAPRED_HOME = $HADOOP_HOME export HADOOP_COMMON_HOME = $HADOOP_HOME export HADOOP_HDFS_HOME = $HADOOP_HOME export YARN_HOME = $HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR = $HADOOP_HOME/lib/native export PATH = $PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin export HADOOP_INSTALL = $HADOOP_HOME
接下来,将所有更改应用到当前运行的系统中。
$ source ~/.bashrc
步骤2:Hadoop配置
您可以在“$HADOOP_HOME/etc/hadoop”位置找到所有Hadoop配置文件。需要根据您的Hadoop基础架构更改这些配置文件。
$ cd $HADOOP_HOME/etc/hadoop
为了使用Java开发Hadoop程序,您必须通过将**JAVA_HOME**值替换为系统中Java的路径来重置**hadoop-env.sh**文件中的Java环境变量。
export JAVA_HOME = /usr/local/jdk1.7.0_71
以下是您必须编辑以配置Hadoop的文件列表:
- core-site.xml
- hdfs-site.xml
- yarn-site.xml
- mapred-site.xml
core-site.xml
**core-site.xml**文件包含诸如Hadoop实例使用的端口号、分配给文件系统的内存、存储数据的内存限制以及读/写缓冲区大小等信息。
打开core-site.xml并在<configuration>,</configuration>标签内添加以下属性。
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://:9000</value>
</property>
</configuration>
hdfs-site.xml
**hdfs-site.xml**文件包含诸如复制数据的值、**namenode**路径和本地文件系统的**datanode**路径等信息。这意味着您要存储Hadoop基础架构的位置。
让我们假设以下数据。
dfs.replication (data replication value) = 1 (In the below given path /hadoop/ is the user name. hadoopinfra/hdfs/namenode is the directory created by hdfs file system.) namenode path = //home/hadoop/hadoopinfra/hdfs/namenode (hadoopinfra/hdfs/datanode is the directory created by hdfs file system.) datanode path = //home/hadoop/hadoopinfra/hdfs/datanode
打开此文件并在<configuration>,</configuration>标签内添加以下属性。
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode</value>
</property>
</configuration>
**注意** — 在上面的文件中,所有属性值都是用户定义的,您可以根据您的Hadoop基础架构进行更改。
yarn-site.xml
此文件用于将yarn配置到Hadoop中。打开yarn-site.xml文件,并在该文件的<configuration>,</configuration>标签之间添加以下属性。
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
mapred-site.xml
此文件用于指定我们正在使用哪个MapReduce框架。默认情况下,Hadoop包含yarn-site.xml的模板。首先,需要使用以下命令将文件从**mapred-site,xml.template**复制到**mapred-site.xml**文件。
$ cp mapred-site.xml.template mapred-site.xml
打开**mapred-site.xml**文件,并在<configuration>,</configuration>标签内添加以下属性。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
验证Hadoop安装
以下步骤用于验证Hadoop安装。
步骤1:Name Node设置
使用命令“hdfs namenode –format”设置namenode,如下所示。
$ cd ~ $ hdfs namenode -format
预期结果如下所示。
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = localhost/192.168.1.11 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.6.4 ... ... 10/24/14 21:30:56 INFO common.Storage: Storage directory /home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted. 10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0 10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11 ************************************************************/
步骤2:验证Hadoop dfs
以下命令用于启动Hadoop dfs。执行此命令将启动您的Hadoop文件系统。
$ start-dfs.sh
预期输出如下:
10/24/14 21:37:56 Starting namenodes on [localhost] localhost: starting namenode, logging to /home/hadoop/hadoop-2.6.4/logs/hadoop- hadoop-namenode-localhost.out localhost: starting datanode, logging to /home/hadoop/hadoop-2.6.4/logs/hadoop- hadoop-datanode-localhost.out Starting secondary namenodes [0.0.0.0]
步骤3:验证Yarn脚本
以下命令用于启动Yarn脚本。执行此命令将启动您的Yarn守护进程。
$ start-yarn.sh
预期输出如下:
starting yarn daemons starting resourcemanager, logging to /home/hadoop/hadoop-2.6.4/logs/yarn- hadoop-resourcemanager-localhost.out localhost: starting nodemanager, logging to /home/hadoop/hadoop- 2.6.4/logs/yarn-hadoop-nodemanager-localhost.out
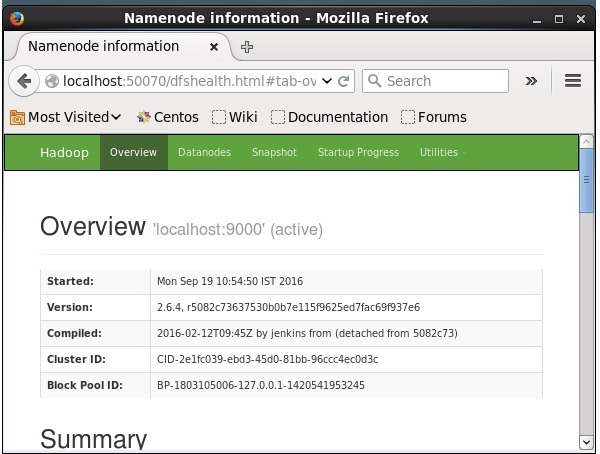
步骤4:在浏览器上访问Hadoop
访问Hadoop的默认端口号是50070。使用以下URL在浏览器上获取Hadoop服务。
https://:50070/
在Hadoop上安装Solr
按照以下步骤下载和安装Solr。
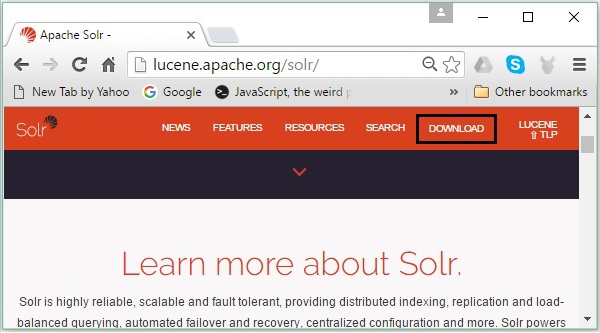
步骤1
单击以下链接打开Apache Solr的主页:https://lucene.apache.org/solr/
步骤2
单击**下载按钮**(如上截图中突出显示的那样)。单击后,您将被重定向到一个页面,其中包含Apache Solr的各种镜像。选择一个镜像并单击它,这将重定向您到一个页面,您可以在该页面下载Apache Solr的源文件和二进制文件,如下面的截图所示。
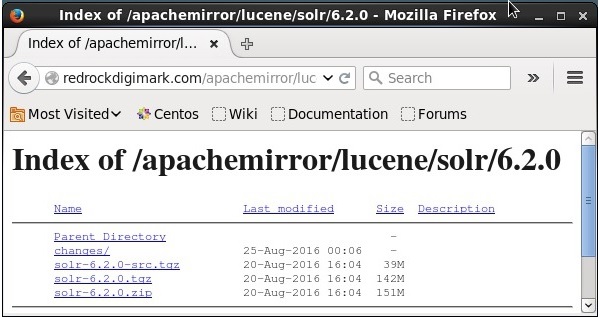
步骤3
单击后,系统下载文件夹中将下载一个名为**Solr-6.2.0.tqz**的文件夹。解压下载文件夹的内容。
步骤4
在Hadoop主目录中创建一个名为Solr的文件夹,并将解压文件夹的内容移动到该文件夹中,如下所示。
$ mkdir Solr $ cd Downloads $ mv Solr-6.2.0 /home/Hadoop/
验证
浏览Solr主目录的**bin**文件夹,并使用**version**选项验证安装,如下面的代码块所示。
$ cd bin/ $ ./Solr version 6.2.0
设置主目录和路径
使用以下命令打开**.bashrc**文件:
[Hadoop@localhost ~]$ source ~/.bashrc
现在为Apache Solr设置主目录和路径目录,如下所示:
export SOLR_HOME = /home/Hadoop/Solr export PATH = $PATH:/$SOLR_HOME/bin/
打开终端并执行以下命令:
[Hadoop@localhost Solr]$ source ~/.bashrc
现在,您可以从任何目录执行Solr命令。
Apache Solr - 架构
在本章中,我们将讨论Apache Solr的架构。下图显示了Apache Solr架构的框图。
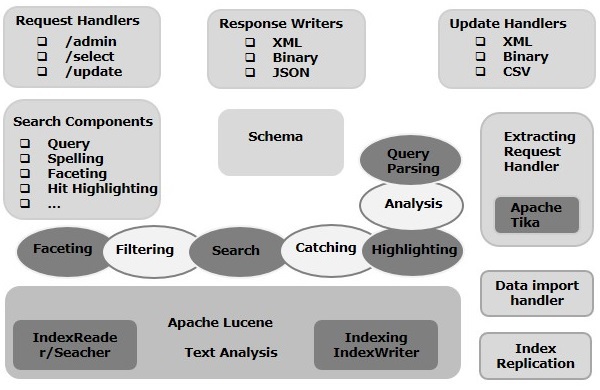
Solr架构 — 构建块
以下是Apache Solr的主要构建块(组件):
