- BigQuery 教程
- BigQuery - 首页
- BigQuery - 概述
- BigQuery - 初始设置
- BigQuery 与本地 SQL 引擎的比较
- BigQuery - Google Cloud Console
- BigQuery - Google Cloud 层次结构
- 什么是 Dremel?
- 什么是 BigQuery Studio?
- BigQuery - 数据集
- BigQuery - 表
- BigQuery - 视图
- BigQuery - 创建表
- BigQuery - 基本模式设计
- BigQuery - 修改表
- BigQuery - 复制表
- 删除和恢复表
- BigQuery - 填充表
- 标准 SQL 与传统 SQL
- BigQuery - 编写第一个查询
- BigQuery - CRUD 操作
- 分区和聚类
- BigQuery - 数据类型
- BigQuery - 复杂数据类型
- BigQuery - STRUCT 数据类型
- BigQuery - ARRAY 数据类型
- BigQuery - JSON 数据类型
- BigQuery - 表元数据
- BigQuery - 用户定义函数
- 连接到外部数据源
- 集成计划查询
- 集成 BigQuery API
- BigQuery - 集成 Airflow
- 集成连接的表格
- 集成数据传输
- BigQuery - 物化视图
- BigQuery - 角色和权限
- BigQuery - 查询优化
- BigQuery - BI 引擎
- 监控使用情况和性能
- BigQuery - 数据仓库
- 挑战和最佳实践
- BigQuery 资源
- BigQuery - 快速指南
- BigQuery - 资源
- BigQuery - 讨论
BigQuery - 物化视图
除了创建表和视图外,BigQuery 还方便创建物化视图。
什么是物化视图?
物化视图类似于表,因为它也是数据的“快照”。但是,物化视图的不同之处在于,真正的物化视图会动态更新,而无需运行查询。
物化视图的类型
广义上讲,有两种物化视图:
- 已保存为表并会定期从外部来源更新的视图。
- 在 BigQuery Studio 中创建的“真正”物化视图。
以下是第一种视图的示例架构:
- SQL 查询现有视图
- 在 Python 脚本中,该视图被转换为数据帧
- 数据帧上传到 BigQuery
- 物化视图被追加或覆盖
由于上述方法是一个多步骤过程,BigQuery 简化了物化视图的创建和维护。
创建 BigQuery 物化视图
用户可以通过运行 **CREATE MATERIALIZED VIEW** SQL 语句来创建 BigQuery 物化视图,后跟:
- 项目
- 数据集
- 新的物化视图名称
- SQL 语句
示例
这是一个示例,其中一个包含假设销售数据的现有表被物化:
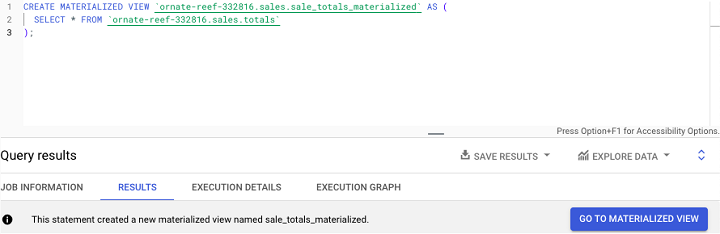
请注意 BigQuery 文档中列出的以下 **限制**:
- 每个表在一个数据集内最多可包含 20 个物化视图
- 一个项目中最多只能有 100 个物化视图
- 一个组织中最多只能有 500 个物化视图
在 BigQuery 中编写简单的 SQL 脚本
现在将所有内容整合在一起,是时候编写一个简单的脚本,该脚本将:
- 使用动态变量
- 删除昨天的数据
- 将新数据插入表中
- 使用查询选择/加载数据
到目前为止,尚未介绍如何在 SQL 脚本中定义和使用变量。
在 BigQuery 中,**变量语法**如下:
DECLARE variable_name TYPE DEFAULT function used to create dynamic variable
例如:
DECLARE yesterday DATE DEFAULT DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)
我们将以此开始以下脚本,该脚本将删除奥斯汀共享单车分区表中的先前数据,并且只插入最新数据。
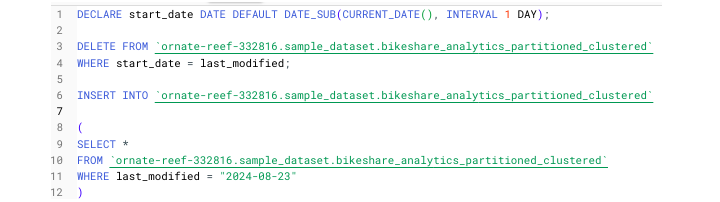
在 BigQuery 中运行此脚本时,由于分号的存在,SQL 引擎将分阶段运行它。可以通过单击“查看结果”来查看最终结果。
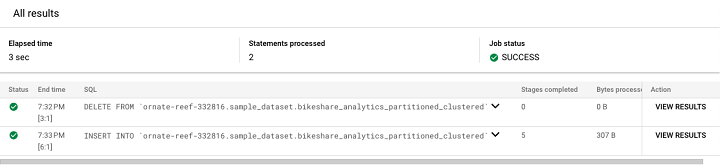
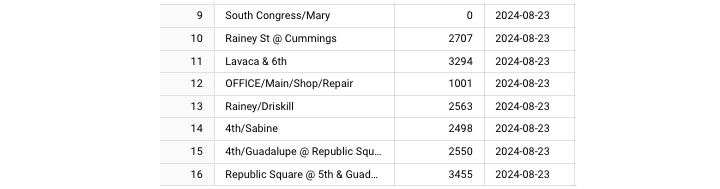
单击 **“查看结果”** 将生成此输出。

最后,我们可以看到添加到表中的新行。
广告