**请求处理器** — 我们发送给Apache Solr的请求由这些请求处理器处理。请求可能是查询请求或索引更新请求。根据我们的需求,我们需要选择请求处理器。要将请求传递给Solr,我们通常会将处理程序映射到某个URI端点,并由其提供指定的请求服务。
**搜索组件** — 搜索组件是Apache Solr中提供的搜索类型(功能)。它可能是拼写检查、查询、构面、命中高亮显示等。这些搜索组件注册为**搜索处理程序**。多个组件可以注册到一个搜索处理程序。
**查询解析器** — Apache Solr查询解析器解析我们传递给Solr的查询,并验证查询的语法错误。解析查询后,它会将它们转换为Lucene可以理解的格式。
**响应编写器** — Apache Solr中的响应编写器是为用户查询生成格式化输出的组件。Solr支持XML、JSON、CSV等响应格式。我们为每种类型的响应都有不同的响应编写器。
**分析器/标记器** — Lucene以标记的形式识别数据。Apache Solr分析内容,将其划分为标记,并将这些标记传递给Lucene。Apache Solr中的分析器检查字段的文本并生成标记流。标记器将分析器准备的标记流分解为标记。
**更新请求处理器** — 每当我们向Apache Solr发送更新请求时,该请求都会通过一组插件(签名、日志记录、索引)运行,这些插件统称为**更新请求处理器**。此处理器负责修改,例如删除字段、添加字段等。
Apache Solr - 术语
在本章中,我们将尝试理解在使用Solr时经常使用的一些术语的真正含义。
常用术语
以下是所有类型的Solr设置中使用的常用术语列表:
**实例** — 与**tomcat实例**或**jetty实例**一样,此术语指的是在JVM内运行的应用程序服务器。Solr的主目录提供了对每个Solr实例的引用,其中可以在每个实例中配置一个或多个核心来运行。
**核心** — 在应用程序中运行多个索引时,您可以在每个实例中拥有多个核心,而不是每个实例拥有一个核心。
**主目录** — 术语$SOLR_HOME指的是包含有关核心及其索引、配置和依赖项的所有信息的根目录。
**分片** — 在分布式环境中,数据在多个Solr实例之间进行分区,其中每个数据块都可以称为**分片**。它包含整个索引的子集。
SolrCloud术语
在前面的一章中,我们讨论了如何在独立模式下安装Apache Solr。请注意,我们也可以在分布式模式(云环境)下安装Solr,其中Solr以主从模式安装。在分布式模式下,索引是在主服务器上创建的,并复制到一个或多个从服务器。
与Solr Cloud相关的关键术语如下:
**节点** — 在Solr Cloud中,Solr的每个单个实例都被视为一个**节点**。
**集群** — 环境的所有节点组合在一起构成一个**集群**。
**集合** — 集群具有一个称为**集合**的逻辑索引。
**分片** — 分片是集合的一部分,它具有一个或多个索引副本。
**副本** — 在Solr Core中,在节点中运行的分片副本称为**副本**。
**领导者** — 它也是分片的副本,它将Solr Cloud的请求分发到其余的副本。
**Zookeeper** — 这是一个Apache项目,Solr Cloud使用它进行集中式配置和协调,以管理集群并选举领导者。
配置文件
Apache Solr中的主要配置文件如下:
**Solr.xml** — 它是$SOLR_HOME目录中的文件,包含Solr Cloud相关信息。要加载核心,Solr会引用此文件,这有助于识别它们。
**Solrconfig.xml** — 此文件包含与请求处理和响应格式相关的定义和特定于核心的配置,以及索引、配置、内存管理和提交。
**Schema.xml** — 此文件包含整个模式以及字段和字段类型。
**Core.properties** — 此文件包含特定于核心的配置。它用于**核心发现**,因为它包含核心的名称和数据目录的路径。它可以用于任何目录,然后将其视为**核心目录**。
Apache Solr - 基本命令
启动Solr
安装Solr后,浏览Solr主目录中的**bin**文件夹,并使用以下命令启动Solr。
[Hadoop@localhost ~]$ cd [Hadoop@localhost ~]$ cd Solr/ [Hadoop@localhost Solr]$ cd bin/ [Hadoop@localhost bin]$ ./Solr start
此命令在后台启动Solr,侦听端口8983,并显示以下消息。
Waiting up to 30 seconds to see Solr running on port 8983 [\] Started Solr server on port 8983 (pid = 6035). Happy searching!
在前景启动Solr
如果您使用**start**命令启动**Solr**,则Solr将在后台启动。相反,您可以使用**–f选项**在前景启动Solr。
[Hadoop@localhost bin]$ ./Solr start –f 5823 INFO (coreLoadExecutor-6-thread-2) [ ] o.a.s.c.SolrResourceLoader Adding 'file:/home/Hadoop/Solr/contrib/extraction/lib/xmlbeans-2.6.0.jar' to classloader 5823 INFO (coreLoadExecutor-6-thread-2) [ ] o.a.s.c.SolrResourceLoader Adding 'file:/home/Hadoop/Solr/dist/Solr-cell-6.2.0.jar' to classloader 5823 INFO (coreLoadExecutor-6-thread-2) [ ] o.a.s.c.SolrResourceLoader Adding 'file:/home/Hadoop/Solr/contrib/clustering/lib/carrot2-guava-18.0.jar' to classloader 5823 INFO (coreLoadExecutor-6-thread-2) [ ] o.a.s.c.SolrResourceLoader Adding 'file:/home/Hadoop/Solr/contrib/clustering/lib/attributes-binder1.3.1.jar' to classloader 5823 INFO (coreLoadExecutor-6-thread-2) [ ] o.a.s.c.SolrResourceLoader Adding 'file:/home/Hadoop/Solr/contrib/clustering/lib/simple-xml-2.7.1.jar' to classloader …………………………………………………………………………………………………………………………………………………………………………………………………………… …………………………………………………………………………………………………………………………………………………………………………………………………. 12901 INFO (coreLoadExecutor-6-thread-1) [ x:Solr_sample] o.a.s.u.UpdateLog Took 24.0ms to seed version buckets with highest version 1546058939881226240 12902 INFO (coreLoadExecutor-6-thread-1) [ x:Solr_sample] o.a.s.c.CoreContainer registering core: Solr_sample 12904 INFO (coreLoadExecutor-6-thread-2) [ x:my_core] o.a.s.u.UpdateLog Took 16.0ms to seed version buckets with highest version 1546058939894857728 12904 INFO (coreLoadExecutor-6-thread-2) [ x:my_core] o.a.s.c.CoreContainer registering core: my_core
在另一个端口上启动Solr
使用**start**命令的**–p选项**,我们可以在另一个端口启动Solr,如下面的代码块所示。
[Hadoop@localhost bin]$ ./Solr start -p 8984 Waiting up to 30 seconds to see Solr running on port 8984 [-] Started Solr server on port 8984 (pid = 10137). Happy searching!
停止Solr
您可以使用**stop**命令停止Solr。
$ ./Solr stop
此命令停止Solr,并显示如下消息。
Sending stop command to Solr running on port 8983 ... waiting 5 seconds to allow Jetty process 6035 to stop gracefully.
重新启动Solr
Solr的**restart**命令会停止Solr 5 秒钟,然后再次启动它。您可以使用以下命令重新启动Solr:
./Solr restart
此命令重新启动Solr,并显示以下消息:
Sending stop command to Solr running on port 8983 ... waiting 5 seconds to allow Jetty process 6671 to stop gracefully. Waiting up to 30 seconds to see Solr running on port 8983 [|] [/] Started Solr server on port 8983 (pid = 6906). Happy searching!
Solr — help命令
Solr的**help**命令可用于检查Solr提示及其选项的使用情况。
[Hadoop@localhost bin]$ ./Solr -help Usage: Solr COMMAND OPTIONS where COMMAND is one of: start, stop, restart, status, healthcheck, create, create_core, create_collection, delete, version, zk Standalone server example (start Solr running in the background on port 8984): ./Solr start -p 8984 SolrCloud example (start Solr running in SolrCloud mode using localhost:2181 to connect to Zookeeper, with 1g max heap size and remote Java debug options enabled): ./Solr start -c -m 1g -z localhost:2181 -a "-Xdebug - Xrunjdwp:transport = dt_socket,server = y,suspend = n,address = 1044" Pass -help after any COMMAND to see command-specific usage information, such as: ./Solr start -help or ./Solr stop -help
Solr — status命令
Solr的**status**命令可用于搜索和查找计算机上正在运行的Solr实例。它可以为您提供有关Solr实例的信息,例如其版本、内存使用情况等。
可以使用以下 status 命令检查 Solr 实例的状态:
[Hadoop@localhost bin]$ ./Solr status
执行上述命令后,Solr 的状态将显示如下:
Found 1 Solr nodes:
Solr process 6906 running on port 8983 {
"Solr_home":"/home/Hadoop/Solr/server/Solr",
"version":"6.2.0 764d0f19151dbff6f5fcd9fc4b2682cf934590c5 -
mike - 2016-08-20 05:41:37",
"startTime":"2016-09-20T06:00:02.877Z",
"uptime":"0 days, 0 hours, 5 minutes, 14 seconds",
"memory":"30.6 MB (%6.2) of 490.7 MB"
}
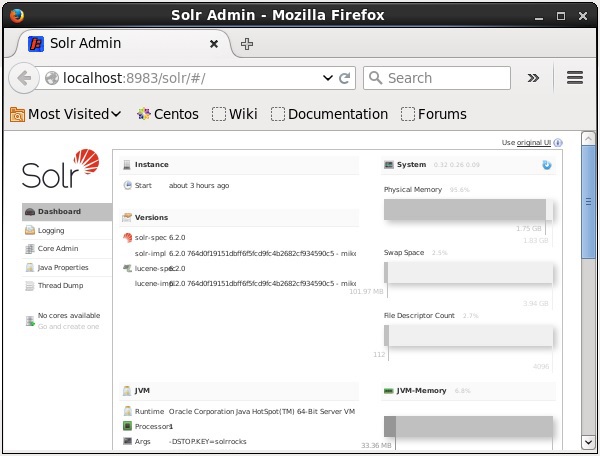
Solr 管理界面
启动 Apache Solr 后,您可以使用以下 URL 访问Solr Web 界面的主页。
Localhost:8983/Solr/
Solr 管理界面的外观如下:
Apache Solr - Core
Solr Core 是 Lucene 索引的运行实例,其中包含使用它所需的所有 Solr 配置文件。我们需要创建一个 Solr Core 来执行索引和分析等操作。
一个 Solr 应用程序可能包含一个或多个 Core。如有必要,Solr 应用程序中的两个 Core 可以相互通信。
创建 Core
安装并启动 Solr 后,您可以连接到 Solr 的客户端(Web 界面)。
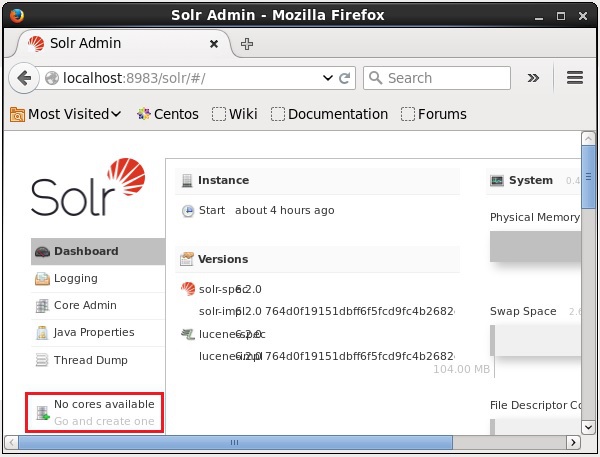
如下面的屏幕截图所示,最初 Apache Solr 中没有 Core。现在,我们将了解如何在 Solr 中创建 Core。
使用 create 命令
创建 Core 的一种方法是使用create命令创建一个无模式 Core,如下所示:
[Hadoop@localhost bin]$ ./Solr create -c Solr_sample
在这里,我们尝试在 Apache Solr 中创建一个名为Solr_sample 的 Core。此命令将创建一个 Core 并显示以下消息。
Copying configuration to new core instance directory:
/home/Hadoop/Solr/server/Solr/Solr_sample
Creating new core 'Solr_sample' using command:
https://:8983/Solr/admin/cores?action=CREATE&name=Solr_sample&instanceD
ir = Solr_sample {
"responseHeader":{
"status":0,
"QTime":11550
},
"core":"Solr_sample"
}
您可以在 Solr 中创建多个 Core。在 Solr 管理界面的左侧,您可以看到一个Core 选择器,您可以在其中选择新创建的 Core,如下面的屏幕截图所示。
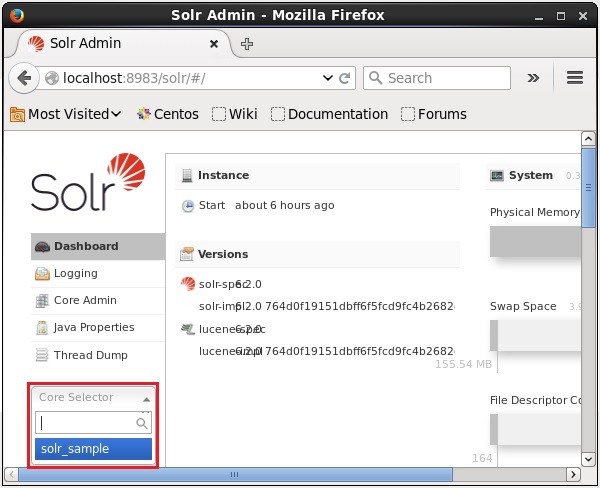
使用 create_core 命令
或者,您可以使用create_core命令创建 Core。此命令具有以下选项:
| –c core_name | 要创建的 Core 的名称 |
| -p port_name | 要创建 Core 的端口 |
| -d conf_dir | 端口的配置目录 |
让我们看看如何使用create_core命令。在这里,我们将尝试创建一个名为my_core 的 Core。
[Hadoop@localhost bin]$ ./Solr create_core -c my_core
执行上述命令后,将创建一个 Core 并显示以下消息:
Copying configuration to new core instance directory:
/home/Hadoop/Solr/server/Solr/my_core
Creating new core 'my_core' using command:
https://:8983/Solr/admin/cores?action=CREATE&name=my_core&instanceD
ir = my_core {
"responseHeader":{
"status":0,
"QTime":1346
},
"core":"my_core"
}
删除 Core
您可以使用 Apache Solr 的delete命令删除 Core。假设我们在 Solr 中有一个名为my_core 的 Core,如下面的屏幕截图所示。
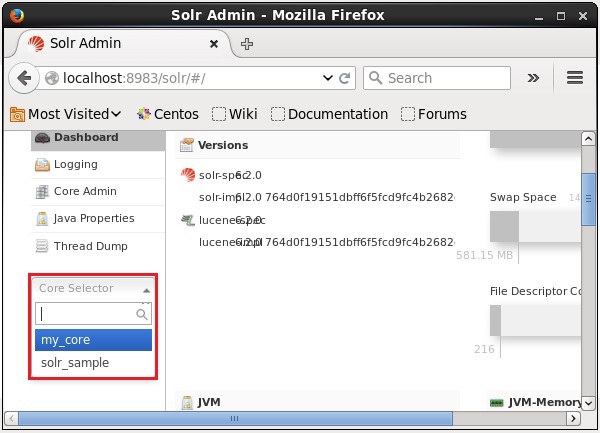
您可以使用delete命令通过将 Core 的名称传递给此命令来删除此 Core,如下所示:
[Hadoop@localhost bin]$ ./Solr delete -c my_core
执行上述命令后,将删除指定的 Core 并显示以下消息。
Deleting core 'my_core' using command:
https://:8983/Solr/admin/cores?action=UNLOAD&core = my_core&deleteIndex
= true&deleteDataDir = true&deleteInstanceDir = true {
"responseHeader" :{
"status":0,
"QTime":170
}
}
您可以打开 Solr 的 Web 界面来验证 Core 是否已被删除。
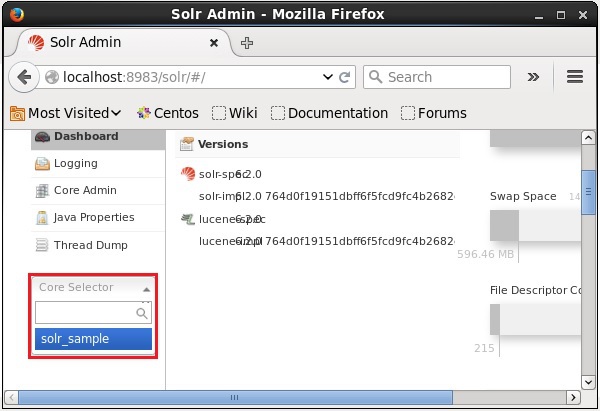
Apache Solr - 索引数据
一般来说,索引是对文档或(其他实体)进行系统化的排列。索引使用户能够在文档中查找信息。
索引收集、解析和存储文档。
进行索引是为了提高查找所需文档时搜索查询的速度和性能。
Apache Solr 中的索引
在 Apache Solr 中,我们可以索引(添加、删除、修改)各种文档格式,例如 xml、csv、pdf 等。我们可以通过多种方式将数据添加到 Solr 索引中。
本章将讨论索引:
- 使用 Solr Web 界面。
- 使用任何客户端 API,例如 Java、Python 等。
- 使用post 工具。
本章将讨论如何使用各种接口(命令行、Web 界面和 Java 客户端 API)将数据添加到 Apache Solr 的索引中。
使用 Post 命令添加文档
Solr 的bin/目录中有一个post命令。使用此命令,您可以将 JSON、XML、CSV 等各种格式的文件索引到 Apache Solr 中。
浏览 Apache Solr 的bin目录并执行 post 命令的–h 选项,如下面的代码块所示。
[Hadoop@localhost bin]$ cd $SOLR_HOME [Hadoop@localhost bin]$ ./post -h
执行上述命令后,您将获得post 命令的选项列表,如下所示。
Usage: post -c <collection> [OPTIONS] <files|directories|urls|-d [".."]>
or post –help
collection name defaults to DEFAULT_SOLR_COLLECTION if not specified
OPTIONS
=======
Solr options:
-url <base Solr update URL> (overrides collection, host, and port)
-host <host> (default: localhost)
-p or -port <port> (default: 8983)
-commit yes|no (default: yes)
Web crawl options:
-recursive <depth> (default: 1)
-delay <seconds> (default: 10)
Directory crawl options:
-delay <seconds> (default: 0)
stdin/args options:
-type <content/type> (default: application/xml)
Other options:
-filetypes <type>[,<type>,...] (default:
xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,
rtf,htm,html,txt,log)
-params "<key> = <value>[&<key> = <value>...]" (values must be
URL-encoded; these pass through to Solr update request)
-out yes|no (default: no; yes outputs Solr response to console)
-format Solr (sends application/json content as Solr commands
to /update instead of /update/json/docs)
Examples:
* JSON file:./post -c wizbang events.json
* XML files: ./post -c records article*.xml
* CSV file: ./post -c signals LATEST-signals.csv
* Directory of files: ./post -c myfiles ~/Documents
* Web crawl: ./post -c gettingstarted http://lucene.apache.org/Solr -recursive 1 -delay 1
* Standard input (stdin): echo '{commit: {}}' | ./post -c my_collection -
type application/json -out yes –d
* Data as string: ./post -c signals -type text/csv -out yes -d $'id,value\n1,0.47'
示例
假设我们有一个名为sample.csv的文件,其内容如下(在bin目录中)。
| 学生 ID | 名字 | 姓氏 | 电话 | 城市 |
|---|---|---|---|---|
| 001 | Rajiv | Reddy | 9848022337 | 海德拉巴 |
| 002 | Siddharth | Bhattacharya | 9848022338 | 加尔各答 |
| 003 | Rajesh | Khanna | 9848022339 | 德里 |
| 004 | Preethi | Agarwal | 9848022330 | 浦那 |
| 005 | Trupthi | Mohanty | 9848022336 | 布巴内斯瓦尔 |
| 006 | Archana | Mishra | 9848022335 | 钦奈 |
以上数据集包含个人详细信息,例如学生 ID、名字、姓氏、电话和城市。数据集的 CSV 文件如下所示。这里,您必须注意,您需要提及模式,并记录其第一行。
id, first_name, last_name, phone_no, location 001, Pruthvi, Reddy, 9848022337, Hyderabad 002, kasyap, Sastry, 9848022338, Vishakapatnam 003, Rajesh, Khanna, 9848022339, Delhi 004, Preethi, Agarwal, 9848022330, Pune 005, Trupthi, Mohanty, 9848022336, Bhubaneshwar 006, Archana, Mishra, 9848022335, Chennai
您可以使用post命令将此数据索引到名为sample_Solr 的 Core 中,如下所示:
[Hadoop@localhost bin]$ ./post -c Solr_sample sample.csv
执行上述命令后,给定的文档将被索引到指定的 Core 中,并生成以下输出。
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-core 6.2.0.jar -Dauto = yes -Dc = Solr_sample -Ddata = files org.apache.Solr.util.SimplePostTool sample.csv SimplePostTool version 5.0.0 Posting files to [base] url https://:8983/Solr/Solr_sample/update... Entering auto mode. File endings considered are xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf, htm,html,txt,log POSTing file sample.csv (text/csv) to [base] 1 files indexed. COMMITting Solr index changes to https://:8983/Solr/Solr_sample/update... Time spent: 0:00:00.228
使用以下 URL 访问 Solr Web UI 的主页:
https://:8983/
选择 Core Solr_sample。默认情况下,请求处理程序为/select,查询为“:” 。无需进行任何修改,单击页面底部的ExecuteQuery按钮。
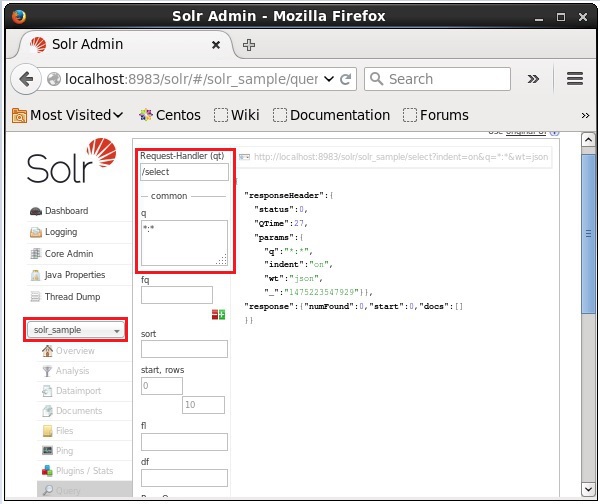
执行查询后,您可以以 JSON 格式(默认)查看已索引 CSV 文档的内容,如下面的屏幕截图所示。
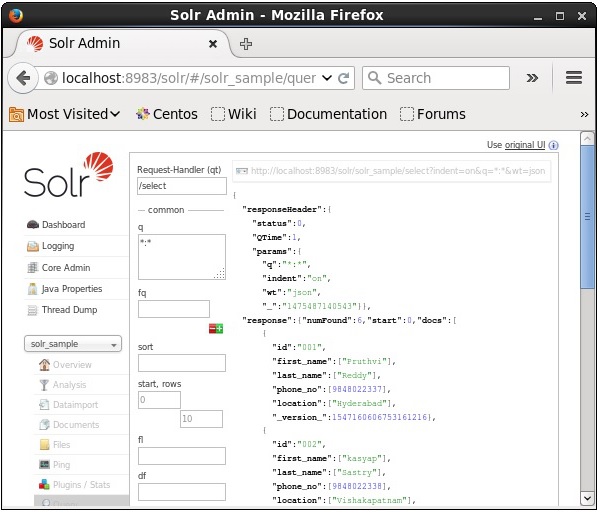
注意 - 同样,您可以索引其他文件格式,例如 JSON、XML、CSV 等。
使用 Solr Web 界面添加文档
您还可以使用 Solr 提供的 Web 界面索引文档。让我们看看如何索引以下 JSON 文档。
[
{
"id" : "001",
"name" : "Ram",
"age" : 53,
"Designation" : "Manager",
"Location" : "Hyderabad",
},
{
"id" : "002",
"name" : "Robert",
"age" : 43,
"Designation" : "SR.Programmer",
"Location" : "Chennai",
},
{
"id" : "003",
"name" : "Rahim",
"age" : 25,
"Designation" : "JR.Programmer",
"Location" : "Delhi",
}
]
步骤1
使用以下 URL 打开 Solr Web 界面:
https://:8983/
步骤2
选择 Core Solr_sample。默认情况下,请求处理程序、公共范围、覆盖和提升字段的值分别为 /update、1000、true 和 1.0,如下面的屏幕截图所示。
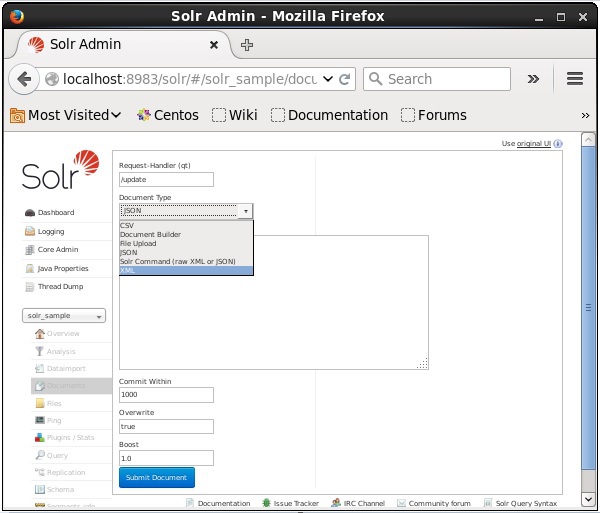
现在,从 JSON、CSV、XML 等中选择您想要的文档格式。在文本区域中键入要索引的文档,然后单击Submit Document按钮,如下面的屏幕截图所示。
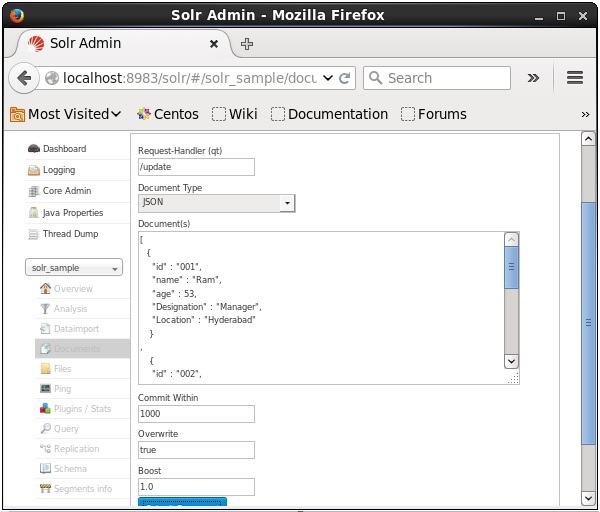
使用 Java 客户端 API 添加文档
以下是将文档添加到 Apache Solr 索引的 Java 程序。将此代码保存到名为AddingDocument.java的文件中。
import java.io.IOException;
import org.apache.Solr.client.Solrj.SolrClient;
import org.apache.Solr.client.Solrj.SolrServerException;
import org.apache.Solr.client.Solrj.impl.HttpSolrClient;
import org.apache.Solr.common.SolrInputDocument;
public class AddingDocument {
public static void main(String args[]) throws Exception {
//Preparing the Solr client
String urlString = "https://:8983/Solr/my_core";
SolrClient Solr = new HttpSolrClient.Builder(urlString).build();
//Preparing the Solr document
SolrInputDocument doc = new SolrInputDocument();
//Adding fields to the document
doc.addField("id", "003");
doc.addField("name", "Rajaman");
doc.addField("age","34");
doc.addField("addr","vishakapatnam");
//Adding the document to Solr
Solr.add(doc);
//Saving the changes
Solr.commit();
System.out.println("Documents added");
}
}
通过在终端中执行以下命令来编译上述代码:
[Hadoop@localhost bin]$ javac AddingDocument [Hadoop@localhost bin]$ java AddingDocument
执行上述命令后,您将获得以下输出。
Documents added
Apache Solr - 添加文档 (XML)
在上一章中,我们解释了如何将 JSON 和 .CSV 文件格式的数据添加到 Solr 中。在本章中,我们将演示如何使用 XML 文档格式将数据添加到 Apache Solr 索引中。
示例数据
假设我们需要使用 XML 文件格式将以下数据添加到 Solr 索引中。
| 学生 ID | 名字 | 姓氏 | 电话 | 城市 |
|---|---|---|---|---|
| 001 | Rajiv | Reddy | 9848022337 | 海德拉巴 |
| 002 | Siddharth | Bhattacharya | 9848022338 | 加尔各答 |
| 003 | Rajesh | Khanna | 9848022339 | 德里 |
| 004 | Preethi | Agarwal | 9848022330 | 浦那 |
| 005 | Trupthi | Mohanty | 9848022336 | 布巴内斯瓦尔 |
| 006 | Archana | Mishra | 9848022335 | 钦奈 |
使用 XML 添加文档
要将上述数据添加到 Solr 索引中,我们需要准备一个 XML 文档,如下所示。将此文档保存到名为sample.xml的文件中。
<add>
<doc>
<field name = "id">001</field>
<field name = "first name">Rajiv</field>
<field name = "last name">Reddy</field>
<field name = "phone">9848022337</field>
<field name = "city">Hyderabad</field>
</doc>
<doc>
<field name = "id">002</field>
<field name = "first name">Siddarth</field>
<field name = "last name">Battacharya</field>
<field name = "phone">9848022338</field>
<field name = "city">Kolkata</field>
</doc>
<doc>
<field name = "id">003</field>
<field name = "first name">Rajesh</field>
<field name = "last name">Khanna</field>
<field name = "phone">9848022339</field>
<field name = "city">Delhi</field>
</doc>
<doc>
<field name = "id">004</field>
<field name = "first name">Preethi</field>
<field name = "last name">Agarwal</field>
<field name = "phone">9848022330</field>
<field name = "city">Pune</field>
</doc>
<doc>
<field name = "id">005</field>
<field name = "first name">Trupthi</field>
<field name = "last name">Mohanthy</field>
<field name = "phone">9848022336</field>
<field name = "city">Bhuwaeshwar</field>
</doc>
<doc>
<field name = "id">006</field>
<field name = "first name">Archana</field>
<field name = "last name">Mishra</field>
<field name = "phone">9848022335</field>
<field name = "city">Chennai</field>
</doc>
</add>
正如您所看到的,写入以将数据添加到索引的 XML 文件包含三个重要的标签,即<add> </add>、<doc></doc>和<field></field>。
add - 这是将文档添加到索引的根标签。它包含一个或多个要添加的文档。
doc - 我们添加的文档应该用<doc></doc>标签括起来。此文档包含字段形式的数据。
field - field 标签保存文档字段的名称和值。
准备文档后,您可以使用上一章中讨论的任何方法将此文档添加到索引中。
假设 XML 文件存在于 Solr 的bin目录中,并且它要索引到名为my_core 的 Core 中,那么您可以使用post工具将其添加到 Solr 索引中,如下所示:
[Hadoop@localhost bin]$ ./post -c my_core sample.xml
执行上述命令后,您将获得以下输出。
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr- core6.2.0.jar -Dauto = yes -Dc = my_core -Ddata = files org.apache.Solr.util.SimplePostTool sample.xml SimplePostTool version 5.0.0 Posting files to [base] url https://:8983/Solr/my_core/update... Entering auto mode. File endings considered are xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx, xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,htm,html,txt,log POSTing file sample.xml (application/xml) to [base] 1 files indexed. COMMITting Solr index changes to https://:8983/Solr/my_core/update... Time spent: 0:00:00.201
验证
访问 Apache Solr Web 界面的主页并选择 Core my_core。尝试通过在文本区域q中传递查询“:”来检索所有文档,然后执行查询。执行后,您可以看到所需数据已添加到 Solr 索引中。
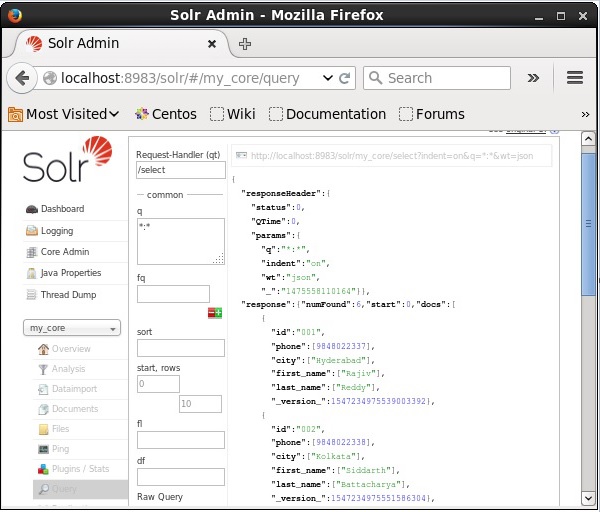
Apache Solr - 更新数据
使用 XML 更新文档
以下是用于更新现有文档中字段的 XML 文件。将其保存到名为update.xml的文件中。
<add>
<doc>
<field name = "id">001</field>
<field name = "first name" update = "set">Raj</field>
<field name = "last name" update = "add">Malhotra</field>
<field name = "phone" update = "add">9000000000</field>
<field name = "city" update = "add">Delhi</field>
</doc>
</add>
正如您所看到的,用于更新数据的 XML 文件与我们用于添加文档的 XML 文件非常相似。但唯一的区别在于我们使用了字段的update属性。
在我们的示例中,我们将使用上述文档并尝试更新 ID 为001的文档的字段。
假设 XML 文档存在于 Solr 的bin目录中。由于我们正在更新存在于名为my_core 的 Core 中的索引,因此您可以使用post工具进行更新,如下所示:
[Hadoop@localhost bin]$ ./post -c my_core update.xml
执行上述命令后,您将获得以下输出。
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-core 6.2.0.jar -Dauto = yes -Dc = my_core -Ddata = files org.apache.Solr.util.SimplePostTool update.xml SimplePostTool version 5.0.0 Posting files to [base] url https://:8983/Solr/my_core/update... Entering auto mode. File endings considered are xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf, htm,html,txt,log POSTing file update.xml (application/xml) to [base] 1 files indexed. COMMITting Solr index changes to https://:8983/Solr/my_core/update... Time spent: 0:00:00.159
验证
访问 Apache Solr Web 界面的主页并选择 Core 为my_core。尝试通过在文本区域q中传递查询“:”来检索所有文档,然后执行查询。执行后,您可以看到文档已更新。
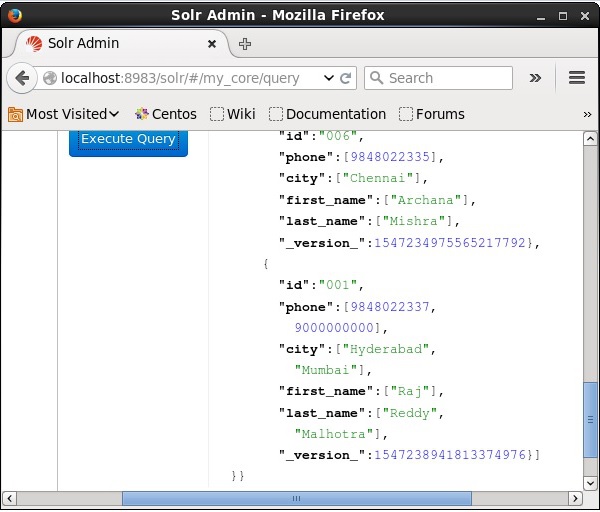
使用 Java(客户端 API)更新文档
以下是将文档添加到 Apache Solr 索引的 Java 程序。将此代码保存到名为UpdatingDocument.java的文件中。
import java.io.IOException;
import org.apache.Solr.client.Solrj.SolrClient;
import org.apache.Solr.client.Solrj.SolrServerException;
import org.apache.Solr.client.Solrj.impl.HttpSolrClient;
import org.apache.Solr.client.Solrj.request.UpdateRequest;
import org.apache.Solr.client.Solrj.response.UpdateResponse;
import org.apache.Solr.common.SolrInputDocument;
public class UpdatingDocument {
public static void main(String args[]) throws SolrServerException, IOException {
//Preparing the Solr client
String urlString = "https://:8983/Solr/my_core";
SolrClient Solr = new HttpSolrClient.Builder(urlString).build();
//Preparing the Solr document
SolrInputDocument doc = new SolrInputDocument();
UpdateRequest updateRequest = new UpdateRequest();
updateRequest.setAction( UpdateRequest.ACTION.COMMIT, false, false);
SolrInputDocument myDocumentInstantlycommited = new SolrInputDocument();
myDocumentInstantlycommited.addField("id", "002");
myDocumentInstantlycommited.addField("name", "Rahman");
myDocumentInstantlycommited.addField("age","27");
myDocumentInstantlycommited.addField("addr","hyderabad");
updateRequest.add( myDocumentInstantlycommited);
UpdateResponse rsp = updateRequest.process(Solr);
System.out.println("Documents Updated");
}
}
通过在终端中执行以下命令来编译上述代码:
[Hadoop@localhost bin]$ javac UpdatingDocument [Hadoop@localhost bin]$ java UpdatingDocument
执行上述命令后,您将获得以下输出。
Documents updated
Apache Solr - 删除文档
删除文档
要从 Apache Solr 的索引中删除文档,我们需要在<delete></delete>标签之间指定要删除的文档的 ID。
<delete> <id>003</id> <id>005</id> <id>004</id> <id>002</id> </delete>
这里,此 XML 代码用于删除 ID 为003和005的文档。将此代码保存到名为delete.xml的文件中。
如果您想删除属于名为my_core 的 Core 的索引中的文档,那么您可以使用post工具发布delete.xml文件,如下所示。
[Hadoop@localhost bin]$ ./post -c my_core delete.xml
执行上述命令后,您将获得以下输出。
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-core 6.2.0.jar -Dauto = yes -Dc = my_core -Ddata = files org.apache.Solr.util.SimplePostTool delete.xml SimplePostTool version 5.0.0 Posting files to [base] url https://:8983/Solr/my_core/update... Entering auto mode. File endings considered are xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots, rtf,htm,html,txt,log POSTing file delete.xml (application/xml) to [base] 1 files indexed. COMMITting Solr index changes to https://:8983/Solr/my_core/update... Time spent: 0:00:00.179
验证
访问 Apache Solr Web 界面的主页并选择 Core 为my_core。尝试通过在文本区域q中传递查询“:”来检索所有文档,然后执行查询。执行后,您可以看到指定的文档已被删除。
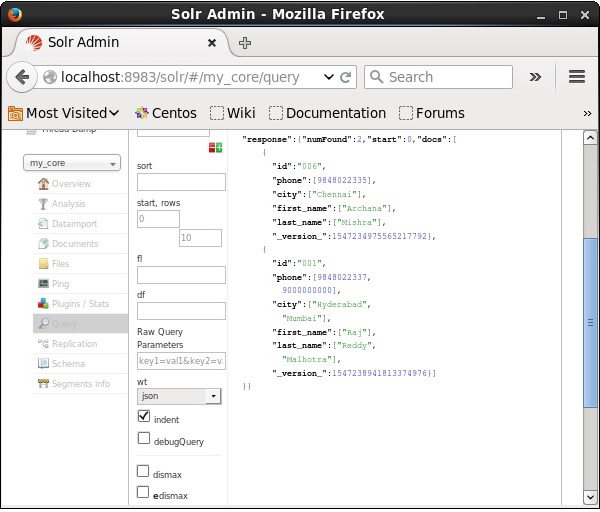
删除字段
有时我们需要根据 ID 以外的字段删除文档。例如,我们可能需要删除城市为钦奈的文档。
在这种情况下,您需要在<query></query>标签对中指定字段的名称和值。
<delete> <query>city:Chennai</query> </delete>
将其另存为delete_field.xml,然后使用 Solr 的post工具对名为my_core 的 Core 执行删除操作。
[Hadoop@localhost bin]$ ./post -c my_core delete_field.xml
执行上述命令后,它将产生以下输出。
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-core 6.2.0.jar -Dauto = yes -Dc = my_core -Ddata = files org.apache.Solr.util.SimplePostTool delete_field.xml SimplePostTool version 5.0.0 Posting files to [base] url https://:8983/Solr/my_core/update... Entering auto mode. File endings considered are xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots, rtf,htm,html,txt,log POSTing file delete_field.xml (application/xml) to [base] 1 files indexed. COMMITting Solr index changes to https://:8983/Solr/my_core/update... Time spent: 0:00:00.084
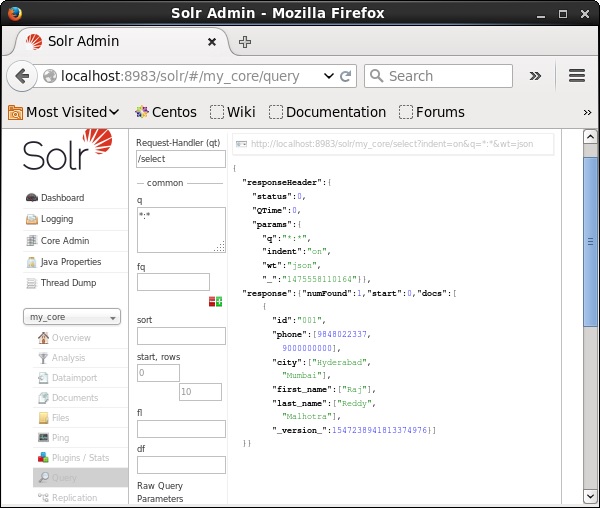
验证
访问Apache Solr Web界面的主页,选择核心为my_core。尝试在文本区域q中输入查询“:”,然后执行查询来检索所有文档。执行后,您可以观察到包含指定字段值对的文档已被删除。
删除所有文档
就像删除特定字段一样,如果您想从索引中删除所有文档,只需在<query></query>标签之间输入“:”,如下所示。
<delete> <query>*:*</query> </delete>
将其保存为delete_all.xml,并使用Solr的post工具对名为my_core的核心执行删除操作。
[Hadoop@localhost bin]$ ./post -c my_core delete_all.xml
执行上述命令后,它将产生以下输出。
/home/Hadoop/java/bin/java -classpath /home/Hadoop/Solr/dist/Solr-core 6.2.0.jar -Dauto = yes -Dc = my_core -Ddata = files org.apache.Solr.util.SimplePostTool deleteAll.xml SimplePostTool version 5.0.0 Posting files to [base] url https://:8983/Solr/my_core/update... Entering auto mode. File endings considered are xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf, htm,html,txt,log POSTing file deleteAll.xml (application/xml) to [base] 1 files indexed. COMMITting Solr index changes to https://:8983/Solr/my_core/update... Time spent: 0:00:00.138
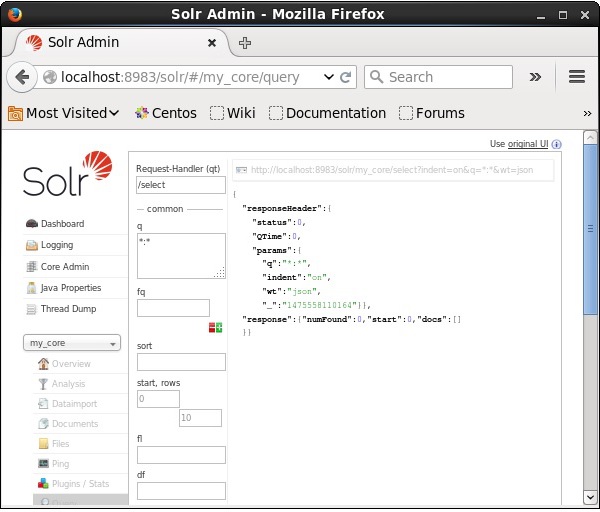
验证
访问Apache Solr Web界面的主页,选择核心为my_core。尝试在文本区域q中输入查询“:”,然后执行查询来检索所有文档。执行后,您可以观察到包含指定字段值对的文档已被删除。
使用Java(客户端API)删除所有文档
以下是将文档添加到 Apache Solr 索引的 Java 程序。将此代码保存到名为UpdatingDocument.java的文件中。
import java.io.IOException;
import org.apache.Solr.client.Solrj.SolrClient;
import org.apache.Solr.client.Solrj.SolrServerException;
import org.apache.Solr.client.Solrj.impl.HttpSolrClient;
import org.apache.Solr.common.SolrInputDocument;
public class DeletingAllDocuments {
public static void main(String args[]) throws SolrServerException, IOException {
//Preparing the Solr client
String urlString = "https://:8983/Solr/my_core";
SolrClient Solr = new HttpSolrClient.Builder(urlString).build();
//Preparing the Solr document
SolrInputDocument doc = new SolrInputDocument();
//Deleting the documents from Solr
Solr.deleteByQuery("*");
//Saving the document
Solr.commit();
System.out.println("Documents deleted");
}
}
通过在终端中执行以下命令来编译上述代码:
[Hadoop@localhost bin]$ javac DeletingAllDocuments [Hadoop@localhost bin]$ java DeletingAllDocuments
执行上述命令后,您将获得以下输出。
Documents deleted
Apache Solr - 检索数据
本章将讨论如何使用Java客户端API检索数据。假设我们有一个名为sample.csv的.csv文档,其内容如下。
001,9848022337,Hyderabad,Rajiv,Reddy 002,9848022338,Kolkata,Siddarth,Battacharya 003,9848022339,Delhi,Rajesh,Khanna
您可以使用post命令将此数据索引到名为sample_Solr的核心下。
[Hadoop@localhost bin]$ ./post -c Solr_sample sample.csv
以下是将文档添加到Apache Solr索引的Java程序。将此代码保存到名为RetrievingData.java的文件中。
import java.io.IOException;
import org.apache.Solr.client.Solrj.SolrClient;
import org.apache.Solr.client.Solrj.SolrQuery;
import org.apache.Solr.client.Solrj.SolrServerException;
import org.apache.Solr.client.Solrj.impl.HttpSolrClient;
import org.apache.Solr.client.Solrj.response.QueryResponse;
import org.apache.Solr.common.SolrDocumentList;
public class RetrievingData {
public static void main(String args[]) throws SolrServerException, IOException {
//Preparing the Solr client
String urlString = "https://:8983/Solr/my_core";
SolrClient Solr = new HttpSolrClient.Builder(urlString).build();
//Preparing Solr query
SolrQuery query = new SolrQuery();
query.setQuery("*:*");
//Adding the field to be retrieved
query.addField("*");
//Executing the query
QueryResponse queryResponse = Solr.query(query);
//Storing the results of the query
SolrDocumentList docs = queryResponse.getResults();
System.out.println(docs);
System.out.println(docs.get(0));
System.out.println(docs.get(1));
System.out.println(docs.get(2));
//Saving the operations
Solr.commit();
}
}
通过在终端中执行以下命令来编译上述代码:
[Hadoop@localhost bin]$ javac RetrievingData [Hadoop@localhost bin]$ java RetrievingData
执行上述命令后,您将获得以下输出。
{numFound = 3,start = 0,docs = [SolrDocument{id=001, phone = [9848022337],
city = [Hyderabad], first_name = [Rajiv], last_name = [Reddy],
_version_ = 1547262806014820352}, SolrDocument{id = 002, phone = [9848022338],
city = [Kolkata], first_name = [Siddarth], last_name = [Battacharya],
_version_ = 1547262806026354688}, SolrDocument{id = 003, phone = [9848022339],
city = [Delhi], first_name = [Rajesh], last_name = [Khanna],
_version_ = 1547262806029500416}]}
SolrDocument{id = 001, phone = [9848022337], city = [Hyderabad], first_name = [Rajiv],
last_name = [Reddy], _version_ = 1547262806014820352}
SolrDocument{id = 002, phone = [9848022338], city = [Kolkata], first_name = [Siddarth],
last_name = [Battacharya], _version_ = 1547262806026354688}
SolrDocument{id = 003, phone = [9848022339], city = [Delhi], first_name = [Rajesh],
last_name = [Khanna], _version_ = 1547262806029500416}
Apache Solr - 查询数据
除了存储数据外,Apache Solr还提供按需查询数据的功能。Solr提供了一些参数,我们可以用这些参数来查询其中存储的数据。
下表列出了Apache Solr中可用的各种查询参数。
| 参数 | 描述 |
|---|---|
| q | 这是Apache Solr的主要查询参数,文档根据其与该参数中词语的相似度进行评分。 |
| fq | 此参数表示Apache Solr的过滤器查询,它将结果集限制为与该过滤器匹配的文档。 |
| start | start参数表示分页结果的起始偏移量,此参数的默认值为0。 |
| rows | 此参数表示每页要检索的文档数量。此参数的默认值为10。 |
| sort | 此参数指定字段列表(用逗号分隔),根据这些字段对查询结果进行排序。 |
| fl | 此参数指定要为结果集中的每个文档返回的字段列表。 |
| wt | 此参数表示我们想要查看结果的响应编写器的类型。 |
您可以将所有这些参数作为查询Apache Solr的选项。访问Apache Solr的主页。在页面左侧,单击“查询”选项。在这里,您可以看到查询参数的字段。
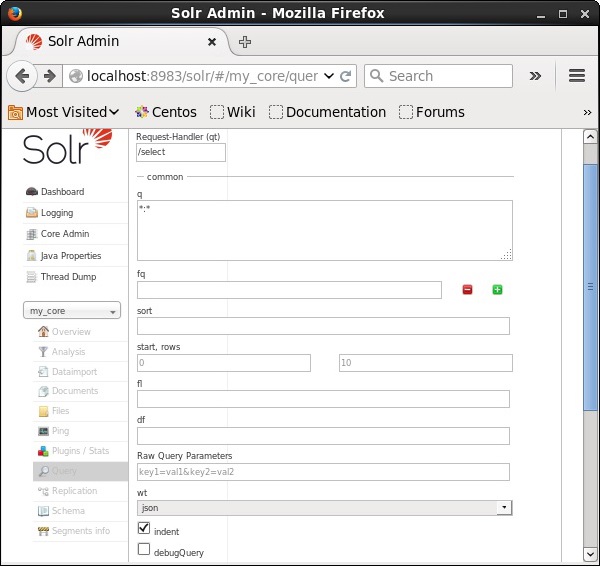
检索记录
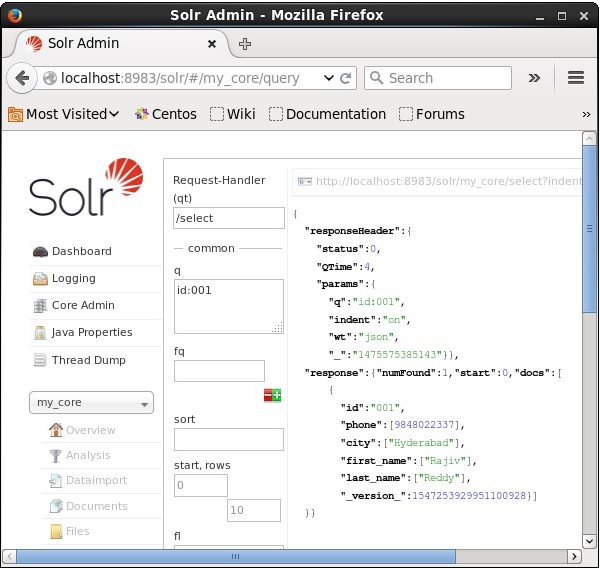
假设我们在名为my_core的核心中有3条记录。要从选定的核心检索特定记录,您需要传递特定文档字段的名称和值对。例如,如果您想检索字段id值为001的记录,您需要将字段的名称值对作为参数q的值传递,例如:Id:001,然后执行查询。
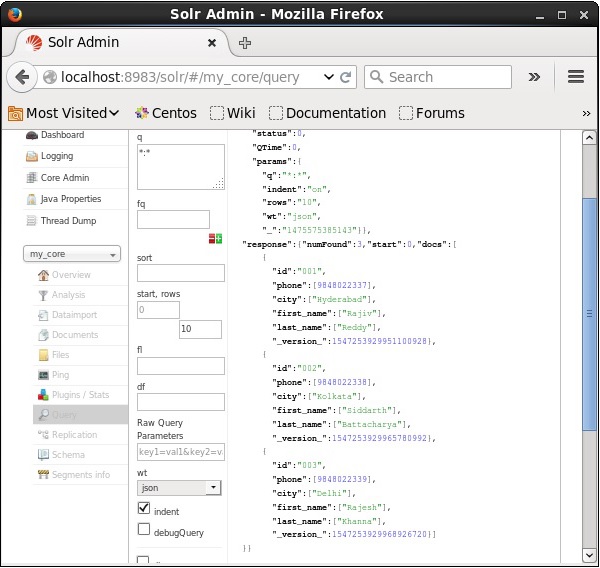
同样,您可以通过将*:*作为参数q的值来检索索引中的所有记录,如下面的屏幕截图所示。
从第2条记录开始检索
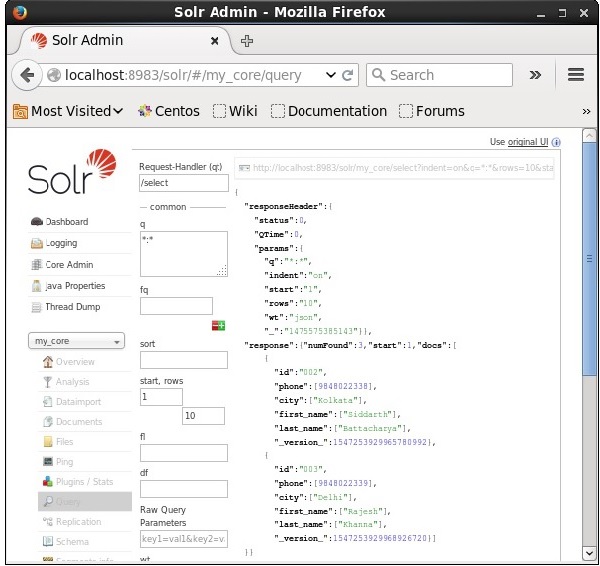
我们可以通过将2作为参数start的值来从第二条记录开始检索记录,如下面的屏幕截图所示。
限制记录数量
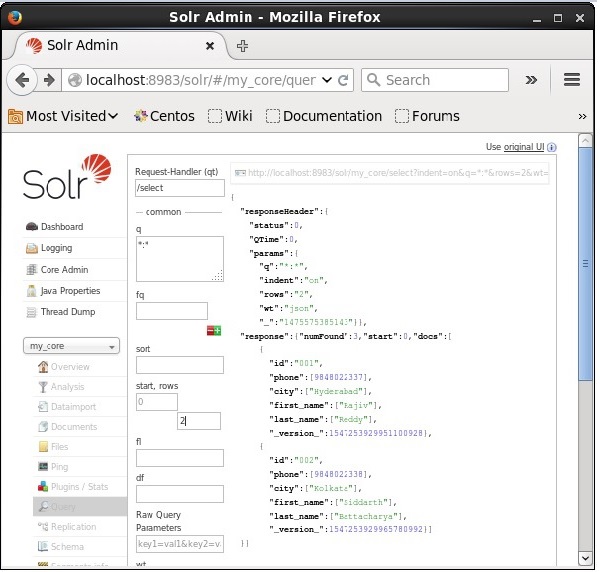
您可以通过在rows参数中指定一个值来限制记录数量。例如,我们可以通过将值2传递给参数rows来将查询结果中的记录总数限制为2,如下面的屏幕截图所示。
响应编写器类型
您可以通过从参数wt提供的多个值中选择一个来获得所需文档类型的响应。
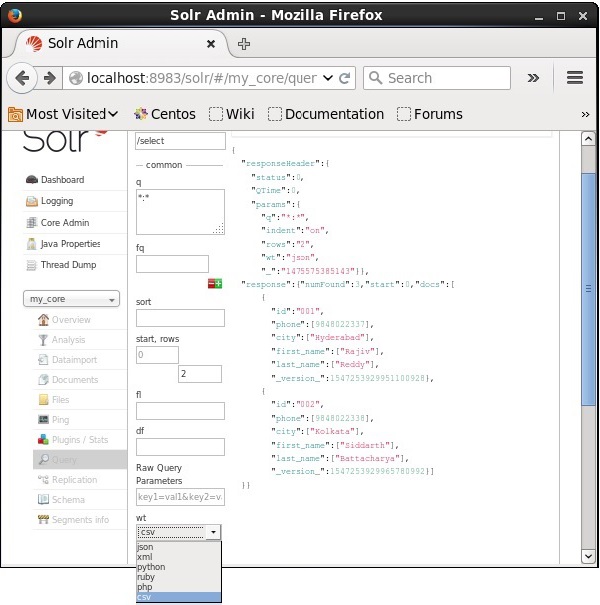
在上例中,我们选择了.csv格式来获取响应。
字段列表
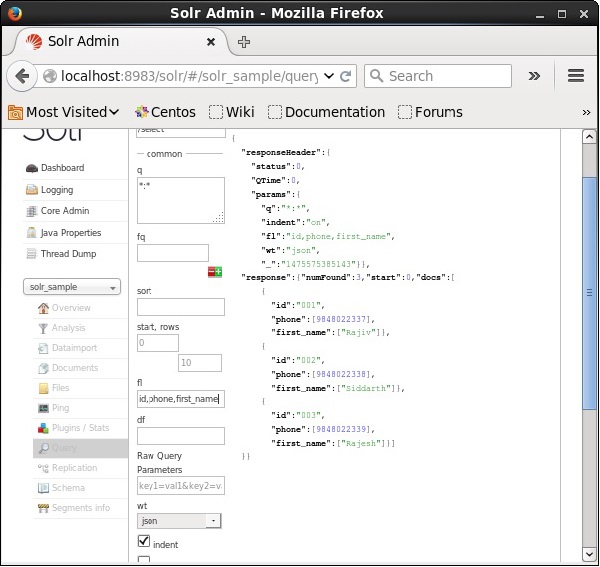
如果我们想要在结果文档中包含特定字段,我们需要将所需字段的列表(用逗号分隔)作为属性fl的值传递。
在下面的示例中,我们尝试检索字段:id、phone和first_name。
Apache Solr - 分面搜索
Apache Solr中的分面是指将搜索结果分类到各个类别。本章将讨论Apache Solr中可用的分面类型:
查询分面 - 它返回当前搜索结果中也匹配给定查询的文档数量。
日期分面 - 它返回属于特定日期范围的文档数量。
分面命令添加到任何普通的Solr查询请求中,分面计数在同一个查询响应中返回。
分面查询示例
使用字段faceting,我们可以检索所有词语的计数,或者只是任何给定字段中的前几个词语的计数。
例如,让我们考虑一下包含各种书籍数据的books.csv文件。
id,cat,name,price,inStock,author,series_t,sequence_i,genre_s 0553573403,book,A Game of Thrones,5.99,true,George R.R. Martin,"A Song of Ice and Fire",1,fantasy 0553579908,book,A Clash of Kings,10.99,true,George R.R. Martin,"A Song of Ice and Fire",2,fantasy 055357342X,book,A Storm of Swords,7.99,true,George R.R. Martin,"A Song of Ice and Fire",3,fantasy 0553293354,book,Foundation,7.99,true,Isaac Asimov,Foundation Novels,1,scifi 0812521390,book,The Black Company,4.99,false,Glen Cook,The Chronicles of The Black Company,1,fantasy 0812550706,book,Ender's Game,6.99,true,Orson Scott Card,Ender,1,scifi 0441385532,book,Jhereg,7.95,false,Steven Brust,Vlad Taltos,1,fantasy 0380014300,book,Nine Princes In Amber,6.99,true,Roger Zelazny,the Chronicles of Amber,1,fantasy 0805080481,book,The Book of Three,5.99,true,Lloyd Alexander,The Chronicles of Prydain,1,fantasy 080508049X,book,The Black Cauldron,5.99,true,Lloyd Alexander,The Chronicles of Prydain,2,fantasy
让我们使用post工具将此文件发布到Apache Solr。
[Hadoop@localhost bin]$ ./post -c Solr_sample sample.csv
执行上述命令后,给定.csv文件中提到的所有文档都将上传到Apache Solr。
现在,让我们在集合/核心my_core上对字段author执行一个包含0行记录的分面查询。
打开Apache Solr的Web UI,在页面左侧,选中facet复选框,如下面的屏幕截图所示。
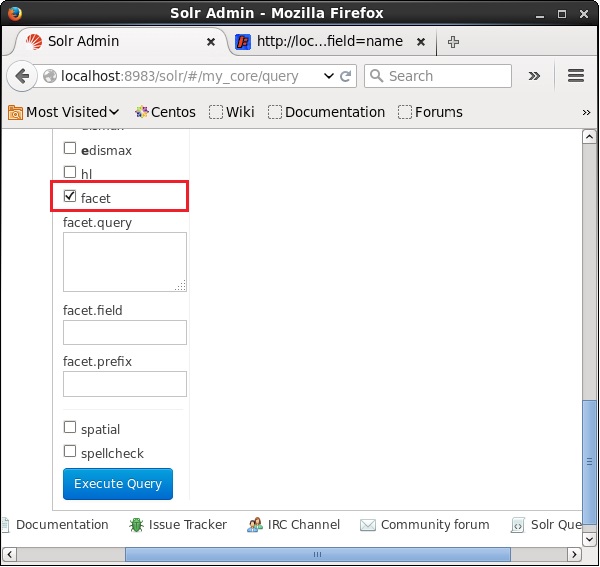
选中复选框后,您将有另外三个文本字段来传递分面搜索的参数。现在,作为查询的参数,传递以下值。
q = *:*, rows = 0, facet.field = author
最后,点击执行查询按钮执行查询。
执行后,将生成以下结果。
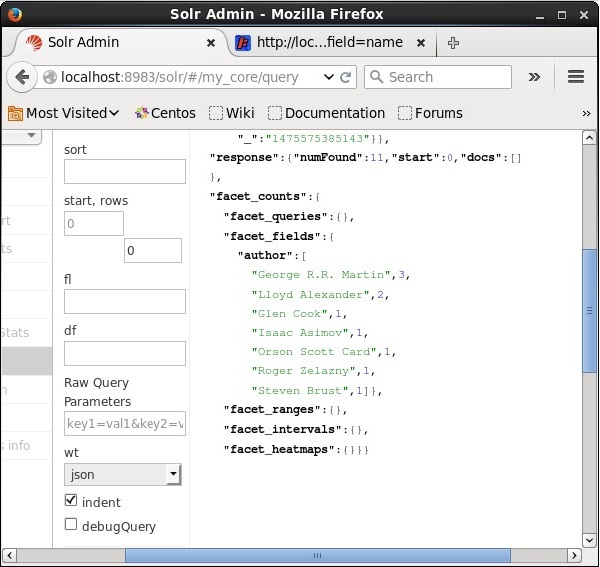
它根据作者对索引中的文档进行分类,并指定每位作者贡献的书籍数量。
使用Java客户端API进行分面
以下是将文档添加到Apache Solr索引的Java程序。将此代码保存到名为HitHighlighting.java的文件中。
import java.io.IOException;
import java.util.List;
import org.apache.Solr.client.Solrj.SolrClient;
import org.apache.Solr.client.Solrj.SolrQuery;
import org.apache.Solr.client.Solrj.SolrServerException;
import org.apache.Solr.client.Solrj.impl.HttpSolrClient;
import org.apache.Solr.client.Solrj.request.QueryRequest;
import org.apache.Solr.client.Solrj.response.FacetField;
import org.apache.Solr.client.Solrj.response.FacetField.Count;
import org.apache.Solr.client.Solrj.response.QueryResponse;
import org.apache.Solr.common.SolrInputDocument;
public class HitHighlighting {
public static void main(String args[]) throws SolrServerException, IOException {
//Preparing the Solr client
String urlString = "https://:8983/Solr/my_core";
SolrClient Solr = new HttpSolrClient.Builder(urlString).build();
//Preparing the Solr document
SolrInputDocument doc = new SolrInputDocument();
//String query = request.query;
SolrQuery query = new SolrQuery();
//Setting the query string
query.setQuery("*:*");
//Setting the no.of rows
query.setRows(0);
//Adding the facet field
query.addFacetField("author");
//Creating the query request
QueryRequest qryReq = new QueryRequest(query);
//Creating the query response
QueryResponse resp = qryReq.process(Solr);
//Retrieving the response fields
System.out.println(resp.getFacetFields());
List<FacetField> facetFields = resp.getFacetFields();
for (int i = 0; i > facetFields.size(); i++) {
FacetField facetField = facetFields.get(i);
List<Count> facetInfo = facetField.getValues();
for (FacetField.Count facetInstance : facetInfo) {
System.out.println(facetInstance.getName() + " : " +
facetInstance.getCount() + " [drilldown qry:" +
facetInstance.getAsFilterQuery());
}
System.out.println("Hello");
}
}
}
通过在终端中执行以下命令来编译上述代码:
[Hadoop@localhost bin]$ javac HitHighlighting [Hadoop@localhost bin]$ java HitHighlighting
执行上述命令后,您将获得以下输出。
[author:[George R.R. Martin (3), Lloyd Alexander (2), Glen Cook (1), Isaac Asimov (1), Orson Scott Card (1), Roger Zelazny (1), Steven Brust (1)]]